-
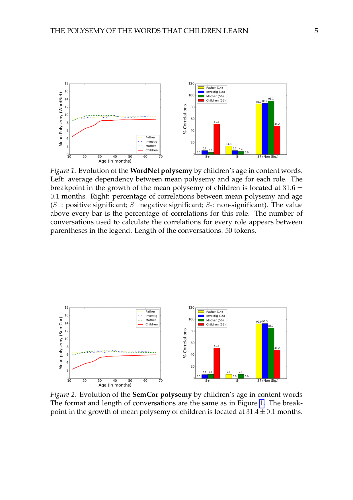
Here we study polysemy as a potential learning bias in vocabulary learning in
children. Words of low polysemy could be preferred as they reduce the
disambiguation effort for the listener. However, such preference could be a
side-effect of another bias: the preference of children for nouns in
combination with the lower polysemy of nouns with respect to other
part-of-speech categories. Our results show that mean polysemy in children
increases over time in two phases, i.e. a fast growth till the 31st month
followed by a slower tendency towards adult speech. In contrast, this evolution
is not found in adults interacting with children. This suggests that children
have a preference for non-polysemous words in their early stages of vocabulary
acquisition. Interestingly, the evolutionary pattern described above weakens
when controlling for syntactic category (noun, verb, adjective or adverb) but
it does not disappear completely, suggesting that it could result from
acombination of a standalone bias for low polysemy and a preference for nouns.
-
Combining deep neural networks with structured logic rules is desirable to
harness flexibility and reduce uninterpretability of the neural models. We
propose a general framework capable of enhancing various types of neural
networks (e.g., CNNs and RNNs) with declarative first-order logic rules.
Specifically, we develop an iterative distillation method that transfers the
structured information of logic rules into the weights of neural networks. We
deploy the framework on a CNN for sentiment analysis, and an RNN for named
entity recognition. With a few highly intuitive rules, we obtain substantial
improvements and achieve state-of-the-art or comparable results to previous
best-performing systems.
-
In recent years, (retro-)digitizing paper-based files became a major
undertaking for private and public archives as well as an important task in
electronic mailroom applications. As a first step, the workflow involves
scanning and Optical Character Recognition (OCR) of documents. Preservation of
document contexts of single page scans is a major requirement in this context.
To facilitate workflows involving very large amounts of paper scans, page
stream segmentation (PSS) is the task to automatically separate a stream of
scanned images into multi-page documents. In a digitization project together
with a German federal archive, we developed a novel approach based on
convolutional neural networks (CNN) combining image and text features to
achieve optimal document separation results. Evaluation shows that our PSS
architecture achieves an accuracy up to 93 % which can be regarded as a new
state-of-the-art for this task.
-
Here we consider some well-known facts in syntax from a physics perspective,
allowing us to establish equivalences between both fields with many
consequences. Mainly, we observe that the operation MERGE, put forward by N.
Chomsky in 1995, can be interpreted as a physical information coarse-graining.
Thus, MERGE in linguistics entails information renormalization in physics,
according to different time scales. We make this point mathematically formal in
terms of language models. In this setting, MERGE amounts to a probability
tensor implementing a coarse-graining, akin to a probabilistic context-free
grammar. The probability vectors of meaningful sentences are given by
stochastic tensor networks (TN) built from diagonal tensors and which are
mostly loop-free, such as Tree Tensor Networks and Matrix Product States, thus
being computationally very efficient to manipulate. We show that this implies
the polynomially-decaying (long-range) correlations experimentally observed in
language, and also provides arguments in favour of certain types of neural
networks for language processing. Moreover, we show how to obtain such language
models from quantum states that can be efficiently prepared on a quantum
computer, and use this to find bounds on the perplexity of the probability
distribution of words in a sentence. Implications of our results are discussed
across several ambits.
-
Matrix syntax is a formal model of syntactic relations in language. The
purpose of this paper is to explain its mathematical foundations, for an
audience with some formal background. We make an axiomatic presentation,
motivating each axiom on linguistic and practical grounds. The resulting
mathematical structure resembles some aspects of quantum mechanics. Matrix
syntax allows us to describe a number of language phenomena that are otherwise
very difficult to explain, such as linguistic chains, and is arguably a more
economical theory of language than most of the theories proposed in the context
of the minimalist program in linguistics. In particular, sentences are
naturally modelled as vectors in a Hilbert space with a tensor product
structure, built from 2x2 matrices belonging to some specific group.
-
We propose a simple yet effective technique for neural network learning. The
forward propagation is computed as usual. In back propagation, only a small
subset of the full gradient is computed to update the model parameters. The
gradient vectors are sparsified in such a way that only the top-$k$ elements
(in terms of magnitude) are kept. As a result, only $k$ rows or columns
(depending on the layout) of the weight matrix are modified, leading to a
linear reduction ($k$ divided by the vector dimension) in the computational
cost. Surprisingly, experimental results demonstrate that we can update only
1-4% of the weights at each back propagation pass. This does not result in a
larger number of training iterations. More interestingly, the accuracy of the
resulting models is actually improved rather than degraded, and a detailed
analysis is given. The code is available at https://github.com/lancopku/meProp
-
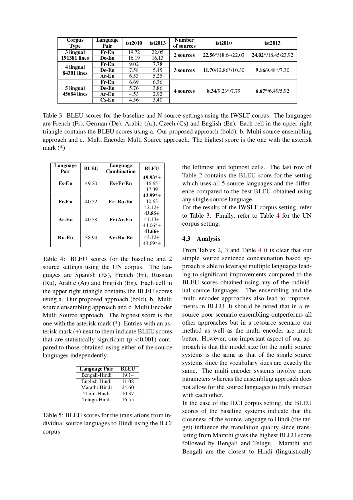
In this paper, we explore a simple solution to "Multi-Source Neural Machine
Translation" (MSNMT) which only relies on preprocessing a N-way multilingual
corpus without modifying the Neural Machine Translation (NMT) architecture or
training procedure. We simply concatenate the source sentences to form a single
long multi-source input sentence while keeping the target side sentence as it
is and train an NMT system using this preprocessed corpus. We evaluate our
method in resource poor as well as resource rich settings and show its
effectiveness (up to 4 BLEU using 2 source languages and up to 6 BLEU using 5
source languages). We also compare against existing methods for MSNMT and show
that our solution gives competitive results despite its simplicity. We also
provide some insights on how the NMT system leverages multilingual information
in such a scenario by visualizing attention.
-
This paper presents an augmentation of MSCOCO dataset where speech is added
to image and text. Speech captions are generated using text-to-speech (TTS)
synthesis resulting in 616,767 spoken captions (more than 600h) paired with
images. Disfluencies and speed perturbation are added to the signal in order to
sound more natural. Each speech signal (WAV) is paired with a JSON file
containing exact timecode for each word/syllable/phoneme in the spoken caption.
Such a corpus could be used for Language and Vision (LaVi) tasks including
speech input or output instead of text. Investigating multimodal learning
schemes for unsupervised speech pattern discovery is also possible with this
corpus, as demonstrated by a preliminary study conducted on a subset of the
corpus (10h, 10k spoken captions). The dataset is available on Zenodo:
https://zenodo.org/record/4282267
-
Blooms Taxonomy (BT) have been used to classify the objectives of learning
outcome by dividing the learning into three different domains; the cognitive
domain, the effective domain and the psychomotor domain. In this paper, we are
introducing a new approach to classify the questions and learning outcome
statements (LOS) into Blooms taxonomy (BT) and to verify BT verb lists, which
are being cited and used by academicians to write questions and (LOS). An
experiment was designed to investigate the semantic relationship between the
action verbs used in both questions and LOS to obtain more accurate
classification of the levels of BT. A sample of 775 different action verbs
collected from different universities allows us to measure an accurate and
clear-cut cognitive level for the action verb. It is worth mentioning that
natural language processing techniques were used to develop our rules as to
induce the questions into chunks in order to extract the action verbs. Our
proposed solution was able to classify the action verb into a precise level of
the cognitive domain. We, on our side, have tested and evaluated our proposed
solution using confusion matrix. The results of evaluation tests yielded 97%
for the macro average of precision and 90% for F1. Thus, the outcome of the
research suggests that it is crucial to analyse and verify the action verbs
cited and used by academicians to write LOS and classify their questions based
on blooms taxonomy in order to obtain a definite and more accurate
classification.
-
Modern neural networks are often augmented with an attention mechanism, which
tells the network where to focus within the input. We propose in this paper a
new framework for sparse and structured attention, building upon a smoothed max
operator. We show that the gradient of this operator defines a mapping from
real values to probabilities, suitable as an attention mechanism. Our framework
includes softmax and a slight generalization of the recently-proposed sparsemax
as special cases. However, we also show how our framework can incorporate
modern structured penalties, resulting in more interpretable attention
mechanisms, that focus on entire segments or groups of an input. We derive
efficient algorithms to compute the forward and backward passes of our
attention mechanisms, enabling their use in a neural network trained with
backpropagation. To showcase their potential as a drop-in replacement for
existing ones, we evaluate our attention mechanisms on three large-scale tasks:
textual entailment, machine translation, and sentence summarization. Our
attention mechanisms improve interpretability without sacrificing performance;
notably, on textual entailment and summarization, we outperform the standard
attention mechanisms based on softmax and sparsemax.
-
We address the problem of automatic American Sign Language fingerspelling
recognition from video. Prior work has largely relied on frame-level labels,
hand-crafted features, or other constraints, and has been hampered by the
scarcity of data for this task. We introduce a model for fingerspelling
recognition that addresses these issues. The model consists of an
auto-encoder-based feature extractor and an attention-based neural
encoder-decoder, which are trained jointly. The model receives a sequence of
image frames and outputs the fingerspelled word, without relying on any
frame-level training labels or hand-crafted features. In addition, the
auto-encoder subcomponent makes it possible to leverage unlabeled data to
improve the feature learning. The model achieves 11.6% and 4.4% absolute letter
accuracy improvement respectively in signer-independent and signer-adapted
fingerspelling recognition over previous approaches that required frame-level
training labels.
-
Multilinguality is gradually becoming ubiquitous in the sense that more and
more researchers have successfully shown that using additional languages help
improve the results in many Natural Language Processing tasks. Multilingual
Multiway Corpora (MMC) contain the same sentence in multiple languages. Such
corpora have been primarily used for Multi-Source and Pivot Language Machine
Translation but are also useful for developing multilingual sequence taggers by
transfer learning. While these corpora are available, they are not organized
for multilingual experiments and researchers need to write boilerplate code
every time they want to use said corpora. Moreover, because there is no
official MMC collection it becomes difficult to compare against existing
approaches. As such we present our work on creating a unified and
systematically organized repository of MMC spanning a large number of
languages. We also provide training, development and test splits for corpora
where official splits are unavailable. We hope that this will help speed up the
pace of multilingual NLP research and ensure that NLP researchers obtain
results that are more trustable since they can be compared easily. We indicate
corpora sources, extraction procedures if any and relevant statistics. We also
make our collection public for research purposes.
-
In Chinese societies, superstition is of paramount importance, and vehicle
license plates with desirable numbers can fetch very high prices in auctions.
Unlike other valuable items, license plates are not allocated an estimated
price before auction. I propose that the task of predicting plate prices can be
viewed as a natural language processing (NLP) task, as the value depends on the
meaning of each individual character on the plate and its semantics. I
construct a deep recurrent neural network (RNN) to predict the prices of
vehicle license plates in Hong Kong, based on the characters on a plate. I
demonstrate the importance of having a deep network and of retraining.
Evaluated on 13 years of historical auction prices, the deep RNN's predictions
can explain over 80 percent of price variations, outperforming previous models
by a significant margin. I also demonstrate how the model can be extended to
become a search engine for plates and to provide estimates of the expected
price distribution.
-
Often when multiple labels are obtained for a training example it is assumed
that there is an element of noise that must be accounted for. It has been shown
that this disagreement can be considered signal instead of noise. In this work
we investigate using soft labels for training data to improve generalization in
machine learning models. However, using soft labels for training Deep Neural
Networks (DNNs) is not practical due to the costs involved in obtaining
multiple labels for large data sets. We propose soft label
memorization-generalization (SLMG), a fine-tuning approach to using soft labels
for training DNNs. We assume that differences in labels provided by human
annotators represent ambiguity about the true label instead of noise.
Experiments with SLMG demonstrate improved generalization performance on the
Natural Language Inference (NLI) task. Our experiments show that by injecting a
small percentage of soft label training data (0.03% of training set size) we
can improve generalization performance over several baselines.
-
Machine Learning has been a big success story during the AI resurgence. One
particular stand out success relates to unsupervised learning from a massive
amount of data, albeit much of it relates to one modality/type of data at a
time. In spite of early assertions of the unreasonable effectiveness of data,
there is increasing recognition of utilizing knowledge whenever it is available
or can be created purposefully. In this paper, we focus on discussing the
indispensable role of knowledge for deeper understanding of complex text and
multimodal data in situations where (i) large amounts of training data
(labeled/unlabeled) are not available or labor intensive to create, (ii) the
objects (particularly text) to be recognized are complex (i.e., beyond simple
entity-person/location/organization names), such as implicit entities and
highly subjective content, and (iii) applications need to use complementary or
related data in multiple modalities/media. What brings us to the cusp of rapid
progress is our ability to (a) create knowledge, varying from comprehensive or
cross domain to domain or application specific, and (b) carefully exploit the
knowledge to further empower or extend the applications of ML/NLP techniques.
Using the early results in several diverse situations - both in data types and
applications - we seek to foretell unprecedented progress in our ability for
deeper understanding and exploitation of multimodal data.
-
This paper proposes a text summarization approach for factual reports using a
deep learning model. This approach consists of three phases: feature
extraction, feature enhancement, and summary generation, which work together to
assimilate core information and generate a coherent, understandable summary. We
are exploring various features to improve the set of sentences selected for the
summary, and are using a Restricted Boltzmann Machine to enhance and abstract
those features to improve resultant accuracy without losing any important
information. The sentences are scored based on those enhanced features and an
extractive summary is constructed. Experimentation carried out on several
articles demonstrates the effectiveness of the proposed approach. Source code
available at: https://github.com/vagisha-nidhi/TextSummarizer
-
We describe the course of a hackathon dedicated to the development of
linguistic tools for Tibetan Buddhist studies. Over a period of five days, a
group of seventeen scholars, scientists, and students developed and compared
algorithms for intertextual alignment and text classification, along with some
basic language tools, including a stemmer and word segmenter.
-
The recent tremendous success of unsupervised word embeddings in a multitude
of applications raises the obvious question if similar methods could be derived
to improve embeddings (i.e. semantic representations) of word sequences as
well. We present a simple but efficient unsupervised objective to train
distributed representations of sentences. Our method outperforms the
state-of-the-art unsupervised models on most benchmark tasks, highlighting the
robustness of the produced general-purpose sentence embeddings.
-
Several approaches have recently been proposed for learning decentralized
deep multiagent policies that coordinate via a differentiable communication
channel. While these policies are effective for many tasks, interpretation of
their induced communication strategies has remained a challenge. Here we
propose to interpret agents' messages by translating them. Unlike in typical
machine translation problems, we have no parallel data to learn from. Instead
we develop a translation model based on the insight that agent messages and
natural language strings mean the same thing if they induce the same belief
about the world in a listener. We present theoretical guarantees and empirical
evidence that our approach preserves both the semantics and pragmatics of
messages by ensuring that players communicating through a translation layer do
not suffer a substantial loss in reward relative to players with a common
language.
-
Explicit concept space models have proven efficacy for text representation in
many natural language and text mining applications. The idea is to embed
textual structures into a semantic space of concepts which captures the main
ideas, objects, and the characteristics of these structures. The so called Bag
of Concepts (BoC) representation suffers from data sparsity causing low
similarity scores between similar texts due to low concept overlap. To address
this problem, we propose two neural embedding models to learn continuous
concept vectors. Once they are learned, we propose an efficient vector
aggregation method to generate fully continuous BoC representations. We
evaluate our concept embedding models on three tasks: 1) measuring entity
semantic relatedness and ranking where we achieve 1.6% improvement in
correlation scores, 2) dataless concept categorization where we achieve
state-of-the-art performance and reduce the categorization error rate by more
than 5% compared to five prior word and entity embedding models, and 3)
dataless document classification where our models outperform the sparse BoC
representations. In addition, by exploiting our efficient linear time vector
aggregation method, we achieve better accuracy scores with much less concept
dimensions compared to previous BoC densification methods which operate in
polynomial time and require hundreds of dimensions in the BoC representation.
-
Bandit structured prediction describes a stochastic optimization framework
where learning is performed from partial feedback. This feedback is received in
the form of a task loss evaluation to a predicted output structure, without
having access to gold standard structures. We advance this framework by lifting
linear bandit learning to neural sequence-to-sequence learning problems using
attention-based recurrent neural networks. Furthermore, we show how to
incorporate control variates into our learning algorithms for variance
reduction and improved generalization. We present an evaluation on a neural
machine translation task that shows improvements of up to 5.89 BLEU points for
domain adaptation from simulated bandit feedback.
-
Language provides simple ways of communicating generalizable knowledge to
each other (e.g., "Birds fly", "John hikes", "Fire makes smoke"). Though found
in every language and emerging early in development, the language of
generalization is philosophically puzzling and has resisted precise
formalization. Here, we propose the first formal account of generalizations
conveyed with language that makes quantitative predictions about human
understanding. We test our model in three diverse domains: generalizations
about categories (generic language), events (habitual language), and causes
(causal language). The model explains the gradience in human endorsement
through the interplay between a simple truth-conditional semantic theory and
diverse beliefs about properties, formalized in a probabilistic model of
language understanding. This work opens the door to understanding precisely how
abstract knowledge is learned from language.
-
This paper describes Luminoso's participation in SemEval 2017 Task 2,
"Multilingual and Cross-lingual Semantic Word Similarity", with a system based
on ConceptNet. ConceptNet is an open, multilingual knowledge graph that focuses
on general knowledge that relates the meanings of words and phrases. Our
submission to SemEval was an update of previous work that builds high-quality,
multilingual word embeddings from a combination of ConceptNet and
distributional semantics. Our system took first place in both subtasks. It
ranked first in 4 out of 5 of the separate languages, and also ranked first in
all 10 of the cross-lingual language pairs.
-
Machine learning about language can be improved by supplying it with specific
knowledge and sources of external information. We present here a new version of
the linked open data resource ConceptNet that is particularly well suited to be
used with modern NLP techniques such as word embeddings.
ConceptNet is a knowledge graph that connects words and phrases of natural
language with labeled edges. Its knowledge is collected from many sources that
include expert-created resources, crowd-sourcing, and games with a purpose. It
is designed to represent the general knowledge involved in understanding
language, improving natural language applications by allowing the application
to better understand the meanings behind the words people use.
When ConceptNet is combined with word embeddings acquired from distributional
semantics (such as word2vec), it provides applications with understanding that
they would not acquire from distributional semantics alone, nor from narrower
resources such as WordNet or DBPedia. We demonstrate this with state-of-the-art
results on intrinsic evaluations of word relatedness that translate into
improvements on applications of word vectors, including solving SAT-style
analogies.
-
Word embeddings are ubiquitous in NLP and information retrieval, but it is
unclear what they represent when the word is polysemous. Here it is shown that
multiple word senses reside in linear superposition within the word embedding
and simple sparse coding can recover vectors that approximately capture the
senses. The success of our approach, which applies to several embedding
methods, is mathematically explained using a variant of the random walk on
discourses model (Arora et al., 2016). A novel aspect of our technique is that
each extracted word sense is accompanied by one of about 2000 "discourse atoms"
that gives a succinct description of which other words co-occur with that word
sense. Discourse atoms can be of independent interest, and make the method
potentially more useful. Empirical tests are used to verify and support the
theory.





 Here we study polysemy as a potential learning bias in vocabulary learning in children. Words of low polysemy could be preferred as they reduce the disambiguation effort for the listener. However, such preference could be a side-effect of another bias: the preference of children for nouns in combination with the lower polysemy of nouns with respect to other part-of-speech categories. Our results show that mean polysemy in children increases over time in two phases, i.e. a fast growth till the 31st month followed by a slower tendency towards adult speech. In contrast, this evolution is not found in adults interacting with children. This suggests that children have a preference for non-polysemous words in their early stages of vocabulary acquisition. Interestingly, the evolutionary pattern described above weakens when controlling for syntactic category (noun, verb, adjective or adverb) but it does not disappear completely, suggesting that it could result from acombination of a standalone bias for low polysemy and a preference for nouns.
Here we study polysemy as a potential learning bias in vocabulary learning in children. Words of low polysemy could be preferred as they reduce the disambiguation effort for the listener. However, such preference could be a side-effect of another bias: the preference of children for nouns in combination with the lower polysemy of nouns with respect to other part-of-speech categories. Our results show that mean polysemy in children increases over time in two phases, i.e. a fast growth till the 31st month followed by a slower tendency towards adult speech. In contrast, this evolution is not found in adults interacting with children. This suggests that children have a preference for non-polysemous words in their early stages of vocabulary acquisition. Interestingly, the evolutionary pattern described above weakens when controlling for syntactic category (noun, verb, adjective or adverb) but it does not disappear completely, suggesting that it could result from acombination of a standalone bias for low polysemy and a preference for nouns.




 Combining deep neural networks with structured logic rules is desirable to harness flexibility and reduce uninterpretability of the neural models. We propose a general framework capable of enhancing various types of neural networks (e.g., CNNs and RNNs) with declarative first-order logic rules. Specifically, we develop an iterative distillation method that transfers the structured information of logic rules into the weights of neural networks. We deploy the framework on a CNN for sentiment analysis, and an RNN for named entity recognition. With a few highly intuitive rules, we obtain substantial improvements and achieve state-of-the-art or comparable results to previous best-performing systems.
Combining deep neural networks with structured logic rules is desirable to harness flexibility and reduce uninterpretability of the neural models. We propose a general framework capable of enhancing various types of neural networks (e.g., CNNs and RNNs) with declarative first-order logic rules. Specifically, we develop an iterative distillation method that transfers the structured information of logic rules into the weights of neural networks. We deploy the framework on a CNN for sentiment analysis, and an RNN for named entity recognition. With a few highly intuitive rules, we obtain substantial improvements and achieve state-of-the-art or comparable results to previous best-performing systems.




 Here we consider some well-known facts in syntax from a physics perspective, allowing us to establish equivalences between both fields with many consequences. Mainly, we observe that the operation MERGE, put forward by N. Chomsky in 1995, can be interpreted as a physical information coarse-graining. Thus, MERGE in linguistics entails information renormalization in physics, according to different time scales. We make this point mathematically formal in terms of language models. In this setting, MERGE amounts to a probability tensor implementing a coarse-graining, akin to a probabilistic context-free grammar. The probability vectors of meaningful sentences are given by stochastic tensor networks (TN) built from diagonal tensors and which are mostly loop-free, such as Tree Tensor Networks and Matrix Product States, thus being computationally very efficient to manipulate. We show that this implies the polynomially-decaying (long-range) correlations experimentally observed in language, and also provides arguments in favour of certain types of neural networks for language processing. Moreover, we show how to obtain such language models from quantum states that can be efficiently prepared on a quantum computer, and use this to find bounds on the perplexity of the probability distribution of words in a sentence. Implications of our results are discussed across several ambits.
Here we consider some well-known facts in syntax from a physics perspective, allowing us to establish equivalences between both fields with many consequences. Mainly, we observe that the operation MERGE, put forward by N. Chomsky in 1995, can be interpreted as a physical information coarse-graining. Thus, MERGE in linguistics entails information renormalization in physics, according to different time scales. We make this point mathematically formal in terms of language models. In this setting, MERGE amounts to a probability tensor implementing a coarse-graining, akin to a probabilistic context-free grammar. The probability vectors of meaningful sentences are given by stochastic tensor networks (TN) built from diagonal tensors and which are mostly loop-free, such as Tree Tensor Networks and Matrix Product States, thus being computationally very efficient to manipulate. We show that this implies the polynomially-decaying (long-range) correlations experimentally observed in language, and also provides arguments in favour of certain types of neural networks for language processing. Moreover, we show how to obtain such language models from quantum states that can be efficiently prepared on a quantum computer, and use this to find bounds on the perplexity of the probability distribution of words in a sentence. Implications of our results are discussed across several ambits.




 In this paper, we explore a simple solution to "Multi-Source Neural Machine Translation" (MSNMT) which only relies on preprocessing a N-way multilingual corpus without modifying the Neural Machine Translation (NMT) architecture or training procedure. We simply concatenate the source sentences to form a single long multi-source input sentence while keeping the target side sentence as it is and train an NMT system using this preprocessed corpus. We evaluate our method in resource poor as well as resource rich settings and show its effectiveness (up to 4 BLEU using 2 source languages and up to 6 BLEU using 5 source languages). We also compare against existing methods for MSNMT and show that our solution gives competitive results despite its simplicity. We also provide some insights on how the NMT system leverages multilingual information in such a scenario by visualizing attention.
In this paper, we explore a simple solution to "Multi-Source Neural Machine Translation" (MSNMT) which only relies on preprocessing a N-way multilingual corpus without modifying the Neural Machine Translation (NMT) architecture or training procedure. We simply concatenate the source sentences to form a single long multi-source input sentence while keeping the target side sentence as it is and train an NMT system using this preprocessed corpus. We evaluate our method in resource poor as well as resource rich settings and show its effectiveness (up to 4 BLEU using 2 source languages and up to 6 BLEU using 5 source languages). We also compare against existing methods for MSNMT and show that our solution gives competitive results despite its simplicity. We also provide some insights on how the NMT system leverages multilingual information in such a scenario by visualizing attention.


 This paper presents an augmentation of MSCOCO dataset where speech is added to image and text. Speech captions are generated using text-to-speech (TTS) synthesis resulting in 616,767 spoken captions (more than 600h) paired with images. Disfluencies and speed perturbation are added to the signal in order to sound more natural. Each speech signal (WAV) is paired with a JSON file containing exact timecode for each word/syllable/phoneme in the spoken caption. Such a corpus could be used for Language and Vision (LaVi) tasks including speech input or output instead of text. Investigating multimodal learning schemes for unsupervised speech pattern discovery is also possible with this corpus, as demonstrated by a preliminary study conducted on a subset of the corpus (10h, 10k spoken captions). The dataset is available on Zenodo: https://zenodo.org/record/4282267
This paper presents an augmentation of MSCOCO dataset where speech is added to image and text. Speech captions are generated using text-to-speech (TTS) synthesis resulting in 616,767 spoken captions (more than 600h) paired with images. Disfluencies and speed perturbation are added to the signal in order to sound more natural. Each speech signal (WAV) is paired with a JSON file containing exact timecode for each word/syllable/phoneme in the spoken caption. Such a corpus could be used for Language and Vision (LaVi) tasks including speech input or output instead of text. Investigating multimodal learning schemes for unsupervised speech pattern discovery is also possible with this corpus, as demonstrated by a preliminary study conducted on a subset of the corpus (10h, 10k spoken captions). The dataset is available on Zenodo: https://zenodo.org/record/4282267




 Modern neural networks are often augmented with an attention mechanism, which tells the network where to focus within the input. We propose in this paper a new framework for sparse and structured attention, building upon a smoothed max operator. We show that the gradient of this operator defines a mapping from real values to probabilities, suitable as an attention mechanism. Our framework includes softmax and a slight generalization of the recently-proposed sparsemax as special cases. However, we also show how our framework can incorporate modern structured penalties, resulting in more interpretable attention mechanisms, that focus on entire segments or groups of an input. We derive efficient algorithms to compute the forward and backward passes of our attention mechanisms, enabling their use in a neural network trained with backpropagation. To showcase their potential as a drop-in replacement for existing ones, we evaluate our attention mechanisms on three large-scale tasks: textual entailment, machine translation, and sentence summarization. Our attention mechanisms improve interpretability without sacrificing performance; notably, on textual entailment and summarization, we outperform the standard attention mechanisms based on softmax and sparsemax.
Modern neural networks are often augmented with an attention mechanism, which tells the network where to focus within the input. We propose in this paper a new framework for sparse and structured attention, building upon a smoothed max operator. We show that the gradient of this operator defines a mapping from real values to probabilities, suitable as an attention mechanism. Our framework includes softmax and a slight generalization of the recently-proposed sparsemax as special cases. However, we also show how our framework can incorporate modern structured penalties, resulting in more interpretable attention mechanisms, that focus on entire segments or groups of an input. We derive efficient algorithms to compute the forward and backward passes of our attention mechanisms, enabling their use in a neural network trained with backpropagation. To showcase their potential as a drop-in replacement for existing ones, we evaluate our attention mechanisms on three large-scale tasks: textual entailment, machine translation, and sentence summarization. Our attention mechanisms improve interpretability without sacrificing performance; notably, on textual entailment and summarization, we outperform the standard attention mechanisms based on softmax and sparsemax.




 In Chinese societies, superstition is of paramount importance, and vehicle license plates with desirable numbers can fetch very high prices in auctions. Unlike other valuable items, license plates are not allocated an estimated price before auction. I propose that the task of predicting plate prices can be viewed as a natural language processing (NLP) task, as the value depends on the meaning of each individual character on the plate and its semantics. I construct a deep recurrent neural network (RNN) to predict the prices of vehicle license plates in Hong Kong, based on the characters on a plate. I demonstrate the importance of having a deep network and of retraining. Evaluated on 13 years of historical auction prices, the deep RNN's predictions can explain over 80 percent of price variations, outperforming previous models by a significant margin. I also demonstrate how the model can be extended to become a search engine for plates and to provide estimates of the expected price distribution.
In Chinese societies, superstition is of paramount importance, and vehicle license plates with desirable numbers can fetch very high prices in auctions. Unlike other valuable items, license plates are not allocated an estimated price before auction. I propose that the task of predicting plate prices can be viewed as a natural language processing (NLP) task, as the value depends on the meaning of each individual character on the plate and its semantics. I construct a deep recurrent neural network (RNN) to predict the prices of vehicle license plates in Hong Kong, based on the characters on a plate. I demonstrate the importance of having a deep network and of retraining. Evaluated on 13 years of historical auction prices, the deep RNN's predictions can explain over 80 percent of price variations, outperforming previous models by a significant margin. I also demonstrate how the model can be extended to become a search engine for plates and to provide estimates of the expected price distribution.




 Often when multiple labels are obtained for a training example it is assumed that there is an element of noise that must be accounted for. It has been shown that this disagreement can be considered signal instead of noise. In this work we investigate using soft labels for training data to improve generalization in machine learning models. However, using soft labels for training Deep Neural Networks (DNNs) is not practical due to the costs involved in obtaining multiple labels for large data sets. We propose soft label memorization-generalization (SLMG), a fine-tuning approach to using soft labels for training DNNs. We assume that differences in labels provided by human annotators represent ambiguity about the true label instead of noise. Experiments with SLMG demonstrate improved generalization performance on the Natural Language Inference (NLI) task. Our experiments show that by injecting a small percentage of soft label training data (0.03% of training set size) we can improve generalization performance over several baselines.
Often when multiple labels are obtained for a training example it is assumed that there is an element of noise that must be accounted for. It has been shown that this disagreement can be considered signal instead of noise. In this work we investigate using soft labels for training data to improve generalization in machine learning models. However, using soft labels for training Deep Neural Networks (DNNs) is not practical due to the costs involved in obtaining multiple labels for large data sets. We propose soft label memorization-generalization (SLMG), a fine-tuning approach to using soft labels for training DNNs. We assume that differences in labels provided by human annotators represent ambiguity about the true label instead of noise. Experiments with SLMG demonstrate improved generalization performance on the Natural Language Inference (NLI) task. Our experiments show that by injecting a small percentage of soft label training data (0.03% of training set size) we can improve generalization performance over several baselines.




 Machine Learning has been a big success story during the AI resurgence. One particular stand out success relates to unsupervised learning from a massive amount of data, albeit much of it relates to one modality/type of data at a time. In spite of early assertions of the unreasonable effectiveness of data, there is increasing recognition of utilizing knowledge whenever it is available or can be created purposefully. In this paper, we focus on discussing the indispensable role of knowledge for deeper understanding of complex text and multimodal data in situations where (i) large amounts of training data (labeled/unlabeled) are not available or labor intensive to create, (ii) the objects (particularly text) to be recognized are complex (i.e., beyond simple entity-person/location/organization names), such as implicit entities and highly subjective content, and (iii) applications need to use complementary or related data in multiple modalities/media. What brings us to the cusp of rapid progress is our ability to (a) create knowledge, varying from comprehensive or cross domain to domain or application specific, and (b) carefully exploit the knowledge to further empower or extend the applications of ML/NLP techniques. Using the early results in several diverse situations - both in data types and applications - we seek to foretell unprecedented progress in our ability for deeper understanding and exploitation of multimodal data.
Machine Learning has been a big success story during the AI resurgence. One particular stand out success relates to unsupervised learning from a massive amount of data, albeit much of it relates to one modality/type of data at a time. In spite of early assertions of the unreasonable effectiveness of data, there is increasing recognition of utilizing knowledge whenever it is available or can be created purposefully. In this paper, we focus on discussing the indispensable role of knowledge for deeper understanding of complex text and multimodal data in situations where (i) large amounts of training data (labeled/unlabeled) are not available or labor intensive to create, (ii) the objects (particularly text) to be recognized are complex (i.e., beyond simple entity-person/location/organization names), such as implicit entities and highly subjective content, and (iii) applications need to use complementary or related data in multiple modalities/media. What brings us to the cusp of rapid progress is our ability to (a) create knowledge, varying from comprehensive or cross domain to domain or application specific, and (b) carefully exploit the knowledge to further empower or extend the applications of ML/NLP techniques. Using the early results in several diverse situations - both in data types and applications - we seek to foretell unprecedented progress in our ability for deeper understanding and exploitation of multimodal data.




 This paper proposes a text summarization approach for factual reports using a deep learning model. This approach consists of three phases: feature extraction, feature enhancement, and summary generation, which work together to assimilate core information and generate a coherent, understandable summary. We are exploring various features to improve the set of sentences selected for the summary, and are using a Restricted Boltzmann Machine to enhance and abstract those features to improve resultant accuracy without losing any important information. The sentences are scored based on those enhanced features and an extractive summary is constructed. Experimentation carried out on several articles demonstrates the effectiveness of the proposed approach. Source code available at: https://github.com/vagisha-nidhi/TextSummarizer
This paper proposes a text summarization approach for factual reports using a deep learning model. This approach consists of three phases: feature extraction, feature enhancement, and summary generation, which work together to assimilate core information and generate a coherent, understandable summary. We are exploring various features to improve the set of sentences selected for the summary, and are using a Restricted Boltzmann Machine to enhance and abstract those features to improve resultant accuracy without losing any important information. The sentences are scored based on those enhanced features and an extractive summary is constructed. Experimentation carried out on several articles demonstrates the effectiveness of the proposed approach. Source code available at: https://github.com/vagisha-nidhi/TextSummarizer


 The recent tremendous success of unsupervised word embeddings in a multitude of applications raises the obvious question if similar methods could be derived to improve embeddings (i.e. semantic representations) of word sequences as well. We present a simple but efficient unsupervised objective to train distributed representations of sentences. Our method outperforms the state-of-the-art unsupervised models on most benchmark tasks, highlighting the robustness of the produced general-purpose sentence embeddings.
The recent tremendous success of unsupervised word embeddings in a multitude of applications raises the obvious question if similar methods could be derived to improve embeddings (i.e. semantic representations) of word sequences as well. We present a simple but efficient unsupervised objective to train distributed representations of sentences. Our method outperforms the state-of-the-art unsupervised models on most benchmark tasks, highlighting the robustness of the produced general-purpose sentence embeddings.




 Several approaches have recently been proposed for learning decentralized deep multiagent policies that coordinate via a differentiable communication channel. While these policies are effective for many tasks, interpretation of their induced communication strategies has remained a challenge. Here we propose to interpret agents' messages by translating them. Unlike in typical machine translation problems, we have no parallel data to learn from. Instead we develop a translation model based on the insight that agent messages and natural language strings mean the same thing if they induce the same belief about the world in a listener. We present theoretical guarantees and empirical evidence that our approach preserves both the semantics and pragmatics of messages by ensuring that players communicating through a translation layer do not suffer a substantial loss in reward relative to players with a common language.
Several approaches have recently been proposed for learning decentralized deep multiagent policies that coordinate via a differentiable communication channel. While these policies are effective for many tasks, interpretation of their induced communication strategies has remained a challenge. Here we propose to interpret agents' messages by translating them. Unlike in typical machine translation problems, we have no parallel data to learn from. Instead we develop a translation model based on the insight that agent messages and natural language strings mean the same thing if they induce the same belief about the world in a listener. We present theoretical guarantees and empirical evidence that our approach preserves both the semantics and pragmatics of messages by ensuring that players communicating through a translation layer do not suffer a substantial loss in reward relative to players with a common language.




 Explicit concept space models have proven efficacy for text representation in many natural language and text mining applications. The idea is to embed textual structures into a semantic space of concepts which captures the main ideas, objects, and the characteristics of these structures. The so called Bag of Concepts (BoC) representation suffers from data sparsity causing low similarity scores between similar texts due to low concept overlap. To address this problem, we propose two neural embedding models to learn continuous concept vectors. Once they are learned, we propose an efficient vector aggregation method to generate fully continuous BoC representations. We evaluate our concept embedding models on three tasks: 1) measuring entity semantic relatedness and ranking where we achieve 1.6% improvement in correlation scores, 2) dataless concept categorization where we achieve state-of-the-art performance and reduce the categorization error rate by more than 5% compared to five prior word and entity embedding models, and 3) dataless document classification where our models outperform the sparse BoC representations. In addition, by exploiting our efficient linear time vector aggregation method, we achieve better accuracy scores with much less concept dimensions compared to previous BoC densification methods which operate in polynomial time and require hundreds of dimensions in the BoC representation.
Explicit concept space models have proven efficacy for text representation in many natural language and text mining applications. The idea is to embed textual structures into a semantic space of concepts which captures the main ideas, objects, and the characteristics of these structures. The so called Bag of Concepts (BoC) representation suffers from data sparsity causing low similarity scores between similar texts due to low concept overlap. To address this problem, we propose two neural embedding models to learn continuous concept vectors. Once they are learned, we propose an efficient vector aggregation method to generate fully continuous BoC representations. We evaluate our concept embedding models on three tasks: 1) measuring entity semantic relatedness and ranking where we achieve 1.6% improvement in correlation scores, 2) dataless concept categorization where we achieve state-of-the-art performance and reduce the categorization error rate by more than 5% compared to five prior word and entity embedding models, and 3) dataless document classification where our models outperform the sparse BoC representations. In addition, by exploiting our efficient linear time vector aggregation method, we achieve better accuracy scores with much less concept dimensions compared to previous BoC densification methods which operate in polynomial time and require hundreds of dimensions in the BoC representation.




 Bandit structured prediction describes a stochastic optimization framework where learning is performed from partial feedback. This feedback is received in the form of a task loss evaluation to a predicted output structure, without having access to gold standard structures. We advance this framework by lifting linear bandit learning to neural sequence-to-sequence learning problems using attention-based recurrent neural networks. Furthermore, we show how to incorporate control variates into our learning algorithms for variance reduction and improved generalization. We present an evaluation on a neural machine translation task that shows improvements of up to 5.89 BLEU points for domain adaptation from simulated bandit feedback.
Bandit structured prediction describes a stochastic optimization framework where learning is performed from partial feedback. This feedback is received in the form of a task loss evaluation to a predicted output structure, without having access to gold standard structures. We advance this framework by lifting linear bandit learning to neural sequence-to-sequence learning problems using attention-based recurrent neural networks. Furthermore, we show how to incorporate control variates into our learning algorithms for variance reduction and improved generalization. We present an evaluation on a neural machine translation task that shows improvements of up to 5.89 BLEU points for domain adaptation from simulated bandit feedback.




 Language provides simple ways of communicating generalizable knowledge to each other (e.g., "Birds fly", "John hikes", "Fire makes smoke"). Though found in every language and emerging early in development, the language of generalization is philosophically puzzling and has resisted precise formalization. Here, we propose the first formal account of generalizations conveyed with language that makes quantitative predictions about human understanding. We test our model in three diverse domains: generalizations about categories (generic language), events (habitual language), and causes (causal language). The model explains the gradience in human endorsement through the interplay between a simple truth-conditional semantic theory and diverse beliefs about properties, formalized in a probabilistic model of language understanding. This work opens the door to understanding precisely how abstract knowledge is learned from language.
Language provides simple ways of communicating generalizable knowledge to each other (e.g., "Birds fly", "John hikes", "Fire makes smoke"). Though found in every language and emerging early in development, the language of generalization is philosophically puzzling and has resisted precise formalization. Here, we propose the first formal account of generalizations conveyed with language that makes quantitative predictions about human understanding. We test our model in three diverse domains: generalizations about categories (generic language), events (habitual language), and causes (causal language). The model explains the gradience in human endorsement through the interplay between a simple truth-conditional semantic theory and diverse beliefs about properties, formalized in a probabilistic model of language understanding. This work opens the door to understanding precisely how abstract knowledge is learned from language.




 This paper describes Luminoso's participation in SemEval 2017 Task 2, "Multilingual and Cross-lingual Semantic Word Similarity", with a system based on ConceptNet. ConceptNet is an open, multilingual knowledge graph that focuses on general knowledge that relates the meanings of words and phrases. Our submission to SemEval was an update of previous work that builds high-quality, multilingual word embeddings from a combination of ConceptNet and distributional semantics. Our system took first place in both subtasks. It ranked first in 4 out of 5 of the separate languages, and also ranked first in all 10 of the cross-lingual language pairs.
This paper describes Luminoso's participation in SemEval 2017 Task 2, "Multilingual and Cross-lingual Semantic Word Similarity", with a system based on ConceptNet. ConceptNet is an open, multilingual knowledge graph that focuses on general knowledge that relates the meanings of words and phrases. Our submission to SemEval was an update of previous work that builds high-quality, multilingual word embeddings from a combination of ConceptNet and distributional semantics. Our system took first place in both subtasks. It ranked first in 4 out of 5 of the separate languages, and also ranked first in all 10 of the cross-lingual language pairs.




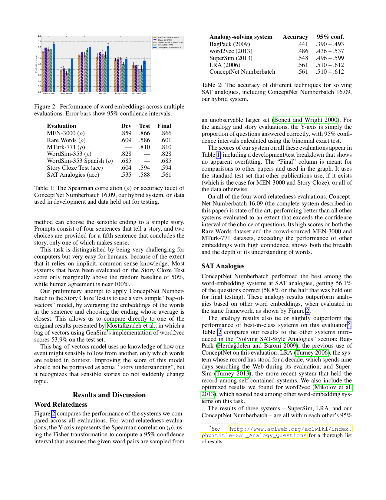 Machine learning about language can be improved by supplying it with specific knowledge and sources of external information. We present here a new version of the linked open data resource ConceptNet that is particularly well suited to be used with modern NLP techniques such as word embeddings. ConceptNet is a knowledge graph that connects words and phrases of natural language with labeled edges. Its knowledge is collected from many sources that include expert-created resources, crowd-sourcing, and games with a purpose. It is designed to represent the general knowledge involved in understanding language, improving natural language applications by allowing the application to better understand the meanings behind the words people use. When ConceptNet is combined with word embeddings acquired from distributional semantics (such as word2vec), it provides applications with understanding that they would not acquire from distributional semantics alone, nor from narrower resources such as WordNet or DBPedia. We demonstrate this with state-of-the-art results on intrinsic evaluations of word relatedness that translate into improvements on applications of word vectors, including solving SAT-style analogies.
Machine learning about language can be improved by supplying it with specific knowledge and sources of external information. We present here a new version of the linked open data resource ConceptNet that is particularly well suited to be used with modern NLP techniques such as word embeddings. ConceptNet is a knowledge graph that connects words and phrases of natural language with labeled edges. Its knowledge is collected from many sources that include expert-created resources, crowd-sourcing, and games with a purpose. It is designed to represent the general knowledge involved in understanding language, improving natural language applications by allowing the application to better understand the meanings behind the words people use. When ConceptNet is combined with word embeddings acquired from distributional semantics (such as word2vec), it provides applications with understanding that they would not acquire from distributional semantics alone, nor from narrower resources such as WordNet or DBPedia. We demonstrate this with state-of-the-art results on intrinsic evaluations of word relatedness that translate into improvements on applications of word vectors, including solving SAT-style analogies.

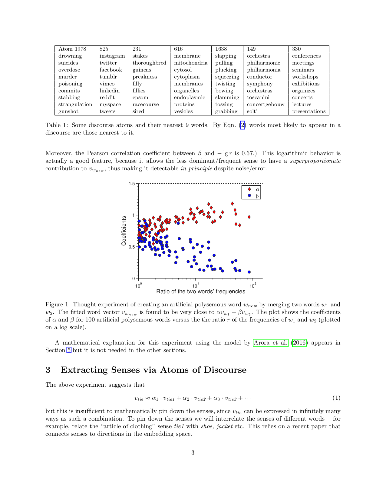


 Word embeddings are ubiquitous in NLP and information retrieval, but it is unclear what they represent when the word is polysemous. Here it is shown that multiple word senses reside in linear superposition within the word embedding and simple sparse coding can recover vectors that approximately capture the senses. The success of our approach, which applies to several embedding methods, is mathematically explained using a variant of the random walk on discourses model (Arora et al., 2016). A novel aspect of our technique is that each extracted word sense is accompanied by one of about 2000 "discourse atoms" that gives a succinct description of which other words co-occur with that word sense. Discourse atoms can be of independent interest, and make the method potentially more useful. Empirical tests are used to verify and support the theory.
Word embeddings are ubiquitous in NLP and information retrieval, but it is unclear what they represent when the word is polysemous. Here it is shown that multiple word senses reside in linear superposition within the word embedding and simple sparse coding can recover vectors that approximately capture the senses. The success of our approach, which applies to several embedding methods, is mathematically explained using a variant of the random walk on discourses model (Arora et al., 2016). A novel aspect of our technique is that each extracted word sense is accompanied by one of about 2000 "discourse atoms" that gives a succinct description of which other words co-occur with that word sense. Discourse atoms can be of independent interest, and make the method potentially more useful. Empirical tests are used to verify and support the theory.