-
Computer networks have become a critical infrastructure. In fact, networks
should not only meet strict requirements in terms of correctness, availability,
and performance, but they should also be very flexible and support fast
updates, e.g., due to policy changes, increasing traffic, or failures. This
paper presents a structured survey of mechanism and protocols to update
computer networks in a fast and consistent manner. In particular, we identify
and discuss the different desirable consistency properties that should be
provided throughout a network update, the algorithmic techniques which are
needed to meet these consistency properties, and the implications on the speed
and costs at which updates can be performed. We also explain the relationship
between consistent network update problems and classic algorithmic optimization
ones. While our survey is mainly motivated by the advent of Software-Defined
Networks (SDNs) and their primary need for correct and efficient update
techniques, the fundamental underlying problems are not new, and we provide a
historical perspective of the subject as well.
-
Software Transactional Memory systems (STMs) have garnered significant
interest as an elegant alternative for addressing synchronization and
concurrency issues with multi-threaded programming in multi-core systems.
Client programs use STMs by issuing transactions. STM ensures that transaction
either commits or aborts. A transaction aborted due to conflicts is typically
re-issued with the expectation that it will complete successfully in a
subsequent incarnation. However, many existing STMs fail to provide starvation
freedom, i.e., in these systems, it is possible that concurrency conflicts may
prevent an incarnated transaction from committing. To overcome this limitation,
we systematically derive a novel starvation free algorithm for multi-version
STM. Our algorithm can be used either with the case where the number of
versions is unbounded and garbage collection is used or where only the latest K
versions are maintained, KSFTM. We have demonstrated that our proposed
algorithm performs better than existing state-of-the-art STMs.
-
Distributed machine learning algorithms enable learning of models from
datasets that are distributed over a network without gathering the data at a
centralized location. While efficient distributed algorithms have been
developed under the assumption of faultless networks, failures that can render
these algorithms nonfunctional occur frequently in the real world. This paper
focuses on the problem of Byzantine failures, which are the hardest to
safeguard against in distributed algorithms. While Byzantine fault tolerance
has a rich history, existing work does not translate into efficient and
practical algorithms for high-dimensional learning in fully distributed (also
known as decentralized) settings. In this paper, an algorithm termed
Byzantine-resilient distributed coordinate descent (ByRDiE) is developed and
analyzed that enables distributed learning in the presence of Byzantine
failures. Theoretical analysis (convex settings) and numerical experiments
(convex and nonconvex settings) highlight its usefulness for high-dimensional
distributed learning in the presence of Byzantine failures.
-
Accelerator architectures specialize in executing SIMD (single instruction,
multiple data) in lockstep. Because the majority of CUDA applications are
parallelized loops, control flow information can provide an in-depth
characterization of a kernel. CUDAflow is a tool that statically separates CUDA
binaries into basic block regions and dynamically measures instruction and
basic block frequencies. CUDAflow captures this information in a control flow
graph (CFG) and performs subgraph matching across various kernel's CFGs to gain
insights to an application's resource requirements, based on the shape and
traversal of the graph, instruction operations executed and registers
allocated, among other information. The utility of CUDAflow is demonstrated
with SHOC and Rodinia application case studies on a variety of GPU
architectures, revealing novel thread divergence characteristics that
facilitates end users, autotuners and compilers in generating high performing
code.
-
Analyzing massive complex networks yields promising insights about our
everyday lives. Building scalable algorithms to do so is a challenging task
that requires a careful analysis and an extensive evaluation. However,
engineering such algorithms is often hindered by the scarcity of
publicly~available~datasets.
Network generators serve as a tool to alleviate this problem by providing
synthetic instances with controllable parameters. However, many network
generators fail to provide instances on a massive scale due to their sequential
nature or resource constraints. Additionally, truly scalable network generators
are few and often limited in their realism.
In this work, we present novel generators for a variety of network models
that are frequently used as benchmarks. By making use of pseudorandomization
and divide-and-conquer schemes, our generators follow a communication-free
paradigm. The resulting generators are thus embarrassingly parallel and have a
near optimal scaling behavior. This allows us to generate instances of up to
$2^{43}$ vertices and $2^{47}$ edges in less than 22 minutes on 32768 cores.
Therefore, our generators allow new graph families to be used on an
unprecedented scale.
-
Most of today's high-speed switches and routers adopt an input-queued
crossbar switch architecture. Such a switch needs to compute a matching
(crossbar schedule) between the input ports and output ports during each
switching cycle (time slot). A key research challenge in designing large (in
number of input/output ports $N$) input-queued crossbar switches is to develop
crossbar scheduling algorithms that can compute "high quality" matchings --
i.e., those that result in high switch throughput (ideally $100\%$) and low
queueing delays for packets -- at line rates. SERENA is one such algorithm: it
outputs excellent matching decisions that result in $100\%$ switch throughput
and reasonably good queueing delays. However, since SERENA is a centralized
algorithm with $O(N)$ computational complexity, it cannot support switches that
both are large and have a very high line rate per port. In this work, we
propose SERENADE (SERENA, the Distributed Edition), a parallel iterative
algorithm that emulates SERENA in only $O(\log N)$ iterations between input
ports and output ports, and hence has a time complexity of only $O(\log N)$ per
port. We prove that SERENADE can exactly emulate SERENA. We also propose an
early-stop version of SERENADE, called O-SERENADE, to only approximately
emulate SERENA. Through extensive simulations, we show that O-SERENADE can
achieve 100\% throughput and that it has similar as or slightly better delay
performance than SERENA under various load conditions and traffic patterns.
-
In this paper we improve the deterministic complexity of two fundamental
communication primitives in the classical model of ad-hoc radio networks with
unknown topology: broadcasting and wake-up. We consider an unknown radio
network, in which all nodes have no prior knowledge about network topology, and
know only the size of the network $n$, the maximum in-degree of any node
$\Delta$, and the eccentricity of the network $D$.
For such networks, we first give an algorithm for wake-up, based on the
existence of small universal synchronizers. This algorithm runs in
$O(\frac{\min\{n, D \Delta\} \log n \log \Delta}{\log\log \Delta})$ time, the
fastest known in both directed and undirected networks, improving over the
previous best $O(n \log^2n)$-time result across all ranges of parameters, but
particularly when maximum in-degree is small.
Next, we introduce a new combinatorial framework of block synchronizers and
prove the existence of such objects of low size. Using this framework, we
design a new deterministic algorithm for the fundamental problem of
broadcasting, running in $O(n \log D \log\log\frac{D \Delta}{n})$ time. This is
the fastest known algorithm for the problem in directed networks, improving
upon the $O(n \log n \log \log n)$-time algorithm of De Marco (2010) and the
$O(n \log^2 D)$-time algorithm due to Czumaj and Rytter (2003). It is also the
first to come within a log-logarithmic factor of the $\Omega(n \log D)$ lower
bound due to Clementi et al.\ (2003).
Our results also have direct implications on the fastest \emph{deterministic
leader election} and \emph{clock synchronization} algorithms in both directed
and undirected radio networks, tasks which are commonly used as building blocks
for more complex procedures.
-
The \emph{beep model} is a very weak communications model in which devices in
a network can communicate only via beeps and silence. As a result of its weak
assumptions, it has broad applicability to many different implementations of
communications networks. This comes at the cost of a restrictive environment
for algorithm design.
Despite being only recently introduced, the beep model has received
considerable attention, in part due to its relationship with other
communication models such as that of ad-hoc radio networks. However, there has
been no definitive published result for several fundamental tasks in the model.
We aim to rectify this with our paper.
We present algorithms and lower bounds for a variety of fundamental global
communications tasks in the model.
-
In this paper we present a framework for leader election in multi-hop radio
networks which yield randomized leader election algorithms taking
$O(\text{broadcasting time})$ in expectation, and another which yields
algorithms taking fixed $O(\sqrt{\log n})$-times broadcasting time. Both
succeed with high probability.
We show how to implement these frameworks in radio networks without collision
detection, and in networks with collision detection (in fact in the strictly
weaker beep model). In doing so, we obtain the first optimal expected-time
leader election algorithms in both settings, and also improve the worst-case
running time in directed networks without collision detection by an $O(\sqrt
{\log n})$ factor.
-
Due to the big size of data and limited data storage volume of a single
computer or a single server, data are often stored in a distributed manner.
Thus, performing large-scale machine learning operations with the distributed
datasets through communication networks is often required. In this paper, we
study the convergence rate of the distributed dual coordinate ascent for
distributed machine learning problems in a general tree-structured network.
Since a tree network model can be understood as the generalization of a star
network model, our algorithm can be thought of as the generalization of the
distributed dual coordinate ascent in a star network model. We provide the
convergence rate of the distributed dual coordinate ascent over a general tree
network in a recursive manner and analyze the network effect on the convergence
rate. Secondly, by considering network communication delays, we optimize the
distributed dual coordinate ascent algorithm to maximize its convergence speed.
From our analytical result, we can choose the optimal number of local
iterations depending on the communication delay severity to achieve the fastest
convergence speed. In numerical experiments, we consider machine learning
scenarios over communication networks, where local workers cannot directly
reach to a central node due to constraints in communication, and demonstrate
that the usability of our distributed dual coordinate ascent algorithm in tree
networks. Additionally, we show that adapting number of local and global
iterations to network communication delays in the distributed dual coordinated
ascent algorithm can improve its convergence speed.
-
In this work, we study the $k$-median and $k$-means clustering problems when
the data is distributed across many servers and can contain outliers. While
there has been a lot of work on these problems for worst-case instances, we
focus on gaining a finer understanding through the lens of beyond worst-case
analysis. Our main motivation is the following: for many applications such as
clustering proteins by function or clustering communities in a social network,
there is some unknown target clustering, and the hope is that running a
$k$-median or $k$-means algorithm will produce clusterings which are close to
matching the target clustering. Worst-case results can guarantee constant
factor approximations to the optimal $k$-median or $k$-means objective value,
but not closeness to the target clustering.
Our first result is a distributed algorithm which returns a near-optimal
clustering assuming a natural notion of stability, namely, approximation
stability [Balcan et. al 2013], even when a constant fraction of the data are
outliers. The communication complexity is $\tilde O(sk+z)$ where $s$ is the
number of machines, $k$ is the number of clusters, and $z$ is the number of
outliers.
Next, we show this amount of communication cannot be improved even in the
setting when the input satisfies various non-worst-case assumptions. We give a
matching $\Omega(sk+z)$ lower bound on the communication required both for
approximating the optimal $k$-means or $k$-median cost up to any constant, and
for returning a clustering that is close to the target clustering in Hamming
distance. These lower bounds hold even when the data satisfies approximation
stability or other common notions of stability, and the cluster sizes are
balanced. Therefore, $\Omega(sk+z)$ is a communication bottleneck, even for
real-world instances.
-
Bayesian matrix factorization (BMF) is a powerful tool for producing low-rank
representations of matrices and for predicting missing values and providing
confidence intervals. Scaling up the posterior inference for massive-scale
matrices is challenging and requires distributing both data and computation
over many workers, making communication the main computational bottleneck.
Embarrassingly parallel inference would remove the communication needed, by
using completely independent computations on different data subsets, but it
suffers from the inherent unidentifiability of BMF solutions. We introduce a
hierarchical decomposition of the joint posterior distribution, which couples
the subset inferences, allowing for embarrassingly parallel computations in a
sequence of at most three stages. Using an efficient approximate
implementation, we show improvements empirically on both real and simulated
data. Our distributed approach is able to achieve a speed-up of almost an order
of magnitude over the full posterior, with a negligible effect on predictive
accuracy. Our method outperforms state-of-the-art embarrassingly parallel MCMC
methods in accuracy, and achieves results competitive to other available
distributed and parallel implementations of BMF.
-
In systems of programmable matter, we are given a collection of simple
computation elements (or particles) with limited (constant-size) memory. We are
interested in when they can self-organize to solve system-wide problems of
movement, configuration and coordination. Here, we initiate a stochastic
approach to developing robust distributed algorithms for programmable matter
systems using Markov chains. We are able to leverage the wealth of prior work
in Markov chains and related areas to design and rigorously analyze our
distributed algorithms and show that they have several desirable properties.
We study the compression problem, in which a particle system must gather as
tightly together as possible, as in a sphere or its equivalent in the presence
of some underlying geometry. More specifically, we seek fully distributed,
local, and asynchronous algorithms that lead the system to converge to a
configuration with small boundary. We present a Markov chain-based algorithm
that solves the compression problem under the geometric amoebot model, for
particle systems that begin in a connected configuration. The algorithm takes
as input a bias parameter $\lambda$, where $\lambda > 1$ corresponds to
particles favoring having more neighbors. We show that for all $\lambda >
2+\sqrt{2}$, there is a constant $\alpha > 1$ such that eventually with all but
exponentially small probability the particles are $\alpha$-compressed, meaning
the perimeter of the system configuration is at most $\alpha \cdot p_{min}$,
where $p_{min}$ is the minimum possible perimeter of the particle system.
Surprisingly, the same algorithm can also be used for expansion when $0 <
\lambda < 2.17$, and we prove similar results about expansion for values of
$\lambda$ in this range. This is counterintuitive as it shows that particles
preferring to be next to each other ($\lambda > 1$) is not sufficient to
guarantee compression.
-
Intel Xeon Phi many-integrated-core (MIC) architectures usher in a new era of
terascale integration. Among emerging killer applications, parallel graph
processing has been a critical technique to analyze connected data. In this
paper, we empirically evaluate various computing platforms including an Intel
Xeon E5 CPU, a Nvidia Geforce GTX1070 GPU and an Xeon Phi 7210 processor
codenamed Knights Landing (KNL) in the domain of parallel graph processing. We
show that the KNL gains encouraging performance when processing graphs, so that
it can become a promising solution to accelerating multi-threaded graph
applications. We further characterize the impact of KNL architectural
enhancements on the performance of a state-of-the art graph framework.We have
four key observations: 1 Different graph applications require distinctive
numbers of threads to reach the peak performance. For the same application,
various datasets need even different numbers of threads to achieve the best
performance. 2 Only a few graph applications benefit from the high bandwidth
MCDRAM, while others favor the low latency DDR4 DRAM. 3 Vector processing units
executing AVX512 SIMD instructions on KNLs are underutilized when running the
state-of-the-art graph framework. 4 The sub-NUMA cache clustering mode offering
the lowest local memory access latency hurts the performance of graph
benchmarks that are lack of NUMA awareness. At last, We suggest future works
including system auto-tuning tools and graph framework optimizations to fully
exploit the potential of KNL for parallel graph processing.
-
A group of mobile agents is given a task to explore an edge-weighted graph
$G$, i.e., every vertex of $G$ has to be visited by at least one agent. There
is no centralized unit to coordinate their actions, but they can freely
communicate with each other. The goal is to construct a deterministic strategy
which allows agents to complete their task optimally. In this paper we are
interested in a cost-optimal strategy, where the cost is understood as the
total distance traversed by agents coupled with the cost of invoking them. Two
graph classes are analyzed, rings and trees, in the off-line and on-line
setting, i.e., when a structure of a graph is known and not known to agents in
advance. We present algorithms that compute the optimal solutions for a given
ring and tree of order $n$, in $O(n)$ time units. For rings in the on-line
setting, we give the $2$-competitive algorithm and prove the lower bound of
$3/2$ for the competitive ratio for any on-line strategy. For every strategy
for trees in the on-line setting, we prove the competitive ratio to be no less
than $2$, which can be achieved by the $DFS$ algorithm.
-
Today's data analytics frameworks are compute-centric, with analytics
execution almost entirely dependent on the pre-determined physical structure of
the high-level computation. Relegating intermediate data to a second class
entity in this manner hurts flexibility, performance, and efficiency. We
present Whiz, a new analytics framework that cleanly separates computation from
intermediate data. It enables runtime visibility into data via programmable
monitoring, and data-driven computation (where intermediate data values drive
when/what computation runs) via an event abstraction. Experiments with a Whiz
prototype on a large cluster using batch, streaming, and graph analytics
workloads show that its performance is 1.3-2x better than state-of-the-art.
-
Given a system model where machines have distinct speeds and power ratings
but are otherwise compatible, we consider various problems of scheduling under
resource constraints on the system which place the restriction that not all
machines can be run at once. These can be power, energy, or makespan
constraints on the system. Given such constraints, there are problems with
divisible as well as non-divisible jobs. In the setting where there is a
constraint on power, we show that the problem of minimizing makespan for a set
of divisible jobs is NP-hard by reduction to the knapsack problem. We then show
that scheduling to minimize energy with power constraints is also NP-hard. We
then consider scheduling with energy and makespan constraints with divisible
jobs and show that these can be solved in polynomial time, and the problems
with non-divisible jobs are NP-hard. We give exact and approximation algorithms
for these problems as required.
-
Many distributed systems work on a common shared state; in such systems,
distributed agreement is necessary for consistency. With an increasing number
of servers, these systems become more susceptible to single-server failures,
increasing the relevance of fault-tolerance. Atomic broadcast enables
fault-tolerant distributed agreement, yet it is costly to solve. Most practical
algorithms entail linear work per broadcast message. AllConcur -- a leaderless
approach -- reduces the work, by connecting the servers via a sparse resilient
overlay network; yet, this resiliency entails redundancy, limiting the
reduction of work. In this paper, we propose AllConcur+, an atomic broadcast
algorithm that lifts this limitation: During intervals with no failures, it
achieves minimal work by using a redundancy-free overlay network. When failures
do occur, it automatically recovers by switching to a resilient overlay
network. In our performance evaluation of non-failure scenarios, AllConcur+
achieves comparable throughput to AllGather -- a non-fault-tolerant distributed
agreement algorithm -- and outperforms AllConcur, LCR and Libpaxos both in
terms of throughput and latency. Furthermore, our evaluation of failure
scenarios shows that AllConcur+'s expected performance is robust with regard to
occasional failures. Thus, for realistic use cases, leveraging redundancy-free
distributed agreement during intervals with no failures improves performance
significantly.
-
This paper describes the application of a high-level language and method in
developing simpler specifications of more complex variants of the Paxos
algorithm for distributed consensus. The specifications are for Multi-Paxos
with preemption, replicated state machine, and reconfiguration and optimized
with state reduction and failure detection. The language is DistAlgo. The key
is to express complex control flows and synchronization conditions precisely at
a high level, using nondeterministic waits and message-history queries. We
obtain complete executable specifications that are almost completely
declarative---updating only a number for the protocol round besides the sets of
messages sent and received.
We show the following results: 1.English and pseudocode descriptions of
distributed algorithms can be captured completely and precisely at a high
level, without adding, removing, or reformulating algorithm details to fit
lower-level, more abstract, or less direct languages. 2.We created higher-level
control flows and synchronization conditions than all previous specifications,
and obtained specifications that are much simpler and smaller, even matching or
smaller than abstract specifications that omit many algorithm details. 3.The
simpler specifications led us to easily discover useless replies, unnecessary
delays, and liveness violations (if messages can be lost) in previous published
specifications, by just following the simplified algorithm flows. 4.The
resulting specifications can be executed directly, and we can express
optimizations cleanly, yielding drastic performance improvement over naive
execution and facilitating a general method for merging processes. 5.We
systematically translated the resulting specifications into TLA+ and developed
machine-checked safety proofs, which also allowed us to detect and fix a subtle
safety violation in an earlier unpublished specification.
-
In this note, we extend the algorithms Extra and subgradient-push to a new
algorithm ExtraPush for consensus optimization with convex differentiable
objective functions over a directed network. When the stationary distribution
of the network can be computed in advance}, we propose a simplified algorithm
called Normalized ExtraPush. Just like Extra, both ExtraPush and Normalized
ExtraPush can iterate with a fixed step size. But unlike Extra, they can take a
column-stochastic mixing matrix, which is not necessarily doubly stochastic.
Therefore, they remove the undirected-network restriction of Extra.
Subgradient-push, while also works for directed networks, is slower on the same
type of problem because it must use a sequence of diminishing step sizes.
We present preliminary analysis for ExtraPush under a bounded sequence
assumption. For Normalized ExtraPush, we show that it naturally produces a
bounded, linearly convergent sequence provided that the objective function is
strongly convex.
In our numerical experiments, ExtraPush and Normalized ExtraPush performed
similarly well. They are significantly faster than subgradient-push, even when
we hand-optimize the step sizes for the latter.
-
This paper is a contribution to the classical cops and robber problem on a
graph, directed to two-dimensional grids and toroidal grids. These studies are
generally aimed at determining the minimum number of cops needed to capture the
robber and proposing algorithms for the capture. We apply some new concepts to
propose a new solution to the problem on grids that was already solved under a
different approach, and apply these concepts to give efficient algorithms for
the capture on toroidal grids. As for grids, we show that two cops suffice even
in a semi-torus (i.e. a grid with toroidal closure in one dimension) and three
cops are necessary and sufficient in a torus. Then we treat the problem in
function of any number k of cops, giving efficient algorithms for grids and
tori and computing lower and upper bounds on the capture time. Conversely we
determine the minimum value of k needed for any given capture time and study a
possible speed-up phenomenon.
-
This paper poses a question about a simple localization problem. The question
is if an {\em oblivious} walker on a line-segment can localize the middle point
of the line-segment in {\em finite} steps observing the direction (i.e., Left
or Right) and the distance to the nearest end point. This problem is arisen
from {\em self-stabilizing} location problems by {\em autonomous mobile robots}
with {\em limited visibility}, that is a widely interested abstract model in
distributed computing. Contrary to appearances, it is far from trivial if this
simple problem is solvable or not, and unsettled yet. This paper is concerned
with three variants of the problem with a minimal relaxation, and presents
self-stabilizing algorithms for them. We also show an easy impossibility
theorem for bilaterally symmetric algorithms.
-
This paper severs as a user guide to the graph partitioning framework KaHIP
(Karlsruhe High Quality Partitioning). We give a rough overview of the
techniques used within the framework and describe the user interface as well as
the file formats used. Moreover, we provide a short description of the current
library functions provided within the framework. Since version 3.00 we support
multilevel partitioning, memetic algorithms, distributed and shared-memory
parallel algorithms, node separator and ordering algorithms, edge partitioning
algorithms as well as ILP solvers.
-
The degree splitting problem requires coloring the edges of a graph red or
blue such that each node has almost the same number of edges in each color, up
to a small additive discrepancy. The directed variant of the problem requires
orienting the edges such that each node has almost the same number of incoming
and outgoing edges, again up to a small additive discrepancy.
We present deterministic distributed algorithms for both variants, which
improve on their counterparts presented by Ghaffari and Su [SODA'17]: our
algorithms are significantly simpler and faster, and have a much smaller
discrepancy. This also leads to a faster and simpler deterministic algorithm
for $(2+o(1))\Delta$-edge-coloring, improving on that of Ghaffari and Su.
-
Paxos is an important algorithm for a set of distributed processes to agree
on a single value or a sequence of values, for which it is called Basic Paxos
or Multi-Paxos, respectively. Consensus is critical when distributed services
are replicated for fault-tolerance, because non-faulty replicas must agree on
the state of the system or the sequence of operations that have been performed.
Unfortunately, consensus algorithms including Multi-Paxos in particular are
well-known to be difficult to understand, and their accurate specifications and
correctness proofs remain challenging, despite extensive studies ever since
Lamport introduced Paxos.
This article describes formal specification and verification of Lamport's
Multi-Paxos algorithm for distributed consensus. The specification is written
in TLA+, Lamport's Temporal Logic of Actions. The proof is written and
automatically checked using TLAPS, the TLA+ Proof System. The proof is for the
safety property of the algorithm. Building on Lamport, Merz, and Doligez's
specification and proof for Basic Paxos, we aim to facilitate the understanding
of Multi-Paxos and its proof by minimizing the difference from those for Basic
Paxos, and to demonstrate a general way of proving other variants of Paxos and
other sophisticated distributed algorithms. We also discuss our general
strategies and results for proving complex invariants using invariance lemmas
and increments, for proving properties about sets and tuples to help the proof
check succeed in significantly reduced time, and for overall proof improvement
leading to considerably reduced proof size.





 Computer networks have become a critical infrastructure. In fact, networks should not only meet strict requirements in terms of correctness, availability, and performance, but they should also be very flexible and support fast updates, e.g., due to policy changes, increasing traffic, or failures. This paper presents a structured survey of mechanism and protocols to update computer networks in a fast and consistent manner. In particular, we identify and discuss the different desirable consistency properties that should be provided throughout a network update, the algorithmic techniques which are needed to meet these consistency properties, and the implications on the speed and costs at which updates can be performed. We also explain the relationship between consistent network update problems and classic algorithmic optimization ones. While our survey is mainly motivated by the advent of Software-Defined Networks (SDNs) and their primary need for correct and efficient update techniques, the fundamental underlying problems are not new, and we provide a historical perspective of the subject as well.
Computer networks have become a critical infrastructure. In fact, networks should not only meet strict requirements in terms of correctness, availability, and performance, but they should also be very flexible and support fast updates, e.g., due to policy changes, increasing traffic, or failures. This paper presents a structured survey of mechanism and protocols to update computer networks in a fast and consistent manner. In particular, we identify and discuss the different desirable consistency properties that should be provided throughout a network update, the algorithmic techniques which are needed to meet these consistency properties, and the implications on the speed and costs at which updates can be performed. We also explain the relationship between consistent network update problems and classic algorithmic optimization ones. While our survey is mainly motivated by the advent of Software-Defined Networks (SDNs) and their primary need for correct and efficient update techniques, the fundamental underlying problems are not new, and we provide a historical perspective of the subject as well.




 Distributed machine learning algorithms enable learning of models from datasets that are distributed over a network without gathering the data at a centralized location. While efficient distributed algorithms have been developed under the assumption of faultless networks, failures that can render these algorithms nonfunctional occur frequently in the real world. This paper focuses on the problem of Byzantine failures, which are the hardest to safeguard against in distributed algorithms. While Byzantine fault tolerance has a rich history, existing work does not translate into efficient and practical algorithms for high-dimensional learning in fully distributed (also known as decentralized) settings. In this paper, an algorithm termed Byzantine-resilient distributed coordinate descent (ByRDiE) is developed and analyzed that enables distributed learning in the presence of Byzantine failures. Theoretical analysis (convex settings) and numerical experiments (convex and nonconvex settings) highlight its usefulness for high-dimensional distributed learning in the presence of Byzantine failures.
Distributed machine learning algorithms enable learning of models from datasets that are distributed over a network without gathering the data at a centralized location. While efficient distributed algorithms have been developed under the assumption of faultless networks, failures that can render these algorithms nonfunctional occur frequently in the real world. This paper focuses on the problem of Byzantine failures, which are the hardest to safeguard against in distributed algorithms. While Byzantine fault tolerance has a rich history, existing work does not translate into efficient and practical algorithms for high-dimensional learning in fully distributed (also known as decentralized) settings. In this paper, an algorithm termed Byzantine-resilient distributed coordinate descent (ByRDiE) is developed and analyzed that enables distributed learning in the presence of Byzantine failures. Theoretical analysis (convex settings) and numerical experiments (convex and nonconvex settings) highlight its usefulness for high-dimensional distributed learning in the presence of Byzantine failures.




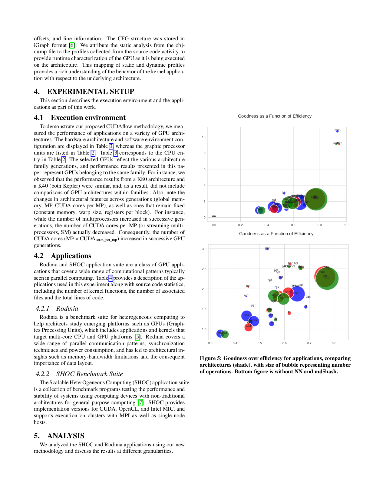 Accelerator architectures specialize in executing SIMD (single instruction, multiple data) in lockstep. Because the majority of CUDA applications are parallelized loops, control flow information can provide an in-depth characterization of a kernel. CUDAflow is a tool that statically separates CUDA binaries into basic block regions and dynamically measures instruction and basic block frequencies. CUDAflow captures this information in a control flow graph (CFG) and performs subgraph matching across various kernel's CFGs to gain insights to an application's resource requirements, based on the shape and traversal of the graph, instruction operations executed and registers allocated, among other information. The utility of CUDAflow is demonstrated with SHOC and Rodinia application case studies on a variety of GPU architectures, revealing novel thread divergence characteristics that facilitates end users, autotuners and compilers in generating high performing code.
Accelerator architectures specialize in executing SIMD (single instruction, multiple data) in lockstep. Because the majority of CUDA applications are parallelized loops, control flow information can provide an in-depth characterization of a kernel. CUDAflow is a tool that statically separates CUDA binaries into basic block regions and dynamically measures instruction and basic block frequencies. CUDAflow captures this information in a control flow graph (CFG) and performs subgraph matching across various kernel's CFGs to gain insights to an application's resource requirements, based on the shape and traversal of the graph, instruction operations executed and registers allocated, among other information. The utility of CUDAflow is demonstrated with SHOC and Rodinia application case studies on a variety of GPU architectures, revealing novel thread divergence characteristics that facilitates end users, autotuners and compilers in generating high performing code.




 Most of today's high-speed switches and routers adopt an input-queued crossbar switch architecture. Such a switch needs to compute a matching (crossbar schedule) between the input ports and output ports during each switching cycle (time slot). A key research challenge in designing large (in number of input/output ports $N$) input-queued crossbar switches is to develop crossbar scheduling algorithms that can compute "high quality" matchings -- i.e., those that result in high switch throughput (ideally $100\%$) and low queueing delays for packets -- at line rates. SERENA is one such algorithm: it outputs excellent matching decisions that result in $100\%$ switch throughput and reasonably good queueing delays. However, since SERENA is a centralized algorithm with $O(N)$ computational complexity, it cannot support switches that both are large and have a very high line rate per port. In this work, we propose SERENADE (SERENA, the Distributed Edition), a parallel iterative algorithm that emulates SERENA in only $O(\log N)$ iterations between input ports and output ports, and hence has a time complexity of only $O(\log N)$ per port. We prove that SERENADE can exactly emulate SERENA. We also propose an early-stop version of SERENADE, called O-SERENADE, to only approximately emulate SERENA. Through extensive simulations, we show that O-SERENADE can achieve 100\% throughput and that it has similar as or slightly better delay performance than SERENA under various load conditions and traffic patterns.
Most of today's high-speed switches and routers adopt an input-queued crossbar switch architecture. Such a switch needs to compute a matching (crossbar schedule) between the input ports and output ports during each switching cycle (time slot). A key research challenge in designing large (in number of input/output ports $N$) input-queued crossbar switches is to develop crossbar scheduling algorithms that can compute "high quality" matchings -- i.e., those that result in high switch throughput (ideally $100\%$) and low queueing delays for packets -- at line rates. SERENA is one such algorithm: it outputs excellent matching decisions that result in $100\%$ switch throughput and reasonably good queueing delays. However, since SERENA is a centralized algorithm with $O(N)$ computational complexity, it cannot support switches that both are large and have a very high line rate per port. In this work, we propose SERENADE (SERENA, the Distributed Edition), a parallel iterative algorithm that emulates SERENA in only $O(\log N)$ iterations between input ports and output ports, and hence has a time complexity of only $O(\log N)$ per port. We prove that SERENADE can exactly emulate SERENA. We also propose an early-stop version of SERENADE, called O-SERENADE, to only approximately emulate SERENA. Through extensive simulations, we show that O-SERENADE can achieve 100\% throughput and that it has similar as or slightly better delay performance than SERENA under various load conditions and traffic patterns.




 In this paper we improve the deterministic complexity of two fundamental communication primitives in the classical model of ad-hoc radio networks with unknown topology: broadcasting and wake-up. We consider an unknown radio network, in which all nodes have no prior knowledge about network topology, and know only the size of the network $n$, the maximum in-degree of any node $\Delta$, and the eccentricity of the network $D$. For such networks, we first give an algorithm for wake-up, based on the existence of small universal synchronizers. This algorithm runs in $O(\frac{\min\{n, D \Delta\} \log n \log \Delta}{\log\log \Delta})$ time, the fastest known in both directed and undirected networks, improving over the previous best $O(n \log^2n)$-time result across all ranges of parameters, but particularly when maximum in-degree is small. Next, we introduce a new combinatorial framework of block synchronizers and prove the existence of such objects of low size. Using this framework, we design a new deterministic algorithm for the fundamental problem of broadcasting, running in $O(n \log D \log\log\frac{D \Delta}{n})$ time. This is the fastest known algorithm for the problem in directed networks, improving upon the $O(n \log n \log \log n)$-time algorithm of De Marco (2010) and the $O(n \log^2 D)$-time algorithm due to Czumaj and Rytter (2003). It is also the first to come within a log-logarithmic factor of the $\Omega(n \log D)$ lower bound due to Clementi et al.\ (2003). Our results also have direct implications on the fastest \emph{deterministic leader election} and \emph{clock synchronization} algorithms in both directed and undirected radio networks, tasks which are commonly used as building blocks for more complex procedures.
In this paper we improve the deterministic complexity of two fundamental communication primitives in the classical model of ad-hoc radio networks with unknown topology: broadcasting and wake-up. We consider an unknown radio network, in which all nodes have no prior knowledge about network topology, and know only the size of the network $n$, the maximum in-degree of any node $\Delta$, and the eccentricity of the network $D$. For such networks, we first give an algorithm for wake-up, based on the existence of small universal synchronizers. This algorithm runs in $O(\frac{\min\{n, D \Delta\} \log n \log \Delta}{\log\log \Delta})$ time, the fastest known in both directed and undirected networks, improving over the previous best $O(n \log^2n)$-time result across all ranges of parameters, but particularly when maximum in-degree is small. Next, we introduce a new combinatorial framework of block synchronizers and prove the existence of such objects of low size. Using this framework, we design a new deterministic algorithm for the fundamental problem of broadcasting, running in $O(n \log D \log\log\frac{D \Delta}{n})$ time. This is the fastest known algorithm for the problem in directed networks, improving upon the $O(n \log n \log \log n)$-time algorithm of De Marco (2010) and the $O(n \log^2 D)$-time algorithm due to Czumaj and Rytter (2003). It is also the first to come within a log-logarithmic factor of the $\Omega(n \log D)$ lower bound due to Clementi et al.\ (2003). Our results also have direct implications on the fastest \emph{deterministic leader election} and \emph{clock synchronization} algorithms in both directed and undirected radio networks, tasks which are commonly used as building blocks for more complex procedures.




 The \emph{beep model} is a very weak communications model in which devices in a network can communicate only via beeps and silence. As a result of its weak assumptions, it has broad applicability to many different implementations of communications networks. This comes at the cost of a restrictive environment for algorithm design. Despite being only recently introduced, the beep model has received considerable attention, in part due to its relationship with other communication models such as that of ad-hoc radio networks. However, there has been no definitive published result for several fundamental tasks in the model. We aim to rectify this with our paper. We present algorithms and lower bounds for a variety of fundamental global communications tasks in the model.
The \emph{beep model} is a very weak communications model in which devices in a network can communicate only via beeps and silence. As a result of its weak assumptions, it has broad applicability to many different implementations of communications networks. This comes at the cost of a restrictive environment for algorithm design. Despite being only recently introduced, the beep model has received considerable attention, in part due to its relationship with other communication models such as that of ad-hoc radio networks. However, there has been no definitive published result for several fundamental tasks in the model. We aim to rectify this with our paper. We present algorithms and lower bounds for a variety of fundamental global communications tasks in the model.




 In this paper we present a framework for leader election in multi-hop radio networks which yield randomized leader election algorithms taking $O(\text{broadcasting time})$ in expectation, and another which yields algorithms taking fixed $O(\sqrt{\log n})$-times broadcasting time. Both succeed with high probability. We show how to implement these frameworks in radio networks without collision detection, and in networks with collision detection (in fact in the strictly weaker beep model). In doing so, we obtain the first optimal expected-time leader election algorithms in both settings, and also improve the worst-case running time in directed networks without collision detection by an $O(\sqrt {\log n})$ factor.
In this paper we present a framework for leader election in multi-hop radio networks which yield randomized leader election algorithms taking $O(\text{broadcasting time})$ in expectation, and another which yields algorithms taking fixed $O(\sqrt{\log n})$-times broadcasting time. Both succeed with high probability. We show how to implement these frameworks in radio networks without collision detection, and in networks with collision detection (in fact in the strictly weaker beep model). In doing so, we obtain the first optimal expected-time leader election algorithms in both settings, and also improve the worst-case running time in directed networks without collision detection by an $O(\sqrt {\log n})$ factor.



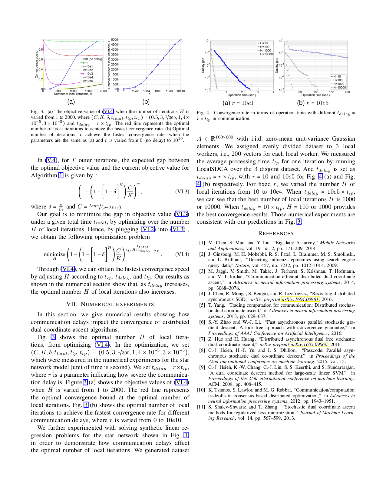
 Due to the big size of data and limited data storage volume of a single computer or a single server, data are often stored in a distributed manner. Thus, performing large-scale machine learning operations with the distributed datasets through communication networks is often required. In this paper, we study the convergence rate of the distributed dual coordinate ascent for distributed machine learning problems in a general tree-structured network. Since a tree network model can be understood as the generalization of a star network model, our algorithm can be thought of as the generalization of the distributed dual coordinate ascent in a star network model. We provide the convergence rate of the distributed dual coordinate ascent over a general tree network in a recursive manner and analyze the network effect on the convergence rate. Secondly, by considering network communication delays, we optimize the distributed dual coordinate ascent algorithm to maximize its convergence speed. From our analytical result, we can choose the optimal number of local iterations depending on the communication delay severity to achieve the fastest convergence speed. In numerical experiments, we consider machine learning scenarios over communication networks, where local workers cannot directly reach to a central node due to constraints in communication, and demonstrate that the usability of our distributed dual coordinate ascent algorithm in tree networks. Additionally, we show that adapting number of local and global iterations to network communication delays in the distributed dual coordinated ascent algorithm can improve its convergence speed.
Due to the big size of data and limited data storage volume of a single computer or a single server, data are often stored in a distributed manner. Thus, performing large-scale machine learning operations with the distributed datasets through communication networks is often required. In this paper, we study the convergence rate of the distributed dual coordinate ascent for distributed machine learning problems in a general tree-structured network. Since a tree network model can be understood as the generalization of a star network model, our algorithm can be thought of as the generalization of the distributed dual coordinate ascent in a star network model. We provide the convergence rate of the distributed dual coordinate ascent over a general tree network in a recursive manner and analyze the network effect on the convergence rate. Secondly, by considering network communication delays, we optimize the distributed dual coordinate ascent algorithm to maximize its convergence speed. From our analytical result, we can choose the optimal number of local iterations depending on the communication delay severity to achieve the fastest convergence speed. In numerical experiments, we consider machine learning scenarios over communication networks, where local workers cannot directly reach to a central node due to constraints in communication, and demonstrate that the usability of our distributed dual coordinate ascent algorithm in tree networks. Additionally, we show that adapting number of local and global iterations to network communication delays in the distributed dual coordinated ascent algorithm can improve its convergence speed.




 In this work, we study the $k$-median and $k$-means clustering problems when the data is distributed across many servers and can contain outliers. While there has been a lot of work on these problems for worst-case instances, we focus on gaining a finer understanding through the lens of beyond worst-case analysis. Our main motivation is the following: for many applications such as clustering proteins by function or clustering communities in a social network, there is some unknown target clustering, and the hope is that running a $k$-median or $k$-means algorithm will produce clusterings which are close to matching the target clustering. Worst-case results can guarantee constant factor approximations to the optimal $k$-median or $k$-means objective value, but not closeness to the target clustering. Our first result is a distributed algorithm which returns a near-optimal clustering assuming a natural notion of stability, namely, approximation stability [Balcan et. al 2013], even when a constant fraction of the data are outliers. The communication complexity is $\tilde O(sk+z)$ where $s$ is the number of machines, $k$ is the number of clusters, and $z$ is the number of outliers. Next, we show this amount of communication cannot be improved even in the setting when the input satisfies various non-worst-case assumptions. We give a matching $\Omega(sk+z)$ lower bound on the communication required both for approximating the optimal $k$-means or $k$-median cost up to any constant, and for returning a clustering that is close to the target clustering in Hamming distance. These lower bounds hold even when the data satisfies approximation stability or other common notions of stability, and the cluster sizes are balanced. Therefore, $\Omega(sk+z)$ is a communication bottleneck, even for real-world instances.
In this work, we study the $k$-median and $k$-means clustering problems when the data is distributed across many servers and can contain outliers. While there has been a lot of work on these problems for worst-case instances, we focus on gaining a finer understanding through the lens of beyond worst-case analysis. Our main motivation is the following: for many applications such as clustering proteins by function or clustering communities in a social network, there is some unknown target clustering, and the hope is that running a $k$-median or $k$-means algorithm will produce clusterings which are close to matching the target clustering. Worst-case results can guarantee constant factor approximations to the optimal $k$-median or $k$-means objective value, but not closeness to the target clustering. Our first result is a distributed algorithm which returns a near-optimal clustering assuming a natural notion of stability, namely, approximation stability [Balcan et. al 2013], even when a constant fraction of the data are outliers. The communication complexity is $\tilde O(sk+z)$ where $s$ is the number of machines, $k$ is the number of clusters, and $z$ is the number of outliers. Next, we show this amount of communication cannot be improved even in the setting when the input satisfies various non-worst-case assumptions. We give a matching $\Omega(sk+z)$ lower bound on the communication required both for approximating the optimal $k$-means or $k$-median cost up to any constant, and for returning a clustering that is close to the target clustering in Hamming distance. These lower bounds hold even when the data satisfies approximation stability or other common notions of stability, and the cluster sizes are balanced. Therefore, $\Omega(sk+z)$ is a communication bottleneck, even for real-world instances.




 Bayesian matrix factorization (BMF) is a powerful tool for producing low-rank representations of matrices and for predicting missing values and providing confidence intervals. Scaling up the posterior inference for massive-scale matrices is challenging and requires distributing both data and computation over many workers, making communication the main computational bottleneck. Embarrassingly parallel inference would remove the communication needed, by using completely independent computations on different data subsets, but it suffers from the inherent unidentifiability of BMF solutions. We introduce a hierarchical decomposition of the joint posterior distribution, which couples the subset inferences, allowing for embarrassingly parallel computations in a sequence of at most three stages. Using an efficient approximate implementation, we show improvements empirically on both real and simulated data. Our distributed approach is able to achieve a speed-up of almost an order of magnitude over the full posterior, with a negligible effect on predictive accuracy. Our method outperforms state-of-the-art embarrassingly parallel MCMC methods in accuracy, and achieves results competitive to other available distributed and parallel implementations of BMF.
Bayesian matrix factorization (BMF) is a powerful tool for producing low-rank representations of matrices and for predicting missing values and providing confidence intervals. Scaling up the posterior inference for massive-scale matrices is challenging and requires distributing both data and computation over many workers, making communication the main computational bottleneck. Embarrassingly parallel inference would remove the communication needed, by using completely independent computations on different data subsets, but it suffers from the inherent unidentifiability of BMF solutions. We introduce a hierarchical decomposition of the joint posterior distribution, which couples the subset inferences, allowing for embarrassingly parallel computations in a sequence of at most three stages. Using an efficient approximate implementation, we show improvements empirically on both real and simulated data. Our distributed approach is able to achieve a speed-up of almost an order of magnitude over the full posterior, with a negligible effect on predictive accuracy. Our method outperforms state-of-the-art embarrassingly parallel MCMC methods in accuracy, and achieves results competitive to other available distributed and parallel implementations of BMF.




 In systems of programmable matter, we are given a collection of simple computation elements (or particles) with limited (constant-size) memory. We are interested in when they can self-organize to solve system-wide problems of movement, configuration and coordination. Here, we initiate a stochastic approach to developing robust distributed algorithms for programmable matter systems using Markov chains. We are able to leverage the wealth of prior work in Markov chains and related areas to design and rigorously analyze our distributed algorithms and show that they have several desirable properties. We study the compression problem, in which a particle system must gather as tightly together as possible, as in a sphere or its equivalent in the presence of some underlying geometry. More specifically, we seek fully distributed, local, and asynchronous algorithms that lead the system to converge to a configuration with small boundary. We present a Markov chain-based algorithm that solves the compression problem under the geometric amoebot model, for particle systems that begin in a connected configuration. The algorithm takes as input a bias parameter $\lambda$, where $\lambda > 1$ corresponds to particles favoring having more neighbors. We show that for all $\lambda > 2+\sqrt{2}$, there is a constant $\alpha > 1$ such that eventually with all but exponentially small probability the particles are $\alpha$-compressed, meaning the perimeter of the system configuration is at most $\alpha \cdot p_{min}$, where $p_{min}$ is the minimum possible perimeter of the particle system. Surprisingly, the same algorithm can also be used for expansion when $0 < \lambda < 2.17$, and we prove similar results about expansion for values of $\lambda$ in this range. This is counterintuitive as it shows that particles preferring to be next to each other ($\lambda > 1$) is not sufficient to guarantee compression.
In systems of programmable matter, we are given a collection of simple computation elements (or particles) with limited (constant-size) memory. We are interested in when they can self-organize to solve system-wide problems of movement, configuration and coordination. Here, we initiate a stochastic approach to developing robust distributed algorithms for programmable matter systems using Markov chains. We are able to leverage the wealth of prior work in Markov chains and related areas to design and rigorously analyze our distributed algorithms and show that they have several desirable properties. We study the compression problem, in which a particle system must gather as tightly together as possible, as in a sphere or its equivalent in the presence of some underlying geometry. More specifically, we seek fully distributed, local, and asynchronous algorithms that lead the system to converge to a configuration with small boundary. We present a Markov chain-based algorithm that solves the compression problem under the geometric amoebot model, for particle systems that begin in a connected configuration. The algorithm takes as input a bias parameter $\lambda$, where $\lambda > 1$ corresponds to particles favoring having more neighbors. We show that for all $\lambda > 2+\sqrt{2}$, there is a constant $\alpha > 1$ such that eventually with all but exponentially small probability the particles are $\alpha$-compressed, meaning the perimeter of the system configuration is at most $\alpha \cdot p_{min}$, where $p_{min}$ is the minimum possible perimeter of the particle system. Surprisingly, the same algorithm can also be used for expansion when $0 < \lambda < 2.17$, and we prove similar results about expansion for values of $\lambda$ in this range. This is counterintuitive as it shows that particles preferring to be next to each other ($\lambda > 1$) is not sufficient to guarantee compression.




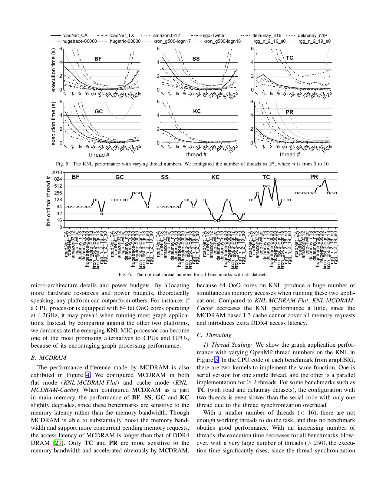 Intel Xeon Phi many-integrated-core (MIC) architectures usher in a new era of terascale integration. Among emerging killer applications, parallel graph processing has been a critical technique to analyze connected data. In this paper, we empirically evaluate various computing platforms including an Intel Xeon E5 CPU, a Nvidia Geforce GTX1070 GPU and an Xeon Phi 7210 processor codenamed Knights Landing (KNL) in the domain of parallel graph processing. We show that the KNL gains encouraging performance when processing graphs, so that it can become a promising solution to accelerating multi-threaded graph applications. We further characterize the impact of KNL architectural enhancements on the performance of a state-of-the art graph framework.We have four key observations: 1 Different graph applications require distinctive numbers of threads to reach the peak performance. For the same application, various datasets need even different numbers of threads to achieve the best performance. 2 Only a few graph applications benefit from the high bandwidth MCDRAM, while others favor the low latency DDR4 DRAM. 3 Vector processing units executing AVX512 SIMD instructions on KNLs are underutilized when running the state-of-the-art graph framework. 4 The sub-NUMA cache clustering mode offering the lowest local memory access latency hurts the performance of graph benchmarks that are lack of NUMA awareness. At last, We suggest future works including system auto-tuning tools and graph framework optimizations to fully exploit the potential of KNL for parallel graph processing.
Intel Xeon Phi many-integrated-core (MIC) architectures usher in a new era of terascale integration. Among emerging killer applications, parallel graph processing has been a critical technique to analyze connected data. In this paper, we empirically evaluate various computing platforms including an Intel Xeon E5 CPU, a Nvidia Geforce GTX1070 GPU and an Xeon Phi 7210 processor codenamed Knights Landing (KNL) in the domain of parallel graph processing. We show that the KNL gains encouraging performance when processing graphs, so that it can become a promising solution to accelerating multi-threaded graph applications. We further characterize the impact of KNL architectural enhancements on the performance of a state-of-the art graph framework.We have four key observations: 1 Different graph applications require distinctive numbers of threads to reach the peak performance. For the same application, various datasets need even different numbers of threads to achieve the best performance. 2 Only a few graph applications benefit from the high bandwidth MCDRAM, while others favor the low latency DDR4 DRAM. 3 Vector processing units executing AVX512 SIMD instructions on KNLs are underutilized when running the state-of-the-art graph framework. 4 The sub-NUMA cache clustering mode offering the lowest local memory access latency hurts the performance of graph benchmarks that are lack of NUMA awareness. At last, We suggest future works including system auto-tuning tools and graph framework optimizations to fully exploit the potential of KNL for parallel graph processing.




 A group of mobile agents is given a task to explore an edge-weighted graph $G$, i.e., every vertex of $G$ has to be visited by at least one agent. There is no centralized unit to coordinate their actions, but they can freely communicate with each other. The goal is to construct a deterministic strategy which allows agents to complete their task optimally. In this paper we are interested in a cost-optimal strategy, where the cost is understood as the total distance traversed by agents coupled with the cost of invoking them. Two graph classes are analyzed, rings and trees, in the off-line and on-line setting, i.e., when a structure of a graph is known and not known to agents in advance. We present algorithms that compute the optimal solutions for a given ring and tree of order $n$, in $O(n)$ time units. For rings in the on-line setting, we give the $2$-competitive algorithm and prove the lower bound of $3/2$ for the competitive ratio for any on-line strategy. For every strategy for trees in the on-line setting, we prove the competitive ratio to be no less than $2$, which can be achieved by the $DFS$ algorithm.
A group of mobile agents is given a task to explore an edge-weighted graph $G$, i.e., every vertex of $G$ has to be visited by at least one agent. There is no centralized unit to coordinate their actions, but they can freely communicate with each other. The goal is to construct a deterministic strategy which allows agents to complete their task optimally. In this paper we are interested in a cost-optimal strategy, where the cost is understood as the total distance traversed by agents coupled with the cost of invoking them. Two graph classes are analyzed, rings and trees, in the off-line and on-line setting, i.e., when a structure of a graph is known and not known to agents in advance. We present algorithms that compute the optimal solutions for a given ring and tree of order $n$, in $O(n)$ time units. For rings in the on-line setting, we give the $2$-competitive algorithm and prove the lower bound of $3/2$ for the competitive ratio for any on-line strategy. For every strategy for trees in the on-line setting, we prove the competitive ratio to be no less than $2$, which can be achieved by the $DFS$ algorithm.




 Today's data analytics frameworks are compute-centric, with analytics execution almost entirely dependent on the pre-determined physical structure of the high-level computation. Relegating intermediate data to a second class entity in this manner hurts flexibility, performance, and efficiency. We present Whiz, a new analytics framework that cleanly separates computation from intermediate data. It enables runtime visibility into data via programmable monitoring, and data-driven computation (where intermediate data values drive when/what computation runs) via an event abstraction. Experiments with a Whiz prototype on a large cluster using batch, streaming, and graph analytics workloads show that its performance is 1.3-2x better than state-of-the-art.
Today's data analytics frameworks are compute-centric, with analytics execution almost entirely dependent on the pre-determined physical structure of the high-level computation. Relegating intermediate data to a second class entity in this manner hurts flexibility, performance, and efficiency. We present Whiz, a new analytics framework that cleanly separates computation from intermediate data. It enables runtime visibility into data via programmable monitoring, and data-driven computation (where intermediate data values drive when/what computation runs) via an event abstraction. Experiments with a Whiz prototype on a large cluster using batch, streaming, and graph analytics workloads show that its performance is 1.3-2x better than state-of-the-art.




 Given a system model where machines have distinct speeds and power ratings but are otherwise compatible, we consider various problems of scheduling under resource constraints on the system which place the restriction that not all machines can be run at once. These can be power, energy, or makespan constraints on the system. Given such constraints, there are problems with divisible as well as non-divisible jobs. In the setting where there is a constraint on power, we show that the problem of minimizing makespan for a set of divisible jobs is NP-hard by reduction to the knapsack problem. We then show that scheduling to minimize energy with power constraints is also NP-hard. We then consider scheduling with energy and makespan constraints with divisible jobs and show that these can be solved in polynomial time, and the problems with non-divisible jobs are NP-hard. We give exact and approximation algorithms for these problems as required.
Given a system model where machines have distinct speeds and power ratings but are otherwise compatible, we consider various problems of scheduling under resource constraints on the system which place the restriction that not all machines can be run at once. These can be power, energy, or makespan constraints on the system. Given such constraints, there are problems with divisible as well as non-divisible jobs. In the setting where there is a constraint on power, we show that the problem of minimizing makespan for a set of divisible jobs is NP-hard by reduction to the knapsack problem. We then show that scheduling to minimize energy with power constraints is also NP-hard. We then consider scheduling with energy and makespan constraints with divisible jobs and show that these can be solved in polynomial time, and the problems with non-divisible jobs are NP-hard. We give exact and approximation algorithms for these problems as required.




 Many distributed systems work on a common shared state; in such systems, distributed agreement is necessary for consistency. With an increasing number of servers, these systems become more susceptible to single-server failures, increasing the relevance of fault-tolerance. Atomic broadcast enables fault-tolerant distributed agreement, yet it is costly to solve. Most practical algorithms entail linear work per broadcast message. AllConcur -- a leaderless approach -- reduces the work, by connecting the servers via a sparse resilient overlay network; yet, this resiliency entails redundancy, limiting the reduction of work. In this paper, we propose AllConcur+, an atomic broadcast algorithm that lifts this limitation: During intervals with no failures, it achieves minimal work by using a redundancy-free overlay network. When failures do occur, it automatically recovers by switching to a resilient overlay network. In our performance evaluation of non-failure scenarios, AllConcur+ achieves comparable throughput to AllGather -- a non-fault-tolerant distributed agreement algorithm -- and outperforms AllConcur, LCR and Libpaxos both in terms of throughput and latency. Furthermore, our evaluation of failure scenarios shows that AllConcur+'s expected performance is robust with regard to occasional failures. Thus, for realistic use cases, leveraging redundancy-free distributed agreement during intervals with no failures improves performance significantly.
Many distributed systems work on a common shared state; in such systems, distributed agreement is necessary for consistency. With an increasing number of servers, these systems become more susceptible to single-server failures, increasing the relevance of fault-tolerance. Atomic broadcast enables fault-tolerant distributed agreement, yet it is costly to solve. Most practical algorithms entail linear work per broadcast message. AllConcur -- a leaderless approach -- reduces the work, by connecting the servers via a sparse resilient overlay network; yet, this resiliency entails redundancy, limiting the reduction of work. In this paper, we propose AllConcur+, an atomic broadcast algorithm that lifts this limitation: During intervals with no failures, it achieves minimal work by using a redundancy-free overlay network. When failures do occur, it automatically recovers by switching to a resilient overlay network. In our performance evaluation of non-failure scenarios, AllConcur+ achieves comparable throughput to AllGather -- a non-fault-tolerant distributed agreement algorithm -- and outperforms AllConcur, LCR and Libpaxos both in terms of throughput and latency. Furthermore, our evaluation of failure scenarios shows that AllConcur+'s expected performance is robust with regard to occasional failures. Thus, for realistic use cases, leveraging redundancy-free distributed agreement during intervals with no failures improves performance significantly.




 This paper describes the application of a high-level language and method in developing simpler specifications of more complex variants of the Paxos algorithm for distributed consensus. The specifications are for Multi-Paxos with preemption, replicated state machine, and reconfiguration and optimized with state reduction and failure detection. The language is DistAlgo. The key is to express complex control flows and synchronization conditions precisely at a high level, using nondeterministic waits and message-history queries. We obtain complete executable specifications that are almost completely declarative---updating only a number for the protocol round besides the sets of messages sent and received. We show the following results: 1.English and pseudocode descriptions of distributed algorithms can be captured completely and precisely at a high level, without adding, removing, or reformulating algorithm details to fit lower-level, more abstract, or less direct languages. 2.We created higher-level control flows and synchronization conditions than all previous specifications, and obtained specifications that are much simpler and smaller, even matching or smaller than abstract specifications that omit many algorithm details. 3.The simpler specifications led us to easily discover useless replies, unnecessary delays, and liveness violations (if messages can be lost) in previous published specifications, by just following the simplified algorithm flows. 4.The resulting specifications can be executed directly, and we can express optimizations cleanly, yielding drastic performance improvement over naive execution and facilitating a general method for merging processes. 5.We systematically translated the resulting specifications into TLA+ and developed machine-checked safety proofs, which also allowed us to detect and fix a subtle safety violation in an earlier unpublished specification.
This paper describes the application of a high-level language and method in developing simpler specifications of more complex variants of the Paxos algorithm for distributed consensus. The specifications are for Multi-Paxos with preemption, replicated state machine, and reconfiguration and optimized with state reduction and failure detection. The language is DistAlgo. The key is to express complex control flows and synchronization conditions precisely at a high level, using nondeterministic waits and message-history queries. We obtain complete executable specifications that are almost completely declarative---updating only a number for the protocol round besides the sets of messages sent and received. We show the following results: 1.English and pseudocode descriptions of distributed algorithms can be captured completely and precisely at a high level, without adding, removing, or reformulating algorithm details to fit lower-level, more abstract, or less direct languages. 2.We created higher-level control flows and synchronization conditions than all previous specifications, and obtained specifications that are much simpler and smaller, even matching or smaller than abstract specifications that omit many algorithm details. 3.The simpler specifications led us to easily discover useless replies, unnecessary delays, and liveness violations (if messages can be lost) in previous published specifications, by just following the simplified algorithm flows. 4.The resulting specifications can be executed directly, and we can express optimizations cleanly, yielding drastic performance improvement over naive execution and facilitating a general method for merging processes. 5.We systematically translated the resulting specifications into TLA+ and developed machine-checked safety proofs, which also allowed us to detect and fix a subtle safety violation in an earlier unpublished specification.




 In this note, we extend the algorithms Extra and subgradient-push to a new algorithm ExtraPush for consensus optimization with convex differentiable objective functions over a directed network. When the stationary distribution of the network can be computed in advance}, we propose a simplified algorithm called Normalized ExtraPush. Just like Extra, both ExtraPush and Normalized ExtraPush can iterate with a fixed step size. But unlike Extra, they can take a column-stochastic mixing matrix, which is not necessarily doubly stochastic. Therefore, they remove the undirected-network restriction of Extra. Subgradient-push, while also works for directed networks, is slower on the same type of problem because it must use a sequence of diminishing step sizes. We present preliminary analysis for ExtraPush under a bounded sequence assumption. For Normalized ExtraPush, we show that it naturally produces a bounded, linearly convergent sequence provided that the objective function is strongly convex. In our numerical experiments, ExtraPush and Normalized ExtraPush performed similarly well. They are significantly faster than subgradient-push, even when we hand-optimize the step sizes for the latter.
In this note, we extend the algorithms Extra and subgradient-push to a new algorithm ExtraPush for consensus optimization with convex differentiable objective functions over a directed network. When the stationary distribution of the network can be computed in advance}, we propose a simplified algorithm called Normalized ExtraPush. Just like Extra, both ExtraPush and Normalized ExtraPush can iterate with a fixed step size. But unlike Extra, they can take a column-stochastic mixing matrix, which is not necessarily doubly stochastic. Therefore, they remove the undirected-network restriction of Extra. Subgradient-push, while also works for directed networks, is slower on the same type of problem because it must use a sequence of diminishing step sizes. We present preliminary analysis for ExtraPush under a bounded sequence assumption. For Normalized ExtraPush, we show that it naturally produces a bounded, linearly convergent sequence provided that the objective function is strongly convex. In our numerical experiments, ExtraPush and Normalized ExtraPush performed similarly well. They are significantly faster than subgradient-push, even when we hand-optimize the step sizes for the latter.




 This paper is a contribution to the classical cops and robber problem on a graph, directed to two-dimensional grids and toroidal grids. These studies are generally aimed at determining the minimum number of cops needed to capture the robber and proposing algorithms for the capture. We apply some new concepts to propose a new solution to the problem on grids that was already solved under a different approach, and apply these concepts to give efficient algorithms for the capture on toroidal grids. As for grids, we show that two cops suffice even in a semi-torus (i.e. a grid with toroidal closure in one dimension) and three cops are necessary and sufficient in a torus. Then we treat the problem in function of any number k of cops, giving efficient algorithms for grids and tori and computing lower and upper bounds on the capture time. Conversely we determine the minimum value of k needed for any given capture time and study a possible speed-up phenomenon.
This paper is a contribution to the classical cops and robber problem on a graph, directed to two-dimensional grids and toroidal grids. These studies are generally aimed at determining the minimum number of cops needed to capture the robber and proposing algorithms for the capture. We apply some new concepts to propose a new solution to the problem on grids that was already solved under a different approach, and apply these concepts to give efficient algorithms for the capture on toroidal grids. As for grids, we show that two cops suffice even in a semi-torus (i.e. a grid with toroidal closure in one dimension) and three cops are necessary and sufficient in a torus. Then we treat the problem in function of any number k of cops, giving efficient algorithms for grids and tori and computing lower and upper bounds on the capture time. Conversely we determine the minimum value of k needed for any given capture time and study a possible speed-up phenomenon.




 This paper poses a question about a simple localization problem. The question is if an {\em oblivious} walker on a line-segment can localize the middle point of the line-segment in {\em finite} steps observing the direction (i.e., Left or Right) and the distance to the nearest end point. This problem is arisen from {\em self-stabilizing} location problems by {\em autonomous mobile robots} with {\em limited visibility}, that is a widely interested abstract model in distributed computing. Contrary to appearances, it is far from trivial if this simple problem is solvable or not, and unsettled yet. This paper is concerned with three variants of the problem with a minimal relaxation, and presents self-stabilizing algorithms for them. We also show an easy impossibility theorem for bilaterally symmetric algorithms.
This paper poses a question about a simple localization problem. The question is if an {\em oblivious} walker on a line-segment can localize the middle point of the line-segment in {\em finite} steps observing the direction (i.e., Left or Right) and the distance to the nearest end point. This problem is arisen from {\em self-stabilizing} location problems by {\em autonomous mobile robots} with {\em limited visibility}, that is a widely interested abstract model in distributed computing. Contrary to appearances, it is far from trivial if this simple problem is solvable or not, and unsettled yet. This paper is concerned with three variants of the problem with a minimal relaxation, and presents self-stabilizing algorithms for them. We also show an easy impossibility theorem for bilaterally symmetric algorithms.




 This paper severs as a user guide to the graph partitioning framework KaHIP (Karlsruhe High Quality Partitioning). We give a rough overview of the techniques used within the framework and describe the user interface as well as the file formats used. Moreover, we provide a short description of the current library functions provided within the framework. Since version 3.00 we support multilevel partitioning, memetic algorithms, distributed and shared-memory parallel algorithms, node separator and ordering algorithms, edge partitioning algorithms as well as ILP solvers.
This paper severs as a user guide to the graph partitioning framework KaHIP (Karlsruhe High Quality Partitioning). We give a rough overview of the techniques used within the framework and describe the user interface as well as the file formats used. Moreover, we provide a short description of the current library functions provided within the framework. Since version 3.00 we support multilevel partitioning, memetic algorithms, distributed and shared-memory parallel algorithms, node separator and ordering algorithms, edge partitioning algorithms as well as ILP solvers.




 The degree splitting problem requires coloring the edges of a graph red or blue such that each node has almost the same number of edges in each color, up to a small additive discrepancy. The directed variant of the problem requires orienting the edges such that each node has almost the same number of incoming and outgoing edges, again up to a small additive discrepancy. We present deterministic distributed algorithms for both variants, which improve on their counterparts presented by Ghaffari and Su [SODA'17]: our algorithms are significantly simpler and faster, and have a much smaller discrepancy. This also leads to a faster and simpler deterministic algorithm for $(2+o(1))\Delta$-edge-coloring, improving on that of Ghaffari and Su.
The degree splitting problem requires coloring the edges of a graph red or blue such that each node has almost the same number of edges in each color, up to a small additive discrepancy. The directed variant of the problem requires orienting the edges such that each node has almost the same number of incoming and outgoing edges, again up to a small additive discrepancy. We present deterministic distributed algorithms for both variants, which improve on their counterparts presented by Ghaffari and Su [SODA'17]: our algorithms are significantly simpler and faster, and have a much smaller discrepancy. This also leads to a faster and simpler deterministic algorithm for $(2+o(1))\Delta$-edge-coloring, improving on that of Ghaffari and Su.