-
The neural network is a powerful computing framework that has been exploited
by biological evolution and by humans for solving diverse problems. Although
the computational capabilities of neural networks are determined by their
structure, the current understanding of the relationships between a neural
network's architecture and function is still primitive. Here we reveal that
neural network's modular architecture plays a vital role in determining the
neural dynamics and memory performance of the network of threshold neurons. In
particular, we demonstrate that there exists an optimal modularity for memory
performance, where a balance between local cohesion and global connectivity is
established, allowing optimally modular networks to remember longer. Our
results suggest that insights from dynamical analysis of neural networks and
information spreading processes can be leveraged to better design neural
networks and may shed light on the brain's modular organization.
-
Combining deep neural networks with structured logic rules is desirable to
harness flexibility and reduce uninterpretability of the neural models. We
propose a general framework capable of enhancing various types of neural
networks (e.g., CNNs and RNNs) with declarative first-order logic rules.
Specifically, we develop an iterative distillation method that transfers the
structured information of logic rules into the weights of neural networks. We
deploy the framework on a CNN for sentiment analysis, and an RNN for named
entity recognition. With a few highly intuitive rules, we obtain substantial
improvements and achieve state-of-the-art or comparable results to previous
best-performing systems.
-
Because preferences naturally arise and play an important role in many
real-life decisions, they are at the backbone of various fields. In particular
preferences are increasingly used in almost all matching procedures-based
applications. In this work we highlight the benefit of using AI insights on
preferences in a large scale application, namely the French Admission
Post-Baccalaureat Platform (APB). Each year APB allocates hundreds of thousands
first year applicants to universities. This is done automatically by matching
applicants preferences to university seats. In practice, APB can be unable to
distinguish between applicants which leads to the introduction of random
selection. This has created frustration in the French public since randomness,
even used as a last mean does not fare well with the republican egalitarian
principle. In this work, we provide a solution to this problem. We take
advantage of recent AI Preferences Theory results to show how to enhance APB in
order to improve expressiveness of applicants preferences and reduce their
exposure to random decisions.
-
We consider the problem of rational uncertainty about unproven mathematical
statements, remarked on by G\"odel and others. Using Bayesian-inspired
arguments we build a normative model of fair bets under deductive uncertainty
which draws from both probability and the theory of algorithms. We comment on
connections to Zeilberger's notion of "semi-rigorous proofs", particularly that
inherent subjectivity would be present. We also discuss a financial view with
models of arbitrage where traders have limited computational resources.
-
In many scientific and engineering applications, we are tasked with the
maximisation of an expensive to evaluate black box function $f$. Traditional
settings for this problem assume just the availability of this single function.
However, in many cases, cheap approximations to $f$ may be obtainable. For
example, the expensive real world behaviour of a robot can be approximated by a
cheap computer simulation. We can use these approximations to eliminate low
function value regions cheaply and use the expensive evaluations of $f$ in a
small but promising region and speedily identify the optimum. We formalise this
task as a \emph{multi-fidelity} bandit problem where the target function and
its approximations are sampled from a Gaussian process. We develop MF-GP-UCB, a
novel method based on upper confidence bound techniques. In our theoretical
analysis we demonstrate that it exhibits precisely the above behaviour, and
achieves better regret than strategies which ignore multi-fidelity information.
Empirically, MF-GP-UCB outperforms such naive strategies and other
multi-fidelity methods on several synthetic and real experiments.
-
In order to have effective human-AI collaboration, it is necessary to address
how the AI agent's behavior is being perceived by the humans-in-the-loop. When
the agent's task plans are generated without such considerations, they may
often demonstrate inexplicable behavior from the human's point of view. This
problem may arise due to the human's partial or inaccurate understanding of the
agent's planning model. This may have serious implications from increased
cognitive load to more serious concerns of safety around a physical agent. In
this paper, we address this issue by modeling plan explicability as a function
of the distance between a plan that agent makes and the plan that human expects
it to make. We learn a regression model for mapping the plan distances to
explicability scores of plans and develop an anytime search algorithm that can
use this model as a heuristic to come up with progressively explicable plans.
We evaluate the effectiveness of our approach in a simulated autonomous car
domain and a physical robot domain.
-
Given an environment with continuous state spaces and discrete actions, we
investigate using a Double Deep Q-learning Reinforcement Agent to find optimal
policies using the LunarLander-v2 OpenAI gym environment.
-
We propose a simple yet effective technique for neural network learning. The
forward propagation is computed as usual. In back propagation, only a small
subset of the full gradient is computed to update the model parameters. The
gradient vectors are sparsified in such a way that only the top-$k$ elements
(in terms of magnitude) are kept. As a result, only $k$ rows or columns
(depending on the layout) of the weight matrix are modified, leading to a
linear reduction ($k$ divided by the vector dimension) in the computational
cost. Surprisingly, experimental results demonstrate that we can update only
1-4% of the weights at each back propagation pass. This does not result in a
larger number of training iterations. More interestingly, the accuracy of the
resulting models is actually improved rather than degraded, and a detailed
analysis is given. The code is available at https://github.com/lancopku/meProp
-
We study the use of randomized value functions to guide deep exploration in
reinforcement learning. This offers an elegant means for synthesizing
statistically and computationally efficient exploration with common practical
approaches to value function learning. We present several reinforcement
learning algorithms that leverage randomized value functions and demonstrate
their efficacy through computational studies. We also prove a regret bound that
establishes statistical efficiency with a tabular representation.
-
Macro-management is an important problem in StarCraft, which has been studied
for a long time. Various datasets together with assorted methods have been
proposed in the last few years. But these datasets have some defects for
boosting the academic and industrial research: 1) There're neither standard
preprocessing, parsing and feature extraction procedures nor predefined
training, validation and test set in some datasets. 2) Some datasets are only
specified for certain tasks in macro-management. 3) Some datasets are either
too small or don't have enough labeled data for modern machine learning
algorithms such as deep neural networks. So most previous methods are trained
with various features, evaluated on different test sets from the same or
different datasets, making it difficult to be compared directly. To boost the
research of macro-management in StarCraft, we release a new dataset MSC based
on the platform SC2LE. MSC consists of well-designed feature vectors,
pre-defined high-level actions and final result of each match. We also split
MSC into training, validation and test set for the convenience of evaluation
and comparison. Besides the dataset, we propose a baseline model and present
initial baseline results for global state evaluation and build order
prediction, which are two of the key tasks in macro-management. Various
downstream tasks and analyses of the dataset are also described for the sake of
research on macro-management in StarCraft II. Homepage:
https://github.com/wuhuikai/MSC.
-
Probabilistic forecasting, i.e. estimating the probability distribution of a
time series' future given its past, is a key enabler for optimizing business
processes. In retail businesses, for example, forecasting demand is crucial for
having the right inventory available at the right time at the right place. In
this paper we propose DeepAR, a methodology for producing accurate
probabilistic forecasts, based on training an auto regressive recurrent network
model on a large number of related time series. We demonstrate how by applying
deep learning techniques to forecasting, one can overcome many of the
challenges faced by widely-used classical approaches to the problem. We show
through extensive empirical evaluation on several real-world forecasting data
sets accuracy improvements of around 15% compared to state-of-the-art methods.
-
A descriptive approach for automatic generation of visual blends is
presented. The implemented system, the Blender, is composed of two components:
the Mapper and the Visual Blender. The approach uses structured visual
representations along with sets of visual relations which describe how the
elements (in which the visual representation can be decomposed) relate among
each other. Our system is a hybrid blender, as the blending process starts at
the Mapper (conceptual level) and ends at the Visual Blender (visual
representation level). The experimental results show that the Blender is able
to create analogies from input mental spaces and produce well-composed blends,
which follow the rules imposed by its base-analogy and its relations. The
resulting blends are visually interesting and some can be considered as
unexpected.
-
In this article, we review recent Deep Learning advances in the context of
how they have been applied to play different types of video games such as
first-person shooters, arcade games, and real-time strategy games. We analyze
the unique requirements that different game genres pose to a deep learning
system and highlight important open challenges in the context of applying these
machine learning methods to video games, such as general game playing, dealing
with extremely large decision spaces and sparse rewards.
-
Learning based on networks of real neurons, and by extension biologically
inspired models of neural networks, has yet to find general learning rules
leading to widespread applications. In this paper, we argue for the existence
of a principle allowing to steer the dynamics of a biologically inspired neural
network. Using carefully timed external stimulation, the network can be driven
towards a desired dynamical state. We term this principle "Learning by
Stimulation Avoidance" (LSA). We demonstrate through simulation that the
minimal sufficient conditions leading to LSA in artificial networks are also
sufficient to reproduce learning results similar to those obtained in
biological neurons by Shahaf and Marom [1]. We examine the mechanism's basic
dynamics in a reduced network, and demonstrate how it scales up to a network of
100 neurons. We show that LSA has a higher explanatory power than existing
hypotheses about the response of biological neural networks to external
simulation, and can be used as a learning rule for an embodied application:
learning of wall avoidance by a simulated robot. The surge in popularity of
artificial neural networks is mostly directed to disembodied models of neurons
with biologically irrelevant dynamics: to the authors' knowledge, this is the
first work demonstrating sensory-motor learning with random spiking networks
through pure Hebbian learning.
-
When using reinforcement learning (RL) algorithms it is common, given a large
state space, to introduce some form of approximation architecture for the value
function (VF). The exact form of this architecture can have a significant
effect on an agent's performance, however, and determining a suitable
approximation architecture can often be a highly complex task. Consequently
there is currently interest among researchers in the potential for allowing RL
algorithms to adaptively generate (i.e. to learn) approximation architectures.
One relatively unexplored method of adapting approximation architectures
involves using feedback regarding the frequency with which an agent has visited
certain states to guide which areas of the state space to approximate with
greater detail. In this article we will: (a) informally discuss the potential
advantages offered by such methods; (b) introduce a new algorithm based on such
methods which adapts a state aggregation approximation architecture on-line and
is designed for use in conjunction with SARSA; (c) provide theoretical results,
in a policy evaluation setting, regarding this particular algorithm's
complexity, convergence properties and potential to reduce VF error; and
finally (d) test experimentally the extent to which this algorithm can improve
performance given a number of different test problems. Taken together our
results suggest that our algorithm (and potentially such methods more
generally) can provide a versatile and computationally lightweight means of
significantly boosting RL performance given suitable conditions which are
commonly encountered in practice.
-
Sequential data modeling and analysis have become indispensable tools for
analyzing sequential data, such as time-series data, because larger amounts of
sensed event data have become available. These methods capture the sequential
structure of data of interest, such as input-output relations and correlation
among datasets. However, because most studies in this area are specialized or
limited to their respective applications, rigorous requirement analysis of such
models has not been undertaken from a general perspective. Therefore, we
particularly examine the structure of sequential data, and extract the
necessity of `state duration' and `state interval' of events for efficient and
rich representation of sequential data. Specifically addressing the hidden
semi-Markov model (HSMM) that represents such state duration inside a model, we
attempt to add representational capability of a state interval of events onto
HSMM. To this end, we propose two extended models: an interval state hidden
semi-Markov model (IS-HSMM) to express the length of a state interval with a
special state node designated as "interval state node"; and an interval length
probability hidden semi-Markov model (ILP-HSMM) which represents the length of
the state interval with a new probabilistic parameter "interval length
probability." Exhaustive simulations have revealed superior performance of the
proposed models in comparison with HSMM. These proposed models are the first
reported extensions of HMM to support state interval representation as well as
state duration representation.
-
Graph based semi-supervised learning (GSSL) has intuitive representation and
can be improved by exploiting the matrix calculation. However, it has to
perform iterative optimization to achieve a preset objective, which usually
leads to low efficiency. Another inconvenience lying in GSSL is that when new
data come, the graph construction and the optimization have to be conducted all
over again. We propose a sound assumption, arguing that: the neighboring data
points are not in peer-to-peer relation, but in a partial-ordered relation
induced by the local density and distance between the data; and the label of a
center can be regarded as the contribution of its followers. Starting from the
assumption, we develop a highly efficient non-iterative label propagation
algorithm based on a novel data structure named as optimal leading forest
(LaPOLeaF). The major weaknesses of the traditional GSSL are addressed by this
study. We further scale LaPOLeaF to accommodate big data by utilizing block
distance matrix technique, parallel computing, and Locality-Sensitive Hashing
(LSH). Experiments on large datasets have shown the promising results of the
proposed methods.
-
The notions of disintegration and Bayesian inversion are fundamental in
conditional probability theory. They produce channels, as conditional
probabilities, from a joint state, or from an already given channel (in
opposite direction). These notions exist in the literature, in concrete
situations, but are presented here in abstract graphical formulations. The
resulting abstract descriptions are used for proving basic results in
conditional probability theory. The existence of disintegration and Bayesian
inversion is discussed for discrete probability, and also for measure-theoretic
probability --- via standard Borel spaces and via likelihoods. Finally, the
usefulness of disintegration and Bayesian inversion is illustrated in several
examples.
-
We introduce a neural architecture for navigation in novel environments. Our
proposed architecture learns to map from first-person views and plans a
sequence of actions towards goals in the environment. The Cognitive Mapper and
Planner (CMP) is based on two key ideas: a) a unified joint architecture for
mapping and planning, such that the mapping is driven by the needs of the task,
and b) a spatial memory with the ability to plan given an incomplete set of
observations about the world. CMP constructs a top-down belief map of the world
and applies a differentiable neural net planner to produce the next action at
each time step. The accumulated belief of the world enables the agent to track
visited regions of the environment. We train and test CMP on navigation
problems in simulation environments derived from scans of real world buildings.
Our experiments demonstrate that CMP outperforms alternate learning-based
architectures, as well as, classical mapping and path planning approaches in
many cases. Furthermore, it naturally extends to semantically specified goals,
such as 'going to a chair'. We also deploy CMP on physical robots in indoor
environments, where it achieves reasonable performance, even though it is
trained entirely in simulation.
-
This paper provides an analysis of the tradeoff between asymptotic bias
(suboptimality with unlimited data) and overfitting (additional suboptimality
due to limited data) in the context of reinforcement learning with partial
observability. Our theoretical analysis formally characterizes that while
potentially increasing the asymptotic bias, a smaller state representation
decreases the risk of overfitting. This analysis relies on expressing the
quality of a state representation by bounding L1 error terms of the associated
belief states. Theoretical results are empirically illustrated when the state
representation is a truncated history of observations, both on synthetic POMDPs
and on a large-scale POMDP in the context of smartgrids, with real-world data.
Finally, similarly to known results in the fully observable setting, we also
briefly discuss and empirically illustrate how using function approximators and
adapting the discount factor may enhance the tradeoff between asymptotic bias
and overfitting in the partially observable context.
-
Human action recognition refers to automatic recognizing human actions from a
video clip. In reality, there often exist multiple human actions in a video
stream. Such a video stream is often weakly-annotated with a set of relevant
human action labels at a global level rather than assigning each label to a
specific video episode corresponding to a single action, which leads to a
multi-label learning problem. Furthermore, there are many meaningful human
actions in reality but it would be extremely difficult to collect/annotate
video clips regarding all of various human actions, which leads to a zero-shot
learning scenario. To the best of our knowledge, there is no work that has
addressed all the above issues together in human action recognition. In this
paper, we formulate a real-world human action recognition task as a multi-label
zero-shot learning problem and propose a framework to tackle this problem in a
holistic way. Our framework holistically tackles the issue of unknown temporal
boundaries between different actions for multi-label learning and exploits the
side information regarding the semantic relationship between different human
actions for knowledge transfer. Consequently, our framework leads to a joint
latent ranking embedding for multi-label zero-shot human action recognition. A
novel neural architecture of two component models and an alternate learning
algorithm are proposed to carry out the joint latent ranking embedding
learning. Thus, multi-label zero-shot recognition is done by measuring
relatedness scores of action labels to a test video clip in the joint latent
visual and semantic embedding spaces. We evaluate our framework with different
settings, including a novel data split scheme designed especially for
evaluating multi-label zero-shot learning, on two datasets: Breakfast and
Charades. The experimental results demonstrate the effectiveness of our
framework.
-
Bayesian optimization has become a fundamental global optimization algorithm
in many problems where sample efficiency is of paramount importance. Recently,
there has been proposed a large number of new applications in fields such as
robotics, machine learning, experimental design, simulation, etc. In this
paper, we focus on several problems that appear in robotics and autonomous
systems: algorithm tuning, automatic control and intelligent design. All those
problems can be mapped to global optimization problems. However, they become
hard optimization problems. Bayesian optimization internally uses a
probabilistic surrogate model (e.g.: Gaussian process) to learn from the
process and reduce the number of samples required. In order to generalize to
unknown functions in a black-box fashion, the common assumption is that the
underlying function can be modeled with a stationary process. Nonstationary
Gaussian process regression cannot generalize easily and it typically requires
prior knowledge of the function. Some works have designed techniques to
generalize Bayesian optimization to nonstationary functions in an indirect way,
but using techniques originally designed for regression, where the objective is
to improve the quality of the surrogate model everywhere. Instead optimization
should focus on improving the surrogate model near the optimum. In this paper,
we present a novel kernel function specially designed for Bayesian
optimization, that allows nonstationary behavior of the surrogate model in an
adaptive local region. In our experiments, we found that this new kernel
results in an improved local search (exploitation), without penalizing the
global search (exploration). We provide results in well-known benchmarks and
real applications. The new method outperforms the state of the art in Bayesian
optimization both in stationary and nonstationary problems.
-
We present a novel framework for the automatic discovery and recognition of
motion primitives in videos of human activities. Given the 3D pose of a human
in a video, human motion primitives are discovered by optimizing the `motion
flux', a quantity which captures the motion variation of a group of skeletal
joints. A normalization of the primitives is proposed in order to make them
invariant with respect to a subject anatomical variations and data sampling
rate. The discovered primitives are unknown and unlabeled and are
unsupervisedly collected into classes via a hierarchical non-parametric Bayes
mixture model. Once classes are determined and labeled they are further
analyzed for establishing models for recognizing discovered primitives. Each
primitive model is defined by a set of learned parameters.
Given new video data and given the estimated pose of the subject appearing on
the video, the motion is segmented into primitives, which are recognized with a
probability given according to the parameters of the learned models.
Using our framework we build a publicly available dataset of human motion
primitives, using sequences taken from well-known motion capture datasets. We
expect that our framework, by providing an objective way for discovering and
categorizing human motion, will be a useful tool in numerous research fields
including video analysis, human inspired motion generation, learning by
demonstration, intuitive human-robot interaction, and human behavior analysis.
-
Multiple automakers have in development or in production automated driving
systems (ADS) that offer freeway-pilot functions. This type of ADS is typically
limited to restricted-access freeways only, that is, the transition from manual
to automated modes takes place only after the ramp merging process is completed
manually. One major challenge to extend the automation to ramp merging is that
the automated vehicle needs to incorporate and optimize long-term objectives
(e.g. successful and smooth merge) when near-term actions must be safely
executed. Moreover, the merging process involves interactions with other
vehicles whose behaviors are sometimes hard to predict but may influence the
merging vehicle optimal actions. To tackle such a complicated control problem,
we propose to apply Deep Reinforcement Learning (DRL) techniques for finding an
optimal driving policy by maximizing the long-term reward in an interactive
environment. Specifically, we apply a Long Short-Term Memory (LSTM)
architecture to model the interactive environment, from which an internal state
containing historical driving information is conveyed to a Deep Q-Network
(DQN). The DQN is used to approximate the Q-function, which takes the internal
state as input and generates Q-values as output for action selection. With this
DRL architecture, the historical impact of interactive environment on the
long-term reward can be captured and taken into account for deciding the
optimal control policy. The proposed architecture has the potential to be
extended and applied to other autonomous driving scenarios such as driving
through a complex intersection or changing lanes under varying traffic flow
conditions.
-
The fixed parameter tractable (FPT) approach is a powerful tool in tackling
computationally hard problems. In this paper, we link FPT results to classic
artificial intelligence (AI) techniques to show how they complement each other.
Specifically, we consider the workflow satisfiability problem (WSP) which asks
whether there exists an assignment of authorised users to the steps in a
workflow specification, subject to certain constraints on the assignment. It
was shown by Cohen et al. (JAIR 2014) that WSP restricted to the class of
user-independent constraints (UI), covering many practical cases, admits FPT
algorithms, i.e. can be solved in time exponential only in the number of steps
$k$ and polynomial in the number of users $n$. Since usually $k << n$ in WSP,
such FPT algorithms are of great practical interest. We present a new
interpretation of the FPT nature of the WSP with UI constraints giving a
decomposition of the problem into two levels. Exploiting this two-level split,
we develop a new FPT algorithm that is by many orders of magnitude faster than
the previous state-of-the-art WSP algorithm and also has only polynomial-space
complexity. We also introduce new pseudo-Boolean (PB) and Constraint
Satisfaction (CSP) formulations of the WSP with UI constraints which
efficiently exploit this new decomposition of the problem and raise the novel
issue of how to use general-purpose solvers to tackle FPT problems in a fashion
that meets FPT efficiency expectations. In our computational study, we
investigate, for the first time, the phase transition (PT) properties of the
WSP, under a model for generation of random instances. We show how PT studies
can be extended, in a novel fashion, to support empirical evaluation of scaling
of FPT algorithms.



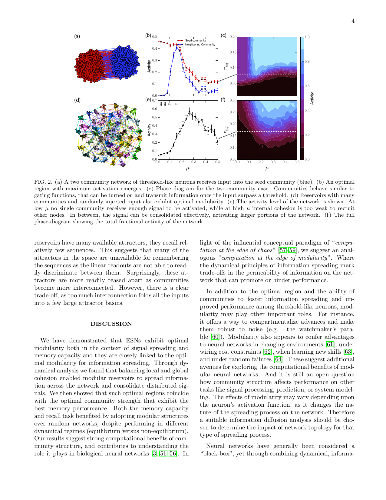
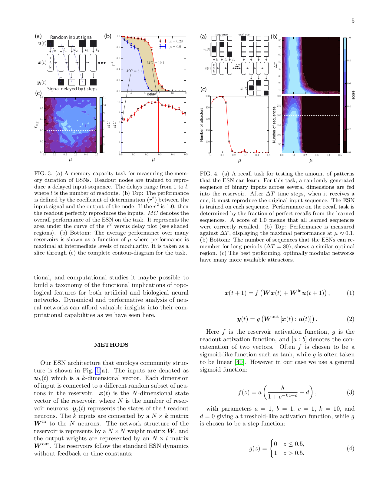
 The neural network is a powerful computing framework that has been exploited by biological evolution and by humans for solving diverse problems. Although the computational capabilities of neural networks are determined by their structure, the current understanding of the relationships between a neural network's architecture and function is still primitive. Here we reveal that neural network's modular architecture plays a vital role in determining the neural dynamics and memory performance of the network of threshold neurons. In particular, we demonstrate that there exists an optimal modularity for memory performance, where a balance between local cohesion and global connectivity is established, allowing optimally modular networks to remember longer. Our results suggest that insights from dynamical analysis of neural networks and information spreading processes can be leveraged to better design neural networks and may shed light on the brain's modular organization.
The neural network is a powerful computing framework that has been exploited by biological evolution and by humans for solving diverse problems. Although the computational capabilities of neural networks are determined by their structure, the current understanding of the relationships between a neural network's architecture and function is still primitive. Here we reveal that neural network's modular architecture plays a vital role in determining the neural dynamics and memory performance of the network of threshold neurons. In particular, we demonstrate that there exists an optimal modularity for memory performance, where a balance between local cohesion and global connectivity is established, allowing optimally modular networks to remember longer. Our results suggest that insights from dynamical analysis of neural networks and information spreading processes can be leveraged to better design neural networks and may shed light on the brain's modular organization.




 Combining deep neural networks with structured logic rules is desirable to harness flexibility and reduce uninterpretability of the neural models. We propose a general framework capable of enhancing various types of neural networks (e.g., CNNs and RNNs) with declarative first-order logic rules. Specifically, we develop an iterative distillation method that transfers the structured information of logic rules into the weights of neural networks. We deploy the framework on a CNN for sentiment analysis, and an RNN for named entity recognition. With a few highly intuitive rules, we obtain substantial improvements and achieve state-of-the-art or comparable results to previous best-performing systems.
Combining deep neural networks with structured logic rules is desirable to harness flexibility and reduce uninterpretability of the neural models. We propose a general framework capable of enhancing various types of neural networks (e.g., CNNs and RNNs) with declarative first-order logic rules. Specifically, we develop an iterative distillation method that transfers the structured information of logic rules into the weights of neural networks. We deploy the framework on a CNN for sentiment analysis, and an RNN for named entity recognition. With a few highly intuitive rules, we obtain substantial improvements and achieve state-of-the-art or comparable results to previous best-performing systems.




 Because preferences naturally arise and play an important role in many real-life decisions, they are at the backbone of various fields. In particular preferences are increasingly used in almost all matching procedures-based applications. In this work we highlight the benefit of using AI insights on preferences in a large scale application, namely the French Admission Post-Baccalaureat Platform (APB). Each year APB allocates hundreds of thousands first year applicants to universities. This is done automatically by matching applicants preferences to university seats. In practice, APB can be unable to distinguish between applicants which leads to the introduction of random selection. This has created frustration in the French public since randomness, even used as a last mean does not fare well with the republican egalitarian principle. In this work, we provide a solution to this problem. We take advantage of recent AI Preferences Theory results to show how to enhance APB in order to improve expressiveness of applicants preferences and reduce their exposure to random decisions.
Because preferences naturally arise and play an important role in many real-life decisions, they are at the backbone of various fields. In particular preferences are increasingly used in almost all matching procedures-based applications. In this work we highlight the benefit of using AI insights on preferences in a large scale application, namely the French Admission Post-Baccalaureat Platform (APB). Each year APB allocates hundreds of thousands first year applicants to universities. This is done automatically by matching applicants preferences to university seats. In practice, APB can be unable to distinguish between applicants which leads to the introduction of random selection. This has created frustration in the French public since randomness, even used as a last mean does not fare well with the republican egalitarian principle. In this work, we provide a solution to this problem. We take advantage of recent AI Preferences Theory results to show how to enhance APB in order to improve expressiveness of applicants preferences and reduce their exposure to random decisions.




 We consider the problem of rational uncertainty about unproven mathematical statements, remarked on by G\"odel and others. Using Bayesian-inspired arguments we build a normative model of fair bets under deductive uncertainty which draws from both probability and the theory of algorithms. We comment on connections to Zeilberger's notion of "semi-rigorous proofs", particularly that inherent subjectivity would be present. We also discuss a financial view with models of arbitrage where traders have limited computational resources.
We consider the problem of rational uncertainty about unproven mathematical statements, remarked on by G\"odel and others. Using Bayesian-inspired arguments we build a normative model of fair bets under deductive uncertainty which draws from both probability and the theory of algorithms. We comment on connections to Zeilberger's notion of "semi-rigorous proofs", particularly that inherent subjectivity would be present. We also discuss a financial view with models of arbitrage where traders have limited computational resources.



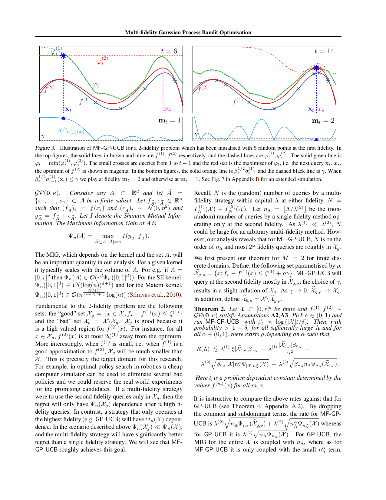
 In many scientific and engineering applications, we are tasked with the maximisation of an expensive to evaluate black box function $f$. Traditional settings for this problem assume just the availability of this single function. However, in many cases, cheap approximations to $f$ may be obtainable. For example, the expensive real world behaviour of a robot can be approximated by a cheap computer simulation. We can use these approximations to eliminate low function value regions cheaply and use the expensive evaluations of $f$ in a small but promising region and speedily identify the optimum. We formalise this task as a \emph{multi-fidelity} bandit problem where the target function and its approximations are sampled from a Gaussian process. We develop MF-GP-UCB, a novel method based on upper confidence bound techniques. In our theoretical analysis we demonstrate that it exhibits precisely the above behaviour, and achieves better regret than strategies which ignore multi-fidelity information. Empirically, MF-GP-UCB outperforms such naive strategies and other multi-fidelity methods on several synthetic and real experiments.
In many scientific and engineering applications, we are tasked with the maximisation of an expensive to evaluate black box function $f$. Traditional settings for this problem assume just the availability of this single function. However, in many cases, cheap approximations to $f$ may be obtainable. For example, the expensive real world behaviour of a robot can be approximated by a cheap computer simulation. We can use these approximations to eliminate low function value regions cheaply and use the expensive evaluations of $f$ in a small but promising region and speedily identify the optimum. We formalise this task as a \emph{multi-fidelity} bandit problem where the target function and its approximations are sampled from a Gaussian process. We develop MF-GP-UCB, a novel method based on upper confidence bound techniques. In our theoretical analysis we demonstrate that it exhibits precisely the above behaviour, and achieves better regret than strategies which ignore multi-fidelity information. Empirically, MF-GP-UCB outperforms such naive strategies and other multi-fidelity methods on several synthetic and real experiments.




 In order to have effective human-AI collaboration, it is necessary to address how the AI agent's behavior is being perceived by the humans-in-the-loop. When the agent's task plans are generated without such considerations, they may often demonstrate inexplicable behavior from the human's point of view. This problem may arise due to the human's partial or inaccurate understanding of the agent's planning model. This may have serious implications from increased cognitive load to more serious concerns of safety around a physical agent. In this paper, we address this issue by modeling plan explicability as a function of the distance between a plan that agent makes and the plan that human expects it to make. We learn a regression model for mapping the plan distances to explicability scores of plans and develop an anytime search algorithm that can use this model as a heuristic to come up with progressively explicable plans. We evaluate the effectiveness of our approach in a simulated autonomous car domain and a physical robot domain.
In order to have effective human-AI collaboration, it is necessary to address how the AI agent's behavior is being perceived by the humans-in-the-loop. When the agent's task plans are generated without such considerations, they may often demonstrate inexplicable behavior from the human's point of view. This problem may arise due to the human's partial or inaccurate understanding of the agent's planning model. This may have serious implications from increased cognitive load to more serious concerns of safety around a physical agent. In this paper, we address this issue by modeling plan explicability as a function of the distance between a plan that agent makes and the plan that human expects it to make. We learn a regression model for mapping the plan distances to explicability scores of plans and develop an anytime search algorithm that can use this model as a heuristic to come up with progressively explicable plans. We evaluate the effectiveness of our approach in a simulated autonomous car domain and a physical robot domain.




 We study the use of randomized value functions to guide deep exploration in reinforcement learning. This offers an elegant means for synthesizing statistically and computationally efficient exploration with common practical approaches to value function learning. We present several reinforcement learning algorithms that leverage randomized value functions and demonstrate their efficacy through computational studies. We also prove a regret bound that establishes statistical efficiency with a tabular representation.
We study the use of randomized value functions to guide deep exploration in reinforcement learning. This offers an elegant means for synthesizing statistically and computationally efficient exploration with common practical approaches to value function learning. We present several reinforcement learning algorithms that leverage randomized value functions and demonstrate their efficacy through computational studies. We also prove a regret bound that establishes statistical efficiency with a tabular representation.




 Probabilistic forecasting, i.e. estimating the probability distribution of a time series' future given its past, is a key enabler for optimizing business processes. In retail businesses, for example, forecasting demand is crucial for having the right inventory available at the right time at the right place. In this paper we propose DeepAR, a methodology for producing accurate probabilistic forecasts, based on training an auto regressive recurrent network model on a large number of related time series. We demonstrate how by applying deep learning techniques to forecasting, one can overcome many of the challenges faced by widely-used classical approaches to the problem. We show through extensive empirical evaluation on several real-world forecasting data sets accuracy improvements of around 15% compared to state-of-the-art methods.
Probabilistic forecasting, i.e. estimating the probability distribution of a time series' future given its past, is a key enabler for optimizing business processes. In retail businesses, for example, forecasting demand is crucial for having the right inventory available at the right time at the right place. In this paper we propose DeepAR, a methodology for producing accurate probabilistic forecasts, based on training an auto regressive recurrent network model on a large number of related time series. We demonstrate how by applying deep learning techniques to forecasting, one can overcome many of the challenges faced by widely-used classical approaches to the problem. We show through extensive empirical evaluation on several real-world forecasting data sets accuracy improvements of around 15% compared to state-of-the-art methods.




 In this article, we review recent Deep Learning advances in the context of how they have been applied to play different types of video games such as first-person shooters, arcade games, and real-time strategy games. We analyze the unique requirements that different game genres pose to a deep learning system and highlight important open challenges in the context of applying these machine learning methods to video games, such as general game playing, dealing with extremely large decision spaces and sparse rewards.
In this article, we review recent Deep Learning advances in the context of how they have been applied to play different types of video games such as first-person shooters, arcade games, and real-time strategy games. We analyze the unique requirements that different game genres pose to a deep learning system and highlight important open challenges in the context of applying these machine learning methods to video games, such as general game playing, dealing with extremely large decision spaces and sparse rewards.


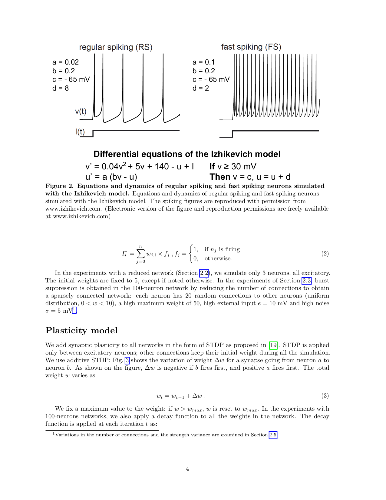
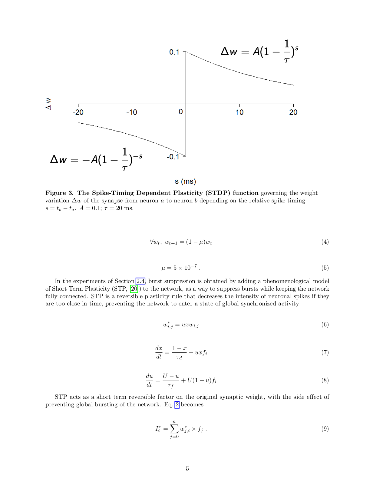
 Learning based on networks of real neurons, and by extension biologically inspired models of neural networks, has yet to find general learning rules leading to widespread applications. In this paper, we argue for the existence of a principle allowing to steer the dynamics of a biologically inspired neural network. Using carefully timed external stimulation, the network can be driven towards a desired dynamical state. We term this principle "Learning by Stimulation Avoidance" (LSA). We demonstrate through simulation that the minimal sufficient conditions leading to LSA in artificial networks are also sufficient to reproduce learning results similar to those obtained in biological neurons by Shahaf and Marom [1]. We examine the mechanism's basic dynamics in a reduced network, and demonstrate how it scales up to a network of 100 neurons. We show that LSA has a higher explanatory power than existing hypotheses about the response of biological neural networks to external simulation, and can be used as a learning rule for an embodied application: learning of wall avoidance by a simulated robot. The surge in popularity of artificial neural networks is mostly directed to disembodied models of neurons with biologically irrelevant dynamics: to the authors' knowledge, this is the first work demonstrating sensory-motor learning with random spiking networks through pure Hebbian learning.
Learning based on networks of real neurons, and by extension biologically inspired models of neural networks, has yet to find general learning rules leading to widespread applications. In this paper, we argue for the existence of a principle allowing to steer the dynamics of a biologically inspired neural network. Using carefully timed external stimulation, the network can be driven towards a desired dynamical state. We term this principle "Learning by Stimulation Avoidance" (LSA). We demonstrate through simulation that the minimal sufficient conditions leading to LSA in artificial networks are also sufficient to reproduce learning results similar to those obtained in biological neurons by Shahaf and Marom [1]. We examine the mechanism's basic dynamics in a reduced network, and demonstrate how it scales up to a network of 100 neurons. We show that LSA has a higher explanatory power than existing hypotheses about the response of biological neural networks to external simulation, and can be used as a learning rule for an embodied application: learning of wall avoidance by a simulated robot. The surge in popularity of artificial neural networks is mostly directed to disembodied models of neurons with biologically irrelevant dynamics: to the authors' knowledge, this is the first work demonstrating sensory-motor learning with random spiking networks through pure Hebbian learning.




 When using reinforcement learning (RL) algorithms it is common, given a large state space, to introduce some form of approximation architecture for the value function (VF). The exact form of this architecture can have a significant effect on an agent's performance, however, and determining a suitable approximation architecture can often be a highly complex task. Consequently there is currently interest among researchers in the potential for allowing RL algorithms to adaptively generate (i.e. to learn) approximation architectures. One relatively unexplored method of adapting approximation architectures involves using feedback regarding the frequency with which an agent has visited certain states to guide which areas of the state space to approximate with greater detail. In this article we will: (a) informally discuss the potential advantages offered by such methods; (b) introduce a new algorithm based on such methods which adapts a state aggregation approximation architecture on-line and is designed for use in conjunction with SARSA; (c) provide theoretical results, in a policy evaluation setting, regarding this particular algorithm's complexity, convergence properties and potential to reduce VF error; and finally (d) test experimentally the extent to which this algorithm can improve performance given a number of different test problems. Taken together our results suggest that our algorithm (and potentially such methods more generally) can provide a versatile and computationally lightweight means of significantly boosting RL performance given suitable conditions which are commonly encountered in practice.
When using reinforcement learning (RL) algorithms it is common, given a large state space, to introduce some form of approximation architecture for the value function (VF). The exact form of this architecture can have a significant effect on an agent's performance, however, and determining a suitable approximation architecture can often be a highly complex task. Consequently there is currently interest among researchers in the potential for allowing RL algorithms to adaptively generate (i.e. to learn) approximation architectures. One relatively unexplored method of adapting approximation architectures involves using feedback regarding the frequency with which an agent has visited certain states to guide which areas of the state space to approximate with greater detail. In this article we will: (a) informally discuss the potential advantages offered by such methods; (b) introduce a new algorithm based on such methods which adapts a state aggregation approximation architecture on-line and is designed for use in conjunction with SARSA; (c) provide theoretical results, in a policy evaluation setting, regarding this particular algorithm's complexity, convergence properties and potential to reduce VF error; and finally (d) test experimentally the extent to which this algorithm can improve performance given a number of different test problems. Taken together our results suggest that our algorithm (and potentially such methods more generally) can provide a versatile and computationally lightweight means of significantly boosting RL performance given suitable conditions which are commonly encountered in practice.




 Sequential data modeling and analysis have become indispensable tools for analyzing sequential data, such as time-series data, because larger amounts of sensed event data have become available. These methods capture the sequential structure of data of interest, such as input-output relations and correlation among datasets. However, because most studies in this area are specialized or limited to their respective applications, rigorous requirement analysis of such models has not been undertaken from a general perspective. Therefore, we particularly examine the structure of sequential data, and extract the necessity of `state duration' and `state interval' of events for efficient and rich representation of sequential data. Specifically addressing the hidden semi-Markov model (HSMM) that represents such state duration inside a model, we attempt to add representational capability of a state interval of events onto HSMM. To this end, we propose two extended models: an interval state hidden semi-Markov model (IS-HSMM) to express the length of a state interval with a special state node designated as "interval state node"; and an interval length probability hidden semi-Markov model (ILP-HSMM) which represents the length of the state interval with a new probabilistic parameter "interval length probability." Exhaustive simulations have revealed superior performance of the proposed models in comparison with HSMM. These proposed models are the first reported extensions of HMM to support state interval representation as well as state duration representation.
Sequential data modeling and analysis have become indispensable tools for analyzing sequential data, such as time-series data, because larger amounts of sensed event data have become available. These methods capture the sequential structure of data of interest, such as input-output relations and correlation among datasets. However, because most studies in this area are specialized or limited to their respective applications, rigorous requirement analysis of such models has not been undertaken from a general perspective. Therefore, we particularly examine the structure of sequential data, and extract the necessity of `state duration' and `state interval' of events for efficient and rich representation of sequential data. Specifically addressing the hidden semi-Markov model (HSMM) that represents such state duration inside a model, we attempt to add representational capability of a state interval of events onto HSMM. To this end, we propose two extended models: an interval state hidden semi-Markov model (IS-HSMM) to express the length of a state interval with a special state node designated as "interval state node"; and an interval length probability hidden semi-Markov model (ILP-HSMM) which represents the length of the state interval with a new probabilistic parameter "interval length probability." Exhaustive simulations have revealed superior performance of the proposed models in comparison with HSMM. These proposed models are the first reported extensions of HMM to support state interval representation as well as state duration representation.




 We introduce a neural architecture for navigation in novel environments. Our proposed architecture learns to map from first-person views and plans a sequence of actions towards goals in the environment. The Cognitive Mapper and Planner (CMP) is based on two key ideas: a) a unified joint architecture for mapping and planning, such that the mapping is driven by the needs of the task, and b) a spatial memory with the ability to plan given an incomplete set of observations about the world. CMP constructs a top-down belief map of the world and applies a differentiable neural net planner to produce the next action at each time step. The accumulated belief of the world enables the agent to track visited regions of the environment. We train and test CMP on navigation problems in simulation environments derived from scans of real world buildings. Our experiments demonstrate that CMP outperforms alternate learning-based architectures, as well as, classical mapping and path planning approaches in many cases. Furthermore, it naturally extends to semantically specified goals, such as 'going to a chair'. We also deploy CMP on physical robots in indoor environments, where it achieves reasonable performance, even though it is trained entirely in simulation.
We introduce a neural architecture for navigation in novel environments. Our proposed architecture learns to map from first-person views and plans a sequence of actions towards goals in the environment. The Cognitive Mapper and Planner (CMP) is based on two key ideas: a) a unified joint architecture for mapping and planning, such that the mapping is driven by the needs of the task, and b) a spatial memory with the ability to plan given an incomplete set of observations about the world. CMP constructs a top-down belief map of the world and applies a differentiable neural net planner to produce the next action at each time step. The accumulated belief of the world enables the agent to track visited regions of the environment. We train and test CMP on navigation problems in simulation environments derived from scans of real world buildings. Our experiments demonstrate that CMP outperforms alternate learning-based architectures, as well as, classical mapping and path planning approaches in many cases. Furthermore, it naturally extends to semantically specified goals, such as 'going to a chair'. We also deploy CMP on physical robots in indoor environments, where it achieves reasonable performance, even though it is trained entirely in simulation.




 Bayesian optimization has become a fundamental global optimization algorithm in many problems where sample efficiency is of paramount importance. Recently, there has been proposed a large number of new applications in fields such as robotics, machine learning, experimental design, simulation, etc. In this paper, we focus on several problems that appear in robotics and autonomous systems: algorithm tuning, automatic control and intelligent design. All those problems can be mapped to global optimization problems. However, they become hard optimization problems. Bayesian optimization internally uses a probabilistic surrogate model (e.g.: Gaussian process) to learn from the process and reduce the number of samples required. In order to generalize to unknown functions in a black-box fashion, the common assumption is that the underlying function can be modeled with a stationary process. Nonstationary Gaussian process regression cannot generalize easily and it typically requires prior knowledge of the function. Some works have designed techniques to generalize Bayesian optimization to nonstationary functions in an indirect way, but using techniques originally designed for regression, where the objective is to improve the quality of the surrogate model everywhere. Instead optimization should focus on improving the surrogate model near the optimum. In this paper, we present a novel kernel function specially designed for Bayesian optimization, that allows nonstationary behavior of the surrogate model in an adaptive local region. In our experiments, we found that this new kernel results in an improved local search (exploitation), without penalizing the global search (exploration). We provide results in well-known benchmarks and real applications. The new method outperforms the state of the art in Bayesian optimization both in stationary and nonstationary problems.
Bayesian optimization has become a fundamental global optimization algorithm in many problems where sample efficiency is of paramount importance. Recently, there has been proposed a large number of new applications in fields such as robotics, machine learning, experimental design, simulation, etc. In this paper, we focus on several problems that appear in robotics and autonomous systems: algorithm tuning, automatic control and intelligent design. All those problems can be mapped to global optimization problems. However, they become hard optimization problems. Bayesian optimization internally uses a probabilistic surrogate model (e.g.: Gaussian process) to learn from the process and reduce the number of samples required. In order to generalize to unknown functions in a black-box fashion, the common assumption is that the underlying function can be modeled with a stationary process. Nonstationary Gaussian process regression cannot generalize easily and it typically requires prior knowledge of the function. Some works have designed techniques to generalize Bayesian optimization to nonstationary functions in an indirect way, but using techniques originally designed for regression, where the objective is to improve the quality of the surrogate model everywhere. Instead optimization should focus on improving the surrogate model near the optimum. In this paper, we present a novel kernel function specially designed for Bayesian optimization, that allows nonstationary behavior of the surrogate model in an adaptive local region. In our experiments, we found that this new kernel results in an improved local search (exploitation), without penalizing the global search (exploration). We provide results in well-known benchmarks and real applications. The new method outperforms the state of the art in Bayesian optimization both in stationary and nonstationary problems.




 The fixed parameter tractable (FPT) approach is a powerful tool in tackling computationally hard problems. In this paper, we link FPT results to classic artificial intelligence (AI) techniques to show how they complement each other. Specifically, we consider the workflow satisfiability problem (WSP) which asks whether there exists an assignment of authorised users to the steps in a workflow specification, subject to certain constraints on the assignment. It was shown by Cohen et al. (JAIR 2014) that WSP restricted to the class of user-independent constraints (UI), covering many practical cases, admits FPT algorithms, i.e. can be solved in time exponential only in the number of steps $k$ and polynomial in the number of users $n$. Since usually $k << n$ in WSP, such FPT algorithms are of great practical interest. We present a new interpretation of the FPT nature of the WSP with UI constraints giving a decomposition of the problem into two levels. Exploiting this two-level split, we develop a new FPT algorithm that is by many orders of magnitude faster than the previous state-of-the-art WSP algorithm and also has only polynomial-space complexity. We also introduce new pseudo-Boolean (PB) and Constraint Satisfaction (CSP) formulations of the WSP with UI constraints which efficiently exploit this new decomposition of the problem and raise the novel issue of how to use general-purpose solvers to tackle FPT problems in a fashion that meets FPT efficiency expectations. In our computational study, we investigate, for the first time, the phase transition (PT) properties of the WSP, under a model for generation of random instances. We show how PT studies can be extended, in a novel fashion, to support empirical evaluation of scaling of FPT algorithms.
The fixed parameter tractable (FPT) approach is a powerful tool in tackling computationally hard problems. In this paper, we link FPT results to classic artificial intelligence (AI) techniques to show how they complement each other. Specifically, we consider the workflow satisfiability problem (WSP) which asks whether there exists an assignment of authorised users to the steps in a workflow specification, subject to certain constraints on the assignment. It was shown by Cohen et al. (JAIR 2014) that WSP restricted to the class of user-independent constraints (UI), covering many practical cases, admits FPT algorithms, i.e. can be solved in time exponential only in the number of steps $k$ and polynomial in the number of users $n$. Since usually $k << n$ in WSP, such FPT algorithms are of great practical interest. We present a new interpretation of the FPT nature of the WSP with UI constraints giving a decomposition of the problem into two levels. Exploiting this two-level split, we develop a new FPT algorithm that is by many orders of magnitude faster than the previous state-of-the-art WSP algorithm and also has only polynomial-space complexity. We also introduce new pseudo-Boolean (PB) and Constraint Satisfaction (CSP) formulations of the WSP with UI constraints which efficiently exploit this new decomposition of the problem and raise the novel issue of how to use general-purpose solvers to tackle FPT problems in a fashion that meets FPT efficiency expectations. In our computational study, we investigate, for the first time, the phase transition (PT) properties of the WSP, under a model for generation of random instances. We show how PT studies can be extended, in a novel fashion, to support empirical evaluation of scaling of FPT algorithms.