-
Most of today's high-speed switches and routers adopt an input-queued
crossbar switch architecture. Such a switch needs to compute a matching
(crossbar schedule) between the input ports and output ports during each
switching cycle (time slot). A key research challenge in designing large (in
number of input/output ports $N$) input-queued crossbar switches is to develop
crossbar scheduling algorithms that can compute "high quality" matchings --
i.e., those that result in high switch throughput (ideally $100\%$) and low
queueing delays for packets -- at line rates. SERENA is one such algorithm: it
outputs excellent matching decisions that result in $100\%$ switch throughput
and reasonably good queueing delays. However, since SERENA is a centralized
algorithm with $O(N)$ computational complexity, it cannot support switches that
both are large and have a very high line rate per port. In this work, we
propose SERENADE (SERENA, the Distributed Edition), a parallel iterative
algorithm that emulates SERENA in only $O(\log N)$ iterations between input
ports and output ports, and hence has a time complexity of only $O(\log N)$ per
port. We prove that SERENADE can exactly emulate SERENA. We also propose an
early-stop version of SERENADE, called O-SERENADE, to only approximately
emulate SERENA. Through extensive simulations, we show that O-SERENADE can
achieve 100\% throughput and that it has similar as or slightly better delay
performance than SERENA under various load conditions and traffic patterns.
-
Exact Maximum Inner Product Search (MIPS) is an important task that is widely
pertinent to recommender systems and high-dimensional similarity search. The
brute-force approach to solving exact MIPS is computationally expensive, thus
spurring recent development of novel indexes and pruning techniques for this
task. In this paper, we show that a hardware-efficient brute-force approach,
blocked matrix multiply (BMM), can outperform the state-of-the-art MIPS solvers
by over an order of magnitude, for some -- but not all -- inputs.
In this paper, we also present a novel MIPS solution, MAXIMUS, that takes
advantage of hardware efficiency and pruning of the search space. Like BMM,
MAXIMUS is faster than other solvers by up to an order of magnitude, but again
only for some inputs. Since no single solution offers the best runtime
performance for all inputs, we introduce a new data-dependent optimizer,
OPTIMUS, that selects online with minimal overhead the best MIPS solver for a
given input. Together, OPTIMUS and MAXIMUS outperform state-of-the-art MIPS
solvers by 3.2$\times$ on average, and up to 10.9$\times$, on widely studied
MIPS datasets.
-
We first consider the static problem of allocating resources to ( i.e. ,
scheduling) multiple distributed application framework s, possibly with
different priorities and server preferences , in a private cloud with
heterogeneous servers. Several fai r scheduling mechanisms have been proposed
for this purpose. We extend pr ior results on max-min and proportional fair
scheduling to t his constrained multiresource and multiserver case for generi c
fair scheduling criteria. The task efficiencies (a metric r elated to
proportional fairness) of max-min fair allocations found b y progressive
filling are compared by illustrative examples . They show that "server
specific" fairness criteria and those that are b ased on residual (unreserved)
resources are more efficient.
-
Motivated by recent concerns that queuing delays in the Internet are on the
rise, we conduct a performance evaluation of Compound TCP (C-TCP) in two
topologies: a single bottleneck and a multi-bottleneck topology, under
different traffic scenarios. The first topology consists of a single bottleneck
router, and the second consists of two distinct sets of TCP flows, regulated by
two edge routers, feeding into a common core router. We focus on some dynamical
and statistical properties of the underlying system. From a dynamical
perspective, we develop fluid models in a regime wherein the number of flows is
large, bandwidth-delay product is high, buffers are dimensioned small
(independent of the bandwidth-delay product) and routers deploy a Drop-Tail
queue policy. A detailed local stability analysis for these models yields the
following key insight: smaller buffers favour stability. Additionally, we
highlight that larger buffers, in addition to increasing latency, are prone to
inducing limit cycles in the system dynamics, via a Hopf bifurcation. These
limit cycles in turn cause synchronisation among the TCP flows, and also result
in a loss of link utilisation. For the topologies considered, we also
empirically analyse some statistical properties of the bottleneck queues. These
statistical analyses serve to validate an important modelling assumption: that
in the regime considered, each bottleneck queue may be approximated as either
an $M/M/1/B$ or an $M/D/1/B$ queue. This immediately makes the modelling
perspective attractive and the analysis tractable. Finally, we show that
smaller buffers, in addition to ensuring stability and low latency, would also
yield fairly good system performance, in terms of throughput and flow
completion times.
-
The field of machine programming (MP), the automation of the development of
software, is making notable research advances. This is, in part, due to the
emergence of a wide range of novel techniques in machine learning. In this
paper, we apply MP to the automation of software performance regression
testing. A performance regression is a software performance degradation caused
by a code change. We present AutoPerf - a novel approach to automate regression
testing that utilizes three core techniques: (i) zero-positive learning, (ii)
autoencoders, and (iii) hardware telemetry. We demonstrate AutoPerf's
generality and efficacy against 3 types of performance regressions across 10
real performance bugs in 7 benchmark and open-source programs. On average,
AutoPerf exhibits 4% profiling overhead and accurately diagnoses more
performance bugs than prior state-of-the-art approaches. Thus far, AutoPerf has
produced no false negatives.
-
Deep Neural Networks (DNNs) require very large amounts of computation both
for training and for inference when deployed in the field. Many different
algorithms have been proposed to implement the most computationally expensive
layers of DNNs. Further, each of these algorithms has a large number of
variants, which offer different trade-offs of parallelism, data locality,
memory footprint, and execution time. In addition, specific algorithms operate
much more efficiently on specialized data layouts and formats.
We state the problem of optimal primitive selection in the presence of data
format transformations, and show that it is NP-hard by demonstrating an
embedding in the Partitioned Boolean Quadratic Assignment problem (PBQP).
We propose an analytic solution via a PBQP solver, and evaluate our approach
experimentally by optimizing several popular DNNs using a library of more than
70 DNN primitives, on an embedded platform and a general purpose platform. We
show experimentally that significant gains are possible versus the state of the
art vendor libraries by using a principled analytic solution to the problem of
layout selection in the presence of data format transformations.
-
Ultra-reliable Point-to-Multipoint (PtM) communications are expected to
become pivotal in networks offering future dependable services for smart
cities. In this regard, sparse Random Linear Network Coding (RLNC) techniques
have been widely employed to provide an efficient way to improve the
reliability of broadcast and multicast data streams. This paper addresses the
pressing concern of providing a tight approximation to the probability of a
user recovering a data stream protected by this kind of coding technique. In
particular, by exploiting the Stein--Chen method, we provide a novel and
general performance framework applicable to any combination of system and
service parameters, such as finite field sizes, lengths of the data stream and
level of sparsity. The deviation of the proposed approximation from Monte Carlo
simulations is negligible, improving significantly on the state of the art
performance bounds.
-
The massive quantities of genomic data being made available through gene
sequencing techniques are enabling breakthroughs in genomic science in many
areas such as medical advances in the diagnosis and treatment of diseases.
Analyzing this data, however, is a computational challenge insofar as the
computational costs of the relevant algorithms can grow with quadratic, cubic
or higher complexity-leading to the need for leadership scale computing. In
this paper we describe a new approach to calculations of the Custom Correlation
Coefficient (CCC) between Single Nucleotide Polymorphisms (SNPs) across a
population, suitable for parallel systems equipped with graphics processing
units (GPUs) or Intel Xeon Phi processors. We describe the mapping of the
algorithms to accelerated processors, techniques used for eliminating redundant
calculations due to symmetries, and strategies for efficient mapping of the
calculations to many-node parallel systems. Results are presented demonstrating
high per-node performance and near-ideal parallel scalability with rates of
more than nine quadrillion elementwise comparisons achieved per second with the
latest optimized code on the ORNL Titan system, this being orders of magnitude
faster than rates achieved using other codes and platforms as reported in the
literature. Also it is estimated that as many as 90 quadrillion comparisons per
second may be achievable on the upcoming ORNL Summit system, an additional 10X
performance increase. In a companion paper we describe corresponding techniques
applied to calculations of the Proportional Similarity metric for comparative
genomics applications.
-
We study delay of jobs that consist of multiple parallel tasks, which is a
critical performance metric in a wide range of applications such as data file
retrieval in coded storage systems and parallel computing. In this problem,
each job is completed only when all of its tasks are completed, so the delay of
a job is the maximum of the delays of its tasks. Despite the wide attention
this problem has received, tight analysis is still largely unknown since
analyzing job delay requires characterizing the complicated correlation among
task delays, which is hard to do.
We first consider an asymptotic regime where the number of servers, $n$, goes
to infinity, and the number of tasks in a job, $k^{(n)}$, is allowed to
increase with $n$. We establish the asymptotic independence of any $k^{(n)}$
queues under the condition $k^{(n)} = o(n^{1/4})$. This greatly generalizes the
asymptotic-independence type of results in the literature where asymptotic
independence is shown only for a fixed constant number of queues. As a
consequence of our independence result, the job delay converges to the maximum
of independent task delays.
We next consider the non-asymptotic regime. Here we prove that independence
yields a stochastic upper bound on job delay for any $n$ and any $k^{(n)}$ with
$k^{(n)}\le n$. The key component of our proof is a new technique we develop,
called "Poisson oversampling". Our approach converts the job delay problem into
a corresponding balls-and-bins problem. However, in contrast with typical
balls-and-bins problems where there is a negative correlation among bins, we
prove that our variant exhibits positive correlation.
-
This paper presents a methodology for simulating the Internet of Things (IoT)
using multi-level simulation models. With respect to conventional simulators,
this approach allows us to tune the level of detail of different parts of the
model without compromising the scalability of the simulation. As a use case, we
have developed a two-level simulator to study the deployment of smart services
over rural territories. The higher level is base on a coarse grained,
agent-based adaptive parallel and distributed simulator. When needed, this
simulator spawns OMNeT++ model instances to evaluate in more detail the issues
concerned with wireless communications in restricted areas of the simulated
world. The performance evaluation confirms the viability of multi-level
simulations for IoT environments.
-
PageRank is a fundamental link analysis algorithm that also functions as a
key representative of the performance of Sparse Matrix-Vector (SpMV)
multiplication. The traditional PageRank implementation generates fine
granularity random memory accesses resulting in large amount of wasteful DRAM
traffic and poor bandwidth utilization. In this paper, we present a novel
Partition-Centric Processing Methodology (PCPM) to compute PageRank, that
drastically reduces the amount of DRAM communication while achieving high
sustained memory bandwidth. PCPM uses a Partition-centric abstraction coupled
with the Gather-Apply-Scatter (GAS) programming model. By carefully examining
how a PCPM based implementation impacts communication characteristics of the
algorithm, we propose several system optimizations that improve the execution
time substantially. More specifically, we develop (1) a new data layout that
significantly reduces communication and random DRAM accesses, and (2) branch
avoidance mechanisms to get rid of unpredictable data-dependent branches.
We perform detailed analytical and experimental evaluation of our approach
using 6 large graphs and demonstrate an average 2.7x speedup in execution time
and 1.7x reduction in communication volume, compared to the state-of-the-art.
We also show that unlike other GAS based implementations, PCPM is able to
further reduce main memory traffic by taking advantage of intelligent node
labeling that enhances locality. Although we use PageRank as the target
application in this paper, our approach can be applied to generic SpMV
computation.
-
The modeling and analysis of an LRU cache is extremely challenging as exact
results for the main performance metrics (e.g. hit rate) are either lacking or
cannot be used because of their high computational complexity for large caches.
As a result, various approximations have been proposed. The state-of-the-art
method is the so-called TTL approximation, first proposed and shown to be
asymptotically exact for IRM requests by Fagin. It has been applied to various
other workload models and numerically demonstrated to be accurate but without
theoretical justification. In this paper we provide theoretical justification
for the approximation in the case where distinct contents are described by
independent stationary and ergodic processes. We show that this approximation
is exact as the cache size and the number of contents go to infinity. This
extends earlier results for the independent reference model. Moreover, we
establish results not only for the aggregate cache hit probability but also for
every individual content. Last, we obtain bounds on the rate of convergence.
-
We present FLASH (\textbf{F}ast \textbf{L}SH \textbf{A}lgorithm for
\textbf{S}imilarity search accelerated with \textbf{H}PC), a similarity search
system for ultra-high dimensional datasets on a single machine, that does not
require similarity computations and is tailored for high-performance computing
platforms. By leveraging a LSH style randomized indexing procedure and
combining it with several principled techniques, such as reservoir sampling,
recent advances in one-pass minwise hashing, and count based estimations, we
reduce the computational and parallelization costs of similarity search, while
retaining sound theoretical guarantees.
We evaluate FLASH on several real, high-dimensional datasets from different
domains, including text, malicious URL, click-through prediction, social
networks, etc. Our experiments shed new light on the difficulties associated
with datasets having several million dimensions. Current state-of-the-art
implementations either fail on the presented scale or are orders of magnitude
slower than FLASH. FLASH is capable of computing an approximate k-NN graph,
from scratch, over the full webspam dataset (1.3 billion nonzeros) in less than
10 seconds. Computing a full k-NN graph in less than 10 seconds on the webspam
dataset, using brute-force ($n^2D$), will require at least 20 teraflops. We
provide CPU and GPU implementations of FLASH for replicability of our results.
-
The goal of privacy metrics is to measure the degree of privacy enjoyed by
users in a system and the amount of protection offered by privacy-enhancing
technologies. In this way, privacy metrics contribute to improving user privacy
in the digital world. The diversity and complexity of privacy metrics in the
literature makes an informed choice of metrics challenging. As a result,
instead of using existing metrics, new metrics are proposed frequently, and
privacy studies are often incomparable. In this survey we alleviate these
problems by structuring the landscape of privacy metrics. To this end, we
explain and discuss a selection of over eighty privacy metrics and introduce
categorizations based on the aspect of privacy they measure, their required
inputs, and the type of data that needs protection. In addition, we present a
method on how to choose privacy metrics based on nine questions that help
identify the right privacy metrics for a given scenario, and highlight topics
where additional work on privacy metrics is needed. Our survey spans multiple
privacy domains and can be understood as a general framework for privacy
measurement.
-
Web developers use base64 formats to include images, fonts, sounds and other
resources directly inside HTML, JavaScript, JSON and XML files. We estimate
that billions of base64 messages are decoded every day. We are motivated to
improve the efficiency of base64 encoding and decoding. Compared to
state-of-the-art implementations, we multiply the speeds of both the encoding
(~10x) and the decoding (~7x). We achieve these good results by using the
single-instruction-multiple-data (SIMD) instructions available on recent Intel
processors (AVX2). Our accelerated software abides by the specification and
reports errors when encountering characters outside of the base64 set. It is
available online as free software under a liberal license.
-
Graphics Processing Units (GPUs) support dynamic voltage and frequency
scaling (DVFS) in order to balance computational performance and energy
consumption. However, there still lacks simple and accurate performance
estimation of a given GPU kernel under different frequency settings on real
hardware, which is important to decide best frequency configuration for energy
saving. This paper reveals a fine-grained model to estimate the execution time
of GPU kernels with both core and memory frequency scaling. Over a 2.5x range
of both core and memory frequencies among 12 GPU kernels, our model achieves
accurate results (within 3.5\%) on real hardware. Compared with the cycle-level
simulators, our model only needs some simple micro-benchmark to extract a set
of hardware parameters and performance counters of the kernels to produce this
high accuracy.
-
Tightening performance bounds of ring networks with cyclic dependencies is
still an open problem in the literature. In this paper, we tackle such a
challenging issue based on Network Calculus. First, we review the conventional
timing approaches in the area and identify their main limitations, in terms of
delay bounds pessimism. Afterwards, we have introduced a new concept called Pay
Multiplexing Only at Convergence points (PMOC) to overcome such limitations.
PMOC considers the flow serialization phenomena along the flow path, by paying
the bursts of interfering flows only at the convergence points. The guaranteed
endto- end service curves under such a concept have been defined and proved for
mono-ring and multiple-ring networks, as well as under Arbitrary and Fixed
Priority multiplexing. A sensitivity analysis of the computed delay bounds for
mono and multiple-ring networks is conducted with respect to various flow and
network parameters, and their tightness is assessed in comparison with an
achievable worst-case delay. A noticeable enhancement of the delay bounds, thus
network resource efficiency and scalability, is highlighted under our proposal
with reference to conventional approaches. Finally, the efficiency of the PMOC
approach to provide timing guarantees is confirmed in the case of a realistic
avionics application.
-
Calibration is an important step towards building reliable IoT systems. For
example, accurate sensor reading requires ADC calibration, and power monitoring
chips must be calibrated before being used for measuring the energy consumption
of IoT devices. In this paper, we present ProCal, a low-cost, accurate, and
scalable power calibration tool. ProCal is a programmable platform which
provides dynamic voltage and current output for calibration. The basic idea is
to use a digital potentiometer connected to a parallel resistor network
controlled through digital switches. The resistance and output frequency of
ProCal is controlled by a software communicating with the board through the SPI
interface. Our design provides a simple synchronization mechanism which
prevents the need for accurate time synchronization. We present mathematical
modeling and validation of the tool by incorporating the concept of Fibonacci
sequence. Our extensive experimental studies show that this tool can
significantly improve measurement accuracy. For example, for ATMega2560, the
ADC error reduces from 0.2% to 0.01%. ProCal not only costs less than 2\% of
the current commercial solutions, it is also highly accurate by being able to
provide extensive range of current and voltage values.
-
The recent ground-breaking advances in deep learning networks ( DNNs ) make
them attractive for embedded systems. However, it can take a long time for DNNs
to make an inference on resource-limited embedded devices. Offloading the
computation into the cloud is often infeasible due to privacy concerns, high
latency, or the lack of connectivity. As such, there is a critical need to find
a way to effectively execute the DNN models locally on the devices. This paper
presents an adaptive scheme to determine which DNN model to use for a given
input, by considering the desired accuracy and inference time. Our approach
employs machine learning to develop a predictive model to quickly select a
pre-trained DNN to use for a given input and the optimization constraint. We
achieve this by first training off-line a predictive model, and then use the
learnt model to select a DNN model to use for new, unseen inputs. We apply our
approach to the image classification task and evaluate it on a Jetson TX2
embedded deep learning platform using the ImageNet ILSVRC 2012 validation
dataset. We consider a range of influential DNN models. Experimental results
show that our approach achieves a 7.52% improvement in inference accuracy, and
a 1.8x reduction in inference time over the most-capable single DNN model.
-
A key enabler for the emerging autonomous and cooperative driving services is
high-throughput and reliable Vehicle-to-Network (V2N) communication. In this
respect, the millimeter wave (mmWave) frequencies hold great promises because
of the large available bandwidth which may provide the required link capacity.
However, this potential is hindered by the challenging propagation
characteristics of high-frequency channels and the dynamic topology of the
vehicular scenarios, which affect the reliability of the connection. Moreover,
mmWave transmissions typically leverage beamforming gain to compensate for the
increased path loss experienced at high frequencies. This, however, requires
fine alignment of the transmitting and receiving beams, which may be difficult
in vehicular scenarios. Those limitations may undermine the performance of V2N
communications and pose new challenges for proper vehicular communication
design. In this paper, we study by simulation the practical feasibility of some
mmWave-aware strategies to support V2N, in comparison to the traditional LTE
connectivity below 6 GHz. The results show that the orchestration among
different radios represents a viable solution to enable both high-capacity and
robust V2N communications.
-
A discrete-event simulation (DES) involves the execution of a sequence of
event handlers dynamically scheduled at runtime. As a consequence, a priori
knowledge of the control flow of the overall simulation program is limited. In
particular, powerful optimizations supported by modern compilers can only be
applied on the scope of individual event handlers, which frequently involve
only a few lines of code. We propose a method that extends the scope for
compiler optimizations in discrete-event simulations by generating batches of
multiple events that are subjected to compiler optimizations as contiguous
procedures. A runtime mechanism executes suitable batches at negligible
overhead. Our method does not require any compiler extensions and introduces
only minor additional effort during model development. The feasibility and
potential performance gains of the approach are illustrated on the example of
an idealized proof-ofconcept model. We believe that the applicability of the
approach extends to general event-driven programs.
-
Linear algebraic expressions are the essence of many computationally
intensive problems, including scientific simulations and machine learning
applications. However, translating high-level formulations of these expressions
to efficient machine-level representations is far from trivial: developers
should be assisted by automatic optimization tools so that they can focus their
attention on high-level problems, rather than low-level details. The
tractability of these optimizations is highly dependent on the choice of the
primitive constructs in terms of which the computations are to be expressed. In
this work we propose to describe operations on multi-dimensional arrays using a
selection of higher-order functions, inspired by functional programming, and we
present rewrite rules for these such that they can be automatically optimized
for modern hierarchical and heterogeneous architectures. Using this formalism
we systematically construct and analyse different subdivisions and permutations
of the dense matrix multiplication problem.
-
The sparse matrix-vector product (SpMV) is a fundamental operation in many
scientific applications from various fields. The High Performance Computing
(HPC) community has therefore continuously invested a lot of effort to provide
an efficient SpMV kernel on modern CPU architectures. Although it has been
shown that block-based kernels help to achieve high performance, they are
difficult to use in practice because of the zero padding they require. In the
current paper, we propose new kernels using the AVX-512 instruction set, which
makes it possible to use a blocking scheme without any zero padding in the
matrix memory storage. We describe mask-based sparse matrix formats and their
corresponding SpMV kernels highly optimized in assembly language. Considering
that the optimal blocking size depends on the matrix, we also provide a method
to predict the best kernel to be used utilizing a simple interpolation of
results from previous executions. We compare the performance of our approach to
that of the Intel MKL CSR kernel and the CSR5 open-source package on a set of
standard benchmark matrices. We show that we can achieve significant
improvements in many cases, both for sequential and for parallel executions.
Finally, we provide the corresponding code in an open source library, called
SPC5.
-
For reasons of both performance and energy efficiency, high-performance
computing (HPC) hardware is becoming increasingly heterogeneous. The OpenCL
framework supports portable programming across a wide range of computing
devices and is gaining influence in programming next-generation accelerators.
To characterize the performance of these devices across a range of applications
requires a diverse, portable and configurable benchmark suite, and OpenCL is an
attractive programming model for this purpose. We present an extended and
enhanced version of the OpenDwarfs OpenCL benchmark suite, with a strong focus
placed on the robustness of applications, curation of additional benchmarks
with an increased emphasis on correctness of results and choice of problem
size. Preliminary results and analysis are reported for eight benchmark codes
on a diverse set of architectures -- three Intel CPUs, five Nvidia GPUs, six
AMD GPUs and a Xeon Phi.
-
We study a parallel queueing system with multiple types of servers and
customers. A bipartite graph describes which pairs of customer-server types are
compatible. We consider the service policy that always assigns servers to the
first, longest waiting compatible customer, and that always assigns customers
to the longest idle compatible server if on arrival, multiple compatible
servers are available. For a general renewal stream of arriving customers and
general service time distributions, the behavior of such systems is very
complicated. In particular, the calculation of matching rates, the fraction of
services of customer-server type, is intractable. We suggest through a
heuristic argument that if the number of servers becomes large, the matching
rates are well approximated by matching rates calculated from the tractable
bipartite infinite matching model. We present simulation evidence to support
this heuristic argument, and show how this can be used to design systems with
desired performance requirements.





 Most of today's high-speed switches and routers adopt an input-queued crossbar switch architecture. Such a switch needs to compute a matching (crossbar schedule) between the input ports and output ports during each switching cycle (time slot). A key research challenge in designing large (in number of input/output ports $N$) input-queued crossbar switches is to develop crossbar scheduling algorithms that can compute "high quality" matchings -- i.e., those that result in high switch throughput (ideally $100\%$) and low queueing delays for packets -- at line rates. SERENA is one such algorithm: it outputs excellent matching decisions that result in $100\%$ switch throughput and reasonably good queueing delays. However, since SERENA is a centralized algorithm with $O(N)$ computational complexity, it cannot support switches that both are large and have a very high line rate per port. In this work, we propose SERENADE (SERENA, the Distributed Edition), a parallel iterative algorithm that emulates SERENA in only $O(\log N)$ iterations between input ports and output ports, and hence has a time complexity of only $O(\log N)$ per port. We prove that SERENADE can exactly emulate SERENA. We also propose an early-stop version of SERENADE, called O-SERENADE, to only approximately emulate SERENA. Through extensive simulations, we show that O-SERENADE can achieve 100\% throughput and that it has similar as or slightly better delay performance than SERENA under various load conditions and traffic patterns.
Most of today's high-speed switches and routers adopt an input-queued crossbar switch architecture. Such a switch needs to compute a matching (crossbar schedule) between the input ports and output ports during each switching cycle (time slot). A key research challenge in designing large (in number of input/output ports $N$) input-queued crossbar switches is to develop crossbar scheduling algorithms that can compute "high quality" matchings -- i.e., those that result in high switch throughput (ideally $100\%$) and low queueing delays for packets -- at line rates. SERENA is one such algorithm: it outputs excellent matching decisions that result in $100\%$ switch throughput and reasonably good queueing delays. However, since SERENA is a centralized algorithm with $O(N)$ computational complexity, it cannot support switches that both are large and have a very high line rate per port. In this work, we propose SERENADE (SERENA, the Distributed Edition), a parallel iterative algorithm that emulates SERENA in only $O(\log N)$ iterations between input ports and output ports, and hence has a time complexity of only $O(\log N)$ per port. We prove that SERENADE can exactly emulate SERENA. We also propose an early-stop version of SERENADE, called O-SERENADE, to only approximately emulate SERENA. Through extensive simulations, we show that O-SERENADE can achieve 100\% throughput and that it has similar as or slightly better delay performance than SERENA under various load conditions and traffic patterns.




 Exact Maximum Inner Product Search (MIPS) is an important task that is widely pertinent to recommender systems and high-dimensional similarity search. The brute-force approach to solving exact MIPS is computationally expensive, thus spurring recent development of novel indexes and pruning techniques for this task. In this paper, we show that a hardware-efficient brute-force approach, blocked matrix multiply (BMM), can outperform the state-of-the-art MIPS solvers by over an order of magnitude, for some -- but not all -- inputs. In this paper, we also present a novel MIPS solution, MAXIMUS, that takes advantage of hardware efficiency and pruning of the search space. Like BMM, MAXIMUS is faster than other solvers by up to an order of magnitude, but again only for some inputs. Since no single solution offers the best runtime performance for all inputs, we introduce a new data-dependent optimizer, OPTIMUS, that selects online with minimal overhead the best MIPS solver for a given input. Together, OPTIMUS and MAXIMUS outperform state-of-the-art MIPS solvers by 3.2$\times$ on average, and up to 10.9$\times$, on widely studied MIPS datasets.
Exact Maximum Inner Product Search (MIPS) is an important task that is widely pertinent to recommender systems and high-dimensional similarity search. The brute-force approach to solving exact MIPS is computationally expensive, thus spurring recent development of novel indexes and pruning techniques for this task. In this paper, we show that a hardware-efficient brute-force approach, blocked matrix multiply (BMM), can outperform the state-of-the-art MIPS solvers by over an order of magnitude, for some -- but not all -- inputs. In this paper, we also present a novel MIPS solution, MAXIMUS, that takes advantage of hardware efficiency and pruning of the search space. Like BMM, MAXIMUS is faster than other solvers by up to an order of magnitude, but again only for some inputs. Since no single solution offers the best runtime performance for all inputs, we introduce a new data-dependent optimizer, OPTIMUS, that selects online with minimal overhead the best MIPS solver for a given input. Together, OPTIMUS and MAXIMUS outperform state-of-the-art MIPS solvers by 3.2$\times$ on average, and up to 10.9$\times$, on widely studied MIPS datasets.




 We first consider the static problem of allocating resources to ( i.e. , scheduling) multiple distributed application framework s, possibly with different priorities and server preferences , in a private cloud with heterogeneous servers. Several fai r scheduling mechanisms have been proposed for this purpose. We extend pr ior results on max-min and proportional fair scheduling to t his constrained multiresource and multiserver case for generi c fair scheduling criteria. The task efficiencies (a metric r elated to proportional fairness) of max-min fair allocations found b y progressive filling are compared by illustrative examples . They show that "server specific" fairness criteria and those that are b ased on residual (unreserved) resources are more efficient.
We first consider the static problem of allocating resources to ( i.e. , scheduling) multiple distributed application framework s, possibly with different priorities and server preferences , in a private cloud with heterogeneous servers. Several fai r scheduling mechanisms have been proposed for this purpose. We extend pr ior results on max-min and proportional fair scheduling to t his constrained multiresource and multiserver case for generi c fair scheduling criteria. The task efficiencies (a metric r elated to proportional fairness) of max-min fair allocations found b y progressive filling are compared by illustrative examples . They show that "server specific" fairness criteria and those that are b ased on residual (unreserved) resources are more efficient.




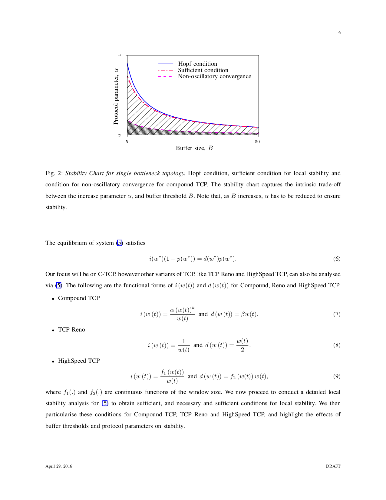 Motivated by recent concerns that queuing delays in the Internet are on the rise, we conduct a performance evaluation of Compound TCP (C-TCP) in two topologies: a single bottleneck and a multi-bottleneck topology, under different traffic scenarios. The first topology consists of a single bottleneck router, and the second consists of two distinct sets of TCP flows, regulated by two edge routers, feeding into a common core router. We focus on some dynamical and statistical properties of the underlying system. From a dynamical perspective, we develop fluid models in a regime wherein the number of flows is large, bandwidth-delay product is high, buffers are dimensioned small (independent of the bandwidth-delay product) and routers deploy a Drop-Tail queue policy. A detailed local stability analysis for these models yields the following key insight: smaller buffers favour stability. Additionally, we highlight that larger buffers, in addition to increasing latency, are prone to inducing limit cycles in the system dynamics, via a Hopf bifurcation. These limit cycles in turn cause synchronisation among the TCP flows, and also result in a loss of link utilisation. For the topologies considered, we also empirically analyse some statistical properties of the bottleneck queues. These statistical analyses serve to validate an important modelling assumption: that in the regime considered, each bottleneck queue may be approximated as either an $M/M/1/B$ or an $M/D/1/B$ queue. This immediately makes the modelling perspective attractive and the analysis tractable. Finally, we show that smaller buffers, in addition to ensuring stability and low latency, would also yield fairly good system performance, in terms of throughput and flow completion times.
Motivated by recent concerns that queuing delays in the Internet are on the rise, we conduct a performance evaluation of Compound TCP (C-TCP) in two topologies: a single bottleneck and a multi-bottleneck topology, under different traffic scenarios. The first topology consists of a single bottleneck router, and the second consists of two distinct sets of TCP flows, regulated by two edge routers, feeding into a common core router. We focus on some dynamical and statistical properties of the underlying system. From a dynamical perspective, we develop fluid models in a regime wherein the number of flows is large, bandwidth-delay product is high, buffers are dimensioned small (independent of the bandwidth-delay product) and routers deploy a Drop-Tail queue policy. A detailed local stability analysis for these models yields the following key insight: smaller buffers favour stability. Additionally, we highlight that larger buffers, in addition to increasing latency, are prone to inducing limit cycles in the system dynamics, via a Hopf bifurcation. These limit cycles in turn cause synchronisation among the TCP flows, and also result in a loss of link utilisation. For the topologies considered, we also empirically analyse some statistical properties of the bottleneck queues. These statistical analyses serve to validate an important modelling assumption: that in the regime considered, each bottleneck queue may be approximated as either an $M/M/1/B$ or an $M/D/1/B$ queue. This immediately makes the modelling perspective attractive and the analysis tractable. Finally, we show that smaller buffers, in addition to ensuring stability and low latency, would also yield fairly good system performance, in terms of throughput and flow completion times.


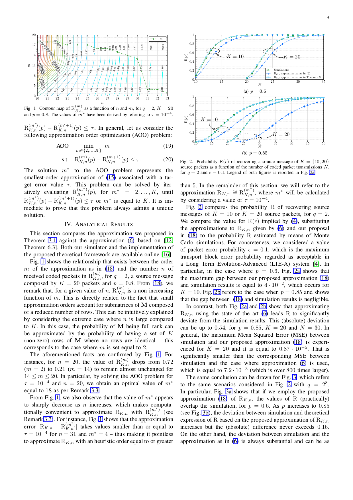
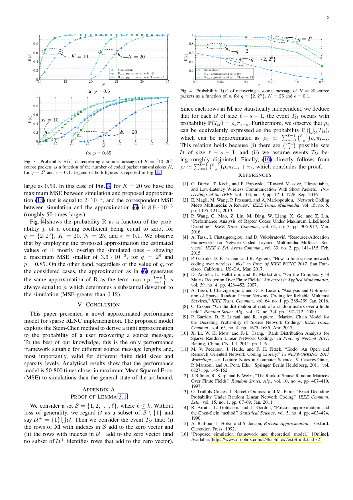
 Ultra-reliable Point-to-Multipoint (PtM) communications are expected to become pivotal in networks offering future dependable services for smart cities. In this regard, sparse Random Linear Network Coding (RLNC) techniques have been widely employed to provide an efficient way to improve the reliability of broadcast and multicast data streams. This paper addresses the pressing concern of providing a tight approximation to the probability of a user recovering a data stream protected by this kind of coding technique. In particular, by exploiting the Stein--Chen method, we provide a novel and general performance framework applicable to any combination of system and service parameters, such as finite field sizes, lengths of the data stream and level of sparsity. The deviation of the proposed approximation from Monte Carlo simulations is negligible, improving significantly on the state of the art performance bounds.
Ultra-reliable Point-to-Multipoint (PtM) communications are expected to become pivotal in networks offering future dependable services for smart cities. In this regard, sparse Random Linear Network Coding (RLNC) techniques have been widely employed to provide an efficient way to improve the reliability of broadcast and multicast data streams. This paper addresses the pressing concern of providing a tight approximation to the probability of a user recovering a data stream protected by this kind of coding technique. In particular, by exploiting the Stein--Chen method, we provide a novel and general performance framework applicable to any combination of system and service parameters, such as finite field sizes, lengths of the data stream and level of sparsity. The deviation of the proposed approximation from Monte Carlo simulations is negligible, improving significantly on the state of the art performance bounds.


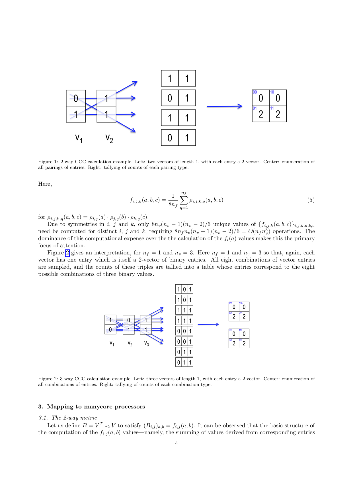

 The massive quantities of genomic data being made available through gene sequencing techniques are enabling breakthroughs in genomic science in many areas such as medical advances in the diagnosis and treatment of diseases. Analyzing this data, however, is a computational challenge insofar as the computational costs of the relevant algorithms can grow with quadratic, cubic or higher complexity-leading to the need for leadership scale computing. In this paper we describe a new approach to calculations of the Custom Correlation Coefficient (CCC) between Single Nucleotide Polymorphisms (SNPs) across a population, suitable for parallel systems equipped with graphics processing units (GPUs) or Intel Xeon Phi processors. We describe the mapping of the algorithms to accelerated processors, techniques used for eliminating redundant calculations due to symmetries, and strategies for efficient mapping of the calculations to many-node parallel systems. Results are presented demonstrating high per-node performance and near-ideal parallel scalability with rates of more than nine quadrillion elementwise comparisons achieved per second with the latest optimized code on the ORNL Titan system, this being orders of magnitude faster than rates achieved using other codes and platforms as reported in the literature. Also it is estimated that as many as 90 quadrillion comparisons per second may be achievable on the upcoming ORNL Summit system, an additional 10X performance increase. In a companion paper we describe corresponding techniques applied to calculations of the Proportional Similarity metric for comparative genomics applications.
The massive quantities of genomic data being made available through gene sequencing techniques are enabling breakthroughs in genomic science in many areas such as medical advances in the diagnosis and treatment of diseases. Analyzing this data, however, is a computational challenge insofar as the computational costs of the relevant algorithms can grow with quadratic, cubic or higher complexity-leading to the need for leadership scale computing. In this paper we describe a new approach to calculations of the Custom Correlation Coefficient (CCC) between Single Nucleotide Polymorphisms (SNPs) across a population, suitable for parallel systems equipped with graphics processing units (GPUs) or Intel Xeon Phi processors. We describe the mapping of the algorithms to accelerated processors, techniques used for eliminating redundant calculations due to symmetries, and strategies for efficient mapping of the calculations to many-node parallel systems. Results are presented demonstrating high per-node performance and near-ideal parallel scalability with rates of more than nine quadrillion elementwise comparisons achieved per second with the latest optimized code on the ORNL Titan system, this being orders of magnitude faster than rates achieved using other codes and platforms as reported in the literature. Also it is estimated that as many as 90 quadrillion comparisons per second may be achievable on the upcoming ORNL Summit system, an additional 10X performance increase. In a companion paper we describe corresponding techniques applied to calculations of the Proportional Similarity metric for comparative genomics applications.




 The modeling and analysis of an LRU cache is extremely challenging as exact results for the main performance metrics (e.g. hit rate) are either lacking or cannot be used because of their high computational complexity for large caches. As a result, various approximations have been proposed. The state-of-the-art method is the so-called TTL approximation, first proposed and shown to be asymptotically exact for IRM requests by Fagin. It has been applied to various other workload models and numerically demonstrated to be accurate but without theoretical justification. In this paper we provide theoretical justification for the approximation in the case where distinct contents are described by independent stationary and ergodic processes. We show that this approximation is exact as the cache size and the number of contents go to infinity. This extends earlier results for the independent reference model. Moreover, we establish results not only for the aggregate cache hit probability but also for every individual content. Last, we obtain bounds on the rate of convergence.
The modeling and analysis of an LRU cache is extremely challenging as exact results for the main performance metrics (e.g. hit rate) are either lacking or cannot be used because of their high computational complexity for large caches. As a result, various approximations have been proposed. The state-of-the-art method is the so-called TTL approximation, first proposed and shown to be asymptotically exact for IRM requests by Fagin. It has been applied to various other workload models and numerically demonstrated to be accurate but without theoretical justification. In this paper we provide theoretical justification for the approximation in the case where distinct contents are described by independent stationary and ergodic processes. We show that this approximation is exact as the cache size and the number of contents go to infinity. This extends earlier results for the independent reference model. Moreover, we establish results not only for the aggregate cache hit probability but also for every individual content. Last, we obtain bounds on the rate of convergence.




 The goal of privacy metrics is to measure the degree of privacy enjoyed by users in a system and the amount of protection offered by privacy-enhancing technologies. In this way, privacy metrics contribute to improving user privacy in the digital world. The diversity and complexity of privacy metrics in the literature makes an informed choice of metrics challenging. As a result, instead of using existing metrics, new metrics are proposed frequently, and privacy studies are often incomparable. In this survey we alleviate these problems by structuring the landscape of privacy metrics. To this end, we explain and discuss a selection of over eighty privacy metrics and introduce categorizations based on the aspect of privacy they measure, their required inputs, and the type of data that needs protection. In addition, we present a method on how to choose privacy metrics based on nine questions that help identify the right privacy metrics for a given scenario, and highlight topics where additional work on privacy metrics is needed. Our survey spans multiple privacy domains and can be understood as a general framework for privacy measurement.
The goal of privacy metrics is to measure the degree of privacy enjoyed by users in a system and the amount of protection offered by privacy-enhancing technologies. In this way, privacy metrics contribute to improving user privacy in the digital world. The diversity and complexity of privacy metrics in the literature makes an informed choice of metrics challenging. As a result, instead of using existing metrics, new metrics are proposed frequently, and privacy studies are often incomparable. In this survey we alleviate these problems by structuring the landscape of privacy metrics. To this end, we explain and discuss a selection of over eighty privacy metrics and introduce categorizations based on the aspect of privacy they measure, their required inputs, and the type of data that needs protection. In addition, we present a method on how to choose privacy metrics based on nine questions that help identify the right privacy metrics for a given scenario, and highlight topics where additional work on privacy metrics is needed. Our survey spans multiple privacy domains and can be understood as a general framework for privacy measurement.




 Web developers use base64 formats to include images, fonts, sounds and other resources directly inside HTML, JavaScript, JSON and XML files. We estimate that billions of base64 messages are decoded every day. We are motivated to improve the efficiency of base64 encoding and decoding. Compared to state-of-the-art implementations, we multiply the speeds of both the encoding (~10x) and the decoding (~7x). We achieve these good results by using the single-instruction-multiple-data (SIMD) instructions available on recent Intel processors (AVX2). Our accelerated software abides by the specification and reports errors when encountering characters outside of the base64 set. It is available online as free software under a liberal license.
Web developers use base64 formats to include images, fonts, sounds and other resources directly inside HTML, JavaScript, JSON and XML files. We estimate that billions of base64 messages are decoded every day. We are motivated to improve the efficiency of base64 encoding and decoding. Compared to state-of-the-art implementations, we multiply the speeds of both the encoding (~10x) and the decoding (~7x). We achieve these good results by using the single-instruction-multiple-data (SIMD) instructions available on recent Intel processors (AVX2). Our accelerated software abides by the specification and reports errors when encountering characters outside of the base64 set. It is available online as free software under a liberal license.

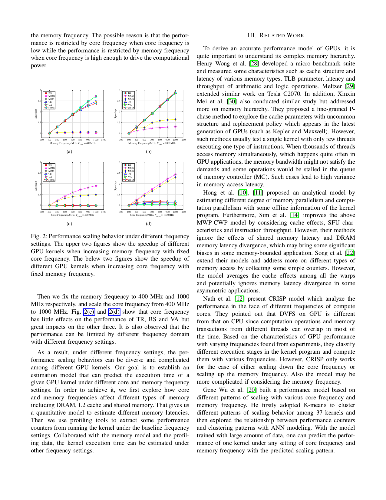
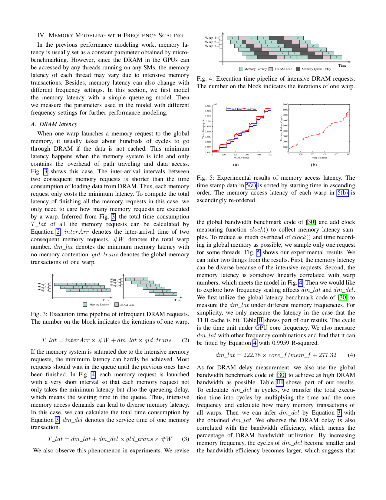

 Graphics Processing Units (GPUs) support dynamic voltage and frequency scaling (DVFS) in order to balance computational performance and energy consumption. However, there still lacks simple and accurate performance estimation of a given GPU kernel under different frequency settings on real hardware, which is important to decide best frequency configuration for energy saving. This paper reveals a fine-grained model to estimate the execution time of GPU kernels with both core and memory frequency scaling. Over a 2.5x range of both core and memory frequencies among 12 GPU kernels, our model achieves accurate results (within 3.5\%) on real hardware. Compared with the cycle-level simulators, our model only needs some simple micro-benchmark to extract a set of hardware parameters and performance counters of the kernels to produce this high accuracy.
Graphics Processing Units (GPUs) support dynamic voltage and frequency scaling (DVFS) in order to balance computational performance and energy consumption. However, there still lacks simple and accurate performance estimation of a given GPU kernel under different frequency settings on real hardware, which is important to decide best frequency configuration for energy saving. This paper reveals a fine-grained model to estimate the execution time of GPU kernels with both core and memory frequency scaling. Over a 2.5x range of both core and memory frequencies among 12 GPU kernels, our model achieves accurate results (within 3.5\%) on real hardware. Compared with the cycle-level simulators, our model only needs some simple micro-benchmark to extract a set of hardware parameters and performance counters of the kernels to produce this high accuracy.




 Tightening performance bounds of ring networks with cyclic dependencies is still an open problem in the literature. In this paper, we tackle such a challenging issue based on Network Calculus. First, we review the conventional timing approaches in the area and identify their main limitations, in terms of delay bounds pessimism. Afterwards, we have introduced a new concept called Pay Multiplexing Only at Convergence points (PMOC) to overcome such limitations. PMOC considers the flow serialization phenomena along the flow path, by paying the bursts of interfering flows only at the convergence points. The guaranteed endto- end service curves under such a concept have been defined and proved for mono-ring and multiple-ring networks, as well as under Arbitrary and Fixed Priority multiplexing. A sensitivity analysis of the computed delay bounds for mono and multiple-ring networks is conducted with respect to various flow and network parameters, and their tightness is assessed in comparison with an achievable worst-case delay. A noticeable enhancement of the delay bounds, thus network resource efficiency and scalability, is highlighted under our proposal with reference to conventional approaches. Finally, the efficiency of the PMOC approach to provide timing guarantees is confirmed in the case of a realistic avionics application.
Tightening performance bounds of ring networks with cyclic dependencies is still an open problem in the literature. In this paper, we tackle such a challenging issue based on Network Calculus. First, we review the conventional timing approaches in the area and identify their main limitations, in terms of delay bounds pessimism. Afterwards, we have introduced a new concept called Pay Multiplexing Only at Convergence points (PMOC) to overcome such limitations. PMOC considers the flow serialization phenomena along the flow path, by paying the bursts of interfering flows only at the convergence points. The guaranteed endto- end service curves under such a concept have been defined and proved for mono-ring and multiple-ring networks, as well as under Arbitrary and Fixed Priority multiplexing. A sensitivity analysis of the computed delay bounds for mono and multiple-ring networks is conducted with respect to various flow and network parameters, and their tightness is assessed in comparison with an achievable worst-case delay. A noticeable enhancement of the delay bounds, thus network resource efficiency and scalability, is highlighted under our proposal with reference to conventional approaches. Finally, the efficiency of the PMOC approach to provide timing guarantees is confirmed in the case of a realistic avionics application.




 The sparse matrix-vector product (SpMV) is a fundamental operation in many scientific applications from various fields. The High Performance Computing (HPC) community has therefore continuously invested a lot of effort to provide an efficient SpMV kernel on modern CPU architectures. Although it has been shown that block-based kernels help to achieve high performance, they are difficult to use in practice because of the zero padding they require. In the current paper, we propose new kernels using the AVX-512 instruction set, which makes it possible to use a blocking scheme without any zero padding in the matrix memory storage. We describe mask-based sparse matrix formats and their corresponding SpMV kernels highly optimized in assembly language. Considering that the optimal blocking size depends on the matrix, we also provide a method to predict the best kernel to be used utilizing a simple interpolation of results from previous executions. We compare the performance of our approach to that of the Intel MKL CSR kernel and the CSR5 open-source package on a set of standard benchmark matrices. We show that we can achieve significant improvements in many cases, both for sequential and for parallel executions. Finally, we provide the corresponding code in an open source library, called SPC5.
The sparse matrix-vector product (SpMV) is a fundamental operation in many scientific applications from various fields. The High Performance Computing (HPC) community has therefore continuously invested a lot of effort to provide an efficient SpMV kernel on modern CPU architectures. Although it has been shown that block-based kernels help to achieve high performance, they are difficult to use in practice because of the zero padding they require. In the current paper, we propose new kernels using the AVX-512 instruction set, which makes it possible to use a blocking scheme without any zero padding in the matrix memory storage. We describe mask-based sparse matrix formats and their corresponding SpMV kernels highly optimized in assembly language. Considering that the optimal blocking size depends on the matrix, we also provide a method to predict the best kernel to be used utilizing a simple interpolation of results from previous executions. We compare the performance of our approach to that of the Intel MKL CSR kernel and the CSR5 open-source package on a set of standard benchmark matrices. We show that we can achieve significant improvements in many cases, both for sequential and for parallel executions. Finally, we provide the corresponding code in an open source library, called SPC5.




 We study a parallel queueing system with multiple types of servers and customers. A bipartite graph describes which pairs of customer-server types are compatible. We consider the service policy that always assigns servers to the first, longest waiting compatible customer, and that always assigns customers to the longest idle compatible server if on arrival, multiple compatible servers are available. For a general renewal stream of arriving customers and general service time distributions, the behavior of such systems is very complicated. In particular, the calculation of matching rates, the fraction of services of customer-server type, is intractable. We suggest through a heuristic argument that if the number of servers becomes large, the matching rates are well approximated by matching rates calculated from the tractable bipartite infinite matching model. We present simulation evidence to support this heuristic argument, and show how this can be used to design systems with desired performance requirements.
We study a parallel queueing system with multiple types of servers and customers. A bipartite graph describes which pairs of customer-server types are compatible. We consider the service policy that always assigns servers to the first, longest waiting compatible customer, and that always assigns customers to the longest idle compatible server if on arrival, multiple compatible servers are available. For a general renewal stream of arriving customers and general service time distributions, the behavior of such systems is very complicated. In particular, the calculation of matching rates, the fraction of services of customer-server type, is intractable. We suggest through a heuristic argument that if the number of servers becomes large, the matching rates are well approximated by matching rates calculated from the tractable bipartite infinite matching model. We present simulation evidence to support this heuristic argument, and show how this can be used to design systems with desired performance requirements.