-
Advances in multimaterial 3D printing have the potential to reproduce various
visual appearance attributes of an object in addition to its shape. Since many
existing 3D file formats encode color and translucency by RGBA textures mapped
to 3D shapes, RGBA information is particularly important for practical
applications. In contrast to color (encoded by RGB), which is specified by the
object's reflectance, selected viewing conditions and a standard observer,
translucency (encoded by A) is neither linked to any measurable physical nor
perceptual quantity. Thus, reproducing translucency encoded by A is open for
interpretation.
In this paper, we propose a rigorous definition for A suitable for use in
graphical 3D printing, which is independent of the 3D printing hardware and
software, and which links both optical material properties and perceptual
uniformity for human observers. By deriving our definition from the absorption
and scattering coefficients of virtual homogeneous reference materials with an
isotropic phase function, we achieve two important properties. First, a simple
adjustment of A is possible, which preserves the translucency appearance if an
object is re-scaled for printing. Second, determining the value of A for a real
(potentially non-homogeneous) material, can be achieved by minimizing a
distance function between light transport measurements of this material and
simulated measurements of the reference materials. Such measurements can be
conducted by commercial spectrophotometers used in graphic arts.
Finally, we conduct visual experiments employing the method of constant
stimuli, and derive from them an embedding of A into a nearly perceptually
uniform scale of translucency for the reference materials.
-
In order to avoid the curse of dimensionality, frequently encountered in Big
Data analysis, there was a vast development in the field of linear and
nonlinear dimension reduction techniques in recent years. These techniques
(sometimes referred to as manifold learning) assume that the scattered input
data is lying on a lower dimensional manifold, thus the high dimensionality
problem can be overcome by learning the lower dimensionality behavior. However,
in real life applications, data is often very noisy. In this work, we propose a
method to approximate $\mathcal{M}$ a $d$-dimensional $C^{m+1}$ smooth
submanifold of $\mathbb{R}^n$ ($d \ll n$) based upon noisy scattered data
points (i.e., a data cloud). We assume that the data points are located "near"
the lower dimensional manifold and suggest a non-linear moving least-squares
projection on an approximating $d$-dimensional manifold. Under some mild
assumptions, the resulting approximant is shown to be infinitely smooth and of
high approximation order (i.e., $O(h^{m+1})$, where $h$ is the fill distance
and $m$ is the degree of the local polynomial approximation). The method
presented here assumes no analytic knowledge of the approximated manifold and
the approximation algorithm is linear in the large dimension $n$. Furthermore,
the approximating manifold can serve as a framework to perform operations
directly on the high dimensional data in a computationally efficient manner.
This way, the preparatory step of dimension reduction, which induces
distortions to the data, can be avoided altogether.
-
This paper presents the nearest neighbor value (NNV) algorithm for high
resolution (H.R.) image interpolation. The difference between the proposed
algorithm and conventional nearest neighbor algorithm is that the concept
applied, to estimate the missing pixel value, is guided by the nearest value
rather than the distance. In other words, the proposed concept selects one
pixel, among four directly surrounding the empty location, whose value is
almost equal to the value generated by the conventional bilinear interpolation
algorithm. The proposed method demonstrated higher performances in terms of
H.R. when compared to the conventional interpolation algorithms mentioned.
-
We propose a novel approach for deformation-aware neural networks that learn
the weighting and synthesis of dense volumetric deformation fields. Our method
specifically targets the space-time representation of physical surfaces from
liquid simulations. Liquids exhibit highly complex, non-linear behavior under
changing simulation conditions such as different initial conditions. Our
algorithm captures these complex phenomena in two stages: a first neural
network computes a weighting function for a set of pre-computed deformations,
while a second network directly generates a deformation field for refining the
surface. Key for successful training runs in this setting is a suitable loss
function that encodes the effect of the deformations, and a robust calculation
of the corresponding gradients. To demonstrate the effectiveness of our
approach, we showcase our method with several complex examples of flowing
liquids with topology changes. Our representation makes it possible to rapidly
generate the desired implicit surfaces. We have implemented a mobile
application to demonstrate that real-time interactions with complex liquid
effects are possible with our approach.
-
A descriptive approach for automatic generation of visual blends is
presented. The implemented system, the Blender, is composed of two components:
the Mapper and the Visual Blender. The approach uses structured visual
representations along with sets of visual relations which describe how the
elements (in which the visual representation can be decomposed) relate among
each other. Our system is a hybrid blender, as the blending process starts at
the Mapper (conceptual level) and ends at the Visual Blender (visual
representation level). The experimental results show that the Blender is able
to create analogies from input mental spaces and produce well-composed blends,
which follow the rules imposed by its base-analogy and its relations. The
resulting blends are visually interesting and some can be considered as
unexpected.
-
We present in this paper a generic and parameter-free algorithm to
efficiently build a wide variety of optical components, such as mirrors or
lenses, that satisfy some light energy constraints. In all of our problems, one
is given a collimated or point light source and a desired illumination after
reflection or refraction and the goal is to design the geometry of a mirror or
lens which transports exactly the light emitted by the source onto the target.
We first propose a general framework and show that eight different optical
component design problems amount to solving a light energy conservation
equation that involves the computation of visibility diagrams. We then show
that these diagrams all have the same structure and can be obtained by
intersecting a 3D Power diagram with a planar or spherical domain. This allows
us to propose an efficient and fully generic algorithm capable to solve these
eight optical component design problems. The support of the prescribed target
illumination can be a set of directions or a set of points located at a finite
distance. Our solutions satisfy design constraints such as convexity or
concavity. We show the effectiveness of our algorithm on simulated and
fabricated examples.
-
The problem of $\textit{visual metamerism}$ is defined as finding a family of
perceptually indistinguishable, yet physically different images. In this paper,
we propose our NeuroFovea metamer model, a foveated generative model that is
based on a mixture of peripheral representations and style transfer
forward-pass algorithms. Our gradient-descent free model is parametrized by a
foveated VGG19 encoder-decoder which allows us to encode images in high
dimensional space and interpolate between the content and texture information
with adaptive instance normalization anywhere in the visual field. Our
contributions include: 1) A framework for computing metamers that resembles a
noisy communication system via a foveated feed-forward encoder-decoder network
-- We observe that metamerism arises as a byproduct of noisy perturbations that
partially lie in the perceptual null space; 2) A perceptual optimization scheme
as a solution to the hyperparametric nature of our metamer model that requires
tuning of the image-texture tradeoff coefficients everywhere in the visual
field which are a consequence of internal noise; 3) An ABX psychophysical
evaluation of our metamers where we also find that the rate of growth of the
receptive fields in our model match V1 for reference metamers and V2 between
synthesized samples. Our model also renders metamers at roughly a second,
presenting a $\times1000$ speed-up compared to the previous work, which allows
for tractable data-driven metamer experiments.
-
A new method is presented, allowing for the generation of 3D terrain and
texture from coherent noise. The method is significantly faster than prevailing
fractal brownian motion approaches, while producing results of equivalent
quality. The algorithm is derived through a systematic approach that
generalizes to an arbitrary number of spatial dimensions and gradient
smoothness. The results are compared, in terms of performance and quality, to
fundamental and efficient gradient noise methods widely used in the domain of
fast terrain generation: Perlin noise and OpenSimplex noise. Finally, to
objectively quantify the degree of realism of the results, a fractal analysis
of the generated landscapes is performed and compared to real terrain data.
-
As many different 3D volumes could produce the same 2D x-ray image, inverting
this process is challenging. We show that recent deep learning-based
convolutional neural networks can solve this task. As the main challenge in
learning is the sheer amount of data created when extending the 2D image into a
3D volume, we suggest firstly to learn a coarse, fixed-resolution volume which
is then fused in a second step with the input x-ray into a high-resolution
volume. To train and validate our approach we introduce a new dataset that
comprises of close to half a million computer-simulated 2D x-ray images of 3D
volumes scanned from 175 mammalian species. Applications of our approach
include stereoscopic rendering of legacy x-ray images, re-rendering of x-rays
including changes of illumination, view pose or geometry. Our evaluation
includes comparison to previous tomography work, previous learning methods
using our data, a user study and application to a set of real x-rays.
-
In recent years, consumer-level depth cameras have been adopted for various
applications. However, they often produce depth maps at only a moderately high
frame rate (approximately 30 frames per second), preventing them from being
used for applications such as digitizing human performance involving fast
motion. On the other hand, low-cost, high-frame-rate video cameras are
available. This motivates us to develop a hybrid camera that consists of a
high-frame-rate video camera and a low-frame-rate depth camera and to allow
temporal interpolation of depth maps with the help of auxiliary color images.
To achieve this, we develop a novel algorithm that reconstructs intermediate
depth maps and estimates scene flow simultaneously. We test our algorithm on
various examples involving fast, non-rigid motions of single or multiple
objects. Our experiments show that our scene flow estimation method is more
precise than a tracking-based method and the state-of-the-art techniques.
-
We propose a platform-independent multi-threaded function library that
provides data structures to generate, differentiate and render both the
ordinary basis and the normalized B-basis of a user-specified extended
Chebyshev (EC) space that comprises the constants and can be identified with
the solution space of a constant-coefficient homogeneous linear differential
equation defined on a sufficiently small interval. Using the obtained
normalized B-bases, our library can also generate, (partially) differentiate,
modify and visualize a large family of so-called B-curves and tensor product
B-surfaces. Moreover, the library also implements methods that can be used to
perform dimension elevation, to subdivide B-curves and B-surfaces by means of
de Casteljau-like B-algorithms, and to generate basis transformations for the
B-representation of arbitrary integral curves and surfaces that are described
in traditional parametric form by means of the ordinary bases of the underlying
EC spaces. Independently of the algebraic, exponential, trigonometric or mixed
type of the applied EC space, the proposed library is numerically stable and
efficient up to a reasonable dimension number and may be useful for academics
and engineers in the fields of Approximation Theory, Computer Aided Geometric
Design, Computer Graphics, Isogeometric and Numerical Analysis.
-
For a monochrome layer $x$ of opacity $0\le o_x\le1 $ placed on another
monochrome layer of opacity 1, the result given by the standard formula is
$$\small\Pi\left({\bf
C}_\varphi\right)=1+\sum_{n=1}^2\left(2-n-(-1)^no_{\chi(\varphi+1)}\right)\left(\chi(n+\varphi-1)-o_{\chi(n+\varphi-1)}\right),$$
the formula being of course explained in detail in this paper. We will
eventually deduce a very simple theorem, generalize it and then see its
validity with alternative formulas to this standard containing the same main
properties here exposed.
-
The colorful appearance of a physical painting is determined by the
distribution of paint pigments across the canvas, which we model as a per-pixel
mixture of a small number of pigments with multispectral absorption and
scattering coefficients. We present an algorithm to efficiently recover this
structure from an RGB image, yielding a plausible set of pigments and a low RGB
reconstruction error. We show that under certain circumstances we are able to
recover pigments that are close to ground truth, while in all cases our results
are always plausible. Using our decomposition, we repose standard digital image
editing operations as operations in pigment space rather than RGB, with
interestingly novel results. We demonstrate tonal adjustments, selection
masking, cut-copy-paste, recoloring, palette summarization, and edge
enhancement.
-
We propose MAD-GAN, an intuitive generalization to the Generative Adversarial
Networks (GANs) and its conditional variants to address the well known problem
of mode collapse. First, MAD-GAN is a multi-agent GAN architecture
incorporating multiple generators and one discriminator. Second, to enforce
that different generators capture diverse high probability modes, the
discriminator of MAD-GAN is designed such that along with finding the real and
fake samples, it is also required to identify the generator that generated the
given fake sample. Intuitively, to succeed in this task, the discriminator must
learn to push different generators towards different identifiable modes. We
perform extensive experiments on synthetic and real datasets and compare
MAD-GAN with different variants of GAN. We show high quality diverse sample
generations for challenging tasks such as image-to-image translation and face
generation. In addition, we also show that MAD-GAN is able to disentangle
different modalities when trained using highly challenging diverse-class
dataset (e.g. dataset with images of forests, icebergs, and bedrooms). In the
end, we show its efficacy on the unsupervised feature representation task. In
Appendix, we introduce a similarity based competing objective (MAD-GAN-Sim)
which encourages different generators to generate diverse samples based on a
user defined similarity metric. We show its performance on the image-to-image
translation, and also show its effectiveness on the unsupervised feature
representation task.
-
In this article, we devise a concise algorithm for computing BOCP. Our method
is simple, easy-to-implement but without loss of efficiency. Given two
circular-arc polygons with $m$ and $n$ edges respectively, our method runs in
$O(m+n+(l+k)\log l)$ time, using $O(m+n+k)$ space, where $k$ is the number of
intersections, and $l$ is the number of {edge}s. Our algorithm has the power to
approximate to linear complexity when $k$ and $l$ are small. The superiority of
the proposed algorithm is also validated through empirical study.
-
This paper proposes a new data-driven approach to model detailed splashes for
liquid simulations with neural networks. Our model learns to generate
small-scale splash detail for the fluid-implicit-particle method using training
data acquired from physically parametrized, high resolution simulations. We use
neural networks to model the regression of splash formation using a classifier
together with a velocity modifier. For the velocity modification, we employ a
heteroscedastic model. We evaluate our method for different spatial scales,
simulation setups, and solvers. Our simulation results demonstrate that our
model significantly improves visual fidelity with a large amount of realistic
droplet formation and yields splash detail much more efficiently than finer
discretizations.
-
A robust and informative local shape descriptor plays an important role in
mesh registration. In this regard, spectral descriptors that are based on the
spectrum of the Laplace-Beltrami operator have been a popular subject of
research for the last decade due to their advantageous properties, such as
isometry invariance. Despite such, however, spectral descriptors often fail to
give a correct similarity measure for non-isometric cases where the metric
distortion between the models is large. Hence, they are not reliable for
correspondence matching problems when the models are not isometric. In this
paper, it is proposed a method to improve the similarity metric of spectral
descriptors for correspondence matching problems. We embed a spectral shape
descriptor into a different metric space where the Euclidean distance between
the elements directly indicates the geometric dissimilarity. We design and
train a Siamese neural network to find such an embedding, where the embedded
descriptors are promoted to rearrange based on the geometric similarity. We
demonstrate our approach can significantly enhance the performance of the
conventional spectral descriptors by the simple augmentation achieved via the
Siamese neural network in comparison to other state-of-the-art methods.
-
Purpose: The class of models that can be represented by STL files is larger
than the class of models that can be printed using additive manufacturing
technologies. Stated differently, there exist well-formed STL files that cannot
be printed. In this paper such a gap is formalized and a fully automatic
procedure is described to turn any such file into a printable model.
Approach: Based on well-established concepts from combinatorial topology, we
provide an unambiguous description of all the mathematical entities involved in
the modeling-printing pipeline. Specifically, we formally define the conditions
that an STL file must satisfy to be printable and, based on these, we design an
as-exact-as-possible repairing algorithm.
Findings: We have found that, in order to cope with all the possible triangle
configurations, the algorithm must distinguish between triangles that bound
solid parts and triangles that constitute zero-thickness sheets. Only the
former set can be fixed without distortion.
Originality: Previous methods that are guaranteed to fix all the possible
configurations provide only approximate solutions with an unnecessary
distortion. Conversely, our procedure is as exact as possible, meaning that no
visible distortion is introduced unless it is strictly imposed by limitations
of the printing device. Thanks to such an unprecedented flexibility and
accuracy, this algorithm is expected to significantly simplify the
modeling-printing process, in particular within the continuously emerging
non-professional "maker" communities.
-
Sketch-based modeling strives to bring the ease and immediacy of drawing to
the 3D world. However, while drawings are easy for humans to create, they are
very challenging for computers to interpret due to their sparsity and
ambiguity. We propose a data-driven approach that tackles this challenge by
learning to reconstruct 3D shapes from one or more drawings. At the core of our
approach is a deep convolutional neural network (CNN) that predicts occupancy
of a voxel grid from a line drawing. This CNN provides us with an initial 3D
reconstruction as soon as the user completes a single drawing of the desired
shape. We complement this single-view network with an updater CNN that refines
an existing prediction given a new drawing of the shape created from a novel
viewpoint. A key advantage of our approach is that we can apply the updater
iteratively to fuse information from an arbitrary number of viewpoints, without
requiring explicit stroke correspondences between the drawings. We train both
CNNs by rendering synthetic contour drawings from hand-modeled shape
collections as well as from procedurally-generated abstract shapes. Finally, we
integrate our CNNs in a minimal modeling interface that allows users to
seamlessly draw an object, rotate it to see its 3D reconstruction, and refine
it by re-drawing from another vantage point using the 3D reconstruction as
guidance. The main strengths of our approach are its robustness to freehand
bitmap drawings, its ability to adapt to different object categories, and the
continuum it offers between single-view and multi-view sketch-based modeling.
-
We study data-driven representations for three-dimensional triangle meshes,
which are one of the prevalent objects used to represent 3D geometry. Recent
works have developed models that exploit the intrinsic geometry of manifolds
and graphs, namely the Graph Neural Networks (GNNs) and its spectral variants,
which learn from the local metric tensor via the Laplacian operator. Despite
offering excellent sample complexity and built-in invariances, intrinsic
geometry alone is invariant to isometric deformations, making it unsuitable for
many applications. To overcome this limitation, we propose several upgrades to
GNNs to leverage extrinsic differential geometry properties of
three-dimensional surfaces, increasing its modeling power.
In particular, we propose to exploit the Dirac operator, whose spectrum
detects principal curvature directions --- this is in stark contrast with the
classical Laplace operator, which directly measures mean curvature. We coin the
resulting models \emph{Surface Networks (SN)}. We prove that these models
define shape representations that are stable to deformation and to
discretization, and we demonstrate the efficiency and versatility of SNs on two
challenging tasks: temporal prediction of mesh deformations under non-linear
dynamics and generative models using a variational autoencoder framework with
encoders/decoders given by SNs.
-
Blue noise sampling has proved useful for many graphics applications, but
remains underexplored in high-dimensional spaces due to the difficulty of
generating distributions and proving properties about them. We present a blue
noise sampling method with good quality and performance across different
dimensions. The method, spoke-dart sampling, shoots rays from prior samples and
selects samples from these rays. It combines the advantages of two major
high-dimensional sampling methods: the locality of advancing front with the
dimensionality-reduction of hyperplanes, specifically line sampling. We prove
that the output sampling is saturated with high probability, with bounds on
distances between pairs of samples and between any domain point and its nearest
sample. We demonstrate spoke-dart applications for approximate Delaunay graph
construction, global optimization, and robotic motion planning. Both the
blue-noise quality of the output distribution and the adaptability of the
intermediate processes of our method are useful in these applications.
-
This paper introduces a novel weighted unsupervised learning for object
detection using an RGB-D camera. This technique is feasible for detecting the
moving objects in the noisy environments that are captured by an RGB-D camera.
The main contribution of this paper is a real-time algorithm for detecting each
object using weighted clustering as a separate cluster. In a preprocessing
step, the algorithm calculates the pose 3D position X, Y, Z and RGB color of
each data point and then it calculates each data point's normal vector using
the point's neighbor. After preprocessing, our algorithm calculates k-weights
for each data point; each weight indicates membership. Resulting in clustered
objects of the scene.
-
The real world exhibits an abundance of non-stationary textures. Examples
include textures with large-scale structures, as well as spatially variant and
inhomogeneous textures. While existing example-based texture synthesis methods
can cope well with stationary textures, non-stationary textures still pose a
considerable challenge, which remains unresolved. In this paper, we propose a
new approach for example-based non-stationary texture synthesis. Our approach
uses a generative adversarial network (GAN), trained to double the spatial
extent of texture blocks extracted from a specific texture exemplar. Once
trained, the fully convolutional generator is able to expand the size of the
entire exemplar, as well as of any of its sub-blocks. We demonstrate that this
conceptually simple approach is highly effective for capturing large-scale
structures, as well as other non-stationary attributes of the input exemplar.
As a result, it can cope with challenging textures, which, to our knowledge, no
other existing method can handle.
-
We present a novel end-to-end framework for facial performance capture given
a monocular video of an actor's face. Our framework are comprised of 2 parts.
First, to extract the information in the frames, we optimize a triplet loss to
learn the embedding space which ensures the semantically closer facial
expressions are closer in the embedding space and the model can be transferred
to distinguish the expressions that are not presented in the training dataset.
Second, the embeddings are fed into an LSTM network to learn the deformation
between frames. In the experiments, we demonstrated that compared to other
methods, our method can distinguish the delicate motion around lips and
significantly reduce jitters between the tracked meshes.
-
Numerous techniques have been proposed for reconstructing 3D models for
opaque objects in past decades. However, none of them can be directly applied
to transparent objects. This paper presents a fully automatic approach for
reconstructing complete 3D shapes of transparent objects. Through positioning
an object on a turntable, its silhouettes and light refraction paths under
different viewing directions are captured. Then, starting from an initial rough
model generated from space carving, our algorithm progressively optimizes the
model under three constraints: surface and refraction normal consistency,
surface projection and silhouette consistency, and surface smoothness.
Experimental results on both synthetic and real objects demonstrate that our
method can successfully recover the complex shapes of transparent objects and
faithfully reproduce their light refraction properties.





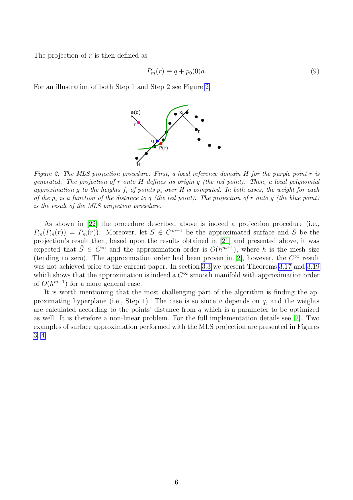 In order to avoid the curse of dimensionality, frequently encountered in Big Data analysis, there was a vast development in the field of linear and nonlinear dimension reduction techniques in recent years. These techniques (sometimes referred to as manifold learning) assume that the scattered input data is lying on a lower dimensional manifold, thus the high dimensionality problem can be overcome by learning the lower dimensionality behavior. However, in real life applications, data is often very noisy. In this work, we propose a method to approximate $\mathcal{M}$ a $d$-dimensional $C^{m+1}$ smooth submanifold of $\mathbb{R}^n$ ($d \ll n$) based upon noisy scattered data points (i.e., a data cloud). We assume that the data points are located "near" the lower dimensional manifold and suggest a non-linear moving least-squares projection on an approximating $d$-dimensional manifold. Under some mild assumptions, the resulting approximant is shown to be infinitely smooth and of high approximation order (i.e., $O(h^{m+1})$, where $h$ is the fill distance and $m$ is the degree of the local polynomial approximation). The method presented here assumes no analytic knowledge of the approximated manifold and the approximation algorithm is linear in the large dimension $n$. Furthermore, the approximating manifold can serve as a framework to perform operations directly on the high dimensional data in a computationally efficient manner. This way, the preparatory step of dimension reduction, which induces distortions to the data, can be avoided altogether.
In order to avoid the curse of dimensionality, frequently encountered in Big Data analysis, there was a vast development in the field of linear and nonlinear dimension reduction techniques in recent years. These techniques (sometimes referred to as manifold learning) assume that the scattered input data is lying on a lower dimensional manifold, thus the high dimensionality problem can be overcome by learning the lower dimensionality behavior. However, in real life applications, data is often very noisy. In this work, we propose a method to approximate $\mathcal{M}$ a $d$-dimensional $C^{m+1}$ smooth submanifold of $\mathbb{R}^n$ ($d \ll n$) based upon noisy scattered data points (i.e., a data cloud). We assume that the data points are located "near" the lower dimensional manifold and suggest a non-linear moving least-squares projection on an approximating $d$-dimensional manifold. Under some mild assumptions, the resulting approximant is shown to be infinitely smooth and of high approximation order (i.e., $O(h^{m+1})$, where $h$ is the fill distance and $m$ is the degree of the local polynomial approximation). The method presented here assumes no analytic knowledge of the approximated manifold and the approximation algorithm is linear in the large dimension $n$. Furthermore, the approximating manifold can serve as a framework to perform operations directly on the high dimensional data in a computationally efficient manner. This way, the preparatory step of dimension reduction, which induces distortions to the data, can be avoided altogether.




 We propose a novel approach for deformation-aware neural networks that learn the weighting and synthesis of dense volumetric deformation fields. Our method specifically targets the space-time representation of physical surfaces from liquid simulations. Liquids exhibit highly complex, non-linear behavior under changing simulation conditions such as different initial conditions. Our algorithm captures these complex phenomena in two stages: a first neural network computes a weighting function for a set of pre-computed deformations, while a second network directly generates a deformation field for refining the surface. Key for successful training runs in this setting is a suitable loss function that encodes the effect of the deformations, and a robust calculation of the corresponding gradients. To demonstrate the effectiveness of our approach, we showcase our method with several complex examples of flowing liquids with topology changes. Our representation makes it possible to rapidly generate the desired implicit surfaces. We have implemented a mobile application to demonstrate that real-time interactions with complex liquid effects are possible with our approach.
We propose a novel approach for deformation-aware neural networks that learn the weighting and synthesis of dense volumetric deformation fields. Our method specifically targets the space-time representation of physical surfaces from liquid simulations. Liquids exhibit highly complex, non-linear behavior under changing simulation conditions such as different initial conditions. Our algorithm captures these complex phenomena in two stages: a first neural network computes a weighting function for a set of pre-computed deformations, while a second network directly generates a deformation field for refining the surface. Key for successful training runs in this setting is a suitable loss function that encodes the effect of the deformations, and a robust calculation of the corresponding gradients. To demonstrate the effectiveness of our approach, we showcase our method with several complex examples of flowing liquids with topology changes. Our representation makes it possible to rapidly generate the desired implicit surfaces. We have implemented a mobile application to demonstrate that real-time interactions with complex liquid effects are possible with our approach.


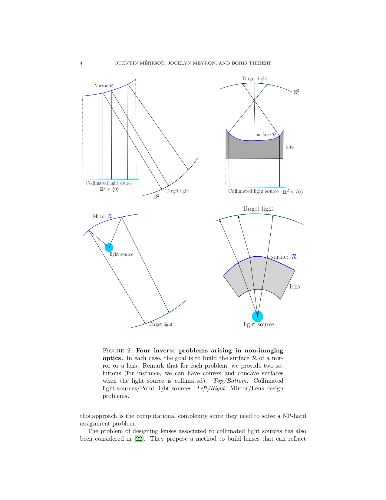

 We present in this paper a generic and parameter-free algorithm to efficiently build a wide variety of optical components, such as mirrors or lenses, that satisfy some light energy constraints. In all of our problems, one is given a collimated or point light source and a desired illumination after reflection or refraction and the goal is to design the geometry of a mirror or lens which transports exactly the light emitted by the source onto the target. We first propose a general framework and show that eight different optical component design problems amount to solving a light energy conservation equation that involves the computation of visibility diagrams. We then show that these diagrams all have the same structure and can be obtained by intersecting a 3D Power diagram with a planar or spherical domain. This allows us to propose an efficient and fully generic algorithm capable to solve these eight optical component design problems. The support of the prescribed target illumination can be a set of directions or a set of points located at a finite distance. Our solutions satisfy design constraints such as convexity or concavity. We show the effectiveness of our algorithm on simulated and fabricated examples.
We present in this paper a generic and parameter-free algorithm to efficiently build a wide variety of optical components, such as mirrors or lenses, that satisfy some light energy constraints. In all of our problems, one is given a collimated or point light source and a desired illumination after reflection or refraction and the goal is to design the geometry of a mirror or lens which transports exactly the light emitted by the source onto the target. We first propose a general framework and show that eight different optical component design problems amount to solving a light energy conservation equation that involves the computation of visibility diagrams. We then show that these diagrams all have the same structure and can be obtained by intersecting a 3D Power diagram with a planar or spherical domain. This allows us to propose an efficient and fully generic algorithm capable to solve these eight optical component design problems. The support of the prescribed target illumination can be a set of directions or a set of points located at a finite distance. Our solutions satisfy design constraints such as convexity or concavity. We show the effectiveness of our algorithm on simulated and fabricated examples.



 The problem of $\textit{visual metamerism}$ is defined as finding a family of perceptually indistinguishable, yet physically different images. In this paper, we propose our NeuroFovea metamer model, a foveated generative model that is based on a mixture of peripheral representations and style transfer forward-pass algorithms. Our gradient-descent free model is parametrized by a foveated VGG19 encoder-decoder which allows us to encode images in high dimensional space and interpolate between the content and texture information with adaptive instance normalization anywhere in the visual field. Our contributions include: 1) A framework for computing metamers that resembles a noisy communication system via a foveated feed-forward encoder-decoder network -- We observe that metamerism arises as a byproduct of noisy perturbations that partially lie in the perceptual null space; 2) A perceptual optimization scheme as a solution to the hyperparametric nature of our metamer model that requires tuning of the image-texture tradeoff coefficients everywhere in the visual field which are a consequence of internal noise; 3) An ABX psychophysical evaluation of our metamers where we also find that the rate of growth of the receptive fields in our model match V1 for reference metamers and V2 between synthesized samples. Our model also renders metamers at roughly a second, presenting a $\times1000$ speed-up compared to the previous work, which allows for tractable data-driven metamer experiments.
The problem of $\textit{visual metamerism}$ is defined as finding a family of perceptually indistinguishable, yet physically different images. In this paper, we propose our NeuroFovea metamer model, a foveated generative model that is based on a mixture of peripheral representations and style transfer forward-pass algorithms. Our gradient-descent free model is parametrized by a foveated VGG19 encoder-decoder which allows us to encode images in high dimensional space and interpolate between the content and texture information with adaptive instance normalization anywhere in the visual field. Our contributions include: 1) A framework for computing metamers that resembles a noisy communication system via a foveated feed-forward encoder-decoder network -- We observe that metamerism arises as a byproduct of noisy perturbations that partially lie in the perceptual null space; 2) A perceptual optimization scheme as a solution to the hyperparametric nature of our metamer model that requires tuning of the image-texture tradeoff coefficients everywhere in the visual field which are a consequence of internal noise; 3) An ABX psychophysical evaluation of our metamers where we also find that the rate of growth of the receptive fields in our model match V1 for reference metamers and V2 between synthesized samples. Our model also renders metamers at roughly a second, presenting a $\times1000$ speed-up compared to the previous work, which allows for tractable data-driven metamer experiments.




 A new method is presented, allowing for the generation of 3D terrain and texture from coherent noise. The method is significantly faster than prevailing fractal brownian motion approaches, while producing results of equivalent quality. The algorithm is derived through a systematic approach that generalizes to an arbitrary number of spatial dimensions and gradient smoothness. The results are compared, in terms of performance and quality, to fundamental and efficient gradient noise methods widely used in the domain of fast terrain generation: Perlin noise and OpenSimplex noise. Finally, to objectively quantify the degree of realism of the results, a fractal analysis of the generated landscapes is performed and compared to real terrain data.
A new method is presented, allowing for the generation of 3D terrain and texture from coherent noise. The method is significantly faster than prevailing fractal brownian motion approaches, while producing results of equivalent quality. The algorithm is derived through a systematic approach that generalizes to an arbitrary number of spatial dimensions and gradient smoothness. The results are compared, in terms of performance and quality, to fundamental and efficient gradient noise methods widely used in the domain of fast terrain generation: Perlin noise and OpenSimplex noise. Finally, to objectively quantify the degree of realism of the results, a fractal analysis of the generated landscapes is performed and compared to real terrain data.




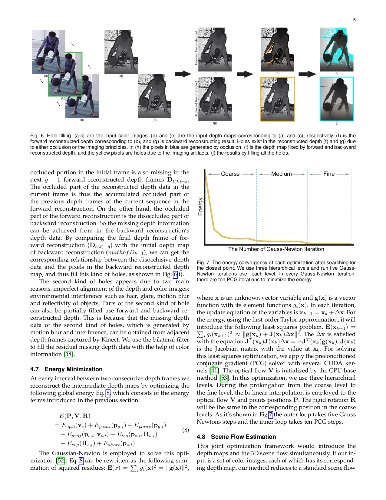 In recent years, consumer-level depth cameras have been adopted for various applications. However, they often produce depth maps at only a moderately high frame rate (approximately 30 frames per second), preventing them from being used for applications such as digitizing human performance involving fast motion. On the other hand, low-cost, high-frame-rate video cameras are available. This motivates us to develop a hybrid camera that consists of a high-frame-rate video camera and a low-frame-rate depth camera and to allow temporal interpolation of depth maps with the help of auxiliary color images. To achieve this, we develop a novel algorithm that reconstructs intermediate depth maps and estimates scene flow simultaneously. We test our algorithm on various examples involving fast, non-rigid motions of single or multiple objects. Our experiments show that our scene flow estimation method is more precise than a tracking-based method and the state-of-the-art techniques.
In recent years, consumer-level depth cameras have been adopted for various applications. However, they often produce depth maps at only a moderately high frame rate (approximately 30 frames per second), preventing them from being used for applications such as digitizing human performance involving fast motion. On the other hand, low-cost, high-frame-rate video cameras are available. This motivates us to develop a hybrid camera that consists of a high-frame-rate video camera and a low-frame-rate depth camera and to allow temporal interpolation of depth maps with the help of auxiliary color images. To achieve this, we develop a novel algorithm that reconstructs intermediate depth maps and estimates scene flow simultaneously. We test our algorithm on various examples involving fast, non-rigid motions of single or multiple objects. Our experiments show that our scene flow estimation method is more precise than a tracking-based method and the state-of-the-art techniques.




 We propose a platform-independent multi-threaded function library that provides data structures to generate, differentiate and render both the ordinary basis and the normalized B-basis of a user-specified extended Chebyshev (EC) space that comprises the constants and can be identified with the solution space of a constant-coefficient homogeneous linear differential equation defined on a sufficiently small interval. Using the obtained normalized B-bases, our library can also generate, (partially) differentiate, modify and visualize a large family of so-called B-curves and tensor product B-surfaces. Moreover, the library also implements methods that can be used to perform dimension elevation, to subdivide B-curves and B-surfaces by means of de Casteljau-like B-algorithms, and to generate basis transformations for the B-representation of arbitrary integral curves and surfaces that are described in traditional parametric form by means of the ordinary bases of the underlying EC spaces. Independently of the algebraic, exponential, trigonometric or mixed type of the applied EC space, the proposed library is numerically stable and efficient up to a reasonable dimension number and may be useful for academics and engineers in the fields of Approximation Theory, Computer Aided Geometric Design, Computer Graphics, Isogeometric and Numerical Analysis.
We propose a platform-independent multi-threaded function library that provides data structures to generate, differentiate and render both the ordinary basis and the normalized B-basis of a user-specified extended Chebyshev (EC) space that comprises the constants and can be identified with the solution space of a constant-coefficient homogeneous linear differential equation defined on a sufficiently small interval. Using the obtained normalized B-bases, our library can also generate, (partially) differentiate, modify and visualize a large family of so-called B-curves and tensor product B-surfaces. Moreover, the library also implements methods that can be used to perform dimension elevation, to subdivide B-curves and B-surfaces by means of de Casteljau-like B-algorithms, and to generate basis transformations for the B-representation of arbitrary integral curves and surfaces that are described in traditional parametric form by means of the ordinary bases of the underlying EC spaces. Independently of the algebraic, exponential, trigonometric or mixed type of the applied EC space, the proposed library is numerically stable and efficient up to a reasonable dimension number and may be useful for academics and engineers in the fields of Approximation Theory, Computer Aided Geometric Design, Computer Graphics, Isogeometric and Numerical Analysis.




 The colorful appearance of a physical painting is determined by the distribution of paint pigments across the canvas, which we model as a per-pixel mixture of a small number of pigments with multispectral absorption and scattering coefficients. We present an algorithm to efficiently recover this structure from an RGB image, yielding a plausible set of pigments and a low RGB reconstruction error. We show that under certain circumstances we are able to recover pigments that are close to ground truth, while in all cases our results are always plausible. Using our decomposition, we repose standard digital image editing operations as operations in pigment space rather than RGB, with interestingly novel results. We demonstrate tonal adjustments, selection masking, cut-copy-paste, recoloring, palette summarization, and edge enhancement.
The colorful appearance of a physical painting is determined by the distribution of paint pigments across the canvas, which we model as a per-pixel mixture of a small number of pigments with multispectral absorption and scattering coefficients. We present an algorithm to efficiently recover this structure from an RGB image, yielding a plausible set of pigments and a low RGB reconstruction error. We show that under certain circumstances we are able to recover pigments that are close to ground truth, while in all cases our results are always plausible. Using our decomposition, we repose standard digital image editing operations as operations in pigment space rather than RGB, with interestingly novel results. We demonstrate tonal adjustments, selection masking, cut-copy-paste, recoloring, palette summarization, and edge enhancement.




 We propose MAD-GAN, an intuitive generalization to the Generative Adversarial Networks (GANs) and its conditional variants to address the well known problem of mode collapse. First, MAD-GAN is a multi-agent GAN architecture incorporating multiple generators and one discriminator. Second, to enforce that different generators capture diverse high probability modes, the discriminator of MAD-GAN is designed such that along with finding the real and fake samples, it is also required to identify the generator that generated the given fake sample. Intuitively, to succeed in this task, the discriminator must learn to push different generators towards different identifiable modes. We perform extensive experiments on synthetic and real datasets and compare MAD-GAN with different variants of GAN. We show high quality diverse sample generations for challenging tasks such as image-to-image translation and face generation. In addition, we also show that MAD-GAN is able to disentangle different modalities when trained using highly challenging diverse-class dataset (e.g. dataset with images of forests, icebergs, and bedrooms). In the end, we show its efficacy on the unsupervised feature representation task. In Appendix, we introduce a similarity based competing objective (MAD-GAN-Sim) which encourages different generators to generate diverse samples based on a user defined similarity metric. We show its performance on the image-to-image translation, and also show its effectiveness on the unsupervised feature representation task.
We propose MAD-GAN, an intuitive generalization to the Generative Adversarial Networks (GANs) and its conditional variants to address the well known problem of mode collapse. First, MAD-GAN is a multi-agent GAN architecture incorporating multiple generators and one discriminator. Second, to enforce that different generators capture diverse high probability modes, the discriminator of MAD-GAN is designed such that along with finding the real and fake samples, it is also required to identify the generator that generated the given fake sample. Intuitively, to succeed in this task, the discriminator must learn to push different generators towards different identifiable modes. We perform extensive experiments on synthetic and real datasets and compare MAD-GAN with different variants of GAN. We show high quality diverse sample generations for challenging tasks such as image-to-image translation and face generation. In addition, we also show that MAD-GAN is able to disentangle different modalities when trained using highly challenging diverse-class dataset (e.g. dataset with images of forests, icebergs, and bedrooms). In the end, we show its efficacy on the unsupervised feature representation task. In Appendix, we introduce a similarity based competing objective (MAD-GAN-Sim) which encourages different generators to generate diverse samples based on a user defined similarity metric. We show its performance on the image-to-image translation, and also show its effectiveness on the unsupervised feature representation task.




 In this article, we devise a concise algorithm for computing BOCP. Our method is simple, easy-to-implement but without loss of efficiency. Given two circular-arc polygons with $m$ and $n$ edges respectively, our method runs in $O(m+n+(l+k)\log l)$ time, using $O(m+n+k)$ space, where $k$ is the number of intersections, and $l$ is the number of {edge}s. Our algorithm has the power to approximate to linear complexity when $k$ and $l$ are small. The superiority of the proposed algorithm is also validated through empirical study.
In this article, we devise a concise algorithm for computing BOCP. Our method is simple, easy-to-implement but without loss of efficiency. Given two circular-arc polygons with $m$ and $n$ edges respectively, our method runs in $O(m+n+(l+k)\log l)$ time, using $O(m+n+k)$ space, where $k$ is the number of intersections, and $l$ is the number of {edge}s. Our algorithm has the power to approximate to linear complexity when $k$ and $l$ are small. The superiority of the proposed algorithm is also validated through empirical study.


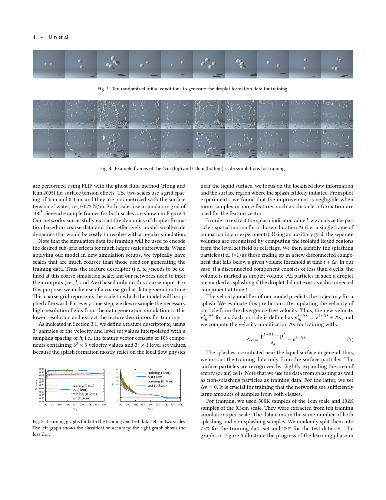

 This paper proposes a new data-driven approach to model detailed splashes for liquid simulations with neural networks. Our model learns to generate small-scale splash detail for the fluid-implicit-particle method using training data acquired from physically parametrized, high resolution simulations. We use neural networks to model the regression of splash formation using a classifier together with a velocity modifier. For the velocity modification, we employ a heteroscedastic model. We evaluate our method for different spatial scales, simulation setups, and solvers. Our simulation results demonstrate that our model significantly improves visual fidelity with a large amount of realistic droplet formation and yields splash detail much more efficiently than finer discretizations.
This paper proposes a new data-driven approach to model detailed splashes for liquid simulations with neural networks. Our model learns to generate small-scale splash detail for the fluid-implicit-particle method using training data acquired from physically parametrized, high resolution simulations. We use neural networks to model the regression of splash formation using a classifier together with a velocity modifier. For the velocity modification, we employ a heteroscedastic model. We evaluate our method for different spatial scales, simulation setups, and solvers. Our simulation results demonstrate that our model significantly improves visual fidelity with a large amount of realistic droplet formation and yields splash detail much more efficiently than finer discretizations.




 Purpose: The class of models that can be represented by STL files is larger than the class of models that can be printed using additive manufacturing technologies. Stated differently, there exist well-formed STL files that cannot be printed. In this paper such a gap is formalized and a fully automatic procedure is described to turn any such file into a printable model. Approach: Based on well-established concepts from combinatorial topology, we provide an unambiguous description of all the mathematical entities involved in the modeling-printing pipeline. Specifically, we formally define the conditions that an STL file must satisfy to be printable and, based on these, we design an as-exact-as-possible repairing algorithm. Findings: We have found that, in order to cope with all the possible triangle configurations, the algorithm must distinguish between triangles that bound solid parts and triangles that constitute zero-thickness sheets. Only the former set can be fixed without distortion. Originality: Previous methods that are guaranteed to fix all the possible configurations provide only approximate solutions with an unnecessary distortion. Conversely, our procedure is as exact as possible, meaning that no visible distortion is introduced unless it is strictly imposed by limitations of the printing device. Thanks to such an unprecedented flexibility and accuracy, this algorithm is expected to significantly simplify the modeling-printing process, in particular within the continuously emerging non-professional "maker" communities.
Purpose: The class of models that can be represented by STL files is larger than the class of models that can be printed using additive manufacturing technologies. Stated differently, there exist well-formed STL files that cannot be printed. In this paper such a gap is formalized and a fully automatic procedure is described to turn any such file into a printable model. Approach: Based on well-established concepts from combinatorial topology, we provide an unambiguous description of all the mathematical entities involved in the modeling-printing pipeline. Specifically, we formally define the conditions that an STL file must satisfy to be printable and, based on these, we design an as-exact-as-possible repairing algorithm. Findings: We have found that, in order to cope with all the possible triangle configurations, the algorithm must distinguish between triangles that bound solid parts and triangles that constitute zero-thickness sheets. Only the former set can be fixed without distortion. Originality: Previous methods that are guaranteed to fix all the possible configurations provide only approximate solutions with an unnecessary distortion. Conversely, our procedure is as exact as possible, meaning that no visible distortion is introduced unless it is strictly imposed by limitations of the printing device. Thanks to such an unprecedented flexibility and accuracy, this algorithm is expected to significantly simplify the modeling-printing process, in particular within the continuously emerging non-professional "maker" communities.




 Sketch-based modeling strives to bring the ease and immediacy of drawing to the 3D world. However, while drawings are easy for humans to create, they are very challenging for computers to interpret due to their sparsity and ambiguity. We propose a data-driven approach that tackles this challenge by learning to reconstruct 3D shapes from one or more drawings. At the core of our approach is a deep convolutional neural network (CNN) that predicts occupancy of a voxel grid from a line drawing. This CNN provides us with an initial 3D reconstruction as soon as the user completes a single drawing of the desired shape. We complement this single-view network with an updater CNN that refines an existing prediction given a new drawing of the shape created from a novel viewpoint. A key advantage of our approach is that we can apply the updater iteratively to fuse information from an arbitrary number of viewpoints, without requiring explicit stroke correspondences between the drawings. We train both CNNs by rendering synthetic contour drawings from hand-modeled shape collections as well as from procedurally-generated abstract shapes. Finally, we integrate our CNNs in a minimal modeling interface that allows users to seamlessly draw an object, rotate it to see its 3D reconstruction, and refine it by re-drawing from another vantage point using the 3D reconstruction as guidance. The main strengths of our approach are its robustness to freehand bitmap drawings, its ability to adapt to different object categories, and the continuum it offers between single-view and multi-view sketch-based modeling.
Sketch-based modeling strives to bring the ease and immediacy of drawing to the 3D world. However, while drawings are easy for humans to create, they are very challenging for computers to interpret due to their sparsity and ambiguity. We propose a data-driven approach that tackles this challenge by learning to reconstruct 3D shapes from one or more drawings. At the core of our approach is a deep convolutional neural network (CNN) that predicts occupancy of a voxel grid from a line drawing. This CNN provides us with an initial 3D reconstruction as soon as the user completes a single drawing of the desired shape. We complement this single-view network with an updater CNN that refines an existing prediction given a new drawing of the shape created from a novel viewpoint. A key advantage of our approach is that we can apply the updater iteratively to fuse information from an arbitrary number of viewpoints, without requiring explicit stroke correspondences between the drawings. We train both CNNs by rendering synthetic contour drawings from hand-modeled shape collections as well as from procedurally-generated abstract shapes. Finally, we integrate our CNNs in a minimal modeling interface that allows users to seamlessly draw an object, rotate it to see its 3D reconstruction, and refine it by re-drawing from another vantage point using the 3D reconstruction as guidance. The main strengths of our approach are its robustness to freehand bitmap drawings, its ability to adapt to different object categories, and the continuum it offers between single-view and multi-view sketch-based modeling.




 We study data-driven representations for three-dimensional triangle meshes, which are one of the prevalent objects used to represent 3D geometry. Recent works have developed models that exploit the intrinsic geometry of manifolds and graphs, namely the Graph Neural Networks (GNNs) and its spectral variants, which learn from the local metric tensor via the Laplacian operator. Despite offering excellent sample complexity and built-in invariances, intrinsic geometry alone is invariant to isometric deformations, making it unsuitable for many applications. To overcome this limitation, we propose several upgrades to GNNs to leverage extrinsic differential geometry properties of three-dimensional surfaces, increasing its modeling power. In particular, we propose to exploit the Dirac operator, whose spectrum detects principal curvature directions --- this is in stark contrast with the classical Laplace operator, which directly measures mean curvature. We coin the resulting models \emph{Surface Networks (SN)}. We prove that these models define shape representations that are stable to deformation and to discretization, and we demonstrate the efficiency and versatility of SNs on two challenging tasks: temporal prediction of mesh deformations under non-linear dynamics and generative models using a variational autoencoder framework with encoders/decoders given by SNs.
We study data-driven representations for three-dimensional triangle meshes, which are one of the prevalent objects used to represent 3D geometry. Recent works have developed models that exploit the intrinsic geometry of manifolds and graphs, namely the Graph Neural Networks (GNNs) and its spectral variants, which learn from the local metric tensor via the Laplacian operator. Despite offering excellent sample complexity and built-in invariances, intrinsic geometry alone is invariant to isometric deformations, making it unsuitable for many applications. To overcome this limitation, we propose several upgrades to GNNs to leverage extrinsic differential geometry properties of three-dimensional surfaces, increasing its modeling power. In particular, we propose to exploit the Dirac operator, whose spectrum detects principal curvature directions --- this is in stark contrast with the classical Laplace operator, which directly measures mean curvature. We coin the resulting models \emph{Surface Networks (SN)}. We prove that these models define shape representations that are stable to deformation and to discretization, and we demonstrate the efficiency and versatility of SNs on two challenging tasks: temporal prediction of mesh deformations under non-linear dynamics and generative models using a variational autoencoder framework with encoders/decoders given by SNs.



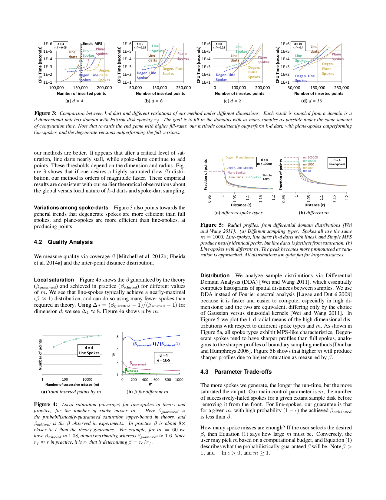
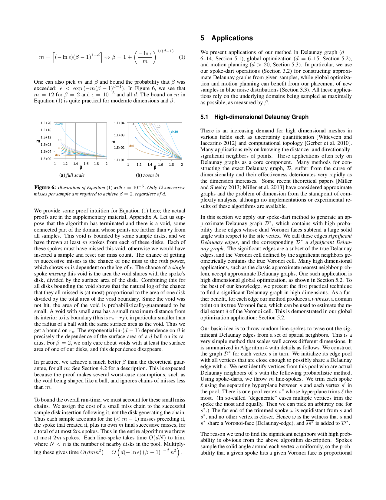 Blue noise sampling has proved useful for many graphics applications, but remains underexplored in high-dimensional spaces due to the difficulty of generating distributions and proving properties about them. We present a blue noise sampling method with good quality and performance across different dimensions. The method, spoke-dart sampling, shoots rays from prior samples and selects samples from these rays. It combines the advantages of two major high-dimensional sampling methods: the locality of advancing front with the dimensionality-reduction of hyperplanes, specifically line sampling. We prove that the output sampling is saturated with high probability, with bounds on distances between pairs of samples and between any domain point and its nearest sample. We demonstrate spoke-dart applications for approximate Delaunay graph construction, global optimization, and robotic motion planning. Both the blue-noise quality of the output distribution and the adaptability of the intermediate processes of our method are useful in these applications.
Blue noise sampling has proved useful for many graphics applications, but remains underexplored in high-dimensional spaces due to the difficulty of generating distributions and proving properties about them. We present a blue noise sampling method with good quality and performance across different dimensions. The method, spoke-dart sampling, shoots rays from prior samples and selects samples from these rays. It combines the advantages of two major high-dimensional sampling methods: the locality of advancing front with the dimensionality-reduction of hyperplanes, specifically line sampling. We prove that the output sampling is saturated with high probability, with bounds on distances between pairs of samples and between any domain point and its nearest sample. We demonstrate spoke-dart applications for approximate Delaunay graph construction, global optimization, and robotic motion planning. Both the blue-noise quality of the output distribution and the adaptability of the intermediate processes of our method are useful in these applications.

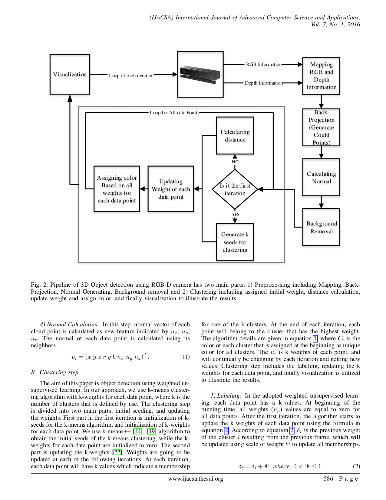


 This paper introduces a novel weighted unsupervised learning for object detection using an RGB-D camera. This technique is feasible for detecting the moving objects in the noisy environments that are captured by an RGB-D camera. The main contribution of this paper is a real-time algorithm for detecting each object using weighted clustering as a separate cluster. In a preprocessing step, the algorithm calculates the pose 3D position X, Y, Z and RGB color of each data point and then it calculates each data point's normal vector using the point's neighbor. After preprocessing, our algorithm calculates k-weights for each data point; each weight indicates membership. Resulting in clustered objects of the scene.
This paper introduces a novel weighted unsupervised learning for object detection using an RGB-D camera. This technique is feasible for detecting the moving objects in the noisy environments that are captured by an RGB-D camera. The main contribution of this paper is a real-time algorithm for detecting each object using weighted clustering as a separate cluster. In a preprocessing step, the algorithm calculates the pose 3D position X, Y, Z and RGB color of each data point and then it calculates each data point's normal vector using the point's neighbor. After preprocessing, our algorithm calculates k-weights for each data point; each weight indicates membership. Resulting in clustered objects of the scene.