-
Combining deep neural networks with structured logic rules is desirable to
harness flexibility and reduce uninterpretability of the neural models. We
propose a general framework capable of enhancing various types of neural
networks (e.g., CNNs and RNNs) with declarative first-order logic rules.
Specifically, we develop an iterative distillation method that transfers the
structured information of logic rules into the weights of neural networks. We
deploy the framework on a CNN for sentiment analysis, and an RNN for named
entity recognition. With a few highly intuitive rules, we obtain substantial
improvements and achieve state-of-the-art or comparable results to previous
best-performing systems.
-
McKernel introduces a framework to use kernel approximates in the mini-batch
setting with Stochastic Gradient Descent (SGD) as an alternative to Deep
Learning. Based on Random Kitchen Sinks [Rahimi and Recht 2007], we provide a
C++ library for Large-scale Machine Learning. It contains a CPU optimized
implementation of the algorithm in [Le et al. 2013], that allows the
computation of approximated kernel expansions in log-linear time. The algorithm
requires to compute the product of matrices Walsh Hadamard. A cache friendly
Fast Walsh Hadamard that achieves compelling speed and outperforms current
state-of-the-art methods has been developed. McKernel establishes the
foundation of a new architecture of learning that allows to obtain large-scale
non-linear classification combining lightning kernel expansions and a linear
classifier. It travails in the mini-batch setting working analogously to Neural
Networks. We show the validity of our method through extensive experiments on
MNIST and FASHION MNIST [Xiao et al. 2017].
-
Latent Dirichlet allocation (LDA) is useful in document analysis, image
processing, and many information systems; however, its generalization
performance has been left unknown because it is a singular learning machine to
which regular statistical theory can not be applied.
Stochastic matrix factorization (SMF) is a restricted matrix factorization in
which matrix factors are stochastic; the column of the matrix is in a simplex.
SMF is being applied to image recognition and text mining. We can understand
SMF as a statistical model by which a stochastic matrix of given data is
represented by a product of two stochastic matrices, whose generalization
performance has also been left unknown because of non-regularity.
In this paper, by using an algebraic and geometric method, we show the
analytic equivalence of LDA and SMF, both of which have the same real log
canonical threshold (RLCT), resulting in that they asymptotically have the same
Bayesian generalization error and the same log marginal likelihood. Moreover,
we derive the upper bound of the RLCT and prove that it is smaller than the
dimension of the parameter divided by two, hence the Bayesian generalization
errors of them are smaller than those of regular statistical models.
-
Distributed machine learning algorithms enable learning of models from
datasets that are distributed over a network without gathering the data at a
centralized location. While efficient distributed algorithms have been
developed under the assumption of faultless networks, failures that can render
these algorithms nonfunctional occur frequently in the real world. This paper
focuses on the problem of Byzantine failures, which are the hardest to
safeguard against in distributed algorithms. While Byzantine fault tolerance
has a rich history, existing work does not translate into efficient and
practical algorithms for high-dimensional learning in fully distributed (also
known as decentralized) settings. In this paper, an algorithm termed
Byzantine-resilient distributed coordinate descent (ByRDiE) is developed and
analyzed that enables distributed learning in the presence of Byzantine
failures. Theoretical analysis (convex settings) and numerical experiments
(convex and nonconvex settings) highlight its usefulness for high-dimensional
distributed learning in the presence of Byzantine failures.
-
Recently, (Blanchet, Kang, and Murhy 2016, and Blanchet, and Kang 2017)
showed that several machine learning algorithms, such as square-root Lasso,
Support Vector Machines, and regularized logistic regression, among many
others, can be represented exactly as distributionally robust optimization
(DRO) problems. The distributional uncertainty is defined as a neighborhood
centered at the empirical distribution. We propose a methodology which learns
such neighborhood in a natural data-driven way. We show rigorously that our
framework encompasses adaptive regularization as a particular case. Moreover,
we demonstrate empirically that our proposed methodology is able to improve
upon a wide range of popular machine learning estimators.
-
We propose a novel method for semi-supervised learning (SSL) based on
data-driven distributionally robust optimization (DRO) using optimal transport
metrics. Our proposed method enhances generalization error by using the
unlabeled data to restrict the support of the worst case distribution in our
DRO formulation. We enable the implementation of our DRO formulation by
proposing a stochastic gradient descent algorithm which allows to easily
implement the training procedure. We demonstrate that our Semi-supervised DRO
method is able to improve the generalization error over natural supervised
procedures and state-of-the-art SSL estimators. Finally, we include a
discussion on the large sample behavior of the optimal uncertainty region in
the DRO formulation. Our discussion exposes important aspects such as the role
of dimension reduction in SSL.
-
We discuss a multiple-play multi-armed bandit (MAB) problem in which several
arms are selected at each round. Recently, Thompson sampling (TS), a randomized
algorithm with a Bayesian spirit, has attracted much attention for its
empirically excellent performance, and it is revealed to have an optimal regret
bound in the standard single-play MAB problem. In this paper, we propose the
multiple-play Thompson sampling (MP-TS) algorithm, an extension of TS to the
multiple-play MAB problem, and discuss its regret analysis. We prove that MP-TS
for binary rewards has the optimal regret upper bound that matches the regret
lower bound provided by Anantharam et al. (1987). Therefore, MP-TS is the first
computationally efficient algorithm with optimal regret. A set of computer
simulations was also conducted, which compared MP-TS with state-of-the-art
algorithms. We also propose a modification of MP-TS, which is shown to have
better empirical performance.
-
A multiple instance dictionary learning approach, Dictionary Learning using
Functions of Multiple Instances (DL-FUMI), is used to perform beat-to-beat
heart rate estimation and to characterize heartbeat signatures from
ballistocardiogram (BCG) signals collected with a hydraulic bed sensor. DL-FUMI
estimates a "heartbeat concept" that represents an individual's personal
ballistocardiogram heartbeat pattern. DL-FUMI formulates heartbeat detection
and heartbeat characterization as a multiple instance learning problem to
address the uncertainty inherent in aligning BCG signals with ground truth
during training. Experimental results show that the estimated heartbeat concept
found by DL-FUMI is an effective heartbeat prototype and achieves superior
performance over comparison algorithms.
-
In school, a teacher plays an important role in various classroom teaching
patterns. Likewise to this human learning activity, the learning using
privileged information (LUPI) paradigm provides additional information
generated by the teacher to 'teach' learning models during the training stage.
Therefore, this novel learning paradigm is a typical Teacher-Student
Interaction mechanism. This paper is the first to present a random vector
functional link network based on the LUPI paradigm, called RVFL+. Rather than
simply combining two existing approaches, the newly-derived RVFL+ fills the gap
between classical randomized neural networks and the newfashioned LUPI
paradigm, which offers an alternative way to train RVFL networks. Moreover, the
proposed RVFL+ can perform in conjunction with the kernel trick for highly
complicated nonlinear feature learning, which is termed KRVFL+. Furthermore,
the statistical property of the proposed RVFL+ is investigated, and we present
a sharp and high-quality generalization error bound based on the Rademacher
complexity. Competitive experimental results on 14 real-world datasets
illustrate the great effectiveness and efficiency of the novel RVFL+ and
KRVFL+, which can achieve better generalization performance than
state-of-the-art methods.
-
Consider the multivariate nonparametric regression model. It is shown that
estimators based on sparsely connected deep neural networks with ReLU
activation function and properly chosen network architecture achieve the
minimax rates of convergence (up to $\log n$-factors) under a general
composition assumption on the regression function. The framework includes many
well-studied structural constraints such as (generalized) additive models.
While there is a lot of flexibility in the network architecture, the tuning
parameter is the sparsity of the network. Specifically, we consider large
networks with number of potential network parameters exceeding the sample size.
The analysis gives some insights into why multilayer feedforward neural
networks perform well in practice. Interestingly, for ReLU activation function
the depth (number of layers) of the neural network architectures plays an
important role and our theory suggests that for nonparametric regression,
scaling the network depth with the sample size is natural. It is also shown
that under the composition assumption wavelet estimators can only achieve
suboptimal rates.
-
We analyze the learning properties of the stochastic gradient method when
multiple passes over the data and mini-batches are allowed. We study how
regularization properties are controlled by the step-size, the number of passes
and the mini-batch size. In particular, we consider the square loss and show
that for a universal step-size choice, the number of passes acts as a
regularization parameter, and optimal finite sample bounds can be achieved by
early-stopping. Moreover, we show that larger step-sizes are allowed when
considering mini-batches. Our analysis is based on a unifying approach,
encompassing both batch and stochastic gradient methods as special cases. As a
byproduct, we derive optimal convergence results for batch gradient methods
(even in the non-attainable cases).
-
We study high-dimensional distribution learning in an agnostic setting where
an adversary is allowed to arbitrarily corrupt an $\varepsilon$-fraction of the
samples. Such questions have a rich history spanning statistics, machine
learning and theoretical computer science. Even in the most basic settings, the
only known approaches are either computationally inefficient or lose
dimension-dependent factors in their error guarantees. This raises the
following question:Is high-dimensional agnostic distribution learning even
possible, algorithmically?
In this work, we obtain the first computationally efficient algorithms with
dimension-independent error guarantees for agnostically learning several
fundamental classes of high-dimensional distributions: (1) a single Gaussian,
(2) a product distribution on the hypercube, (3) mixtures of two product
distributions (under a natural balancedness condition), and (4) mixtures of
spherical Gaussians. Our algorithms achieve error that is independent of the
dimension, and in many cases scales nearly-linearly with the fraction of
adversarially corrupted samples. Moreover, we develop a general recipe for
detecting and correcting corruptions in high-dimensions, that may be applicable
to many other problems.
-
In many scientific and engineering applications, we are tasked with the
maximisation of an expensive to evaluate black box function $f$. Traditional
settings for this problem assume just the availability of this single function.
However, in many cases, cheap approximations to $f$ may be obtainable. For
example, the expensive real world behaviour of a robot can be approximated by a
cheap computer simulation. We can use these approximations to eliminate low
function value regions cheaply and use the expensive evaluations of $f$ in a
small but promising region and speedily identify the optimum. We formalise this
task as a \emph{multi-fidelity} bandit problem where the target function and
its approximations are sampled from a Gaussian process. We develop MF-GP-UCB, a
novel method based on upper confidence bound techniques. In our theoretical
analysis we demonstrate that it exhibits precisely the above behaviour, and
achieves better regret than strategies which ignore multi-fidelity information.
Empirically, MF-GP-UCB outperforms such naive strategies and other
multi-fidelity methods on several synthetic and real experiments.
-
Inference of latent feature models in the Bayesian nonparametric setting is
generally difficult, especially in high dimensional settings, because it
usually requires proposing features from some prior distribution. In special
cases, where the integration is tractable, we can sample new feature
assignments according to a predictive likelihood. However, this still may not
be efficient in high dimensions. We present a novel method to accelerate the
mixing of latent variable model inference by proposing feature locations based
on the data, as opposed to the prior. First, we introduce an accelerated
feature proposal mechanism that we show is a valid Bayesian inference
algorithm. Next, we propose an approximate inference strategy to perform
accelerated inference in parallel. A two-stage algorithm that combines the two
approaches provides a computationally attractive method that exhibits good
mixing behavior and converges to the posterior distribution of our model, while
allowing us to exploit parallelization.
-
While many statistical models and methods are now available for network
analysis, resampling network data remains a challenging problem.
Cross-validation is a useful general tool for model selection and parameter
tuning, but is not directly applicable to networks since splitting network
nodes into groups requires deleting edges and destroys some of the network
structure. Here we propose a new network resampling strategy based on splitting
node pairs rather than nodes applicable to cross-validation for a wide range of
network model selection tasks. We provide a theoretical justification for our
method in a general setting and examples of how our method can be used in
specific network model selection and parameter tuning tasks. Numerical results
on simulated networks and on a citation network of statisticians show that this
cross-validation approach works well for model selection.
-
We investigate metric learning in the context of dynamic time warping (DTW),
the by far most popular dissimilarity measure used for the comparison and
analysis of motion capture data. While metric learning enables a
problem-adapted representation of data, the majority of methods has been
proposed for vectorial data only. In this contribution, we extend the popular
principle offered by the large margin nearest neighbors learner (LMNN) to DTW
by treating the resulting component-wise dissimilarity values as features. We
demonstrate that this principle greatly enhances the classification accuracy in
several benchmarks. Further, we show that recent auxiliary concepts such as
metric regularization can be transferred from the vectorial case to
component-wise DTW in a similar way. We illustrate that metric regularization
constitutes a crucial prerequisite for the interpretation of the resulting
relevance profiles.
-
This tutorial provides a gentle introduction to the particle
Metropolis-Hastings (PMH) algorithm for parameter inference in nonlinear
state-space models together with a software implementation in the statistical
programming language R. We employ a step-by-step approach to develop an
implementation of the PMH algorithm (and the particle filter within) together
with the reader. This final implementation is also available as the package
pmhtutorial in the CRAN repository. Throughout the tutorial, we provide some
intuition as to how the algorithm operates and discuss some solutions to
problems that might occur in practice. To illustrate the use of PMH, we
consider parameter inference in a linear Gaussian state-space model with
synthetic data and a nonlinear stochastic volatility model with real-world
data.
-
The resemblance between the methods used in quantum-many body physics and in
machine learning has drawn considerable attention. In particular, tensor
networks (TNs) and deep learning architectures bear striking similarities to
the extent that TNs can be used for machine learning. Previous results used
one-dimensional TNs in image recognition, showing limited scalability and
flexibilities. In this work, we train two-dimensional hierarchical TNs to solve
image recognition problems, using a training algorithm derived from the
multi-scale entanglement renormalization ansatz. This approach introduces
mathematical connections among quantum many-body physics, quantum information
theory, and machine learning. While keeping the TN unitary in the training
phase, TN states are defined, which encode classes of images into quantum
many-body states. We study the quantum features of the TN states, including
quantum entanglement and fidelity. We find these quantities could be properties
that characterize the image classes, as well as the machine learning tasks.
-
Ensembling multiple predictions is a widely used technique for improving the
accuracy of various machine learning tasks. One obvious drawback of ensembling
is its higher execution cost during inference. In this paper, we first describe
our insights on the relationship between the probability of prediction and the
effect of ensembling with current deep neural networks; ensembling does not
help mispredictions for inputs predicted with a high probability even when
there is a non-negligible number of mispredicted inputs. This finding motivated
us to develop a way to adaptively control the ensembling. If the prediction for
an input reaches a high enough probability, i.e., the output from the softmax
function, on the basis of the confidence level, we stop ensembling for this
input to avoid wasting computation power. We evaluated the adaptive ensembling
by using various datasets and showed that it reduces the computation cost
significantly while achieving accuracy similar to that of static ensembling
using a pre-defined number of local predictions. We also show that our
statistically rigorous confidence-level-based early-exit condition reduces the
burden of task-dependent threshold tuning better compared with naive early exit
based on a pre-defined threshold in addition to yielding a better accuracy with
the same cost.
-
This paper investigates the behavior of the Min-Sum message passing scheme to
solve systems of linear equations in the Laplacian matrices of graphs and to
compute electric flows. Voltage and flow problems involve the minimization of
quadratic functions and are fundamental primitives that arise in several
domains. Algorithms that have been proposed are typically centralized and
involve multiple graph-theoretic constructions or sampling mechanisms that make
them difficult to implement and analyze. On the other hand, message passing
routines are distributed, simple, and easy to implement. In this paper we
establish a framework to analyze Min-Sum to solve voltage and flow problems. We
characterize the error committed by the algorithm on general weighted graphs in
terms of hitting times of random walks defined on the computation trees that
support the operations of the algorithms with time. For $d$-regular graphs with
equal weights, we show that the convergence of the algorithms is controlled by
the total variation distance between the distributions of non-backtracking
random walks defined on the original graph that start from neighboring nodes.
The framework that we introduce extends the analysis of Min-Sum to settings
where the contraction arguments previously considered in the literature (based
on the assumption of walk summability or scaled diagonal dominance) can not be
used, possibly in the presence of constraints.
-
We study the use of randomized value functions to guide deep exploration in
reinforcement learning. This offers an elegant means for synthesizing
statistically and computationally efficient exploration with common practical
approaches to value function learning. We present several reinforcement
learning algorithms that leverage randomized value functions and demonstrate
their efficacy through computational studies. We also prove a regret bound that
establishes statistical efficiency with a tabular representation.
-
Instance- and Label-dependent label Noise (ILN) widely exists in real-world
datasets but has been rarely studied. In this paper, we focus on Bounded
Instance- and Label-dependent label Noise (BILN), a particular case of ILN
where the label noise rates -- the probabilities that the true labels of
examples flip into the corrupted ones -- have upper bound less than $1$.
Specifically, we introduce the concept of distilled examples, i.e. examples
whose labels are identical with the labels assigned for them by the Bayes
optimal classifier, and prove that under certain conditions classifiers learnt
on distilled examples will converge to the Bayes optimal classifier. Inspired
by the idea of learning with distilled examples, we then propose a learning
algorithm with theoretical guarantees for its robustness to BILN. At last,
empirical evaluations on both synthetic and real-world datasets show
effectiveness of our algorithm in learning with BILN.
-
The automation of posterior inference in Bayesian data analysis has enabled
experts and nonexperts alike to use more sophisticated models, engage in faster
exploratory modeling and analysis, and ensure experimental reproducibility.
However, standard automated posterior inference algorithms are not tractable at
the scale of massive modern datasets, and modifications to make them so are
typically model-specific, require expert tuning, and can break theoretical
guarantees on inferential quality. Building on the Bayesian coresets framework,
this work instead takes advantage of data redundancy to shrink the dataset
itself as a preprocessing step, providing fully-automated, scalable Bayesian
inference with theoretical guarantees. We begin with an intuitive reformulation
of Bayesian coreset construction as sparse vector sum approximation, and
demonstrate that its automation and performance-based shortcomings arise from
the use of the supremum norm. To address these shortcomings we develop Hilbert
coresets, i.e., Bayesian coresets constructed under a norm induced by an
inner-product on the log-likelihood function space. We propose two Hilbert
coreset construction algorithms---one based on importance sampling, and one
based on the Frank-Wolfe algorithm---along with theoretical guarantees on
approximation quality as a function of coreset size. Since the exact
computation of the proposed inner-products is model-specific, we automate the
construction with a random finite-dimensional projection of the log-likelihood
functions. The resulting automated coreset construction algorithm is simple to
implement, and experiments on a variety of models with real and synthetic
datasets show that it provides high-quality posterior approximations and a
significant reduction in the computational cost of inference.
-
We present a mathematical analysis of a non-convex energy landscape for
robust subspace recovery. We prove that an underlying subspace is the only
stationary point and local minimizer in a specified neighborhood under a
deterministic condition on a dataset. If the deterministic condition is
satisfied, we further show that a geodesic gradient descent method over the
Grassmannian manifold can exactly recover the underlying subspace when the
method is properly initialized. Proper initialization by principal component
analysis is guaranteed with a simple deterministic condition. Under slightly
stronger assumptions, the gradient descent method with a piecewise constant
step-size scheme achieves linear convergence. The practicality of the
deterministic condition is demonstrated on some statistical models of data, and
the method achieves almost state-of-the-art recovery guarantees on the Haystack
Model for different regimes of sample size and ambient dimension. In
particular, when the ambient dimension is fixed and the sample size is large
enough, we show that our gradient method can exactly recover the underlying
subspace for any fixed fraction of outliers (less than 1).
-
Feature selection is a standard approach to understanding and modeling
high-dimensional classification data, but the corresponding statistical methods
hinge on tuning parameters that are difficult to calibrate. In particular,
existing calibration schemes in the logistic regression framework lack any
finite sample guarantees. In this paper, we introduce a novel calibration
scheme for $\ell_1$-penalized logistic regression. It is based on simple tests
along the tuning parameter path and is equipped with optimal guarantees for
feature selection. It is also amenable to easy and efficient implementations,
and it rivals or outmatches existing methods in simulations and real data
applications.





 Combining deep neural networks with structured logic rules is desirable to harness flexibility and reduce uninterpretability of the neural models. We propose a general framework capable of enhancing various types of neural networks (e.g., CNNs and RNNs) with declarative first-order logic rules. Specifically, we develop an iterative distillation method that transfers the structured information of logic rules into the weights of neural networks. We deploy the framework on a CNN for sentiment analysis, and an RNN for named entity recognition. With a few highly intuitive rules, we obtain substantial improvements and achieve state-of-the-art or comparable results to previous best-performing systems.
Combining deep neural networks with structured logic rules is desirable to harness flexibility and reduce uninterpretability of the neural models. We propose a general framework capable of enhancing various types of neural networks (e.g., CNNs and RNNs) with declarative first-order logic rules. Specifically, we develop an iterative distillation method that transfers the structured information of logic rules into the weights of neural networks. We deploy the framework on a CNN for sentiment analysis, and an RNN for named entity recognition. With a few highly intuitive rules, we obtain substantial improvements and achieve state-of-the-art or comparable results to previous best-performing systems.


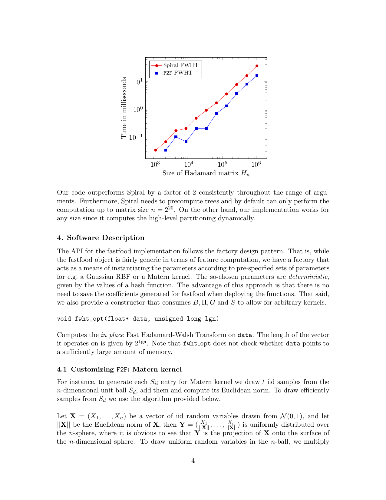

 McKernel introduces a framework to use kernel approximates in the mini-batch setting with Stochastic Gradient Descent (SGD) as an alternative to Deep Learning. Based on Random Kitchen Sinks [Rahimi and Recht 2007], we provide a C++ library for Large-scale Machine Learning. It contains a CPU optimized implementation of the algorithm in [Le et al. 2013], that allows the computation of approximated kernel expansions in log-linear time. The algorithm requires to compute the product of matrices Walsh Hadamard. A cache friendly Fast Walsh Hadamard that achieves compelling speed and outperforms current state-of-the-art methods has been developed. McKernel establishes the foundation of a new architecture of learning that allows to obtain large-scale non-linear classification combining lightning kernel expansions and a linear classifier. It travails in the mini-batch setting working analogously to Neural Networks. We show the validity of our method through extensive experiments on MNIST and FASHION MNIST [Xiao et al. 2017].
McKernel introduces a framework to use kernel approximates in the mini-batch setting with Stochastic Gradient Descent (SGD) as an alternative to Deep Learning. Based on Random Kitchen Sinks [Rahimi and Recht 2007], we provide a C++ library for Large-scale Machine Learning. It contains a CPU optimized implementation of the algorithm in [Le et al. 2013], that allows the computation of approximated kernel expansions in log-linear time. The algorithm requires to compute the product of matrices Walsh Hadamard. A cache friendly Fast Walsh Hadamard that achieves compelling speed and outperforms current state-of-the-art methods has been developed. McKernel establishes the foundation of a new architecture of learning that allows to obtain large-scale non-linear classification combining lightning kernel expansions and a linear classifier. It travails in the mini-batch setting working analogously to Neural Networks. We show the validity of our method through extensive experiments on MNIST and FASHION MNIST [Xiao et al. 2017].




 Distributed machine learning algorithms enable learning of models from datasets that are distributed over a network without gathering the data at a centralized location. While efficient distributed algorithms have been developed under the assumption of faultless networks, failures that can render these algorithms nonfunctional occur frequently in the real world. This paper focuses on the problem of Byzantine failures, which are the hardest to safeguard against in distributed algorithms. While Byzantine fault tolerance has a rich history, existing work does not translate into efficient and practical algorithms for high-dimensional learning in fully distributed (also known as decentralized) settings. In this paper, an algorithm termed Byzantine-resilient distributed coordinate descent (ByRDiE) is developed and analyzed that enables distributed learning in the presence of Byzantine failures. Theoretical analysis (convex settings) and numerical experiments (convex and nonconvex settings) highlight its usefulness for high-dimensional distributed learning in the presence of Byzantine failures.
Distributed machine learning algorithms enable learning of models from datasets that are distributed over a network without gathering the data at a centralized location. While efficient distributed algorithms have been developed under the assumption of faultless networks, failures that can render these algorithms nonfunctional occur frequently in the real world. This paper focuses on the problem of Byzantine failures, which are the hardest to safeguard against in distributed algorithms. While Byzantine fault tolerance has a rich history, existing work does not translate into efficient and practical algorithms for high-dimensional learning in fully distributed (also known as decentralized) settings. In this paper, an algorithm termed Byzantine-resilient distributed coordinate descent (ByRDiE) is developed and analyzed that enables distributed learning in the presence of Byzantine failures. Theoretical analysis (convex settings) and numerical experiments (convex and nonconvex settings) highlight its usefulness for high-dimensional distributed learning in the presence of Byzantine failures.




 Recently, (Blanchet, Kang, and Murhy 2016, and Blanchet, and Kang 2017) showed that several machine learning algorithms, such as square-root Lasso, Support Vector Machines, and regularized logistic regression, among many others, can be represented exactly as distributionally robust optimization (DRO) problems. The distributional uncertainty is defined as a neighborhood centered at the empirical distribution. We propose a methodology which learns such neighborhood in a natural data-driven way. We show rigorously that our framework encompasses adaptive regularization as a particular case. Moreover, we demonstrate empirically that our proposed methodology is able to improve upon a wide range of popular machine learning estimators.
Recently, (Blanchet, Kang, and Murhy 2016, and Blanchet, and Kang 2017) showed that several machine learning algorithms, such as square-root Lasso, Support Vector Machines, and regularized logistic regression, among many others, can be represented exactly as distributionally robust optimization (DRO) problems. The distributional uncertainty is defined as a neighborhood centered at the empirical distribution. We propose a methodology which learns such neighborhood in a natural data-driven way. We show rigorously that our framework encompasses adaptive regularization as a particular case. Moreover, we demonstrate empirically that our proposed methodology is able to improve upon a wide range of popular machine learning estimators.
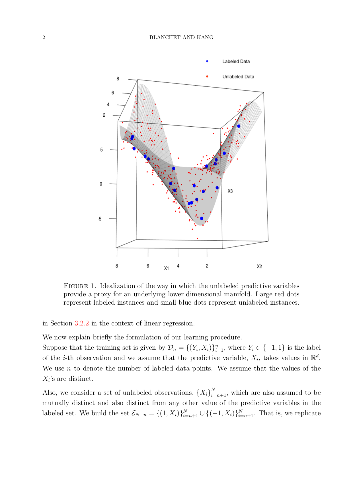



 We propose a novel method for semi-supervised learning (SSL) based on data-driven distributionally robust optimization (DRO) using optimal transport metrics. Our proposed method enhances generalization error by using the unlabeled data to restrict the support of the worst case distribution in our DRO formulation. We enable the implementation of our DRO formulation by proposing a stochastic gradient descent algorithm which allows to easily implement the training procedure. We demonstrate that our Semi-supervised DRO method is able to improve the generalization error over natural supervised procedures and state-of-the-art SSL estimators. Finally, we include a discussion on the large sample behavior of the optimal uncertainty region in the DRO formulation. Our discussion exposes important aspects such as the role of dimension reduction in SSL.
We propose a novel method for semi-supervised learning (SSL) based on data-driven distributionally robust optimization (DRO) using optimal transport metrics. Our proposed method enhances generalization error by using the unlabeled data to restrict the support of the worst case distribution in our DRO formulation. We enable the implementation of our DRO formulation by proposing a stochastic gradient descent algorithm which allows to easily implement the training procedure. We demonstrate that our Semi-supervised DRO method is able to improve the generalization error over natural supervised procedures and state-of-the-art SSL estimators. Finally, we include a discussion on the large sample behavior of the optimal uncertainty region in the DRO formulation. Our discussion exposes important aspects such as the role of dimension reduction in SSL.




 We discuss a multiple-play multi-armed bandit (MAB) problem in which several arms are selected at each round. Recently, Thompson sampling (TS), a randomized algorithm with a Bayesian spirit, has attracted much attention for its empirically excellent performance, and it is revealed to have an optimal regret bound in the standard single-play MAB problem. In this paper, we propose the multiple-play Thompson sampling (MP-TS) algorithm, an extension of TS to the multiple-play MAB problem, and discuss its regret analysis. We prove that MP-TS for binary rewards has the optimal regret upper bound that matches the regret lower bound provided by Anantharam et al. (1987). Therefore, MP-TS is the first computationally efficient algorithm with optimal regret. A set of computer simulations was also conducted, which compared MP-TS with state-of-the-art algorithms. We also propose a modification of MP-TS, which is shown to have better empirical performance.
We discuss a multiple-play multi-armed bandit (MAB) problem in which several arms are selected at each round. Recently, Thompson sampling (TS), a randomized algorithm with a Bayesian spirit, has attracted much attention for its empirically excellent performance, and it is revealed to have an optimal regret bound in the standard single-play MAB problem. In this paper, we propose the multiple-play Thompson sampling (MP-TS) algorithm, an extension of TS to the multiple-play MAB problem, and discuss its regret analysis. We prove that MP-TS for binary rewards has the optimal regret upper bound that matches the regret lower bound provided by Anantharam et al. (1987). Therefore, MP-TS is the first computationally efficient algorithm with optimal regret. A set of computer simulations was also conducted, which compared MP-TS with state-of-the-art algorithms. We also propose a modification of MP-TS, which is shown to have better empirical performance.




 In school, a teacher plays an important role in various classroom teaching patterns. Likewise to this human learning activity, the learning using privileged information (LUPI) paradigm provides additional information generated by the teacher to 'teach' learning models during the training stage. Therefore, this novel learning paradigm is a typical Teacher-Student Interaction mechanism. This paper is the first to present a random vector functional link network based on the LUPI paradigm, called RVFL+. Rather than simply combining two existing approaches, the newly-derived RVFL+ fills the gap between classical randomized neural networks and the newfashioned LUPI paradigm, which offers an alternative way to train RVFL networks. Moreover, the proposed RVFL+ can perform in conjunction with the kernel trick for highly complicated nonlinear feature learning, which is termed KRVFL+. Furthermore, the statistical property of the proposed RVFL+ is investigated, and we present a sharp and high-quality generalization error bound based on the Rademacher complexity. Competitive experimental results on 14 real-world datasets illustrate the great effectiveness and efficiency of the novel RVFL+ and KRVFL+, which can achieve better generalization performance than state-of-the-art methods.
In school, a teacher plays an important role in various classroom teaching patterns. Likewise to this human learning activity, the learning using privileged information (LUPI) paradigm provides additional information generated by the teacher to 'teach' learning models during the training stage. Therefore, this novel learning paradigm is a typical Teacher-Student Interaction mechanism. This paper is the first to present a random vector functional link network based on the LUPI paradigm, called RVFL+. Rather than simply combining two existing approaches, the newly-derived RVFL+ fills the gap between classical randomized neural networks and the newfashioned LUPI paradigm, which offers an alternative way to train RVFL networks. Moreover, the proposed RVFL+ can perform in conjunction with the kernel trick for highly complicated nonlinear feature learning, which is termed KRVFL+. Furthermore, the statistical property of the proposed RVFL+ is investigated, and we present a sharp and high-quality generalization error bound based on the Rademacher complexity. Competitive experimental results on 14 real-world datasets illustrate the great effectiveness and efficiency of the novel RVFL+ and KRVFL+, which can achieve better generalization performance than state-of-the-art methods.




 Consider the multivariate nonparametric regression model. It is shown that estimators based on sparsely connected deep neural networks with ReLU activation function and properly chosen network architecture achieve the minimax rates of convergence (up to $\log n$-factors) under a general composition assumption on the regression function. The framework includes many well-studied structural constraints such as (generalized) additive models. While there is a lot of flexibility in the network architecture, the tuning parameter is the sparsity of the network. Specifically, we consider large networks with number of potential network parameters exceeding the sample size. The analysis gives some insights into why multilayer feedforward neural networks perform well in practice. Interestingly, for ReLU activation function the depth (number of layers) of the neural network architectures plays an important role and our theory suggests that for nonparametric regression, scaling the network depth with the sample size is natural. It is also shown that under the composition assumption wavelet estimators can only achieve suboptimal rates.
Consider the multivariate nonparametric regression model. It is shown that estimators based on sparsely connected deep neural networks with ReLU activation function and properly chosen network architecture achieve the minimax rates of convergence (up to $\log n$-factors) under a general composition assumption on the regression function. The framework includes many well-studied structural constraints such as (generalized) additive models. While there is a lot of flexibility in the network architecture, the tuning parameter is the sparsity of the network. Specifically, we consider large networks with number of potential network parameters exceeding the sample size. The analysis gives some insights into why multilayer feedforward neural networks perform well in practice. Interestingly, for ReLU activation function the depth (number of layers) of the neural network architectures plays an important role and our theory suggests that for nonparametric regression, scaling the network depth with the sample size is natural. It is also shown that under the composition assumption wavelet estimators can only achieve suboptimal rates.




 We analyze the learning properties of the stochastic gradient method when multiple passes over the data and mini-batches are allowed. We study how regularization properties are controlled by the step-size, the number of passes and the mini-batch size. In particular, we consider the square loss and show that for a universal step-size choice, the number of passes acts as a regularization parameter, and optimal finite sample bounds can be achieved by early-stopping. Moreover, we show that larger step-sizes are allowed when considering mini-batches. Our analysis is based on a unifying approach, encompassing both batch and stochastic gradient methods as special cases. As a byproduct, we derive optimal convergence results for batch gradient methods (even in the non-attainable cases).
We analyze the learning properties of the stochastic gradient method when multiple passes over the data and mini-batches are allowed. We study how regularization properties are controlled by the step-size, the number of passes and the mini-batch size. In particular, we consider the square loss and show that for a universal step-size choice, the number of passes acts as a regularization parameter, and optimal finite sample bounds can be achieved by early-stopping. Moreover, we show that larger step-sizes are allowed when considering mini-batches. Our analysis is based on a unifying approach, encompassing both batch and stochastic gradient methods as special cases. As a byproduct, we derive optimal convergence results for batch gradient methods (even in the non-attainable cases).




 We study high-dimensional distribution learning in an agnostic setting where an adversary is allowed to arbitrarily corrupt an $\varepsilon$-fraction of the samples. Such questions have a rich history spanning statistics, machine learning and theoretical computer science. Even in the most basic settings, the only known approaches are either computationally inefficient or lose dimension-dependent factors in their error guarantees. This raises the following question:Is high-dimensional agnostic distribution learning even possible, algorithmically? In this work, we obtain the first computationally efficient algorithms with dimension-independent error guarantees for agnostically learning several fundamental classes of high-dimensional distributions: (1) a single Gaussian, (2) a product distribution on the hypercube, (3) mixtures of two product distributions (under a natural balancedness condition), and (4) mixtures of spherical Gaussians. Our algorithms achieve error that is independent of the dimension, and in many cases scales nearly-linearly with the fraction of adversarially corrupted samples. Moreover, we develop a general recipe for detecting and correcting corruptions in high-dimensions, that may be applicable to many other problems.
We study high-dimensional distribution learning in an agnostic setting where an adversary is allowed to arbitrarily corrupt an $\varepsilon$-fraction of the samples. Such questions have a rich history spanning statistics, machine learning and theoretical computer science. Even in the most basic settings, the only known approaches are either computationally inefficient or lose dimension-dependent factors in their error guarantees. This raises the following question:Is high-dimensional agnostic distribution learning even possible, algorithmically? In this work, we obtain the first computationally efficient algorithms with dimension-independent error guarantees for agnostically learning several fundamental classes of high-dimensional distributions: (1) a single Gaussian, (2) a product distribution on the hypercube, (3) mixtures of two product distributions (under a natural balancedness condition), and (4) mixtures of spherical Gaussians. Our algorithms achieve error that is independent of the dimension, and in many cases scales nearly-linearly with the fraction of adversarially corrupted samples. Moreover, we develop a general recipe for detecting and correcting corruptions in high-dimensions, that may be applicable to many other problems.



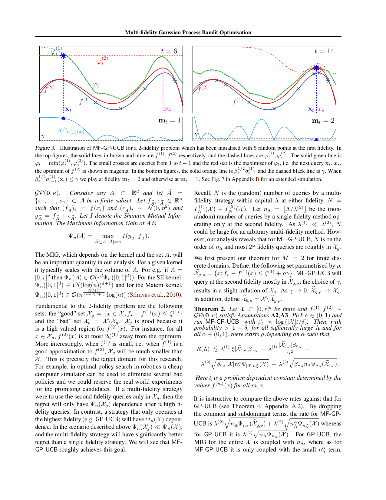
 In many scientific and engineering applications, we are tasked with the maximisation of an expensive to evaluate black box function $f$. Traditional settings for this problem assume just the availability of this single function. However, in many cases, cheap approximations to $f$ may be obtainable. For example, the expensive real world behaviour of a robot can be approximated by a cheap computer simulation. We can use these approximations to eliminate low function value regions cheaply and use the expensive evaluations of $f$ in a small but promising region and speedily identify the optimum. We formalise this task as a \emph{multi-fidelity} bandit problem where the target function and its approximations are sampled from a Gaussian process. We develop MF-GP-UCB, a novel method based on upper confidence bound techniques. In our theoretical analysis we demonstrate that it exhibits precisely the above behaviour, and achieves better regret than strategies which ignore multi-fidelity information. Empirically, MF-GP-UCB outperforms such naive strategies and other multi-fidelity methods on several synthetic and real experiments.
In many scientific and engineering applications, we are tasked with the maximisation of an expensive to evaluate black box function $f$. Traditional settings for this problem assume just the availability of this single function. However, in many cases, cheap approximations to $f$ may be obtainable. For example, the expensive real world behaviour of a robot can be approximated by a cheap computer simulation. We can use these approximations to eliminate low function value regions cheaply and use the expensive evaluations of $f$ in a small but promising region and speedily identify the optimum. We formalise this task as a \emph{multi-fidelity} bandit problem where the target function and its approximations are sampled from a Gaussian process. We develop MF-GP-UCB, a novel method based on upper confidence bound techniques. In our theoretical analysis we demonstrate that it exhibits precisely the above behaviour, and achieves better regret than strategies which ignore multi-fidelity information. Empirically, MF-GP-UCB outperforms such naive strategies and other multi-fidelity methods on several synthetic and real experiments.




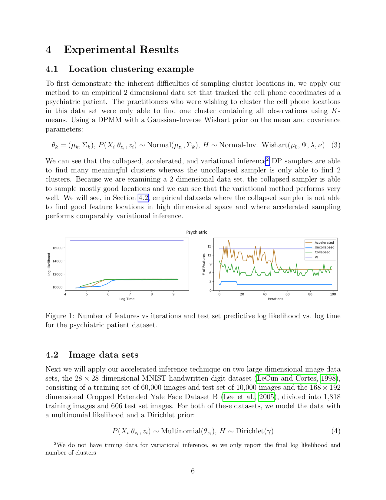 Inference of latent feature models in the Bayesian nonparametric setting is generally difficult, especially in high dimensional settings, because it usually requires proposing features from some prior distribution. In special cases, where the integration is tractable, we can sample new feature assignments according to a predictive likelihood. However, this still may not be efficient in high dimensions. We present a novel method to accelerate the mixing of latent variable model inference by proposing feature locations based on the data, as opposed to the prior. First, we introduce an accelerated feature proposal mechanism that we show is a valid Bayesian inference algorithm. Next, we propose an approximate inference strategy to perform accelerated inference in parallel. A two-stage algorithm that combines the two approaches provides a computationally attractive method that exhibits good mixing behavior and converges to the posterior distribution of our model, while allowing us to exploit parallelization.
Inference of latent feature models in the Bayesian nonparametric setting is generally difficult, especially in high dimensional settings, because it usually requires proposing features from some prior distribution. In special cases, where the integration is tractable, we can sample new feature assignments according to a predictive likelihood. However, this still may not be efficient in high dimensions. We present a novel method to accelerate the mixing of latent variable model inference by proposing feature locations based on the data, as opposed to the prior. First, we introduce an accelerated feature proposal mechanism that we show is a valid Bayesian inference algorithm. Next, we propose an approximate inference strategy to perform accelerated inference in parallel. A two-stage algorithm that combines the two approaches provides a computationally attractive method that exhibits good mixing behavior and converges to the posterior distribution of our model, while allowing us to exploit parallelization.




 While many statistical models and methods are now available for network analysis, resampling network data remains a challenging problem. Cross-validation is a useful general tool for model selection and parameter tuning, but is not directly applicable to networks since splitting network nodes into groups requires deleting edges and destroys some of the network structure. Here we propose a new network resampling strategy based on splitting node pairs rather than nodes applicable to cross-validation for a wide range of network model selection tasks. We provide a theoretical justification for our method in a general setting and examples of how our method can be used in specific network model selection and parameter tuning tasks. Numerical results on simulated networks and on a citation network of statisticians show that this cross-validation approach works well for model selection.
While many statistical models and methods are now available for network analysis, resampling network data remains a challenging problem. Cross-validation is a useful general tool for model selection and parameter tuning, but is not directly applicable to networks since splitting network nodes into groups requires deleting edges and destroys some of the network structure. Here we propose a new network resampling strategy based on splitting node pairs rather than nodes applicable to cross-validation for a wide range of network model selection tasks. We provide a theoretical justification for our method in a general setting and examples of how our method can be used in specific network model selection and parameter tuning tasks. Numerical results on simulated networks and on a citation network of statisticians show that this cross-validation approach works well for model selection.




 This tutorial provides a gentle introduction to the particle Metropolis-Hastings (PMH) algorithm for parameter inference in nonlinear state-space models together with a software implementation in the statistical programming language R. We employ a step-by-step approach to develop an implementation of the PMH algorithm (and the particle filter within) together with the reader. This final implementation is also available as the package pmhtutorial in the CRAN repository. Throughout the tutorial, we provide some intuition as to how the algorithm operates and discuss some solutions to problems that might occur in practice. To illustrate the use of PMH, we consider parameter inference in a linear Gaussian state-space model with synthetic data and a nonlinear stochastic volatility model with real-world data.
This tutorial provides a gentle introduction to the particle Metropolis-Hastings (PMH) algorithm for parameter inference in nonlinear state-space models together with a software implementation in the statistical programming language R. We employ a step-by-step approach to develop an implementation of the PMH algorithm (and the particle filter within) together with the reader. This final implementation is also available as the package pmhtutorial in the CRAN repository. Throughout the tutorial, we provide some intuition as to how the algorithm operates and discuss some solutions to problems that might occur in practice. To illustrate the use of PMH, we consider parameter inference in a linear Gaussian state-space model with synthetic data and a nonlinear stochastic volatility model with real-world data.




 This paper investigates the behavior of the Min-Sum message passing scheme to solve systems of linear equations in the Laplacian matrices of graphs and to compute electric flows. Voltage and flow problems involve the minimization of quadratic functions and are fundamental primitives that arise in several domains. Algorithms that have been proposed are typically centralized and involve multiple graph-theoretic constructions or sampling mechanisms that make them difficult to implement and analyze. On the other hand, message passing routines are distributed, simple, and easy to implement. In this paper we establish a framework to analyze Min-Sum to solve voltage and flow problems. We characterize the error committed by the algorithm on general weighted graphs in terms of hitting times of random walks defined on the computation trees that support the operations of the algorithms with time. For $d$-regular graphs with equal weights, we show that the convergence of the algorithms is controlled by the total variation distance between the distributions of non-backtracking random walks defined on the original graph that start from neighboring nodes. The framework that we introduce extends the analysis of Min-Sum to settings where the contraction arguments previously considered in the literature (based on the assumption of walk summability or scaled diagonal dominance) can not be used, possibly in the presence of constraints.
This paper investigates the behavior of the Min-Sum message passing scheme to solve systems of linear equations in the Laplacian matrices of graphs and to compute electric flows. Voltage and flow problems involve the minimization of quadratic functions and are fundamental primitives that arise in several domains. Algorithms that have been proposed are typically centralized and involve multiple graph-theoretic constructions or sampling mechanisms that make them difficult to implement and analyze. On the other hand, message passing routines are distributed, simple, and easy to implement. In this paper we establish a framework to analyze Min-Sum to solve voltage and flow problems. We characterize the error committed by the algorithm on general weighted graphs in terms of hitting times of random walks defined on the computation trees that support the operations of the algorithms with time. For $d$-regular graphs with equal weights, we show that the convergence of the algorithms is controlled by the total variation distance between the distributions of non-backtracking random walks defined on the original graph that start from neighboring nodes. The framework that we introduce extends the analysis of Min-Sum to settings where the contraction arguments previously considered in the literature (based on the assumption of walk summability or scaled diagonal dominance) can not be used, possibly in the presence of constraints.




 We study the use of randomized value functions to guide deep exploration in reinforcement learning. This offers an elegant means for synthesizing statistically and computationally efficient exploration with common practical approaches to value function learning. We present several reinforcement learning algorithms that leverage randomized value functions and demonstrate their efficacy through computational studies. We also prove a regret bound that establishes statistical efficiency with a tabular representation.
We study the use of randomized value functions to guide deep exploration in reinforcement learning. This offers an elegant means for synthesizing statistically and computationally efficient exploration with common practical approaches to value function learning. We present several reinforcement learning algorithms that leverage randomized value functions and demonstrate their efficacy through computational studies. We also prove a regret bound that establishes statistical efficiency with a tabular representation.

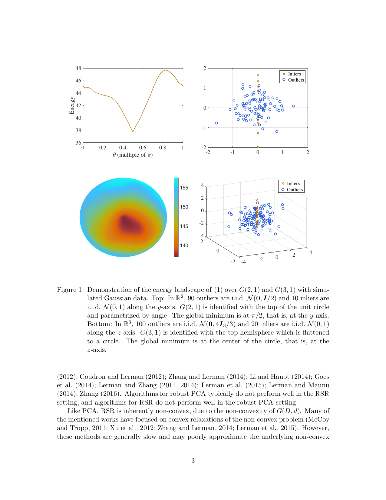


 We present a mathematical analysis of a non-convex energy landscape for robust subspace recovery. We prove that an underlying subspace is the only stationary point and local minimizer in a specified neighborhood under a deterministic condition on a dataset. If the deterministic condition is satisfied, we further show that a geodesic gradient descent method over the Grassmannian manifold can exactly recover the underlying subspace when the method is properly initialized. Proper initialization by principal component analysis is guaranteed with a simple deterministic condition. Under slightly stronger assumptions, the gradient descent method with a piecewise constant step-size scheme achieves linear convergence. The practicality of the deterministic condition is demonstrated on some statistical models of data, and the method achieves almost state-of-the-art recovery guarantees on the Haystack Model for different regimes of sample size and ambient dimension. In particular, when the ambient dimension is fixed and the sample size is large enough, we show that our gradient method can exactly recover the underlying subspace for any fixed fraction of outliers (less than 1).
We present a mathematical analysis of a non-convex energy landscape for robust subspace recovery. We prove that an underlying subspace is the only stationary point and local minimizer in a specified neighborhood under a deterministic condition on a dataset. If the deterministic condition is satisfied, we further show that a geodesic gradient descent method over the Grassmannian manifold can exactly recover the underlying subspace when the method is properly initialized. Proper initialization by principal component analysis is guaranteed with a simple deterministic condition. Under slightly stronger assumptions, the gradient descent method with a piecewise constant step-size scheme achieves linear convergence. The practicality of the deterministic condition is demonstrated on some statistical models of data, and the method achieves almost state-of-the-art recovery guarantees on the Haystack Model for different regimes of sample size and ambient dimension. In particular, when the ambient dimension is fixed and the sample size is large enough, we show that our gradient method can exactly recover the underlying subspace for any fixed fraction of outliers (less than 1).




 Feature selection is a standard approach to understanding and modeling high-dimensional classification data, but the corresponding statistical methods hinge on tuning parameters that are difficult to calibrate. In particular, existing calibration schemes in the logistic regression framework lack any finite sample guarantees. In this paper, we introduce a novel calibration scheme for $\ell_1$-penalized logistic regression. It is based on simple tests along the tuning parameter path and is equipped with optimal guarantees for feature selection. It is also amenable to easy and efficient implementations, and it rivals or outmatches existing methods in simulations and real data applications.
Feature selection is a standard approach to understanding and modeling high-dimensional classification data, but the corresponding statistical methods hinge on tuning parameters that are difficult to calibrate. In particular, existing calibration schemes in the logistic regression framework lack any finite sample guarantees. In this paper, we introduce a novel calibration scheme for $\ell_1$-penalized logistic regression. It is based on simple tests along the tuning parameter path and is equipped with optimal guarantees for feature selection. It is also amenable to easy and efficient implementations, and it rivals or outmatches existing methods in simulations and real data applications.