-
The neural network is a powerful computing framework that has been exploited
by biological evolution and by humans for solving diverse problems. Although
the computational capabilities of neural networks are determined by their
structure, the current understanding of the relationships between a neural
network's architecture and function is still primitive. Here we reveal that
neural network's modular architecture plays a vital role in determining the
neural dynamics and memory performance of the network of threshold neurons. In
particular, we demonstrate that there exists an optimal modularity for memory
performance, where a balance between local cohesion and global connectivity is
established, allowing optimally modular networks to remember longer. Our
results suggest that insights from dynamical analysis of neural networks and
information spreading processes can be leveraged to better design neural
networks and may shed light on the brain's modular organization.
-
In school, a teacher plays an important role in various classroom teaching
patterns. Likewise to this human learning activity, the learning using
privileged information (LUPI) paradigm provides additional information
generated by the teacher to 'teach' learning models during the training stage.
Therefore, this novel learning paradigm is a typical Teacher-Student
Interaction mechanism. This paper is the first to present a random vector
functional link network based on the LUPI paradigm, called RVFL+. Rather than
simply combining two existing approaches, the newly-derived RVFL+ fills the gap
between classical randomized neural networks and the newfashioned LUPI
paradigm, which offers an alternative way to train RVFL networks. Moreover, the
proposed RVFL+ can perform in conjunction with the kernel trick for highly
complicated nonlinear feature learning, which is termed KRVFL+. Furthermore,
the statistical property of the proposed RVFL+ is investigated, and we present
a sharp and high-quality generalization error bound based on the Rademacher
complexity. Competitive experimental results on 14 real-world datasets
illustrate the great effectiveness and efficiency of the novel RVFL+ and
KRVFL+, which can achieve better generalization performance than
state-of-the-art methods.
-
As one of the most important paradigms of recurrent neural networks, the echo
state network (ESN) has been applied to a wide range of fields, from robotics
to medicine, finance, and language processing. A key feature of the ESN
paradigm is its reservoir --- a directed and weighted network of neurons that
projects the input time series into a high dimensional space where linear
regression or classification can be applied. Despite extensive studies, the
impact of the reservoir network on the ESN performance remains unclear.
Combining tools from physics, dynamical systems and network science, we attempt
to open the black box of ESN and offer insights to understand the behavior of
general artificial neural networks. Through spectral analysis of the reservoir
network we reveal a key factor that largely determines the ESN memory capacity
and hence affects its performance. Moreover, we find that adding short loops to
the reservoir network can tailor ESN for specific tasks and optimize learning.
We validate our findings by applying ESN to forecast both synthetic and real
benchmark time series. Our results provide a new way to design task-specific
ESN. More importantly, it demonstrates the power of combining tools from
physics, dynamical systems and network science to offer new insights in
understanding the mechanisms of general artificial neural networks.
-
Analysis of sleep for the diagnosis of sleep disorders such as Type-1
Narcolepsy (T1N) currently requires visual inspection of polysomnography
records by trained scoring technicians. Here, we used neural networks in
approximately 3,000 normal and abnormal sleep recordings to automate sleep
stage scoring, producing a hypnodensity graph - a probability distribution
conveying more information than classical hypnograms. Accuracy of sleep stage
scoring was validated in 70 subjects assessed by six scorers. The best model
performed better than any individual scorer (87% versus consensus). It also
reliably scores sleep down to 5 instead of 30 second scoring epochs. A T1N
marker based on unusual sleep-stage overlaps achieved a specificity of 96% and
a sensitivity of 91%, validated in independent datasets. Addition of
HLA-DQB1*06:02 typing increased specificity to 99%. Our method can reduce time
spent in sleep clinics and automates T1N diagnosis. It also opens the
possibility of diagnosing T1N using home sleep studies.
-
Nowadays deep learning is dominating the field of machine learning with
state-of-the-art performance in various application areas. Recently, spiking
neural networks (SNNs) have been attracting a great deal of attention, notably
owning to their power efficiency, which can potentially allow us to implement a
low-power deep learning engine suitable for real-time/mobile applications.
However, implementing SNN-based deep learning remains challenging, especially
gradient-based training of SNNs by error backpropagation. We cannot simply
propagate errors through SNNs in conventional way because of the property of
SNNs that process discrete data in the form of a series. Consequently, most of
the previous studies employ a workaround technique, which first trains a
conventional weighted-sum deep neural network and then maps the learning
weights to the SNN under training, instead of training SNN parameters directly.
In order to eliminate this workaround, recently proposed is a new class of SNN
named deep spiking networks (DSNs), which can be trained directly (without a
mapping from conventional deep networks) by error backpropagation with
stochastic gradient descent. In this paper, we show that the initialization of
the membrane potential on the backward path is an important step in DSN
training, through diverse experiments performed under various conditions.
Furthermore, we propose a simple and efficient method that can improve DSN
training by controlling the initial membrane potential on the backward path. In
our experiments, adopting the proposed approach allowed us to boost the
performance of DSN training in terms of converging time and accuracy.
-
Collective, especially group-based, managerial decision making is crucial in
organizations. Using an evolutionary theoretic approach to collective decision
making, agent-based simulations were conducted to investigate how human
collective decision making would be affected by the agents' diversity in
problem understanding and/or behavior in discussion, as well as by their social
network structure. Simulation results indicated that groups with consistent
problem understanding tended to produce higher utility values of ideas and
displayed better decision convergence, but only if there was no group-level
bias in collective problem understanding. Simulation results also indicated the
importance of balance between selection-oriented (i.e., exploitative) and
variation-oriented (i.e., explorative) behaviors in discussion to achieve
quality final decisions. Expanding the group size and introducing non-trivial
social network structure generally improved the quality of ideas at the cost of
decision convergence. Simulations with different social network topologies
revealed collective decision making on small-world networks with high local
clustering tended to achieve highest decision quality more often than on random
or scale-free networks. Implications of this evolutionary theory and simulation
approach for future managerial research on collective, group, and multi-level
decision making are discussed.
-
Learning based on networks of real neurons, and by extension biologically
inspired models of neural networks, has yet to find general learning rules
leading to widespread applications. In this paper, we argue for the existence
of a principle allowing to steer the dynamics of a biologically inspired neural
network. Using carefully timed external stimulation, the network can be driven
towards a desired dynamical state. We term this principle "Learning by
Stimulation Avoidance" (LSA). We demonstrate through simulation that the
minimal sufficient conditions leading to LSA in artificial networks are also
sufficient to reproduce learning results similar to those obtained in
biological neurons by Shahaf and Marom [1]. We examine the mechanism's basic
dynamics in a reduced network, and demonstrate how it scales up to a network of
100 neurons. We show that LSA has a higher explanatory power than existing
hypotheses about the response of biological neural networks to external
simulation, and can be used as a learning rule for an embodied application:
learning of wall avoidance by a simulated robot. The surge in popularity of
artificial neural networks is mostly directed to disembodied models of neurons
with biologically irrelevant dynamics: to the authors' knowledge, this is the
first work demonstrating sensory-motor learning with random spiking networks
through pure Hebbian learning.
-
Natural evolution has produced a tremendous diversity of functional
organisms. Many believe an essential component of this process was the
evolution of evolvability, whereby evolution speeds up its ability to innovate
by generating a more adaptive pool of offspring. One hypothesized mechanism for
evolvability is developmental canalization, wherein certain dimensions of
variation become more likely to be traversed and others are prevented from
being explored (e.g. offspring tend to have similarly sized legs, and mutations
affect the length of both legs, not each leg individually). While ubiquitous in
nature, canalization almost never evolves in computational simulations of
evolution. Not only does that deprive us of in silico models in which to study
the evolution of evolvability, but it also raises the question of which
conditions give rise to this form of evolvability. Answering this question
would shed light on why such evolvability emerged naturally and could
accelerate engineering efforts to harness evolution to solve important
engineering challenges. In this paper we reveal a unique system in which
canalization did emerge in computational evolution. We document that genomes
entrench certain dimensions of variation that were frequently explored during
their evolutionary history. The genetic representation of these organisms also
evolved to be highly modular and hierarchical, and we show that these
organizational properties correlate with increased fitness. Interestingly, the
type of computational evolutionary experiment that produced this evolvability
was very different from traditional digital evolution in that there was no
objective, suggesting that open-ended, divergent evolutionary processes may be
necessary for the evolution of evolvability.
-
Gated Recurrent Unit (GRU) is a recently-developed variation of the long
short-term memory (LSTM) unit, both of which are types of recurrent neural
network (RNN). Through empirical evidence, both models have been proven to be
effective in a wide variety of machine learning tasks such as natural language
processing (Wen et al., 2015), speech recognition (Chorowski et al., 2015), and
text classification (Yang et al., 2016). Conventionally, like most neural
networks, both of the aforementioned RNN variants employ the Softmax function
as its final output layer for its prediction, and the cross-entropy function
for computing its loss. In this paper, we present an amendment to this norm by
introducing linear support vector machine (SVM) as the replacement for Softmax
in the final output layer of a GRU model. Furthermore, the cross-entropy
function shall be replaced with a margin-based function. While there have been
similar studies (Alalshekmubarak & Smith, 2013; Tang, 2013), this proposal is
primarily intended for binary classification on intrusion detection using the
2013 network traffic data from the honeypot systems of Kyoto University.
Results show that the GRU-SVM model performs relatively higher than the
conventional GRU-Softmax model. The proposed model reached a training accuracy
of ~81.54% and a testing accuracy of ~84.15%, while the latter was able to
reach a training accuracy of ~63.07% and a testing accuracy of ~70.75%. In
addition, the juxtaposition of these two final output layers indicate that the
SVM would outperform Softmax in prediction time - a theoretical implication
which was supported by the actual training and testing time in the study.
-
We explore the use of neural networks trained with dropout in predicting
epileptic seizures from electroencephalographic data (scalp EEG). The input to
the neural network is a 126 feature vector containing 9 features for each of
the 14 EEG channels obtained over 1-second, non-overlapping windows. The models
in our experiments achieved high sensitivity and specificity on patient records
not used in the training process. This is demonstrated using
leave-one-out-cross-validation across patient records, where we hold out one
patient's record as the test set and use all other patients' records for
training; repeating this procedure for all patients in the database.
-
Optimization problems with more than one objective consist in a very
attractive topic for researchers due to its applicability in real-world
situations. Over the years, the research effort in the Computational
Intelligence field resulted in algorithms able to achieve good results by
solving problems with more than one conflicting objective. However, these
techniques do not exhibit the same performance as the number of objectives
increases and become greater than 3. This paper proposes an adaptation of the
metaheuristic Fish School Search to solve optimization problems with many
objectives. This adaptation is based on the division of the candidate solutions
in clusters that are specialized in solving a single-objective problem
generated by the decomposition of the original problem. For this, we used
concepts and ideas often employed by state-of-the-art algorithms, namely: (i)
reference points and lines in the objectives space; (ii) clustering process;
and (iii) the decomposition technique Penalty-based Boundary Intersection. The
proposed algorithm was compared with two state-of-the-art bio-inspired
algorithms. Moreover, a version of the proposed technique tailored to solve
multi-modal problems was also presented. The experiments executed have shown
that the performance obtained by both versions is competitive with
state-of-the-art results.
-
The key idea of variational auto-encoders (VAEs) resembles that of
traditional auto-encoder models in which spatial information is supposed to be
explicitly encoded in the latent space. However, the latent variables in VAEs
are vectors, which can be interpreted as multiple feature maps of size 1x1.
Such representations can only convey spatial information implicitly when
coupled with powerful decoders. In this work, we propose spatial VAEs that use
feature maps of larger size as latent variables to explicitly capture spatial
information. This is achieved by allowing the latent variables to be sampled
from matrix-variate normal (MVN) distributions whose parameters are computed
from the encoder network. To increase dependencies among locations on latent
feature maps and reduce the number of parameters, we further propose spatial
VAEs via low-rank MVN distributions. Experimental results show that the
proposed spatial VAEs outperform original VAEs in capturing rich structural and
spatial information.
-
We review Boltzmann machines extended for time-series. These models often
have recurrent structure, and back propagration through time (BPTT) is used to
learn their parameters. The per-step computational complexity of BPTT in online
learning, however, grows linearly with respect to the length of preceding
time-series (i.e., learning rule is not local in time), which limits the
applicability of BPTT in online learning. We then review dynamic Boltzmann
machines (DyBMs), whose learning rule is local in time. DyBM's learning rule
relates to spike-timing dependent plasticity (STDP), which has been postulated
and experimentally confirmed for biological neural networks.
-
We review Boltzmann machines and energy-based models. A Boltzmann machine
defines a probability distribution over binary-valued patterns. One can learn
parameters of a Boltzmann machine via gradient based approaches in a way that
log likelihood of data is increased. The gradient and Hessian of a Boltzmann
machine admit beautiful mathematical representations, although computing them
is in general intractable. This intractability motivates approximate methods,
including Gibbs sampler and contrastive divergence, and tractable alternatives,
namely energy-based models.
-
In this work we present a theoretical model for differentiable programming.
We construct an algebraic language that encapsulates formal semantics of
differentiable programs by way of Operational Calculus. The algebraic nature of
Operational Calculus can alter the properties of the programs that are
expressed within the language and transform them into their solutions.
In our model programs are elements of programming spaces and viewed as maps
from the virtual memory space to itself. Virtual memory space is an algebra of
programs, an algebraic data structure one can calculate with. We define the
operator of differentiation ($\partial$) on programming spaces and, using its
powers, implement the general shift operator and the operator of program
composition. We provide the formula for the expansion of a differentiable
program into an infinite tensor series in terms of the powers of $\partial$. We
express the operator of program composition in terms of the generalized shift
operator and $\partial$, which implements a differentiable composition in the
language. Such operators serve as abstractions over the tensor series algebra,
as main actors in our language.
We demonstrate our models usefulness in differentiable programming by using
it to analyse iterators, deriving fractional iterations and their iterating
velocities, and explicitly solve the special case of ReduceSum.
-
Several test function suites are being used for numerical benchmarking of
multiobjective optimization algorithms. While they have some desirable
properties, like well-understood Pareto sets and Pareto fronts of various
shapes, most of the currently used functions possess characteristics that are
arguably under-represented in real-world problems. They mainly stem from the
easier construction of such functions and result in improbable properties such
as separability, optima located exactly at the boundary constraints, and the
existence of variables that solely control the distance between a solution and
the Pareto front. Here, we propose an alternative way to constructing
multiobjective problems-by combining existing single-objective problems from
the literature. We describe in particular the bbob-biobj test suite with 55
bi-objective functions in continuous domain, and its extended version with 92
bi-objective functions (bbob-biobj-ext). Both test suites have been implemented
in the COCO platform for black-box optimization benchmarking. Finally, we
recommend a general procedure for creating test suites for an arbitrary number
of objectives. Besides providing the formal function definitions and presenting
their (known) properties, this paper also aims at giving the rationale behind
our approach in terms of groups of functions with similar properties, objective
space normalization, and problem instances. The latter allows us to easily
compare the performance of deterministic and stochastic solvers, which is an
often overlooked issue in benchmarking.
-
We investigate whether quantum annealers with select chip layouts can
outperform classical computers in reinforcement learning tasks. We associate a
transverse field Ising spin Hamiltonian with a layout of qubits similar to that
of a deep Boltzmann machine (DBM) and use simulated quantum annealing (SQA) to
numerically simulate quantum sampling from this system. We design a
reinforcement learning algorithm in which the set of visible nodes representing
the states and actions of an optimal policy are the first and last layers of
the deep network. In absence of a transverse field, our simulations show that
DBMs are trained more effectively than restricted Boltzmann machines (RBM) with
the same number of nodes. We then develop a framework for training the network
as a quantum Boltzmann machine (QBM) in the presence of a significant
transverse field for reinforcement learning. This method also outperforms the
reinforcement learning method that uses RBMs.
-
This paper provides theoretical insights into why and how deep learning can
generalize well, despite its large capacity, complexity, possible algorithmic
instability, nonrobustness, and sharp minima, responding to an open question in
the literature. We also discuss approaches to provide non-vacuous
generalization guarantees for deep learning. Based on theoretical observations,
we propose new open problems and discuss the limitations of our results.
-
Several approaches have recently been proposed for learning decentralized
deep multiagent policies that coordinate via a differentiable communication
channel. While these policies are effective for many tasks, interpretation of
their induced communication strategies has remained a challenge. Here we
propose to interpret agents' messages by translating them. Unlike in typical
machine translation problems, we have no parallel data to learn from. Instead
we develop a translation model based on the insight that agent messages and
natural language strings mean the same thing if they induce the same belief
about the world in a listener. We present theoretical guarantees and empirical
evidence that our approach preserves both the semantics and pragmatics of
messages by ensuring that players communicating through a translation layer do
not suffer a substantial loss in reward relative to players with a common
language.
-
We propose a method to build quantum memristors in quantum photonic
platforms. We firstly design an effective beam splitter, which is tunable in
real-time, by means of a Mach-Zehnder-type array with two equal 50:50 beam
splitters and a tunable retarder, which allows us to control its reflectivity.
Then, we show that this tunable beam splitter, when equipped with weak
measurements and classical feedback, behaves as a quantum memristor. Indeed, in
order to prove its quantumness, we show how to codify quantum information in
the coherent beams. Moreover, we estimate the memory capability of the quantum
memristor. Finally, we show the feasibility of the proposed setup in integrated
quantum photonics.
-
The field of machine programming (MP), the automation of the development of
software, is making notable research advances. This is, in part, due to the
emergence of a wide range of novel techniques in machine learning. In this
paper, we apply MP to the automation of software performance regression
testing. A performance regression is a software performance degradation caused
by a code change. We present AutoPerf - a novel approach to automate regression
testing that utilizes three core techniques: (i) zero-positive learning, (ii)
autoencoders, and (iii) hardware telemetry. We demonstrate AutoPerf's
generality and efficacy against 3 types of performance regressions across 10
real performance bugs in 7 benchmark and open-source programs. On average,
AutoPerf exhibits 4% profiling overhead and accurately diagnoses more
performance bugs than prior state-of-the-art approaches. Thus far, AutoPerf has
produced no false negatives.
-
It has been observed that many complex real-world networks have certain
properties, such as a high clustering coefficient, a low diameter, and a
power-law degree distribution. A network with a power-law degree distribution
is known as scale-free network. In order to study these networks, various
random graph models have been proposed, e.g. Preferential Attachment, Chung-Lu,
or Hyperbolic.
We look at the interplay between the power-law degree distribution and the
run time of optimization techniques for well known combinatorial problems. We
observe that on scale-free networks, simple evolutionary algorithms (EAs)
quickly reach a constant-factor approximation ratio on common covering problems
We prove that the single-objective (1+1)EA reaches a constant-factor
approximation ratio on the Minimum Dominating Set problem, the Minimum Vertex
Cover problem, the Minimum Connected Dominating Set problem, and the Maximum
Independent Set problem in expected polynomial number of calls to the fitness
function.
Furthermore, we prove that the multi-objective GSEMO algorithm reaches a
better approximation ratio than the (1+1)EA on those problems, within
polynomial fitness evaluations.
-
An important field in robotics is the optimization of controllers. Currently,
robots are often treated as a black box in this optimization process, which is
the reason why derivative-free optimization methods such as evolutionary
algorithms or reinforcement learning are omnipresent. When gradient-based
methods are used, models are kept small or rely on finite difference
approximations for the Jacobian. This method quickly grows expensive with
increasing numbers of parameters, such as found in deep learning. We propose
the implementation of a modern physics engine, which can differentiate control
parameters. This engine is implemented for both CPU and GPU. Firstly, this
paper shows how such an engine speeds up the optimization process, even for
small problems. Furthermore, it explains why this is an alternative approach to
deep Q-learning, for using deep learning in robotics. Finally, we argue that
this is a big step for deep learning in robotics, as it opens up new
possibilities to optimize robots, both in hardware and software.
-
Multi-task learning (MTL) allows deep neural networks to learn from related
tasks by sharing parameters with other networks. In practice, however, MTL
involves searching an enormous space of possible parameter sharing
architectures to find (a) the layers or subspaces that benefit from sharing,
(b) the appropriate amount of sharing, and (c) the appropriate relative weights
of the different task losses. Recent work has addressed each of the above
problems in isolation. In this work we present an approach that learns a latent
multi-task architecture that jointly addresses (a)--(c). We present experiments
on synthetic data and data from OntoNotes 5.0, including four different tasks
and seven different domains. Our extension consistently outperforms previous
approaches to learning latent architectures for multi-task problems and
achieves up to 15% average error reductions over common approaches to MTL.
-
The seminal work of Gatys et al. demonstrated the power of Convolutional
Neural Networks (CNNs) in creating artistic imagery by separating and
recombining image content and style. This process of using CNNs to render a
content image in different styles is referred to as Neural Style Transfer
(NST). Since then, NST has become a trending topic both in academic literature
and industrial applications. It is receiving increasing attention and a variety
of approaches are proposed to either improve or extend the original NST
algorithm. In this paper, we aim to provide a comprehensive overview of the
current progress towards NST. We first propose a taxonomy of current algorithms
in the field of NST. Then, we present several evaluation methods and compare
different NST algorithms both qualitatively and quantitatively. The review
concludes with a discussion of various applications of NST and open problems
for future research. A list of papers discussed in this review, corresponding
codes, pre-trained models and more comparison results are publicly available at
https://github.com/ycjing/Neural-Style-Transfer-Papers.



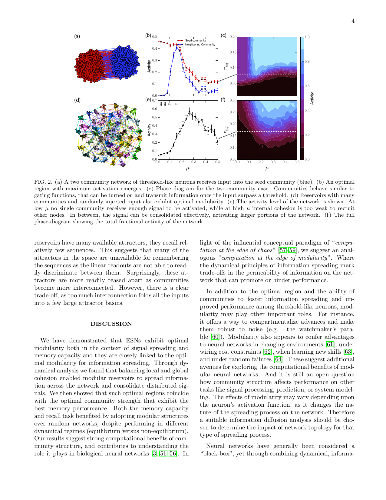
 The neural network is a powerful computing framework that has been exploited by biological evolution and by humans for solving diverse problems. Although the computational capabilities of neural networks are determined by their structure, the current understanding of the relationships between a neural network's architecture and function is still primitive. Here we reveal that neural network's modular architecture plays a vital role in determining the neural dynamics and memory performance of the network of threshold neurons. In particular, we demonstrate that there exists an optimal modularity for memory performance, where a balance between local cohesion and global connectivity is established, allowing optimally modular networks to remember longer. Our results suggest that insights from dynamical analysis of neural networks and information spreading processes can be leveraged to better design neural networks and may shed light on the brain's modular organization.
The neural network is a powerful computing framework that has been exploited by biological evolution and by humans for solving diverse problems. Although the computational capabilities of neural networks are determined by their structure, the current understanding of the relationships between a neural network's architecture and function is still primitive. Here we reveal that neural network's modular architecture plays a vital role in determining the neural dynamics and memory performance of the network of threshold neurons. In particular, we demonstrate that there exists an optimal modularity for memory performance, where a balance between local cohesion and global connectivity is established, allowing optimally modular networks to remember longer. Our results suggest that insights from dynamical analysis of neural networks and information spreading processes can be leveraged to better design neural networks and may shed light on the brain's modular organization.




 In school, a teacher plays an important role in various classroom teaching patterns. Likewise to this human learning activity, the learning using privileged information (LUPI) paradigm provides additional information generated by the teacher to 'teach' learning models during the training stage. Therefore, this novel learning paradigm is a typical Teacher-Student Interaction mechanism. This paper is the first to present a random vector functional link network based on the LUPI paradigm, called RVFL+. Rather than simply combining two existing approaches, the newly-derived RVFL+ fills the gap between classical randomized neural networks and the newfashioned LUPI paradigm, which offers an alternative way to train RVFL networks. Moreover, the proposed RVFL+ can perform in conjunction with the kernel trick for highly complicated nonlinear feature learning, which is termed KRVFL+. Furthermore, the statistical property of the proposed RVFL+ is investigated, and we present a sharp and high-quality generalization error bound based on the Rademacher complexity. Competitive experimental results on 14 real-world datasets illustrate the great effectiveness and efficiency of the novel RVFL+ and KRVFL+, which can achieve better generalization performance than state-of-the-art methods.
In school, a teacher plays an important role in various classroom teaching patterns. Likewise to this human learning activity, the learning using privileged information (LUPI) paradigm provides additional information generated by the teacher to 'teach' learning models during the training stage. Therefore, this novel learning paradigm is a typical Teacher-Student Interaction mechanism. This paper is the first to present a random vector functional link network based on the LUPI paradigm, called RVFL+. Rather than simply combining two existing approaches, the newly-derived RVFL+ fills the gap between classical randomized neural networks and the newfashioned LUPI paradigm, which offers an alternative way to train RVFL networks. Moreover, the proposed RVFL+ can perform in conjunction with the kernel trick for highly complicated nonlinear feature learning, which is termed KRVFL+. Furthermore, the statistical property of the proposed RVFL+ is investigated, and we present a sharp and high-quality generalization error bound based on the Rademacher complexity. Competitive experimental results on 14 real-world datasets illustrate the great effectiveness and efficiency of the novel RVFL+ and KRVFL+, which can achieve better generalization performance than state-of-the-art methods.




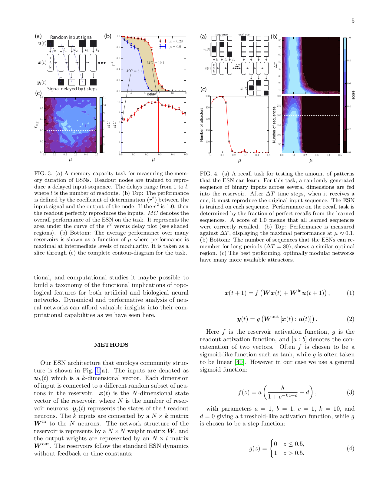
 As one of the most important paradigms of recurrent neural networks, the echo state network (ESN) has been applied to a wide range of fields, from robotics to medicine, finance, and language processing. A key feature of the ESN paradigm is its reservoir --- a directed and weighted network of neurons that projects the input time series into a high dimensional space where linear regression or classification can be applied. Despite extensive studies, the impact of the reservoir network on the ESN performance remains unclear. Combining tools from physics, dynamical systems and network science, we attempt to open the black box of ESN and offer insights to understand the behavior of general artificial neural networks. Through spectral analysis of the reservoir network we reveal a key factor that largely determines the ESN memory capacity and hence affects its performance. Moreover, we find that adding short loops to the reservoir network can tailor ESN for specific tasks and optimize learning. We validate our findings by applying ESN to forecast both synthetic and real benchmark time series. Our results provide a new way to design task-specific ESN. More importantly, it demonstrates the power of combining tools from physics, dynamical systems and network science to offer new insights in understanding the mechanisms of general artificial neural networks.
As one of the most important paradigms of recurrent neural networks, the echo state network (ESN) has been applied to a wide range of fields, from robotics to medicine, finance, and language processing. A key feature of the ESN paradigm is its reservoir --- a directed and weighted network of neurons that projects the input time series into a high dimensional space where linear regression or classification can be applied. Despite extensive studies, the impact of the reservoir network on the ESN performance remains unclear. Combining tools from physics, dynamical systems and network science, we attempt to open the black box of ESN and offer insights to understand the behavior of general artificial neural networks. Through spectral analysis of the reservoir network we reveal a key factor that largely determines the ESN memory capacity and hence affects its performance. Moreover, we find that adding short loops to the reservoir network can tailor ESN for specific tasks and optimize learning. We validate our findings by applying ESN to forecast both synthetic and real benchmark time series. Our results provide a new way to design task-specific ESN. More importantly, it demonstrates the power of combining tools from physics, dynamical systems and network science to offer new insights in understanding the mechanisms of general artificial neural networks.


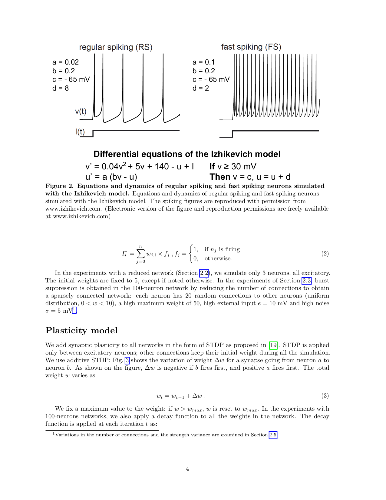
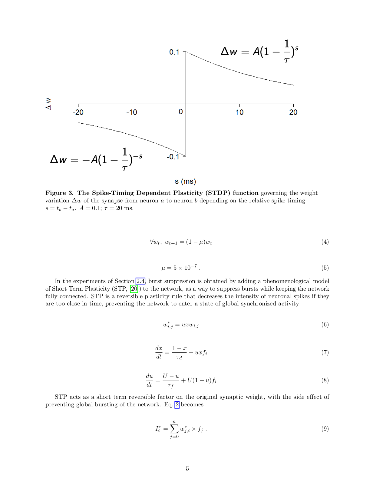
 Learning based on networks of real neurons, and by extension biologically inspired models of neural networks, has yet to find general learning rules leading to widespread applications. In this paper, we argue for the existence of a principle allowing to steer the dynamics of a biologically inspired neural network. Using carefully timed external stimulation, the network can be driven towards a desired dynamical state. We term this principle "Learning by Stimulation Avoidance" (LSA). We demonstrate through simulation that the minimal sufficient conditions leading to LSA in artificial networks are also sufficient to reproduce learning results similar to those obtained in biological neurons by Shahaf and Marom [1]. We examine the mechanism's basic dynamics in a reduced network, and demonstrate how it scales up to a network of 100 neurons. We show that LSA has a higher explanatory power than existing hypotheses about the response of biological neural networks to external simulation, and can be used as a learning rule for an embodied application: learning of wall avoidance by a simulated robot. The surge in popularity of artificial neural networks is mostly directed to disembodied models of neurons with biologically irrelevant dynamics: to the authors' knowledge, this is the first work demonstrating sensory-motor learning with random spiking networks through pure Hebbian learning.
Learning based on networks of real neurons, and by extension biologically inspired models of neural networks, has yet to find general learning rules leading to widespread applications. In this paper, we argue for the existence of a principle allowing to steer the dynamics of a biologically inspired neural network. Using carefully timed external stimulation, the network can be driven towards a desired dynamical state. We term this principle "Learning by Stimulation Avoidance" (LSA). We demonstrate through simulation that the minimal sufficient conditions leading to LSA in artificial networks are also sufficient to reproduce learning results similar to those obtained in biological neurons by Shahaf and Marom [1]. We examine the mechanism's basic dynamics in a reduced network, and demonstrate how it scales up to a network of 100 neurons. We show that LSA has a higher explanatory power than existing hypotheses about the response of biological neural networks to external simulation, and can be used as a learning rule for an embodied application: learning of wall avoidance by a simulated robot. The surge in popularity of artificial neural networks is mostly directed to disembodied models of neurons with biologically irrelevant dynamics: to the authors' knowledge, this is the first work demonstrating sensory-motor learning with random spiking networks through pure Hebbian learning.




 Natural evolution has produced a tremendous diversity of functional organisms. Many believe an essential component of this process was the evolution of evolvability, whereby evolution speeds up its ability to innovate by generating a more adaptive pool of offspring. One hypothesized mechanism for evolvability is developmental canalization, wherein certain dimensions of variation become more likely to be traversed and others are prevented from being explored (e.g. offspring tend to have similarly sized legs, and mutations affect the length of both legs, not each leg individually). While ubiquitous in nature, canalization almost never evolves in computational simulations of evolution. Not only does that deprive us of in silico models in which to study the evolution of evolvability, but it also raises the question of which conditions give rise to this form of evolvability. Answering this question would shed light on why such evolvability emerged naturally and could accelerate engineering efforts to harness evolution to solve important engineering challenges. In this paper we reveal a unique system in which canalization did emerge in computational evolution. We document that genomes entrench certain dimensions of variation that were frequently explored during their evolutionary history. The genetic representation of these organisms also evolved to be highly modular and hierarchical, and we show that these organizational properties correlate with increased fitness. Interestingly, the type of computational evolutionary experiment that produced this evolvability was very different from traditional digital evolution in that there was no objective, suggesting that open-ended, divergent evolutionary processes may be necessary for the evolution of evolvability.
Natural evolution has produced a tremendous diversity of functional organisms. Many believe an essential component of this process was the evolution of evolvability, whereby evolution speeds up its ability to innovate by generating a more adaptive pool of offspring. One hypothesized mechanism for evolvability is developmental canalization, wherein certain dimensions of variation become more likely to be traversed and others are prevented from being explored (e.g. offspring tend to have similarly sized legs, and mutations affect the length of both legs, not each leg individually). While ubiquitous in nature, canalization almost never evolves in computational simulations of evolution. Not only does that deprive us of in silico models in which to study the evolution of evolvability, but it also raises the question of which conditions give rise to this form of evolvability. Answering this question would shed light on why such evolvability emerged naturally and could accelerate engineering efforts to harness evolution to solve important engineering challenges. In this paper we reveal a unique system in which canalization did emerge in computational evolution. We document that genomes entrench certain dimensions of variation that were frequently explored during their evolutionary history. The genetic representation of these organisms also evolved to be highly modular and hierarchical, and we show that these organizational properties correlate with increased fitness. Interestingly, the type of computational evolutionary experiment that produced this evolvability was very different from traditional digital evolution in that there was no objective, suggesting that open-ended, divergent evolutionary processes may be necessary for the evolution of evolvability.

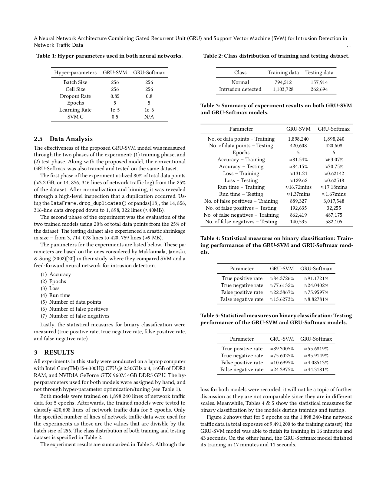

 Gated Recurrent Unit (GRU) is a recently-developed variation of the long short-term memory (LSTM) unit, both of which are types of recurrent neural network (RNN). Through empirical evidence, both models have been proven to be effective in a wide variety of machine learning tasks such as natural language processing (Wen et al., 2015), speech recognition (Chorowski et al., 2015), and text classification (Yang et al., 2016). Conventionally, like most neural networks, both of the aforementioned RNN variants employ the Softmax function as its final output layer for its prediction, and the cross-entropy function for computing its loss. In this paper, we present an amendment to this norm by introducing linear support vector machine (SVM) as the replacement for Softmax in the final output layer of a GRU model. Furthermore, the cross-entropy function shall be replaced with a margin-based function. While there have been similar studies (Alalshekmubarak & Smith, 2013; Tang, 2013), this proposal is primarily intended for binary classification on intrusion detection using the 2013 network traffic data from the honeypot systems of Kyoto University. Results show that the GRU-SVM model performs relatively higher than the conventional GRU-Softmax model. The proposed model reached a training accuracy of ~81.54% and a testing accuracy of ~84.15%, while the latter was able to reach a training accuracy of ~63.07% and a testing accuracy of ~70.75%. In addition, the juxtaposition of these two final output layers indicate that the SVM would outperform Softmax in prediction time - a theoretical implication which was supported by the actual training and testing time in the study.
Gated Recurrent Unit (GRU) is a recently-developed variation of the long short-term memory (LSTM) unit, both of which are types of recurrent neural network (RNN). Through empirical evidence, both models have been proven to be effective in a wide variety of machine learning tasks such as natural language processing (Wen et al., 2015), speech recognition (Chorowski et al., 2015), and text classification (Yang et al., 2016). Conventionally, like most neural networks, both of the aforementioned RNN variants employ the Softmax function as its final output layer for its prediction, and the cross-entropy function for computing its loss. In this paper, we present an amendment to this norm by introducing linear support vector machine (SVM) as the replacement for Softmax in the final output layer of a GRU model. Furthermore, the cross-entropy function shall be replaced with a margin-based function. While there have been similar studies (Alalshekmubarak & Smith, 2013; Tang, 2013), this proposal is primarily intended for binary classification on intrusion detection using the 2013 network traffic data from the honeypot systems of Kyoto University. Results show that the GRU-SVM model performs relatively higher than the conventional GRU-Softmax model. The proposed model reached a training accuracy of ~81.54% and a testing accuracy of ~84.15%, while the latter was able to reach a training accuracy of ~63.07% and a testing accuracy of ~70.75%. In addition, the juxtaposition of these two final output layers indicate that the SVM would outperform Softmax in prediction time - a theoretical implication which was supported by the actual training and testing time in the study.




 Optimization problems with more than one objective consist in a very attractive topic for researchers due to its applicability in real-world situations. Over the years, the research effort in the Computational Intelligence field resulted in algorithms able to achieve good results by solving problems with more than one conflicting objective. However, these techniques do not exhibit the same performance as the number of objectives increases and become greater than 3. This paper proposes an adaptation of the metaheuristic Fish School Search to solve optimization problems with many objectives. This adaptation is based on the division of the candidate solutions in clusters that are specialized in solving a single-objective problem generated by the decomposition of the original problem. For this, we used concepts and ideas often employed by state-of-the-art algorithms, namely: (i) reference points and lines in the objectives space; (ii) clustering process; and (iii) the decomposition technique Penalty-based Boundary Intersection. The proposed algorithm was compared with two state-of-the-art bio-inspired algorithms. Moreover, a version of the proposed technique tailored to solve multi-modal problems was also presented. The experiments executed have shown that the performance obtained by both versions is competitive with state-of-the-art results.
Optimization problems with more than one objective consist in a very attractive topic for researchers due to its applicability in real-world situations. Over the years, the research effort in the Computational Intelligence field resulted in algorithms able to achieve good results by solving problems with more than one conflicting objective. However, these techniques do not exhibit the same performance as the number of objectives increases and become greater than 3. This paper proposes an adaptation of the metaheuristic Fish School Search to solve optimization problems with many objectives. This adaptation is based on the division of the candidate solutions in clusters that are specialized in solving a single-objective problem generated by the decomposition of the original problem. For this, we used concepts and ideas often employed by state-of-the-art algorithms, namely: (i) reference points and lines in the objectives space; (ii) clustering process; and (iii) the decomposition technique Penalty-based Boundary Intersection. The proposed algorithm was compared with two state-of-the-art bio-inspired algorithms. Moreover, a version of the proposed technique tailored to solve multi-modal problems was also presented. The experiments executed have shown that the performance obtained by both versions is competitive with state-of-the-art results.


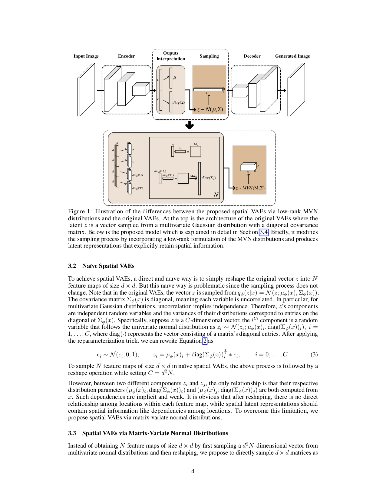

 The key idea of variational auto-encoders (VAEs) resembles that of traditional auto-encoder models in which spatial information is supposed to be explicitly encoded in the latent space. However, the latent variables in VAEs are vectors, which can be interpreted as multiple feature maps of size 1x1. Such representations can only convey spatial information implicitly when coupled with powerful decoders. In this work, we propose spatial VAEs that use feature maps of larger size as latent variables to explicitly capture spatial information. This is achieved by allowing the latent variables to be sampled from matrix-variate normal (MVN) distributions whose parameters are computed from the encoder network. To increase dependencies among locations on latent feature maps and reduce the number of parameters, we further propose spatial VAEs via low-rank MVN distributions. Experimental results show that the proposed spatial VAEs outperform original VAEs in capturing rich structural and spatial information.
The key idea of variational auto-encoders (VAEs) resembles that of traditional auto-encoder models in which spatial information is supposed to be explicitly encoded in the latent space. However, the latent variables in VAEs are vectors, which can be interpreted as multiple feature maps of size 1x1. Such representations can only convey spatial information implicitly when coupled with powerful decoders. In this work, we propose spatial VAEs that use feature maps of larger size as latent variables to explicitly capture spatial information. This is achieved by allowing the latent variables to be sampled from matrix-variate normal (MVN) distributions whose parameters are computed from the encoder network. To increase dependencies among locations on latent feature maps and reduce the number of parameters, we further propose spatial VAEs via low-rank MVN distributions. Experimental results show that the proposed spatial VAEs outperform original VAEs in capturing rich structural and spatial information.



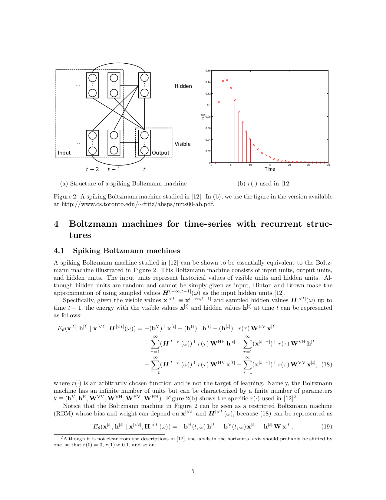
 We review Boltzmann machines extended for time-series. These models often have recurrent structure, and back propagration through time (BPTT) is used to learn their parameters. The per-step computational complexity of BPTT in online learning, however, grows linearly with respect to the length of preceding time-series (i.e., learning rule is not local in time), which limits the applicability of BPTT in online learning. We then review dynamic Boltzmann machines (DyBMs), whose learning rule is local in time. DyBM's learning rule relates to spike-timing dependent plasticity (STDP), which has been postulated and experimentally confirmed for biological neural networks.
We review Boltzmann machines extended for time-series. These models often have recurrent structure, and back propagration through time (BPTT) is used to learn their parameters. The per-step computational complexity of BPTT in online learning, however, grows linearly with respect to the length of preceding time-series (i.e., learning rule is not local in time), which limits the applicability of BPTT in online learning. We then review dynamic Boltzmann machines (DyBMs), whose learning rule is local in time. DyBM's learning rule relates to spike-timing dependent plasticity (STDP), which has been postulated and experimentally confirmed for biological neural networks.




 We review Boltzmann machines and energy-based models. A Boltzmann machine defines a probability distribution over binary-valued patterns. One can learn parameters of a Boltzmann machine via gradient based approaches in a way that log likelihood of data is increased. The gradient and Hessian of a Boltzmann machine admit beautiful mathematical representations, although computing them is in general intractable. This intractability motivates approximate methods, including Gibbs sampler and contrastive divergence, and tractable alternatives, namely energy-based models.
We review Boltzmann machines and energy-based models. A Boltzmann machine defines a probability distribution over binary-valued patterns. One can learn parameters of a Boltzmann machine via gradient based approaches in a way that log likelihood of data is increased. The gradient and Hessian of a Boltzmann machine admit beautiful mathematical representations, although computing them is in general intractable. This intractability motivates approximate methods, including Gibbs sampler and contrastive divergence, and tractable alternatives, namely energy-based models.




 In this work we present a theoretical model for differentiable programming. We construct an algebraic language that encapsulates formal semantics of differentiable programs by way of Operational Calculus. The algebraic nature of Operational Calculus can alter the properties of the programs that are expressed within the language and transform them into their solutions. In our model programs are elements of programming spaces and viewed as maps from the virtual memory space to itself. Virtual memory space is an algebra of programs, an algebraic data structure one can calculate with. We define the operator of differentiation ($\partial$) on programming spaces and, using its powers, implement the general shift operator and the operator of program composition. We provide the formula for the expansion of a differentiable program into an infinite tensor series in terms of the powers of $\partial$. We express the operator of program composition in terms of the generalized shift operator and $\partial$, which implements a differentiable composition in the language. Such operators serve as abstractions over the tensor series algebra, as main actors in our language. We demonstrate our models usefulness in differentiable programming by using it to analyse iterators, deriving fractional iterations and their iterating velocities, and explicitly solve the special case of ReduceSum.
In this work we present a theoretical model for differentiable programming. We construct an algebraic language that encapsulates formal semantics of differentiable programs by way of Operational Calculus. The algebraic nature of Operational Calculus can alter the properties of the programs that are expressed within the language and transform them into their solutions. In our model programs are elements of programming spaces and viewed as maps from the virtual memory space to itself. Virtual memory space is an algebra of programs, an algebraic data structure one can calculate with. We define the operator of differentiation ($\partial$) on programming spaces and, using its powers, implement the general shift operator and the operator of program composition. We provide the formula for the expansion of a differentiable program into an infinite tensor series in terms of the powers of $\partial$. We express the operator of program composition in terms of the generalized shift operator and $\partial$, which implements a differentiable composition in the language. Such operators serve as abstractions over the tensor series algebra, as main actors in our language. We demonstrate our models usefulness in differentiable programming by using it to analyse iterators, deriving fractional iterations and their iterating velocities, and explicitly solve the special case of ReduceSum.


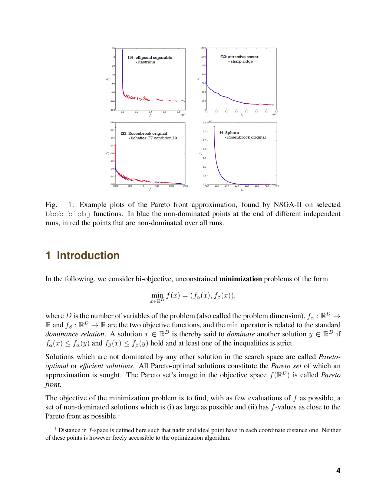

 Several test function suites are being used for numerical benchmarking of multiobjective optimization algorithms. While they have some desirable properties, like well-understood Pareto sets and Pareto fronts of various shapes, most of the currently used functions possess characteristics that are arguably under-represented in real-world problems. They mainly stem from the easier construction of such functions and result in improbable properties such as separability, optima located exactly at the boundary constraints, and the existence of variables that solely control the distance between a solution and the Pareto front. Here, we propose an alternative way to constructing multiobjective problems-by combining existing single-objective problems from the literature. We describe in particular the bbob-biobj test suite with 55 bi-objective functions in continuous domain, and its extended version with 92 bi-objective functions (bbob-biobj-ext). Both test suites have been implemented in the COCO platform for black-box optimization benchmarking. Finally, we recommend a general procedure for creating test suites for an arbitrary number of objectives. Besides providing the formal function definitions and presenting their (known) properties, this paper also aims at giving the rationale behind our approach in terms of groups of functions with similar properties, objective space normalization, and problem instances. The latter allows us to easily compare the performance of deterministic and stochastic solvers, which is an often overlooked issue in benchmarking.
Several test function suites are being used for numerical benchmarking of multiobjective optimization algorithms. While they have some desirable properties, like well-understood Pareto sets and Pareto fronts of various shapes, most of the currently used functions possess characteristics that are arguably under-represented in real-world problems. They mainly stem from the easier construction of such functions and result in improbable properties such as separability, optima located exactly at the boundary constraints, and the existence of variables that solely control the distance between a solution and the Pareto front. Here, we propose an alternative way to constructing multiobjective problems-by combining existing single-objective problems from the literature. We describe in particular the bbob-biobj test suite with 55 bi-objective functions in continuous domain, and its extended version with 92 bi-objective functions (bbob-biobj-ext). Both test suites have been implemented in the COCO platform for black-box optimization benchmarking. Finally, we recommend a general procedure for creating test suites for an arbitrary number of objectives. Besides providing the formal function definitions and presenting their (known) properties, this paper also aims at giving the rationale behind our approach in terms of groups of functions with similar properties, objective space normalization, and problem instances. The latter allows us to easily compare the performance of deterministic and stochastic solvers, which is an often overlooked issue in benchmarking.




 We investigate whether quantum annealers with select chip layouts can outperform classical computers in reinforcement learning tasks. We associate a transverse field Ising spin Hamiltonian with a layout of qubits similar to that of a deep Boltzmann machine (DBM) and use simulated quantum annealing (SQA) to numerically simulate quantum sampling from this system. We design a reinforcement learning algorithm in which the set of visible nodes representing the states and actions of an optimal policy are the first and last layers of the deep network. In absence of a transverse field, our simulations show that DBMs are trained more effectively than restricted Boltzmann machines (RBM) with the same number of nodes. We then develop a framework for training the network as a quantum Boltzmann machine (QBM) in the presence of a significant transverse field for reinforcement learning. This method also outperforms the reinforcement learning method that uses RBMs.
We investigate whether quantum annealers with select chip layouts can outperform classical computers in reinforcement learning tasks. We associate a transverse field Ising spin Hamiltonian with a layout of qubits similar to that of a deep Boltzmann machine (DBM) and use simulated quantum annealing (SQA) to numerically simulate quantum sampling from this system. We design a reinforcement learning algorithm in which the set of visible nodes representing the states and actions of an optimal policy are the first and last layers of the deep network. In absence of a transverse field, our simulations show that DBMs are trained more effectively than restricted Boltzmann machines (RBM) with the same number of nodes. We then develop a framework for training the network as a quantum Boltzmann machine (QBM) in the presence of a significant transverse field for reinforcement learning. This method also outperforms the reinforcement learning method that uses RBMs.




 This paper provides theoretical insights into why and how deep learning can generalize well, despite its large capacity, complexity, possible algorithmic instability, nonrobustness, and sharp minima, responding to an open question in the literature. We also discuss approaches to provide non-vacuous generalization guarantees for deep learning. Based on theoretical observations, we propose new open problems and discuss the limitations of our results.
This paper provides theoretical insights into why and how deep learning can generalize well, despite its large capacity, complexity, possible algorithmic instability, nonrobustness, and sharp minima, responding to an open question in the literature. We also discuss approaches to provide non-vacuous generalization guarantees for deep learning. Based on theoretical observations, we propose new open problems and discuss the limitations of our results.




 Several approaches have recently been proposed for learning decentralized deep multiagent policies that coordinate via a differentiable communication channel. While these policies are effective for many tasks, interpretation of their induced communication strategies has remained a challenge. Here we propose to interpret agents' messages by translating them. Unlike in typical machine translation problems, we have no parallel data to learn from. Instead we develop a translation model based on the insight that agent messages and natural language strings mean the same thing if they induce the same belief about the world in a listener. We present theoretical guarantees and empirical evidence that our approach preserves both the semantics and pragmatics of messages by ensuring that players communicating through a translation layer do not suffer a substantial loss in reward relative to players with a common language.
Several approaches have recently been proposed for learning decentralized deep multiagent policies that coordinate via a differentiable communication channel. While these policies are effective for many tasks, interpretation of their induced communication strategies has remained a challenge. Here we propose to interpret agents' messages by translating them. Unlike in typical machine translation problems, we have no parallel data to learn from. Instead we develop a translation model based on the insight that agent messages and natural language strings mean the same thing if they induce the same belief about the world in a listener. We present theoretical guarantees and empirical evidence that our approach preserves both the semantics and pragmatics of messages by ensuring that players communicating through a translation layer do not suffer a substantial loss in reward relative to players with a common language.




 It has been observed that many complex real-world networks have certain properties, such as a high clustering coefficient, a low diameter, and a power-law degree distribution. A network with a power-law degree distribution is known as scale-free network. In order to study these networks, various random graph models have been proposed, e.g. Preferential Attachment, Chung-Lu, or Hyperbolic. We look at the interplay between the power-law degree distribution and the run time of optimization techniques for well known combinatorial problems. We observe that on scale-free networks, simple evolutionary algorithms (EAs) quickly reach a constant-factor approximation ratio on common covering problems We prove that the single-objective (1+1)EA reaches a constant-factor approximation ratio on the Minimum Dominating Set problem, the Minimum Vertex Cover problem, the Minimum Connected Dominating Set problem, and the Maximum Independent Set problem in expected polynomial number of calls to the fitness function. Furthermore, we prove that the multi-objective GSEMO algorithm reaches a better approximation ratio than the (1+1)EA on those problems, within polynomial fitness evaluations.
It has been observed that many complex real-world networks have certain properties, such as a high clustering coefficient, a low diameter, and a power-law degree distribution. A network with a power-law degree distribution is known as scale-free network. In order to study these networks, various random graph models have been proposed, e.g. Preferential Attachment, Chung-Lu, or Hyperbolic. We look at the interplay between the power-law degree distribution and the run time of optimization techniques for well known combinatorial problems. We observe that on scale-free networks, simple evolutionary algorithms (EAs) quickly reach a constant-factor approximation ratio on common covering problems We prove that the single-objective (1+1)EA reaches a constant-factor approximation ratio on the Minimum Dominating Set problem, the Minimum Vertex Cover problem, the Minimum Connected Dominating Set problem, and the Maximum Independent Set problem in expected polynomial number of calls to the fitness function. Furthermore, we prove that the multi-objective GSEMO algorithm reaches a better approximation ratio than the (1+1)EA on those problems, within polynomial fitness evaluations.




 An important field in robotics is the optimization of controllers. Currently, robots are often treated as a black box in this optimization process, which is the reason why derivative-free optimization methods such as evolutionary algorithms or reinforcement learning are omnipresent. When gradient-based methods are used, models are kept small or rely on finite difference approximations for the Jacobian. This method quickly grows expensive with increasing numbers of parameters, such as found in deep learning. We propose the implementation of a modern physics engine, which can differentiate control parameters. This engine is implemented for both CPU and GPU. Firstly, this paper shows how such an engine speeds up the optimization process, even for small problems. Furthermore, it explains why this is an alternative approach to deep Q-learning, for using deep learning in robotics. Finally, we argue that this is a big step for deep learning in robotics, as it opens up new possibilities to optimize robots, both in hardware and software.
An important field in robotics is the optimization of controllers. Currently, robots are often treated as a black box in this optimization process, which is the reason why derivative-free optimization methods such as evolutionary algorithms or reinforcement learning are omnipresent. When gradient-based methods are used, models are kept small or rely on finite difference approximations for the Jacobian. This method quickly grows expensive with increasing numbers of parameters, such as found in deep learning. We propose the implementation of a modern physics engine, which can differentiate control parameters. This engine is implemented for both CPU and GPU. Firstly, this paper shows how such an engine speeds up the optimization process, even for small problems. Furthermore, it explains why this is an alternative approach to deep Q-learning, for using deep learning in robotics. Finally, we argue that this is a big step for deep learning in robotics, as it opens up new possibilities to optimize robots, both in hardware and software.



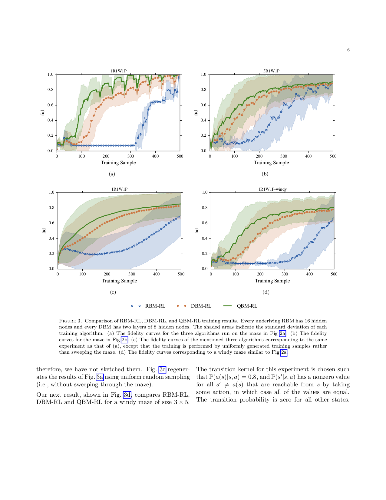
 Multi-task learning (MTL) allows deep neural networks to learn from related tasks by sharing parameters with other networks. In practice, however, MTL involves searching an enormous space of possible parameter sharing architectures to find (a) the layers or subspaces that benefit from sharing, (b) the appropriate amount of sharing, and (c) the appropriate relative weights of the different task losses. Recent work has addressed each of the above problems in isolation. In this work we present an approach that learns a latent multi-task architecture that jointly addresses (a)--(c). We present experiments on synthetic data and data from OntoNotes 5.0, including four different tasks and seven different domains. Our extension consistently outperforms previous approaches to learning latent architectures for multi-task problems and achieves up to 15% average error reductions over common approaches to MTL.
Multi-task learning (MTL) allows deep neural networks to learn from related tasks by sharing parameters with other networks. In practice, however, MTL involves searching an enormous space of possible parameter sharing architectures to find (a) the layers or subspaces that benefit from sharing, (b) the appropriate amount of sharing, and (c) the appropriate relative weights of the different task losses. Recent work has addressed each of the above problems in isolation. In this work we present an approach that learns a latent multi-task architecture that jointly addresses (a)--(c). We present experiments on synthetic data and data from OntoNotes 5.0, including four different tasks and seven different domains. Our extension consistently outperforms previous approaches to learning latent architectures for multi-task problems and achieves up to 15% average error reductions over common approaches to MTL.




 The seminal work of Gatys et al. demonstrated the power of Convolutional Neural Networks (CNNs) in creating artistic imagery by separating and recombining image content and style. This process of using CNNs to render a content image in different styles is referred to as Neural Style Transfer (NST). Since then, NST has become a trending topic both in academic literature and industrial applications. It is receiving increasing attention and a variety of approaches are proposed to either improve or extend the original NST algorithm. In this paper, we aim to provide a comprehensive overview of the current progress towards NST. We first propose a taxonomy of current algorithms in the field of NST. Then, we present several evaluation methods and compare different NST algorithms both qualitatively and quantitatively. The review concludes with a discussion of various applications of NST and open problems for future research. A list of papers discussed in this review, corresponding codes, pre-trained models and more comparison results are publicly available at https://github.com/ycjing/Neural-Style-Transfer-Papers.
The seminal work of Gatys et al. demonstrated the power of Convolutional Neural Networks (CNNs) in creating artistic imagery by separating and recombining image content and style. This process of using CNNs to render a content image in different styles is referred to as Neural Style Transfer (NST). Since then, NST has become a trending topic both in academic literature and industrial applications. It is receiving increasing attention and a variety of approaches are proposed to either improve or extend the original NST algorithm. In this paper, we aim to provide a comprehensive overview of the current progress towards NST. We first propose a taxonomy of current algorithms in the field of NST. Then, we present several evaluation methods and compare different NST algorithms both qualitatively and quantitatively. The review concludes with a discussion of various applications of NST and open problems for future research. A list of papers discussed in this review, corresponding codes, pre-trained models and more comparison results are publicly available at https://github.com/ycjing/Neural-Style-Transfer-Papers.