-
Dense kernel matrices $\Theta \in \mathbb{R}^{N \times N}$ obtained from
point evaluations of a covariance function $G$ at locations $\{ x_{i} \}_{1
\leq i \leq N} \subset \mathbb{R}^{d}$ arise in statistics, machine learning,
and numerical analysis. For covariance functions that are Green's functions of
elliptic boundary value problems and homogeneously-distributed sampling points,
we show how to identify a subset $S \subset \{ 1 , \dots , N \}^2$, with $\# S
= O ( N \log (N) \log^{d} ( N /\epsilon ) )$, such that the zero fill-in
incomplete Cholesky factorisation of the sparse matrix $\Theta_{ij} 1_{( i, j )
\in S}$ is an $\epsilon$-approximation of $\Theta$. This factorisation can
provably be obtained in complexity $O ( N \log( N ) \log^{d}( N /\epsilon) )$
in space and $O ( N \log^{2}( N ) \log^{2d}( N /\epsilon) )$ in time, improving
upon the state of the art for general elliptic operators; we further present
numerical evidence that $d$ can be taken to be the intrinsic dimension of the
data set rather than that of the ambient space. The algorithm only needs to
know the spatial configuration of the $x_{i}$ and does not require an analytic
representation of $G$. Furthermore, this factorization straightforwardly
provides an approximate sparse PCA with optimal rate of convergence in the
operator norm. Hence, by using only subsampling and the incomplete Cholesky
factorization, we obtain, at nearly linear complexity, the compression,
inversion and approximate PCA of a large class of covariance matrices. By
inverting the order of the Cholesky factorization we also obtain a solver for
elliptic PDE with complexity $O ( N \log^{d}( N /\epsilon) )$ in space and $O (
N \log^{2d}( N /\epsilon) )$ in time, improving upon the state of the art for
general elliptic operators.
-
This paper shows effectiveness of X3SAT in proving P = NP. This is due to the
fact that it is easy to check unsatisfiability of a particular truth
assignment. A truth assignment leads to some reductions of clauses by means of
"exactly-1 disjunction". The reductions result in a conjunction of literals,
called the scope of the assignment. It is proved that this particular truth
assignment makes the formula unsatisfiable iff the scope_s is unsatisfiable for
some s, which is trivial to check. Then, each literal such that its scope is
unsatisfiable is removed from the formula. Therefore, the formula is
satisfiable iff the scope of every literal is satisfied.
-
The complexity of computing the Fourier transform is a longstanding open
problem. Very recently, Ailon (2013, 2014, 2015) showed in a collection of
papers that, roughly speaking, a speedup of the Fourier transform computation
implies numerical ill-condition. The papers also quantify this tradeoff. The
main method for proving these results is via a potential function called
quasi-entropy, reminiscent of Shannon entropy. The quasi-entropy method opens
new doors to understanding the computational complexity of the important
Fourier transformation. However, it suffers from various obvious limitations.
This paper, motivated by one such limitation, partly overcomes it, while at the
same time sheds llight on new interesting, and problems on the intersection of
computational complexity and group theory. The paper also explains why this
research direction, if fruitful, has a chance of solving much bigger questions
about the complexity of the Fourier transform.
-
We present new results on realtime alternating, private alternating, and
quantum alternating automaton models. Firstly, we show that the emptiness
problem for alternating one-counter automata on unary alphabets is undecidable.
Then, we present two equivalent definitions of realtime private alternating
finite automata (PAFAs). We show that the emptiness problem is undecidable for
PAFAs. Furthermore, PAFAs can recognize some nonregular unary languages,
including the unary squares language, which seems to be difficult even for some
classical counter automata with two-way input. Regarding quantum finite
automata (QFAs), we show that the emptiness problem is undecidable both for
universal QFAs on general alphabets, and for alternating QFAs with two
alternations on unary alphabets. On the other hand, the same problem is
decidable for nondeterministic QFAs on general alphabets. We also show that the
unary squares language is recognized by alternating QFAs with two alternations.
-
Many natural combinatorial problems can be expressed as constraint
satisfaction problems. This class of problems is known to be NP-complete in
general, but certain restrictions on the form of the constraints can ensure
tractability. The standard way to parameterize interesting subclasses of the
constraint satisfaction problem is via finite constraint languages. The main
problem is to classify those subclasses that are solvable in polynomial time
and those that are NP-complete. It was conjectured that if a constraint
language has a weak near unanimity polymorphism then the corresponding
constraint satisfaction problem is tractable, otherwise it is NP-complete.
In the paper we present an algorithm that solves Constraint Satisfaction
Problem in polynomial time for constraint languages having a weak near
unanimity polymorphism, which proves the remaining part of the conjecture.
-
We study the detection problem of finding planted solutions in random
instances of flat satisfiability problems, a generalization of boolean
satisfiability formulas. We describe the properties of random instances of flat
satisfiability, as well of the optimal rates of detection of the associated
hypothesis testing problem. We also study the performance of an algorithmically
efficient testing procedure. We introduce a modification of our model, the
light planting of solutions, and show that it is as hard as the problem of
learning parity with noise. This hints strongly at the difficulty of detecting
planted flat satisfiability for a wide class of tests.
-
Given a graph $F$, let $I(F)$ be the class of graphs containing $F$ as an
induced subgraph. Let $W[F]$ denote the minimum $k$ such that $I(F)$ is
definable in $k$-variable first-order logic. The recognition problem of $I(F)$,
known as Induced Subgraph Isomorphism (for the pattern graph $F$), is solvable
in time $O(n^{W[F]})$. Motivated by this fact, we are interested in determining
or estimating the value of $W[F]$. Using Olariu's characterization of paw-free
graphs, we show that $I(K_3+e)$ is definable by a first-order sentence of
quantifier depth 3, where $K_3+e$ denotes the paw graph. This provides an
example of a graph $F$ with $W[F]$ strictly less than the number of vertices in
$F$. On the other hand, we prove that $W[F]=4$ for all $F$ on 4 vertices except
the paw graph and its complement. If $F$ is a graph on $t$ vertices, we prove a
general lower bound $W[F]>(1/2-o(1))t$, where the function in the little-o
notation approaches 0 as $t$ inreases. This bound holds true even for a related
parameter $W^*[F]\le W[F]$, which is defined as the minimum $k$ such that
$I(F)$ is definable in the infinitary logic $L^k_{\infty\omega}$. We show that
$W^*[F]$ can be strictly less than $W[F]$. Specifically, $W^*[P_4]=3$ for $P_4$
being the path graph on 4 vertices.
Using the lower bound for $W[F]$, we also obtain a succintness result for
existential monadic second-order logic: A usage of just one monadic quantifier
sometimes reduces the first-order quantifier depth at a super-recursive rate.
-
We study rewritability of monadic disjunctive Datalog programs, (the
complements of) MMSNP sentences, and ontology-mediated queries (OMQs) based on
expressive description logics of the ALC family and on conjunctive queries. We
show that rewritability into FO and into monadic Datalog (MDLog) are decidable,
and that rewritability into Datalog is decidable when the original query
satisfies a certain condition related to equality. We establish
2NExpTime-completeness for all studied problems except rewritability into MDLog
for which there remains a gap between 2NExpTime and 3ExpTime. We also analyze
the shape of rewritings, which in the MMSNP case correspond to obstructions,
and give a new construction of canonical Datalog programs that is more
elementary than existing ones and also applies to formulas with free variables.
-
Blind delegation protocols allow a client to delegate a computation to a
server so that the server learns nothing about the input to the computation
apart from its size. For the specific case of quantum computation we know that
blind delegation protocols can achieve information-theoretic security. In this
paper we prove, provided certain complexity-theoretic conjectures are true,
that the power of information-theoretically secure blind delegation protocols
for quantum computation (ITS-BQC protocols) is in a number of ways constrained.
In the first part of our paper we provide some indication that ITS-BQC
protocols for delegating $\sf BQP$ computations in which the client and the
server interact only classically are unlikely to exist. We first show that
having such a protocol with $O(n^d)$ bits of classical communication implies
that $\mathsf{BQP} \subset \mathsf{MA/O(n^d)}$. We conjecture that this
containment is unlikely by providing an oracle relative to which $\mathsf{BQP}
\not\subset \mathsf{MA/O(n^d)}$. We then show that if an ITS-BQC protocol
exists with polynomial classical communication and which allows the client to
delegate quantum sampling problems, then there exist non-uniform circuits of
size $2^{n - \mathsf{\Omega}(n/log(n))}$, making polynomially-sized queries to
an $\sf NP^{NP}$ oracle, for computing the permanent of an $n \times n$ matrix.
The second part of our paper concerns ITS-BQC protocols in which the client and
the server engage in one round of quantum communication and then exchange
polynomially many classical messages. First, we provide a complexity-theoretic
upper bound on the types of functions that could be delegated in such a
protocol, namely $\mathsf{QCMA/qpoly \cap coQCMA/qpoly}$. Then, we show that
having such a protocol for delegating $\mathsf{NP}$-hard functions implies
$\mathsf{coNP^{NP^{NP}}} \subseteq \mathsf{NP^{NP^{PromiseQMA}}}$.
-
Population protocols have been introduced by Angluin et al. as a model in
which n passively mobile anonymous finite-state agents stably compute a
predicate on the multiset of their inputs via interactions by pairs. The model
has been extended by Guerraoui and Ruppert to yield the community protocol
models where agents have unique identifiers but may only store a finite number
of the identifiers they already heard about. The population protocol models can
only compute semi-linear predicates, whereas in the community protocol model
the whole community of agents provides collectively the power of a Turing
machine with a O(n log n) space. We consider variations on the above models and
we obtain a whole landscape that covers and extends already known results: By
considering the case of homonyms, that is to say the case when several agents
may share the same identifier, we provide a hierarchy that goes from the case
of no identifier (i.e. a single one for all, i.e. the population protocol
model) to the case of unique identifiers (i.e. community protocol model). We
obtain in particular that any Turing Machine on space O(logO(1) n) can be
simulated with at least O(logO(1) n) identifiers, a result filling a gap left
open in all previous studies. Our results also extend and revisit in particular
the hierarchy provided by Chatzigiannakis et al. on population protocols
carrying Turing Machines on limited space, solving the problem of the gap left
by this work between per-agent space o(log log n) (proved to be equivalent to
population protocols) and O(log n) (proved to be equivalent to Turing
machines).
-
String matching is the problem of deciding whether a given $n$-bit string
contains a given $k$-bit pattern. We study the complexity of this problem in
three settings.
Communication complexity. For small $k$, we provide near-optimal upper and
lower bounds on the communication complexity of string matching. For large $k$,
our bounds leave open an exponential gap; we exhibit some evidence for the
existence of a better protocol.
Circuit complexity. We present several upper and lower bounds on the size of
circuits with threshold and DeMorgan gates solving the string matching problem.
Similarly to the above, our bounds are near-optimal for small $k$.
Learning. We consider the problem of learning a hidden pattern of length at
most $k$ relative to the classifier that assigns 1 to every string that
contains the pattern. We prove optimal bounds on the VC dimension and sample
complexity of this problem.
-
We present an O(n^6 ) linear programming model for the traveling salesman
(TSP) and quadratic assignment (QAP) problems. The basic model is developed
within the framework of the TSP. It does not involve the city-to-city
variables-based, traditional TSP polytope referred to in the literature as "the
TSP polytope." We do not model explicit Hamiltonian cycles of the cities.
Instead, we use a time-dependent abstraction of TSP tours and develop a direct
extended formulation of the linear assignment problem (LAP) polytope. The model
is exact in the sense that it has integral extreme points which are in
one-to-one correspondence with TSP tours. It can be solved optimally using any
linear programming (LP) solver, hence offering a new (incidental) proof of the
equality of the computational complexity classes "P" and "NP." The extensions
of the model to the time-dependent traveling salesman problem (TDTSP) as well
as the quadratic assignment problem (QAP) are straightforward. The reasons for
the non-applicability of existing negative extended formulations results for
"the TSP polytope" to the model in this paper as well as our software
implementation and the computational experimentation we conducted are briefly
discussed.
-
We study the computational complexity of distance games, a class of
combinatorial games played on graphs. A move consists of colouring an
uncoloured vertex subject to it not being at certain distances determined by
two sets, D and S. D is the set of forbidden distances for colouring vertices
in different colors, while S is the set of forbidden distances for the same
colour. The last player to move wins. Well-known examples of distance games are
Node-Kayles, Snort, and Col, whose complexities were shown to be PSPACE-hard.
We show that many more distance games are also PSPACE-hard.
-
In this paper, we introduce a general framework for fine-grained reductions
of approximate counting problems to their decision versions. (Thus we use an
oracle that decides whether any witness exists to multiplicatively approximate
the number of witnesses with minimal overhead.) This mirrors a foundational
result of Sipser (STOC 1983) and Stockmeyer (SICOMP 1985) in the
polynomial-time setting, and a similar result of M\"uller (IWPEC 2006) in the
FPT setting. Using our framework, we obtain such reductions for some of the
most important problems in fine-grained complexity: the Orthogonal Vectors
problem, 3SUM, and the Negative-Weight Triangle problem (which is closely
related to All-Pairs Shortest Path).
We also provide a fine-grained reduction from approximate #SAT to SAT.
Suppose the Strong Exponential Time Hypothesis (SETH) is false, so that for
some $1<c<2$ and all $k$ there is an $O(c^n)$-time algorithm for k-SAT. Then we
prove that for all $k$, there is an $O((c+o(1))^n)$-time algorithm for
approximate #$k$-SAT. In particular, our result implies that the Exponential
Time Hypothesis (ETH) is equivalent to the seemingly-weaker statement that
there is no algorithm to approximate #3-SAT to within a factor of $1+\epsilon$
in time $2^{o(n)}/\epsilon^2$ (taking $\epsilon > 0$ as part of the input).
-
A colouring of a graph $G=(V,E)$ is a function $c: V\rightarrow\{1,2,\ldots
\}$ such that $c(u)\neq c(v)$ for every $uv\in E$. A $k$-regular list
assignment of $G$ is a function $L$ with domain $V$ such that for every $u\in
V$, $L(u)$ is a subset of $\{1, 2, \dots\}$ of size $k$. A colouring $c$ of $G$
respects a $k$-regular list assignment $L$ of $G$ if $c(u)\in L(u)$ for every
$u\in V$. A graph $G$ is $k$-choosable if for every $k$-regular list assignment
$L$ of $G$, there exists a colouring of $G$ that respects $L$. We may also ask
if for a given $k$-regular list assignment $L$ of a given graph $G$, there
exists a colouring of $G$ that respects $L$. This yields the $k$-Regular List
Colouring problem. For $k\in \{3,4\}$ we determine a family of classes ${\cal
G}$ of planar graphs, such that either $k$-Regular List Colouring is
NP-complete for instances $(G,L)$ with $G\in {\cal G}$, or every $G\in {\cal
G}$ is $k$-choosable. By using known examples of non-$3$-choosable and
non-$4$-choosable graphs, this enables us to classify the complexity of
$k$-Regular List Colouring restricted to planar graphs, planar bipartite
graphs, planar triangle-free graphs and to planar graphs with no $4$-cycles and
no $5$-cycles. We also classify the complexity of $k$-Regular List Colouring
and a number of related colouring problems for graphs with bounded maximum
degree.
-
We consider two basic algorithmic problems concerning tuples of
(skew-)symmetric matrices. The first problem asks to decide, given two tuples
of (skew-)symmetric matrices $(B_1, \dots, B_m)$ and $(C_1, \dots, C_m)$,
whether there exists an invertible matrix $A$ such that for every $i\in\{1,
\dots, m\}$, $A^tB_iA=C_i$. We show that this problem can be solved in
randomized polynomial time over finite fields of odd size, the real field, and
the complex field. The second problem asks to decide, given a tuple of square
matrices $(B_1, \dots, B_m)$, whether there exist invertible matrices $A$ and
$D$, such that for every $i\in\{1, \dots, m\}$, $AB_iD$ is (skew-)symmetric. We
show that this problem can be solved in deterministic polynomial time over
fields of characteristic not $2$. For both problems we exploit the structure of
the underlying $*$-algebras, and utilize results and methods from the module
isomorphism problem.
Applications of our results range from multivariate cryptography, group
isomorphism, to polynomial identity testing. Specifically, these results imply
efficient algorithms for the following problems. (1) Test isomorphism of
quadratic forms with one secret over a finite field of odd size. This problem
belongs to a family of problems that serves as the security basis of certain
authentication schemes proposed by Patarin (Eurocrypto 1996). (2) Test
isomorphism of $p$-groups of class 2 and exponent $p$ ($p$ odd) with order
$p^k$ in time polynomial in the group order, when the commutator subgroup is of
order $p^{O(\sqrt{k})}$. (3) Deterministically reveal two families of
singularity witnesses caused by the skew-symmetric structure, which represents
a natural next step for the polynomial identity testing problem following the
direction set up by the recent resolution of the non-commutative rank problem
(Garg et al., FOCS 2016; Ivanyos et al., ITCS 2017).
-
A tight lower bound for required I/O when computing an ordinary matrix-matrix
multiplication on a processor with two layers of memory is established. Prior
work obtained weaker lower bounds by reasoning about the number of segments
needed to perform $C:=AB$, for distinct matrices $A$, $B$, and $C$, where each
segment is a series of operations involving $M$ reads and writes to and from
fast memory, and $M$ is the size of fast memory. A lower bound on the number of
segments was then determined by obtaining an upper bound on the number of
elementary multiplications performed per segment. This paper follows the same
high level approach, but improves the lower bound by (1) transforming
algorithms for MMM so that they perform all computation via fused multiply-add
instructions (FMAs) and using this to reason about only the cost associated
with reading the matrices, and (2) decoupling the per-segment I/O cost from the
size of fast memory. For $n \times n$ matrices, the lower bound's leading-order
term is $2n^3/\sqrt{M}$. A theoretical algorithm whose leading terms attains
this is introduced. To what extent the state-of-the-art Goto's Algorithm
attains the lower bound is discussed.
-
The fixed parameter tractable (FPT) approach is a powerful tool in tackling
computationally hard problems. In this paper, we link FPT results to classic
artificial intelligence (AI) techniques to show how they complement each other.
Specifically, we consider the workflow satisfiability problem (WSP) which asks
whether there exists an assignment of authorised users to the steps in a
workflow specification, subject to certain constraints on the assignment. It
was shown by Cohen et al. (JAIR 2014) that WSP restricted to the class of
user-independent constraints (UI), covering many practical cases, admits FPT
algorithms, i.e. can be solved in time exponential only in the number of steps
$k$ and polynomial in the number of users $n$. Since usually $k << n$ in WSP,
such FPT algorithms are of great practical interest. We present a new
interpretation of the FPT nature of the WSP with UI constraints giving a
decomposition of the problem into two levels. Exploiting this two-level split,
we develop a new FPT algorithm that is by many orders of magnitude faster than
the previous state-of-the-art WSP algorithm and also has only polynomial-space
complexity. We also introduce new pseudo-Boolean (PB) and Constraint
Satisfaction (CSP) formulations of the WSP with UI constraints which
efficiently exploit this new decomposition of the problem and raise the novel
issue of how to use general-purpose solvers to tackle FPT problems in a fashion
that meets FPT efficiency expectations. In our computational study, we
investigate, for the first time, the phase transition (PT) properties of the
WSP, under a model for generation of random instances. We show how PT studies
can be extended, in a novel fashion, to support empirical evaluation of scaling
of FPT algorithms.
-
Approximate counting via correlation decay is the core algorithmic technique
used in the sharp delineation of the computational phase transition that arises
in the approximation of the partition function of anti-ferromagnetic two-spin
models.
Previous analyses of correlation-decay algorithms implicitly depended on the
occurrence of strong spatial mixing (SSM). This means that one uses worst-case
analysis of the recursive procedure that creates the sub-instances. We develop
a new analysis method that is more refined than the worst-case analysis. We
take the shape of instances in the computation tree into consideration and
amortise against certain "bad" instances that are created as the recursion
proceeds. This enables us to show correlation decay and to obtain an FPTAS even
when SSM fails.
We apply our technique to the problem of approximately counting independent
sets in hypergraphs with degree upper-bound Delta and with a lower bound k on
the arity of hyperedges. Liu and Lin gave an FPTAS for k>=2 and Delta<=5 (lack
of SSM was the obstacle preventing this algorithm from being generalised to
Delta=6). Our technique gives a tight result for Delta=6, showing that there is
an FPTAS for k>=3 and Delta<=6. The best previously-known approximation scheme
for Delta=6 is the Markov-chain simulation based FPRAS of Bordewich, Dyer and
Karpinski, which only works for k>=8.
Our technique also applies for larger values of k, giving an FPTAS for
k>=Delta. This bound is not substantially stronger than existing randomised
results in the literature. Nevertheless, it gives the first deterministic
approximation scheme in this regime. Moreover, unlike existing results, it
leads to an FPTAS for counting dominating sets in regular graphs with
sufficiently large degree.
We further demonstrate that approximately counting independent sets in
hypergraphs is NP-hard even within the uniqueness regime.
-
Mutual information I in infinite sequences (and in their finite prefixes) is
essential in theoretical analysis of many situations. Yet its right definition
has been elusive for a long time. I address it by generalizing Kolmogorov
Complexity theory from measures to SEMImeasures i.e, infimums of sets of
measures. Being concave rather than linear functionals, semimeasures are quite
delicate to handle. Yet, they adequately grasp various theoretical and
practical scenaria. A simple lower bound i$(\alpha:\beta) = \sup_{x\in N} (K(x)
- K(x|\alpha) - K(x|\beta)) $ for information turns out tight for Martin-Lof
random $ \alpha,\beta $. For all sequences I$(\alpha:\beta) $ is characterized
by the minimum of i$(\alpha':\beta') $ over random $ \alpha',\beta' $ with $
U(\alpha')=\alpha, U(\beta')=\beta $.
-
Arora, Barak, Brunnermeier, and Ge showed that taking computational
complexity into account, a dishonest seller could strategically place lemons in
financial derivatives to make them substantially less valuable to buyers. We
show that if the seller is required to construct derivatives of a certain form,
then this phenomenon disappears. In particular, we define and construct
pseudorandom derivative families, for which lemon placement only slightly
affects the values of the derivatives. Our constructions use expander graphs.
We study our derivatives in a more general setting than Arora et al. In
particular, we analyze arbitrary tranches of the common collateralized debt
obligations (CDOs) when the underlying assets can have significant
dependencies.
-
Young flattenings, introduced by Landsberg and Ottaviani, give determinantal
equations for secant varieties and their non-vanishing provides lower bounds
for border ranks of tensors and in particular polynomials. We study
monomial-optimal shapes for Young flattenings, which exhibit the limits of the
Young flattening method. In particular, they provide the best possible lower
bound for large classes of monomials including all monomials up to degree 6,
monomials in 3 variables, and any power of the product of variables. On the
other hand, for degree 7 and higher there are monomials for which no Young
flattening can give a lower bound that matches the conjecturally tight upper
bound of Landsberg and Teitler.
-
In this paper we present a deterministic polynomial time algorithm for
testing if a symbolic matrix in non-commuting variables over $\mathbb{Q}$ is
invertible or not. The analogous question for commuting variables is the
celebrated polynomial identity testing (PIT) for symbolic determinants. In
contrast to the commutative case, which has an efficient probabilistic
algorithm, the best previous algorithm for the non-commutative setting required
exponential time (whether or not randomization is allowed). The algorithm
efficiently solves the "word problem" for the free skew field, and the identity
testing problem for arithmetic formulae with division over non-commuting
variables, two problems which had only exponential-time algorithms prior to
this work.
The main contribution of this paper is a complexity analysis of an existing
algorithm due to Gurvits, who proved it was polynomial time for certain classes
of inputs. We prove it always runs in polynomial time. The main component of
our analysis is a simple (given the necessary known tools) lower bound on
central notion of capacity of operators (introduced by Gurvits). We extend the
algorithm to actually approximate capacity to any accuracy in polynomial time,
and use this analysis to give quantitative bounds on the continuity of capacity
(the latter is used in a subsequent paper on Brascamp-Lieb inequalities).
Symbolic matrices in non-commuting variables, and the related structural and
algorithmic questions, have a remarkable number of diverse origins and
motivations. They arise independently in (commutative) invariant theory and
representation theory, linear algebra, optimization, linear system theory,
quantum information theory, approximation of the permanent and naturally in
non-commutative algebra. We provide a detailed account of some of these sources
and their interconnections.
-
A $\textit{sigma partitioning}$ of a graph $G$ is a partition of the vertices
into sets $P_1, \ldots, P_k$ such that for every two adjacent vertices $u$ and
$v$ there is an index $i$ such that $u$ and $v$ have different numbers of
neighbors in $P_i$. The $\textit{ sigma number}$ of a graph $G$, denoted by
$\sigma(G)$, is the minimum number $k$ such that $ G $ has a sigma partitioning
$P_1, \ldots, P_k$. Also, a $\textit{ lucky labeling}$ of a graph $G$ is a
function $ \ell :V(G) \rightarrow \mathbb{N}$, such that for every two adjacent
vertices $ v $ and $ u$ of $ G $, $ \sum_{w \sim v}\ell(w)\neq \sum_{w \sim
u}\ell(w) $ ($ x \sim y $ means that $ x $ and $y$ are adjacent). The $\textit{
lucky number}$ of $ G $, denoted by $\eta(G)$, is the minimum number $k $ such
that $ G $ has a lucky labeling $ \ell :V(G) \rightarrow \mathbb{N}_k$. It was
conjectured in [Inform. Process. Lett., 112(4):109--112, 2012] that it is $
\mathbf{NP} $-complete to decide whether $ \eta(G)=2$ for a given 3-regular
graph $G$. In this work, we prove this conjecture. Among other results, we give
an upper bound of five for the sigma number of a uniformly random graph.
-
In the Planar 3-SAT problem, we are given a 3-SAT formula together with its
incidence graph, which is planar, and are asked whether this formula is
satisfiable. Since Lichtenstein's proof that this problem is NP-complete, it
has been used as a starting point for a large number of reductions. In the
course of this research, different restrictions on the incidence graph of the
formula have been devised, for which the problem also remains hard.
In this paper, we investigate the restriction in which we require that the
incidence graph can be augmented by the edges of a Hamiltonian cycle that first
passes through all variables and then through all clauses, in a way that the
resulting graph is still planar. We show that the problem of deciding
satisfiability of a 3-SAT formula remains NP-complete even if the incidence
graph is restricted in that way and the Hamiltonian cycle is given. This
complements previous results demanding cycles only through either the variables
or clauses.
The problem remains hard for monotone formulas, as well as for instances with
exactly three distinct variables per clause. In the course of this
investigation, we show that monotone instances of Planar 3-SAT with exactly
three distinct variables per clause are always satisfiable, thus settling the
question by Darmann, D\"ocker, and Dorn on the complexity of this problem
variant in a surprising way.

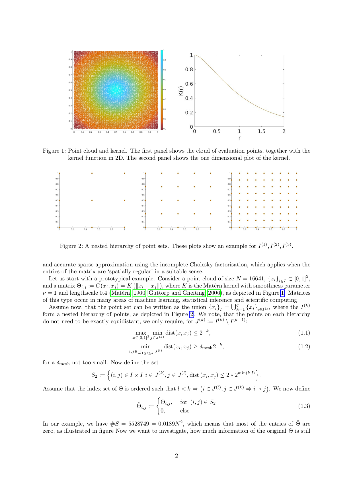
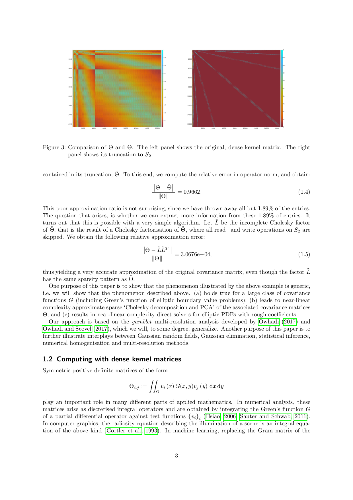
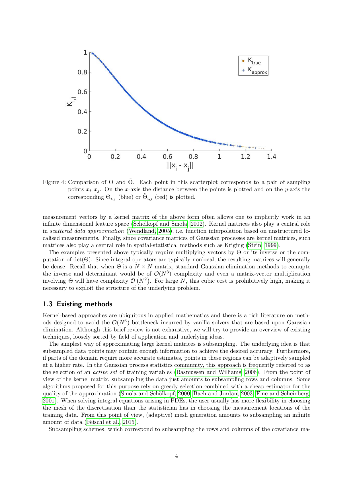

 Dense kernel matrices $\Theta \in \mathbb{R}^{N \times N}$ obtained from point evaluations of a covariance function $G$ at locations $\{ x_{i} \}_{1 \leq i \leq N} \subset \mathbb{R}^{d}$ arise in statistics, machine learning, and numerical analysis. For covariance functions that are Green's functions of elliptic boundary value problems and homogeneously-distributed sampling points, we show how to identify a subset $S \subset \{ 1 , \dots , N \}^2$, with $\# S = O ( N \log (N) \log^{d} ( N /\epsilon ) )$, such that the zero fill-in incomplete Cholesky factorisation of the sparse matrix $\Theta_{ij} 1_{( i, j ) \in S}$ is an $\epsilon$-approximation of $\Theta$. This factorisation can provably be obtained in complexity $O ( N \log( N ) \log^{d}( N /\epsilon) )$ in space and $O ( N \log^{2}( N ) \log^{2d}( N /\epsilon) )$ in time, improving upon the state of the art for general elliptic operators; we further present numerical evidence that $d$ can be taken to be the intrinsic dimension of the data set rather than that of the ambient space. The algorithm only needs to know the spatial configuration of the $x_{i}$ and does not require an analytic representation of $G$. Furthermore, this factorization straightforwardly provides an approximate sparse PCA with optimal rate of convergence in the operator norm. Hence, by using only subsampling and the incomplete Cholesky factorization, we obtain, at nearly linear complexity, the compression, inversion and approximate PCA of a large class of covariance matrices. By inverting the order of the Cholesky factorization we also obtain a solver for elliptic PDE with complexity $O ( N \log^{d}( N /\epsilon) )$ in space and $O ( N \log^{2d}( N /\epsilon) )$ in time, improving upon the state of the art for general elliptic operators.
Dense kernel matrices $\Theta \in \mathbb{R}^{N \times N}$ obtained from point evaluations of a covariance function $G$ at locations $\{ x_{i} \}_{1 \leq i \leq N} \subset \mathbb{R}^{d}$ arise in statistics, machine learning, and numerical analysis. For covariance functions that are Green's functions of elliptic boundary value problems and homogeneously-distributed sampling points, we show how to identify a subset $S \subset \{ 1 , \dots , N \}^2$, with $\# S = O ( N \log (N) \log^{d} ( N /\epsilon ) )$, such that the zero fill-in incomplete Cholesky factorisation of the sparse matrix $\Theta_{ij} 1_{( i, j ) \in S}$ is an $\epsilon$-approximation of $\Theta$. This factorisation can provably be obtained in complexity $O ( N \log( N ) \log^{d}( N /\epsilon) )$ in space and $O ( N \log^{2}( N ) \log^{2d}( N /\epsilon) )$ in time, improving upon the state of the art for general elliptic operators; we further present numerical evidence that $d$ can be taken to be the intrinsic dimension of the data set rather than that of the ambient space. The algorithm only needs to know the spatial configuration of the $x_{i}$ and does not require an analytic representation of $G$. Furthermore, this factorization straightforwardly provides an approximate sparse PCA with optimal rate of convergence in the operator norm. Hence, by using only subsampling and the incomplete Cholesky factorization, we obtain, at nearly linear complexity, the compression, inversion and approximate PCA of a large class of covariance matrices. By inverting the order of the Cholesky factorization we also obtain a solver for elliptic PDE with complexity $O ( N \log^{d}( N /\epsilon) )$ in space and $O ( N \log^{2d}( N /\epsilon) )$ in time, improving upon the state of the art for general elliptic operators.

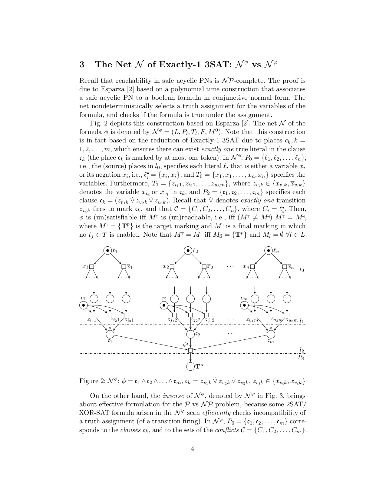
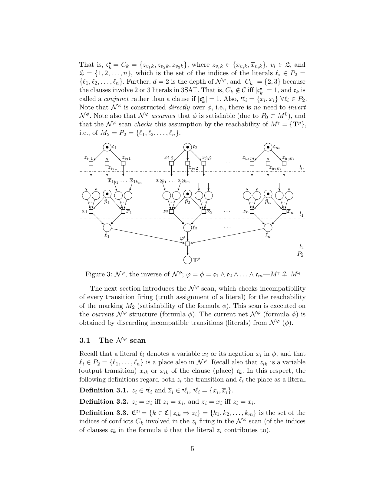
 This paper shows effectiveness of X3SAT in proving P = NP. This is due to the fact that it is easy to check unsatisfiability of a particular truth assignment. A truth assignment leads to some reductions of clauses by means of "exactly-1 disjunction". The reductions result in a conjunction of literals, called the scope of the assignment. It is proved that this particular truth assignment makes the formula unsatisfiable iff the scope_s is unsatisfiable for some s, which is trivial to check. Then, each literal such that its scope is unsatisfiable is removed from the formula. Therefore, the formula is satisfiable iff the scope of every literal is satisfied.
This paper shows effectiveness of X3SAT in proving P = NP. This is due to the fact that it is easy to check unsatisfiability of a particular truth assignment. A truth assignment leads to some reductions of clauses by means of "exactly-1 disjunction". The reductions result in a conjunction of literals, called the scope of the assignment. It is proved that this particular truth assignment makes the formula unsatisfiable iff the scope_s is unsatisfiable for some s, which is trivial to check. Then, each literal such that its scope is unsatisfiable is removed from the formula. Therefore, the formula is satisfiable iff the scope of every literal is satisfied.




 The complexity of computing the Fourier transform is a longstanding open problem. Very recently, Ailon (2013, 2014, 2015) showed in a collection of papers that, roughly speaking, a speedup of the Fourier transform computation implies numerical ill-condition. The papers also quantify this tradeoff. The main method for proving these results is via a potential function called quasi-entropy, reminiscent of Shannon entropy. The quasi-entropy method opens new doors to understanding the computational complexity of the important Fourier transformation. However, it suffers from various obvious limitations. This paper, motivated by one such limitation, partly overcomes it, while at the same time sheds llight on new interesting, and problems on the intersection of computational complexity and group theory. The paper also explains why this research direction, if fruitful, has a chance of solving much bigger questions about the complexity of the Fourier transform.
The complexity of computing the Fourier transform is a longstanding open problem. Very recently, Ailon (2013, 2014, 2015) showed in a collection of papers that, roughly speaking, a speedup of the Fourier transform computation implies numerical ill-condition. The papers also quantify this tradeoff. The main method for proving these results is via a potential function called quasi-entropy, reminiscent of Shannon entropy. The quasi-entropy method opens new doors to understanding the computational complexity of the important Fourier transformation. However, it suffers from various obvious limitations. This paper, motivated by one such limitation, partly overcomes it, while at the same time sheds llight on new interesting, and problems on the intersection of computational complexity and group theory. The paper also explains why this research direction, if fruitful, has a chance of solving much bigger questions about the complexity of the Fourier transform.




 We present new results on realtime alternating, private alternating, and quantum alternating automaton models. Firstly, we show that the emptiness problem for alternating one-counter automata on unary alphabets is undecidable. Then, we present two equivalent definitions of realtime private alternating finite automata (PAFAs). We show that the emptiness problem is undecidable for PAFAs. Furthermore, PAFAs can recognize some nonregular unary languages, including the unary squares language, which seems to be difficult even for some classical counter automata with two-way input. Regarding quantum finite automata (QFAs), we show that the emptiness problem is undecidable both for universal QFAs on general alphabets, and for alternating QFAs with two alternations on unary alphabets. On the other hand, the same problem is decidable for nondeterministic QFAs on general alphabets. We also show that the unary squares language is recognized by alternating QFAs with two alternations.
We present new results on realtime alternating, private alternating, and quantum alternating automaton models. Firstly, we show that the emptiness problem for alternating one-counter automata on unary alphabets is undecidable. Then, we present two equivalent definitions of realtime private alternating finite automata (PAFAs). We show that the emptiness problem is undecidable for PAFAs. Furthermore, PAFAs can recognize some nonregular unary languages, including the unary squares language, which seems to be difficult even for some classical counter automata with two-way input. Regarding quantum finite automata (QFAs), we show that the emptiness problem is undecidable both for universal QFAs on general alphabets, and for alternating QFAs with two alternations on unary alphabets. On the other hand, the same problem is decidable for nondeterministic QFAs on general alphabets. We also show that the unary squares language is recognized by alternating QFAs with two alternations.




 Many natural combinatorial problems can be expressed as constraint satisfaction problems. This class of problems is known to be NP-complete in general, but certain restrictions on the form of the constraints can ensure tractability. The standard way to parameterize interesting subclasses of the constraint satisfaction problem is via finite constraint languages. The main problem is to classify those subclasses that are solvable in polynomial time and those that are NP-complete. It was conjectured that if a constraint language has a weak near unanimity polymorphism then the corresponding constraint satisfaction problem is tractable, otherwise it is NP-complete. In the paper we present an algorithm that solves Constraint Satisfaction Problem in polynomial time for constraint languages having a weak near unanimity polymorphism, which proves the remaining part of the conjecture.
Many natural combinatorial problems can be expressed as constraint satisfaction problems. This class of problems is known to be NP-complete in general, but certain restrictions on the form of the constraints can ensure tractability. The standard way to parameterize interesting subclasses of the constraint satisfaction problem is via finite constraint languages. The main problem is to classify those subclasses that are solvable in polynomial time and those that are NP-complete. It was conjectured that if a constraint language has a weak near unanimity polymorphism then the corresponding constraint satisfaction problem is tractable, otherwise it is NP-complete. In the paper we present an algorithm that solves Constraint Satisfaction Problem in polynomial time for constraint languages having a weak near unanimity polymorphism, which proves the remaining part of the conjecture.




 We study the detection problem of finding planted solutions in random instances of flat satisfiability problems, a generalization of boolean satisfiability formulas. We describe the properties of random instances of flat satisfiability, as well of the optimal rates of detection of the associated hypothesis testing problem. We also study the performance of an algorithmically efficient testing procedure. We introduce a modification of our model, the light planting of solutions, and show that it is as hard as the problem of learning parity with noise. This hints strongly at the difficulty of detecting planted flat satisfiability for a wide class of tests.
We study the detection problem of finding planted solutions in random instances of flat satisfiability problems, a generalization of boolean satisfiability formulas. We describe the properties of random instances of flat satisfiability, as well of the optimal rates of detection of the associated hypothesis testing problem. We also study the performance of an algorithmically efficient testing procedure. We introduce a modification of our model, the light planting of solutions, and show that it is as hard as the problem of learning parity with noise. This hints strongly at the difficulty of detecting planted flat satisfiability for a wide class of tests.




 Given a graph $F$, let $I(F)$ be the class of graphs containing $F$ as an induced subgraph. Let $W[F]$ denote the minimum $k$ such that $I(F)$ is definable in $k$-variable first-order logic. The recognition problem of $I(F)$, known as Induced Subgraph Isomorphism (for the pattern graph $F$), is solvable in time $O(n^{W[F]})$. Motivated by this fact, we are interested in determining or estimating the value of $W[F]$. Using Olariu's characterization of paw-free graphs, we show that $I(K_3+e)$ is definable by a first-order sentence of quantifier depth 3, where $K_3+e$ denotes the paw graph. This provides an example of a graph $F$ with $W[F]$ strictly less than the number of vertices in $F$. On the other hand, we prove that $W[F]=4$ for all $F$ on 4 vertices except the paw graph and its complement. If $F$ is a graph on $t$ vertices, we prove a general lower bound $W[F]>(1/2-o(1))t$, where the function in the little-o notation approaches 0 as $t$ inreases. This bound holds true even for a related parameter $W^*[F]\le W[F]$, which is defined as the minimum $k$ such that $I(F)$ is definable in the infinitary logic $L^k_{\infty\omega}$. We show that $W^*[F]$ can be strictly less than $W[F]$. Specifically, $W^*[P_4]=3$ for $P_4$ being the path graph on 4 vertices. Using the lower bound for $W[F]$, we also obtain a succintness result for existential monadic second-order logic: A usage of just one monadic quantifier sometimes reduces the first-order quantifier depth at a super-recursive rate.
Given a graph $F$, let $I(F)$ be the class of graphs containing $F$ as an induced subgraph. Let $W[F]$ denote the minimum $k$ such that $I(F)$ is definable in $k$-variable first-order logic. The recognition problem of $I(F)$, known as Induced Subgraph Isomorphism (for the pattern graph $F$), is solvable in time $O(n^{W[F]})$. Motivated by this fact, we are interested in determining or estimating the value of $W[F]$. Using Olariu's characterization of paw-free graphs, we show that $I(K_3+e)$ is definable by a first-order sentence of quantifier depth 3, where $K_3+e$ denotes the paw graph. This provides an example of a graph $F$ with $W[F]$ strictly less than the number of vertices in $F$. On the other hand, we prove that $W[F]=4$ for all $F$ on 4 vertices except the paw graph and its complement. If $F$ is a graph on $t$ vertices, we prove a general lower bound $W[F]>(1/2-o(1))t$, where the function in the little-o notation approaches 0 as $t$ inreases. This bound holds true even for a related parameter $W^*[F]\le W[F]$, which is defined as the minimum $k$ such that $I(F)$ is definable in the infinitary logic $L^k_{\infty\omega}$. We show that $W^*[F]$ can be strictly less than $W[F]$. Specifically, $W^*[P_4]=3$ for $P_4$ being the path graph on 4 vertices. Using the lower bound for $W[F]$, we also obtain a succintness result for existential monadic second-order logic: A usage of just one monadic quantifier sometimes reduces the first-order quantifier depth at a super-recursive rate.




 We study rewritability of monadic disjunctive Datalog programs, (the complements of) MMSNP sentences, and ontology-mediated queries (OMQs) based on expressive description logics of the ALC family and on conjunctive queries. We show that rewritability into FO and into monadic Datalog (MDLog) are decidable, and that rewritability into Datalog is decidable when the original query satisfies a certain condition related to equality. We establish 2NExpTime-completeness for all studied problems except rewritability into MDLog for which there remains a gap between 2NExpTime and 3ExpTime. We also analyze the shape of rewritings, which in the MMSNP case correspond to obstructions, and give a new construction of canonical Datalog programs that is more elementary than existing ones and also applies to formulas with free variables.
We study rewritability of monadic disjunctive Datalog programs, (the complements of) MMSNP sentences, and ontology-mediated queries (OMQs) based on expressive description logics of the ALC family and on conjunctive queries. We show that rewritability into FO and into monadic Datalog (MDLog) are decidable, and that rewritability into Datalog is decidable when the original query satisfies a certain condition related to equality. We establish 2NExpTime-completeness for all studied problems except rewritability into MDLog for which there remains a gap between 2NExpTime and 3ExpTime. We also analyze the shape of rewritings, which in the MMSNP case correspond to obstructions, and give a new construction of canonical Datalog programs that is more elementary than existing ones and also applies to formulas with free variables.




 Blind delegation protocols allow a client to delegate a computation to a server so that the server learns nothing about the input to the computation apart from its size. For the specific case of quantum computation we know that blind delegation protocols can achieve information-theoretic security. In this paper we prove, provided certain complexity-theoretic conjectures are true, that the power of information-theoretically secure blind delegation protocols for quantum computation (ITS-BQC protocols) is in a number of ways constrained. In the first part of our paper we provide some indication that ITS-BQC protocols for delegating $\sf BQP$ computations in which the client and the server interact only classically are unlikely to exist. We first show that having such a protocol with $O(n^d)$ bits of classical communication implies that $\mathsf{BQP} \subset \mathsf{MA/O(n^d)}$. We conjecture that this containment is unlikely by providing an oracle relative to which $\mathsf{BQP} \not\subset \mathsf{MA/O(n^d)}$. We then show that if an ITS-BQC protocol exists with polynomial classical communication and which allows the client to delegate quantum sampling problems, then there exist non-uniform circuits of size $2^{n - \mathsf{\Omega}(n/log(n))}$, making polynomially-sized queries to an $\sf NP^{NP}$ oracle, for computing the permanent of an $n \times n$ matrix. The second part of our paper concerns ITS-BQC protocols in which the client and the server engage in one round of quantum communication and then exchange polynomially many classical messages. First, we provide a complexity-theoretic upper bound on the types of functions that could be delegated in such a protocol, namely $\mathsf{QCMA/qpoly \cap coQCMA/qpoly}$. Then, we show that having such a protocol for delegating $\mathsf{NP}$-hard functions implies $\mathsf{coNP^{NP^{NP}}} \subseteq \mathsf{NP^{NP^{PromiseQMA}}}$.
Blind delegation protocols allow a client to delegate a computation to a server so that the server learns nothing about the input to the computation apart from its size. For the specific case of quantum computation we know that blind delegation protocols can achieve information-theoretic security. In this paper we prove, provided certain complexity-theoretic conjectures are true, that the power of information-theoretically secure blind delegation protocols for quantum computation (ITS-BQC protocols) is in a number of ways constrained. In the first part of our paper we provide some indication that ITS-BQC protocols for delegating $\sf BQP$ computations in which the client and the server interact only classically are unlikely to exist. We first show that having such a protocol with $O(n^d)$ bits of classical communication implies that $\mathsf{BQP} \subset \mathsf{MA/O(n^d)}$. We conjecture that this containment is unlikely by providing an oracle relative to which $\mathsf{BQP} \not\subset \mathsf{MA/O(n^d)}$. We then show that if an ITS-BQC protocol exists with polynomial classical communication and which allows the client to delegate quantum sampling problems, then there exist non-uniform circuits of size $2^{n - \mathsf{\Omega}(n/log(n))}$, making polynomially-sized queries to an $\sf NP^{NP}$ oracle, for computing the permanent of an $n \times n$ matrix. The second part of our paper concerns ITS-BQC protocols in which the client and the server engage in one round of quantum communication and then exchange polynomially many classical messages. First, we provide a complexity-theoretic upper bound on the types of functions that could be delegated in such a protocol, namely $\mathsf{QCMA/qpoly \cap coQCMA/qpoly}$. Then, we show that having such a protocol for delegating $\mathsf{NP}$-hard functions implies $\mathsf{coNP^{NP^{NP}}} \subseteq \mathsf{NP^{NP^{PromiseQMA}}}$.




 Population protocols have been introduced by Angluin et al. as a model in which n passively mobile anonymous finite-state agents stably compute a predicate on the multiset of their inputs via interactions by pairs. The model has been extended by Guerraoui and Ruppert to yield the community protocol models where agents have unique identifiers but may only store a finite number of the identifiers they already heard about. The population protocol models can only compute semi-linear predicates, whereas in the community protocol model the whole community of agents provides collectively the power of a Turing machine with a O(n log n) space. We consider variations on the above models and we obtain a whole landscape that covers and extends already known results: By considering the case of homonyms, that is to say the case when several agents may share the same identifier, we provide a hierarchy that goes from the case of no identifier (i.e. a single one for all, i.e. the population protocol model) to the case of unique identifiers (i.e. community protocol model). We obtain in particular that any Turing Machine on space O(logO(1) n) can be simulated with at least O(logO(1) n) identifiers, a result filling a gap left open in all previous studies. Our results also extend and revisit in particular the hierarchy provided by Chatzigiannakis et al. on population protocols carrying Turing Machines on limited space, solving the problem of the gap left by this work between per-agent space o(log log n) (proved to be equivalent to population protocols) and O(log n) (proved to be equivalent to Turing machines).
Population protocols have been introduced by Angluin et al. as a model in which n passively mobile anonymous finite-state agents stably compute a predicate on the multiset of their inputs via interactions by pairs. The model has been extended by Guerraoui and Ruppert to yield the community protocol models where agents have unique identifiers but may only store a finite number of the identifiers they already heard about. The population protocol models can only compute semi-linear predicates, whereas in the community protocol model the whole community of agents provides collectively the power of a Turing machine with a O(n log n) space. We consider variations on the above models and we obtain a whole landscape that covers and extends already known results: By considering the case of homonyms, that is to say the case when several agents may share the same identifier, we provide a hierarchy that goes from the case of no identifier (i.e. a single one for all, i.e. the population protocol model) to the case of unique identifiers (i.e. community protocol model). We obtain in particular that any Turing Machine on space O(logO(1) n) can be simulated with at least O(logO(1) n) identifiers, a result filling a gap left open in all previous studies. Our results also extend and revisit in particular the hierarchy provided by Chatzigiannakis et al. on population protocols carrying Turing Machines on limited space, solving the problem of the gap left by this work between per-agent space o(log log n) (proved to be equivalent to population protocols) and O(log n) (proved to be equivalent to Turing machines).




 We present an O(n^6 ) linear programming model for the traveling salesman (TSP) and quadratic assignment (QAP) problems. The basic model is developed within the framework of the TSP. It does not involve the city-to-city variables-based, traditional TSP polytope referred to in the literature as "the TSP polytope." We do not model explicit Hamiltonian cycles of the cities. Instead, we use a time-dependent abstraction of TSP tours and develop a direct extended formulation of the linear assignment problem (LAP) polytope. The model is exact in the sense that it has integral extreme points which are in one-to-one correspondence with TSP tours. It can be solved optimally using any linear programming (LP) solver, hence offering a new (incidental) proof of the equality of the computational complexity classes "P" and "NP." The extensions of the model to the time-dependent traveling salesman problem (TDTSP) as well as the quadratic assignment problem (QAP) are straightforward. The reasons for the non-applicability of existing negative extended formulations results for "the TSP polytope" to the model in this paper as well as our software implementation and the computational experimentation we conducted are briefly discussed.
We present an O(n^6 ) linear programming model for the traveling salesman (TSP) and quadratic assignment (QAP) problems. The basic model is developed within the framework of the TSP. It does not involve the city-to-city variables-based, traditional TSP polytope referred to in the literature as "the TSP polytope." We do not model explicit Hamiltonian cycles of the cities. Instead, we use a time-dependent abstraction of TSP tours and develop a direct extended formulation of the linear assignment problem (LAP) polytope. The model is exact in the sense that it has integral extreme points which are in one-to-one correspondence with TSP tours. It can be solved optimally using any linear programming (LP) solver, hence offering a new (incidental) proof of the equality of the computational complexity classes "P" and "NP." The extensions of the model to the time-dependent traveling salesman problem (TDTSP) as well as the quadratic assignment problem (QAP) are straightforward. The reasons for the non-applicability of existing negative extended formulations results for "the TSP polytope" to the model in this paper as well as our software implementation and the computational experimentation we conducted are briefly discussed.




 We study the computational complexity of distance games, a class of combinatorial games played on graphs. A move consists of colouring an uncoloured vertex subject to it not being at certain distances determined by two sets, D and S. D is the set of forbidden distances for colouring vertices in different colors, while S is the set of forbidden distances for the same colour. The last player to move wins. Well-known examples of distance games are Node-Kayles, Snort, and Col, whose complexities were shown to be PSPACE-hard. We show that many more distance games are also PSPACE-hard.
We study the computational complexity of distance games, a class of combinatorial games played on graphs. A move consists of colouring an uncoloured vertex subject to it not being at certain distances determined by two sets, D and S. D is the set of forbidden distances for colouring vertices in different colors, while S is the set of forbidden distances for the same colour. The last player to move wins. Well-known examples of distance games are Node-Kayles, Snort, and Col, whose complexities were shown to be PSPACE-hard. We show that many more distance games are also PSPACE-hard.




 In this paper, we introduce a general framework for fine-grained reductions of approximate counting problems to their decision versions. (Thus we use an oracle that decides whether any witness exists to multiplicatively approximate the number of witnesses with minimal overhead.) This mirrors a foundational result of Sipser (STOC 1983) and Stockmeyer (SICOMP 1985) in the polynomial-time setting, and a similar result of M\"uller (IWPEC 2006) in the FPT setting. Using our framework, we obtain such reductions for some of the most important problems in fine-grained complexity: the Orthogonal Vectors problem, 3SUM, and the Negative-Weight Triangle problem (which is closely related to All-Pairs Shortest Path). We also provide a fine-grained reduction from approximate #SAT to SAT. Suppose the Strong Exponential Time Hypothesis (SETH) is false, so that for some $1<c<2$ and all $k$ there is an $O(c^n)$-time algorithm for k-SAT. Then we prove that for all $k$, there is an $O((c+o(1))^n)$-time algorithm for approximate #$k$-SAT. In particular, our result implies that the Exponential Time Hypothesis (ETH) is equivalent to the seemingly-weaker statement that there is no algorithm to approximate #3-SAT to within a factor of $1+\epsilon$ in time $2^{o(n)}/\epsilon^2$ (taking $\epsilon > 0$ as part of the input).
In this paper, we introduce a general framework for fine-grained reductions of approximate counting problems to their decision versions. (Thus we use an oracle that decides whether any witness exists to multiplicatively approximate the number of witnesses with minimal overhead.) This mirrors a foundational result of Sipser (STOC 1983) and Stockmeyer (SICOMP 1985) in the polynomial-time setting, and a similar result of M\"uller (IWPEC 2006) in the FPT setting. Using our framework, we obtain such reductions for some of the most important problems in fine-grained complexity: the Orthogonal Vectors problem, 3SUM, and the Negative-Weight Triangle problem (which is closely related to All-Pairs Shortest Path). We also provide a fine-grained reduction from approximate #SAT to SAT. Suppose the Strong Exponential Time Hypothesis (SETH) is false, so that for some $1<c<2$ and all $k$ there is an $O(c^n)$-time algorithm for k-SAT. Then we prove that for all $k$, there is an $O((c+o(1))^n)$-time algorithm for approximate #$k$-SAT. In particular, our result implies that the Exponential Time Hypothesis (ETH) is equivalent to the seemingly-weaker statement that there is no algorithm to approximate #3-SAT to within a factor of $1+\epsilon$ in time $2^{o(n)}/\epsilon^2$ (taking $\epsilon > 0$ as part of the input).




 A colouring of a graph $G=(V,E)$ is a function $c: V\rightarrow\{1,2,\ldots \}$ such that $c(u)\neq c(v)$ for every $uv\in E$. A $k$-regular list assignment of $G$ is a function $L$ with domain $V$ such that for every $u\in V$, $L(u)$ is a subset of $\{1, 2, \dots\}$ of size $k$. A colouring $c$ of $G$ respects a $k$-regular list assignment $L$ of $G$ if $c(u)\in L(u)$ for every $u\in V$. A graph $G$ is $k$-choosable if for every $k$-regular list assignment $L$ of $G$, there exists a colouring of $G$ that respects $L$. We may also ask if for a given $k$-regular list assignment $L$ of a given graph $G$, there exists a colouring of $G$ that respects $L$. This yields the $k$-Regular List Colouring problem. For $k\in \{3,4\}$ we determine a family of classes ${\cal G}$ of planar graphs, such that either $k$-Regular List Colouring is NP-complete for instances $(G,L)$ with $G\in {\cal G}$, or every $G\in {\cal G}$ is $k$-choosable. By using known examples of non-$3$-choosable and non-$4$-choosable graphs, this enables us to classify the complexity of $k$-Regular List Colouring restricted to planar graphs, planar bipartite graphs, planar triangle-free graphs and to planar graphs with no $4$-cycles and no $5$-cycles. We also classify the complexity of $k$-Regular List Colouring and a number of related colouring problems for graphs with bounded maximum degree.
A colouring of a graph $G=(V,E)$ is a function $c: V\rightarrow\{1,2,\ldots \}$ such that $c(u)\neq c(v)$ for every $uv\in E$. A $k$-regular list assignment of $G$ is a function $L$ with domain $V$ such that for every $u\in V$, $L(u)$ is a subset of $\{1, 2, \dots\}$ of size $k$. A colouring $c$ of $G$ respects a $k$-regular list assignment $L$ of $G$ if $c(u)\in L(u)$ for every $u\in V$. A graph $G$ is $k$-choosable if for every $k$-regular list assignment $L$ of $G$, there exists a colouring of $G$ that respects $L$. We may also ask if for a given $k$-regular list assignment $L$ of a given graph $G$, there exists a colouring of $G$ that respects $L$. This yields the $k$-Regular List Colouring problem. For $k\in \{3,4\}$ we determine a family of classes ${\cal G}$ of planar graphs, such that either $k$-Regular List Colouring is NP-complete for instances $(G,L)$ with $G\in {\cal G}$, or every $G\in {\cal G}$ is $k$-choosable. By using known examples of non-$3$-choosable and non-$4$-choosable graphs, this enables us to classify the complexity of $k$-Regular List Colouring restricted to planar graphs, planar bipartite graphs, planar triangle-free graphs and to planar graphs with no $4$-cycles and no $5$-cycles. We also classify the complexity of $k$-Regular List Colouring and a number of related colouring problems for graphs with bounded maximum degree.




 We consider two basic algorithmic problems concerning tuples of (skew-)symmetric matrices. The first problem asks to decide, given two tuples of (skew-)symmetric matrices $(B_1, \dots, B_m)$ and $(C_1, \dots, C_m)$, whether there exists an invertible matrix $A$ such that for every $i\in\{1, \dots, m\}$, $A^tB_iA=C_i$. We show that this problem can be solved in randomized polynomial time over finite fields of odd size, the real field, and the complex field. The second problem asks to decide, given a tuple of square matrices $(B_1, \dots, B_m)$, whether there exist invertible matrices $A$ and $D$, such that for every $i\in\{1, \dots, m\}$, $AB_iD$ is (skew-)symmetric. We show that this problem can be solved in deterministic polynomial time over fields of characteristic not $2$. For both problems we exploit the structure of the underlying $*$-algebras, and utilize results and methods from the module isomorphism problem. Applications of our results range from multivariate cryptography, group isomorphism, to polynomial identity testing. Specifically, these results imply efficient algorithms for the following problems. (1) Test isomorphism of quadratic forms with one secret over a finite field of odd size. This problem belongs to a family of problems that serves as the security basis of certain authentication schemes proposed by Patarin (Eurocrypto 1996). (2) Test isomorphism of $p$-groups of class 2 and exponent $p$ ($p$ odd) with order $p^k$ in time polynomial in the group order, when the commutator subgroup is of order $p^{O(\sqrt{k})}$. (3) Deterministically reveal two families of singularity witnesses caused by the skew-symmetric structure, which represents a natural next step for the polynomial identity testing problem following the direction set up by the recent resolution of the non-commutative rank problem (Garg et al., FOCS 2016; Ivanyos et al., ITCS 2017).
We consider two basic algorithmic problems concerning tuples of (skew-)symmetric matrices. The first problem asks to decide, given two tuples of (skew-)symmetric matrices $(B_1, \dots, B_m)$ and $(C_1, \dots, C_m)$, whether there exists an invertible matrix $A$ such that for every $i\in\{1, \dots, m\}$, $A^tB_iA=C_i$. We show that this problem can be solved in randomized polynomial time over finite fields of odd size, the real field, and the complex field. The second problem asks to decide, given a tuple of square matrices $(B_1, \dots, B_m)$, whether there exist invertible matrices $A$ and $D$, such that for every $i\in\{1, \dots, m\}$, $AB_iD$ is (skew-)symmetric. We show that this problem can be solved in deterministic polynomial time over fields of characteristic not $2$. For both problems we exploit the structure of the underlying $*$-algebras, and utilize results and methods from the module isomorphism problem. Applications of our results range from multivariate cryptography, group isomorphism, to polynomial identity testing. Specifically, these results imply efficient algorithms for the following problems. (1) Test isomorphism of quadratic forms with one secret over a finite field of odd size. This problem belongs to a family of problems that serves as the security basis of certain authentication schemes proposed by Patarin (Eurocrypto 1996). (2) Test isomorphism of $p$-groups of class 2 and exponent $p$ ($p$ odd) with order $p^k$ in time polynomial in the group order, when the commutator subgroup is of order $p^{O(\sqrt{k})}$. (3) Deterministically reveal two families of singularity witnesses caused by the skew-symmetric structure, which represents a natural next step for the polynomial identity testing problem following the direction set up by the recent resolution of the non-commutative rank problem (Garg et al., FOCS 2016; Ivanyos et al., ITCS 2017).




 The fixed parameter tractable (FPT) approach is a powerful tool in tackling computationally hard problems. In this paper, we link FPT results to classic artificial intelligence (AI) techniques to show how they complement each other. Specifically, we consider the workflow satisfiability problem (WSP) which asks whether there exists an assignment of authorised users to the steps in a workflow specification, subject to certain constraints on the assignment. It was shown by Cohen et al. (JAIR 2014) that WSP restricted to the class of user-independent constraints (UI), covering many practical cases, admits FPT algorithms, i.e. can be solved in time exponential only in the number of steps $k$ and polynomial in the number of users $n$. Since usually $k << n$ in WSP, such FPT algorithms are of great practical interest. We present a new interpretation of the FPT nature of the WSP with UI constraints giving a decomposition of the problem into two levels. Exploiting this two-level split, we develop a new FPT algorithm that is by many orders of magnitude faster than the previous state-of-the-art WSP algorithm and also has only polynomial-space complexity. We also introduce new pseudo-Boolean (PB) and Constraint Satisfaction (CSP) formulations of the WSP with UI constraints which efficiently exploit this new decomposition of the problem and raise the novel issue of how to use general-purpose solvers to tackle FPT problems in a fashion that meets FPT efficiency expectations. In our computational study, we investigate, for the first time, the phase transition (PT) properties of the WSP, under a model for generation of random instances. We show how PT studies can be extended, in a novel fashion, to support empirical evaluation of scaling of FPT algorithms.
The fixed parameter tractable (FPT) approach is a powerful tool in tackling computationally hard problems. In this paper, we link FPT results to classic artificial intelligence (AI) techniques to show how they complement each other. Specifically, we consider the workflow satisfiability problem (WSP) which asks whether there exists an assignment of authorised users to the steps in a workflow specification, subject to certain constraints on the assignment. It was shown by Cohen et al. (JAIR 2014) that WSP restricted to the class of user-independent constraints (UI), covering many practical cases, admits FPT algorithms, i.e. can be solved in time exponential only in the number of steps $k$ and polynomial in the number of users $n$. Since usually $k << n$ in WSP, such FPT algorithms are of great practical interest. We present a new interpretation of the FPT nature of the WSP with UI constraints giving a decomposition of the problem into two levels. Exploiting this two-level split, we develop a new FPT algorithm that is by many orders of magnitude faster than the previous state-of-the-art WSP algorithm and also has only polynomial-space complexity. We also introduce new pseudo-Boolean (PB) and Constraint Satisfaction (CSP) formulations of the WSP with UI constraints which efficiently exploit this new decomposition of the problem and raise the novel issue of how to use general-purpose solvers to tackle FPT problems in a fashion that meets FPT efficiency expectations. In our computational study, we investigate, for the first time, the phase transition (PT) properties of the WSP, under a model for generation of random instances. We show how PT studies can be extended, in a novel fashion, to support empirical evaluation of scaling of FPT algorithms.




 Approximate counting via correlation decay is the core algorithmic technique used in the sharp delineation of the computational phase transition that arises in the approximation of the partition function of anti-ferromagnetic two-spin models. Previous analyses of correlation-decay algorithms implicitly depended on the occurrence of strong spatial mixing (SSM). This means that one uses worst-case analysis of the recursive procedure that creates the sub-instances. We develop a new analysis method that is more refined than the worst-case analysis. We take the shape of instances in the computation tree into consideration and amortise against certain "bad" instances that are created as the recursion proceeds. This enables us to show correlation decay and to obtain an FPTAS even when SSM fails. We apply our technique to the problem of approximately counting independent sets in hypergraphs with degree upper-bound Delta and with a lower bound k on the arity of hyperedges. Liu and Lin gave an FPTAS for k>=2 and Delta<=5 (lack of SSM was the obstacle preventing this algorithm from being generalised to Delta=6). Our technique gives a tight result for Delta=6, showing that there is an FPTAS for k>=3 and Delta<=6. The best previously-known approximation scheme for Delta=6 is the Markov-chain simulation based FPRAS of Bordewich, Dyer and Karpinski, which only works for k>=8. Our technique also applies for larger values of k, giving an FPTAS for k>=Delta. This bound is not substantially stronger than existing randomised results in the literature. Nevertheless, it gives the first deterministic approximation scheme in this regime. Moreover, unlike existing results, it leads to an FPTAS for counting dominating sets in regular graphs with sufficiently large degree. We further demonstrate that approximately counting independent sets in hypergraphs is NP-hard even within the uniqueness regime.
Approximate counting via correlation decay is the core algorithmic technique used in the sharp delineation of the computational phase transition that arises in the approximation of the partition function of anti-ferromagnetic two-spin models. Previous analyses of correlation-decay algorithms implicitly depended on the occurrence of strong spatial mixing (SSM). This means that one uses worst-case analysis of the recursive procedure that creates the sub-instances. We develop a new analysis method that is more refined than the worst-case analysis. We take the shape of instances in the computation tree into consideration and amortise against certain "bad" instances that are created as the recursion proceeds. This enables us to show correlation decay and to obtain an FPTAS even when SSM fails. We apply our technique to the problem of approximately counting independent sets in hypergraphs with degree upper-bound Delta and with a lower bound k on the arity of hyperedges. Liu and Lin gave an FPTAS for k>=2 and Delta<=5 (lack of SSM was the obstacle preventing this algorithm from being generalised to Delta=6). Our technique gives a tight result for Delta=6, showing that there is an FPTAS for k>=3 and Delta<=6. The best previously-known approximation scheme for Delta=6 is the Markov-chain simulation based FPRAS of Bordewich, Dyer and Karpinski, which only works for k>=8. Our technique also applies for larger values of k, giving an FPTAS for k>=Delta. This bound is not substantially stronger than existing randomised results in the literature. Nevertheless, it gives the first deterministic approximation scheme in this regime. Moreover, unlike existing results, it leads to an FPTAS for counting dominating sets in regular graphs with sufficiently large degree. We further demonstrate that approximately counting independent sets in hypergraphs is NP-hard even within the uniqueness regime.




 Arora, Barak, Brunnermeier, and Ge showed that taking computational complexity into account, a dishonest seller could strategically place lemons in financial derivatives to make them substantially less valuable to buyers. We show that if the seller is required to construct derivatives of a certain form, then this phenomenon disappears. In particular, we define and construct pseudorandom derivative families, for which lemon placement only slightly affects the values of the derivatives. Our constructions use expander graphs. We study our derivatives in a more general setting than Arora et al. In particular, we analyze arbitrary tranches of the common collateralized debt obligations (CDOs) when the underlying assets can have significant dependencies.
Arora, Barak, Brunnermeier, and Ge showed that taking computational complexity into account, a dishonest seller could strategically place lemons in financial derivatives to make them substantially less valuable to buyers. We show that if the seller is required to construct derivatives of a certain form, then this phenomenon disappears. In particular, we define and construct pseudorandom derivative families, for which lemon placement only slightly affects the values of the derivatives. Our constructions use expander graphs. We study our derivatives in a more general setting than Arora et al. In particular, we analyze arbitrary tranches of the common collateralized debt obligations (CDOs) when the underlying assets can have significant dependencies.




 In this paper we present a deterministic polynomial time algorithm for testing if a symbolic matrix in non-commuting variables over $\mathbb{Q}$ is invertible or not. The analogous question for commuting variables is the celebrated polynomial identity testing (PIT) for symbolic determinants. In contrast to the commutative case, which has an efficient probabilistic algorithm, the best previous algorithm for the non-commutative setting required exponential time (whether or not randomization is allowed). The algorithm efficiently solves the "word problem" for the free skew field, and the identity testing problem for arithmetic formulae with division over non-commuting variables, two problems which had only exponential-time algorithms prior to this work. The main contribution of this paper is a complexity analysis of an existing algorithm due to Gurvits, who proved it was polynomial time for certain classes of inputs. We prove it always runs in polynomial time. The main component of our analysis is a simple (given the necessary known tools) lower bound on central notion of capacity of operators (introduced by Gurvits). We extend the algorithm to actually approximate capacity to any accuracy in polynomial time, and use this analysis to give quantitative bounds on the continuity of capacity (the latter is used in a subsequent paper on Brascamp-Lieb inequalities). Symbolic matrices in non-commuting variables, and the related structural and algorithmic questions, have a remarkable number of diverse origins and motivations. They arise independently in (commutative) invariant theory and representation theory, linear algebra, optimization, linear system theory, quantum information theory, approximation of the permanent and naturally in non-commutative algebra. We provide a detailed account of some of these sources and their interconnections.
In this paper we present a deterministic polynomial time algorithm for testing if a symbolic matrix in non-commuting variables over $\mathbb{Q}$ is invertible or not. The analogous question for commuting variables is the celebrated polynomial identity testing (PIT) for symbolic determinants. In contrast to the commutative case, which has an efficient probabilistic algorithm, the best previous algorithm for the non-commutative setting required exponential time (whether or not randomization is allowed). The algorithm efficiently solves the "word problem" for the free skew field, and the identity testing problem for arithmetic formulae with division over non-commuting variables, two problems which had only exponential-time algorithms prior to this work. The main contribution of this paper is a complexity analysis of an existing algorithm due to Gurvits, who proved it was polynomial time for certain classes of inputs. We prove it always runs in polynomial time. The main component of our analysis is a simple (given the necessary known tools) lower bound on central notion of capacity of operators (introduced by Gurvits). We extend the algorithm to actually approximate capacity to any accuracy in polynomial time, and use this analysis to give quantitative bounds on the continuity of capacity (the latter is used in a subsequent paper on Brascamp-Lieb inequalities). Symbolic matrices in non-commuting variables, and the related structural and algorithmic questions, have a remarkable number of diverse origins and motivations. They arise independently in (commutative) invariant theory and representation theory, linear algebra, optimization, linear system theory, quantum information theory, approximation of the permanent and naturally in non-commutative algebra. We provide a detailed account of some of these sources and their interconnections.




 A $\textit{sigma partitioning}$ of a graph $G$ is a partition of the vertices into sets $P_1, \ldots, P_k$ such that for every two adjacent vertices $u$ and $v$ there is an index $i$ such that $u$ and $v$ have different numbers of neighbors in $P_i$. The $\textit{ sigma number}$ of a graph $G$, denoted by $\sigma(G)$, is the minimum number $k$ such that $ G $ has a sigma partitioning $P_1, \ldots, P_k$. Also, a $\textit{ lucky labeling}$ of a graph $G$ is a function $ \ell :V(G) \rightarrow \mathbb{N}$, such that for every two adjacent vertices $ v $ and $ u$ of $ G $, $ \sum_{w \sim v}\ell(w)\neq \sum_{w \sim u}\ell(w) $ ($ x \sim y $ means that $ x $ and $y$ are adjacent). The $\textit{ lucky number}$ of $ G $, denoted by $\eta(G)$, is the minimum number $k $ such that $ G $ has a lucky labeling $ \ell :V(G) \rightarrow \mathbb{N}_k$. It was conjectured in [Inform. Process. Lett., 112(4):109--112, 2012] that it is $ \mathbf{NP} $-complete to decide whether $ \eta(G)=2$ for a given 3-regular graph $G$. In this work, we prove this conjecture. Among other results, we give an upper bound of five for the sigma number of a uniformly random graph.
A $\textit{sigma partitioning}$ of a graph $G$ is a partition of the vertices into sets $P_1, \ldots, P_k$ such that for every two adjacent vertices $u$ and $v$ there is an index $i$ such that $u$ and $v$ have different numbers of neighbors in $P_i$. The $\textit{ sigma number}$ of a graph $G$, denoted by $\sigma(G)$, is the minimum number $k$ such that $ G $ has a sigma partitioning $P_1, \ldots, P_k$. Also, a $\textit{ lucky labeling}$ of a graph $G$ is a function $ \ell :V(G) \rightarrow \mathbb{N}$, such that for every two adjacent vertices $ v $ and $ u$ of $ G $, $ \sum_{w \sim v}\ell(w)\neq \sum_{w \sim u}\ell(w) $ ($ x \sim y $ means that $ x $ and $y$ are adjacent). The $\textit{ lucky number}$ of $ G $, denoted by $\eta(G)$, is the minimum number $k $ such that $ G $ has a lucky labeling $ \ell :V(G) \rightarrow \mathbb{N}_k$. It was conjectured in [Inform. Process. Lett., 112(4):109--112, 2012] that it is $ \mathbf{NP} $-complete to decide whether $ \eta(G)=2$ for a given 3-regular graph $G$. In this work, we prove this conjecture. Among other results, we give an upper bound of five for the sigma number of a uniformly random graph.