-
Future wireless systems are expected to provide a wide range of services to
more and more users. Advanced scheduling strategies thus arise not only to
perform efficient radio resource management, but also to provide fairness among
the users. On the other hand, the users' perceived quality, i.e., Quality of
Experience (QoE), is becoming one of the main drivers within the schedulers
design. In this context, this paper starts by providing a comprehension of what
is QoE and an overview of the evolution of wireless scheduling techniques.
Afterwards, a survey on the most recent QoE-based scheduling strategies for
wireless systems is presented, highlighting the application/service of the
different approaches reported in the literature, as well as the parameters that
were taken into account for QoE optimization. Therefore, this paper aims at
helping readers interested in learning the basic concepts of QoE-oriented
wireless resources scheduling, as well as getting in touch with its current
research frontier.
-
The availability of labeled image datasets has been shown critical for
high-level image understanding, which continuously drives the progress of
feature designing and models developing. However, constructing labeled image
datasets is laborious and monotonous. To eliminate manual annotation, in this
work, we propose a novel image dataset construction framework by employing
multiple textual queries. We aim at collecting diverse and accurate images for
given queries from the Web. Specifically, we formulate noisy textual queries
removing and noisy images filtering as a multi-view and multi-instance learning
problem separately. Our proposed approach not only improves the accuracy but
also enhances the diversity of the selected images. To verify the effectiveness
of our proposed approach, we construct an image dataset with 100 categories.
The experiments show significant performance gains by using the generated data
of our approach on several tasks, such as image classification, cross-dataset
generalization, and object detection. The proposed method also consistently
outperforms existing weakly supervised and web-supervised approaches.
-
Modern popular TV series often develop complex storylines spanning several
seasons, but are usually watched in quite a discontinuous way. As a result, the
viewer generally needs a comprehensive summary of the previous season plot
before the new one starts. The generation of such summaries requires first to
identify and characterize the dynamics of the series subplots. One way of doing
so is to study the underlying social network of interactions between the
characters involved in the narrative. The standard tools used in the Social
Networks Analysis field to extract such a network rely on an integration of
time, either over the whole considered period, or as a sequence of several
time-slices. However, they turn out to be inappropriate in the case of TV
series, due to the fact the scenes showed onscreen alternatively focus on
parallel storylines, and do not necessarily respect a traditional chronology.
This makes existing extraction methods inefficient to describe the dynamics of
relationships between characters, or to get a relevant instantaneous view of
the current social state in the plot. This is especially true for characters
shown as interacting with each other at some previous point in the plot but
temporarily neglected by the narrative. In this article, we introduce narrative
smoothing, a novel, still exploratory, network extraction method. It smooths
the relationship dynamics based on the plot properties, aiming at solving some
of the limitations present in the standard approaches. In order to assess our
method, we apply it to a new corpus of 3 popular TV series, and compare it to
both standard approaches. Our results are promising, showing narrative
smoothing leads to more relevant observations when it comes to the
characterization of the protagonists and their relationships. It could be used
as a basis for further modeling the intertwined storylines constituting TV
series plots.
-
In this paper, a novel strategy of Secure Steganograpy based on Generative
Adversarial Networks is proposed to generate suitable and secure covers for
steganography. The proposed architecture has one generative network, and two
discriminative networks. The generative network mainly evaluates the visual
quality of the generated images for steganography, and the discriminative
networks are utilized to assess their suitableness for information hiding.
Different from the existing work which adopts Deep Convolutional Generative
Adversarial Networks, we utilize another form of generative adversarial
networks. By using this new form of generative adversarial networks,
significant improvements are made on the convergence speed, the training
stability and the image quality. Furthermore, a sophisticated steganalysis
network is reconstructed for the discriminative network, and the network can
better evaluate the performance of the generated images. Numerous experiments
are conducted on the publicly available datasets to demonstrate the
effectiveness and robustness of the proposed method.
-
Analyzing videos of human actions involves understanding the temporal
relationships among video frames. State-of-the-art action recognition
approaches rely on traditional optical flow estimation methods to pre-compute
motion information for CNNs. Such a two-stage approach is computationally
expensive, storage demanding, and not end-to-end trainable. In this paper, we
present a novel CNN architecture that implicitly captures motion information
between adjacent frames. We name our approach hidden two-stream CNNs because it
only takes raw video frames as input and directly predicts action classes
without explicitly computing optical flow. Our end-to-end approach is 10x
faster than its two-stage baseline. Experimental results on four challenging
action recognition datasets: UCF101, HMDB51, THUMOS14 and ActivityNet v1.2 show
that our approach significantly outperforms the previous best real-time
approaches.
-
In image compression, classical block-based separable transforms tend to be
inefficient when image blocks contain arbitrarily shaped discontinuities. For
this reason, transforms incorporating directional information are an appealing
alternative. In this paper, we propose a new approach to this problem, namely a
discrete cosine transform (DCT) that can be steered in any chosen direction.
Such transform, called steerable DCT (SDCT), allows to rotate in a flexible way
pairs of basis vectors, and enables precise matching of directionality in each
image block, achieving improved coding efficiency. The optimal rotation angles
for SDCT can be represented as solution of a suitable rate-distortion (RD)
problem. We propose iterative methods to search such solution, and we develop a
fully fledged image encoder to practically compare our techniques with other
competing transforms. Analytical and numerical results prove that SDCT
outperforms both DCT and state-of-the-art directional transforms.
-
Development of digital content has increased the necessity of copyright
protection by means of watermarking. Imperceptibility and robustness are two
important features of watermarking algorithms. The goal of watermarking methods
is to satisfy the tradeoff between these two contradicting characteristics.
Recently watermarking methods in transform domains have displayed favorable
results. In this paper, we present an adaptive blind watermarking method which
has high transparency in areas that are important to human visual system. We
propose a fuzzy system for adaptive control of the embedding strength factor.
Features such as saliency, intensity, and edge-concentration, are used as fuzzy
attributes. Redundant embedding in discrete cosine transform (DCT) of wavelet
domain has increased the robustness of our method. Experimental results show
the efficiency of the proposed method and better results are obtained as
compared to comparable methods with same size of watermark logo.
-
Recent advances in next-generation sequencing technologies have facilitated
the use of deoxyribonucleic acid (DNA) as a novel covert channels in
steganography. There are various methods that exist in other domains to detect
hidden messages in conventional covert channels. However, they have not been
applied to DNA steganography. The current most common detection approaches,
namely frequency analysis-based methods, often overlook important signals when
directly applied to DNA steganography because those methods depend on the
distribution of the number of sequence characters. To address this limitation,
we propose a general sequence learning-based DNA steganalysis framework. The
proposed approach learns the intrinsic distribution of coding and non-coding
sequences and detects hidden messages by exploiting distribution variations
after hiding these messages. Using deep recurrent neural networks (RNNs), our
framework identifies the distribution variations by using the classification
score to predict whether a sequence is to be a coding or non-coding sequence.
We compare our proposed method to various existing methods and biological
sequence analysis methods implemented on top of our framework. According to our
experimental results, our approach delivers a robust detection performance
compared to other tools.
-
Most of previous machine learning algorithms are proposed based on the i.i.d.
hypothesis. However, this ideal assumption is often violated in real
applications, where selection bias may arise between training and testing
process. Moreover, in many scenarios, the testing data is not even available
during the training process, which makes the traditional methods like transfer
learning infeasible due to their need on prior of test distribution. Therefore,
how to address the agnostic selection bias for robust model learning is of
paramount importance for both academic research and real applications. In this
paper, under the assumption that causal relationships among variables are
robust across domains, we incorporate causal technique into predictive modeling
and propose a novel Causally Regularized Logistic Regression (CRLR) algorithm
by jointly optimize global confounder balancing and weighted logistic
regression. Global confounder balancing helps to identify causal features,
whose causal effect on outcome are stable across domains, then performing
logistic regression on those causal features constructs a robust predictive
model against the agnostic bias. To validate the effectiveness of our CRLR
algorithm, we conduct comprehensive experiments on both synthetic and real
world datasets. Experimental results clearly demonstrate that our CRLR
algorithm outperforms the state-of-the-art methods, and the interpretability of
our method can be fully depicted by the feature visualization.
-
The two-terminal key agreement problem with biometric or physical identifiers
is considered. Two linear code constructions based on Wyner-Ziv coding are
developed. The first construction uses random linear codes and achieves all
points of the key-leakage-storage regions of the generated-secret and
chosen-secret models. The second construction uses nested polar codes for
vector quantization during enrollment and for error correction during
reconstruction. Simulations show that the nested polar codes achieve
privacy-leakage and storage rates that improve on existing code designs. One
proposed code achieves a rate tuple that cannot be achieved by existing
methods.
-
We introduce a dataset for facilitating audio-visual analysis of music
performances. The dataset comprises 44 simple multi-instrument classical music
pieces assembled from coordinated but separately recorded performances of
individual tracks. For each piece, we provide the musical score in MIDI format,
the audio recordings of the individual tracks, the audio and video recording of
the assembled mixture, and ground-truth annotation files including frame-level
and note-level transcriptions. We describe our methodology for the creation of
the dataset, particularly highlighting our approaches for addressing the
challenges involved in maintaining synchronization and expressiveness. We
demonstrate the high quality of synchronization achieved with our proposed
approach by comparing the dataset with existing widely-used music audio
datasets.
We anticipate that the dataset will be useful for the development and
evaluation of existing music information retrieval (MIR) tasks, as well as for
novel multi-modal tasks. We benchmark two existing MIR tasks (multi-pitch
analysis and score-informed source separation) on the dataset and compare with
other existing music audio datasets. Additionally, we consider two novel
multi-modal MIR tasks (visually informed multi-pitch analysis and polyphonic
vibrato analysis) enabled by the dataset and provide evaluation measures and
baseline systems for future comparisons (from our recent work). Finally, we
propose several emerging research directions that the dataset enables.
-
The latest High Efficiency Video Coding (HEVC) standard has been increasingly
applied to generate video streams over the Internet. However, HEVC compressed
videos may incur severe quality degradation, particularly at low bit-rates.
Thus, it is necessary to enhance the visual quality of HEVC videos at the
decoder side. To this end, this paper proposes a Quality Enhancement
Convolutional Neural Network (QE-CNN) method that does not require any
modification of the encoder to achieve quality enhancement for HEVC. In
particular, our QE-CNN method learns QE-CNN-I and QE-CNN-P models to reduce the
distortion of HEVC I and P frames, respectively. The proposed method differs
from the existing CNN-based quality enhancement approaches, which only handle
intra-coding distortion and are thus not suitable for P frames. Our
experimental results validate that our QE-CNN method is effective in enhancing
quality for both I and P frames of HEVC videos. To apply our QE-CNN method in
time-constrained scenarios, we further propose a Time-constrained Quality
Enhancement Optimization (TQEO) scheme. Our TQEO scheme controls the
computational time of QE-CNN to meet a target, meanwhile maximizing the quality
enhancement. Next, the experimental results demonstrate the effectiveness of
our TQEO scheme from the aspects of time control accuracy and quality
enhancement under different time constraints. Finally, we design a prototype to
implement our TQEO scheme in a real-time scenario.
-
Mp3 is a very popular audio format and hence it can be a good host for
carrying hidden messages. Therefore, different steganography methods have been
proposed for mp3 hosts. But, current literature has only focused on
steganalysis of mp3stego. In this paper we mention some of the limitations of
mp3stego and argue that UnderMp3Cover (Ump3c) does not have those limitations.
Ump3c makes subtle changes only to the global gain of bitstream and keeps the
rest of bitstream intact. Therefore, its detection is much harder than
mp3stego. To address this, joint distributions between global gain and other
fields of mp3 bit stream are used. The changes are detected by measuring the
mutual information from those joint distributions. Furthermore, we show that
different mp3 encoders have dissimilar performances. Consequently, a novel
multi-layer architecture for steganalysis of Ump3c is proposed. In this manner,
the first layer detects the encoder and the second layer performs the
steganalysis job. One of advantages of this architecture is that feature
extraction and feature selection can be optimized for each encoder separately.
We show this multi-layer architecture outperforms the conventional single-layer
methods. Comparing results of the proposed method with other works shows an
improvement of 20.4% in the accuracy of steganalysis.
-
Real world multimedia data is often composed of multiple modalities such as
an image or a video with associated text (e.g. captions, user comments, etc.)
and metadata. Such multimodal data packages are prone to manipulations, where a
subset of these modalities can be altered to misrepresent or repurpose data
packages, with possible malicious intent. It is, therefore, important to
develop methods to assess or verify the integrity of these multimedia packages.
Using computer vision and natural language processing methods to directly
compare the image (or video) and the associated caption to verify the integrity
of a media package is only possible for a limited set of objects and scenes. In
this paper, we present a novel deep learning-based approach for assessing the
semantic integrity of multimedia packages containing images and captions, using
a reference set of multimedia packages. We construct a joint embedding of
images and captions with deep multimodal representation learning on the
reference dataset in a framework that also provides image-caption consistency
scores (ICCSs). The integrity of query media packages is assessed as the
inlierness of the query ICCSs with respect to the reference dataset. We present
the MultimodAl Information Manipulation dataset (MAIM), a new dataset of media
packages from Flickr, which we make available to the research community. We use
both the newly created dataset as well as Flickr30K and MS COCO datasets to
quantitatively evaluate our proposed approach. The reference dataset does not
contain unmanipulated versions of tampered query packages. Our method is able
to achieve F1 scores of 0.75, 0.89 and 0.94 on MAIM, Flickr30K and MS COCO,
respectively, for detecting semantically incoherent media packages.
-
The demand for global video has been burgeoning across industries. With the
expansion and improvement of video-streaming services, cloud-based video is
evolving into a necessary feature of any successful business for reaching
internal and external audiences. This paper considers video streaming over
distributed systems where the video segments are encoded using an erasure code
for better reliability thus being the first work to our best knowledge that
considers video streaming over erasure-coded distributed cloud systems. The
download time of each coded chunk of each video segment is characterized and
ordered statistics over the choice of the erasure-coded chunks is used to
obtain the playback time of different video segments. Using the playback times,
bounds on the moment generating function on the stall duration is used to bound
the mean stall duration. Moment generating function based bounds on the ordered
statistics are also used to bound the stall duration tail probability which
determines the probability that the stall time is greater than a pre-defined
number. These two metrics, mean stall duration and the stall duration tail
probability, are important quality of experience (QoE) measures for the end
users. Based on these metrics, we formulate an optimization problem to jointly
minimize the convex combination of both the QoE metrics averaged over all
requests over the placement and access of the video content. The non-convex
problem is solved using an efficient iterative algorithm. Numerical results
show significant improvement in QoE metrics for cloud-based video as compared
to the considered baselines.
-
With the aim of developing a fast yet accurate algorithm for compressive
sensing (CS) reconstruction of natural images, we combine in this paper the
merits of two existing categories of CS methods: the structure insights of
traditional optimization-based methods and the speed of recent network-based
ones. Specifically, we propose a novel structured deep network, dubbed
ISTA-Net, which is inspired by the Iterative Shrinkage-Thresholding Algorithm
(ISTA) for optimizing a general $\ell_1$ norm CS reconstruction model. To cast
ISTA into deep network form, we develop an effective strategy to solve the
proximal mapping associated with the sparsity-inducing regularizer using
nonlinear transforms. All the parameters in ISTA-Net (\eg nonlinear transforms,
shrinkage thresholds, step sizes, etc.) are learned end-to-end, rather than
being hand-crafted. Moreover, considering that the residuals of natural images
are more compressible, an enhanced version of ISTA-Net in the residual domain,
dubbed {ISTA-Net}$^+$, is derived to further improve CS reconstruction.
Extensive CS experiments demonstrate that the proposed ISTA-Nets outperform
existing state-of-the-art optimization-based and network-based CS methods by
large margins, while maintaining fast computational speed. Our source codes are
available: \textsl{http://jianzhang.tech/projects/ISTA-Net}.
-
This paper introduces a novel weighted unsupervised learning for object
detection using an RGB-D camera. This technique is feasible for detecting the
moving objects in the noisy environments that are captured by an RGB-D camera.
The main contribution of this paper is a real-time algorithm for detecting each
object using weighted clustering as a separate cluster. In a preprocessing
step, the algorithm calculates the pose 3D position X, Y, Z and RGB color of
each data point and then it calculates each data point's normal vector using
the point's neighbor. After preprocessing, our algorithm calculates k-weights
for each data point; each weight indicates membership. Resulting in clustered
objects of the scene.
-
In this paper, a new framework for construction of Cardan grille for
information hiding is proposed. Based on the semantic image inpainting
technique, the stego image are driven by secret messages directly. A mask
called Digital Cardan Grille (DCG) for determining the hidden location is
introduced to hide the message. The message is written to the corrupted region
that needs to be filled in the corrupted image in advance. Then the corrupted
image with secret message is feeded into a Generative Adversarial Network (GAN)
for semantic completion. The adversarial game not only reconstruct the
corrupted image , but also generate a stego image which contains the logic
rationality of image content. The experimental results verify the feasibility
of the proposed method.
-
In this paper, we propose a partition-masked Convolution Neural Network (CNN)
to achieve compressed-video enhancement for the state-of-the-art coding
standard, High Efficiency Video Coding (HECV). More precisely, our method
utilizes the partition information produced by the encoder to guide the quality
enhancement process. In contrast to existing CNN-based approaches, which only
take the decoded frame as the input to the CNN, the proposed approach considers
the coding unit (CU) size information and combines it with the distorted
decoded frame such that the degradation introduced by HEVC is reduced more
efficiently. Experimental results show that our approach leads to over 9.76%
BD-rate saving on benchmark sequences, which achieves the state-of-the-art
performance.
-
Computation capabilities of recent mobile devices enable natural feature
processing for Augmented Reality (AR). However, mobile AR applications are
still faced with scalability and performance challenges. In this paper, we
propose CloudAR, a mobile AR framework utilizing the advantages of cloud and
edge computing through recognition task offloading. We explore the design space
of cloud-based AR exhaustively and optimize the offloading pipeline to minimize
the time and energy consumption. We design an innovative tracking system for
mobile devices which provides lightweight tracking in 6 degree of freedom
(6DoF) and hides the offloading latency from users' perception. We also design
a multi-object image retrieval pipeline that executes fast and accurate image
recognition tasks on servers. In our evaluations, the mobile AR application
built with the CloudAR framework runs at 30 frames per second (FPS) on average
with precise tracking of only 1~2 pixel errors and image recognition of at
least 97% accuracy. Our results also show that CloudAR outperforms one of the
leading commercial AR framework in several performance metrics.
-
The optimization of occlusion-inducing depth pixels in depth map coding has
received little attention in the literature, since their associated texture
pixels are occluded in the synthesized view and their effect on the synthesized
view is considered negligible. However, the occlusion-inducing depth pixels
still need to consume the bits to be transmitted, and will induce geometry
distortion that inherently exists in the synthesized view. In this paper, we
propose an efficient depth map coding scheme specifically for the
occlusion-inducing depth pixels by using allowable depth distortions. Firstly,
we formulate a problem of minimizing the overall geometry distortion in the
occlusion subject to the bit rate constraint, for which the depth distortion is
properly adjusted within the set of allowable depth distortions that introduce
the same disparity error as the initial depth distortion. Then, we propose a
dynamic programming solution to find the optimal depth distortion vector for
the occlusion. The proposed algorithm can improve the coding efficiency without
alteration of the occlusion order. Simulation results confirm the performance
improvement compared to other existing algorithms.
-
Tensor completion recovers missing entries of multiway data. Teh missing of
entries could often be caused during teh data acquisition and transformation.
In dis paper, we provide an overview of recent development in low rank tensor
completion for estimating teh missing components of visual data, e. g. , color
images and videos. First, we categorize these methods into two groups based on
teh different optimization models. One optimizes factors of tensor
decompositions wif predefined tensor rank. Teh other iteratively updates teh
estimated tensor via minimizing teh tensor rank. Besides, we summarize teh
corresponding algorithms to solve those optimization problems in details.
Numerical experiments are given to demonstrate teh performance comparison when
different methods are applied to color image and video processing.
-
Multimodal machine translation is one of the applications that integrates
computer vision and language processing. It is a unique task given that in the
field of machine translation, many state-of-the-arts algorithms still only
employ textual information. In this work, we explore the effectiveness of
reinforcement learning in multimodal machine translation. We present a novel
algorithm based on the Advantage Actor-Critic (A2C) algorithm that specifically
cater to the multimodal machine translation task of the EMNLP 2018 Third
Conference on Machine Translation (WMT18). We experiment our proposed algorithm
on the Multi30K multilingual English-German image description dataset and the
Flickr30K image entity dataset. Our model takes two channels of inputs, image
and text, uses translation evaluation metrics as training rewards, and achieves
better results than supervised learning MLE baseline models. Furthermore, we
discuss the prospects and limitations of using reinforcement learning for
machine translation. Our experiment results suggest a promising reinforcement
learning solution to the general task of multimodal sequence to sequence
learning.
-
This paper presents an after-the-fact summary of the participation of the
vitrivr system to the 2018 Video Browser Showdown. A particular focus is on
additions made since the original publication and the systems performance
during the competition.
-
Real-time video streaming is now one of the main applications in all network
environments. Due to the fluctuation of throughput under various network
conditions, how to choose a proper bitrate adaptively has become an upcoming
and interestingly issue. To tackle this problem, most adaptive bitrate control
methods have been proposed to provide high video bitrates instead of video
qualities. Nevertheless, we notice that there exists a trade-off between
sending bitrate and video quality, which motivates us to focus on how to get a
balance between them. In this paper, we propose QARC (video Quality Awareness
Rate Control), a rate control algorithm that aims to have a higher perceptual
video quality with possibly lower sending rate and transmission latency.
Starting from scratch, QARC uses deep reinforcement learning(DRL) algorithm to
train a neural network to select future bitrates based on previously observed
network status and past video frames. To overcome the "state explosion
problem", we design a neural network to predict future perceptual video quality
as a vector for taking the place of the raw picture in the DRL's inputs. We
evaluate QARC over a trace-driven emulation, outperforming existing approach
with improvements in average video quality of 18\% - 25\% and decreases in
average latency with 23% -45%. Meanwhile, Comparing QARC with offline optimal
high bitrate method on various network conditions also yields a solid result.





 Future wireless systems are expected to provide a wide range of services to more and more users. Advanced scheduling strategies thus arise not only to perform efficient radio resource management, but also to provide fairness among the users. On the other hand, the users' perceived quality, i.e., Quality of Experience (QoE), is becoming one of the main drivers within the schedulers design. In this context, this paper starts by providing a comprehension of what is QoE and an overview of the evolution of wireless scheduling techniques. Afterwards, a survey on the most recent QoE-based scheduling strategies for wireless systems is presented, highlighting the application/service of the different approaches reported in the literature, as well as the parameters that were taken into account for QoE optimization. Therefore, this paper aims at helping readers interested in learning the basic concepts of QoE-oriented wireless resources scheduling, as well as getting in touch with its current research frontier.
Future wireless systems are expected to provide a wide range of services to more and more users. Advanced scheduling strategies thus arise not only to perform efficient radio resource management, but also to provide fairness among the users. On the other hand, the users' perceived quality, i.e., Quality of Experience (QoE), is becoming one of the main drivers within the schedulers design. In this context, this paper starts by providing a comprehension of what is QoE and an overview of the evolution of wireless scheduling techniques. Afterwards, a survey on the most recent QoE-based scheduling strategies for wireless systems is presented, highlighting the application/service of the different approaches reported in the literature, as well as the parameters that were taken into account for QoE optimization. Therefore, this paper aims at helping readers interested in learning the basic concepts of QoE-oriented wireless resources scheduling, as well as getting in touch with its current research frontier.




 The availability of labeled image datasets has been shown critical for high-level image understanding, which continuously drives the progress of feature designing and models developing. However, constructing labeled image datasets is laborious and monotonous. To eliminate manual annotation, in this work, we propose a novel image dataset construction framework by employing multiple textual queries. We aim at collecting diverse and accurate images for given queries from the Web. Specifically, we formulate noisy textual queries removing and noisy images filtering as a multi-view and multi-instance learning problem separately. Our proposed approach not only improves the accuracy but also enhances the diversity of the selected images. To verify the effectiveness of our proposed approach, we construct an image dataset with 100 categories. The experiments show significant performance gains by using the generated data of our approach on several tasks, such as image classification, cross-dataset generalization, and object detection. The proposed method also consistently outperforms existing weakly supervised and web-supervised approaches.
The availability of labeled image datasets has been shown critical for high-level image understanding, which continuously drives the progress of feature designing and models developing. However, constructing labeled image datasets is laborious and monotonous. To eliminate manual annotation, in this work, we propose a novel image dataset construction framework by employing multiple textual queries. We aim at collecting diverse and accurate images for given queries from the Web. Specifically, we formulate noisy textual queries removing and noisy images filtering as a multi-view and multi-instance learning problem separately. Our proposed approach not only improves the accuracy but also enhances the diversity of the selected images. To verify the effectiveness of our proposed approach, we construct an image dataset with 100 categories. The experiments show significant performance gains by using the generated data of our approach on several tasks, such as image classification, cross-dataset generalization, and object detection. The proposed method also consistently outperforms existing weakly supervised and web-supervised approaches.




 Modern popular TV series often develop complex storylines spanning several seasons, but are usually watched in quite a discontinuous way. As a result, the viewer generally needs a comprehensive summary of the previous season plot before the new one starts. The generation of such summaries requires first to identify and characterize the dynamics of the series subplots. One way of doing so is to study the underlying social network of interactions between the characters involved in the narrative. The standard tools used in the Social Networks Analysis field to extract such a network rely on an integration of time, either over the whole considered period, or as a sequence of several time-slices. However, they turn out to be inappropriate in the case of TV series, due to the fact the scenes showed onscreen alternatively focus on parallel storylines, and do not necessarily respect a traditional chronology. This makes existing extraction methods inefficient to describe the dynamics of relationships between characters, or to get a relevant instantaneous view of the current social state in the plot. This is especially true for characters shown as interacting with each other at some previous point in the plot but temporarily neglected by the narrative. In this article, we introduce narrative smoothing, a novel, still exploratory, network extraction method. It smooths the relationship dynamics based on the plot properties, aiming at solving some of the limitations present in the standard approaches. In order to assess our method, we apply it to a new corpus of 3 popular TV series, and compare it to both standard approaches. Our results are promising, showing narrative smoothing leads to more relevant observations when it comes to the characterization of the protagonists and their relationships. It could be used as a basis for further modeling the intertwined storylines constituting TV series plots.
Modern popular TV series often develop complex storylines spanning several seasons, but are usually watched in quite a discontinuous way. As a result, the viewer generally needs a comprehensive summary of the previous season plot before the new one starts. The generation of such summaries requires first to identify and characterize the dynamics of the series subplots. One way of doing so is to study the underlying social network of interactions between the characters involved in the narrative. The standard tools used in the Social Networks Analysis field to extract such a network rely on an integration of time, either over the whole considered period, or as a sequence of several time-slices. However, they turn out to be inappropriate in the case of TV series, due to the fact the scenes showed onscreen alternatively focus on parallel storylines, and do not necessarily respect a traditional chronology. This makes existing extraction methods inefficient to describe the dynamics of relationships between characters, or to get a relevant instantaneous view of the current social state in the plot. This is especially true for characters shown as interacting with each other at some previous point in the plot but temporarily neglected by the narrative. In this article, we introduce narrative smoothing, a novel, still exploratory, network extraction method. It smooths the relationship dynamics based on the plot properties, aiming at solving some of the limitations present in the standard approaches. In order to assess our method, we apply it to a new corpus of 3 popular TV series, and compare it to both standard approaches. Our results are promising, showing narrative smoothing leads to more relevant observations when it comes to the characterization of the protagonists and their relationships. It could be used as a basis for further modeling the intertwined storylines constituting TV series plots.




 Analyzing videos of human actions involves understanding the temporal relationships among video frames. State-of-the-art action recognition approaches rely on traditional optical flow estimation methods to pre-compute motion information for CNNs. Such a two-stage approach is computationally expensive, storage demanding, and not end-to-end trainable. In this paper, we present a novel CNN architecture that implicitly captures motion information between adjacent frames. We name our approach hidden two-stream CNNs because it only takes raw video frames as input and directly predicts action classes without explicitly computing optical flow. Our end-to-end approach is 10x faster than its two-stage baseline. Experimental results on four challenging action recognition datasets: UCF101, HMDB51, THUMOS14 and ActivityNet v1.2 show that our approach significantly outperforms the previous best real-time approaches.
Analyzing videos of human actions involves understanding the temporal relationships among video frames. State-of-the-art action recognition approaches rely on traditional optical flow estimation methods to pre-compute motion information for CNNs. Such a two-stage approach is computationally expensive, storage demanding, and not end-to-end trainable. In this paper, we present a novel CNN architecture that implicitly captures motion information between adjacent frames. We name our approach hidden two-stream CNNs because it only takes raw video frames as input and directly predicts action classes without explicitly computing optical flow. Our end-to-end approach is 10x faster than its two-stage baseline. Experimental results on four challenging action recognition datasets: UCF101, HMDB51, THUMOS14 and ActivityNet v1.2 show that our approach significantly outperforms the previous best real-time approaches.




 Recent advances in next-generation sequencing technologies have facilitated the use of deoxyribonucleic acid (DNA) as a novel covert channels in steganography. There are various methods that exist in other domains to detect hidden messages in conventional covert channels. However, they have not been applied to DNA steganography. The current most common detection approaches, namely frequency analysis-based methods, often overlook important signals when directly applied to DNA steganography because those methods depend on the distribution of the number of sequence characters. To address this limitation, we propose a general sequence learning-based DNA steganalysis framework. The proposed approach learns the intrinsic distribution of coding and non-coding sequences and detects hidden messages by exploiting distribution variations after hiding these messages. Using deep recurrent neural networks (RNNs), our framework identifies the distribution variations by using the classification score to predict whether a sequence is to be a coding or non-coding sequence. We compare our proposed method to various existing methods and biological sequence analysis methods implemented on top of our framework. According to our experimental results, our approach delivers a robust detection performance compared to other tools.
Recent advances in next-generation sequencing technologies have facilitated the use of deoxyribonucleic acid (DNA) as a novel covert channels in steganography. There are various methods that exist in other domains to detect hidden messages in conventional covert channels. However, they have not been applied to DNA steganography. The current most common detection approaches, namely frequency analysis-based methods, often overlook important signals when directly applied to DNA steganography because those methods depend on the distribution of the number of sequence characters. To address this limitation, we propose a general sequence learning-based DNA steganalysis framework. The proposed approach learns the intrinsic distribution of coding and non-coding sequences and detects hidden messages by exploiting distribution variations after hiding these messages. Using deep recurrent neural networks (RNNs), our framework identifies the distribution variations by using the classification score to predict whether a sequence is to be a coding or non-coding sequence. We compare our proposed method to various existing methods and biological sequence analysis methods implemented on top of our framework. According to our experimental results, our approach delivers a robust detection performance compared to other tools.




 Most of previous machine learning algorithms are proposed based on the i.i.d. hypothesis. However, this ideal assumption is often violated in real applications, where selection bias may arise between training and testing process. Moreover, in many scenarios, the testing data is not even available during the training process, which makes the traditional methods like transfer learning infeasible due to their need on prior of test distribution. Therefore, how to address the agnostic selection bias for robust model learning is of paramount importance for both academic research and real applications. In this paper, under the assumption that causal relationships among variables are robust across domains, we incorporate causal technique into predictive modeling and propose a novel Causally Regularized Logistic Regression (CRLR) algorithm by jointly optimize global confounder balancing and weighted logistic regression. Global confounder balancing helps to identify causal features, whose causal effect on outcome are stable across domains, then performing logistic regression on those causal features constructs a robust predictive model against the agnostic bias. To validate the effectiveness of our CRLR algorithm, we conduct comprehensive experiments on both synthetic and real world datasets. Experimental results clearly demonstrate that our CRLR algorithm outperforms the state-of-the-art methods, and the interpretability of our method can be fully depicted by the feature visualization.
Most of previous machine learning algorithms are proposed based on the i.i.d. hypothesis. However, this ideal assumption is often violated in real applications, where selection bias may arise between training and testing process. Moreover, in many scenarios, the testing data is not even available during the training process, which makes the traditional methods like transfer learning infeasible due to their need on prior of test distribution. Therefore, how to address the agnostic selection bias for robust model learning is of paramount importance for both academic research and real applications. In this paper, under the assumption that causal relationships among variables are robust across domains, we incorporate causal technique into predictive modeling and propose a novel Causally Regularized Logistic Regression (CRLR) algorithm by jointly optimize global confounder balancing and weighted logistic regression. Global confounder balancing helps to identify causal features, whose causal effect on outcome are stable across domains, then performing logistic regression on those causal features constructs a robust predictive model against the agnostic bias. To validate the effectiveness of our CRLR algorithm, we conduct comprehensive experiments on both synthetic and real world datasets. Experimental results clearly demonstrate that our CRLR algorithm outperforms the state-of-the-art methods, and the interpretability of our method can be fully depicted by the feature visualization.




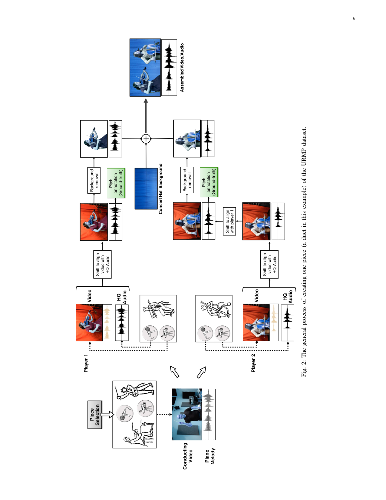 We introduce a dataset for facilitating audio-visual analysis of music performances. The dataset comprises 44 simple multi-instrument classical music pieces assembled from coordinated but separately recorded performances of individual tracks. For each piece, we provide the musical score in MIDI format, the audio recordings of the individual tracks, the audio and video recording of the assembled mixture, and ground-truth annotation files including frame-level and note-level transcriptions. We describe our methodology for the creation of the dataset, particularly highlighting our approaches for addressing the challenges involved in maintaining synchronization and expressiveness. We demonstrate the high quality of synchronization achieved with our proposed approach by comparing the dataset with existing widely-used music audio datasets. We anticipate that the dataset will be useful for the development and evaluation of existing music information retrieval (MIR) tasks, as well as for novel multi-modal tasks. We benchmark two existing MIR tasks (multi-pitch analysis and score-informed source separation) on the dataset and compare with other existing music audio datasets. Additionally, we consider two novel multi-modal MIR tasks (visually informed multi-pitch analysis and polyphonic vibrato analysis) enabled by the dataset and provide evaluation measures and baseline systems for future comparisons (from our recent work). Finally, we propose several emerging research directions that the dataset enables.
We introduce a dataset for facilitating audio-visual analysis of music performances. The dataset comprises 44 simple multi-instrument classical music pieces assembled from coordinated but separately recorded performances of individual tracks. For each piece, we provide the musical score in MIDI format, the audio recordings of the individual tracks, the audio and video recording of the assembled mixture, and ground-truth annotation files including frame-level and note-level transcriptions. We describe our methodology for the creation of the dataset, particularly highlighting our approaches for addressing the challenges involved in maintaining synchronization and expressiveness. We demonstrate the high quality of synchronization achieved with our proposed approach by comparing the dataset with existing widely-used music audio datasets. We anticipate that the dataset will be useful for the development and evaluation of existing music information retrieval (MIR) tasks, as well as for novel multi-modal tasks. We benchmark two existing MIR tasks (multi-pitch analysis and score-informed source separation) on the dataset and compare with other existing music audio datasets. Additionally, we consider two novel multi-modal MIR tasks (visually informed multi-pitch analysis and polyphonic vibrato analysis) enabled by the dataset and provide evaluation measures and baseline systems for future comparisons (from our recent work). Finally, we propose several emerging research directions that the dataset enables.
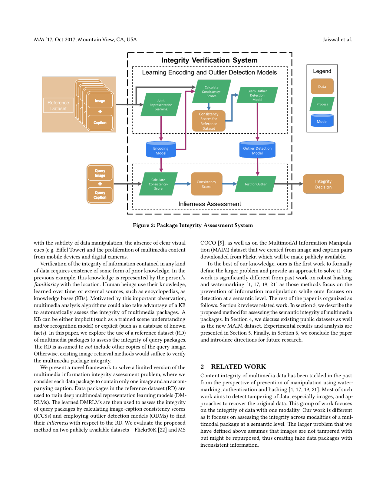



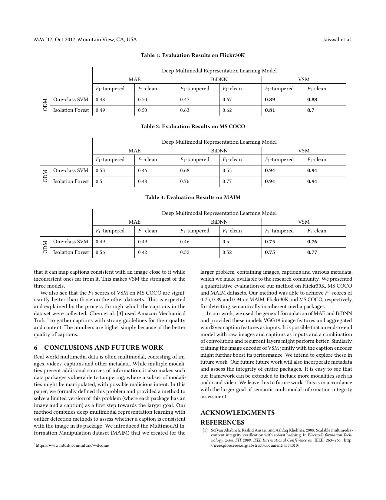 Real world multimedia data is often composed of multiple modalities such as an image or a video with associated text (e.g. captions, user comments, etc.) and metadata. Such multimodal data packages are prone to manipulations, where a subset of these modalities can be altered to misrepresent or repurpose data packages, with possible malicious intent. It is, therefore, important to develop methods to assess or verify the integrity of these multimedia packages. Using computer vision and natural language processing methods to directly compare the image (or video) and the associated caption to verify the integrity of a media package is only possible for a limited set of objects and scenes. In this paper, we present a novel deep learning-based approach for assessing the semantic integrity of multimedia packages containing images and captions, using a reference set of multimedia packages. We construct a joint embedding of images and captions with deep multimodal representation learning on the reference dataset in a framework that also provides image-caption consistency scores (ICCSs). The integrity of query media packages is assessed as the inlierness of the query ICCSs with respect to the reference dataset. We present the MultimodAl Information Manipulation dataset (MAIM), a new dataset of media packages from Flickr, which we make available to the research community. We use both the newly created dataset as well as Flickr30K and MS COCO datasets to quantitatively evaluate our proposed approach. The reference dataset does not contain unmanipulated versions of tampered query packages. Our method is able to achieve F1 scores of 0.75, 0.89 and 0.94 on MAIM, Flickr30K and MS COCO, respectively, for detecting semantically incoherent media packages.
Real world multimedia data is often composed of multiple modalities such as an image or a video with associated text (e.g. captions, user comments, etc.) and metadata. Such multimodal data packages are prone to manipulations, where a subset of these modalities can be altered to misrepresent or repurpose data packages, with possible malicious intent. It is, therefore, important to develop methods to assess or verify the integrity of these multimedia packages. Using computer vision and natural language processing methods to directly compare the image (or video) and the associated caption to verify the integrity of a media package is only possible for a limited set of objects and scenes. In this paper, we present a novel deep learning-based approach for assessing the semantic integrity of multimedia packages containing images and captions, using a reference set of multimedia packages. We construct a joint embedding of images and captions with deep multimodal representation learning on the reference dataset in a framework that also provides image-caption consistency scores (ICCSs). The integrity of query media packages is assessed as the inlierness of the query ICCSs with respect to the reference dataset. We present the MultimodAl Information Manipulation dataset (MAIM), a new dataset of media packages from Flickr, which we make available to the research community. We use both the newly created dataset as well as Flickr30K and MS COCO datasets to quantitatively evaluate our proposed approach. The reference dataset does not contain unmanipulated versions of tampered query packages. Our method is able to achieve F1 scores of 0.75, 0.89 and 0.94 on MAIM, Flickr30K and MS COCO, respectively, for detecting semantically incoherent media packages.




 The demand for global video has been burgeoning across industries. With the expansion and improvement of video-streaming services, cloud-based video is evolving into a necessary feature of any successful business for reaching internal and external audiences. This paper considers video streaming over distributed systems where the video segments are encoded using an erasure code for better reliability thus being the first work to our best knowledge that considers video streaming over erasure-coded distributed cloud systems. The download time of each coded chunk of each video segment is characterized and ordered statistics over the choice of the erasure-coded chunks is used to obtain the playback time of different video segments. Using the playback times, bounds on the moment generating function on the stall duration is used to bound the mean stall duration. Moment generating function based bounds on the ordered statistics are also used to bound the stall duration tail probability which determines the probability that the stall time is greater than a pre-defined number. These two metrics, mean stall duration and the stall duration tail probability, are important quality of experience (QoE) measures for the end users. Based on these metrics, we formulate an optimization problem to jointly minimize the convex combination of both the QoE metrics averaged over all requests over the placement and access of the video content. The non-convex problem is solved using an efficient iterative algorithm. Numerical results show significant improvement in QoE metrics for cloud-based video as compared to the considered baselines.
The demand for global video has been burgeoning across industries. With the expansion and improvement of video-streaming services, cloud-based video is evolving into a necessary feature of any successful business for reaching internal and external audiences. This paper considers video streaming over distributed systems where the video segments are encoded using an erasure code for better reliability thus being the first work to our best knowledge that considers video streaming over erasure-coded distributed cloud systems. The download time of each coded chunk of each video segment is characterized and ordered statistics over the choice of the erasure-coded chunks is used to obtain the playback time of different video segments. Using the playback times, bounds on the moment generating function on the stall duration is used to bound the mean stall duration. Moment generating function based bounds on the ordered statistics are also used to bound the stall duration tail probability which determines the probability that the stall time is greater than a pre-defined number. These two metrics, mean stall duration and the stall duration tail probability, are important quality of experience (QoE) measures for the end users. Based on these metrics, we formulate an optimization problem to jointly minimize the convex combination of both the QoE metrics averaged over all requests over the placement and access of the video content. The non-convex problem is solved using an efficient iterative algorithm. Numerical results show significant improvement in QoE metrics for cloud-based video as compared to the considered baselines.




 With the aim of developing a fast yet accurate algorithm for compressive sensing (CS) reconstruction of natural images, we combine in this paper the merits of two existing categories of CS methods: the structure insights of traditional optimization-based methods and the speed of recent network-based ones. Specifically, we propose a novel structured deep network, dubbed ISTA-Net, which is inspired by the Iterative Shrinkage-Thresholding Algorithm (ISTA) for optimizing a general $\ell_1$ norm CS reconstruction model. To cast ISTA into deep network form, we develop an effective strategy to solve the proximal mapping associated with the sparsity-inducing regularizer using nonlinear transforms. All the parameters in ISTA-Net (\eg nonlinear transforms, shrinkage thresholds, step sizes, etc.) are learned end-to-end, rather than being hand-crafted. Moreover, considering that the residuals of natural images are more compressible, an enhanced version of ISTA-Net in the residual domain, dubbed {ISTA-Net}$^+$, is derived to further improve CS reconstruction. Extensive CS experiments demonstrate that the proposed ISTA-Nets outperform existing state-of-the-art optimization-based and network-based CS methods by large margins, while maintaining fast computational speed. Our source codes are available: \textsl{http://jianzhang.tech/projects/ISTA-Net}.
With the aim of developing a fast yet accurate algorithm for compressive sensing (CS) reconstruction of natural images, we combine in this paper the merits of two existing categories of CS methods: the structure insights of traditional optimization-based methods and the speed of recent network-based ones. Specifically, we propose a novel structured deep network, dubbed ISTA-Net, which is inspired by the Iterative Shrinkage-Thresholding Algorithm (ISTA) for optimizing a general $\ell_1$ norm CS reconstruction model. To cast ISTA into deep network form, we develop an effective strategy to solve the proximal mapping associated with the sparsity-inducing regularizer using nonlinear transforms. All the parameters in ISTA-Net (\eg nonlinear transforms, shrinkage thresholds, step sizes, etc.) are learned end-to-end, rather than being hand-crafted. Moreover, considering that the residuals of natural images are more compressible, an enhanced version of ISTA-Net in the residual domain, dubbed {ISTA-Net}$^+$, is derived to further improve CS reconstruction. Extensive CS experiments demonstrate that the proposed ISTA-Nets outperform existing state-of-the-art optimization-based and network-based CS methods by large margins, while maintaining fast computational speed. Our source codes are available: \textsl{http://jianzhang.tech/projects/ISTA-Net}.

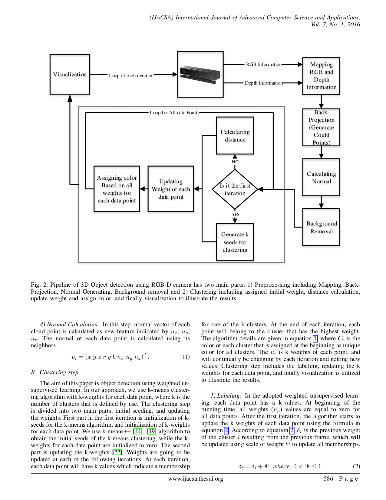


 This paper introduces a novel weighted unsupervised learning for object detection using an RGB-D camera. This technique is feasible for detecting the moving objects in the noisy environments that are captured by an RGB-D camera. The main contribution of this paper is a real-time algorithm for detecting each object using weighted clustering as a separate cluster. In a preprocessing step, the algorithm calculates the pose 3D position X, Y, Z and RGB color of each data point and then it calculates each data point's normal vector using the point's neighbor. After preprocessing, our algorithm calculates k-weights for each data point; each weight indicates membership. Resulting in clustered objects of the scene.
This paper introduces a novel weighted unsupervised learning for object detection using an RGB-D camera. This technique is feasible for detecting the moving objects in the noisy environments that are captured by an RGB-D camera. The main contribution of this paper is a real-time algorithm for detecting each object using weighted clustering as a separate cluster. In a preprocessing step, the algorithm calculates the pose 3D position X, Y, Z and RGB color of each data point and then it calculates each data point's normal vector using the point's neighbor. After preprocessing, our algorithm calculates k-weights for each data point; each weight indicates membership. Resulting in clustered objects of the scene.