-
The presence of certain clinical dermoscopic features within a skin lesion
may indicate melanoma, and automatically detecting these features may lead to
more quantitative and reproducible diagnoses. We reformulate the task of
classifying clinical dermoscopic features within superpixels as a segmentation
problem, and propose a fully convolutional neural network to detect clinical
dermoscopic features from dermoscopy skin lesion images. Our neural network
architecture uses interpolated feature maps from several intermediate network
layers, and addresses imbalanced labels by minimizing a negative multi-label
Dice-F$_1$ score, where the score is computed across the mini-batch for each
label. Our approach ranked first place in the 2017 ISIC-ISBI Part 2:
Dermoscopic Feature Classification Task challenge over both the provided
validation and test datasets, achieving a 0.895% area under the receiver
operator characteristic curve score. We show how simple baseline models can
outrank state-of-the-art approaches when using the official metrics of the
challenge, and propose to use a fuzzy Jaccard Index that ignores the empty set
(i.e., masks devoid of positive pixels) when ranking models. Our results
suggest that (i) the classification of clinical dermoscopic features can be
effectively approached as a segmentation problem, and (ii) the current metrics
used to rank models may not well capture the efficacy of the model. We plan to
make our trained model and code publicly available.
-
In interpretation of remote sensing images, it is possible that some images
which are supplied by different sensors become incomprehensible. For better
visual perception of these images, it is essential to operate series of
pre-processing and elementary corrections and then operate a series of main
processing steps for more precise analysis on the images. There are several
approaches for processing which are depended on the type of remote sensing
images. The discussed approach in this article, i.e. image fusion, is the use
of natural colors of an optical image for adding color to a grayscale satellite
image which gives us the ability for better observation of the HR image of OLI
sensor of Landsat-8. This process with emphasis on details of fusion technique
has previously been performed; however, we are going to apply the concept of
the interpolation process. In fact, we see many important software tools such
as ENVI and ERDAS as the most famous remote sensing image processing tools have
only classical interpolation techniques (such as bi-linear (BL) and
bi-cubic/cubic convolution (CC)). Therefore, ENVI- and ERDAS-based researches
in image fusion area and even other fusion researches often dont use new and
better interpolators and are mainly concentrated on the fusion algorithms
details for achieving a better quality, so we only focus on the interpolation
impact on fusion quality in Landsat-8 multispectral images. The important
feature of this approach is to use a statistical, adaptive, and edge-guided
interpolation method for improving the color quality in the images in practice.
Numerical simulations show selecting the suitable interpolation techniques in
MRF-based images creates better quality than the classical interpolators.
-
Context categorization is a fundamental pre-requisite for multi-domain
multimedia content analysis applications in order to manage contextual
information in an efficient manner. In this paper, we introduce a new color
image context categorization method (DITEC) based on the trace transform. The
problem of dimensionality reduction of the obtained trace transform signal is
addressed through statistical descriptors that keep the underlying information.
These extracted features offer a highly discriminant behavior for content
categorization. The theoretical properties of the method are analyzed and
validated experimentally through two different datasets.
-
Approximate nearest neighbour (ANN) search is one of the most important
problems in computer science fields such as data mining or computer vision. In
this paper, we focus on ANN for high-dimensional binary vectors and we propose
a simple yet powerful search method that uses Random Binary Search Trees
(RBST). We apply our method to a dataset of 1.25M binary local feature
descriptors obtained from a real-life image-based localisation system provided
by Google as a part of Project Tango. An extensive evaluation of our method
against the state-of-the-art variations of Locality Sensitive Hashing (LSH),
namely Uniform LSH and Multi-probe LSH, shows the superiority of our method in
terms of retrieval precision with performance boost of over 20%
-
We propose a novel approach to address the problem of Simultaneous Detection
and Segmentation introduced in [Hariharan et al 2014]. Using the hierarchical
structures first presented in [Arbel\'aez et al 2011] we use an efficient and
accurate procedure that exploits the feature information of the hierarchy using
Locality Sensitive Hashing. We build on recent work that utilizes convolutional
neural networks to detect bounding boxes in an image [Ren et al 2015] and then
use the top similar hierarchical region that best fits each bounding box after
hashing, we call this approach C&Z Segmentation. We then refine our final
segmentation results by automatic hierarchical pruning. C&Z Segmentation
introduces a train-free alternative to Hypercolumns [Hariharan et al 2015]. We
conduct extensive experiments on PASCAL VOC 2012 segmentation dataset, showing
that C&Z gives competitive state-of-the-art segmentations of objects.
-
Reliable obstacle detection and classification in rough and unstructured
terrain such as agricultural fields or orchards remains a challenging problem.
These environments involve large variations in both geometry and appearance,
challenging perception systems that rely on only a single sensor modality.
Geometrically, tall grass, fallen leaves, or terrain roughness can mistakenly
be perceived as nontraversable or might even obscure actual obstacles.
Likewise, traversable grass or dirt roads and obstacles such as trees and
bushes might be visually ambiguous. In this paper, we combine appearance- and
geometry-based detection methods by probabilistically fusing lidar and camera
sensing with semantic segmentation using a conditional random field. We apply a
state-of-the-art multimodal fusion algorithm from the scene analysis domain and
adjust it for obstacle detection in agriculture with moving ground vehicles.
This involves explicitly handling sparse point cloud data and exploiting both
spatial, temporal, and multimodal links between corresponding 2D and 3D
regions. The proposed method was evaluated on a diverse data set, comprising a
dairy paddock and different orchards gathered with a perception research robot
in Australia. Results showed that for a two-class classification problem
(ground and nonground), only the camera leveraged from information provided by
the other modality with an increase in the mean classification score of 0.5%.
However, as more classes were introduced (ground, sky, vegetation, and object),
both modalities complemented each other with improvements of 1.4% in 2D and
7.9% in 3D. Finally, introducing temporal links between successive frames
resulted in improvements of 0.2% in 2D and 1.5% in 3D.
-
Convolutional networks reach top quality in pixel-level video object
segmentation but require a large amount of training data (1k~100k) to deliver
such results. We propose a new training strategy which achieves
state-of-the-art results across three evaluation datasets while using 20x~1000x
less annotated data than competing methods. Our approach is suitable for both
single and multiple object segmentation. Instead of using large training sets
hoping to generalize across domains, we generate in-domain training data using
the provided annotation on the first frame of each video to synthesize ("lucid
dream") plausible future video frames. In-domain per-video training data allows
us to train high quality appearance- and motion-based models, as well as tune
the post-processing stage. This approach allows to reach competitive results
even when training from only a single annotated frame, without ImageNet
pre-training. Our results indicate that using a larger training set is not
automatically better, and that for the video object segmentation task a smaller
training set that is closer to the target domain is more effective. This
changes the mindset regarding how many training samples and general
"objectness" knowledge are required for the video object segmentation task.
-
We propose a simple yet effective technique for neural network learning. The
forward propagation is computed as usual. In back propagation, only a small
subset of the full gradient is computed to update the model parameters. The
gradient vectors are sparsified in such a way that only the top-$k$ elements
(in terms of magnitude) are kept. As a result, only $k$ rows or columns
(depending on the layout) of the weight matrix are modified, leading to a
linear reduction ($k$ divided by the vector dimension) in the computational
cost. Surprisingly, experimental results demonstrate that we can update only
1-4% of the weights at each back propagation pass. This does not result in a
larger number of training iterations. More interestingly, the accuracy of the
resulting models is actually improved rather than degraded, and a detailed
analysis is given. The code is available at https://github.com/lancopku/meProp
-
Inferring the relations between two images is an important class of tasks in
computer vision. Examples of such tasks include computing optical flow and
stereo disparity. We treat the relation inference tasks as a machine learning
problem and tackle it with neural networks. A key to the problem is learning a
representation of relations. We propose a new neural network module, contrast
association unit (CAU), which explicitly models the relations between two sets
of input variables. Due to the non-negativity of the weights in CAU, we adopt a
multiplicative update algorithm for learning these weights. Experiments show
that neural networks with CAUs are more effective in learning five fundamental
image transformations than conventional neural networks.
-
A great deal of work aims to discover large general purpose models of image
interest or memorability for visual search and information retrieval. This
paper argues that image interest is often domain and user specific, and that
efficient mechanisms for learning about this domain-specific image interest as
quickly as possible, while limiting the amount of data-labelling required, are
often more useful to end-users. This work uses pairwise image comparisons to
reduce the labelling burden on these users, and introduces an image interest
estimation approach that performs similarly to recent data hungry deep learning
approaches trained using pairwise ranking losses. Here, we use a Gaussian
process model to interpolate image interest inferred using a Bayesian ranking
approach over image features extracted using a pre-trained convolutional neural
network. Results show that fitting a Gaussian process in high-dimensional image
feature space is not only computationally feasible, but also effective across a
broad range of domains. The proposed probabilistic interest estimation approach
produces image interests paired with uncertainties that can be used to identify
images for which additional labelling is required and measure inference
convergence, allowing for sample efficient active model training. Importantly,
the probabilistic formulation allows for effective visual search and
information retrieval when limited labelling data is available.
-
This paper proposes an effective approach for the scaling registration of
$m$-D point sets. Different from the rigid transformation, the scaling
registration can not be formulated into the common least square function due to
the ill-posed problem caused by the scale factor. Therefore, this paper designs
a novel objective function for the scaling registration problem. The appearance
of this objective function is a rational fraction, where the numerator item is
the least square error and the denominator item is the square of the scale
factor. By imposing the emphasis on scale factor, the ill-posed problem can be
avoided in the scaling registration. Subsequently, the new objective function
can be solved by the proposed scaling iterative closest point (ICP) algorithm,
which can obtain the optimal scaling transformation. For the practical
applications, the scaling ICP algorithm is further extended to align partially
overlapping point sets. Finally, the proposed approach is tested on public data
sets and applied to merging grid maps of different resolutions. Experimental
results demonstrate its superiority over previous approaches on efficiency and
robustness.
-
Ensembling multiple predictions is a widely used technique for improving the
accuracy of various machine learning tasks. One obvious drawback of ensembling
is its higher execution cost during inference. In this paper, we first describe
our insights on the relationship between the probability of prediction and the
effect of ensembling with current deep neural networks; ensembling does not
help mispredictions for inputs predicted with a high probability even when
there is a non-negligible number of mispredicted inputs. This finding motivated
us to develop a way to adaptively control the ensembling. If the prediction for
an input reaches a high enough probability, i.e., the output from the softmax
function, on the basis of the confidence level, we stop ensembling for this
input to avoid wasting computation power. We evaluated the adaptive ensembling
by using various datasets and showed that it reduces the computation cost
significantly while achieving accuracy similar to that of static ensembling
using a pre-defined number of local predictions. We also show that our
statistically rigorous confidence-level-based early-exit condition reduces the
burden of task-dependent threshold tuning better compared with naive early exit
based on a pre-defined threshold in addition to yielding a better accuracy with
the same cost.
-
We discuss the geometry of rational maps from a projective space of an
arbitrary dimension to the product of projective spaces of lower dimensions
induced by linear projections. In particular, we give an algebro-geometric
variant of the projective reconstruction theorem by Hartley and Schaffalitzky
[HS09].
-
Active vision is inherently attention-driven: The agent actively selects
views to attend in order to fast achieve the vision task while improving its
internal representation of the scene being observed. Inspired by the recent
success of attention-based models in 2D vision tasks based on single RGB
images, we propose to address the multi-view depth-based active object
recognition using attention mechanism, through developing an end-to-end
recurrent 3D attentional network. The architecture takes advantage of a
recurrent neural network (RNN) to store and update an internal representation.
Our model, trained with 3D shape datasets, is able to iteratively attend to the
best views targeting an object of interest for recognizing it. To realize 3D
view selection, we derive a 3D spatial transformer network which is
differentiable for training with backpropagation, achieving much faster
convergence than the reinforcement learning employed by most existing
attention-based models. Experiments show that our method, with only depth
input, achieves state-of-the-art next-best-view performance in time efficiency
and recognition accuracy.
-
Neonatal brain segmentation in magnetic resonance (MR) is a challenging
problem due to poor image quality and low contrast between white and gray
matter regions. Most existing approaches for this problem are based on
multi-atlas label fusion strategies, which are time-consuming and sensitive to
registration errors. As alternative to these methods, we propose a
hyper-densely connected 3D convolutional neural network that employs MR-T1 and
T2 images as input, which are processed independently in two separated paths.
An important difference with previous densely connected networks is the use of
direct connections between layers from the same and different paths. Adopting
such dense connectivity helps the learning process by including deep
supervision and improving gradient flow. We evaluated our approach on data from
the MICCAI Grand Challenge on 6-month infant Brain MRI Segmentation (iSEG),
obtaining very competitive results. Among 21 teams, our approach ranked first
or second in most metrics, translating into a state-of-the-art performance.
-
The availability of labeled image datasets has been shown critical for
high-level image understanding, which continuously drives the progress of
feature designing and models developing. However, constructing labeled image
datasets is laborious and monotonous. To eliminate manual annotation, in this
work, we propose a novel image dataset construction framework by employing
multiple textual queries. We aim at collecting diverse and accurate images for
given queries from the Web. Specifically, we formulate noisy textual queries
removing and noisy images filtering as a multi-view and multi-instance learning
problem separately. Our proposed approach not only improves the accuracy but
also enhances the diversity of the selected images. To verify the effectiveness
of our proposed approach, we construct an image dataset with 100 categories.
The experiments show significant performance gains by using the generated data
of our approach on several tasks, such as image classification, cross-dataset
generalization, and object detection. The proposed method also consistently
outperforms existing weakly supervised and web-supervised approaches.
-
The image biomarker standardisation initiative (IBSI) is an independent
international collaboration which works towards standardising the extraction of
image biomarkers from acquired imaging for the purpose of high-throughput
quantitative image analysis (radiomics). Lack of reproducibility and validation
of high-throughput quantitative image analysis studies is considered to be a
major challenge for the field. Part of this challenge lies in the scantiness of
consensus-based guidelines and definitions for the process of translating
acquired imaging into high-throughput image biomarkers. The IBSI therefore
seeks to provide image biomarker nomenclature and definitions, benchmark data
sets, and benchmark values to verify image processing and image biomarker
calculations, as well as reporting guidelines, for high-throughput image
analysis.
-
Food image recognition is one of the promising applications of visual object
recognition in computer vision. In this study, a small-scale dataset consisting
of 5822 images of ten categories and a five-layer CNN was constructed to
recognize these images. The bag-of-features (BoF) model coupled with support
vector machine (SVM) was first evaluated for image classification, resulting in
an overall accuracy of 56%; while the CNN model performed much better with an
overall accuracy of 74%. Data augmentation techniques based on geometric
transformation were applied to increase the size of training images, which
achieved a significantly improved accuracy of more than 90% while preventing
the overfitting issue that occurred to the CNN based on raw training data.
Further improvements can be expected by collecting more images and optimizing
the network architecture and hyper-parameters.
-
Most blind deconvolution methods usually pre-define a large kernel size to
guarantee the support domain. Blur kernel estimation error is likely to be
introduced, yielding severe artifacts in deblurring results. In this paper, we
first theoretically and experimentally analyze the mechanism to estimation
error in oversized kernel, and show that it holds even on blurry images without
noises. Then to suppress this adverse effect, we propose a low rank-based
regularization on blur kernel to exploit the structural information in degraded
kernels, by which larger-kernel effect can be effectively suppressed. And we
propose an efficient optimization algorithm to solve it. Experimental results
on benchmark datasets show that the proposed method is comparable with the
state-of-the-arts by accordingly setting proper kernel size, and performs much
better in handling larger-size kernels quantitatively and qualitatively. The
deblurring results on real-world blurry images further validate the
effectiveness of the proposed method.
-
Fine-grained visual categorization is to recognize hundreds of subcategories
belonging to the same basic-level category, which is a highly challenging task
due to the quite subtle and local visual distinctions among similar
subcategories. Most existing methods generally learn part detectors to discover
discriminative regions for better categorization performance. However, not all
parts are beneficial and indispensable for visual categorization, and the
setting of part detector number heavily relies on prior knowledge as well as
experimental validation. As is known to all, when we describe the object of an
image via textual descriptions, we mainly focus on the pivotal characteristics,
and rarely pay attention to common characteristics as well as the background
areas. This is an involuntary transfer from human visual attention to textual
attention, which leads to the fact that textual attention tells us how many and
which parts are discriminative and significant to categorization. So textual
attention could help us to discover visual attention in image. Inspired by
this, we propose a fine-grained visual-textual representation learning (VTRL)
approach, and its main contributions are: (1) Fine-grained visual-textual
pattern mining devotes to discovering discriminative visual-textual pairwise
information for boosting categorization performance through jointly modeling
vision and text with generative adversarial networks (GANs), which
automatically and adaptively discovers discriminative parts. (2) Visual-textual
representation learning jointly combines visual and textual information, which
preserves the intra-modality and inter-modality information to generate
complementary fine-grained representation, as well as further improves
categorization performance.
-
Many machine vision applications, such as semantic segmentation and depth
prediction, require predictions for every pixel of the input image. Models for
such problems usually consist of encoders which decrease spatial resolution
while learning a high-dimensional representation, followed by decoders who
recover the original input resolution and result in low-dimensional
predictions. While encoders have been studied rigorously, relatively few
studies address the decoder side. This paper presents an extensive comparison
of a variety of decoders for a variety of pixel-wise tasks ranging from
classification, regression to synthesis. Our contributions are: (1) Decoders
matter: we observe significant variance in results between different types of
decoders on various problems. (2) We introduce new residual-like connections
for decoders. (3) We introduce a novel decoder: bilinear additive upsampling.
(4) We explore prediction artifacts.
-
We address the problem of automatic American Sign Language fingerspelling
recognition from video. Prior work has largely relied on frame-level labels,
hand-crafted features, or other constraints, and has been hampered by the
scarcity of data for this task. We introduce a model for fingerspelling
recognition that addresses these issues. The model consists of an
auto-encoder-based feature extractor and an attention-based neural
encoder-decoder, which are trained jointly. The model receives a sequence of
image frames and outputs the fingerspelled word, without relying on any
frame-level training labels or hand-crafted features. In addition, the
auto-encoder subcomponent makes it possible to leverage unlabeled data to
improve the feature learning. The model achieves 11.6% and 4.4% absolute letter
accuracy improvement respectively in signer-independent and signer-adapted
fingerspelling recognition over previous approaches that required frame-level
training labels.
-
This paper proposes a novel framework to reconstruct the dynamic magnetic
resonance images (DMRI) with motion compensation (MC). Due to the inherent
motion effects during DMRI acquisition, reconstruction of DMRI using motion
estimation/compensation (ME/MC) has been studied under a compressed sensing
(CS) scheme. In this paper, by embedding the intensity-based optical flow (OF)
constraint into the traditional CS scheme, we are able to couple the DMRI
reconstruction with motion field estimation. The formulated optimization
problem is solved by a primal-dual algorithm with linesearch due to its
efficiency when dealing with non-differentiable problems. With the estimated
motion field, the DMRI reconstruction is refined through MC. By employing the
multi-scale coarse-to-fine strategy, we are able to update the
variables(temporal image sequences and motion vectors) and to refine the image
reconstruction alternately. Moreover, the proposed framework is capable of
handling a wide class of prior information (regularizations) for DMRI
reconstruction, such as sparsity, low rank and total variation. Experiments on
various DMRI data, ranging from in vivo lung to cardiac dataset, validate the
reconstruction quality improvement using the proposed scheme in comparison to
several state-of-the-art algorithms.
-
Optimal surface segmentation is a state-of-the-art method used for
segmentation of multiple globally optimal surfaces in volumetric datasets. The
method is widely used in numerous medical image segmentation applications.
However, nodes in the graph based optimal surface segmentation method typically
encode uniformly distributed orthogonal voxels of the volume. Thus the
segmentation cannot attain an accuracy greater than a single unit voxel, i.e.
the distance between two adjoining nodes in graph space. Segmentation accuracy
higher than a unit voxel is achievable by exploiting partial volume information
in the voxels which shall result in non-equidistant spacing between adjoining
graph nodes. This paper reports a generalized graph based multiple surface
segmentation method with convex priors which can optimally segment the target
surfaces in an irregularly sampled space. The proposed method allows
non-equidistant spacing between the adjoining graph nodes to achieve subvoxel
segmentation accuracy by utilizing the partial volume information in the
voxels. The partial volume information in the voxels is exploited by computing
a displacement field from the original volume data to identify the
subvoxel-accurate centers within each voxel resulting in non-equidistant
spacing between the adjoining graph nodes. The smoothness of each surface
modeled as a convex constraint governs the connectivity and regularity of the
surface. We employ an edge-based graph representation to incorporate the
necessary constraints and the globally optimal solution is obtained by
computing a minimum s-t cut. The proposed method was validated on 10
intravascular multi-frame ultrasound image datasets for subvoxel segmentation
accuracy. In all cases, the approach yielded highly accurate results. Our
approach can be readily extended to higher-dimensional segmentations.
-
In this paper, we aim to monitor the flow of people in large public
infrastructures. We propose an unsupervised methodology to cluster people flow
patterns into the most typical and meaningful configurations. By processing 3D
images from a network of depth cameras, we build a descriptor for the flow
pattern. We define a data-irregularity measure that assesses how well each
descriptor fits a data model. This allows us to rank flow patterns from highly
distinctive (outliers) to very common ones. By discarding outliers, we obtain
more reliable key configurations (classes). Synthetic experiments show that the
proposed method is superior to standard clustering methods. We applied it in an
operational scenario during 14 days in the X-ray screening area of an
international airport. Results show that our methodology is able to
successfully summarize the representative patterns for such a long observation
period, providing relevant information for airport management. Beyond regular
flows, our method identifies a set of rare events corresponding to uncommon
activities (cleaning, special security and circulating staff).





 The presence of certain clinical dermoscopic features within a skin lesion may indicate melanoma, and automatically detecting these features may lead to more quantitative and reproducible diagnoses. We reformulate the task of classifying clinical dermoscopic features within superpixels as a segmentation problem, and propose a fully convolutional neural network to detect clinical dermoscopic features from dermoscopy skin lesion images. Our neural network architecture uses interpolated feature maps from several intermediate network layers, and addresses imbalanced labels by minimizing a negative multi-label Dice-F$_1$ score, where the score is computed across the mini-batch for each label. Our approach ranked first place in the 2017 ISIC-ISBI Part 2: Dermoscopic Feature Classification Task challenge over both the provided validation and test datasets, achieving a 0.895% area under the receiver operator characteristic curve score. We show how simple baseline models can outrank state-of-the-art approaches when using the official metrics of the challenge, and propose to use a fuzzy Jaccard Index that ignores the empty set (i.e., masks devoid of positive pixels) when ranking models. Our results suggest that (i) the classification of clinical dermoscopic features can be effectively approached as a segmentation problem, and (ii) the current metrics used to rank models may not well capture the efficacy of the model. We plan to make our trained model and code publicly available.
The presence of certain clinical dermoscopic features within a skin lesion may indicate melanoma, and automatically detecting these features may lead to more quantitative and reproducible diagnoses. We reformulate the task of classifying clinical dermoscopic features within superpixels as a segmentation problem, and propose a fully convolutional neural network to detect clinical dermoscopic features from dermoscopy skin lesion images. Our neural network architecture uses interpolated feature maps from several intermediate network layers, and addresses imbalanced labels by minimizing a negative multi-label Dice-F$_1$ score, where the score is computed across the mini-batch for each label. Our approach ranked first place in the 2017 ISIC-ISBI Part 2: Dermoscopic Feature Classification Task challenge over both the provided validation and test datasets, achieving a 0.895% area under the receiver operator characteristic curve score. We show how simple baseline models can outrank state-of-the-art approaches when using the official metrics of the challenge, and propose to use a fuzzy Jaccard Index that ignores the empty set (i.e., masks devoid of positive pixels) when ranking models. Our results suggest that (i) the classification of clinical dermoscopic features can be effectively approached as a segmentation problem, and (ii) the current metrics used to rank models may not well capture the efficacy of the model. We plan to make our trained model and code publicly available.




 Context categorization is a fundamental pre-requisite for multi-domain multimedia content analysis applications in order to manage contextual information in an efficient manner. In this paper, we introduce a new color image context categorization method (DITEC) based on the trace transform. The problem of dimensionality reduction of the obtained trace transform signal is addressed through statistical descriptors that keep the underlying information. These extracted features offer a highly discriminant behavior for content categorization. The theoretical properties of the method are analyzed and validated experimentally through two different datasets.
Context categorization is a fundamental pre-requisite for multi-domain multimedia content analysis applications in order to manage contextual information in an efficient manner. In this paper, we introduce a new color image context categorization method (DITEC) based on the trace transform. The problem of dimensionality reduction of the obtained trace transform signal is addressed through statistical descriptors that keep the underlying information. These extracted features offer a highly discriminant behavior for content categorization. The theoretical properties of the method are analyzed and validated experimentally through two different datasets.


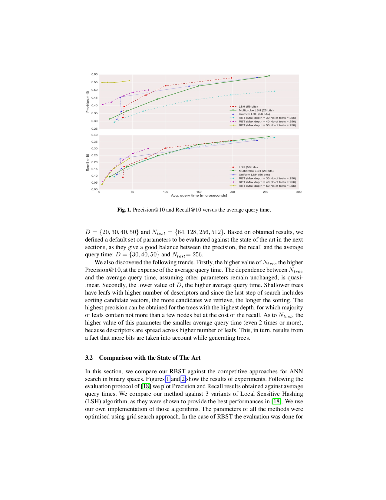
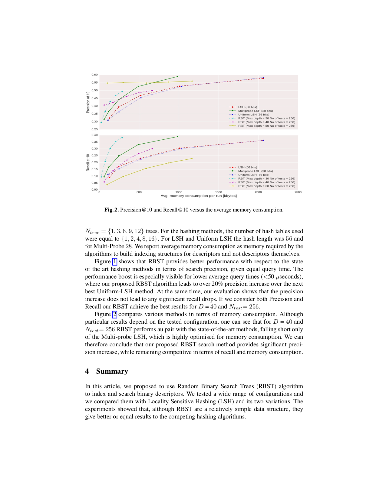
 Approximate nearest neighbour (ANN) search is one of the most important problems in computer science fields such as data mining or computer vision. In this paper, we focus on ANN for high-dimensional binary vectors and we propose a simple yet powerful search method that uses Random Binary Search Trees (RBST). We apply our method to a dataset of 1.25M binary local feature descriptors obtained from a real-life image-based localisation system provided by Google as a part of Project Tango. An extensive evaluation of our method against the state-of-the-art variations of Locality Sensitive Hashing (LSH), namely Uniform LSH and Multi-probe LSH, shows the superiority of our method in terms of retrieval precision with performance boost of over 20%
Approximate nearest neighbour (ANN) search is one of the most important problems in computer science fields such as data mining or computer vision. In this paper, we focus on ANN for high-dimensional binary vectors and we propose a simple yet powerful search method that uses Random Binary Search Trees (RBST). We apply our method to a dataset of 1.25M binary local feature descriptors obtained from a real-life image-based localisation system provided by Google as a part of Project Tango. An extensive evaluation of our method against the state-of-the-art variations of Locality Sensitive Hashing (LSH), namely Uniform LSH and Multi-probe LSH, shows the superiority of our method in terms of retrieval precision with performance boost of over 20%




 We propose a novel approach to address the problem of Simultaneous Detection and Segmentation introduced in [Hariharan et al 2014]. Using the hierarchical structures first presented in [Arbel\'aez et al 2011] we use an efficient and accurate procedure that exploits the feature information of the hierarchy using Locality Sensitive Hashing. We build on recent work that utilizes convolutional neural networks to detect bounding boxes in an image [Ren et al 2015] and then use the top similar hierarchical region that best fits each bounding box after hashing, we call this approach C&Z Segmentation. We then refine our final segmentation results by automatic hierarchical pruning. C&Z Segmentation introduces a train-free alternative to Hypercolumns [Hariharan et al 2015]. We conduct extensive experiments on PASCAL VOC 2012 segmentation dataset, showing that C&Z gives competitive state-of-the-art segmentations of objects.
We propose a novel approach to address the problem of Simultaneous Detection and Segmentation introduced in [Hariharan et al 2014]. Using the hierarchical structures first presented in [Arbel\'aez et al 2011] we use an efficient and accurate procedure that exploits the feature information of the hierarchy using Locality Sensitive Hashing. We build on recent work that utilizes convolutional neural networks to detect bounding boxes in an image [Ren et al 2015] and then use the top similar hierarchical region that best fits each bounding box after hashing, we call this approach C&Z Segmentation. We then refine our final segmentation results by automatic hierarchical pruning. C&Z Segmentation introduces a train-free alternative to Hypercolumns [Hariharan et al 2015]. We conduct extensive experiments on PASCAL VOC 2012 segmentation dataset, showing that C&Z gives competitive state-of-the-art segmentations of objects.




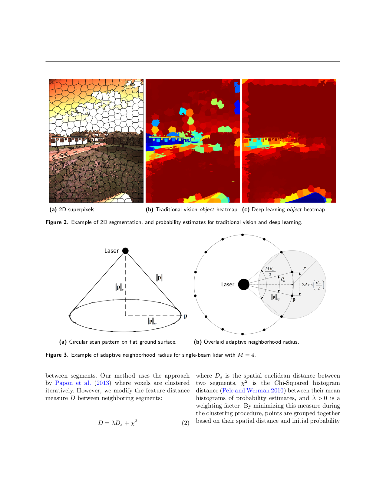 Reliable obstacle detection and classification in rough and unstructured terrain such as agricultural fields or orchards remains a challenging problem. These environments involve large variations in both geometry and appearance, challenging perception systems that rely on only a single sensor modality. Geometrically, tall grass, fallen leaves, or terrain roughness can mistakenly be perceived as nontraversable or might even obscure actual obstacles. Likewise, traversable grass or dirt roads and obstacles such as trees and bushes might be visually ambiguous. In this paper, we combine appearance- and geometry-based detection methods by probabilistically fusing lidar and camera sensing with semantic segmentation using a conditional random field. We apply a state-of-the-art multimodal fusion algorithm from the scene analysis domain and adjust it for obstacle detection in agriculture with moving ground vehicles. This involves explicitly handling sparse point cloud data and exploiting both spatial, temporal, and multimodal links between corresponding 2D and 3D regions. The proposed method was evaluated on a diverse data set, comprising a dairy paddock and different orchards gathered with a perception research robot in Australia. Results showed that for a two-class classification problem (ground and nonground), only the camera leveraged from information provided by the other modality with an increase in the mean classification score of 0.5%. However, as more classes were introduced (ground, sky, vegetation, and object), both modalities complemented each other with improvements of 1.4% in 2D and 7.9% in 3D. Finally, introducing temporal links between successive frames resulted in improvements of 0.2% in 2D and 1.5% in 3D.
Reliable obstacle detection and classification in rough and unstructured terrain such as agricultural fields or orchards remains a challenging problem. These environments involve large variations in both geometry and appearance, challenging perception systems that rely on only a single sensor modality. Geometrically, tall grass, fallen leaves, or terrain roughness can mistakenly be perceived as nontraversable or might even obscure actual obstacles. Likewise, traversable grass or dirt roads and obstacles such as trees and bushes might be visually ambiguous. In this paper, we combine appearance- and geometry-based detection methods by probabilistically fusing lidar and camera sensing with semantic segmentation using a conditional random field. We apply a state-of-the-art multimodal fusion algorithm from the scene analysis domain and adjust it for obstacle detection in agriculture with moving ground vehicles. This involves explicitly handling sparse point cloud data and exploiting both spatial, temporal, and multimodal links between corresponding 2D and 3D regions. The proposed method was evaluated on a diverse data set, comprising a dairy paddock and different orchards gathered with a perception research robot in Australia. Results showed that for a two-class classification problem (ground and nonground), only the camera leveraged from information provided by the other modality with an increase in the mean classification score of 0.5%. However, as more classes were introduced (ground, sky, vegetation, and object), both modalities complemented each other with improvements of 1.4% in 2D and 7.9% in 3D. Finally, introducing temporal links between successive frames resulted in improvements of 0.2% in 2D and 1.5% in 3D.




 Convolutional networks reach top quality in pixel-level video object segmentation but require a large amount of training data (1k~100k) to deliver such results. We propose a new training strategy which achieves state-of-the-art results across three evaluation datasets while using 20x~1000x less annotated data than competing methods. Our approach is suitable for both single and multiple object segmentation. Instead of using large training sets hoping to generalize across domains, we generate in-domain training data using the provided annotation on the first frame of each video to synthesize ("lucid dream") plausible future video frames. In-domain per-video training data allows us to train high quality appearance- and motion-based models, as well as tune the post-processing stage. This approach allows to reach competitive results even when training from only a single annotated frame, without ImageNet pre-training. Our results indicate that using a larger training set is not automatically better, and that for the video object segmentation task a smaller training set that is closer to the target domain is more effective. This changes the mindset regarding how many training samples and general "objectness" knowledge are required for the video object segmentation task.
Convolutional networks reach top quality in pixel-level video object segmentation but require a large amount of training data (1k~100k) to deliver such results. We propose a new training strategy which achieves state-of-the-art results across three evaluation datasets while using 20x~1000x less annotated data than competing methods. Our approach is suitable for both single and multiple object segmentation. Instead of using large training sets hoping to generalize across domains, we generate in-domain training data using the provided annotation on the first frame of each video to synthesize ("lucid dream") plausible future video frames. In-domain per-video training data allows us to train high quality appearance- and motion-based models, as well as tune the post-processing stage. This approach allows to reach competitive results even when training from only a single annotated frame, without ImageNet pre-training. Our results indicate that using a larger training set is not automatically better, and that for the video object segmentation task a smaller training set that is closer to the target domain is more effective. This changes the mindset regarding how many training samples and general "objectness" knowledge are required for the video object segmentation task.




 Inferring the relations between two images is an important class of tasks in computer vision. Examples of such tasks include computing optical flow and stereo disparity. We treat the relation inference tasks as a machine learning problem and tackle it with neural networks. A key to the problem is learning a representation of relations. We propose a new neural network module, contrast association unit (CAU), which explicitly models the relations between two sets of input variables. Due to the non-negativity of the weights in CAU, we adopt a multiplicative update algorithm for learning these weights. Experiments show that neural networks with CAUs are more effective in learning five fundamental image transformations than conventional neural networks.
Inferring the relations between two images is an important class of tasks in computer vision. Examples of such tasks include computing optical flow and stereo disparity. We treat the relation inference tasks as a machine learning problem and tackle it with neural networks. A key to the problem is learning a representation of relations. We propose a new neural network module, contrast association unit (CAU), which explicitly models the relations between two sets of input variables. Due to the non-negativity of the weights in CAU, we adopt a multiplicative update algorithm for learning these weights. Experiments show that neural networks with CAUs are more effective in learning five fundamental image transformations than conventional neural networks.



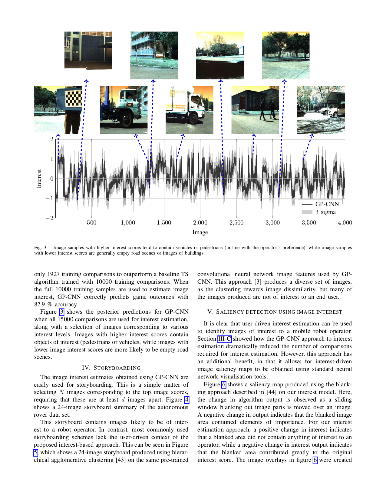
 A great deal of work aims to discover large general purpose models of image interest or memorability for visual search and information retrieval. This paper argues that image interest is often domain and user specific, and that efficient mechanisms for learning about this domain-specific image interest as quickly as possible, while limiting the amount of data-labelling required, are often more useful to end-users. This work uses pairwise image comparisons to reduce the labelling burden on these users, and introduces an image interest estimation approach that performs similarly to recent data hungry deep learning approaches trained using pairwise ranking losses. Here, we use a Gaussian process model to interpolate image interest inferred using a Bayesian ranking approach over image features extracted using a pre-trained convolutional neural network. Results show that fitting a Gaussian process in high-dimensional image feature space is not only computationally feasible, but also effective across a broad range of domains. The proposed probabilistic interest estimation approach produces image interests paired with uncertainties that can be used to identify images for which additional labelling is required and measure inference convergence, allowing for sample efficient active model training. Importantly, the probabilistic formulation allows for effective visual search and information retrieval when limited labelling data is available.
A great deal of work aims to discover large general purpose models of image interest or memorability for visual search and information retrieval. This paper argues that image interest is often domain and user specific, and that efficient mechanisms for learning about this domain-specific image interest as quickly as possible, while limiting the amount of data-labelling required, are often more useful to end-users. This work uses pairwise image comparisons to reduce the labelling burden on these users, and introduces an image interest estimation approach that performs similarly to recent data hungry deep learning approaches trained using pairwise ranking losses. Here, we use a Gaussian process model to interpolate image interest inferred using a Bayesian ranking approach over image features extracted using a pre-trained convolutional neural network. Results show that fitting a Gaussian process in high-dimensional image feature space is not only computationally feasible, but also effective across a broad range of domains. The proposed probabilistic interest estimation approach produces image interests paired with uncertainties that can be used to identify images for which additional labelling is required and measure inference convergence, allowing for sample efficient active model training. Importantly, the probabilistic formulation allows for effective visual search and information retrieval when limited labelling data is available.




 This paper proposes an effective approach for the scaling registration of $m$-D point sets. Different from the rigid transformation, the scaling registration can not be formulated into the common least square function due to the ill-posed problem caused by the scale factor. Therefore, this paper designs a novel objective function for the scaling registration problem. The appearance of this objective function is a rational fraction, where the numerator item is the least square error and the denominator item is the square of the scale factor. By imposing the emphasis on scale factor, the ill-posed problem can be avoided in the scaling registration. Subsequently, the new objective function can be solved by the proposed scaling iterative closest point (ICP) algorithm, which can obtain the optimal scaling transformation. For the practical applications, the scaling ICP algorithm is further extended to align partially overlapping point sets. Finally, the proposed approach is tested on public data sets and applied to merging grid maps of different resolutions. Experimental results demonstrate its superiority over previous approaches on efficiency and robustness.
This paper proposes an effective approach for the scaling registration of $m$-D point sets. Different from the rigid transformation, the scaling registration can not be formulated into the common least square function due to the ill-posed problem caused by the scale factor. Therefore, this paper designs a novel objective function for the scaling registration problem. The appearance of this objective function is a rational fraction, where the numerator item is the least square error and the denominator item is the square of the scale factor. By imposing the emphasis on scale factor, the ill-posed problem can be avoided in the scaling registration. Subsequently, the new objective function can be solved by the proposed scaling iterative closest point (ICP) algorithm, which can obtain the optimal scaling transformation. For the practical applications, the scaling ICP algorithm is further extended to align partially overlapping point sets. Finally, the proposed approach is tested on public data sets and applied to merging grid maps of different resolutions. Experimental results demonstrate its superiority over previous approaches on efficiency and robustness.




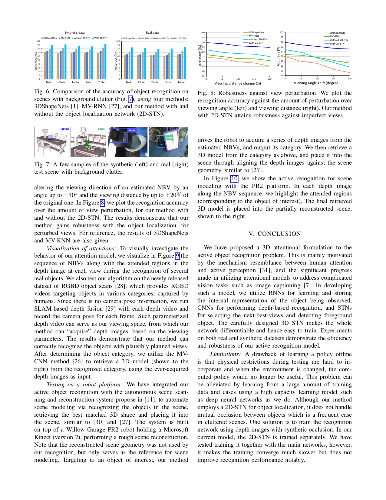 Active vision is inherently attention-driven: The agent actively selects views to attend in order to fast achieve the vision task while improving its internal representation of the scene being observed. Inspired by the recent success of attention-based models in 2D vision tasks based on single RGB images, we propose to address the multi-view depth-based active object recognition using attention mechanism, through developing an end-to-end recurrent 3D attentional network. The architecture takes advantage of a recurrent neural network (RNN) to store and update an internal representation. Our model, trained with 3D shape datasets, is able to iteratively attend to the best views targeting an object of interest for recognizing it. To realize 3D view selection, we derive a 3D spatial transformer network which is differentiable for training with backpropagation, achieving much faster convergence than the reinforcement learning employed by most existing attention-based models. Experiments show that our method, with only depth input, achieves state-of-the-art next-best-view performance in time efficiency and recognition accuracy.
Active vision is inherently attention-driven: The agent actively selects views to attend in order to fast achieve the vision task while improving its internal representation of the scene being observed. Inspired by the recent success of attention-based models in 2D vision tasks based on single RGB images, we propose to address the multi-view depth-based active object recognition using attention mechanism, through developing an end-to-end recurrent 3D attentional network. The architecture takes advantage of a recurrent neural network (RNN) to store and update an internal representation. Our model, trained with 3D shape datasets, is able to iteratively attend to the best views targeting an object of interest for recognizing it. To realize 3D view selection, we derive a 3D spatial transformer network which is differentiable for training with backpropagation, achieving much faster convergence than the reinforcement learning employed by most existing attention-based models. Experiments show that our method, with only depth input, achieves state-of-the-art next-best-view performance in time efficiency and recognition accuracy.




 The availability of labeled image datasets has been shown critical for high-level image understanding, which continuously drives the progress of feature designing and models developing. However, constructing labeled image datasets is laborious and monotonous. To eliminate manual annotation, in this work, we propose a novel image dataset construction framework by employing multiple textual queries. We aim at collecting diverse and accurate images for given queries from the Web. Specifically, we formulate noisy textual queries removing and noisy images filtering as a multi-view and multi-instance learning problem separately. Our proposed approach not only improves the accuracy but also enhances the diversity of the selected images. To verify the effectiveness of our proposed approach, we construct an image dataset with 100 categories. The experiments show significant performance gains by using the generated data of our approach on several tasks, such as image classification, cross-dataset generalization, and object detection. The proposed method also consistently outperforms existing weakly supervised and web-supervised approaches.
The availability of labeled image datasets has been shown critical for high-level image understanding, which continuously drives the progress of feature designing and models developing. However, constructing labeled image datasets is laborious and monotonous. To eliminate manual annotation, in this work, we propose a novel image dataset construction framework by employing multiple textual queries. We aim at collecting diverse and accurate images for given queries from the Web. Specifically, we formulate noisy textual queries removing and noisy images filtering as a multi-view and multi-instance learning problem separately. Our proposed approach not only improves the accuracy but also enhances the diversity of the selected images. To verify the effectiveness of our proposed approach, we construct an image dataset with 100 categories. The experiments show significant performance gains by using the generated data of our approach on several tasks, such as image classification, cross-dataset generalization, and object detection. The proposed method also consistently outperforms existing weakly supervised and web-supervised approaches.




 The image biomarker standardisation initiative (IBSI) is an independent international collaboration which works towards standardising the extraction of image biomarkers from acquired imaging for the purpose of high-throughput quantitative image analysis (radiomics). Lack of reproducibility and validation of high-throughput quantitative image analysis studies is considered to be a major challenge for the field. Part of this challenge lies in the scantiness of consensus-based guidelines and definitions for the process of translating acquired imaging into high-throughput image biomarkers. The IBSI therefore seeks to provide image biomarker nomenclature and definitions, benchmark data sets, and benchmark values to verify image processing and image biomarker calculations, as well as reporting guidelines, for high-throughput image analysis.
The image biomarker standardisation initiative (IBSI) is an independent international collaboration which works towards standardising the extraction of image biomarkers from acquired imaging for the purpose of high-throughput quantitative image analysis (radiomics). Lack of reproducibility and validation of high-throughput quantitative image analysis studies is considered to be a major challenge for the field. Part of this challenge lies in the scantiness of consensus-based guidelines and definitions for the process of translating acquired imaging into high-throughput image biomarkers. The IBSI therefore seeks to provide image biomarker nomenclature and definitions, benchmark data sets, and benchmark values to verify image processing and image biomarker calculations, as well as reporting guidelines, for high-throughput image analysis.


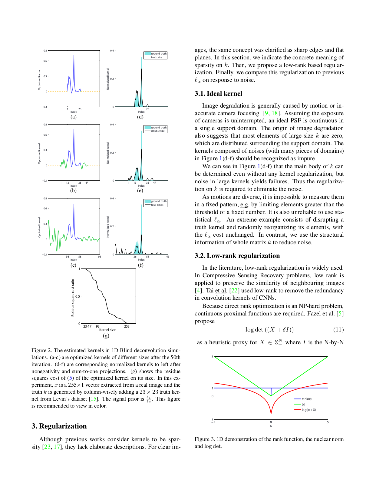
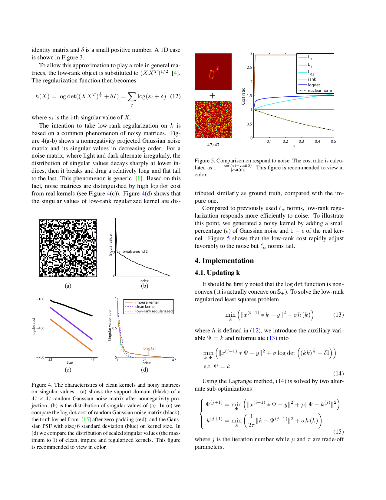
 Most blind deconvolution methods usually pre-define a large kernel size to guarantee the support domain. Blur kernel estimation error is likely to be introduced, yielding severe artifacts in deblurring results. In this paper, we first theoretically and experimentally analyze the mechanism to estimation error in oversized kernel, and show that it holds even on blurry images without noises. Then to suppress this adverse effect, we propose a low rank-based regularization on blur kernel to exploit the structural information in degraded kernels, by which larger-kernel effect can be effectively suppressed. And we propose an efficient optimization algorithm to solve it. Experimental results on benchmark datasets show that the proposed method is comparable with the state-of-the-arts by accordingly setting proper kernel size, and performs much better in handling larger-size kernels quantitatively and qualitatively. The deblurring results on real-world blurry images further validate the effectiveness of the proposed method.
Most blind deconvolution methods usually pre-define a large kernel size to guarantee the support domain. Blur kernel estimation error is likely to be introduced, yielding severe artifacts in deblurring results. In this paper, we first theoretically and experimentally analyze the mechanism to estimation error in oversized kernel, and show that it holds even on blurry images without noises. Then to suppress this adverse effect, we propose a low rank-based regularization on blur kernel to exploit the structural information in degraded kernels, by which larger-kernel effect can be effectively suppressed. And we propose an efficient optimization algorithm to solve it. Experimental results on benchmark datasets show that the proposed method is comparable with the state-of-the-arts by accordingly setting proper kernel size, and performs much better in handling larger-size kernels quantitatively and qualitatively. The deblurring results on real-world blurry images further validate the effectiveness of the proposed method.




 Many machine vision applications, such as semantic segmentation and depth prediction, require predictions for every pixel of the input image. Models for such problems usually consist of encoders which decrease spatial resolution while learning a high-dimensional representation, followed by decoders who recover the original input resolution and result in low-dimensional predictions. While encoders have been studied rigorously, relatively few studies address the decoder side. This paper presents an extensive comparison of a variety of decoders for a variety of pixel-wise tasks ranging from classification, regression to synthesis. Our contributions are: (1) Decoders matter: we observe significant variance in results between different types of decoders on various problems. (2) We introduce new residual-like connections for decoders. (3) We introduce a novel decoder: bilinear additive upsampling. (4) We explore prediction artifacts.
Many machine vision applications, such as semantic segmentation and depth prediction, require predictions for every pixel of the input image. Models for such problems usually consist of encoders which decrease spatial resolution while learning a high-dimensional representation, followed by decoders who recover the original input resolution and result in low-dimensional predictions. While encoders have been studied rigorously, relatively few studies address the decoder side. This paper presents an extensive comparison of a variety of decoders for a variety of pixel-wise tasks ranging from classification, regression to synthesis. Our contributions are: (1) Decoders matter: we observe significant variance in results between different types of decoders on various problems. (2) We introduce new residual-like connections for decoders. (3) We introduce a novel decoder: bilinear additive upsampling. (4) We explore prediction artifacts.




 This paper proposes a novel framework to reconstruct the dynamic magnetic resonance images (DMRI) with motion compensation (MC). Due to the inherent motion effects during DMRI acquisition, reconstruction of DMRI using motion estimation/compensation (ME/MC) has been studied under a compressed sensing (CS) scheme. In this paper, by embedding the intensity-based optical flow (OF) constraint into the traditional CS scheme, we are able to couple the DMRI reconstruction with motion field estimation. The formulated optimization problem is solved by a primal-dual algorithm with linesearch due to its efficiency when dealing with non-differentiable problems. With the estimated motion field, the DMRI reconstruction is refined through MC. By employing the multi-scale coarse-to-fine strategy, we are able to update the variables(temporal image sequences and motion vectors) and to refine the image reconstruction alternately. Moreover, the proposed framework is capable of handling a wide class of prior information (regularizations) for DMRI reconstruction, such as sparsity, low rank and total variation. Experiments on various DMRI data, ranging from in vivo lung to cardiac dataset, validate the reconstruction quality improvement using the proposed scheme in comparison to several state-of-the-art algorithms.
This paper proposes a novel framework to reconstruct the dynamic magnetic resonance images (DMRI) with motion compensation (MC). Due to the inherent motion effects during DMRI acquisition, reconstruction of DMRI using motion estimation/compensation (ME/MC) has been studied under a compressed sensing (CS) scheme. In this paper, by embedding the intensity-based optical flow (OF) constraint into the traditional CS scheme, we are able to couple the DMRI reconstruction with motion field estimation. The formulated optimization problem is solved by a primal-dual algorithm with linesearch due to its efficiency when dealing with non-differentiable problems. With the estimated motion field, the DMRI reconstruction is refined through MC. By employing the multi-scale coarse-to-fine strategy, we are able to update the variables(temporal image sequences and motion vectors) and to refine the image reconstruction alternately. Moreover, the proposed framework is capable of handling a wide class of prior information (regularizations) for DMRI reconstruction, such as sparsity, low rank and total variation. Experiments on various DMRI data, ranging from in vivo lung to cardiac dataset, validate the reconstruction quality improvement using the proposed scheme in comparison to several state-of-the-art algorithms.




 Optimal surface segmentation is a state-of-the-art method used for segmentation of multiple globally optimal surfaces in volumetric datasets. The method is widely used in numerous medical image segmentation applications. However, nodes in the graph based optimal surface segmentation method typically encode uniformly distributed orthogonal voxels of the volume. Thus the segmentation cannot attain an accuracy greater than a single unit voxel, i.e. the distance between two adjoining nodes in graph space. Segmentation accuracy higher than a unit voxel is achievable by exploiting partial volume information in the voxels which shall result in non-equidistant spacing between adjoining graph nodes. This paper reports a generalized graph based multiple surface segmentation method with convex priors which can optimally segment the target surfaces in an irregularly sampled space. The proposed method allows non-equidistant spacing between the adjoining graph nodes to achieve subvoxel segmentation accuracy by utilizing the partial volume information in the voxels. The partial volume information in the voxels is exploited by computing a displacement field from the original volume data to identify the subvoxel-accurate centers within each voxel resulting in non-equidistant spacing between the adjoining graph nodes. The smoothness of each surface modeled as a convex constraint governs the connectivity and regularity of the surface. We employ an edge-based graph representation to incorporate the necessary constraints and the globally optimal solution is obtained by computing a minimum s-t cut. The proposed method was validated on 10 intravascular multi-frame ultrasound image datasets for subvoxel segmentation accuracy. In all cases, the approach yielded highly accurate results. Our approach can be readily extended to higher-dimensional segmentations.
Optimal surface segmentation is a state-of-the-art method used for segmentation of multiple globally optimal surfaces in volumetric datasets. The method is widely used in numerous medical image segmentation applications. However, nodes in the graph based optimal surface segmentation method typically encode uniformly distributed orthogonal voxels of the volume. Thus the segmentation cannot attain an accuracy greater than a single unit voxel, i.e. the distance between two adjoining nodes in graph space. Segmentation accuracy higher than a unit voxel is achievable by exploiting partial volume information in the voxels which shall result in non-equidistant spacing between adjoining graph nodes. This paper reports a generalized graph based multiple surface segmentation method with convex priors which can optimally segment the target surfaces in an irregularly sampled space. The proposed method allows non-equidistant spacing between the adjoining graph nodes to achieve subvoxel segmentation accuracy by utilizing the partial volume information in the voxels. The partial volume information in the voxels is exploited by computing a displacement field from the original volume data to identify the subvoxel-accurate centers within each voxel resulting in non-equidistant spacing between the adjoining graph nodes. The smoothness of each surface modeled as a convex constraint governs the connectivity and regularity of the surface. We employ an edge-based graph representation to incorporate the necessary constraints and the globally optimal solution is obtained by computing a minimum s-t cut. The proposed method was validated on 10 intravascular multi-frame ultrasound image datasets for subvoxel segmentation accuracy. In all cases, the approach yielded highly accurate results. Our approach can be readily extended to higher-dimensional segmentations.

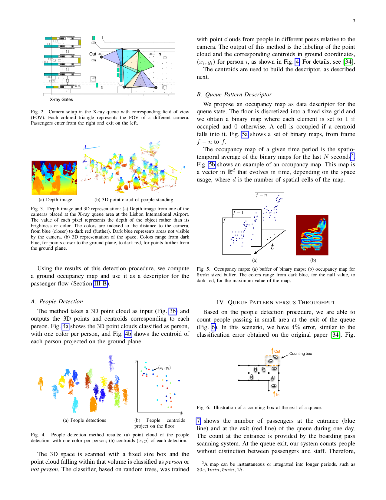
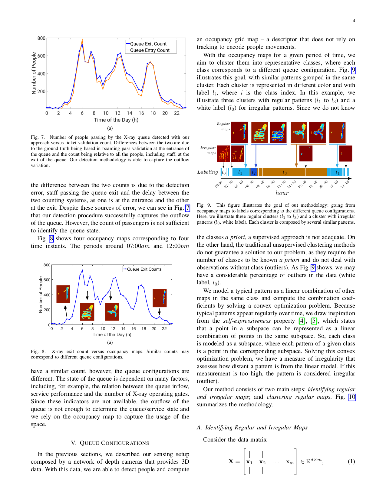

 In this paper, we aim to monitor the flow of people in large public infrastructures. We propose an unsupervised methodology to cluster people flow patterns into the most typical and meaningful configurations. By processing 3D images from a network of depth cameras, we build a descriptor for the flow pattern. We define a data-irregularity measure that assesses how well each descriptor fits a data model. This allows us to rank flow patterns from highly distinctive (outliers) to very common ones. By discarding outliers, we obtain more reliable key configurations (classes). Synthetic experiments show that the proposed method is superior to standard clustering methods. We applied it in an operational scenario during 14 days in the X-ray screening area of an international airport. Results show that our methodology is able to successfully summarize the representative patterns for such a long observation period, providing relevant information for airport management. Beyond regular flows, our method identifies a set of rare events corresponding to uncommon activities (cleaning, special security and circulating staff).
In this paper, we aim to monitor the flow of people in large public infrastructures. We propose an unsupervised methodology to cluster people flow patterns into the most typical and meaningful configurations. By processing 3D images from a network of depth cameras, we build a descriptor for the flow pattern. We define a data-irregularity measure that assesses how well each descriptor fits a data model. This allows us to rank flow patterns from highly distinctive (outliers) to very common ones. By discarding outliers, we obtain more reliable key configurations (classes). Synthetic experiments show that the proposed method is superior to standard clustering methods. We applied it in an operational scenario during 14 days in the X-ray screening area of an international airport. Results show that our methodology is able to successfully summarize the representative patterns for such a long observation period, providing relevant information for airport management. Beyond regular flows, our method identifies a set of rare events corresponding to uncommon activities (cleaning, special security and circulating staff).