-
Read-Copy Update (RCU) is a scalable, high-performance Linux-kernel
synchronization mechanism that runs low-overhead readers concurrently with
updaters. Production-quality RCU implementations for multi-core systems are
decidedly non-trivial. Giving the ubiquity of Linux, a rare "million-year" bug
can occur several times per day across the installed base. Stringent validation
of RCU's complex behaviors is thus critically important. Exhaustive testing is
infeasible due to the exponential number of possible executions, which suggests
use of formal verification.
Previous verification efforts on RCU either focus on simple implementations
or use modeling languages, the latter requiring error-prone manual translation
that must be repeated frequently due to regular changes in the Linux kernel's
RCU implementation. In this paper, we first describe the implementation of Tree
RCU in the Linux kernel. We then discuss how to construct a model directly from
Tree RCU's source code in C, and use the CBMC model checker to verify its
safety and liveness properties. To our best knowledge, this is the first
verification of a significant part of RCU's source code, and is an important
step towards integration of formal verification into the Linux kernel's
regression test suite.
-
With the emergence of Non-Volatile Memories (NVMs) and their shortcomings
such as limited endurance and high power consumption in write requests, several
studies have suggested hybrid memory architecture employing both Dynamic Random
Access Memory (DRAM) and NVM in a memory system. By conducting a comprehensive
experiments, we have observed that such studies lack to consider very important
aspects of hybrid memories including the effect of: a) data migrations on
performance, b) data migrations on power, and c) the granularity of data
migration. This paper presents an efficient data migration scheme at the
Operating System level in a hybrid DRAMNVM memory architecture. In the proposed
scheme, two Least Recently Used (LRU) queues, one for DRAM section and one for
NVM section, are used for the sake of data migration. With careful
characterization of the workloads obtained from PARSEC benchmark suite, the
proposed scheme prevents unnecessary migrations and only allows migrations
which benefits the system in terms of power and performance. The experimental
results show that the proposed scheme can reduce the power consumption up to
79% compared to DRAM-only memory and up to 48% compared to the state-of-the art
techniques.
-
Modern GPUs face a trade-off on how the page size used for memory management
affects address translation and demand paging. Support for multiple page sizes
can help relax the page size trade-off so that address translation and demand
paging optimizations work together synergistically. However, existing page
coalescing and splintering policies require costly base page migrations that
undermine the benefits multiple page sizes provide. In this paper, we observe
that GPGPU applications present an opportunity to support multiple page sizes
without costly data migration, as the applications perform most of their memory
allocation en masse (i.e., they allocate a large number of base pages at once).
We show that this en masse allocation allows us to create intelligent memory
allocation policies which ensure that base pages that are contiguous in virtual
memory are allocated to contiguous physical memory pages. As a result,
coalescing and splintering operations no longer need to migrate base pages.
We introduce Mosaic, a GPU memory manager that provides
application-transparent support for multiple page sizes. Mosaic uses base pages
to transfer data over the system I/O bus, and allocates physical memory in a
way that (1) preserves base page contiguity and (2) ensures that a large page
frame contains pages from only a single memory protection domain. This
mechanism allows the TLB to use large pages, reducing address translation
overhead. During data transfer, this mechanism enables the GPU to transfer only
the base pages that are needed by the application over the system I/O bus,
keeping demand paging overhead low.
-
Integrated CPU-GPU architecture provides excellent acceleration capabilities
for data parallel applications on embedded platforms while meeting the size,
weight and power (SWaP) requirements. However, sharing of main memory between
CPU applications and GPU kernels can severely affect the execution of GPU
kernels and diminish the performance gain provided by GPU. For example, in the
NVIDIA Tegra K1 platform which has the integrated CPU-GPU architecture, we
noticed that in the worst case scenario, the GPU kernels can suffer as much as
4X slowdown in the presence of co-running memory intensive CPU applications
compared to their solo execution. In this paper, we propose a software
mechanism, which we call BWLOCK++, to protect the performance of GPU kernels
from co-scheduled memory intensive CPU applications.
-
Poor time predictability of multicore processors has been a long-standing
challenge in the real-time systems community. In this paper, we make a case
that a fundamental problem that prevents efficient and predictable real-time
computing on multicore is the lack of a proper memory abstraction to express
memory criticality, which cuts across various layers of the system: the
application, OS, and hardware. We, therefore, propose a new holistic resource
management approach driven by a new memory abstraction, which we call
Deterministic Memory. The key characteristic of deterministic memory is that
the platform - the OS and hardware - guarantees small and tightly bounded
worst-case memory access timing. In contrast, we call the conventional memory
abstraction as best-effort memory in which only highly pessimistic worst-case
bounds can be achieved. We propose to utilize both abstractions to achieve high
time predictability but without significantly sacrificing performance. We
present deterministic memory-aware OS and architecture designs, including
OS-level page allocator, hardware-level cache, and DRAM controller designs. We
implement the proposed OS and architecture extensions on Linux and gem5
simulator. Our evaluation results, using a set of synthetic and real-world
benchmarks, demonstrate the feasibility and effectiveness of our approach.
-
Reproducing executions of multithreaded programs is very challenging due to
many intrinsic and external non-deterministic factors. Existing RnR systems
achieve significant progress in terms of performance overhead, but none targets
the in-situ setting, in which replay occurs within the same process as the
recording process. Also, most existing work cannot achieve identical replay,
which may prevent the reproduction of some errors.
This paper presents iReplayer, which aims to identically replay multithreaded
programs in the original process (under the "in-situ" setting). The novel
in-situ and identical replay of iReplayer makes it more likely to reproduce
errors, and allows it to directly employ debugging mechanisms (e.g.
watchpoints) to aid failure diagnosis. Currently, iReplayer only incurs 3%
performance overhead on average, which allows it to be always enabled in the
production environment. iReplayer enables a range of possibilities, and this
paper presents three examples: two automatic tools for detecting buffer
overflows and use-after-free bugs, and one interactive debugging tool that is
integrated with GDB.
-
Applications in the AI and HPC fields require much memory capacity, and the
amount of energy consumed by main memory of server machines is ever increasing.
Energy consumption of main memory can be greatly reduced by applying
approximate computing in exchange for increased bit error rates. AI and HPC
applications are to some extent robust to bit errors because small numerical
errors are amortized by their iterative nature. However, a single occurrence of
a NaN due to bit-flips corrupts the whole calculation result. The issue is that
fixing every bit-flip using ECC incurs too much overhead because the bit error
rate is much higher than in normal environments. We propose a low-overhead
method to fix NaNs when approximate computing is applied to main memory. The
main idea is to reactively repair NaNs while leaving other non-fatal numerical
errors as-is to reduce the overhead. We implemented a prototype by leveraging
floating-point exceptions of x86 CPUs, and the preliminary evaluations showed
that our method incurs negligible overhead.
-
In this work we present the Secure Machine, SeM for short, a CPU architecture
extension for secure computing. SeM uses a small amount of in-chip additional
hardware that monitors key communication channels inside the CPU chip, and only
acts when required. SeM provides confidentiality and integrity for a secure
program without trusting the platform software or any off-chip hardware. SeM
supports existing binaries of single- and multi-threaded applications running
on single- or multi-core, multi-CPU. The performance reduction caused by it is
only few percent, most of which is due to the memory encryption layer that is
commonly used in many secure architectures.
We also developed SeM-Prepare, a software tool that automatically instruments
existing applications (binaries) with additional instructions so they can be
securely executed on our architecture without requiring any programming efforts
or the availability of the desired program`s source code.
To enable secure data sharing in shared memory environments, we developed
Secure Distributed Shared Memory (SDSM), an efficient (time and memory)
algorithm for allowing thousands of compute nodes to share data securely while
running on an untrusted computing environment. SDSM shows a negligible
reduction in performance, and it requires negligible and hardware resources. We
developed Distributed Memory Integrity Trees, a method for enhancing single
node integrity trees for preserving the integrity of a distributed application
running on an untrusted computing environment. We show that our method is
applicable to existing single node integrity trees such as Merkle Tree, Bonsai
Merkle Tree, and Intel`s SGX memory integrity engine. All these building blocks
may be used together to form a practical secure system, and some can be used in
conjunction with other secure systems.
-
The sporadic task model is often used to analyze recurrent execution of
identical tasks in real-time systems. A sporadic task defines an infinite
sequence of task instances, also called jobs, that arrive under the minimum
inter-arrival time constraint. To ensure the system safety, timeliness has to
be guaranteed in addition to functional correctness, i.e., all jobs of all
tasks have to be finished before the job deadlines. We focus on analyzing
arbitrary-deadline task sets on a homogeneous (identical) multiprocessor system
under any given global fixed-priority scheduling approach and provide a series
of schedulability tests with different tradeoffs between their time complexity
and their accuracy. Under the arbitrary-deadline setting, the relative deadline
of a task can be longer than the minimum inter-arrival time of the jobs of the
task. We show that global deadline-monotonic (DM) scheduling has a speedup
bound of $3-1/M$ against any optimal scheduling algorithms, where $M$ is the
number of identical processors, and prove that this bound is asymptotically
tight.
-
Commodity OS kernels are known to have broad attack surfaces due to the large
code base and the numerous features such as device drivers. For a real-world
use case (e.g., an Apache Server), many kernel services are unused and only a
small amount of kernel code is used. Within the used code, a certain part is
invoked only at the runtime phase while the rest are executed at startup and/or
shutdown phases in the kernel's lifetime run.
In this paper, we propose a reliable and practical system, named KASR, which
transparently reduces attack surfaces of commodity OS kernels at the runtime
phase without requiring their source code. The KASR system, residing in a
trusted hypervisor, achieves the attack surface reduction through two reliable
steps: (1) deprives unused code of executable permissions, and (2)
transparently segments used code and selectively activates them according to
their phases. KASR also prevents unknown code from executing in the kernel
space, and thus it is able to defend against all kernel code injection attacks.
We implement a prototype of KASR on the Xen-4.8.2 hypervisor and evaluate its
security effectiveness on Linux kernel-4.4.0-87-generic. Our evaluation shows
that KASR reduces kernel attack surface by 64%, trims off 40% of in-memory CVE
vulnerabilities and 66% of system calls, and prohibits 99% of on-disk device
drivers (including their related CVEs) from executing. Besides, KASR
successfully detects and blocks all 6 real-world kernel rootkits. We measure
its performance overhead with three benchmark tools (i.e., SPECINT, httperf and
bonnie++). The experimental results indicate that KASR imposes less than 1%
averaged performance overhead compared to an unmodified Xen hypervisor.
-
Timing guarantees are crucial to cyber-physical applications that must bound
the end-to-end delay between sensing, processing and actuation. For example, in
a flight controller for a multirotor drone, the data from a gyro or inertial
sensor must be gathered and processed to determine the attitude of the
aircraft. Sensor data fusion is followed by control decisions that adjust the
flight of a drone by altering motor speeds. If the processing pipeline between
sensor input and actuation is not bounded, the drone will lose control and
possibly fail to maintain flight.
Motivated by the implementation of a multithreaded drone flight controller on
the Quest RTOS, we develop a composable pipe model based on the system's task,
scheduling and communication abstractions. This pipe model is used to analyze
two semantics of end-to-end time: reaction time and freshness time. We also
argue that end-to-end timing properties should be factored in at the early
stage of application design. Thus, we provide a mathematical framework to
derive feasible task periods that satisfy both a given set of end-to-end timing
constraints and the schedulability requirement. We demonstrate the
applicability of our design approach by using it to port the Cleanflight flight
controller firmware to Quest on the Intel Aero board. Experiments show that
Cleanflight ported to Quest is able to achieve end-to-end latencies within the
predicted time bounds derived by analysis.
-
Time awareness is critical to a broad range of emerging applications -- in
Cyber-Physical Systems and Internet of Things -- running on commodity platforms
and operating systems. Traditionally, time is synchronized across devices
through a best-effort background service whose performance is neither
observable nor controllable, thus consuming system resources independently of
application needs while not allowing the applications and OS services to adapt
to changes in uncertainty in system time. We advocate for rethinking how time
is managed in a system stack. In this paper, we propose a new clock model that
characterizes various sources of timing uncertainties in true time. We then
present a Kalman filter based time synchronization protocol that adapts to the
uncertainties exposed by the clock model. Our realization of a
uncertainty-aware clock model and synchronization protocol is based on a
standard embedded Linux platform.
-
Creating a model of a computer system that can be used for tasks such as
predicting future resource usage and detecting anomalies is a challenging
problem. Most current systems rely on heuristics and overly simplistic
assumptions about the workloads and system statistics. These heuristics are
typically a one-size-fits-all solution so as to be applicable in a wide range
of applications and systems environments.
With this paper, we present our ongoing work of integrating systems telemetry
ranging from standard resource usage statistics to kernel and library calls of
applications into a machine learning model. Intuitively, such a ML model
approximates, at any point in time, the state of a system and allows us to
solve tasks such as resource usage prediction and anomaly detection. To achieve
this goal, we leverage readily-available information that does not require any
changes to the applications run on the system. We train recurrent neural
networks to learn a model of the system under consideration. As a proof of
concept, we train models specifically to predict future resource usage of
running applications.
-
This paper introduces the concept of size-aware sharding to improve tail
latencies for in-memory key-value stores, and describes its implementation in
the Minos key-value store. Tail latencies are crucial in distributed
applications with high fan-out ratios, because overall response time is
determined by the slowest response. Size-aware sharding distributes requests
for keys to cores according to the size of the item associated with the key. In
particular, requests for small and large items are sent to disjoint subsets of
cores. Size-aware sharding improves tail latencies by avoiding head-of-line
blocking, in which a request for a small item gets queued behind a request for
a large item. Alternative size-unaware approaches to sharding, such as
keyhash-based sharding, request dispatching and stealing do not avoid
head-of-line blocking, and therefore exhibit worse tail latencies. The
challenge in implementing size-aware sharding is to maintain high throughput by
avoiding the cost of software dispatching and by achieving load balancing
between different cores. Minos uses hardware dispatch for all requests for
small items, which form the very large majority of all requests. It achieves
load balancing by adapting the number of cores handling requests for small and
large items to their relative presence in the workload. We compare Minos to
three state-of-the-art designs of in-memory KV stores. Compared to its closest
competitor, Minos achieves a 99th percentile latency that is up to two orders
of magnitude lower. Put differently, for a given value for the 99th percentile
latency equal to 10 times the mean service time, Minos achieves a throughput
that is up to 7.4 times higher.
-
Efficient, reliable trapping of execution in a program at the desired
location is a hot area of research for security professionals. The progression
of debuggers and malware is akin to a game of cat and mouse - each are
constantly in a state of trying to thwart one another. At the core of most
efficient debuggers today is a combination of virtual machines and traditional
binary modification breakpoints (int3). In this paper, we present a design for
Virtual Breakpoints, a modification to the x86 MMU which brings breakpoint
management into hardware alongside page tables. We demonstrate the fundamental
abstraction failures of current trapping methods, and rebuild the mechanism
from the ground up. Our design delivers fast, reliable trapping without the
pitfalls of binary modification.
-
Basic mirroring (BM) classified as RAID level 1 replicates data on two disks,
thus doubling disk access bandwidth for read requests. RAID1/0 is an array of
BM pairs with balanced loads due to striping. When a disk fails the read load
on its pair is doubled, which results in halving the maximum attainable
bandwidth. We review RAID1 organizations which attain a balanced load upon disk
failure, but as shown by reliability analysis tend to be less reliable than
RAID1/0. Hybrid disk arrays which store XORed instead of replicated data tend
to have a higher reliability than mirrored disks, but incur a higher overhead
in updating data. Read request response time can be improved by processing them
at a higher priority than writes, since they have a direct effect on
application response time. Shortest seek distance and affinity based routing
both shorten seek time. Anticipatory arm placement places arms optimally to
minimize the seek distance. The analysis of RAID1 in normal, degraded, and
rebuild mode is provided to quantify RAID1/0 performance. We compare the
reliability of mirrored disk organizations against each other and hybrid disks
and erasure coded disk arrays.
-
Many applications have service requirements that are not easily met by
existing operating systems. Real-time and security-critical tasks, for example,
often require custom OSes to meet their needs. However, development of special
purpose OSes is a time-consuming and difficult exercise. Drivers, libraries and
applications have to be written from scratch or ported from existing sources.
Many researchers have tackled this problem by developing ways to extend
existing systems with application-specific services. However, it is often
difficult to ensure an adequate degree of separation between legacy and new
services, especially when security and timing requirements are at stake.
Virtualization, for example, supports logical isolation of separate guest
services, but suffers from inadequate temporal isolation of time-critical code
required for real-time systems. This paper presents vLibOS, a master-slave
paradigm for new systems, whose services are built on legacy code that is
temporally and spatially isolated in separate VM domains. Existing OSes are
treated as sandboxed libraries, providing legacy services that are requested by
inter-VM calls, which execute with the time budget of the caller. We evaluate a
real-time implementation of vLibOS. Empirical results show that vLibOS achieves
as much as a 50\% reduction in performance slowdown for real-time threads, when
competing for a shared memory bus with a Linux VM.
-
To satisfy increasing storage demands in both capacity and performance,
industry has turned to multiple storage technologies, including Flash SSDs and
SMR disks. These devices employ a translation layer that conceals the
idiosyncrasies of their mediums and enables random access. Device translation
layers are, however, inherently constrained: resources on the drive are scarce,
they cannot be adapted to application requirements, and lack visibility across
multiple devices. As a result, performance and durability of many storage
devices is severely degraded.
In this paper, we present SALSA: a translation layer that executes on the
host and allows unmodified applications to better utilize commodity storage.
SALSA supports a wide range of single- and multi-device optimizations and,
because is implemented in software, can adapt to specific workloads. We
describe SALSA's design, and demonstrate its significant benefits using
microbenchmarks and case studies based on three applications: MySQL, the Swift
object store, and a video server.
-
Data retrieval systems such as online search engines and online social
networks must comply with the privacy policies of personal and selectively
shared data items, regulatory policies regarding data retention and censorship,
and the provider's own policies regarding data use. Enforcing these policies is
difficult and error-prone. Systematic techniques to enforce policies are either
limited to type-based policies that apply uniformly to all data of the same
type, or incur significant runtime overhead.
This paper presents Shai, the first system that systematically enforces
data-specific policies with near-zero overhead in the common case. Shai's key
idea is to push as many policy checks as possible to an offline, ahead-of-time
analysis phase, often relying on predicted values of runtime parameters such as
the state of access control lists or connected users' attributes. Runtime
interception is used sparingly, only to verify these predictions and to make
any remaining policy checks. Our prototype implementation relies on efficient,
modern OS primitives for sandboxing and isolation. We present the design of
Shai and quantify its overheads on an experimental data indexing and search
pipeline based on the popular search engine Apache Lucene.
-
The Internet of Things (IoT) is rapidly evolving based on low-power compliant
protocol standards that extend the Internet into the embedded world. Pioneering
implementations have proven it is feasible to inter-network very constrained
devices, but had to rely on peculiar cross-layered designs and offer a
minimalistic set of features. In the long run, however, professional use and
massive deployment of IoT devices require full-featured, cleanly composed, and
flexible network stacks.
This paper introduces the networking architecture that turns RIOT into a
powerful IoT system, to enable low-power wireless scenarios. RIOT networking
offers (i) a modular architecture with generic interfaces for plugging in
drivers, protocols, or entire stacks, (ii) support for multiple heterogeneous
interfaces and stacks that can concurrently operate, and (iii) GNRC, its
cleanly layered, recursively composed default network stack. We contribute an
in-depth analysis of the communication performance and resource efficiency of
RIOT, both on a micro-benchmarking level as well as by comparing IoT
communication across different platforms. Our findings show that, though it is
based on significantly different design trade-offs, the networking subsystem of
RIOT achieves a performance equivalent to that of Contiki and TinyOS, the two
operating systems which pioneered IoT software platforms.
-
Modern Operating Systems are typically POSIX-compliant. The system calls are
the fundamental layer of interaction between user-space applications and the OS
kernel and its implementation of fundamental abstractions and primitives used
in modern computing. The next generation of NVM/SCM memory raises critical
questions about the efficiency of modern OS architecture. This paper
investigates how the POSIX API drives performance for a system with NVM/SCM
memory. We show that OS and metadata related system calls represent the most
important area of optimization. However, the synchronization related system
calls (poll(), futex(), wait4()) are the most time-consuming overhead that even
a RAMdisk platform fails to eliminate. Attempting to preserve the POSIX-based
approach will likely result in fundamental inefficiencies for any future
applications of NVM/SCM memory.
-
The security of billions of devices worldwide depends on the security and
robustness of the mainline Linux kernel. However, the increasing number of
kernel-specific vulnerabilities, especially memory safety vulnerabilities,
shows that the kernel is a popular and practically exploitable target. Two
major causes of memory safety vulnerabilities are reference counter overflows
(temporal memory errors) and lack of pointer bounds checking (spatial memory
errors).
To succeed in practice, security mechanisms for critical systems like the
Linux kernel must also consider performance and deployability as critical
design objectives. We present and systematically analyze two such mechanisms
for improving memory safety in the Linux kernel: (a) an overflow-resistant
reference counter data structure designed to accommodate typical reference
counter usage in kernel source code, and (b) runtime pointer bounds checking
using Intel MPX in the kernel.
-
Computing technology has gotten cheaper and more powerful, allowing users to
have a growing number of personal computing devices at their disposal. While
this trend is beneficial for the user, it also creates a growing management
burden for the user. Each device must be managed independently and users must
repeat the same management tasks on the each device, such as updating software,
changing configurations, backup, and replicating data for availability. To
prevent the management burden from increasing with the number of devices, we
propose that all devices run a single system image called a personal computing
image. Personal computing images export a device-specific user interface on
each device, but provide a consistent view of application and operating state
across all devices. As a result, management tasks can be performed once on any
device and will be automatically propagated to all other devices belonging to
the user. We discuss evolutionary steps that can be taken to achieve personal
computing images for devices and elaborate on challenges that we believe
building such systems will face.
-
Virtualization technologies have evolved along with the development of
computational environments since virtualization offered needed features at that
time such as isolation, accountability, resource allocation, resource fair
sharing and so on. Novel processor technologies bring to commodity computers
the possibility to emulate diverse environments where a wide range of
computational scenarios can be run. Along with processors evolution, system
developers have created different virtualization mechanisms where each new
development enhanced the performance of previous virtualized environments.
Recently, operating system-based virtualization technologies captured the
attention of communities abroad (from industry to academy and research) because
their important improvements on performance area.
In this paper, the features of three container-based operating systems
virtualization tools (LXC, Docker and Singularity) are presented. LXC, Docker,
Singularity and bare metal are put under test through a customized single node
HPL-Benchmark and a MPI-based application for the multi node testbed. Also the
disk I/O performance, Memory (RAM) performance, Network bandwidth and GPU
performance are tested for the COS technologies vs bare metal. Preliminary
results and conclusions around them are presented and discussed.
-
In spite of years of improvements to software security, heap-related attacks
still remain a severe threat. One reason is that many existing memory
allocators fall short in a variety of aspects. For instance,
performance-oriented allocators are designed with very limited countermeasures
against attacks, but secure allocators generally suffer from significant
performance overhead, e.g., running up to 10x slower. This paper, therefore,
introduces FreeGuard, a secure memory allocator that prevents or reduces a wide
range of heap-related attacks, such as heap overflows, heap over-reads,
use-after-frees, as well as double and invalid frees. FreeGuard has similar
performance to the default Linux allocator, with less than 2% overhead on
average, but provides significant improvement to security guarantees. FreeGuard
also addresses multiple implementation issues of existing secure allocators,
such as the issue of scalability. Experimental results demonstrate that
FreeGuard is very effective in defending against a variety of heap-related
attacks.





 Read-Copy Update (RCU) is a scalable, high-performance Linux-kernel synchronization mechanism that runs low-overhead readers concurrently with updaters. Production-quality RCU implementations for multi-core systems are decidedly non-trivial. Giving the ubiquity of Linux, a rare "million-year" bug can occur several times per day across the installed base. Stringent validation of RCU's complex behaviors is thus critically important. Exhaustive testing is infeasible due to the exponential number of possible executions, which suggests use of formal verification. Previous verification efforts on RCU either focus on simple implementations or use modeling languages, the latter requiring error-prone manual translation that must be repeated frequently due to regular changes in the Linux kernel's RCU implementation. In this paper, we first describe the implementation of Tree RCU in the Linux kernel. We then discuss how to construct a model directly from Tree RCU's source code in C, and use the CBMC model checker to verify its safety and liveness properties. To our best knowledge, this is the first verification of a significant part of RCU's source code, and is an important step towards integration of formal verification into the Linux kernel's regression test suite.
Read-Copy Update (RCU) is a scalable, high-performance Linux-kernel synchronization mechanism that runs low-overhead readers concurrently with updaters. Production-quality RCU implementations for multi-core systems are decidedly non-trivial. Giving the ubiquity of Linux, a rare "million-year" bug can occur several times per day across the installed base. Stringent validation of RCU's complex behaviors is thus critically important. Exhaustive testing is infeasible due to the exponential number of possible executions, which suggests use of formal verification. Previous verification efforts on RCU either focus on simple implementations or use modeling languages, the latter requiring error-prone manual translation that must be repeated frequently due to regular changes in the Linux kernel's RCU implementation. In this paper, we first describe the implementation of Tree RCU in the Linux kernel. We then discuss how to construct a model directly from Tree RCU's source code in C, and use the CBMC model checker to verify its safety and liveness properties. To our best knowledge, this is the first verification of a significant part of RCU's source code, and is an important step towards integration of formal verification into the Linux kernel's regression test suite.




 Poor time predictability of multicore processors has been a long-standing challenge in the real-time systems community. In this paper, we make a case that a fundamental problem that prevents efficient and predictable real-time computing on multicore is the lack of a proper memory abstraction to express memory criticality, which cuts across various layers of the system: the application, OS, and hardware. We, therefore, propose a new holistic resource management approach driven by a new memory abstraction, which we call Deterministic Memory. The key characteristic of deterministic memory is that the platform - the OS and hardware - guarantees small and tightly bounded worst-case memory access timing. In contrast, we call the conventional memory abstraction as best-effort memory in which only highly pessimistic worst-case bounds can be achieved. We propose to utilize both abstractions to achieve high time predictability but without significantly sacrificing performance. We present deterministic memory-aware OS and architecture designs, including OS-level page allocator, hardware-level cache, and DRAM controller designs. We implement the proposed OS and architecture extensions on Linux and gem5 simulator. Our evaluation results, using a set of synthetic and real-world benchmarks, demonstrate the feasibility and effectiveness of our approach.
Poor time predictability of multicore processors has been a long-standing challenge in the real-time systems community. In this paper, we make a case that a fundamental problem that prevents efficient and predictable real-time computing on multicore is the lack of a proper memory abstraction to express memory criticality, which cuts across various layers of the system: the application, OS, and hardware. We, therefore, propose a new holistic resource management approach driven by a new memory abstraction, which we call Deterministic Memory. The key characteristic of deterministic memory is that the platform - the OS and hardware - guarantees small and tightly bounded worst-case memory access timing. In contrast, we call the conventional memory abstraction as best-effort memory in which only highly pessimistic worst-case bounds can be achieved. We propose to utilize both abstractions to achieve high time predictability but without significantly sacrificing performance. We present deterministic memory-aware OS and architecture designs, including OS-level page allocator, hardware-level cache, and DRAM controller designs. We implement the proposed OS and architecture extensions on Linux and gem5 simulator. Our evaluation results, using a set of synthetic and real-world benchmarks, demonstrate the feasibility and effectiveness of our approach.




 To satisfy increasing storage demands in both capacity and performance, industry has turned to multiple storage technologies, including Flash SSDs and SMR disks. These devices employ a translation layer that conceals the idiosyncrasies of their mediums and enables random access. Device translation layers are, however, inherently constrained: resources on the drive are scarce, they cannot be adapted to application requirements, and lack visibility across multiple devices. As a result, performance and durability of many storage devices is severely degraded. In this paper, we present SALSA: a translation layer that executes on the host and allows unmodified applications to better utilize commodity storage. SALSA supports a wide range of single- and multi-device optimizations and, because is implemented in software, can adapt to specific workloads. We describe SALSA's design, and demonstrate its significant benefits using microbenchmarks and case studies based on three applications: MySQL, the Swift object store, and a video server.
To satisfy increasing storage demands in both capacity and performance, industry has turned to multiple storage technologies, including Flash SSDs and SMR disks. These devices employ a translation layer that conceals the idiosyncrasies of their mediums and enables random access. Device translation layers are, however, inherently constrained: resources on the drive are scarce, they cannot be adapted to application requirements, and lack visibility across multiple devices. As a result, performance and durability of many storage devices is severely degraded. In this paper, we present SALSA: a translation layer that executes on the host and allows unmodified applications to better utilize commodity storage. SALSA supports a wide range of single- and multi-device optimizations and, because is implemented in software, can adapt to specific workloads. We describe SALSA's design, and demonstrate its significant benefits using microbenchmarks and case studies based on three applications: MySQL, the Swift object store, and a video server.




 Data retrieval systems such as online search engines and online social networks must comply with the privacy policies of personal and selectively shared data items, regulatory policies regarding data retention and censorship, and the provider's own policies regarding data use. Enforcing these policies is difficult and error-prone. Systematic techniques to enforce policies are either limited to type-based policies that apply uniformly to all data of the same type, or incur significant runtime overhead. This paper presents Shai, the first system that systematically enforces data-specific policies with near-zero overhead in the common case. Shai's key idea is to push as many policy checks as possible to an offline, ahead-of-time analysis phase, often relying on predicted values of runtime parameters such as the state of access control lists or connected users' attributes. Runtime interception is used sparingly, only to verify these predictions and to make any remaining policy checks. Our prototype implementation relies on efficient, modern OS primitives for sandboxing and isolation. We present the design of Shai and quantify its overheads on an experimental data indexing and search pipeline based on the popular search engine Apache Lucene.
Data retrieval systems such as online search engines and online social networks must comply with the privacy policies of personal and selectively shared data items, regulatory policies regarding data retention and censorship, and the provider's own policies regarding data use. Enforcing these policies is difficult and error-prone. Systematic techniques to enforce policies are either limited to type-based policies that apply uniformly to all data of the same type, or incur significant runtime overhead. This paper presents Shai, the first system that systematically enforces data-specific policies with near-zero overhead in the common case. Shai's key idea is to push as many policy checks as possible to an offline, ahead-of-time analysis phase, often relying on predicted values of runtime parameters such as the state of access control lists or connected users' attributes. Runtime interception is used sparingly, only to verify these predictions and to make any remaining policy checks. Our prototype implementation relies on efficient, modern OS primitives for sandboxing and isolation. We present the design of Shai and quantify its overheads on an experimental data indexing and search pipeline based on the popular search engine Apache Lucene.


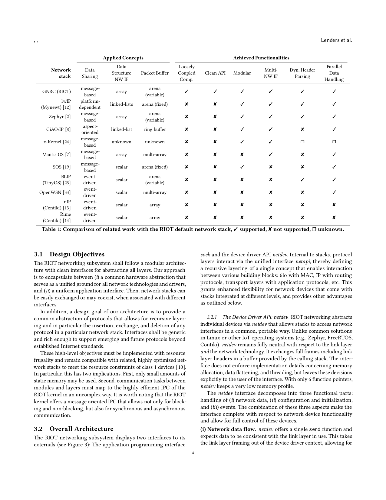

 The Internet of Things (IoT) is rapidly evolving based on low-power compliant protocol standards that extend the Internet into the embedded world. Pioneering implementations have proven it is feasible to inter-network very constrained devices, but had to rely on peculiar cross-layered designs and offer a minimalistic set of features. In the long run, however, professional use and massive deployment of IoT devices require full-featured, cleanly composed, and flexible network stacks. This paper introduces the networking architecture that turns RIOT into a powerful IoT system, to enable low-power wireless scenarios. RIOT networking offers (i) a modular architecture with generic interfaces for plugging in drivers, protocols, or entire stacks, (ii) support for multiple heterogeneous interfaces and stacks that can concurrently operate, and (iii) GNRC, its cleanly layered, recursively composed default network stack. We contribute an in-depth analysis of the communication performance and resource efficiency of RIOT, both on a micro-benchmarking level as well as by comparing IoT communication across different platforms. Our findings show that, though it is based on significantly different design trade-offs, the networking subsystem of RIOT achieves a performance equivalent to that of Contiki and TinyOS, the two operating systems which pioneered IoT software platforms.
The Internet of Things (IoT) is rapidly evolving based on low-power compliant protocol standards that extend the Internet into the embedded world. Pioneering implementations have proven it is feasible to inter-network very constrained devices, but had to rely on peculiar cross-layered designs and offer a minimalistic set of features. In the long run, however, professional use and massive deployment of IoT devices require full-featured, cleanly composed, and flexible network stacks. This paper introduces the networking architecture that turns RIOT into a powerful IoT system, to enable low-power wireless scenarios. RIOT networking offers (i) a modular architecture with generic interfaces for plugging in drivers, protocols, or entire stacks, (ii) support for multiple heterogeneous interfaces and stacks that can concurrently operate, and (iii) GNRC, its cleanly layered, recursively composed default network stack. We contribute an in-depth analysis of the communication performance and resource efficiency of RIOT, both on a micro-benchmarking level as well as by comparing IoT communication across different platforms. Our findings show that, though it is based on significantly different design trade-offs, the networking subsystem of RIOT achieves a performance equivalent to that of Contiki and TinyOS, the two operating systems which pioneered IoT software platforms.