-
This paper is a survey and an analysis of different ways of using deep
learning (deep artificial neural networks) to generate musical content. We
propose a methodology based on five dimensions for our analysis:
Objective - What musical content is to be generated? Examples are: melody,
polyphony, accompaniment or counterpoint. - For what destination and for what
use? To be performed by a human(s) (in the case of a musical score), or by a
machine (in the case of an audio file).
Representation - What are the concepts to be manipulated? Examples are:
waveform, spectrogram, note, chord, meter and beat. - What format is to be
used? Examples are: MIDI, piano roll or text. - How will the representation be
encoded? Examples are: scalar, one-hot or many-hot.
Architecture - What type(s) of deep neural network is (are) to be used?
Examples are: feedforward network, recurrent network, autoencoder or generative
adversarial networks.
Challenge - What are the limitations and open challenges? Examples are:
variability, interactivity and creativity.
Strategy - How do we model and control the process of generation? Examples
are: single-step feedforward, iterative feedforward, sampling or input
manipulation.
For each dimension, we conduct a comparative analysis of various models and
techniques and we propose some tentative multidimensional typology. This
typology is bottom-up, based on the analysis of many existing deep-learning
based systems for music generation selected from the relevant literature. These
systems are described and are used to exemplify the various choices of
objective, representation, architecture, challenge and strategy. The last
section includes some discussion and some prospects.
-
This paper introduces Gabor scattering, a feature extractor based on Gabor
frames and Mallat's scattering transform. By using a simple signal model for
audio signals specific properties of Gabor scattering are studied. It is shown
that for each layer, specific invariances to certain signal characteristics
occur. Furthermore, deformation stability of the coefficient vector generated
by the feature extractor is derived by using a decoupling technique which
exploits the contractivity of general scattering networks. Deformations are
introduced as changes in spectral shape and frequency modulation. The
theoretical results are illustrated by numerical examples and experiments.
Numerical evidence is given by evaluation on a synthetic and a "real" data set,
that the invariances encoded by the Gabor scattering transform lead to higher
performance in comparison with just using Gabor transform, especially when few
training samples are available.
-
OBJECTIVE: We aim to extract and denoise the attended speaker in a noisy,
two-speaker acoustic scenario, relying on microphone array recordings from a
binaural hearing aid, which are complemented with electroencephalography (EEG)
recordings to infer the speaker of interest. METHODS: In this study, we propose
a modular processing flow that first extracts the two speech envelopes from the
microphone recordings, then selects the attended speech envelope based on the
EEG, and finally uses this envelope to inform a multi-channel speech separation
and denoising algorithm. RESULTS: Strong suppression of interfering
(unattended) speech and background noise is achieved, while the attended speech
is preserved. Furthermore, EEG-based auditory attention detection (AAD) is
shown to be robust to the use of noisy speech signals. CONCLUSIONS: Our results
show that AAD-based speaker extraction from microphone array recordings is
feasible and robust, even in noisy acoustic environments, and without access to
the clean speech signals to perform EEG-based AAD. SIGNIFICANCE: Current
research on AAD always assumes the availability of the clean speech signals,
which limits the applicability in real settings. We have extended this research
to detect the attended speaker even when only microphone recordings with noisy
speech mixtures are available. This is an enabling ingredient for new
brain-computer interfaces and effective filtering schemes in neuro-steered
hearing prostheses. Here, we provide a first proof of concept for EEG-informed
attended speaker extraction and denoising.
-
The perception of consonance/dissonance of musical harmonies is strongly
correlated with their periodicity. This is shown in this article by
consistently applying recent results from psychophysics and neuroacoustics,
namely that the just noticeable difference between pitches for humans is about
1% for the musically important low frequency range and that periodicities of
complex chords can be detected in the human brain. Based thereon, the concepts
of relative and logarithmic periodicity with smoothing are introduced as
powerful measures of harmoniousness. The presented results correlate
significantly with empirical investigations on the perception of chords. Even
for scales, plausible results are obtained. For example, all classical church
modes appear in the front ranks of all theoretically possible seven-tone
scales.
-
Automatic music transcription (AMT) aims to infer a latent symbolic
representation of a piece of music (piano-roll), given a corresponding observed
audio recording. Transcribing polyphonic music (when multiple notes are played
simultaneously) is a challenging problem, due to highly structured overlapping
between harmonics. We study whether the introduction of physically inspired
Gaussian process (GP) priors into audio content analysis models improves the
extraction of patterns required for AMT. Audio signals are described as a
linear combination of sources. Each source is decomposed into the product of an
amplitude-envelope, and a quasi-periodic component process. We introduce the
Mat\'ern spectral mixture (MSM) kernel for describing frequency content of
singles notes. We consider two different regression approaches. In the sigmoid
model every pitch-activation is independently non-linear transformed. In the
softmax model several activation GPs are jointly non-linearly transformed. This
introduce cross-correlation between activations. We use variational Bayes for
approximate inference. We empirically evaluate how these models work in
practice transcribing polyphonic music. We demonstrate that rather than
encourage dependency between activations, what is relevant for improving pitch
detection is to learnt priors that fit the frequency content of the sound
events to detect.
-
A new architecture of an artificial neural network that helps to generate
longer melodic patterns is introduced alongside with methods for
post-generation filtering. The proposed approach called variational autoencoder
supported by history is based on a recurrent highway gated network combined
with a variational autoencoder. Combination of this architecture with filtering
heuristics allows generating pseudo-live acoustically pleasing and melodically
diverse music.
-
Algorithmic composition of music has a long history and with the development
of powerful deep learning methods, there has recently been increased interest
in exploring algorithms and models to create art. We explore the utility of
state space models, in particular hidden Markov models (HMMs) and variants, in
composing classical piano pieces from the Romantic era and consider the models'
ability to generate new pieces that sound like they were composed by a human.
We find that the models we explored are fairly successful at generating new
pieces that have largely consonant harmonies, especially when trained on
original pieces with simple harmonic structure. However, we conclude that the
major limitation in using these models to generate music that sounds like it
was composed by a human is the lack of melodic progression in the composed
pieces. We also examine the performance of the models in the context of music
theory.
-
In North-Indian-Music-System(NIMS),tabla is mostly used as percussive
accompaniment for vocal-music in polyphonic-compositions. The human auditory
system uses perceptual grouping of musical-elements and easily filters the
tabla component, thereby decoding prominent rhythmic features like tala, tempo
from a polyphonic composition. For Western music, lots of work have been
reported for automated drum analysis of polyphonic composition. However,
attempts at computational analysis of tala by separating the tabla-signal from
mixed signal in NIMS have not been successful. Tabla is played with two
components - right and left. The right-hand component has frequency overlap
with voice and other instruments. So, tala analysis of polyphonic-composition,
by accurately separating the tabla-signal from the mixture is a baffling task,
therefore an area of challenge. In this work we propose a novel technique for
successfully detecting tala using left-tabla signal, producing meaningful
results because the left-tabla normally doesn't have frequency overlap with
voice and other instruments. North-Indian-rhythm follows complex cyclic
pattern, against linear approach of Western-rhythm. We have exploited this
cyclic property along with stressed and non-stressed methods of playing
tabla-strokes to extract a characteristic pattern from the left-tabla strokes,
which, after matching with the grammar of tala-system, determines the tala and
tempo of the composition. A large number of
polyphonic(vocal+tabla+other-instruments) compositions has been analyzed with
the methodology and the result clearly reveals the effectiveness of proposed
techniques.
-
Eliminating the negative effect of non-stationary environmental noise is a
long-standing research topic for automatic speech recognition that stills
remains an important challenge. Data-driven supervised approaches, including
ones based on deep neural networks, have recently emerged as potential
alternatives to traditional unsupervised approaches and with sufficient
training, can alleviate the shortcomings of the unsupervised methods in various
real-life acoustic environments. In this light, we review recently developed,
representative deep learning approaches for tackling non-stationary additive
and convolutional degradation of speech with the aim of providing guidelines
for those involved in the development of environmentally robust speech
recognition systems. We separately discuss single- and multi-channel techniques
developed for the front-end and back-end of speech recognition systems, as well
as joint front-end and back-end training frameworks.
-
Music summarization allows for higher efficiency in processing, storage, and
sharing of datasets. Machine-oriented approaches, being agnostic to human
consumption, optimize these aspects even further. Such summaries have already
been successfully validated in some MIR tasks. We now generalize previous
conclusions by evaluating the impact of generic summarization of music from a
probabilistic perspective. We estimate Gaussian distributions for original and
summarized songs and compute their relative entropy, in order to measure
information loss incurred by summarization. Our results suggest that relative
entropy is a good predictor of summarization performance in the context of
tasks relying on a bag-of-features model. Based on this observation, we further
propose a straightforward yet expressive summarizer, which minimizes relative
entropy with respect to the original song, that objectively outperforms
previous methods and is better suited to avoid potential copyright issues.
-
We introduce a dataset for facilitating audio-visual analysis of music
performances. The dataset comprises 44 simple multi-instrument classical music
pieces assembled from coordinated but separately recorded performances of
individual tracks. For each piece, we provide the musical score in MIDI format,
the audio recordings of the individual tracks, the audio and video recording of
the assembled mixture, and ground-truth annotation files including frame-level
and note-level transcriptions. We describe our methodology for the creation of
the dataset, particularly highlighting our approaches for addressing the
challenges involved in maintaining synchronization and expressiveness. We
demonstrate the high quality of synchronization achieved with our proposed
approach by comparing the dataset with existing widely-used music audio
datasets.
We anticipate that the dataset will be useful for the development and
evaluation of existing music information retrieval (MIR) tasks, as well as for
novel multi-modal tasks. We benchmark two existing MIR tasks (multi-pitch
analysis and score-informed source separation) on the dataset and compare with
other existing music audio datasets. Additionally, we consider two novel
multi-modal MIR tasks (visually informed multi-pitch analysis and polyphonic
vibrato analysis) enabled by the dataset and provide evaluation measures and
baseline systems for future comparisons (from our recent work). Finally, we
propose several emerging research directions that the dataset enables.
-
In the Pythagorean tuning system, the fifth is used to generate a scale of 12
notes per octave. In this paper, we use the octave to generate a scale of 19
notes per tritave; one can play this scale on a traditional piano. In this
system, the octave becomes a proper interval and the 2:3:4 chord a proper
chord. We study harmonic properties obtained from the 2:3:4 chord, in
particular composition elements using dominants, subdominants, higher
dominants, associated minor chords, inversions, and diminished chords. The
Tonnetz (array notation) turns out to be an effective tool to visualize the
harmonic development in a composition based on these elements. 2:3:4-harmony
may sound pure, yet sparse, as we illustrate in a short piece.
-
Instrumental intelligibility metrics are commonly used as an alternative to
listening tests. This paper evaluates 12 monaural intrusive intelligibility
metrics: SII, HEGP, CSII, HASPI, NCM, QSTI, STOI, ESTOI, MIKNN, SIMI, SIIB, and
$\text{sEPSM}^\text{corr}$. In addition, this paper investigates the ability of
intelligibility metrics to generalize to new types of distortions and analyzes
why the top performing metrics have high performance. The intelligibility data
were obtained from 11 listening tests described in the literature. The stimuli
included Dutch, Danish, and English speech that was distorted by additive
noise, reverberation, competing talkers, pre-processing enhancement, and
post-processing enhancement. SIIB and HASPI had the highest performance
achieving a correlation with listening test scores on average of $\rho=0.92$
and $\rho=0.89$, respectively. The high performance of SIIB may, in part, be
the result of SIIBs developers having access to all the intelligibility data
considered in the evaluation. The results show that intelligibility metrics
tend to perform poorly on data sets that were not used during their
development. By modifying the original implementations of SIIB and STOI, the
advantage of reducing statistical dependencies between input features is
demonstrated. Additionally, the paper presents a new version of SIIB called
$\text{SIIB}^\text{Gauss}$, which has similar performance to SIIB and HASPI,
but takes less time to compute by two orders of magnitude.
-
Signal amplitude envelope allows to obtain information of the signal features
for different applications. It is widely used to pre-process sound and other
signals of physiological origin in human or animal studies. In order to obtain
signal envelope, a fast and simple algorithm is proposed based on peak
detection. The procedure presented here is quite straightforward and can be
used in different applications of time series analysis. It can be applied in
signals with different origin and frequency content. This algorithm presented
is implemented based on python libraries. An open source code is also provided.
Aspects on the parameter selection are discussed to adapt the same method for
different applications. Also traditional methods are revisited and compared
with the one proposed here.
-
In this paper, a novel multitaper modified group delay function-based
representation for speech signals is proposed. With a set of phoneme-based
experiments, it is shown that the proposed method performs better that an
existing multitaper magnitude (MT-MAG) estimation technique, in terms of
variance and MSE, both in spectral- and cepstral-domains. In particular, the
performance of MT-MOGDF is found to be the best with the Thomson tapers.
Additionally, the utility of the MT-MOGDF technique is highlighted in a speaker
recognition experimental setup, where an improvement of around $20\%$ compared
to the next-best technique is obtained. Moreover, the computational
requirements of the proposed technique is comparable to that of MT-MAG. The
proposed feature can be used in for many speech-related applications; in
particular, it is best suited among those that require information of speaker
and speech.
-
In music domain, feature learning has been conducted mainly in two ways:
unsupervised learning based on sparse representations or supervised learning by
semantic labels such as music genre. However, finding discriminative features
in an unsupervised way is challenging and supervised feature learning using
semantic labels may involve noisy or expensive annotation. In this paper, we
present a supervised feature learning approach using artist labels annotated in
every single track as objective meta data. We propose two deep convolutional
neural networks (DCNN) to learn the deep artist features. One is a plain DCNN
trained with the whole artist labels simultaneously, and the other is a Siamese
DCNN trained with a subset of the artist labels based on the artist identity.
We apply the trained models to music classification and retrieval tasks in
transfer learning settings. The results show that our approach is comparable to
previous state-of-the-art methods, indicating that the proposed approach
captures general music audio features as much as the models learned with
semantic labels. Also, we discuss the advantages and disadvantages of the two
models.
-
Speech separation is the task of separating target speech from background
interference. Traditionally, speech separation is studied as a signal
processing problem. A more recent approach formulates speech separation as a
supervised learning problem, where the discriminative patterns of speech,
speakers, and background noise are learned from training data. Over the past
decade, many supervised separation algorithms have been put forward. In
particular, the recent introduction of deep learning to supervised speech
separation has dramatically accelerated progress and boosted separation
performance. This article provides a comprehensive overview of the research on
deep learning based supervised speech separation in the last several years. We
first introduce the background of speech separation and the formulation of
supervised separation. Then we discuss three main components of supervised
separation: learning machines, training targets, and acoustic features. Much of
the overview is on separation algorithms where we review monaural methods,
including speech enhancement (speech-nonspeech separation), speaker separation
(multi-talker separation), and speech dereverberation, as well as
multi-microphone techniques. The important issue of generalization, unique to
supervised learning, is discussed. This overview provides a historical
perspective on how advances are made. In addition, we discuss a number of
conceptual issues, including what constitutes the target source.
-
Segments that span contiguous parts of inputs, such as phonemes in speech,
named entities in sentences, actions in videos, occur frequently in sequence
prediction problems. Segmental models, a class of models that explicitly
hypothesizes segments, have allowed the exploration of rich segment features
for sequence prediction. However, segmental models suffer from slow decoding,
hampering the use of computationally expensive features.
In this thesis, we introduce discriminative segmental cascades, a multi-pass
inference framework that allows us to improve accuracy by adding higher-order
features and neural segmental features while maintaining efficiency. We also
show that instead of including more features to obtain better accuracy,
segmental cascades can be used to speed up training and decoding.
Segmental models, similarly to conventional speech recognizers, are typically
trained in multiple stages. In the first stage, a frame classifier is trained
with manual alignments, and then in the second stage, segmental models are
trained with manual alignments and the out- puts of the frame classifier.
However, obtaining manual alignments are time-consuming and expensive. We
explore end-to-end training for segmental models with various loss functions,
and show how end-to-end training with marginal log loss can eliminate the need
for detailed manual alignments.
We draw the connections between the marginal log loss and a popular
end-to-end training approach called connectionist temporal classification. We
present a unifying framework for various end-to-end graph search-based models,
such as hidden Markov models, connectionist temporal classification, and
segmental models. Finally, we discuss possible extensions of segmental models
to large-vocabulary sequence prediction tasks.
-
In this paper, we empirically investigate the effect of audio preprocessing
on music tagging with deep neural networks. We perform comprehensive
experiments involving audio preprocessing using different time-frequency
representations, logarithmic magnitude compression, frequency weighting, and
scaling. We show that many commonly used input preprocessing techniques are
redundant except magnitude compression.
-
Despite noise suppression being a mature area in signal processing, it
remains highly dependent on fine tuning of estimator algorithms and parameters.
In this paper, we demonstrate a hybrid DSP/deep learning approach to noise
suppression. A deep neural network with four hidden layers is used to estimate
ideal critical band gains, while a more traditional pitch filter attenuates
noise between pitch harmonics. The approach achieves significantly higher
quality than a traditional minimum mean squared error spectral estimator, while
keeping the complexity low enough for real-time operation at 48 kHz on a
low-power processor.
-
Most existing datasets for speaker identification contain samples obtained
under quite constrained conditions, and are usually hand-annotated, hence
limited in size. The goal of this paper is to generate a large scale
text-independent speaker identification dataset collected 'in the wild'. We
make two contributions. First, we propose a fully automated pipeline based on
computer vision techniques to create the dataset from open-source media. Our
pipeline involves obtaining videos from YouTube; performing active speaker
verification using a two-stream synchronization Convolutional Neural Network
(CNN), and confirming the identity of the speaker using CNN based facial
recognition. We use this pipeline to curate VoxCeleb which contains hundreds of
thousands of 'real world' utterances for over 1,000 celebrities. Our second
contribution is to apply and compare various state of the art speaker
identification techniques on our dataset to establish baseline performance. We
show that a CNN based architecture obtains the best performance for both
identification and verification.
-
There is a common observation that audio event classification is easier to
deal with than detection. So far, this observation has been accepted as a fact
and we lack of a careful analysis. In this paper, we reason the rationale
behind this fact and, more importantly, leverage them to benefit the audio
event detection task. We present an improved detection pipeline in which a
verification step is appended to augment a detection system. This step employs
a high-quality event classifier to postprocess the benign event hypotheses
outputted by the detection system and reject false alarms. To demonstrate the
effectiveness of the proposed pipeline, we implement and pair up different
event detectors based on the most common detection schemes and various event
classifiers, ranging from the standard bag-of-words model to the
state-of-the-art bank-of-regressors one. Experimental results on the ITC-Irst
dataset show significant improvements to detection performance. More
importantly, these improvements are consistent for all detector-classifier
combinations.
-
Sound event detection systems typically consist of two stages: extracting
hand-crafted features from the raw audio waveform, and learning a mapping
between these features and the target sound events using a classifier.
Recently, the focus of sound event detection research has been mostly shifted
to the latter stage using standard features such as mel spectrogram as the
input for classifiers such as deep neural networks. In this work, we utilize
end-to-end approach and propose to combine these two stages in a single deep
neural network classifier. The feature extraction over the raw waveform is
conducted by a feedforward layer block, whose parameters are initialized to
extract the time-frequency representations. The feature extraction parameters
are updated during training, resulting with a representation that is optimized
for the specific task. This feature extraction block is followed by (and
jointly trained with) a convolutional recurrent network, which has recently
given state-of-the-art results in many sound recognition tasks. The proposed
system does not outperform a convolutional recurrent network with fixed
hand-crafted features. The final magnitude spectrum characteristics of the
feature extraction block parameters indicate that the most relevant information
for the given task is contained in 0 - 3 kHz frequency range, and this is also
supported by the empirical results on the SED performance.
-
Traditional intelligent fault diagnosis of rolling bearings work well only
under a common assumption that the labeled training data (source domain) and
unlabeled testing data (target domain) are drawn from the same distribution.
However, in many real-world applications, this assumption does not hold,
especially when the working condition varies. In this paper, a new adversarial
adaptive 1-D CNN called A2CNN is proposed to address this problem. A2CNN
consists of four parts, namely, a source feature extractor, a target feature
extractor, a label classifier and a domain discriminator. The layers between
the source and target feature extractor are partially untied during the
training stage to take both training efficiency and domain adaptation into
consideration. Experiments show that A2CNN has strong fault-discriminative and
domain-invariant capacity, and therefore can achieve high accuracy under
different working conditions. We also visualize the learned features and the
networks to explore the reasons behind the high performance of our proposed
model.
-
The computer vision literature shows that randomly weighted neural networks
perform reasonably as feature extractors. Following this idea, we study how
non-trained (randomly weighted) convolutional neural networks perform as
feature extractors for (music) audio classification tasks. We use features
extracted from the embeddings of deep architectures as input to a classifier -
with the goal to compare classification accuracies when using different
randomly weighted architectures. By following this methodology, we run a
comprehensive evaluation of the current deep architectures for audio
classification, and provide evidence that the architectures alone are an
important piece for resolving (music) audio problems using deep neural
networks.





 OBJECTIVE: We aim to extract and denoise the attended speaker in a noisy, two-speaker acoustic scenario, relying on microphone array recordings from a binaural hearing aid, which are complemented with electroencephalography (EEG) recordings to infer the speaker of interest. METHODS: In this study, we propose a modular processing flow that first extracts the two speech envelopes from the microphone recordings, then selects the attended speech envelope based on the EEG, and finally uses this envelope to inform a multi-channel speech separation and denoising algorithm. RESULTS: Strong suppression of interfering (unattended) speech and background noise is achieved, while the attended speech is preserved. Furthermore, EEG-based auditory attention detection (AAD) is shown to be robust to the use of noisy speech signals. CONCLUSIONS: Our results show that AAD-based speaker extraction from microphone array recordings is feasible and robust, even in noisy acoustic environments, and without access to the clean speech signals to perform EEG-based AAD. SIGNIFICANCE: Current research on AAD always assumes the availability of the clean speech signals, which limits the applicability in real settings. We have extended this research to detect the attended speaker even when only microphone recordings with noisy speech mixtures are available. This is an enabling ingredient for new brain-computer interfaces and effective filtering schemes in neuro-steered hearing prostheses. Here, we provide a first proof of concept for EEG-informed attended speaker extraction and denoising.
OBJECTIVE: We aim to extract and denoise the attended speaker in a noisy, two-speaker acoustic scenario, relying on microphone array recordings from a binaural hearing aid, which are complemented with electroencephalography (EEG) recordings to infer the speaker of interest. METHODS: In this study, we propose a modular processing flow that first extracts the two speech envelopes from the microphone recordings, then selects the attended speech envelope based on the EEG, and finally uses this envelope to inform a multi-channel speech separation and denoising algorithm. RESULTS: Strong suppression of interfering (unattended) speech and background noise is achieved, while the attended speech is preserved. Furthermore, EEG-based auditory attention detection (AAD) is shown to be robust to the use of noisy speech signals. CONCLUSIONS: Our results show that AAD-based speaker extraction from microphone array recordings is feasible and robust, even in noisy acoustic environments, and without access to the clean speech signals to perform EEG-based AAD. SIGNIFICANCE: Current research on AAD always assumes the availability of the clean speech signals, which limits the applicability in real settings. We have extended this research to detect the attended speaker even when only microphone recordings with noisy speech mixtures are available. This is an enabling ingredient for new brain-computer interfaces and effective filtering schemes in neuro-steered hearing prostheses. Here, we provide a first proof of concept for EEG-informed attended speaker extraction and denoising.




 The perception of consonance/dissonance of musical harmonies is strongly correlated with their periodicity. This is shown in this article by consistently applying recent results from psychophysics and neuroacoustics, namely that the just noticeable difference between pitches for humans is about 1% for the musically important low frequency range and that periodicities of complex chords can be detected in the human brain. Based thereon, the concepts of relative and logarithmic periodicity with smoothing are introduced as powerful measures of harmoniousness. The presented results correlate significantly with empirical investigations on the perception of chords. Even for scales, plausible results are obtained. For example, all classical church modes appear in the front ranks of all theoretically possible seven-tone scales.
The perception of consonance/dissonance of musical harmonies is strongly correlated with their periodicity. This is shown in this article by consistently applying recent results from psychophysics and neuroacoustics, namely that the just noticeable difference between pitches for humans is about 1% for the musically important low frequency range and that periodicities of complex chords can be detected in the human brain. Based thereon, the concepts of relative and logarithmic periodicity with smoothing are introduced as powerful measures of harmoniousness. The presented results correlate significantly with empirical investigations on the perception of chords. Even for scales, plausible results are obtained. For example, all classical church modes appear in the front ranks of all theoretically possible seven-tone scales.




 Automatic music transcription (AMT) aims to infer a latent symbolic representation of a piece of music (piano-roll), given a corresponding observed audio recording. Transcribing polyphonic music (when multiple notes are played simultaneously) is a challenging problem, due to highly structured overlapping between harmonics. We study whether the introduction of physically inspired Gaussian process (GP) priors into audio content analysis models improves the extraction of patterns required for AMT. Audio signals are described as a linear combination of sources. Each source is decomposed into the product of an amplitude-envelope, and a quasi-periodic component process. We introduce the Mat\'ern spectral mixture (MSM) kernel for describing frequency content of singles notes. We consider two different regression approaches. In the sigmoid model every pitch-activation is independently non-linear transformed. In the softmax model several activation GPs are jointly non-linearly transformed. This introduce cross-correlation between activations. We use variational Bayes for approximate inference. We empirically evaluate how these models work in practice transcribing polyphonic music. We demonstrate that rather than encourage dependency between activations, what is relevant for improving pitch detection is to learnt priors that fit the frequency content of the sound events to detect.
Automatic music transcription (AMT) aims to infer a latent symbolic representation of a piece of music (piano-roll), given a corresponding observed audio recording. Transcribing polyphonic music (when multiple notes are played simultaneously) is a challenging problem, due to highly structured overlapping between harmonics. We study whether the introduction of physically inspired Gaussian process (GP) priors into audio content analysis models improves the extraction of patterns required for AMT. Audio signals are described as a linear combination of sources. Each source is decomposed into the product of an amplitude-envelope, and a quasi-periodic component process. We introduce the Mat\'ern spectral mixture (MSM) kernel for describing frequency content of singles notes. We consider two different regression approaches. In the sigmoid model every pitch-activation is independently non-linear transformed. In the softmax model several activation GPs are jointly non-linearly transformed. This introduce cross-correlation between activations. We use variational Bayes for approximate inference. We empirically evaluate how these models work in practice transcribing polyphonic music. We demonstrate that rather than encourage dependency between activations, what is relevant for improving pitch detection is to learnt priors that fit the frequency content of the sound events to detect.


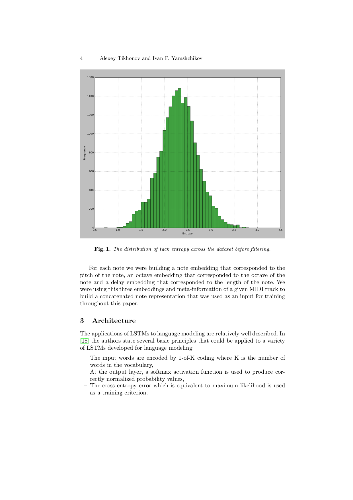

 A new architecture of an artificial neural network that helps to generate longer melodic patterns is introduced alongside with methods for post-generation filtering. The proposed approach called variational autoencoder supported by history is based on a recurrent highway gated network combined with a variational autoencoder. Combination of this architecture with filtering heuristics allows generating pseudo-live acoustically pleasing and melodically diverse music.
A new architecture of an artificial neural network that helps to generate longer melodic patterns is introduced alongside with methods for post-generation filtering. The proposed approach called variational autoencoder supported by history is based on a recurrent highway gated network combined with a variational autoencoder. Combination of this architecture with filtering heuristics allows generating pseudo-live acoustically pleasing and melodically diverse music.




 Algorithmic composition of music has a long history and with the development of powerful deep learning methods, there has recently been increased interest in exploring algorithms and models to create art. We explore the utility of state space models, in particular hidden Markov models (HMMs) and variants, in composing classical piano pieces from the Romantic era and consider the models' ability to generate new pieces that sound like they were composed by a human. We find that the models we explored are fairly successful at generating new pieces that have largely consonant harmonies, especially when trained on original pieces with simple harmonic structure. However, we conclude that the major limitation in using these models to generate music that sounds like it was composed by a human is the lack of melodic progression in the composed pieces. We also examine the performance of the models in the context of music theory.
Algorithmic composition of music has a long history and with the development of powerful deep learning methods, there has recently been increased interest in exploring algorithms and models to create art. We explore the utility of state space models, in particular hidden Markov models (HMMs) and variants, in composing classical piano pieces from the Romantic era and consider the models' ability to generate new pieces that sound like they were composed by a human. We find that the models we explored are fairly successful at generating new pieces that have largely consonant harmonies, especially when trained on original pieces with simple harmonic structure. However, we conclude that the major limitation in using these models to generate music that sounds like it was composed by a human is the lack of melodic progression in the composed pieces. We also examine the performance of the models in the context of music theory.



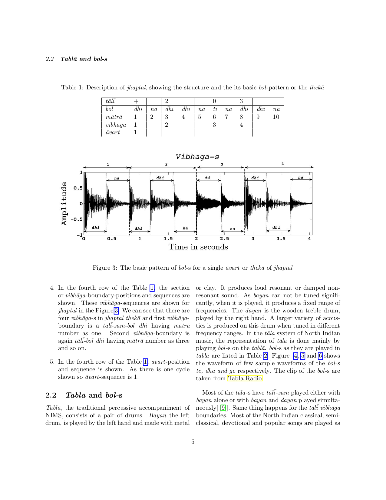
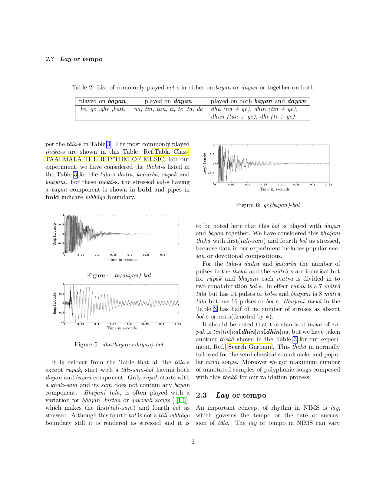 In North-Indian-Music-System(NIMS),tabla is mostly used as percussive accompaniment for vocal-music in polyphonic-compositions. The human auditory system uses perceptual grouping of musical-elements and easily filters the tabla component, thereby decoding prominent rhythmic features like tala, tempo from a polyphonic composition. For Western music, lots of work have been reported for automated drum analysis of polyphonic composition. However, attempts at computational analysis of tala by separating the tabla-signal from mixed signal in NIMS have not been successful. Tabla is played with two components - right and left. The right-hand component has frequency overlap with voice and other instruments. So, tala analysis of polyphonic-composition, by accurately separating the tabla-signal from the mixture is a baffling task, therefore an area of challenge. In this work we propose a novel technique for successfully detecting tala using left-tabla signal, producing meaningful results because the left-tabla normally doesn't have frequency overlap with voice and other instruments. North-Indian-rhythm follows complex cyclic pattern, against linear approach of Western-rhythm. We have exploited this cyclic property along with stressed and non-stressed methods of playing tabla-strokes to extract a characteristic pattern from the left-tabla strokes, which, after matching with the grammar of tala-system, determines the tala and tempo of the composition. A large number of polyphonic(vocal+tabla+other-instruments) compositions has been analyzed with the methodology and the result clearly reveals the effectiveness of proposed techniques.
In North-Indian-Music-System(NIMS),tabla is mostly used as percussive accompaniment for vocal-music in polyphonic-compositions. The human auditory system uses perceptual grouping of musical-elements and easily filters the tabla component, thereby decoding prominent rhythmic features like tala, tempo from a polyphonic composition. For Western music, lots of work have been reported for automated drum analysis of polyphonic composition. However, attempts at computational analysis of tala by separating the tabla-signal from mixed signal in NIMS have not been successful. Tabla is played with two components - right and left. The right-hand component has frequency overlap with voice and other instruments. So, tala analysis of polyphonic-composition, by accurately separating the tabla-signal from the mixture is a baffling task, therefore an area of challenge. In this work we propose a novel technique for successfully detecting tala using left-tabla signal, producing meaningful results because the left-tabla normally doesn't have frequency overlap with voice and other instruments. North-Indian-rhythm follows complex cyclic pattern, against linear approach of Western-rhythm. We have exploited this cyclic property along with stressed and non-stressed methods of playing tabla-strokes to extract a characteristic pattern from the left-tabla strokes, which, after matching with the grammar of tala-system, determines the tala and tempo of the composition. A large number of polyphonic(vocal+tabla+other-instruments) compositions has been analyzed with the methodology and the result clearly reveals the effectiveness of proposed techniques.




 Eliminating the negative effect of non-stationary environmental noise is a long-standing research topic for automatic speech recognition that stills remains an important challenge. Data-driven supervised approaches, including ones based on deep neural networks, have recently emerged as potential alternatives to traditional unsupervised approaches and with sufficient training, can alleviate the shortcomings of the unsupervised methods in various real-life acoustic environments. In this light, we review recently developed, representative deep learning approaches for tackling non-stationary additive and convolutional degradation of speech with the aim of providing guidelines for those involved in the development of environmentally robust speech recognition systems. We separately discuss single- and multi-channel techniques developed for the front-end and back-end of speech recognition systems, as well as joint front-end and back-end training frameworks.
Eliminating the negative effect of non-stationary environmental noise is a long-standing research topic for automatic speech recognition that stills remains an important challenge. Data-driven supervised approaches, including ones based on deep neural networks, have recently emerged as potential alternatives to traditional unsupervised approaches and with sufficient training, can alleviate the shortcomings of the unsupervised methods in various real-life acoustic environments. In this light, we review recently developed, representative deep learning approaches for tackling non-stationary additive and convolutional degradation of speech with the aim of providing guidelines for those involved in the development of environmentally robust speech recognition systems. We separately discuss single- and multi-channel techniques developed for the front-end and back-end of speech recognition systems, as well as joint front-end and back-end training frameworks.




 Music summarization allows for higher efficiency in processing, storage, and sharing of datasets. Machine-oriented approaches, being agnostic to human consumption, optimize these aspects even further. Such summaries have already been successfully validated in some MIR tasks. We now generalize previous conclusions by evaluating the impact of generic summarization of music from a probabilistic perspective. We estimate Gaussian distributions for original and summarized songs and compute their relative entropy, in order to measure information loss incurred by summarization. Our results suggest that relative entropy is a good predictor of summarization performance in the context of tasks relying on a bag-of-features model. Based on this observation, we further propose a straightforward yet expressive summarizer, which minimizes relative entropy with respect to the original song, that objectively outperforms previous methods and is better suited to avoid potential copyright issues.
Music summarization allows for higher efficiency in processing, storage, and sharing of datasets. Machine-oriented approaches, being agnostic to human consumption, optimize these aspects even further. Such summaries have already been successfully validated in some MIR tasks. We now generalize previous conclusions by evaluating the impact of generic summarization of music from a probabilistic perspective. We estimate Gaussian distributions for original and summarized songs and compute their relative entropy, in order to measure information loss incurred by summarization. Our results suggest that relative entropy is a good predictor of summarization performance in the context of tasks relying on a bag-of-features model. Based on this observation, we further propose a straightforward yet expressive summarizer, which minimizes relative entropy with respect to the original song, that objectively outperforms previous methods and is better suited to avoid potential copyright issues.




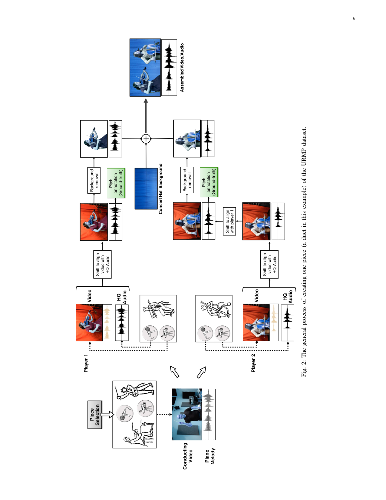 We introduce a dataset for facilitating audio-visual analysis of music performances. The dataset comprises 44 simple multi-instrument classical music pieces assembled from coordinated but separately recorded performances of individual tracks. For each piece, we provide the musical score in MIDI format, the audio recordings of the individual tracks, the audio and video recording of the assembled mixture, and ground-truth annotation files including frame-level and note-level transcriptions. We describe our methodology for the creation of the dataset, particularly highlighting our approaches for addressing the challenges involved in maintaining synchronization and expressiveness. We demonstrate the high quality of synchronization achieved with our proposed approach by comparing the dataset with existing widely-used music audio datasets. We anticipate that the dataset will be useful for the development and evaluation of existing music information retrieval (MIR) tasks, as well as for novel multi-modal tasks. We benchmark two existing MIR tasks (multi-pitch analysis and score-informed source separation) on the dataset and compare with other existing music audio datasets. Additionally, we consider two novel multi-modal MIR tasks (visually informed multi-pitch analysis and polyphonic vibrato analysis) enabled by the dataset and provide evaluation measures and baseline systems for future comparisons (from our recent work). Finally, we propose several emerging research directions that the dataset enables.
We introduce a dataset for facilitating audio-visual analysis of music performances. The dataset comprises 44 simple multi-instrument classical music pieces assembled from coordinated but separately recorded performances of individual tracks. For each piece, we provide the musical score in MIDI format, the audio recordings of the individual tracks, the audio and video recording of the assembled mixture, and ground-truth annotation files including frame-level and note-level transcriptions. We describe our methodology for the creation of the dataset, particularly highlighting our approaches for addressing the challenges involved in maintaining synchronization and expressiveness. We demonstrate the high quality of synchronization achieved with our proposed approach by comparing the dataset with existing widely-used music audio datasets. We anticipate that the dataset will be useful for the development and evaluation of existing music information retrieval (MIR) tasks, as well as for novel multi-modal tasks. We benchmark two existing MIR tasks (multi-pitch analysis and score-informed source separation) on the dataset and compare with other existing music audio datasets. Additionally, we consider two novel multi-modal MIR tasks (visually informed multi-pitch analysis and polyphonic vibrato analysis) enabled by the dataset and provide evaluation measures and baseline systems for future comparisons (from our recent work). Finally, we propose several emerging research directions that the dataset enables.




 Instrumental intelligibility metrics are commonly used as an alternative to listening tests. This paper evaluates 12 monaural intrusive intelligibility metrics: SII, HEGP, CSII, HASPI, NCM, QSTI, STOI, ESTOI, MIKNN, SIMI, SIIB, and $\text{sEPSM}^\text{corr}$. In addition, this paper investigates the ability of intelligibility metrics to generalize to new types of distortions and analyzes why the top performing metrics have high performance. The intelligibility data were obtained from 11 listening tests described in the literature. The stimuli included Dutch, Danish, and English speech that was distorted by additive noise, reverberation, competing talkers, pre-processing enhancement, and post-processing enhancement. SIIB and HASPI had the highest performance achieving a correlation with listening test scores on average of $\rho=0.92$ and $\rho=0.89$, respectively. The high performance of SIIB may, in part, be the result of SIIBs developers having access to all the intelligibility data considered in the evaluation. The results show that intelligibility metrics tend to perform poorly on data sets that were not used during their development. By modifying the original implementations of SIIB and STOI, the advantage of reducing statistical dependencies between input features is demonstrated. Additionally, the paper presents a new version of SIIB called $\text{SIIB}^\text{Gauss}$, which has similar performance to SIIB and HASPI, but takes less time to compute by two orders of magnitude.
Instrumental intelligibility metrics are commonly used as an alternative to listening tests. This paper evaluates 12 monaural intrusive intelligibility metrics: SII, HEGP, CSII, HASPI, NCM, QSTI, STOI, ESTOI, MIKNN, SIMI, SIIB, and $\text{sEPSM}^\text{corr}$. In addition, this paper investigates the ability of intelligibility metrics to generalize to new types of distortions and analyzes why the top performing metrics have high performance. The intelligibility data were obtained from 11 listening tests described in the literature. The stimuli included Dutch, Danish, and English speech that was distorted by additive noise, reverberation, competing talkers, pre-processing enhancement, and post-processing enhancement. SIIB and HASPI had the highest performance achieving a correlation with listening test scores on average of $\rho=0.92$ and $\rho=0.89$, respectively. The high performance of SIIB may, in part, be the result of SIIBs developers having access to all the intelligibility data considered in the evaluation. The results show that intelligibility metrics tend to perform poorly on data sets that were not used during their development. By modifying the original implementations of SIIB and STOI, the advantage of reducing statistical dependencies between input features is demonstrated. Additionally, the paper presents a new version of SIIB called $\text{SIIB}^\text{Gauss}$, which has similar performance to SIIB and HASPI, but takes less time to compute by two orders of magnitude.


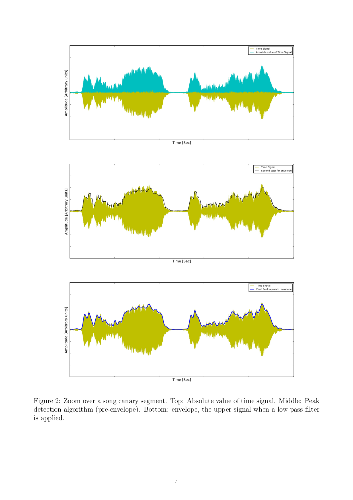
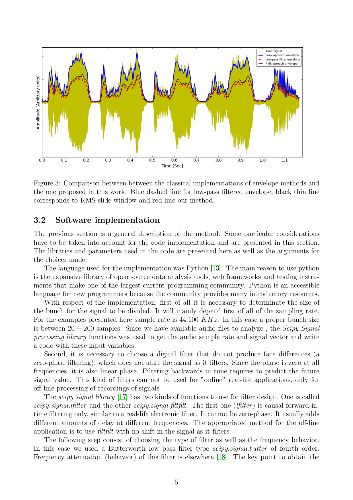
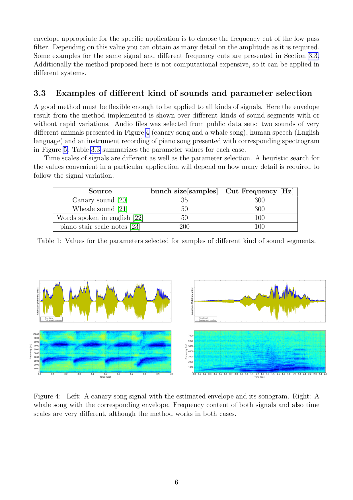 Signal amplitude envelope allows to obtain information of the signal features for different applications. It is widely used to pre-process sound and other signals of physiological origin in human or animal studies. In order to obtain signal envelope, a fast and simple algorithm is proposed based on peak detection. The procedure presented here is quite straightforward and can be used in different applications of time series analysis. It can be applied in signals with different origin and frequency content. This algorithm presented is implemented based on python libraries. An open source code is also provided. Aspects on the parameter selection are discussed to adapt the same method for different applications. Also traditional methods are revisited and compared with the one proposed here.
Signal amplitude envelope allows to obtain information of the signal features for different applications. It is widely used to pre-process sound and other signals of physiological origin in human or animal studies. In order to obtain signal envelope, a fast and simple algorithm is proposed based on peak detection. The procedure presented here is quite straightforward and can be used in different applications of time series analysis. It can be applied in signals with different origin and frequency content. This algorithm presented is implemented based on python libraries. An open source code is also provided. Aspects on the parameter selection are discussed to adapt the same method for different applications. Also traditional methods are revisited and compared with the one proposed here.


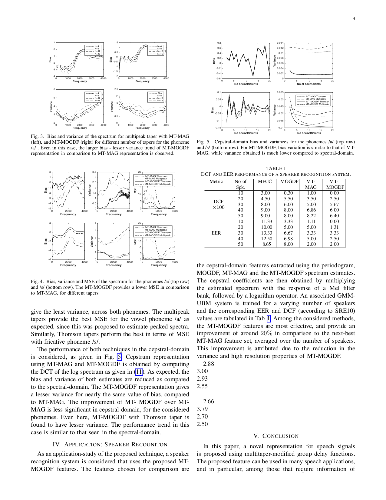

 In this paper, a novel multitaper modified group delay function-based representation for speech signals is proposed. With a set of phoneme-based experiments, it is shown that the proposed method performs better that an existing multitaper magnitude (MT-MAG) estimation technique, in terms of variance and MSE, both in spectral- and cepstral-domains. In particular, the performance of MT-MOGDF is found to be the best with the Thomson tapers. Additionally, the utility of the MT-MOGDF technique is highlighted in a speaker recognition experimental setup, where an improvement of around $20\%$ compared to the next-best technique is obtained. Moreover, the computational requirements of the proposed technique is comparable to that of MT-MAG. The proposed feature can be used in for many speech-related applications; in particular, it is best suited among those that require information of speaker and speech.
In this paper, a novel multitaper modified group delay function-based representation for speech signals is proposed. With a set of phoneme-based experiments, it is shown that the proposed method performs better that an existing multitaper magnitude (MT-MAG) estimation technique, in terms of variance and MSE, both in spectral- and cepstral-domains. In particular, the performance of MT-MOGDF is found to be the best with the Thomson tapers. Additionally, the utility of the MT-MOGDF technique is highlighted in a speaker recognition experimental setup, where an improvement of around $20\%$ compared to the next-best technique is obtained. Moreover, the computational requirements of the proposed technique is comparable to that of MT-MAG. The proposed feature can be used in for many speech-related applications; in particular, it is best suited among those that require information of speaker and speech.

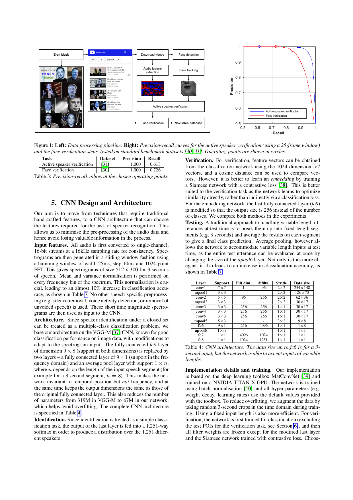


 Most existing datasets for speaker identification contain samples obtained under quite constrained conditions, and are usually hand-annotated, hence limited in size. The goal of this paper is to generate a large scale text-independent speaker identification dataset collected 'in the wild'. We make two contributions. First, we propose a fully automated pipeline based on computer vision techniques to create the dataset from open-source media. Our pipeline involves obtaining videos from YouTube; performing active speaker verification using a two-stream synchronization Convolutional Neural Network (CNN), and confirming the identity of the speaker using CNN based facial recognition. We use this pipeline to curate VoxCeleb which contains hundreds of thousands of 'real world' utterances for over 1,000 celebrities. Our second contribution is to apply and compare various state of the art speaker identification techniques on our dataset to establish baseline performance. We show that a CNN based architecture obtains the best performance for both identification and verification.
Most existing datasets for speaker identification contain samples obtained under quite constrained conditions, and are usually hand-annotated, hence limited in size. The goal of this paper is to generate a large scale text-independent speaker identification dataset collected 'in the wild'. We make two contributions. First, we propose a fully automated pipeline based on computer vision techniques to create the dataset from open-source media. Our pipeline involves obtaining videos from YouTube; performing active speaker verification using a two-stream synchronization Convolutional Neural Network (CNN), and confirming the identity of the speaker using CNN based facial recognition. We use this pipeline to curate VoxCeleb which contains hundreds of thousands of 'real world' utterances for over 1,000 celebrities. Our second contribution is to apply and compare various state of the art speaker identification techniques on our dataset to establish baseline performance. We show that a CNN based architecture obtains the best performance for both identification and verification.



 There is a common observation that audio event classification is easier to deal with than detection. So far, this observation has been accepted as a fact and we lack of a careful analysis. In this paper, we reason the rationale behind this fact and, more importantly, leverage them to benefit the audio event detection task. We present an improved detection pipeline in which a verification step is appended to augment a detection system. This step employs a high-quality event classifier to postprocess the benign event hypotheses outputted by the detection system and reject false alarms. To demonstrate the effectiveness of the proposed pipeline, we implement and pair up different event detectors based on the most common detection schemes and various event classifiers, ranging from the standard bag-of-words model to the state-of-the-art bank-of-regressors one. Experimental results on the ITC-Irst dataset show significant improvements to detection performance. More importantly, these improvements are consistent for all detector-classifier combinations.
There is a common observation that audio event classification is easier to deal with than detection. So far, this observation has been accepted as a fact and we lack of a careful analysis. In this paper, we reason the rationale behind this fact and, more importantly, leverage them to benefit the audio event detection task. We present an improved detection pipeline in which a verification step is appended to augment a detection system. This step employs a high-quality event classifier to postprocess the benign event hypotheses outputted by the detection system and reject false alarms. To demonstrate the effectiveness of the proposed pipeline, we implement and pair up different event detectors based on the most common detection schemes and various event classifiers, ranging from the standard bag-of-words model to the state-of-the-art bank-of-regressors one. Experimental results on the ITC-Irst dataset show significant improvements to detection performance. More importantly, these improvements are consistent for all detector-classifier combinations.