-
Reliable obstacle detection and classification in rough and unstructured
terrain such as agricultural fields or orchards remains a challenging problem.
These environments involve large variations in both geometry and appearance,
challenging perception systems that rely on only a single sensor modality.
Geometrically, tall grass, fallen leaves, or terrain roughness can mistakenly
be perceived as nontraversable or might even obscure actual obstacles.
Likewise, traversable grass or dirt roads and obstacles such as trees and
bushes might be visually ambiguous. In this paper, we combine appearance- and
geometry-based detection methods by probabilistically fusing lidar and camera
sensing with semantic segmentation using a conditional random field. We apply a
state-of-the-art multimodal fusion algorithm from the scene analysis domain and
adjust it for obstacle detection in agriculture with moving ground vehicles.
This involves explicitly handling sparse point cloud data and exploiting both
spatial, temporal, and multimodal links between corresponding 2D and 3D
regions. The proposed method was evaluated on a diverse data set, comprising a
dairy paddock and different orchards gathered with a perception research robot
in Australia. Results showed that for a two-class classification problem
(ground and nonground), only the camera leveraged from information provided by
the other modality with an increase in the mean classification score of 0.5%.
However, as more classes were introduced (ground, sky, vegetation, and object),
both modalities complemented each other with improvements of 1.4% in 2D and
7.9% in 3D. Finally, introducing temporal links between successive frames
resulted in improvements of 0.2% in 2D and 1.5% in 3D.
-
In order to have effective human-AI collaboration, it is necessary to address
how the AI agent's behavior is being perceived by the humans-in-the-loop. When
the agent's task plans are generated without such considerations, they may
often demonstrate inexplicable behavior from the human's point of view. This
problem may arise due to the human's partial or inaccurate understanding of the
agent's planning model. This may have serious implications from increased
cognitive load to more serious concerns of safety around a physical agent. In
this paper, we address this issue by modeling plan explicability as a function
of the distance between a plan that agent makes and the plan that human expects
it to make. We learn a regression model for mapping the plan distances to
explicability scores of plans and develop an anytime search algorithm that can
use this model as a heuristic to come up with progressively explicable plans.
We evaluate the effectiveness of our approach in a simulated autonomous car
domain and a physical robot domain.
-
A defining feature of sampling-based motion planning is the reliance on an
implicit representation of the state space, which is enabled by a set of
probing samples. Traditionally, these samples are drawn either
probabilistically or deterministically to uniformly cover the state space. Yet,
the motion of many robotic systems is often restricted to "small" regions of
the state space, due to, for example, differential constraints or
collision-avoidance constraints. To accelerate the planning process, it is thus
desirable to devise non-uniform sampling strategies that favor sampling in
those regions where an optimal solution might lie. This paper proposes a
methodology for non-uniform sampling, whereby a sampling distribution is
learned from demonstrations, and then used to bias sampling. The sampling
distribution is computed through a conditional variational autoencoder,
allowing sample generation from the latent space conditioned on the specific
planning problem. This methodology is general, can be used in combination with
any sampling-based planner, and can effectively exploit the underlying
structure of a planning problem while maintaining the theoretical guarantees of
sampling-based approaches. Specifically, on several planning problems, the
proposed methodology is shown to effectively learn representations for the
relevant regions of the state space, resulting in an order of magnitude
improvement in terms of success rate and convergence to the optimal cost.
-
A great deal of work aims to discover large general purpose models of image
interest or memorability for visual search and information retrieval. This
paper argues that image interest is often domain and user specific, and that
efficient mechanisms for learning about this domain-specific image interest as
quickly as possible, while limiting the amount of data-labelling required, are
often more useful to end-users. This work uses pairwise image comparisons to
reduce the labelling burden on these users, and introduces an image interest
estimation approach that performs similarly to recent data hungry deep learning
approaches trained using pairwise ranking losses. Here, we use a Gaussian
process model to interpolate image interest inferred using a Bayesian ranking
approach over image features extracted using a pre-trained convolutional neural
network. Results show that fitting a Gaussian process in high-dimensional image
feature space is not only computationally feasible, but also effective across a
broad range of domains. The proposed probabilistic interest estimation approach
produces image interests paired with uncertainties that can be used to identify
images for which additional labelling is required and measure inference
convergence, allowing for sample efficient active model training. Importantly,
the probabilistic formulation allows for effective visual search and
information retrieval when limited labelling data is available.
-
We address the problem of controlling the workspace of a 3-DoF mobile robot.
In a human-robot shared space, robots should navigate in a human-acceptable way
according to the users' demands. For this purpose, we employ virtual borders,
that are non-physical borders, to allow a user the restriction of the robot's
workspace. To this end, we propose an interaction method based on a laser
pointer to intuitively define virtual borders. This interaction method uses a
previously developed framework based on robot guidance to change the robot's
navigational behavior. Furthermore, we extend this framework to increase the
flexibility by considering different types of virtual borders, i.e. polygons
and curves separating an area. We evaluated our method with 15 non-expert users
concerning correctness, accuracy and teaching time. The experimental results
revealed a high accuracy and linear teaching time with respect to the border
length while correctly incorporating the borders into the robot's navigational
map. Finally, our user study showed that non-expert users can employ our
interaction method.
-
Mobile ground robots operating on unstructured terrain must predict which
areas of the environment they are able to pass in order to plan feasible paths.
We address traversability estimation as a heightmap classification problem: we
build a convolutional neural network that, given an image representing the
heightmap of a terrain patch, predicts whether the robot will be able to
traverse such patch from left to right. The classifier is trained for a
specific robot model (wheeled, tracked, legged, snake-like) using simulation
data on procedurally generated training terrains; the trained classifier can be
applied to unseen large heightmaps to yield oriented traversability maps, and
then plan traversable paths. We extensively evaluate the approach in simulation
on six real-world elevation datasets, and run a real-robot validation in one
indoor and one outdoor environment.
-
Tactile-based blind grasping addresses realistic robotic grasping in which
the hand only has access to proprioceptive and tactile sensors. The robotic
hand has no prior knowledge of the object/grasp properties, such as object
weight, inertia, and shape. There exists no manipulation controller that
rigorously guarantees object manipulation in such a setting. Here, a robust
control law is proposed for object manipulation in tactile-based blind
grasping. The analysis ensures semi-global asymptotic and exponential stability
in the presence of model uncertainties and external disturbances that are
neglected in related work. Simulation and experimental results validate the
effectiveness of the proposed approach.
-
We introduce a neural architecture for navigation in novel environments. Our
proposed architecture learns to map from first-person views and plans a
sequence of actions towards goals in the environment. The Cognitive Mapper and
Planner (CMP) is based on two key ideas: a) a unified joint architecture for
mapping and planning, such that the mapping is driven by the needs of the task,
and b) a spatial memory with the ability to plan given an incomplete set of
observations about the world. CMP constructs a top-down belief map of the world
and applies a differentiable neural net planner to produce the next action at
each time step. The accumulated belief of the world enables the agent to track
visited regions of the environment. We train and test CMP on navigation
problems in simulation environments derived from scans of real world buildings.
Our experiments demonstrate that CMP outperforms alternate learning-based
architectures, as well as, classical mapping and path planning approaches in
many cases. Furthermore, it naturally extends to semantically specified goals,
such as 'going to a chair'. We also deploy CMP on physical robots in indoor
environments, where it achieves reasonable performance, even though it is
trained entirely in simulation.
-
The fresh water reservoirs are one of the main power resources of
Pakistan.These water reservoirs are in the form of Tarbela Dam, Mangla Dam,
Bhasha Dam,and Warsak Dam. To estimate the current power capability of the
Dams, the statistical information about the water in the dam has to be clear
and precise. For the purpose of water management monthly or yearly survey of
the dams required. One of the important parameter is to find the water level of
water, which can help us in finding the pressure and flow of water in dams. The
existing surveying systems have some problems, i.e., risky, errors in
measurement and sometimes expensive. Our project has tried a lot to overcome
these flaws and to develop more economical, safe and accurate system for
finding depth values of dams and ponds. The key purpose of Our Project
Autonomous Surveying Boat is to have it log water depths along a predefined set
of points. The Autonomous Surveying Boat floats in water according to
predefined path, getting the coordinates from GPS Sensor and direction is
controlled by using Magnetometer Sensor. It stores its data on SD card as a
text file for later readings. The boat can also be used to find the average
capacity of the dam. The average depth is calculated from the measured depth
values at different set points of the dam. The actual length of the dam is
determined by the magnetometer. The numbers of surveys over the time can help
us in finding the silting ratio in dams.For square dams the length and width of
the dam are measured and the average depth, then using these three parameters
we can estimate the average capacity of the dam.The boat is scalable for
furthered modification if needed.
-
We present a novel framework for the automatic discovery and recognition of
motion primitives in videos of human activities. Given the 3D pose of a human
in a video, human motion primitives are discovered by optimizing the `motion
flux', a quantity which captures the motion variation of a group of skeletal
joints. A normalization of the primitives is proposed in order to make them
invariant with respect to a subject anatomical variations and data sampling
rate. The discovered primitives are unknown and unlabeled and are
unsupervisedly collected into classes via a hierarchical non-parametric Bayes
mixture model. Once classes are determined and labeled they are further
analyzed for establishing models for recognizing discovered primitives. Each
primitive model is defined by a set of learned parameters.
Given new video data and given the estimated pose of the subject appearing on
the video, the motion is segmented into primitives, which are recognized with a
probability given according to the parameters of the learned models.
Using our framework we build a publicly available dataset of human motion
primitives, using sequences taken from well-known motion capture datasets. We
expect that our framework, by providing an objective way for discovering and
categorizing human motion, will be a useful tool in numerous research fields
including video analysis, human inspired motion generation, learning by
demonstration, intuitive human-robot interaction, and human behavior analysis.
-
This work studies the problem of stochastic dynamic filtering and state
propagation with complex beliefs. The main contribution is GP-SUM, a filtering
algorithm tailored to dynamic systems and observation models expressed as
Gaussian Processes (GP), and to states represented as a weighted sum of
Gaussians. The key attribute of GP-SUM is that it does not rely on
linearizations of the dynamic or observation models, or on unimodal Gaussian
approximations of the belief, hence enables tracking complex state
distributions. The algorithm can be seen as a combination of a sampling-based
filter with a probabilistic Bayes filter. On the one hand, GP-SUM operates by
sampling the state distribution and propagating each sample through the dynamic
system and observation models. On the other hand, it achieves effective
sampling and accurate probabilistic propagation by relying on the GP form of
the system, and the sum-of-Gaussian form of the belief. We show that GP-SUM
outperforms several GP-Bayes and Particle Filters on a standard benchmark. We
also demonstrate its use in a pushing task, predicting with experimental
accuracy the naturally occurring non-Gaussian distributions.
-
In this note, we extend the algorithms Extra and subgradient-push to a new
algorithm ExtraPush for consensus optimization with convex differentiable
objective functions over a directed network. When the stationary distribution
of the network can be computed in advance}, we propose a simplified algorithm
called Normalized ExtraPush. Just like Extra, both ExtraPush and Normalized
ExtraPush can iterate with a fixed step size. But unlike Extra, they can take a
column-stochastic mixing matrix, which is not necessarily doubly stochastic.
Therefore, they remove the undirected-network restriction of Extra.
Subgradient-push, while also works for directed networks, is slower on the same
type of problem because it must use a sequence of diminishing step sizes.
We present preliminary analysis for ExtraPush under a bounded sequence
assumption. For Normalized ExtraPush, we show that it naturally produces a
bounded, linearly convergent sequence provided that the objective function is
strongly convex.
In our numerical experiments, ExtraPush and Normalized ExtraPush performed
similarly well. They are significantly faster than subgradient-push, even when
we hand-optimize the step sizes for the latter.
-
This study considers the control of parent-child systems where a parent
system is acted on by a set of controllable child systems (i.e. a swarm).
Examples of such systems include a swarm of robots pushing an object over a
surface, a swarm of aerial vehicles carrying a large load, or a set of end
effectors manipulating an object. In this paper, a general approach for
decoupling the swarm from the parent system through a low-dimensional abstract
state space is presented. The requirements of this approach are given along
with how constraints on both systems propagate through the abstract state and
impact the requirements of the controllers for both systems. To demonstrate,
several controllers with hard state constraints are designed to track a given
desired angle trajectory of a tilting plane with a swarm of robots driving on
top. Both homogeneous and heterogeneous swarms of varying sizes and properties
are considered to test the robustness of this architecture. The controllers are
shown to be locally asymptotically stable and are demonstrated in simulation.
-
Characterizing human values is a topic deeply interwoven with the sciences,
humanities, art, and many other human endeavors. In recent years, a number of
thinkers have argued that accelerating trends in computer science, cognitive
science, and related disciplines foreshadow the creation of intelligent
machines which meet and ultimately surpass the cognitive abilities of human
beings, thereby entangling an understanding of human values with future
technological development. Contemporary research accomplishments suggest
sophisticated AI systems becoming widespread and responsible for managing many
aspects of the modern world, from preemptively planning users' travel schedules
and logistics, to fully autonomous vehicles, to domestic robots assisting in
daily living. The extrapolation of these trends has been most forcefully
described in the context of a hypothetical "intelligence explosion," in which
the capabilities of an intelligent software agent would rapidly increase due to
the presence of feedback loops unavailable to biological organisms. The
possibility of superintelligent agents, or simply the widespread deployment of
sophisticated, autonomous AI systems, highlights an important theoretical
problem: the need to separate the cognitive and rational capacities of an agent
from the fundamental goal structure, or value system, which constrains and
guides the agent's actions. The "value alignment problem" is to specify a goal
structure for autonomous agents compatible with human values. In this brief
article, we suggest that recent ideas from affective neuroscience and related
disciplines aimed at characterizing neurological and behavioral universals in
the mammalian class provide important conceptual foundations relevant to
describing human values. We argue that the notion of "mammalian value systems"
points to a potential avenue for fundamental research in AI safety and AI
ethics.
-
The complex physical properties of highly deformable materials such as
clothes pose significant challenges fanipulation systems. We present a novel
visual feedback dictionary-based method for manipulating defoor autonomous
robotic mrmable objects towards a desired configuration. Our approach is based
on visual servoing and we use an efficient technique to extract key features
from the RGB sensor stream in the form of a histogram of deformable model
features. These histogram features serve as high-level representations of the
state of the deformable material. Next, we collect manipulation data and use a
visual feedback dictionary that maps the velocity in the high-dimensional
feature space to the velocity of the robotic end-effectors for manipulation. We
have evaluated our approach on a set of complex manipulation tasks and
human-robot manipulation tasks on different cloth pieces with varying material
characteristics.
-
Loop-closure detection on 3D data is a challenging task that has been
commonly approached by adapting image-based solutions. Methods based on local
features suffer from ambiguity and from robustness to environment changes while
methods based on global features are viewpoint dependent. We propose SegMatch,
a reliable loop-closure detection algorithm based on the matching of 3D
segments. Segments provide a good compromise between local and global
descriptions, incorporating their strengths while reducing their individual
drawbacks.
SegMatch does not rely on assumptions of "perfect segmentation", or on the
existence of "objects" in the environment, which allows for reliable execution
on large scale, unstructured environments. We quantitatively demonstrate that
SegMatch can achieve accurate localization at a frequency of 1Hz on the largest
sequence of the KITTI odometry dataset. We furthermore show how this algorithm
can reliably detect and close loops in real-time, during online operation. In
addition, the source code for the SegMatch algorithm will be made available
after publication.
-
This paper considers the chattering problem of sliding mode control while
delay in robot manipulator caused chaos in such electromechanical systems.
Fractional calculus as a powerful theorem to produce a novel sliding mode;
which has a dynamic essence is used for chattering elimination. To realize the
control of a class of chaotic systems in master-slave configuration this novel
fractional dynamic sliding mode control scheme is presented and examined on
delay based chaotic robot in joint and work space. Also the stability of the
closed-loop system is guaranteed by Lyapunov stability theory. Beside these,
delayed robot motions are sorted out for qualitative and quantification study.
Finally, numerical simulation example illustrates the feasibility of proposed
control method.
-
Autonomous driving requires operation in different behavioral modes ranging
from lane following and intersection crossing to turning and stopping. However,
most existing deep learning approaches to autonomous driving do not consider
the behavioral mode in the training strategy. This paper describes a technique
for learning multiple distinct behavioral modes in a single deep neural network
through the use of multi-modal multi-task learning. We study the effectiveness
of this approach, denoted MultiNet, using self-driving model cars for driving
in unstructured environments such as sidewalks and unpaved roads. Using labeled
data from over one hundred hours of driving our fleet of 1/10th scale model
cars, we trained different neural networks to predict the steering angle and
driving speed of the vehicle in different behavioral modes. We show that in
each case, MultiNet networks outperform networks trained on individual modes
while using a fraction of the total number of parameters.
-
In this paper, we introduce a dynamic fiducial marker which can change its
appearance according to the spatiotemporal requirements of the visual
perception task of a mobile robot using a camera as the sensor. We present a
control scheme to dynamically change the appearance of the marker in order to
increase the range of detection and to assure a better accuracy on the close
range. The marker control takes into account the camera to marker distance
(which influences the scale of the marker in image coordinates) to select which
fiducial markers to display. Hence, we realize a tight coupling between the
visual pose control of the mobile robot and the appearance of the dynamic
fiducial marker. Additionally, we discuss the practical implications of time
delays due to processing time and communication delays between the robot and
the marker. Finally, we propose a real-time dynamic marker visual servoing
control scheme for quadcopter landing and evaluate the performance on a
real-world example.
-
We report on an extensive study of the benefits and limitations of current
deep learning approaches to object recognition in robot vision scenarios,
introducing a novel dataset used for our investigation. To avoid the biases in
currently available datasets, we consider a natural human-robot interaction
setting to design a data-acquisition protocol for visual object recognition on
the iCub humanoid robot. Analyzing the performance of off-the-shelf models
trained off-line on large-scale image retrieval datasets, we show the necessity
for knowledge transfer. We evaluate different ways in which this last step can
be done, and identify the major bottlenecks affecting robotic scenarios. By
studying both object categorization and identification problems, we highlight
key differences between object recognition in robotics applications and in
image retrieval tasks, for which the considered deep learning approaches have
been originally designed. In a nutshell, our results confirm the remarkable
improvements yield by deep learning in this setting, while pointing to specific
open challenges that need be addressed for seamless deployment in robotics.
-
We develop a new analysis of sampling-based motion planning in Euclidean
space with uniform random sampling, which significantly improves upon the
celebrated result of Karaman and Frazzoli (2011) and subsequent work.
Particularly, we prove the existence of a critical connection radius
proportional to ${\Theta(n^{-1/d})}$ for $n$ samples and ${d}$ dimensions:
Below this value the planner is guaranteed to fail (similarly shown by the
aforementioned work, ibid.). More importantly, for larger radius values the
planner is asymptotically (near-)optimal. Furthermore, our analysis yields an
explicit lower bound of ${1-O( n^{-1})}$ on the probability of success. A
practical implication of our work is that asymptotic (near-)optimality is
achieved when each sample is connected to only ${\Theta(1)}$ neighbors. This is
in stark contrast to previous work which requires ${\Theta(\log n)}$
connections, that are induced by a radius of order ${\left(\frac{\log
n}{n}\right)^{1/d}}$. Our analysis is not restricted to PRM and applies to a
variety of PRM-based planners, including RRG, FMT* and BTT. Continuum
percolation plays an important role in our proofs. Lastly, we develop similar
theory for all the aforementioned planners when constructed with deterministic
samples, which are then sparsified in a randomized fashion. We believe that
this new model, and its analysis, is interesting in its own right.
-
Contact modeling plays a central role in motion planning, simulation, and
control of legged robots, as legged locomotion is realized through contact. The
two prevailing approaches to model the contact consider rigid and compliant
premise at interaction ports. Contrary to the dynamics model of legged systems
with rigid contact (without impact) which is straightforward to develop, there
is no consensus among researchers to employ a standard compliant contact model.
Our main goal in this paper is to study the dynamics model structure of bipedal
walking systems with a rigid contact and a \textit{novel} compliant contact
model and to present experimental validation of both models. For the model with
rigid contact, after developing the model of the articulated bodies in flight
phase without any contact with the environment, we apply the holonomic
constraints at contact points and develop a constrained dynamics model of the
robot in both single and double support phases. For the model with compliant
contact, we propose a novel nonlinear contact model and simulate the motion of
the robot using this model. In order to show the performance of the developed
models, we compare obtained results from these models to the empirical
measurements from bipedal walking of the human-sized humanoid robot SURENA III,
which has been designed and fabricated at CAST, University of Tehran. This
analysis shows the merit of both models in estimating dynamic behavior of the
robot walking on a semi-rigid surface. The model with rigid contact, which is
less complex and independent of the physical properties of the contacting
bodies, can be employed for model-based motion optimization, analysis as well
as control, while the model with compliant contact and more complexity is
suitable for more realistic simulation scenarios.
-
The theoretical ability of modular robots to reconfigure in response to
complex tasks in a priori unknown environments has frequently been cited as an
advantage and remains a major motivator for work in the field. We present a
modular robot system capable of autonomously completing high-level tasks by
reactively reconfiguring to meet the needs of a perceived, a priori unknown
environment. The system integrates perception, high-level planning, and modular
hardware, and is validated in three hardware demonstrations. Given a high-level
task specification, a modular robot autonomously explores an unknown
environment, decides when and how to reconfigure, and manipulates objects to
complete its task. The system architecture balances distributed mechanical
elements with centralized perception, planning, and control. By providing an
example of how a modular robot system can be designed to leverage reactive
reconfigurability in unknown environments, we have begun to lay the groundwork
for modular self-reconfigurable robots to address tasks in the real world.
-
This paper addresses the problem of Human-Aware Navigation (HAN), using multi
camera sensors to implement a vision-based person tracking system. The main
contributions of this paper are as follows: a novel and efficient Deep Learning
person detection and a standardization of human-aware constraints. In the first
stage of the approach, we propose to cascade the Aggregate Channel Features
(ACF) detector with a deep Convolutional Neural Network (CNN) to achieve fast
and accurate Pedestrian Detection (PD). Regarding the human awareness (that can
be defined as constraints associated with the robot's motion), we use a mixture
of asymmetric Gaussian functions, to define the cost functions associated to
each constraint. Both methods proposed herein are evaluated individually to
measure the impact of each of the components. The final solution (including
both the proposed pedestrian detection and the human-aware constraints) is
tested in a typical domestic indoor scenario, in four distinct experiments. The
results show that the robot is able to cope with human-aware constraints,
defined after common proxemics and social rules.
-
The biomechanics of the human body gives subjects a high degree of freedom in
how they can execute movement. Nevertheless, subjects exhibit regularity in
their movement patterns. One way to account for this regularity is to suppose
that subjects select movement trajectories that are optimal in some sense. We
adopt the principle that human movements are optimal and develop a general
model for human movement patters that uses variational methods in the form of
optimal control theory to calculate trajectories of movement trajectories of
the body. We find that in this approach a constant of the motion that arises
from the model and which plays a role in the optimal control model that is
analogous to the role that the mechanical energy plays in classical physics. We
illustrate how this approach works in practice by using it to develop a model
of walking gait, making all the derivations and calculations in detail. We
finally show that this optimal control model of walking gait recovers in an
appropriate limit an existing model of walking gait which has been shown to
provide good estimates of many observed characteristics of walking gait.





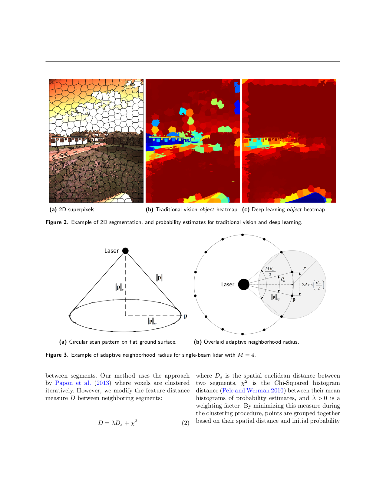 Reliable obstacle detection and classification in rough and unstructured terrain such as agricultural fields or orchards remains a challenging problem. These environments involve large variations in both geometry and appearance, challenging perception systems that rely on only a single sensor modality. Geometrically, tall grass, fallen leaves, or terrain roughness can mistakenly be perceived as nontraversable or might even obscure actual obstacles. Likewise, traversable grass or dirt roads and obstacles such as trees and bushes might be visually ambiguous. In this paper, we combine appearance- and geometry-based detection methods by probabilistically fusing lidar and camera sensing with semantic segmentation using a conditional random field. We apply a state-of-the-art multimodal fusion algorithm from the scene analysis domain and adjust it for obstacle detection in agriculture with moving ground vehicles. This involves explicitly handling sparse point cloud data and exploiting both spatial, temporal, and multimodal links between corresponding 2D and 3D regions. The proposed method was evaluated on a diverse data set, comprising a dairy paddock and different orchards gathered with a perception research robot in Australia. Results showed that for a two-class classification problem (ground and nonground), only the camera leveraged from information provided by the other modality with an increase in the mean classification score of 0.5%. However, as more classes were introduced (ground, sky, vegetation, and object), both modalities complemented each other with improvements of 1.4% in 2D and 7.9% in 3D. Finally, introducing temporal links between successive frames resulted in improvements of 0.2% in 2D and 1.5% in 3D.
Reliable obstacle detection and classification in rough and unstructured terrain such as agricultural fields or orchards remains a challenging problem. These environments involve large variations in both geometry and appearance, challenging perception systems that rely on only a single sensor modality. Geometrically, tall grass, fallen leaves, or terrain roughness can mistakenly be perceived as nontraversable or might even obscure actual obstacles. Likewise, traversable grass or dirt roads and obstacles such as trees and bushes might be visually ambiguous. In this paper, we combine appearance- and geometry-based detection methods by probabilistically fusing lidar and camera sensing with semantic segmentation using a conditional random field. We apply a state-of-the-art multimodal fusion algorithm from the scene analysis domain and adjust it for obstacle detection in agriculture with moving ground vehicles. This involves explicitly handling sparse point cloud data and exploiting both spatial, temporal, and multimodal links between corresponding 2D and 3D regions. The proposed method was evaluated on a diverse data set, comprising a dairy paddock and different orchards gathered with a perception research robot in Australia. Results showed that for a two-class classification problem (ground and nonground), only the camera leveraged from information provided by the other modality with an increase in the mean classification score of 0.5%. However, as more classes were introduced (ground, sky, vegetation, and object), both modalities complemented each other with improvements of 1.4% in 2D and 7.9% in 3D. Finally, introducing temporal links between successive frames resulted in improvements of 0.2% in 2D and 1.5% in 3D.




 In order to have effective human-AI collaboration, it is necessary to address how the AI agent's behavior is being perceived by the humans-in-the-loop. When the agent's task plans are generated without such considerations, they may often demonstrate inexplicable behavior from the human's point of view. This problem may arise due to the human's partial or inaccurate understanding of the agent's planning model. This may have serious implications from increased cognitive load to more serious concerns of safety around a physical agent. In this paper, we address this issue by modeling plan explicability as a function of the distance between a plan that agent makes and the plan that human expects it to make. We learn a regression model for mapping the plan distances to explicability scores of plans and develop an anytime search algorithm that can use this model as a heuristic to come up with progressively explicable plans. We evaluate the effectiveness of our approach in a simulated autonomous car domain and a physical robot domain.
In order to have effective human-AI collaboration, it is necessary to address how the AI agent's behavior is being perceived by the humans-in-the-loop. When the agent's task plans are generated without such considerations, they may often demonstrate inexplicable behavior from the human's point of view. This problem may arise due to the human's partial or inaccurate understanding of the agent's planning model. This may have serious implications from increased cognitive load to more serious concerns of safety around a physical agent. In this paper, we address this issue by modeling plan explicability as a function of the distance between a plan that agent makes and the plan that human expects it to make. We learn a regression model for mapping the plan distances to explicability scores of plans and develop an anytime search algorithm that can use this model as a heuristic to come up with progressively explicable plans. We evaluate the effectiveness of our approach in a simulated autonomous car domain and a physical robot domain.



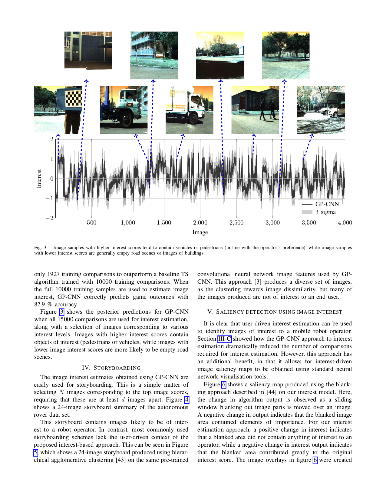
 A great deal of work aims to discover large general purpose models of image interest or memorability for visual search and information retrieval. This paper argues that image interest is often domain and user specific, and that efficient mechanisms for learning about this domain-specific image interest as quickly as possible, while limiting the amount of data-labelling required, are often more useful to end-users. This work uses pairwise image comparisons to reduce the labelling burden on these users, and introduces an image interest estimation approach that performs similarly to recent data hungry deep learning approaches trained using pairwise ranking losses. Here, we use a Gaussian process model to interpolate image interest inferred using a Bayesian ranking approach over image features extracted using a pre-trained convolutional neural network. Results show that fitting a Gaussian process in high-dimensional image feature space is not only computationally feasible, but also effective across a broad range of domains. The proposed probabilistic interest estimation approach produces image interests paired with uncertainties that can be used to identify images for which additional labelling is required and measure inference convergence, allowing for sample efficient active model training. Importantly, the probabilistic formulation allows for effective visual search and information retrieval when limited labelling data is available.
A great deal of work aims to discover large general purpose models of image interest or memorability for visual search and information retrieval. This paper argues that image interest is often domain and user specific, and that efficient mechanisms for learning about this domain-specific image interest as quickly as possible, while limiting the amount of data-labelling required, are often more useful to end-users. This work uses pairwise image comparisons to reduce the labelling burden on these users, and introduces an image interest estimation approach that performs similarly to recent data hungry deep learning approaches trained using pairwise ranking losses. Here, we use a Gaussian process model to interpolate image interest inferred using a Bayesian ranking approach over image features extracted using a pre-trained convolutional neural network. Results show that fitting a Gaussian process in high-dimensional image feature space is not only computationally feasible, but also effective across a broad range of domains. The proposed probabilistic interest estimation approach produces image interests paired with uncertainties that can be used to identify images for which additional labelling is required and measure inference convergence, allowing for sample efficient active model training. Importantly, the probabilistic formulation allows for effective visual search and information retrieval when limited labelling data is available.




 We address the problem of controlling the workspace of a 3-DoF mobile robot. In a human-robot shared space, robots should navigate in a human-acceptable way according to the users' demands. For this purpose, we employ virtual borders, that are non-physical borders, to allow a user the restriction of the robot's workspace. To this end, we propose an interaction method based on a laser pointer to intuitively define virtual borders. This interaction method uses a previously developed framework based on robot guidance to change the robot's navigational behavior. Furthermore, we extend this framework to increase the flexibility by considering different types of virtual borders, i.e. polygons and curves separating an area. We evaluated our method with 15 non-expert users concerning correctness, accuracy and teaching time. The experimental results revealed a high accuracy and linear teaching time with respect to the border length while correctly incorporating the borders into the robot's navigational map. Finally, our user study showed that non-expert users can employ our interaction method.
We address the problem of controlling the workspace of a 3-DoF mobile robot. In a human-robot shared space, robots should navigate in a human-acceptable way according to the users' demands. For this purpose, we employ virtual borders, that are non-physical borders, to allow a user the restriction of the robot's workspace. To this end, we propose an interaction method based on a laser pointer to intuitively define virtual borders. This interaction method uses a previously developed framework based on robot guidance to change the robot's navigational behavior. Furthermore, we extend this framework to increase the flexibility by considering different types of virtual borders, i.e. polygons and curves separating an area. We evaluated our method with 15 non-expert users concerning correctness, accuracy and teaching time. The experimental results revealed a high accuracy and linear teaching time with respect to the border length while correctly incorporating the borders into the robot's navigational map. Finally, our user study showed that non-expert users can employ our interaction method.




 We introduce a neural architecture for navigation in novel environments. Our proposed architecture learns to map from first-person views and plans a sequence of actions towards goals in the environment. The Cognitive Mapper and Planner (CMP) is based on two key ideas: a) a unified joint architecture for mapping and planning, such that the mapping is driven by the needs of the task, and b) a spatial memory with the ability to plan given an incomplete set of observations about the world. CMP constructs a top-down belief map of the world and applies a differentiable neural net planner to produce the next action at each time step. The accumulated belief of the world enables the agent to track visited regions of the environment. We train and test CMP on navigation problems in simulation environments derived from scans of real world buildings. Our experiments demonstrate that CMP outperforms alternate learning-based architectures, as well as, classical mapping and path planning approaches in many cases. Furthermore, it naturally extends to semantically specified goals, such as 'going to a chair'. We also deploy CMP on physical robots in indoor environments, where it achieves reasonable performance, even though it is trained entirely in simulation.
We introduce a neural architecture for navigation in novel environments. Our proposed architecture learns to map from first-person views and plans a sequence of actions towards goals in the environment. The Cognitive Mapper and Planner (CMP) is based on two key ideas: a) a unified joint architecture for mapping and planning, such that the mapping is driven by the needs of the task, and b) a spatial memory with the ability to plan given an incomplete set of observations about the world. CMP constructs a top-down belief map of the world and applies a differentiable neural net planner to produce the next action at each time step. The accumulated belief of the world enables the agent to track visited regions of the environment. We train and test CMP on navigation problems in simulation environments derived from scans of real world buildings. Our experiments demonstrate that CMP outperforms alternate learning-based architectures, as well as, classical mapping and path planning approaches in many cases. Furthermore, it naturally extends to semantically specified goals, such as 'going to a chair'. We also deploy CMP on physical robots in indoor environments, where it achieves reasonable performance, even though it is trained entirely in simulation.




 In this note, we extend the algorithms Extra and subgradient-push to a new algorithm ExtraPush for consensus optimization with convex differentiable objective functions over a directed network. When the stationary distribution of the network can be computed in advance}, we propose a simplified algorithm called Normalized ExtraPush. Just like Extra, both ExtraPush and Normalized ExtraPush can iterate with a fixed step size. But unlike Extra, they can take a column-stochastic mixing matrix, which is not necessarily doubly stochastic. Therefore, they remove the undirected-network restriction of Extra. Subgradient-push, while also works for directed networks, is slower on the same type of problem because it must use a sequence of diminishing step sizes. We present preliminary analysis for ExtraPush under a bounded sequence assumption. For Normalized ExtraPush, we show that it naturally produces a bounded, linearly convergent sequence provided that the objective function is strongly convex. In our numerical experiments, ExtraPush and Normalized ExtraPush performed similarly well. They are significantly faster than subgradient-push, even when we hand-optimize the step sizes for the latter.
In this note, we extend the algorithms Extra and subgradient-push to a new algorithm ExtraPush for consensus optimization with convex differentiable objective functions over a directed network. When the stationary distribution of the network can be computed in advance}, we propose a simplified algorithm called Normalized ExtraPush. Just like Extra, both ExtraPush and Normalized ExtraPush can iterate with a fixed step size. But unlike Extra, they can take a column-stochastic mixing matrix, which is not necessarily doubly stochastic. Therefore, they remove the undirected-network restriction of Extra. Subgradient-push, while also works for directed networks, is slower on the same type of problem because it must use a sequence of diminishing step sizes. We present preliminary analysis for ExtraPush under a bounded sequence assumption. For Normalized ExtraPush, we show that it naturally produces a bounded, linearly convergent sequence provided that the objective function is strongly convex. In our numerical experiments, ExtraPush and Normalized ExtraPush performed similarly well. They are significantly faster than subgradient-push, even when we hand-optimize the step sizes for the latter.




 This study considers the control of parent-child systems where a parent system is acted on by a set of controllable child systems (i.e. a swarm). Examples of such systems include a swarm of robots pushing an object over a surface, a swarm of aerial vehicles carrying a large load, or a set of end effectors manipulating an object. In this paper, a general approach for decoupling the swarm from the parent system through a low-dimensional abstract state space is presented. The requirements of this approach are given along with how constraints on both systems propagate through the abstract state and impact the requirements of the controllers for both systems. To demonstrate, several controllers with hard state constraints are designed to track a given desired angle trajectory of a tilting plane with a swarm of robots driving on top. Both homogeneous and heterogeneous swarms of varying sizes and properties are considered to test the robustness of this architecture. The controllers are shown to be locally asymptotically stable and are demonstrated in simulation.
This study considers the control of parent-child systems where a parent system is acted on by a set of controllable child systems (i.e. a swarm). Examples of such systems include a swarm of robots pushing an object over a surface, a swarm of aerial vehicles carrying a large load, or a set of end effectors manipulating an object. In this paper, a general approach for decoupling the swarm from the parent system through a low-dimensional abstract state space is presented. The requirements of this approach are given along with how constraints on both systems propagate through the abstract state and impact the requirements of the controllers for both systems. To demonstrate, several controllers with hard state constraints are designed to track a given desired angle trajectory of a tilting plane with a swarm of robots driving on top. Both homogeneous and heterogeneous swarms of varying sizes and properties are considered to test the robustness of this architecture. The controllers are shown to be locally asymptotically stable and are demonstrated in simulation.




 Characterizing human values is a topic deeply interwoven with the sciences, humanities, art, and many other human endeavors. In recent years, a number of thinkers have argued that accelerating trends in computer science, cognitive science, and related disciplines foreshadow the creation of intelligent machines which meet and ultimately surpass the cognitive abilities of human beings, thereby entangling an understanding of human values with future technological development. Contemporary research accomplishments suggest sophisticated AI systems becoming widespread and responsible for managing many aspects of the modern world, from preemptively planning users' travel schedules and logistics, to fully autonomous vehicles, to domestic robots assisting in daily living. The extrapolation of these trends has been most forcefully described in the context of a hypothetical "intelligence explosion," in which the capabilities of an intelligent software agent would rapidly increase due to the presence of feedback loops unavailable to biological organisms. The possibility of superintelligent agents, or simply the widespread deployment of sophisticated, autonomous AI systems, highlights an important theoretical problem: the need to separate the cognitive and rational capacities of an agent from the fundamental goal structure, or value system, which constrains and guides the agent's actions. The "value alignment problem" is to specify a goal structure for autonomous agents compatible with human values. In this brief article, we suggest that recent ideas from affective neuroscience and related disciplines aimed at characterizing neurological and behavioral universals in the mammalian class provide important conceptual foundations relevant to describing human values. We argue that the notion of "mammalian value systems" points to a potential avenue for fundamental research in AI safety and AI ethics.
Characterizing human values is a topic deeply interwoven with the sciences, humanities, art, and many other human endeavors. In recent years, a number of thinkers have argued that accelerating trends in computer science, cognitive science, and related disciplines foreshadow the creation of intelligent machines which meet and ultimately surpass the cognitive abilities of human beings, thereby entangling an understanding of human values with future technological development. Contemporary research accomplishments suggest sophisticated AI systems becoming widespread and responsible for managing many aspects of the modern world, from preemptively planning users' travel schedules and logistics, to fully autonomous vehicles, to domestic robots assisting in daily living. The extrapolation of these trends has been most forcefully described in the context of a hypothetical "intelligence explosion," in which the capabilities of an intelligent software agent would rapidly increase due to the presence of feedback loops unavailable to biological organisms. The possibility of superintelligent agents, or simply the widespread deployment of sophisticated, autonomous AI systems, highlights an important theoretical problem: the need to separate the cognitive and rational capacities of an agent from the fundamental goal structure, or value system, which constrains and guides the agent's actions. The "value alignment problem" is to specify a goal structure for autonomous agents compatible with human values. In this brief article, we suggest that recent ideas from affective neuroscience and related disciplines aimed at characterizing neurological and behavioral universals in the mammalian class provide important conceptual foundations relevant to describing human values. We argue that the notion of "mammalian value systems" points to a potential avenue for fundamental research in AI safety and AI ethics.



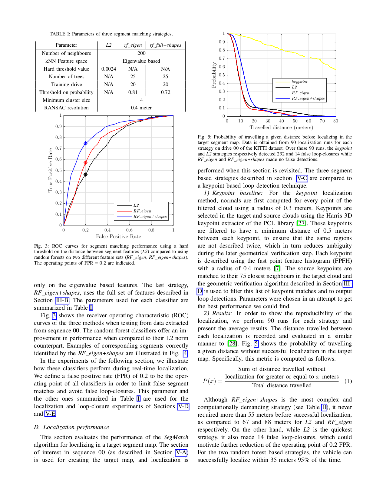
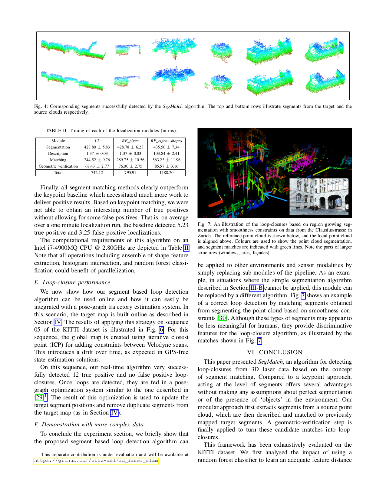 Loop-closure detection on 3D data is a challenging task that has been commonly approached by adapting image-based solutions. Methods based on local features suffer from ambiguity and from robustness to environment changes while methods based on global features are viewpoint dependent. We propose SegMatch, a reliable loop-closure detection algorithm based on the matching of 3D segments. Segments provide a good compromise between local and global descriptions, incorporating their strengths while reducing their individual drawbacks. SegMatch does not rely on assumptions of "perfect segmentation", or on the existence of "objects" in the environment, which allows for reliable execution on large scale, unstructured environments. We quantitatively demonstrate that SegMatch can achieve accurate localization at a frequency of 1Hz on the largest sequence of the KITTI odometry dataset. We furthermore show how this algorithm can reliably detect and close loops in real-time, during online operation. In addition, the source code for the SegMatch algorithm will be made available after publication.
Loop-closure detection on 3D data is a challenging task that has been commonly approached by adapting image-based solutions. Methods based on local features suffer from ambiguity and from robustness to environment changes while methods based on global features are viewpoint dependent. We propose SegMatch, a reliable loop-closure detection algorithm based on the matching of 3D segments. Segments provide a good compromise between local and global descriptions, incorporating their strengths while reducing their individual drawbacks. SegMatch does not rely on assumptions of "perfect segmentation", or on the existence of "objects" in the environment, which allows for reliable execution on large scale, unstructured environments. We quantitatively demonstrate that SegMatch can achieve accurate localization at a frequency of 1Hz on the largest sequence of the KITTI odometry dataset. We furthermore show how this algorithm can reliably detect and close loops in real-time, during online operation. In addition, the source code for the SegMatch algorithm will be made available after publication.



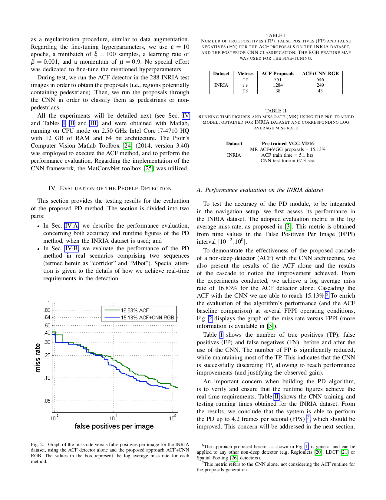
 This paper addresses the problem of Human-Aware Navigation (HAN), using multi camera sensors to implement a vision-based person tracking system. The main contributions of this paper are as follows: a novel and efficient Deep Learning person detection and a standardization of human-aware constraints. In the first stage of the approach, we propose to cascade the Aggregate Channel Features (ACF) detector with a deep Convolutional Neural Network (CNN) to achieve fast and accurate Pedestrian Detection (PD). Regarding the human awareness (that can be defined as constraints associated with the robot's motion), we use a mixture of asymmetric Gaussian functions, to define the cost functions associated to each constraint. Both methods proposed herein are evaluated individually to measure the impact of each of the components. The final solution (including both the proposed pedestrian detection and the human-aware constraints) is tested in a typical domestic indoor scenario, in four distinct experiments. The results show that the robot is able to cope with human-aware constraints, defined after common proxemics and social rules.
This paper addresses the problem of Human-Aware Navigation (HAN), using multi camera sensors to implement a vision-based person tracking system. The main contributions of this paper are as follows: a novel and efficient Deep Learning person detection and a standardization of human-aware constraints. In the first stage of the approach, we propose to cascade the Aggregate Channel Features (ACF) detector with a deep Convolutional Neural Network (CNN) to achieve fast and accurate Pedestrian Detection (PD). Regarding the human awareness (that can be defined as constraints associated with the robot's motion), we use a mixture of asymmetric Gaussian functions, to define the cost functions associated to each constraint. Both methods proposed herein are evaluated individually to measure the impact of each of the components. The final solution (including both the proposed pedestrian detection and the human-aware constraints) is tested in a typical domestic indoor scenario, in four distinct experiments. The results show that the robot is able to cope with human-aware constraints, defined after common proxemics and social rules.