-
We describe a modular rewriting system for translating optimization problems
written in a domain-specific language to forms compatible with low-level solver
interfaces. Translation is facilitated by reductions, which accept a category
of problems and transform instances of that category to equivalent instances of
another category. Our system proceeds in two key phases: analysis, in which we
attempt to find a suitable solver for a supplied problem, and canonicalization,
in which we rewrite the problem in the selected solver's standard form. We
implement the described system in version 1.0 of CVXPY, a domain-specific
language for mathematical and especially convex optimization. By treating
reductions as first-class objects, our method makes it easy to match problems
to solvers well-suited for them and to support solvers with a wide variety of
standard forms.
-
Software for mixed-integer linear programming can return incorrect results
for a number of reasons, one being the use of inexact floating-point
arithmetic. Even solvers that employ exact arithmetic may suffer from
programming or algorithmic errors, motivating the desire for a way to produce
independently verifiable certificates of claimed results. Due to the complex
nature of state-of-the-art MILP solution algorithms, the ideal form of such a
certificate is not entirely clear. This paper proposes such a certificate
format, illustrating its capabilities and structure through examples. The
certificate format is designed with simplicity in mind and is composed of a
list of statements that can be sequentially verified using a limited number of
simple yet powerful inference rules. We present a supplementary verification
tool for compressing and checking these certificates independently of how they
were created. We report computational results on a selection of mixed-integer
linear programming instances from the literature. To this end, we have extended
the exact rational version of the MIP solver SCIP to produce such certificates.
-
This paper summarizes the development of Veamy, an object-oriented C++
library for the virtual element method (VEM) on general polygonal meshes, whose
modular design is focused on its extensibility. The linear elastostatic and
Poisson problems in two dimensions have been chosen as the starting stage for
the development of this library. The theory of the VEM, upon which Veamy is
built, is presented using a notation and a terminology that resemble the
language of the finite element method (FEM) in engineering analysis. Several
examples are provided to demonstrate the usage of Veamy, and in particular, one
of them features the interaction between Veamy and the polygonal mesh generator
PolyMesher. A computational performance comparison between VEM and FEM is also
conducted. Veamy is free and open source software.
-
Classical simulation of quantum computation is necessary for studying the
numerical behavior of quantum algorithms, as there does not yet exist a large
viable quantum computer on which to perform numerical tests. Tensor network
(TN) contraction is an algorithmic method that can efficiently simulate some
quantum circuits, often greatly reducing the computational cost over methods
that simulate the full Hilbert space. In this study we implement a tensor
network contraction program for simulating quantum circuits using multi-core
compute nodes. We show simulation results for the Max-Cut problem on 3- through
7-regular graphs using the quantum approximate optimization algorithm (QAOA),
successfully simulating up to 100 qubits. We test two different methods for
generating the ordering of tensor index contractions: one is based on the tree
decomposition of the line graph, while the other generates ordering using a
straight-forward stochastic scheme. Through studying instances of QAOA
circuits, we show the expected result that as the treewidth of the quantum
circuit's line graph decreases, TN contraction becomes significantly more
efficient than simulating the whole Hilbert space. The results in this work
suggest that tensor contraction methods are superior only when simulating
Max-Cut/QAOA with graphs of regularities approximately five and below. Insight
into this point of equal computational cost helps one determine which
simulation method will be more efficient for a given quantum circuit. The
stochastic contraction method outperforms the line graph based method only when
the time to calculate a reasonable tree decomposition is prohibitively
expensive. Finally, we release our software package, qTorch (Quantum TensOR
Contraction Handler), intended for general quantum circuit simulation.
-
We present a full implementation of the parareal algorithm---an integration
technique to solve differential equations in parallel---in the Julia
programming language for a fully general, first-order, initial-value problem.
We provide a brief overview of Julia---a concurrent programming language for
scientific computing. Our implementation of the parareal algorithm accepts both
coarse and fine integrators as functional arguments. We use Euler's method and
another Runge-Kutta integration technique as the integrators in our
experiments. We also present a simulation of the algorithm for purposes of
pedagogy and as a tool for investigating the performance of the algorithm.
-
scikit-multilearn is a Python library for performing multi-label
classification. The library is compatible with the scikit/scipy ecosystem and
uses sparse matrices for all internal operations. It provides native Python
implementations of popular multi-label classification methods alongside a novel
framework for label space partitioning and division. It includes modern
algorithm adaptation methods, network-based label space division approaches,
which extracts label dependency information and multi-label embedding
classifiers. It provides python wrapped access to the extensive multi-label
method stack from Java libraries and makes it possible to extend deep learning
single-label methods for multi-label tasks. The library allows multi-label
stratification and data set management. The implementation is more efficient in
problem transformation than other established libraries, has good test coverage
and follows PEP8. Source code and documentation can be downloaded from
http://scikit.ml and also via pip. The library follows BSD licensing scheme.
-
We discuss the design decisions, design alternatives and rationale behind the
third generation of Peano, a framework for dynamically adaptive Cartesian
meshes derived from spacetrees. Peano ties the mesh traversal to the mesh
storage and supports only one element-wise traversal order resulting from
space-filling curves. The user is not free to choose a traversal order herself.
The traversal can exploit regular grid subregions and shared memory as well as
distributed memory systems with almost no modifications to a serial application
code. We formalize the software design by means of two interacting
automata---one automaton for the multiscale grid traversal and one for the
application-specific algorithmic steps. This yields a callback-based
programming paradigm. We further sketch the supported application types and the
two data storage schemes realized, before we detail high-performance computing
aspects and lessons learned. Special emphasis is put on observations regarding
the used programming idioms and algorithmic concepts. This transforms our
report from a "one way to implement things" code description into a generic
discussion and summary of some alternatives, rationale and design decisions to
be made for any tree-based adaptive mesh refinement software.
-
Numerical accuracy of floating point computation is a well studied topic
which has not made its way to the end-user in scientific computing. Yet, it has
become a critical issue with the recent requirements for code modernization to
harness new highly parallel hardware and perform higher resolution computation.
To democratize numerical accuracy analysis, it is important to propose tools
and methodologies to study large use cases in a reliable and automatic way. In
this paper, we propose verificarlo, an extension to the LLVM compiler to
automatically use Monte Carlo Arithmetic in a transparent way for the end-user.
It supports all the major languages including C, C++, and Fortran. Unlike
source-to-source approaches, our implementation captures the influence of
compiler optimizations on the numerical accuracy. We illustrate how Monte Carlo
Arithmetic using the verificarlo tool outperforms the existing approaches on
various use cases and is a step toward automatic numerical analysis.
-
The \texttt{StronglyStableIdeals} package for \textit{Macaulay2} provides a
method to compute all saturated strongly stable ideals in a given polynomial
ring with a fixed Hilbert polynomial. A description of the main method and
auxiliary tools is given.
-
The paper proposes a combination of the subdomain deflation method and local
algebraic multigrid as a scalable distributed memory preconditioner that is
able to solve large linear systems of equations. The implementation of the
algorithm is made available for the community as part of an open source AMGCL
library. The solution targets both homogeneous (CPU-only) and heterogeneous
(CPU/GPU) systems, employing hybrid MPI/OpenMP approach in the former and a
combination of MPI, OpenMP, and CUDA in the latter cases. The use of OpenMP
minimizes the number of MPI processes, thus reducing the communication overhead
of the deflation method and improving both weak and strong scalability of the
preconditioner. The examples of scalar, Poisson-like, systems as well as
non-scalar problems, stemming out of the discretization of the Navier-Stokes
equations, are considered in order to estimate performance of the implemented
algorithm. A comparison with a traditional global AMG preconditioner based on a
well-established Trilinos ML package is provided.
-
We propose a platform-independent multi-threaded function library that
provides data structures to generate, differentiate and render both the
ordinary basis and the normalized B-basis of a user-specified extended
Chebyshev (EC) space that comprises the constants and can be identified with
the solution space of a constant-coefficient homogeneous linear differential
equation defined on a sufficiently small interval. Using the obtained
normalized B-bases, our library can also generate, (partially) differentiate,
modify and visualize a large family of so-called B-curves and tensor product
B-surfaces. Moreover, the library also implements methods that can be used to
perform dimension elevation, to subdivide B-curves and B-surfaces by means of
de Casteljau-like B-algorithms, and to generate basis transformations for the
B-representation of arbitrary integral curves and surfaces that are described
in traditional parametric form by means of the ordinary bases of the underlying
EC spaces. Independently of the algebraic, exponential, trigonometric or mixed
type of the applied EC space, the proposed library is numerically stable and
efficient up to a reasonable dimension number and may be useful for academics
and engineers in the fields of Approximation Theory, Computer Aided Geometric
Design, Computer Graphics, Isogeometric and Numerical Analysis.
-
The R package frailtySurv for simulating and fitting semi-parametric shared
frailty models is introduced. Package frailtySurv implements semi-parametric
consistent estimators for a variety of frailty distributions, including gamma,
log-normal, inverse Gaussian and power variance function, and provides
consistent estimators of the standard errors of the parameters' estimators. The
parameters' estimators are asymptotically normally distributed, and therefore
statistical inference based on the results of this package, such as hypothesis
testing and confidence intervals, can be performed using the normal
distribution. Extensive simulations demonstrate the flexibility and correct
implementation of the estimator. Two case studies performed with publicly
available datasets demonstrate applicability of the package. In the Diabetic
Retinopathy Study, the onset of blindness is clustered by patient, and in a
large hard drive failure dataset, failure times are thought to be clustered by
the hard drive manufacturer and model.
-
We present a proof of concept for solving a 1+1D complex-valued, delay
partial differential equation (PDE) that emerges in the study of waveguide
quantum electrodynamics (QED) by adapting the finite-difference time-domain
(FDTD) method. The delay term is spatially non-local, rendering conventional
approaches such as the method of lines inapplicable. We show that by properly
designing the grid and by supplying the (partial) exact solution as the
boundary condition, the delay PDE can be numerically solved. In addition, we
demonstrate that while the delay imposes strong data dependency, multi-thread
parallelization can nevertheless be applied to such a problem. Our code
provides a numerically exact solution to the time-dependent multi-photon
scattering problem in waveguide QED.
-
Owl is a new numerical library developed in the OCaml language. It focuses on
providing a comprehensive set of high-level numerical functions so that
developers can quickly build up data analytical applications. In this abstract,
we will present Owl's design, core components, and its key functionality.
-
We propose to consider ensembles of cycles (quadrics), which are
interconnected through conformal-invariant geometric relations (e.g. "to be
orthogonal", "to be tangent", etc.), as new objects in an extended Moebius--Lie
geometry. It was recently demonstrated in several related papers, that such
ensembles of cycles naturally parameterise many other conformally-invariant
objects, e.g. loxodromes or continued fractions. The paper describes a method,
which reduces a collection of conformally invariant geometric relations to a
system of linear equations, which may be accompanied by one fixed quadratic
relation.
To show its usefulness, the method is implemented as a C++ library. It
operates with numeric and symbolic data of cycles in spaces of arbitrary
dimensionality and metrics with any signatures. Numeric calculations can be
done in exact or approximate arithmetic. In the two- and three-dimensional
cases illustrations and animations can be produced. An interactive Python
wrapper of the library is provided as well.
-
Engine for Likelihood-Free Inference (ELFI) is a Python software library for
performing likelihood-free inference (LFI). ELFI provides a convenient syntax
for arranging components in LFI, such as priors, simulators, summaries or
distances, to a network called ELFI graph. The components can be implemented in
a wide variety of languages. The stand-alone ELFI graph can be used with any of
the available inference methods without modifications. A central method
implemented in ELFI is Bayesian Optimization for Likelihood-Free Inference
(BOLFI), which has recently been shown to accelerate likelihood-free inference
up to several orders of magnitude by surrogate-modelling the distance. ELFI
also has an inbuilt support for output data storing for reuse and analysis, and
supports parallelization of computation from multiple cores up to a cluster
environment. ELFI is designed to be extensible and provides interfaces for
widening its functionality. This makes the adding of new inference methods to
ELFI straightforward and automatically compatible with the inbuilt features.
-
A flexible and highly-extensible data assimilation testing suite, named
DATeS, is described in this paper. DATeS aims to offer a unified testing
environment that allows researchers to compare different data assimilation
methodologies and understand their performance in various settings. The core of
DATeS is implemented in Python and takes advantage of its object-oriented
capabilities. The main components of the package (the numerical models, the
data assimilation algorithms, the linear algebra solvers, and the time
discretization routines) are independent of each other, which offers great
flexibility to configure data assimilation applications. DATeS can interface
easily with large third-party numerical models written in Fortran or in C, and
with a plethora of external solvers.
-
Web developers use base64 formats to include images, fonts, sounds and other
resources directly inside HTML, JavaScript, JSON and XML files. We estimate
that billions of base64 messages are decoded every day. We are motivated to
improve the efficiency of base64 encoding and decoding. Compared to
state-of-the-art implementations, we multiply the speeds of both the encoding
(~10x) and the decoding (~7x). We achieve these good results by using the
single-instruction-multiple-data (SIMD) instructions available on recent Intel
processors (AVX2). Our accelerated software abides by the specification and
reports errors when encountering characters outside of the base64 set. It is
available online as free software under a liberal license.
-
Scikit-learn is a Python module integrating a wide range of state-of-the-art
machine learning algorithms for medium-scale supervised and unsupervised
problems. This package focuses on bringing machine learning to non-specialists
using a general-purpose high-level language. Emphasis is put on ease of use,
performance, documentation, and API consistency. It has minimal dependencies
and is distributed under the simplified BSD license, encouraging its use in
both academic and commercial settings. Source code, binaries, and documentation
can be downloaded from http://scikit-learn.org.
-
System Gramian matrices are a well-known encoding for properties of
input-output systems such as controllability, observability or minimality.
These so-called system Gramians were developed in linear system theory for
applications such as model order reduction of control systems. Empirical
Gramian are an extension to the system Gramians for parametric and nonlinear
systems as well as a data-driven method of computation. The empirical Gramian
framework - emgr - implements the empirical Gramians in a uniform and
configurable manner, with applications such as Gramian-based (nonlinear) model
reduction, decentralized control, sensitivity analysis, parameter
identification and combined state and parameter reduction.
-
A numerical method of solving the problem of acoustic wave radiation in the
presence of a rigid scatterer is described. It combines the finite element
method and the boundary algebraic equations. In the proposed method, the
exterior domain around the scatterer is discretized, so that there appear an
infinite domain with regular discretization and a relatively small layer with
irregular mesh. For the infinite regular mesh, the boundary algebraic equation
method is used with spurious resonance suppression according to Burton and
Miller. In the thin layer with irregular mesh, the finite element method is
used. The proposed method is characterized by simple implementation, fair
accuracy, and absence of spurious resonances.
-
Forward Automatic Differentiation (AD) is a technique for augmenting programs
to compute derivatives. The essence of Forward AD is to attach perturbations to
each number, and propagate these through the computation. When derivatives are
nested, the distinct derivative calculations, and their associated
perturbations, must be distinguished. This is typically accomplished by
creating a unique tag for each derivative calculation, tagging the
perturbations, and overloading the arithmetic operators. We exhibit a subtle
bug, present in fielded implementations, in which perturbations are confused
despite the tagging machinery. The essence of the bug is this: each invocation
of a derivative creates a unique tag but a unique tag is needed for each
derivative calculation. When taking derivatives of higher-order functions,
these need not correspond! The derivative of a higher-order function $f$ that
returns a function $g$ will be a function $f'$ that returns a function
$\bar{g}$ that performs a derivative calculation. A single invocation of $f'$
will create a single fresh tag but that same tag will be used for each
derivative calculation resulting from an invocation of $\bar{g}$. This
situation arises when taking derivatives of curried functions. Two potential
solutions are presented, and their serious deficiencies discussed. One requires
eta expansion to delay the creation of fresh tags from the invocation of $f'$
to the invocation of $\bar{g}$, which can be difficult or even impossible in
some circumstances. The other requires $f'$ to wrap $\bar{g}$ with tag
renaming, which is difficult to implement without violating the desirable
complexity properties of forward AD.
-
We study algorithms for the fast computation of modular inverses.
Newton-Raphson iteration over $p$-adic numbers gives a recurrence relation
computing modular inverse modulo $p^m$, that is logarithmic in $m$. We solve
the recurrence to obtain an explicit formula for the inverse. Then we study
different implementation variants of this iteration and show that our explicit
formula is interesting for small exponent values but slower or large exponent,
say of more than $700$ bits. Overall we thus propose a hybrid combination of
our explicit formula and the best asymptotic variants. This hybrid combination
yields then a constant factor improvement, also for large exponents.
-
The sparse matrix-vector product (SpMV) is a fundamental operation in many
scientific applications from various fields. The High Performance Computing
(HPC) community has therefore continuously invested a lot of effort to provide
an efficient SpMV kernel on modern CPU architectures. Although it has been
shown that block-based kernels help to achieve high performance, they are
difficult to use in practice because of the zero padding they require. In the
current paper, we propose new kernels using the AVX-512 instruction set, which
makes it possible to use a blocking scheme without any zero padding in the
matrix memory storage. We describe mask-based sparse matrix formats and their
corresponding SpMV kernels highly optimized in assembly language. Considering
that the optimal blocking size depends on the matrix, we also provide a method
to predict the best kernel to be used utilizing a simple interpolation of
results from previous executions. We compare the performance of our approach to
that of the Intel MKL CSR kernel and the CSR5 open-source package on a set of
standard benchmark matrices. We show that we can achieve significant
improvements in many cases, both for sequential and for parallel executions.
Finally, we provide the corresponding code in an open source library, called
SPC5.
-
When implementing functionality which requires sparse matrices, there are
numerous storage formats to choose from, each with advantages and
disadvantages. To achieve good performance, several formats may need to be used
in one program, requiring explicit selection and conversion between the
formats. This can be both tedious and error-prone, especially for non-expert
users. Motivated by this issue, we present a user-friendly sparse matrix class
for the C++ language, with a high-level application programming interface
deliberately similar to the widely used MATLAB language. The class internally
uses two main approaches to achieve efficient execution: (i) a hybrid storage
framework, which automatically and seamlessly switches between three underlying
storage formats (compressed sparse column, coordinate list, Red-Black tree)
depending on which format is best suited for specific operations, and (ii)
template-based meta-programming to automatically detect and optimise execution
of common expression patterns. To facilitate relatively quick conversion of
research code into production environments, the class and its associated
functions provide a suite of essential sparse linear algebra functionality
(eg., arithmetic operations, submatrix manipulation) as well as high-level
functions for sparse eigendecompositions and linear equation solvers. The
latter are achieved by providing easy-to-use abstractions of the low-level
ARPACK and SuperLU libraries. The source code is open and provided under the
permissive Apache 2.0 license, allowing unencumbered use in commercial
products.





 Software for mixed-integer linear programming can return incorrect results for a number of reasons, one being the use of inexact floating-point arithmetic. Even solvers that employ exact arithmetic may suffer from programming or algorithmic errors, motivating the desire for a way to produce independently verifiable certificates of claimed results. Due to the complex nature of state-of-the-art MILP solution algorithms, the ideal form of such a certificate is not entirely clear. This paper proposes such a certificate format, illustrating its capabilities and structure through examples. The certificate format is designed with simplicity in mind and is composed of a list of statements that can be sequentially verified using a limited number of simple yet powerful inference rules. We present a supplementary verification tool for compressing and checking these certificates independently of how they were created. We report computational results on a selection of mixed-integer linear programming instances from the literature. To this end, we have extended the exact rational version of the MIP solver SCIP to produce such certificates.
Software for mixed-integer linear programming can return incorrect results for a number of reasons, one being the use of inexact floating-point arithmetic. Even solvers that employ exact arithmetic may suffer from programming or algorithmic errors, motivating the desire for a way to produce independently verifiable certificates of claimed results. Due to the complex nature of state-of-the-art MILP solution algorithms, the ideal form of such a certificate is not entirely clear. This paper proposes such a certificate format, illustrating its capabilities and structure through examples. The certificate format is designed with simplicity in mind and is composed of a list of statements that can be sequentially verified using a limited number of simple yet powerful inference rules. We present a supplementary verification tool for compressing and checking these certificates independently of how they were created. We report computational results on a selection of mixed-integer linear programming instances from the literature. To this end, we have extended the exact rational version of the MIP solver SCIP to produce such certificates.




 This paper summarizes the development of Veamy, an object-oriented C++ library for the virtual element method (VEM) on general polygonal meshes, whose modular design is focused on its extensibility. The linear elastostatic and Poisson problems in two dimensions have been chosen as the starting stage for the development of this library. The theory of the VEM, upon which Veamy is built, is presented using a notation and a terminology that resemble the language of the finite element method (FEM) in engineering analysis. Several examples are provided to demonstrate the usage of Veamy, and in particular, one of them features the interaction between Veamy and the polygonal mesh generator PolyMesher. A computational performance comparison between VEM and FEM is also conducted. Veamy is free and open source software.
This paper summarizes the development of Veamy, an object-oriented C++ library for the virtual element method (VEM) on general polygonal meshes, whose modular design is focused on its extensibility. The linear elastostatic and Poisson problems in two dimensions have been chosen as the starting stage for the development of this library. The theory of the VEM, upon which Veamy is built, is presented using a notation and a terminology that resemble the language of the finite element method (FEM) in engineering analysis. Several examples are provided to demonstrate the usage of Veamy, and in particular, one of them features the interaction between Veamy and the polygonal mesh generator PolyMesher. A computational performance comparison between VEM and FEM is also conducted. Veamy is free and open source software.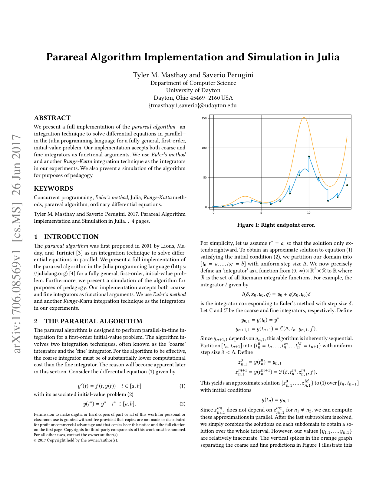

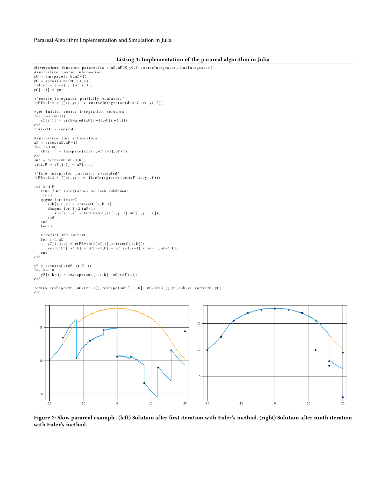


 We present a full implementation of the parareal algorithm---an integration technique to solve differential equations in parallel---in the Julia programming language for a fully general, first-order, initial-value problem. We provide a brief overview of Julia---a concurrent programming language for scientific computing. Our implementation of the parareal algorithm accepts both coarse and fine integrators as functional arguments. We use Euler's method and another Runge-Kutta integration technique as the integrators in our experiments. We also present a simulation of the algorithm for purposes of pedagogy and as a tool for investigating the performance of the algorithm.
We present a full implementation of the parareal algorithm---an integration technique to solve differential equations in parallel---in the Julia programming language for a fully general, first-order, initial-value problem. We provide a brief overview of Julia---a concurrent programming language for scientific computing. Our implementation of the parareal algorithm accepts both coarse and fine integrators as functional arguments. We use Euler's method and another Runge-Kutta integration technique as the integrators in our experiments. We also present a simulation of the algorithm for purposes of pedagogy and as a tool for investigating the performance of the algorithm.




 scikit-multilearn is a Python library for performing multi-label classification. The library is compatible with the scikit/scipy ecosystem and uses sparse matrices for all internal operations. It provides native Python implementations of popular multi-label classification methods alongside a novel framework for label space partitioning and division. It includes modern algorithm adaptation methods, network-based label space division approaches, which extracts label dependency information and multi-label embedding classifiers. It provides python wrapped access to the extensive multi-label method stack from Java libraries and makes it possible to extend deep learning single-label methods for multi-label tasks. The library allows multi-label stratification and data set management. The implementation is more efficient in problem transformation than other established libraries, has good test coverage and follows PEP8. Source code and documentation can be downloaded from http://scikit.ml and also via pip. The library follows BSD licensing scheme.
scikit-multilearn is a Python library for performing multi-label classification. The library is compatible with the scikit/scipy ecosystem and uses sparse matrices for all internal operations. It provides native Python implementations of popular multi-label classification methods alongside a novel framework for label space partitioning and division. It includes modern algorithm adaptation methods, network-based label space division approaches, which extracts label dependency information and multi-label embedding classifiers. It provides python wrapped access to the extensive multi-label method stack from Java libraries and makes it possible to extend deep learning single-label methods for multi-label tasks. The library allows multi-label stratification and data set management. The implementation is more efficient in problem transformation than other established libraries, has good test coverage and follows PEP8. Source code and documentation can be downloaded from http://scikit.ml and also via pip. The library follows BSD licensing scheme.




 We discuss the design decisions, design alternatives and rationale behind the third generation of Peano, a framework for dynamically adaptive Cartesian meshes derived from spacetrees. Peano ties the mesh traversal to the mesh storage and supports only one element-wise traversal order resulting from space-filling curves. The user is not free to choose a traversal order herself. The traversal can exploit regular grid subregions and shared memory as well as distributed memory systems with almost no modifications to a serial application code. We formalize the software design by means of two interacting automata---one automaton for the multiscale grid traversal and one for the application-specific algorithmic steps. This yields a callback-based programming paradigm. We further sketch the supported application types and the two data storage schemes realized, before we detail high-performance computing aspects and lessons learned. Special emphasis is put on observations regarding the used programming idioms and algorithmic concepts. This transforms our report from a "one way to implement things" code description into a generic discussion and summary of some alternatives, rationale and design decisions to be made for any tree-based adaptive mesh refinement software.
We discuss the design decisions, design alternatives and rationale behind the third generation of Peano, a framework for dynamically adaptive Cartesian meshes derived from spacetrees. Peano ties the mesh traversal to the mesh storage and supports only one element-wise traversal order resulting from space-filling curves. The user is not free to choose a traversal order herself. The traversal can exploit regular grid subregions and shared memory as well as distributed memory systems with almost no modifications to a serial application code. We formalize the software design by means of two interacting automata---one automaton for the multiscale grid traversal and one for the application-specific algorithmic steps. This yields a callback-based programming paradigm. We further sketch the supported application types and the two data storage schemes realized, before we detail high-performance computing aspects and lessons learned. Special emphasis is put on observations regarding the used programming idioms and algorithmic concepts. This transforms our report from a "one way to implement things" code description into a generic discussion and summary of some alternatives, rationale and design decisions to be made for any tree-based adaptive mesh refinement software.


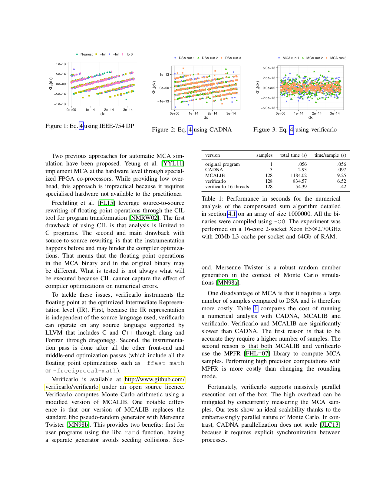

 Numerical accuracy of floating point computation is a well studied topic which has not made its way to the end-user in scientific computing. Yet, it has become a critical issue with the recent requirements for code modernization to harness new highly parallel hardware and perform higher resolution computation. To democratize numerical accuracy analysis, it is important to propose tools and methodologies to study large use cases in a reliable and automatic way. In this paper, we propose verificarlo, an extension to the LLVM compiler to automatically use Monte Carlo Arithmetic in a transparent way for the end-user. It supports all the major languages including C, C++, and Fortran. Unlike source-to-source approaches, our implementation captures the influence of compiler optimizations on the numerical accuracy. We illustrate how Monte Carlo Arithmetic using the verificarlo tool outperforms the existing approaches on various use cases and is a step toward automatic numerical analysis.
Numerical accuracy of floating point computation is a well studied topic which has not made its way to the end-user in scientific computing. Yet, it has become a critical issue with the recent requirements for code modernization to harness new highly parallel hardware and perform higher resolution computation. To democratize numerical accuracy analysis, it is important to propose tools and methodologies to study large use cases in a reliable and automatic way. In this paper, we propose verificarlo, an extension to the LLVM compiler to automatically use Monte Carlo Arithmetic in a transparent way for the end-user. It supports all the major languages including C, C++, and Fortran. Unlike source-to-source approaches, our implementation captures the influence of compiler optimizations on the numerical accuracy. We illustrate how Monte Carlo Arithmetic using the verificarlo tool outperforms the existing approaches on various use cases and is a step toward automatic numerical analysis.




 The \texttt{StronglyStableIdeals} package for \textit{Macaulay2} provides a method to compute all saturated strongly stable ideals in a given polynomial ring with a fixed Hilbert polynomial. A description of the main method and auxiliary tools is given.
The \texttt{StronglyStableIdeals} package for \textit{Macaulay2} provides a method to compute all saturated strongly stable ideals in a given polynomial ring with a fixed Hilbert polynomial. A description of the main method and auxiliary tools is given.




 We propose a platform-independent multi-threaded function library that provides data structures to generate, differentiate and render both the ordinary basis and the normalized B-basis of a user-specified extended Chebyshev (EC) space that comprises the constants and can be identified with the solution space of a constant-coefficient homogeneous linear differential equation defined on a sufficiently small interval. Using the obtained normalized B-bases, our library can also generate, (partially) differentiate, modify and visualize a large family of so-called B-curves and tensor product B-surfaces. Moreover, the library also implements methods that can be used to perform dimension elevation, to subdivide B-curves and B-surfaces by means of de Casteljau-like B-algorithms, and to generate basis transformations for the B-representation of arbitrary integral curves and surfaces that are described in traditional parametric form by means of the ordinary bases of the underlying EC spaces. Independently of the algebraic, exponential, trigonometric or mixed type of the applied EC space, the proposed library is numerically stable and efficient up to a reasonable dimension number and may be useful for academics and engineers in the fields of Approximation Theory, Computer Aided Geometric Design, Computer Graphics, Isogeometric and Numerical Analysis.
We propose a platform-independent multi-threaded function library that provides data structures to generate, differentiate and render both the ordinary basis and the normalized B-basis of a user-specified extended Chebyshev (EC) space that comprises the constants and can be identified with the solution space of a constant-coefficient homogeneous linear differential equation defined on a sufficiently small interval. Using the obtained normalized B-bases, our library can also generate, (partially) differentiate, modify and visualize a large family of so-called B-curves and tensor product B-surfaces. Moreover, the library also implements methods that can be used to perform dimension elevation, to subdivide B-curves and B-surfaces by means of de Casteljau-like B-algorithms, and to generate basis transformations for the B-representation of arbitrary integral curves and surfaces that are described in traditional parametric form by means of the ordinary bases of the underlying EC spaces. Independently of the algebraic, exponential, trigonometric or mixed type of the applied EC space, the proposed library is numerically stable and efficient up to a reasonable dimension number and may be useful for academics and engineers in the fields of Approximation Theory, Computer Aided Geometric Design, Computer Graphics, Isogeometric and Numerical Analysis.




 The R package frailtySurv for simulating and fitting semi-parametric shared frailty models is introduced. Package frailtySurv implements semi-parametric consistent estimators for a variety of frailty distributions, including gamma, log-normal, inverse Gaussian and power variance function, and provides consistent estimators of the standard errors of the parameters' estimators. The parameters' estimators are asymptotically normally distributed, and therefore statistical inference based on the results of this package, such as hypothesis testing and confidence intervals, can be performed using the normal distribution. Extensive simulations demonstrate the flexibility and correct implementation of the estimator. Two case studies performed with publicly available datasets demonstrate applicability of the package. In the Diabetic Retinopathy Study, the onset of blindness is clustered by patient, and in a large hard drive failure dataset, failure times are thought to be clustered by the hard drive manufacturer and model.
The R package frailtySurv for simulating and fitting semi-parametric shared frailty models is introduced. Package frailtySurv implements semi-parametric consistent estimators for a variety of frailty distributions, including gamma, log-normal, inverse Gaussian and power variance function, and provides consistent estimators of the standard errors of the parameters' estimators. The parameters' estimators are asymptotically normally distributed, and therefore statistical inference based on the results of this package, such as hypothesis testing and confidence intervals, can be performed using the normal distribution. Extensive simulations demonstrate the flexibility and correct implementation of the estimator. Two case studies performed with publicly available datasets demonstrate applicability of the package. In the Diabetic Retinopathy Study, the onset of blindness is clustered by patient, and in a large hard drive failure dataset, failure times are thought to be clustered by the hard drive manufacturer and model.




 We present a proof of concept for solving a 1+1D complex-valued, delay partial differential equation (PDE) that emerges in the study of waveguide quantum electrodynamics (QED) by adapting the finite-difference time-domain (FDTD) method. The delay term is spatially non-local, rendering conventional approaches such as the method of lines inapplicable. We show that by properly designing the grid and by supplying the (partial) exact solution as the boundary condition, the delay PDE can be numerically solved. In addition, we demonstrate that while the delay imposes strong data dependency, multi-thread parallelization can nevertheless be applied to such a problem. Our code provides a numerically exact solution to the time-dependent multi-photon scattering problem in waveguide QED.
We present a proof of concept for solving a 1+1D complex-valued, delay partial differential equation (PDE) that emerges in the study of waveguide quantum electrodynamics (QED) by adapting the finite-difference time-domain (FDTD) method. The delay term is spatially non-local, rendering conventional approaches such as the method of lines inapplicable. We show that by properly designing the grid and by supplying the (partial) exact solution as the boundary condition, the delay PDE can be numerically solved. In addition, we demonstrate that while the delay imposes strong data dependency, multi-thread parallelization can nevertheless be applied to such a problem. Our code provides a numerically exact solution to the time-dependent multi-photon scattering problem in waveguide QED.




 Owl is a new numerical library developed in the OCaml language. It focuses on providing a comprehensive set of high-level numerical functions so that developers can quickly build up data analytical applications. In this abstract, we will present Owl's design, core components, and its key functionality.
Owl is a new numerical library developed in the OCaml language. It focuses on providing a comprehensive set of high-level numerical functions so that developers can quickly build up data analytical applications. In this abstract, we will present Owl's design, core components, and its key functionality.




 We propose to consider ensembles of cycles (quadrics), which are interconnected through conformal-invariant geometric relations (e.g. "to be orthogonal", "to be tangent", etc.), as new objects in an extended Moebius--Lie geometry. It was recently demonstrated in several related papers, that such ensembles of cycles naturally parameterise many other conformally-invariant objects, e.g. loxodromes or continued fractions. The paper describes a method, which reduces a collection of conformally invariant geometric relations to a system of linear equations, which may be accompanied by one fixed quadratic relation. To show its usefulness, the method is implemented as a C++ library. It operates with numeric and symbolic data of cycles in spaces of arbitrary dimensionality and metrics with any signatures. Numeric calculations can be done in exact or approximate arithmetic. In the two- and three-dimensional cases illustrations and animations can be produced. An interactive Python wrapper of the library is provided as well.
We propose to consider ensembles of cycles (quadrics), which are interconnected through conformal-invariant geometric relations (e.g. "to be orthogonal", "to be tangent", etc.), as new objects in an extended Moebius--Lie geometry. It was recently demonstrated in several related papers, that such ensembles of cycles naturally parameterise many other conformally-invariant objects, e.g. loxodromes or continued fractions. The paper describes a method, which reduces a collection of conformally invariant geometric relations to a system of linear equations, which may be accompanied by one fixed quadratic relation. To show its usefulness, the method is implemented as a C++ library. It operates with numeric and symbolic data of cycles in spaces of arbitrary dimensionality and metrics with any signatures. Numeric calculations can be done in exact or approximate arithmetic. In the two- and three-dimensional cases illustrations and animations can be produced. An interactive Python wrapper of the library is provided as well.




 Engine for Likelihood-Free Inference (ELFI) is a Python software library for performing likelihood-free inference (LFI). ELFI provides a convenient syntax for arranging components in LFI, such as priors, simulators, summaries or distances, to a network called ELFI graph. The components can be implemented in a wide variety of languages. The stand-alone ELFI graph can be used with any of the available inference methods without modifications. A central method implemented in ELFI is Bayesian Optimization for Likelihood-Free Inference (BOLFI), which has recently been shown to accelerate likelihood-free inference up to several orders of magnitude by surrogate-modelling the distance. ELFI also has an inbuilt support for output data storing for reuse and analysis, and supports parallelization of computation from multiple cores up to a cluster environment. ELFI is designed to be extensible and provides interfaces for widening its functionality. This makes the adding of new inference methods to ELFI straightforward and automatically compatible with the inbuilt features.
Engine for Likelihood-Free Inference (ELFI) is a Python software library for performing likelihood-free inference (LFI). ELFI provides a convenient syntax for arranging components in LFI, such as priors, simulators, summaries or distances, to a network called ELFI graph. The components can be implemented in a wide variety of languages. The stand-alone ELFI graph can be used with any of the available inference methods without modifications. A central method implemented in ELFI is Bayesian Optimization for Likelihood-Free Inference (BOLFI), which has recently been shown to accelerate likelihood-free inference up to several orders of magnitude by surrogate-modelling the distance. ELFI also has an inbuilt support for output data storing for reuse and analysis, and supports parallelization of computation from multiple cores up to a cluster environment. ELFI is designed to be extensible and provides interfaces for widening its functionality. This makes the adding of new inference methods to ELFI straightforward and automatically compatible with the inbuilt features.




 A flexible and highly-extensible data assimilation testing suite, named DATeS, is described in this paper. DATeS aims to offer a unified testing environment that allows researchers to compare different data assimilation methodologies and understand their performance in various settings. The core of DATeS is implemented in Python and takes advantage of its object-oriented capabilities. The main components of the package (the numerical models, the data assimilation algorithms, the linear algebra solvers, and the time discretization routines) are independent of each other, which offers great flexibility to configure data assimilation applications. DATeS can interface easily with large third-party numerical models written in Fortran or in C, and with a plethora of external solvers.
A flexible and highly-extensible data assimilation testing suite, named DATeS, is described in this paper. DATeS aims to offer a unified testing environment that allows researchers to compare different data assimilation methodologies and understand their performance in various settings. The core of DATeS is implemented in Python and takes advantage of its object-oriented capabilities. The main components of the package (the numerical models, the data assimilation algorithms, the linear algebra solvers, and the time discretization routines) are independent of each other, which offers great flexibility to configure data assimilation applications. DATeS can interface easily with large third-party numerical models written in Fortran or in C, and with a plethora of external solvers.




 Web developers use base64 formats to include images, fonts, sounds and other resources directly inside HTML, JavaScript, JSON and XML files. We estimate that billions of base64 messages are decoded every day. We are motivated to improve the efficiency of base64 encoding and decoding. Compared to state-of-the-art implementations, we multiply the speeds of both the encoding (~10x) and the decoding (~7x). We achieve these good results by using the single-instruction-multiple-data (SIMD) instructions available on recent Intel processors (AVX2). Our accelerated software abides by the specification and reports errors when encountering characters outside of the base64 set. It is available online as free software under a liberal license.
Web developers use base64 formats to include images, fonts, sounds and other resources directly inside HTML, JavaScript, JSON and XML files. We estimate that billions of base64 messages are decoded every day. We are motivated to improve the efficiency of base64 encoding and decoding. Compared to state-of-the-art implementations, we multiply the speeds of both the encoding (~10x) and the decoding (~7x). We achieve these good results by using the single-instruction-multiple-data (SIMD) instructions available on recent Intel processors (AVX2). Our accelerated software abides by the specification and reports errors when encountering characters outside of the base64 set. It is available online as free software under a liberal license.




 Scikit-learn is a Python module integrating a wide range of state-of-the-art machine learning algorithms for medium-scale supervised and unsupervised problems. This package focuses on bringing machine learning to non-specialists using a general-purpose high-level language. Emphasis is put on ease of use, performance, documentation, and API consistency. It has minimal dependencies and is distributed under the simplified BSD license, encouraging its use in both academic and commercial settings. Source code, binaries, and documentation can be downloaded from http://scikit-learn.org.
Scikit-learn is a Python module integrating a wide range of state-of-the-art machine learning algorithms for medium-scale supervised and unsupervised problems. This package focuses on bringing machine learning to non-specialists using a general-purpose high-level language. Emphasis is put on ease of use, performance, documentation, and API consistency. It has minimal dependencies and is distributed under the simplified BSD license, encouraging its use in both academic and commercial settings. Source code, binaries, and documentation can be downloaded from http://scikit-learn.org.




 System Gramian matrices are a well-known encoding for properties of input-output systems such as controllability, observability or minimality. These so-called system Gramians were developed in linear system theory for applications such as model order reduction of control systems. Empirical Gramian are an extension to the system Gramians for parametric and nonlinear systems as well as a data-driven method of computation. The empirical Gramian framework - emgr - implements the empirical Gramians in a uniform and configurable manner, with applications such as Gramian-based (nonlinear) model reduction, decentralized control, sensitivity analysis, parameter identification and combined state and parameter reduction.
System Gramian matrices are a well-known encoding for properties of input-output systems such as controllability, observability or minimality. These so-called system Gramians were developed in linear system theory for applications such as model order reduction of control systems. Empirical Gramian are an extension to the system Gramians for parametric and nonlinear systems as well as a data-driven method of computation. The empirical Gramian framework - emgr - implements the empirical Gramians in a uniform and configurable manner, with applications such as Gramian-based (nonlinear) model reduction, decentralized control, sensitivity analysis, parameter identification and combined state and parameter reduction.




 A numerical method of solving the problem of acoustic wave radiation in the presence of a rigid scatterer is described. It combines the finite element method and the boundary algebraic equations. In the proposed method, the exterior domain around the scatterer is discretized, so that there appear an infinite domain with regular discretization and a relatively small layer with irregular mesh. For the infinite regular mesh, the boundary algebraic equation method is used with spurious resonance suppression according to Burton and Miller. In the thin layer with irregular mesh, the finite element method is used. The proposed method is characterized by simple implementation, fair accuracy, and absence of spurious resonances.
A numerical method of solving the problem of acoustic wave radiation in the presence of a rigid scatterer is described. It combines the finite element method and the boundary algebraic equations. In the proposed method, the exterior domain around the scatterer is discretized, so that there appear an infinite domain with regular discretization and a relatively small layer with irregular mesh. For the infinite regular mesh, the boundary algebraic equation method is used with spurious resonance suppression according to Burton and Miller. In the thin layer with irregular mesh, the finite element method is used. The proposed method is characterized by simple implementation, fair accuracy, and absence of spurious resonances.




 Forward Automatic Differentiation (AD) is a technique for augmenting programs to compute derivatives. The essence of Forward AD is to attach perturbations to each number, and propagate these through the computation. When derivatives are nested, the distinct derivative calculations, and their associated perturbations, must be distinguished. This is typically accomplished by creating a unique tag for each derivative calculation, tagging the perturbations, and overloading the arithmetic operators. We exhibit a subtle bug, present in fielded implementations, in which perturbations are confused despite the tagging machinery. The essence of the bug is this: each invocation of a derivative creates a unique tag but a unique tag is needed for each derivative calculation. When taking derivatives of higher-order functions, these need not correspond! The derivative of a higher-order function $f$ that returns a function $g$ will be a function $f'$ that returns a function $\bar{g}$ that performs a derivative calculation. A single invocation of $f'$ will create a single fresh tag but that same tag will be used for each derivative calculation resulting from an invocation of $\bar{g}$. This situation arises when taking derivatives of curried functions. Two potential solutions are presented, and their serious deficiencies discussed. One requires eta expansion to delay the creation of fresh tags from the invocation of $f'$ to the invocation of $\bar{g}$, which can be difficult or even impossible in some circumstances. The other requires $f'$ to wrap $\bar{g}$ with tag renaming, which is difficult to implement without violating the desirable complexity properties of forward AD.
Forward Automatic Differentiation (AD) is a technique for augmenting programs to compute derivatives. The essence of Forward AD is to attach perturbations to each number, and propagate these through the computation. When derivatives are nested, the distinct derivative calculations, and their associated perturbations, must be distinguished. This is typically accomplished by creating a unique tag for each derivative calculation, tagging the perturbations, and overloading the arithmetic operators. We exhibit a subtle bug, present in fielded implementations, in which perturbations are confused despite the tagging machinery. The essence of the bug is this: each invocation of a derivative creates a unique tag but a unique tag is needed for each derivative calculation. When taking derivatives of higher-order functions, these need not correspond! The derivative of a higher-order function $f$ that returns a function $g$ will be a function $f'$ that returns a function $\bar{g}$ that performs a derivative calculation. A single invocation of $f'$ will create a single fresh tag but that same tag will be used for each derivative calculation resulting from an invocation of $\bar{g}$. This situation arises when taking derivatives of curried functions. Two potential solutions are presented, and their serious deficiencies discussed. One requires eta expansion to delay the creation of fresh tags from the invocation of $f'$ to the invocation of $\bar{g}$, which can be difficult or even impossible in some circumstances. The other requires $f'$ to wrap $\bar{g}$ with tag renaming, which is difficult to implement without violating the desirable complexity properties of forward AD.




 We study algorithms for the fast computation of modular inverses. Newton-Raphson iteration over $p$-adic numbers gives a recurrence relation computing modular inverse modulo $p^m$, that is logarithmic in $m$. We solve the recurrence to obtain an explicit formula for the inverse. Then we study different implementation variants of this iteration and show that our explicit formula is interesting for small exponent values but slower or large exponent, say of more than $700$ bits. Overall we thus propose a hybrid combination of our explicit formula and the best asymptotic variants. This hybrid combination yields then a constant factor improvement, also for large exponents.
We study algorithms for the fast computation of modular inverses. Newton-Raphson iteration over $p$-adic numbers gives a recurrence relation computing modular inverse modulo $p^m$, that is logarithmic in $m$. We solve the recurrence to obtain an explicit formula for the inverse. Then we study different implementation variants of this iteration and show that our explicit formula is interesting for small exponent values but slower or large exponent, say of more than $700$ bits. Overall we thus propose a hybrid combination of our explicit formula and the best asymptotic variants. This hybrid combination yields then a constant factor improvement, also for large exponents.




 The sparse matrix-vector product (SpMV) is a fundamental operation in many scientific applications from various fields. The High Performance Computing (HPC) community has therefore continuously invested a lot of effort to provide an efficient SpMV kernel on modern CPU architectures. Although it has been shown that block-based kernels help to achieve high performance, they are difficult to use in practice because of the zero padding they require. In the current paper, we propose new kernels using the AVX-512 instruction set, which makes it possible to use a blocking scheme without any zero padding in the matrix memory storage. We describe mask-based sparse matrix formats and their corresponding SpMV kernels highly optimized in assembly language. Considering that the optimal blocking size depends on the matrix, we also provide a method to predict the best kernel to be used utilizing a simple interpolation of results from previous executions. We compare the performance of our approach to that of the Intel MKL CSR kernel and the CSR5 open-source package on a set of standard benchmark matrices. We show that we can achieve significant improvements in many cases, both for sequential and for parallel executions. Finally, we provide the corresponding code in an open source library, called SPC5.
The sparse matrix-vector product (SpMV) is a fundamental operation in many scientific applications from various fields. The High Performance Computing (HPC) community has therefore continuously invested a lot of effort to provide an efficient SpMV kernel on modern CPU architectures. Although it has been shown that block-based kernels help to achieve high performance, they are difficult to use in practice because of the zero padding they require. In the current paper, we propose new kernels using the AVX-512 instruction set, which makes it possible to use a blocking scheme without any zero padding in the matrix memory storage. We describe mask-based sparse matrix formats and their corresponding SpMV kernels highly optimized in assembly language. Considering that the optimal blocking size depends on the matrix, we also provide a method to predict the best kernel to be used utilizing a simple interpolation of results from previous executions. We compare the performance of our approach to that of the Intel MKL CSR kernel and the CSR5 open-source package on a set of standard benchmark matrices. We show that we can achieve significant improvements in many cases, both for sequential and for parallel executions. Finally, we provide the corresponding code in an open source library, called SPC5.