-
Computer networks have become a critical infrastructure. In fact, networks
should not only meet strict requirements in terms of correctness, availability,
and performance, but they should also be very flexible and support fast
updates, e.g., due to policy changes, increasing traffic, or failures. This
paper presents a structured survey of mechanism and protocols to update
computer networks in a fast and consistent manner. In particular, we identify
and discuss the different desirable consistency properties that should be
provided throughout a network update, the algorithmic techniques which are
needed to meet these consistency properties, and the implications on the speed
and costs at which updates can be performed. We also explain the relationship
between consistent network update problems and classic algorithmic optimization
ones. While our survey is mainly motivated by the advent of Software-Defined
Networks (SDNs) and their primary need for correct and efficient update
techniques, the fundamental underlying problems are not new, and we provide a
historical perspective of the subject as well.
-
We strengthen the connections between electrical transformations and homotopy
from the planar setting---observed and studied since Steinitz---to arbitrary
surfaces with punctures. As a result, we improve our earlier lower bound on the
number of electrical transformations required to reduce an $n$-vertex graph on
surface in the worst case [SOCG 2016] in two different directions. Our previous
$\Omega(n^{3/2})$ lower bound applies only to facial electrical transformations
on plane graphs with no terminals. First we provide a stronger $\Omega(n^2)$
lower bound when the planar graph has two or more terminals, which follows from
a quadratic lower bound on the number of homotopy moves in the annulus. Our
second result extends our earlier $\Omega(n^{3/2})$ lower bound to the wider
class of planar electrical transformations, which preserve the planarity of the
graph but may delete cycles that are not faces of the given embedding. This new
lower bound follows from the observation that the defect of the medial graph of
a planar graph is the same for all its planar embeddings.
-
Dense kernel matrices $\Theta \in \mathbb{R}^{N \times N}$ obtained from
point evaluations of a covariance function $G$ at locations $\{ x_{i} \}_{1
\leq i \leq N} \subset \mathbb{R}^{d}$ arise in statistics, machine learning,
and numerical analysis. For covariance functions that are Green's functions of
elliptic boundary value problems and homogeneously-distributed sampling points,
we show how to identify a subset $S \subset \{ 1 , \dots , N \}^2$, with $\# S
= O ( N \log (N) \log^{d} ( N /\epsilon ) )$, such that the zero fill-in
incomplete Cholesky factorisation of the sparse matrix $\Theta_{ij} 1_{( i, j )
\in S}$ is an $\epsilon$-approximation of $\Theta$. This factorisation can
provably be obtained in complexity $O ( N \log( N ) \log^{d}( N /\epsilon) )$
in space and $O ( N \log^{2}( N ) \log^{2d}( N /\epsilon) )$ in time, improving
upon the state of the art for general elliptic operators; we further present
numerical evidence that $d$ can be taken to be the intrinsic dimension of the
data set rather than that of the ambient space. The algorithm only needs to
know the spatial configuration of the $x_{i}$ and does not require an analytic
representation of $G$. Furthermore, this factorization straightforwardly
provides an approximate sparse PCA with optimal rate of convergence in the
operator norm. Hence, by using only subsampling and the incomplete Cholesky
factorization, we obtain, at nearly linear complexity, the compression,
inversion and approximate PCA of a large class of covariance matrices. By
inverting the order of the Cholesky factorization we also obtain a solver for
elliptic PDE with complexity $O ( N \log^{d}( N /\epsilon) )$ in space and $O (
N \log^{2d}( N /\epsilon) )$ in time, improving upon the state of the art for
general elliptic operators.
-
We give offline algorithms for processing a sequence of $2$ and $3$ edge and
vertex connectivity queries in a fully-dynamic undirected graph. While the
current best fully-dynamic online data structures for $3$-edge and $3$-vertex
connectivity require $O(n^{2/3})$ and $O(n)$ time per update, respectively, our
per-operation cost is only $O(\log n)$, optimal due to the dynamic connectivity
lower bound of Patrascu and Demaine. Our approach utilizes a divide and conquer
scheme that transforms a graph into smaller equivalents that preserve
connectivity information. This construction of equivalents is closely-related
to the development of vertex sparsifiers, and shares important connections to
several upcoming results in dynamic graph data structures, outside of just the
offline model.
-
Based on the famous Rotation-Extension technique, by creating the new
concepts and methods: broad cycle, main segment, useful cut and insert,
destroying edges for a main segment, main goal Hamilton cycle, depth-first
search tree, we develop a polynomial time algorithm for a famous NPC: the
Hamilton cycle problem. Thus we proved that NP=P. The key points of this paper
are: 1) there are two ways to get a Hamilton cycle in exponential time: a full
permutation of n vertices; or, chose n edges from all k edges, and check all
possible combinations. The main problem is: how to avoid checking all
combinations of n edges from all edges. My algorithm can avoid this. Lemma 1
and lemma 2 are very important. They are the foundation that we always can get
a good branch in the depth-first search tree and can get a series of destroying
edges (all are bad edges) for this good branch in polynomial time. The
extraordinary insights are: destroying edges, a tree contains each main segment
at most one time at the same time, and dynamic combinations. The difficult part
is to understand how to construct a main segment's series of destroying edges
by dynamic combinations. The proof logic is: if there is at least on Hamilton
cycle in the graph, we always can do useful cut and inserts until a Hamilton
cycle is got. The times of useful cut and inserts are polynomial. So if at any
step we cannot have a useful cut and insert, this means that there are no
Hamilton cycles in the graph. In this version, I add a detailed polynomial time
algorithm and proof for 3SAT
-
A parallel algorithm for maximal independent set (MIS) in hypergraphs has
been a long-standing algorithmic challenge, dating back nearly 30 years to a
survey of Karp & Ramachandran (1990). The best randomized parallel algorithm
for hypergraphs of fixed rank $r$ was developed by Beame & Luby (1990) and
Kelsen (1992), running in time roughly $(\log n)^{r!}$.
We improve the randomized algorithm of Kelsen, reducing the runtime to
roughly $(\log n)^{2^r}$ and simplifying the analysis through the use of
more-modern concentration inequalities. We also give a method for derandomizing
concentration bounds for low-degree polynomials, which are the key technical
tool used to analyze that algorithm. This leads to a deterministic PRAM
algorithm also running in $(\log n)^{2^{r+3}}$ time and $\text{poly}(m,n)$
processors. This is the first deterministic algorithm with sub-polynomial
runtime for hypergraphs of rank $r > 3$.
Our analysis can also apply when $r$ is slowly growing; using this in
conjunction with a strategy of Bercea et al. (2015) gives a deterministic MIS
algorithm running in time $\exp(O( \frac{\log (mn)}{\log \log (mn)}))$.
-
Analyzing massive complex networks yields promising insights about our
everyday lives. Building scalable algorithms to do so is a challenging task
that requires a careful analysis and an extensive evaluation. However,
engineering such algorithms is often hindered by the scarcity of
publicly~available~datasets.
Network generators serve as a tool to alleviate this problem by providing
synthetic instances with controllable parameters. However, many network
generators fail to provide instances on a massive scale due to their sequential
nature or resource constraints. Additionally, truly scalable network generators
are few and often limited in their realism.
In this work, we present novel generators for a variety of network models
that are frequently used as benchmarks. By making use of pseudorandomization
and divide-and-conquer schemes, our generators follow a communication-free
paradigm. The resulting generators are thus embarrassingly parallel and have a
near optimal scaling behavior. This allows us to generate instances of up to
$2^{43}$ vertices and $2^{47}$ edges in less than 22 minutes on 32768 cores.
Therefore, our generators allow new graph families to be used on an
unprecedented scale.
-
Exact Maximum Inner Product Search (MIPS) is an important task that is widely
pertinent to recommender systems and high-dimensional similarity search. The
brute-force approach to solving exact MIPS is computationally expensive, thus
spurring recent development of novel indexes and pruning techniques for this
task. In this paper, we show that a hardware-efficient brute-force approach,
blocked matrix multiply (BMM), can outperform the state-of-the-art MIPS solvers
by over an order of magnitude, for some -- but not all -- inputs.
In this paper, we also present a novel MIPS solution, MAXIMUS, that takes
advantage of hardware efficiency and pruning of the search space. Like BMM,
MAXIMUS is faster than other solvers by up to an order of magnitude, but again
only for some inputs. Since no single solution offers the best runtime
performance for all inputs, we introduce a new data-dependent optimizer,
OPTIMUS, that selects online with minimal overhead the best MIPS solver for a
given input. Together, OPTIMUS and MAXIMUS outperform state-of-the-art MIPS
solvers by 3.2$\times$ on average, and up to 10.9$\times$, on widely studied
MIPS datasets.
-
We study high-dimensional distribution learning in an agnostic setting where
an adversary is allowed to arbitrarily corrupt an $\varepsilon$-fraction of the
samples. Such questions have a rich history spanning statistics, machine
learning and theoretical computer science. Even in the most basic settings, the
only known approaches are either computationally inefficient or lose
dimension-dependent factors in their error guarantees. This raises the
following question:Is high-dimensional agnostic distribution learning even
possible, algorithmically?
In this work, we obtain the first computationally efficient algorithms with
dimension-independent error guarantees for agnostically learning several
fundamental classes of high-dimensional distributions: (1) a single Gaussian,
(2) a product distribution on the hypercube, (3) mixtures of two product
distributions (under a natural balancedness condition), and (4) mixtures of
spherical Gaussians. Our algorithms achieve error that is independent of the
dimension, and in many cases scales nearly-linearly with the fraction of
adversarially corrupted samples. Moreover, we develop a general recipe for
detecting and correcting corruptions in high-dimensions, that may be applicable
to many other problems.
-
We consider a stochastic variant of the packing-type integer linear
programming problem, which contains random variables in the objective vector.
We are allowed to reveal each entry of the objective vector by conducting a
query, and the task is to find a good solution by conducting a small number of
queries. We propose a general framework of adaptive and non-adaptive algorithms
for this problem, and provide a unified methodology for analyzing the
performance of those algorithms. We also demonstrate our framework by applying
it to a variety of stochastic combinatorial optimization problems such as
matching, matroid, and stable set problems.
-
A seed in a word is a relaxed version of a period in which the occurrences of
the repeating subword may overlap. We show a linear-time algorithm computing a
linear-size representation of all the seeds of a word (the number of seeds
might be quadratic). In particular, one can easily derive the shortest seed and
the number of seeds from our representation. Thus, we solve an open problem
stated in the survey by Smyth (2000) and improve upon a previous O(n log n)
algorithm by Iliopoulos, Moore, and Park (1996). Our approach is based on
combinatorial relations between seeds and subword complexity (used here for the
first time in context of seeds). In the previous papers, the compact
representation of seeds consisted of two independent parts operating on the
suffix tree of the word and the suffix tree of the reverse of the word,
respectively. Our second contribution is a simpler representation of all seeds
which avoids dealing with the reversed word.
A preliminary version of this work, with a much more complex algorithm
constructing the earlier representation of seeds, was presented at the 23rd
Annual ACM-SIAM Symposium of Discrete Algorithms (SODA 2012).
-
We present a new algorithm which detects the maximal possible number of
matched disjoint pairs satisfying a given caliper when a bipartite matching is
done with respect to a scalar index (e.g., propensity score), and constructs a
corresponding matching. Variable width calipers are compatible with the
technique, provided that the width of the caliper is a Lipschitz function of
the index. If the observations are ordered with respect to the index then the
matching needs $O(N)$ operations, where $N$ is the total number of subjects to
be matched. The case of 1-to-$n$ matching is also considered.
We offer also a new fast algorithm for optimal complete one-to-one matching
on a scalar index when the treatment and control groups are of the same size.
This allows us to improve greedy nearest neighbor matching on a scalar index.
Keywords: propensity score matching, nearest neighbor matching, matching with
caliper, variable width caliper.
-
This summary of the doctoral thesis is created to emphasize the close
connection of the proposed spectral analysis method with the Discrete Fourier
Transform (DFT), the most extensively studied and frequently used approach in
the history of signal processing. It is shown that in a typical application
case, where uniform data readings are transformed to the same number of
uniformly spaced frequencies, the results of the classical DFT and proposed
approach coincide. The difference in performance appears when the length of the
DFT is selected to be greater than the length of the data. The DFT solves the
unknown data problem by padding readings with zeros up to the length of the
DFT, while the proposed Extended DFT (EDFT) deals with this situation in a
different way, it uses the Fourier integral transform as a target and optimizes
the transform basis in the extended frequency range without putting such
restrictions on the time domain. Consequently, the Inverse DFT (IDFT) applied
to the result of EDFT returns not only known readings, but also the
extrapolated data, where classical DFT is able to give back just zeros, and
higher resolution are achieved at frequencies where the data has been
successfully extended. It has been demonstrated that EDFT able to process data
with missing readings or gaps inside or even nonuniformly distributed data.
Thus, EDFT significantly extends the usability of the DFT-based methods, where
previously these approaches have been considered as not applicable. The EDFT
founds the solution in an iterative way and requires repeated calculations to
get the adaptive basis, and this makes it numerical complexity much higher
compared to DFT. This disadvantage was a serious problem in the 1990s, when the
method has been proposed. Fortunately, since then the power of computers has
increased so much that nowadays EDFT application could be considered as a real
alternative.
-
Given a Binary Decision Diagram B of a Boolean function \phi in variables,
all N many k-ones models of \phi can be enumerated in time polynomial in n and
N and |B|. Using novel wildcards enables a compressed enumeration of these
models. Simple examples show that the compression can be arbitrarily high.
-
We introduce a family of multi-way Cheeger-type constants $\{h_k^{\sigma},
k=1,2,\ldots, n\}$ on a signed graph $\Gamma=(G,\sigma)$ such that
$h_k^{\sigma}=0$ if and only if $\Gamma$ has $k$ balanced connected components.
These constants are switching invariant and bring together in a unified
viewpoint a number of important graph-theoretical concepts, including the
classical Cheeger constant, those measures of bipartiteness introduced by
Desai-Rao, Trevisan, Bauer-Jost, respectively, on unsigned graphs,, and the
frustration index (originally called the line index of balance by Harary) on
signed graphs. We further unify the (higher-order or improved) Cheeger and dual
Cheeger inequalities for unsigned graphs as well as the underlying algorithmic
proof techniques by establishing their corresponding versions on signed graphs.
In particular, we develop a spectral clustering method for finding $k$
almost-balanced subgraphs, each defining a sparse cut. The proper metric for
such a clustering is the metric on a real projective space. We also prove
estimates of the extremal eigenvalues of signed Laplace matrix in terms of
number of signed triangles ($3$-cycles).
-
This paper investigates the behavior of the Min-Sum message passing scheme to
solve systems of linear equations in the Laplacian matrices of graphs and to
compute electric flows. Voltage and flow problems involve the minimization of
quadratic functions and are fundamental primitives that arise in several
domains. Algorithms that have been proposed are typically centralized and
involve multiple graph-theoretic constructions or sampling mechanisms that make
them difficult to implement and analyze. On the other hand, message passing
routines are distributed, simple, and easy to implement. In this paper we
establish a framework to analyze Min-Sum to solve voltage and flow problems. We
characterize the error committed by the algorithm on general weighted graphs in
terms of hitting times of random walks defined on the computation trees that
support the operations of the algorithms with time. For $d$-regular graphs with
equal weights, we show that the convergence of the algorithms is controlled by
the total variation distance between the distributions of non-backtracking
random walks defined on the original graph that start from neighboring nodes.
The framework that we introduce extends the analysis of Min-Sum to settings
where the contraction arguments previously considered in the literature (based
on the assumption of walk summability or scaled diagonal dominance) can not be
used, possibly in the presence of constraints.
-
In this work, we study the $k$-median and $k$-means clustering problems when
the data is distributed across many servers and can contain outliers. While
there has been a lot of work on these problems for worst-case instances, we
focus on gaining a finer understanding through the lens of beyond worst-case
analysis. Our main motivation is the following: for many applications such as
clustering proteins by function or clustering communities in a social network,
there is some unknown target clustering, and the hope is that running a
$k$-median or $k$-means algorithm will produce clusterings which are close to
matching the target clustering. Worst-case results can guarantee constant
factor approximations to the optimal $k$-median or $k$-means objective value,
but not closeness to the target clustering.
Our first result is a distributed algorithm which returns a near-optimal
clustering assuming a natural notion of stability, namely, approximation
stability [Balcan et. al 2013], even when a constant fraction of the data are
outliers. The communication complexity is $\tilde O(sk+z)$ where $s$ is the
number of machines, $k$ is the number of clusters, and $z$ is the number of
outliers.
Next, we show this amount of communication cannot be improved even in the
setting when the input satisfies various non-worst-case assumptions. We give a
matching $\Omega(sk+z)$ lower bound on the communication required both for
approximating the optimal $k$-means or $k$-median cost up to any constant, and
for returning a clustering that is close to the target clustering in Hamming
distance. These lower bounds hold even when the data satisfies approximation
stability or other common notions of stability, and the cluster sizes are
balanced. Therefore, $\Omega(sk+z)$ is a communication bottleneck, even for
real-world instances.
-
In systems of programmable matter, we are given a collection of simple
computation elements (or particles) with limited (constant-size) memory. We are
interested in when they can self-organize to solve system-wide problems of
movement, configuration and coordination. Here, we initiate a stochastic
approach to developing robust distributed algorithms for programmable matter
systems using Markov chains. We are able to leverage the wealth of prior work
in Markov chains and related areas to design and rigorously analyze our
distributed algorithms and show that they have several desirable properties.
We study the compression problem, in which a particle system must gather as
tightly together as possible, as in a sphere or its equivalent in the presence
of some underlying geometry. More specifically, we seek fully distributed,
local, and asynchronous algorithms that lead the system to converge to a
configuration with small boundary. We present a Markov chain-based algorithm
that solves the compression problem under the geometric amoebot model, for
particle systems that begin in a connected configuration. The algorithm takes
as input a bias parameter $\lambda$, where $\lambda > 1$ corresponds to
particles favoring having more neighbors. We show that for all $\lambda >
2+\sqrt{2}$, there is a constant $\alpha > 1$ such that eventually with all but
exponentially small probability the particles are $\alpha$-compressed, meaning
the perimeter of the system configuration is at most $\alpha \cdot p_{min}$,
where $p_{min}$ is the minimum possible perimeter of the particle system.
Surprisingly, the same algorithm can also be used for expansion when $0 <
\lambda < 2.17$, and we prove similar results about expansion for values of
$\lambda$ in this range. This is counterintuitive as it shows that particles
preferring to be next to each other ($\lambda > 1$) is not sufficient to
guarantee compression.
-
The dictionary matching is a task to find all occurrences of patterns in a
set $D$ (called a dictionary) on a text $T$. The Aho-Corasick-automaton
(AC-automaton) is a data structure which enables us to solve the dictionary
matching problem in $O(d\log\sigma)$ preprocessing time and
$O(n\log\sigma+occ)$ matching time, where $d$ is the total length of the
patterns in $D$, $n$ is the length of the text, $\sigma$ is the alphabet size,
and $occ$ is the total number of occurrences of all the patterns in the text.
The dynamic dictionary matching is a variant where patterns may dynamically be
inserted into and deleted from $D$. This problem is called semi-dynamic
dictionary matching if only insertions are allowed. In this paper, we propose
two efficient algorithms. For a pattern of length $m$, our first algorithm
supports insertions in $O(m\log\sigma+\log d/\log\log d)$ time and pattern
matching in $O(n\log\sigma+occ)$ time for the semi-dynamic setting and supports
both insertions and deletions in $O(\sigma m+\log d/\log\log d)$ time and
pattern matching in $O(n(\log d/\log\log d+\log\sigma)+occ(\log d/\log\log d))$
time for the dynamic setting by some modifications. This algorithm is based on
the directed acyclic word graph. Our second algorithm, which is based on the
AC-automaton, supports insertions in $O(m\log \sigma+u_f+u_o)$ time for the
semi-dynamic setting and supports both insertions and deletions in $O(\sigma
m+u_f+u_o)$ time for the dynamic setting, where $u_f$ and $u_o$ respectively
denote the numbers of states in which the failure function and the output
function need to be updated. This algorithm performs pattern matching in
$O(n\log\sigma+occ)$ time for both settings. Our algorithm achieves optimal
update time for AC-automaton based methods over constant-size alphabets, since
any algorithm which explicitly maintains the AC-automaton requires
$\Omega(m+u_f+u_o)$ update time.
-
The assortment problem in revenue management is the problem of deciding which
subset of products to offer to consumers in order to maximise revenue. A simple
and natural strategy is to select the best assortment out of all those that are
constructed by fixing a threshold revenue $\pi$ and then choosing all products
with revenue at least $\pi$. This is known as the revenue-ordered assortments
strategy. In this paper we study the approximation guarantees provided by
revenue-ordered assortments when customers are rational in the following sense:
the probability of selecting a specific product from the set being offered
cannot increase if the set is enlarged. This rationality assumption, known as
regularity, is satisfied by almost all discrete choice models considered in the
revenue management and choice theory literature, and in particular by random
utility models. The bounds we obtain are tight and improve on recent results in
that direction, such as for the Mixed Multinomial Logit model by
Rusmevichientong et al. (2014). An appealing feature of our analysis is its
simplicity, as it relies only on the regularity condition.
We also draw a connection between assortment optimisation and two pricing
problems called unit demand envy-free pricing and Stackelberg minimum spanning
tree: These problems can be restated as assortment problems under discrete
choice models satisfying the regularity condition, and moreover revenue-ordered
assortments correspond then to the well-studied uniform pricing heuristic. When
specialised to that setting, the general bounds we establish for
revenue-ordered assortments match and unify the best known results on uniform
pricing.
-
We provide simple and approximately revenue-optimal mechanisms in the
multi-item multi-bidder settings. We unify and improve all previous results, as
well as generalize the results to broader cases. In particular, we prove that
the better of the following two simple, deterministic and Dominant Strategy
Incentive Compatible mechanisms, a sequential posted price mechanism or an
anonymous sequential posted price mechanism with entry fee, achieves a constant
fraction of the optimal revenue among all randomized, Bayesian Incentive
Compatible mechanisms, when buyers' valuations are XOS over independent items.
If the buyers' valuations are subadditive over independent items, the
approximation factor degrades to $O(\log m)$, where $m$ is the number of items.
We obtain our results by first extending the Cai-Devanur-Weinberg duality
framework to derive an effective benchmark of the optimal revenue for
subadditive bidders, and then analyzing this upper bound with new techniques.
-
Web-based services often run randomized experiments to improve their
products. A popular way to run these experiments is to use geographical regions
as units of experimentation, since this does not require tracking of individual
users or browser cookies. Since users may issue queries from multiple
geographical locations, geo-regions cannot be considered independent and
interference may be present in the experiment. In this paper, we study this
problem, and first present GeoCUTS, a novel algorithm that forms geographical
clusters to minimize interference while preserving balance in cluster size. We
use a random sample of anonymized traffic from Google Search to form a graph
representing user movements, then construct a geographically coherent
clustering of the graph. Our main technical contribution is a statistical
framework to measure the effectiveness of clusterings. Furthermore, we perform
empirical evaluations showing that the performance of GeoCUTS is comparable to
hand-crafted geo-regions with respect to both novel and existing metrics.
-
The main purpose of this paper is pedagogical.
Despite its importance, all proofs of the correctness of Strassen's famous
1969 algorithm to multiply two 2x2 matrices with only seven multiplications
involve some basis-dependent calculations such as explicitly multiplying
specific 2x2 matrices, expanding expressions to cancel terms with opposing
signs, or expanding tensors over the standard basis. This makes the proof
nontrivial to memorize and many presentations of the proof avoid showing all
the details and leave a significant amount of verifications to the reader.
In this note we give a short, self-contained, basis-independent proof of the
existence of Strassen's algorithm that avoids these types of calculations. We
achieve this by focusing on symmetries and algebraic properties.
Our proof can be seen as a coordinate-free version of the construction of
Clausen from 1988, combined with recent work on the geometry of Strassen's
algorithm by Chiantini, Ikenmeyer, Landsberg, and Ottaviani from 2016.
-
Compression and sparsification algorithms are frequently applied in a
preprocessing step before analyzing or optimizing large networks/graphs. In
this paper we propose and study a new framework contracting edges of a graph
(merging vertices into super-vertices) with the goal of preserving pairwise
distances as accurately as possible. Formally, given an edge-weighted graph,
the contraction should guarantee that for any two vertices at distance $d$, the
corresponding super-vertices remain at distance at least $\varphi(d)$ in the
contracted graph, where $\varphi$ is a tolerance function bounding the
permitted distance distortion. We present a comprehensive picture of the
algorithmic complexity of the contraction problem for affine tolerance
functions $\varphi(x)=x/\alpha-\beta$, where $\alpha\geq 1$ and $\beta\geq 0$
are arbitrary real-valued parameters. Specifically, we present polynomial-time
algorithms for trees as well as hardness and inapproximability results for
different graph classes, precisely separating easy and hard cases. Further we
analyze the asymptotic behavior of contractions, and find efficient algorithms
to compute (non-optimal) contractions despite our hardness results.
-
We present an O(n^6 ) linear programming model for the traveling salesman
(TSP) and quadratic assignment (QAP) problems. The basic model is developed
within the framework of the TSP. It does not involve the city-to-city
variables-based, traditional TSP polytope referred to in the literature as "the
TSP polytope." We do not model explicit Hamiltonian cycles of the cities.
Instead, we use a time-dependent abstraction of TSP tours and develop a direct
extended formulation of the linear assignment problem (LAP) polytope. The model
is exact in the sense that it has integral extreme points which are in
one-to-one correspondence with TSP tours. It can be solved optimally using any
linear programming (LP) solver, hence offering a new (incidental) proof of the
equality of the computational complexity classes "P" and "NP." The extensions
of the model to the time-dependent traveling salesman problem (TDTSP) as well
as the quadratic assignment problem (QAP) are straightforward. The reasons for
the non-applicability of existing negative extended formulations results for
"the TSP polytope" to the model in this paper as well as our software
implementation and the computational experimentation we conducted are briefly
discussed.





 Computer networks have become a critical infrastructure. In fact, networks should not only meet strict requirements in terms of correctness, availability, and performance, but they should also be very flexible and support fast updates, e.g., due to policy changes, increasing traffic, or failures. This paper presents a structured survey of mechanism and protocols to update computer networks in a fast and consistent manner. In particular, we identify and discuss the different desirable consistency properties that should be provided throughout a network update, the algorithmic techniques which are needed to meet these consistency properties, and the implications on the speed and costs at which updates can be performed. We also explain the relationship between consistent network update problems and classic algorithmic optimization ones. While our survey is mainly motivated by the advent of Software-Defined Networks (SDNs) and their primary need for correct and efficient update techniques, the fundamental underlying problems are not new, and we provide a historical perspective of the subject as well.
Computer networks have become a critical infrastructure. In fact, networks should not only meet strict requirements in terms of correctness, availability, and performance, but they should also be very flexible and support fast updates, e.g., due to policy changes, increasing traffic, or failures. This paper presents a structured survey of mechanism and protocols to update computer networks in a fast and consistent manner. In particular, we identify and discuss the different desirable consistency properties that should be provided throughout a network update, the algorithmic techniques which are needed to meet these consistency properties, and the implications on the speed and costs at which updates can be performed. We also explain the relationship between consistent network update problems and classic algorithmic optimization ones. While our survey is mainly motivated by the advent of Software-Defined Networks (SDNs) and their primary need for correct and efficient update techniques, the fundamental underlying problems are not new, and we provide a historical perspective of the subject as well.




 We strengthen the connections between electrical transformations and homotopy from the planar setting---observed and studied since Steinitz---to arbitrary surfaces with punctures. As a result, we improve our earlier lower bound on the number of electrical transformations required to reduce an $n$-vertex graph on surface in the worst case [SOCG 2016] in two different directions. Our previous $\Omega(n^{3/2})$ lower bound applies only to facial electrical transformations on plane graphs with no terminals. First we provide a stronger $\Omega(n^2)$ lower bound when the planar graph has two or more terminals, which follows from a quadratic lower bound on the number of homotopy moves in the annulus. Our second result extends our earlier $\Omega(n^{3/2})$ lower bound to the wider class of planar electrical transformations, which preserve the planarity of the graph but may delete cycles that are not faces of the given embedding. This new lower bound follows from the observation that the defect of the medial graph of a planar graph is the same for all its planar embeddings.
We strengthen the connections between electrical transformations and homotopy from the planar setting---observed and studied since Steinitz---to arbitrary surfaces with punctures. As a result, we improve our earlier lower bound on the number of electrical transformations required to reduce an $n$-vertex graph on surface in the worst case [SOCG 2016] in two different directions. Our previous $\Omega(n^{3/2})$ lower bound applies only to facial electrical transformations on plane graphs with no terminals. First we provide a stronger $\Omega(n^2)$ lower bound when the planar graph has two or more terminals, which follows from a quadratic lower bound on the number of homotopy moves in the annulus. Our second result extends our earlier $\Omega(n^{3/2})$ lower bound to the wider class of planar electrical transformations, which preserve the planarity of the graph but may delete cycles that are not faces of the given embedding. This new lower bound follows from the observation that the defect of the medial graph of a planar graph is the same for all its planar embeddings.
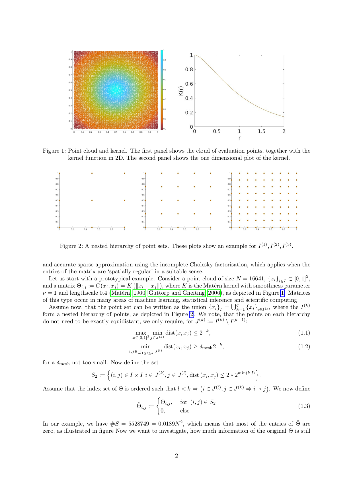
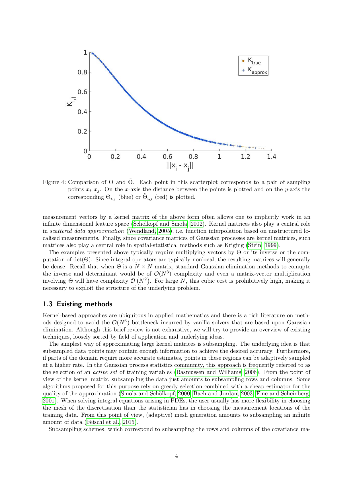

 Dense kernel matrices $\Theta \in \mathbb{R}^{N \times N}$ obtained from point evaluations of a covariance function $G$ at locations $\{ x_{i} \}_{1 \leq i \leq N} \subset \mathbb{R}^{d}$ arise in statistics, machine learning, and numerical analysis. For covariance functions that are Green's functions of elliptic boundary value problems and homogeneously-distributed sampling points, we show how to identify a subset $S \subset \{ 1 , \dots , N \}^2$, with $\# S = O ( N \log (N) \log^{d} ( N /\epsilon ) )$, such that the zero fill-in incomplete Cholesky factorisation of the sparse matrix $\Theta_{ij} 1_{( i, j ) \in S}$ is an $\epsilon$-approximation of $\Theta$. This factorisation can provably be obtained in complexity $O ( N \log( N ) \log^{d}( N /\epsilon) )$ in space and $O ( N \log^{2}( N ) \log^{2d}( N /\epsilon) )$ in time, improving upon the state of the art for general elliptic operators; we further present numerical evidence that $d$ can be taken to be the intrinsic dimension of the data set rather than that of the ambient space. The algorithm only needs to know the spatial configuration of the $x_{i}$ and does not require an analytic representation of $G$. Furthermore, this factorization straightforwardly provides an approximate sparse PCA with optimal rate of convergence in the operator norm. Hence, by using only subsampling and the incomplete Cholesky factorization, we obtain, at nearly linear complexity, the compression, inversion and approximate PCA of a large class of covariance matrices. By inverting the order of the Cholesky factorization we also obtain a solver for elliptic PDE with complexity $O ( N \log^{d}( N /\epsilon) )$ in space and $O ( N \log^{2d}( N /\epsilon) )$ in time, improving upon the state of the art for general elliptic operators.
Dense kernel matrices $\Theta \in \mathbb{R}^{N \times N}$ obtained from point evaluations of a covariance function $G$ at locations $\{ x_{i} \}_{1 \leq i \leq N} \subset \mathbb{R}^{d}$ arise in statistics, machine learning, and numerical analysis. For covariance functions that are Green's functions of elliptic boundary value problems and homogeneously-distributed sampling points, we show how to identify a subset $S \subset \{ 1 , \dots , N \}^2$, with $\# S = O ( N \log (N) \log^{d} ( N /\epsilon ) )$, such that the zero fill-in incomplete Cholesky factorisation of the sparse matrix $\Theta_{ij} 1_{( i, j ) \in S}$ is an $\epsilon$-approximation of $\Theta$. This factorisation can provably be obtained in complexity $O ( N \log( N ) \log^{d}( N /\epsilon) )$ in space and $O ( N \log^{2}( N ) \log^{2d}( N /\epsilon) )$ in time, improving upon the state of the art for general elliptic operators; we further present numerical evidence that $d$ can be taken to be the intrinsic dimension of the data set rather than that of the ambient space. The algorithm only needs to know the spatial configuration of the $x_{i}$ and does not require an analytic representation of $G$. Furthermore, this factorization straightforwardly provides an approximate sparse PCA with optimal rate of convergence in the operator norm. Hence, by using only subsampling and the incomplete Cholesky factorization, we obtain, at nearly linear complexity, the compression, inversion and approximate PCA of a large class of covariance matrices. By inverting the order of the Cholesky factorization we also obtain a solver for elliptic PDE with complexity $O ( N \log^{d}( N /\epsilon) )$ in space and $O ( N \log^{2d}( N /\epsilon) )$ in time, improving upon the state of the art for general elliptic operators.




 We give offline algorithms for processing a sequence of $2$ and $3$ edge and vertex connectivity queries in a fully-dynamic undirected graph. While the current best fully-dynamic online data structures for $3$-edge and $3$-vertex connectivity require $O(n^{2/3})$ and $O(n)$ time per update, respectively, our per-operation cost is only $O(\log n)$, optimal due to the dynamic connectivity lower bound of Patrascu and Demaine. Our approach utilizes a divide and conquer scheme that transforms a graph into smaller equivalents that preserve connectivity information. This construction of equivalents is closely-related to the development of vertex sparsifiers, and shares important connections to several upcoming results in dynamic graph data structures, outside of just the offline model.
We give offline algorithms for processing a sequence of $2$ and $3$ edge and vertex connectivity queries in a fully-dynamic undirected graph. While the current best fully-dynamic online data structures for $3$-edge and $3$-vertex connectivity require $O(n^{2/3})$ and $O(n)$ time per update, respectively, our per-operation cost is only $O(\log n)$, optimal due to the dynamic connectivity lower bound of Patrascu and Demaine. Our approach utilizes a divide and conquer scheme that transforms a graph into smaller equivalents that preserve connectivity information. This construction of equivalents is closely-related to the development of vertex sparsifiers, and shares important connections to several upcoming results in dynamic graph data structures, outside of just the offline model.




 Based on the famous Rotation-Extension technique, by creating the new concepts and methods: broad cycle, main segment, useful cut and insert, destroying edges for a main segment, main goal Hamilton cycle, depth-first search tree, we develop a polynomial time algorithm for a famous NPC: the Hamilton cycle problem. Thus we proved that NP=P. The key points of this paper are: 1) there are two ways to get a Hamilton cycle in exponential time: a full permutation of n vertices; or, chose n edges from all k edges, and check all possible combinations. The main problem is: how to avoid checking all combinations of n edges from all edges. My algorithm can avoid this. Lemma 1 and lemma 2 are very important. They are the foundation that we always can get a good branch in the depth-first search tree and can get a series of destroying edges (all are bad edges) for this good branch in polynomial time. The extraordinary insights are: destroying edges, a tree contains each main segment at most one time at the same time, and dynamic combinations. The difficult part is to understand how to construct a main segment's series of destroying edges by dynamic combinations. The proof logic is: if there is at least on Hamilton cycle in the graph, we always can do useful cut and inserts until a Hamilton cycle is got. The times of useful cut and inserts are polynomial. So if at any step we cannot have a useful cut and insert, this means that there are no Hamilton cycles in the graph. In this version, I add a detailed polynomial time algorithm and proof for 3SAT
Based on the famous Rotation-Extension technique, by creating the new concepts and methods: broad cycle, main segment, useful cut and insert, destroying edges for a main segment, main goal Hamilton cycle, depth-first search tree, we develop a polynomial time algorithm for a famous NPC: the Hamilton cycle problem. Thus we proved that NP=P. The key points of this paper are: 1) there are two ways to get a Hamilton cycle in exponential time: a full permutation of n vertices; or, chose n edges from all k edges, and check all possible combinations. The main problem is: how to avoid checking all combinations of n edges from all edges. My algorithm can avoid this. Lemma 1 and lemma 2 are very important. They are the foundation that we always can get a good branch in the depth-first search tree and can get a series of destroying edges (all are bad edges) for this good branch in polynomial time. The extraordinary insights are: destroying edges, a tree contains each main segment at most one time at the same time, and dynamic combinations. The difficult part is to understand how to construct a main segment's series of destroying edges by dynamic combinations. The proof logic is: if there is at least on Hamilton cycle in the graph, we always can do useful cut and inserts until a Hamilton cycle is got. The times of useful cut and inserts are polynomial. So if at any step we cannot have a useful cut and insert, this means that there are no Hamilton cycles in the graph. In this version, I add a detailed polynomial time algorithm and proof for 3SAT




 A parallel algorithm for maximal independent set (MIS) in hypergraphs has been a long-standing algorithmic challenge, dating back nearly 30 years to a survey of Karp & Ramachandran (1990). The best randomized parallel algorithm for hypergraphs of fixed rank $r$ was developed by Beame & Luby (1990) and Kelsen (1992), running in time roughly $(\log n)^{r!}$. We improve the randomized algorithm of Kelsen, reducing the runtime to roughly $(\log n)^{2^r}$ and simplifying the analysis through the use of more-modern concentration inequalities. We also give a method for derandomizing concentration bounds for low-degree polynomials, which are the key technical tool used to analyze that algorithm. This leads to a deterministic PRAM algorithm also running in $(\log n)^{2^{r+3}}$ time and $\text{poly}(m,n)$ processors. This is the first deterministic algorithm with sub-polynomial runtime for hypergraphs of rank $r > 3$. Our analysis can also apply when $r$ is slowly growing; using this in conjunction with a strategy of Bercea et al. (2015) gives a deterministic MIS algorithm running in time $\exp(O( \frac{\log (mn)}{\log \log (mn)}))$.
A parallel algorithm for maximal independent set (MIS) in hypergraphs has been a long-standing algorithmic challenge, dating back nearly 30 years to a survey of Karp & Ramachandran (1990). The best randomized parallel algorithm for hypergraphs of fixed rank $r$ was developed by Beame & Luby (1990) and Kelsen (1992), running in time roughly $(\log n)^{r!}$. We improve the randomized algorithm of Kelsen, reducing the runtime to roughly $(\log n)^{2^r}$ and simplifying the analysis through the use of more-modern concentration inequalities. We also give a method for derandomizing concentration bounds for low-degree polynomials, which are the key technical tool used to analyze that algorithm. This leads to a deterministic PRAM algorithm also running in $(\log n)^{2^{r+3}}$ time and $\text{poly}(m,n)$ processors. This is the first deterministic algorithm with sub-polynomial runtime for hypergraphs of rank $r > 3$. Our analysis can also apply when $r$ is slowly growing; using this in conjunction with a strategy of Bercea et al. (2015) gives a deterministic MIS algorithm running in time $\exp(O( \frac{\log (mn)}{\log \log (mn)}))$.




 Exact Maximum Inner Product Search (MIPS) is an important task that is widely pertinent to recommender systems and high-dimensional similarity search. The brute-force approach to solving exact MIPS is computationally expensive, thus spurring recent development of novel indexes and pruning techniques for this task. In this paper, we show that a hardware-efficient brute-force approach, blocked matrix multiply (BMM), can outperform the state-of-the-art MIPS solvers by over an order of magnitude, for some -- but not all -- inputs. In this paper, we also present a novel MIPS solution, MAXIMUS, that takes advantage of hardware efficiency and pruning of the search space. Like BMM, MAXIMUS is faster than other solvers by up to an order of magnitude, but again only for some inputs. Since no single solution offers the best runtime performance for all inputs, we introduce a new data-dependent optimizer, OPTIMUS, that selects online with minimal overhead the best MIPS solver for a given input. Together, OPTIMUS and MAXIMUS outperform state-of-the-art MIPS solvers by 3.2$\times$ on average, and up to 10.9$\times$, on widely studied MIPS datasets.
Exact Maximum Inner Product Search (MIPS) is an important task that is widely pertinent to recommender systems and high-dimensional similarity search. The brute-force approach to solving exact MIPS is computationally expensive, thus spurring recent development of novel indexes and pruning techniques for this task. In this paper, we show that a hardware-efficient brute-force approach, blocked matrix multiply (BMM), can outperform the state-of-the-art MIPS solvers by over an order of magnitude, for some -- but not all -- inputs. In this paper, we also present a novel MIPS solution, MAXIMUS, that takes advantage of hardware efficiency and pruning of the search space. Like BMM, MAXIMUS is faster than other solvers by up to an order of magnitude, but again only for some inputs. Since no single solution offers the best runtime performance for all inputs, we introduce a new data-dependent optimizer, OPTIMUS, that selects online with minimal overhead the best MIPS solver for a given input. Together, OPTIMUS and MAXIMUS outperform state-of-the-art MIPS solvers by 3.2$\times$ on average, and up to 10.9$\times$, on widely studied MIPS datasets.




 We study high-dimensional distribution learning in an agnostic setting where an adversary is allowed to arbitrarily corrupt an $\varepsilon$-fraction of the samples. Such questions have a rich history spanning statistics, machine learning and theoretical computer science. Even in the most basic settings, the only known approaches are either computationally inefficient or lose dimension-dependent factors in their error guarantees. This raises the following question:Is high-dimensional agnostic distribution learning even possible, algorithmically? In this work, we obtain the first computationally efficient algorithms with dimension-independent error guarantees for agnostically learning several fundamental classes of high-dimensional distributions: (1) a single Gaussian, (2) a product distribution on the hypercube, (3) mixtures of two product distributions (under a natural balancedness condition), and (4) mixtures of spherical Gaussians. Our algorithms achieve error that is independent of the dimension, and in many cases scales nearly-linearly with the fraction of adversarially corrupted samples. Moreover, we develop a general recipe for detecting and correcting corruptions in high-dimensions, that may be applicable to many other problems.
We study high-dimensional distribution learning in an agnostic setting where an adversary is allowed to arbitrarily corrupt an $\varepsilon$-fraction of the samples. Such questions have a rich history spanning statistics, machine learning and theoretical computer science. Even in the most basic settings, the only known approaches are either computationally inefficient or lose dimension-dependent factors in their error guarantees. This raises the following question:Is high-dimensional agnostic distribution learning even possible, algorithmically? In this work, we obtain the first computationally efficient algorithms with dimension-independent error guarantees for agnostically learning several fundamental classes of high-dimensional distributions: (1) a single Gaussian, (2) a product distribution on the hypercube, (3) mixtures of two product distributions (under a natural balancedness condition), and (4) mixtures of spherical Gaussians. Our algorithms achieve error that is independent of the dimension, and in many cases scales nearly-linearly with the fraction of adversarially corrupted samples. Moreover, we develop a general recipe for detecting and correcting corruptions in high-dimensions, that may be applicable to many other problems.




 We consider a stochastic variant of the packing-type integer linear programming problem, which contains random variables in the objective vector. We are allowed to reveal each entry of the objective vector by conducting a query, and the task is to find a good solution by conducting a small number of queries. We propose a general framework of adaptive and non-adaptive algorithms for this problem, and provide a unified methodology for analyzing the performance of those algorithms. We also demonstrate our framework by applying it to a variety of stochastic combinatorial optimization problems such as matching, matroid, and stable set problems.
We consider a stochastic variant of the packing-type integer linear programming problem, which contains random variables in the objective vector. We are allowed to reveal each entry of the objective vector by conducting a query, and the task is to find a good solution by conducting a small number of queries. We propose a general framework of adaptive and non-adaptive algorithms for this problem, and provide a unified methodology for analyzing the performance of those algorithms. We also demonstrate our framework by applying it to a variety of stochastic combinatorial optimization problems such as matching, matroid, and stable set problems.




 We present a new algorithm which detects the maximal possible number of matched disjoint pairs satisfying a given caliper when a bipartite matching is done with respect to a scalar index (e.g., propensity score), and constructs a corresponding matching. Variable width calipers are compatible with the technique, provided that the width of the caliper is a Lipschitz function of the index. If the observations are ordered with respect to the index then the matching needs $O(N)$ operations, where $N$ is the total number of subjects to be matched. The case of 1-to-$n$ matching is also considered. We offer also a new fast algorithm for optimal complete one-to-one matching on a scalar index when the treatment and control groups are of the same size. This allows us to improve greedy nearest neighbor matching on a scalar index. Keywords: propensity score matching, nearest neighbor matching, matching with caliper, variable width caliper.
We present a new algorithm which detects the maximal possible number of matched disjoint pairs satisfying a given caliper when a bipartite matching is done with respect to a scalar index (e.g., propensity score), and constructs a corresponding matching. Variable width calipers are compatible with the technique, provided that the width of the caliper is a Lipschitz function of the index. If the observations are ordered with respect to the index then the matching needs $O(N)$ operations, where $N$ is the total number of subjects to be matched. The case of 1-to-$n$ matching is also considered. We offer also a new fast algorithm for optimal complete one-to-one matching on a scalar index when the treatment and control groups are of the same size. This allows us to improve greedy nearest neighbor matching on a scalar index. Keywords: propensity score matching, nearest neighbor matching, matching with caliper, variable width caliper.




 Given a Binary Decision Diagram B of a Boolean function \phi in variables, all N many k-ones models of \phi can be enumerated in time polynomial in n and N and |B|. Using novel wildcards enables a compressed enumeration of these models. Simple examples show that the compression can be arbitrarily high.
Given a Binary Decision Diagram B of a Boolean function \phi in variables, all N many k-ones models of \phi can be enumerated in time polynomial in n and N and |B|. Using novel wildcards enables a compressed enumeration of these models. Simple examples show that the compression can be arbitrarily high.




 We introduce a family of multi-way Cheeger-type constants $\{h_k^{\sigma}, k=1,2,\ldots, n\}$ on a signed graph $\Gamma=(G,\sigma)$ such that $h_k^{\sigma}=0$ if and only if $\Gamma$ has $k$ balanced connected components. These constants are switching invariant and bring together in a unified viewpoint a number of important graph-theoretical concepts, including the classical Cheeger constant, those measures of bipartiteness introduced by Desai-Rao, Trevisan, Bauer-Jost, respectively, on unsigned graphs,, and the frustration index (originally called the line index of balance by Harary) on signed graphs. We further unify the (higher-order or improved) Cheeger and dual Cheeger inequalities for unsigned graphs as well as the underlying algorithmic proof techniques by establishing their corresponding versions on signed graphs. In particular, we develop a spectral clustering method for finding $k$ almost-balanced subgraphs, each defining a sparse cut. The proper metric for such a clustering is the metric on a real projective space. We also prove estimates of the extremal eigenvalues of signed Laplace matrix in terms of number of signed triangles ($3$-cycles).
We introduce a family of multi-way Cheeger-type constants $\{h_k^{\sigma}, k=1,2,\ldots, n\}$ on a signed graph $\Gamma=(G,\sigma)$ such that $h_k^{\sigma}=0$ if and only if $\Gamma$ has $k$ balanced connected components. These constants are switching invariant and bring together in a unified viewpoint a number of important graph-theoretical concepts, including the classical Cheeger constant, those measures of bipartiteness introduced by Desai-Rao, Trevisan, Bauer-Jost, respectively, on unsigned graphs,, and the frustration index (originally called the line index of balance by Harary) on signed graphs. We further unify the (higher-order or improved) Cheeger and dual Cheeger inequalities for unsigned graphs as well as the underlying algorithmic proof techniques by establishing their corresponding versions on signed graphs. In particular, we develop a spectral clustering method for finding $k$ almost-balanced subgraphs, each defining a sparse cut. The proper metric for such a clustering is the metric on a real projective space. We also prove estimates of the extremal eigenvalues of signed Laplace matrix in terms of number of signed triangles ($3$-cycles).




 This paper investigates the behavior of the Min-Sum message passing scheme to solve systems of linear equations in the Laplacian matrices of graphs and to compute electric flows. Voltage and flow problems involve the minimization of quadratic functions and are fundamental primitives that arise in several domains. Algorithms that have been proposed are typically centralized and involve multiple graph-theoretic constructions or sampling mechanisms that make them difficult to implement and analyze. On the other hand, message passing routines are distributed, simple, and easy to implement. In this paper we establish a framework to analyze Min-Sum to solve voltage and flow problems. We characterize the error committed by the algorithm on general weighted graphs in terms of hitting times of random walks defined on the computation trees that support the operations of the algorithms with time. For $d$-regular graphs with equal weights, we show that the convergence of the algorithms is controlled by the total variation distance between the distributions of non-backtracking random walks defined on the original graph that start from neighboring nodes. The framework that we introduce extends the analysis of Min-Sum to settings where the contraction arguments previously considered in the literature (based on the assumption of walk summability or scaled diagonal dominance) can not be used, possibly in the presence of constraints.
This paper investigates the behavior of the Min-Sum message passing scheme to solve systems of linear equations in the Laplacian matrices of graphs and to compute electric flows. Voltage and flow problems involve the minimization of quadratic functions and are fundamental primitives that arise in several domains. Algorithms that have been proposed are typically centralized and involve multiple graph-theoretic constructions or sampling mechanisms that make them difficult to implement and analyze. On the other hand, message passing routines are distributed, simple, and easy to implement. In this paper we establish a framework to analyze Min-Sum to solve voltage and flow problems. We characterize the error committed by the algorithm on general weighted graphs in terms of hitting times of random walks defined on the computation trees that support the operations of the algorithms with time. For $d$-regular graphs with equal weights, we show that the convergence of the algorithms is controlled by the total variation distance between the distributions of non-backtracking random walks defined on the original graph that start from neighboring nodes. The framework that we introduce extends the analysis of Min-Sum to settings where the contraction arguments previously considered in the literature (based on the assumption of walk summability or scaled diagonal dominance) can not be used, possibly in the presence of constraints.




 In this work, we study the $k$-median and $k$-means clustering problems when the data is distributed across many servers and can contain outliers. While there has been a lot of work on these problems for worst-case instances, we focus on gaining a finer understanding through the lens of beyond worst-case analysis. Our main motivation is the following: for many applications such as clustering proteins by function or clustering communities in a social network, there is some unknown target clustering, and the hope is that running a $k$-median or $k$-means algorithm will produce clusterings which are close to matching the target clustering. Worst-case results can guarantee constant factor approximations to the optimal $k$-median or $k$-means objective value, but not closeness to the target clustering. Our first result is a distributed algorithm which returns a near-optimal clustering assuming a natural notion of stability, namely, approximation stability [Balcan et. al 2013], even when a constant fraction of the data are outliers. The communication complexity is $\tilde O(sk+z)$ where $s$ is the number of machines, $k$ is the number of clusters, and $z$ is the number of outliers. Next, we show this amount of communication cannot be improved even in the setting when the input satisfies various non-worst-case assumptions. We give a matching $\Omega(sk+z)$ lower bound on the communication required both for approximating the optimal $k$-means or $k$-median cost up to any constant, and for returning a clustering that is close to the target clustering in Hamming distance. These lower bounds hold even when the data satisfies approximation stability or other common notions of stability, and the cluster sizes are balanced. Therefore, $\Omega(sk+z)$ is a communication bottleneck, even for real-world instances.
In this work, we study the $k$-median and $k$-means clustering problems when the data is distributed across many servers and can contain outliers. While there has been a lot of work on these problems for worst-case instances, we focus on gaining a finer understanding through the lens of beyond worst-case analysis. Our main motivation is the following: for many applications such as clustering proteins by function or clustering communities in a social network, there is some unknown target clustering, and the hope is that running a $k$-median or $k$-means algorithm will produce clusterings which are close to matching the target clustering. Worst-case results can guarantee constant factor approximations to the optimal $k$-median or $k$-means objective value, but not closeness to the target clustering. Our first result is a distributed algorithm which returns a near-optimal clustering assuming a natural notion of stability, namely, approximation stability [Balcan et. al 2013], even when a constant fraction of the data are outliers. The communication complexity is $\tilde O(sk+z)$ where $s$ is the number of machines, $k$ is the number of clusters, and $z$ is the number of outliers. Next, we show this amount of communication cannot be improved even in the setting when the input satisfies various non-worst-case assumptions. We give a matching $\Omega(sk+z)$ lower bound on the communication required both for approximating the optimal $k$-means or $k$-median cost up to any constant, and for returning a clustering that is close to the target clustering in Hamming distance. These lower bounds hold even when the data satisfies approximation stability or other common notions of stability, and the cluster sizes are balanced. Therefore, $\Omega(sk+z)$ is a communication bottleneck, even for real-world instances.




 In systems of programmable matter, we are given a collection of simple computation elements (or particles) with limited (constant-size) memory. We are interested in when they can self-organize to solve system-wide problems of movement, configuration and coordination. Here, we initiate a stochastic approach to developing robust distributed algorithms for programmable matter systems using Markov chains. We are able to leverage the wealth of prior work in Markov chains and related areas to design and rigorously analyze our distributed algorithms and show that they have several desirable properties. We study the compression problem, in which a particle system must gather as tightly together as possible, as in a sphere or its equivalent in the presence of some underlying geometry. More specifically, we seek fully distributed, local, and asynchronous algorithms that lead the system to converge to a configuration with small boundary. We present a Markov chain-based algorithm that solves the compression problem under the geometric amoebot model, for particle systems that begin in a connected configuration. The algorithm takes as input a bias parameter $\lambda$, where $\lambda > 1$ corresponds to particles favoring having more neighbors. We show that for all $\lambda > 2+\sqrt{2}$, there is a constant $\alpha > 1$ such that eventually with all but exponentially small probability the particles are $\alpha$-compressed, meaning the perimeter of the system configuration is at most $\alpha \cdot p_{min}$, where $p_{min}$ is the minimum possible perimeter of the particle system. Surprisingly, the same algorithm can also be used for expansion when $0 < \lambda < 2.17$, and we prove similar results about expansion for values of $\lambda$ in this range. This is counterintuitive as it shows that particles preferring to be next to each other ($\lambda > 1$) is not sufficient to guarantee compression.
In systems of programmable matter, we are given a collection of simple computation elements (or particles) with limited (constant-size) memory. We are interested in when they can self-organize to solve system-wide problems of movement, configuration and coordination. Here, we initiate a stochastic approach to developing robust distributed algorithms for programmable matter systems using Markov chains. We are able to leverage the wealth of prior work in Markov chains and related areas to design and rigorously analyze our distributed algorithms and show that they have several desirable properties. We study the compression problem, in which a particle system must gather as tightly together as possible, as in a sphere or its equivalent in the presence of some underlying geometry. More specifically, we seek fully distributed, local, and asynchronous algorithms that lead the system to converge to a configuration with small boundary. We present a Markov chain-based algorithm that solves the compression problem under the geometric amoebot model, for particle systems that begin in a connected configuration. The algorithm takes as input a bias parameter $\lambda$, where $\lambda > 1$ corresponds to particles favoring having more neighbors. We show that for all $\lambda > 2+\sqrt{2}$, there is a constant $\alpha > 1$ such that eventually with all but exponentially small probability the particles are $\alpha$-compressed, meaning the perimeter of the system configuration is at most $\alpha \cdot p_{min}$, where $p_{min}$ is the minimum possible perimeter of the particle system. Surprisingly, the same algorithm can also be used for expansion when $0 < \lambda < 2.17$, and we prove similar results about expansion for values of $\lambda$ in this range. This is counterintuitive as it shows that particles preferring to be next to each other ($\lambda > 1$) is not sufficient to guarantee compression.




 We provide simple and approximately revenue-optimal mechanisms in the multi-item multi-bidder settings. We unify and improve all previous results, as well as generalize the results to broader cases. In particular, we prove that the better of the following two simple, deterministic and Dominant Strategy Incentive Compatible mechanisms, a sequential posted price mechanism or an anonymous sequential posted price mechanism with entry fee, achieves a constant fraction of the optimal revenue among all randomized, Bayesian Incentive Compatible mechanisms, when buyers' valuations are XOS over independent items. If the buyers' valuations are subadditive over independent items, the approximation factor degrades to $O(\log m)$, where $m$ is the number of items. We obtain our results by first extending the Cai-Devanur-Weinberg duality framework to derive an effective benchmark of the optimal revenue for subadditive bidders, and then analyzing this upper bound with new techniques.
We provide simple and approximately revenue-optimal mechanisms in the multi-item multi-bidder settings. We unify and improve all previous results, as well as generalize the results to broader cases. In particular, we prove that the better of the following two simple, deterministic and Dominant Strategy Incentive Compatible mechanisms, a sequential posted price mechanism or an anonymous sequential posted price mechanism with entry fee, achieves a constant fraction of the optimal revenue among all randomized, Bayesian Incentive Compatible mechanisms, when buyers' valuations are XOS over independent items. If the buyers' valuations are subadditive over independent items, the approximation factor degrades to $O(\log m)$, where $m$ is the number of items. We obtain our results by first extending the Cai-Devanur-Weinberg duality framework to derive an effective benchmark of the optimal revenue for subadditive bidders, and then analyzing this upper bound with new techniques.




 Web-based services often run randomized experiments to improve their products. A popular way to run these experiments is to use geographical regions as units of experimentation, since this does not require tracking of individual users or browser cookies. Since users may issue queries from multiple geographical locations, geo-regions cannot be considered independent and interference may be present in the experiment. In this paper, we study this problem, and first present GeoCUTS, a novel algorithm that forms geographical clusters to minimize interference while preserving balance in cluster size. We use a random sample of anonymized traffic from Google Search to form a graph representing user movements, then construct a geographically coherent clustering of the graph. Our main technical contribution is a statistical framework to measure the effectiveness of clusterings. Furthermore, we perform empirical evaluations showing that the performance of GeoCUTS is comparable to hand-crafted geo-regions with respect to both novel and existing metrics.
Web-based services often run randomized experiments to improve their products. A popular way to run these experiments is to use geographical regions as units of experimentation, since this does not require tracking of individual users or browser cookies. Since users may issue queries from multiple geographical locations, geo-regions cannot be considered independent and interference may be present in the experiment. In this paper, we study this problem, and first present GeoCUTS, a novel algorithm that forms geographical clusters to minimize interference while preserving balance in cluster size. We use a random sample of anonymized traffic from Google Search to form a graph representing user movements, then construct a geographically coherent clustering of the graph. Our main technical contribution is a statistical framework to measure the effectiveness of clusterings. Furthermore, we perform empirical evaluations showing that the performance of GeoCUTS is comparable to hand-crafted geo-regions with respect to both novel and existing metrics.




 The main purpose of this paper is pedagogical. Despite its importance, all proofs of the correctness of Strassen's famous 1969 algorithm to multiply two 2x2 matrices with only seven multiplications involve some basis-dependent calculations such as explicitly multiplying specific 2x2 matrices, expanding expressions to cancel terms with opposing signs, or expanding tensors over the standard basis. This makes the proof nontrivial to memorize and many presentations of the proof avoid showing all the details and leave a significant amount of verifications to the reader. In this note we give a short, self-contained, basis-independent proof of the existence of Strassen's algorithm that avoids these types of calculations. We achieve this by focusing on symmetries and algebraic properties. Our proof can be seen as a coordinate-free version of the construction of Clausen from 1988, combined with recent work on the geometry of Strassen's algorithm by Chiantini, Ikenmeyer, Landsberg, and Ottaviani from 2016.
The main purpose of this paper is pedagogical. Despite its importance, all proofs of the correctness of Strassen's famous 1969 algorithm to multiply two 2x2 matrices with only seven multiplications involve some basis-dependent calculations such as explicitly multiplying specific 2x2 matrices, expanding expressions to cancel terms with opposing signs, or expanding tensors over the standard basis. This makes the proof nontrivial to memorize and many presentations of the proof avoid showing all the details and leave a significant amount of verifications to the reader. In this note we give a short, self-contained, basis-independent proof of the existence of Strassen's algorithm that avoids these types of calculations. We achieve this by focusing on symmetries and algebraic properties. Our proof can be seen as a coordinate-free version of the construction of Clausen from 1988, combined with recent work on the geometry of Strassen's algorithm by Chiantini, Ikenmeyer, Landsberg, and Ottaviani from 2016.




 Compression and sparsification algorithms are frequently applied in a preprocessing step before analyzing or optimizing large networks/graphs. In this paper we propose and study a new framework contracting edges of a graph (merging vertices into super-vertices) with the goal of preserving pairwise distances as accurately as possible. Formally, given an edge-weighted graph, the contraction should guarantee that for any two vertices at distance $d$, the corresponding super-vertices remain at distance at least $\varphi(d)$ in the contracted graph, where $\varphi$ is a tolerance function bounding the permitted distance distortion. We present a comprehensive picture of the algorithmic complexity of the contraction problem for affine tolerance functions $\varphi(x)=x/\alpha-\beta$, where $\alpha\geq 1$ and $\beta\geq 0$ are arbitrary real-valued parameters. Specifically, we present polynomial-time algorithms for trees as well as hardness and inapproximability results for different graph classes, precisely separating easy and hard cases. Further we analyze the asymptotic behavior of contractions, and find efficient algorithms to compute (non-optimal) contractions despite our hardness results.
Compression and sparsification algorithms are frequently applied in a preprocessing step before analyzing or optimizing large networks/graphs. In this paper we propose and study a new framework contracting edges of a graph (merging vertices into super-vertices) with the goal of preserving pairwise distances as accurately as possible. Formally, given an edge-weighted graph, the contraction should guarantee that for any two vertices at distance $d$, the corresponding super-vertices remain at distance at least $\varphi(d)$ in the contracted graph, where $\varphi$ is a tolerance function bounding the permitted distance distortion. We present a comprehensive picture of the algorithmic complexity of the contraction problem for affine tolerance functions $\varphi(x)=x/\alpha-\beta$, where $\alpha\geq 1$ and $\beta\geq 0$ are arbitrary real-valued parameters. Specifically, we present polynomial-time algorithms for trees as well as hardness and inapproximability results for different graph classes, precisely separating easy and hard cases. Further we analyze the asymptotic behavior of contractions, and find efficient algorithms to compute (non-optimal) contractions despite our hardness results.




 We present an O(n^6 ) linear programming model for the traveling salesman (TSP) and quadratic assignment (QAP) problems. The basic model is developed within the framework of the TSP. It does not involve the city-to-city variables-based, traditional TSP polytope referred to in the literature as "the TSP polytope." We do not model explicit Hamiltonian cycles of the cities. Instead, we use a time-dependent abstraction of TSP tours and develop a direct extended formulation of the linear assignment problem (LAP) polytope. The model is exact in the sense that it has integral extreme points which are in one-to-one correspondence with TSP tours. It can be solved optimally using any linear programming (LP) solver, hence offering a new (incidental) proof of the equality of the computational complexity classes "P" and "NP." The extensions of the model to the time-dependent traveling salesman problem (TDTSP) as well as the quadratic assignment problem (QAP) are straightforward. The reasons for the non-applicability of existing negative extended formulations results for "the TSP polytope" to the model in this paper as well as our software implementation and the computational experimentation we conducted are briefly discussed.
We present an O(n^6 ) linear programming model for the traveling salesman (TSP) and quadratic assignment (QAP) problems. The basic model is developed within the framework of the TSP. It does not involve the city-to-city variables-based, traditional TSP polytope referred to in the literature as "the TSP polytope." We do not model explicit Hamiltonian cycles of the cities. Instead, we use a time-dependent abstraction of TSP tours and develop a direct extended formulation of the linear assignment problem (LAP) polytope. The model is exact in the sense that it has integral extreme points which are in one-to-one correspondence with TSP tours. It can be solved optimally using any linear programming (LP) solver, hence offering a new (incidental) proof of the equality of the computational complexity classes "P" and "NP." The extensions of the model to the time-dependent traveling salesman problem (TDTSP) as well as the quadratic assignment problem (QAP) are straightforward. The reasons for the non-applicability of existing negative extended formulations results for "the TSP polytope" to the model in this paper as well as our software implementation and the computational experimentation we conducted are briefly discussed.