-
Matsumoto and Amano (2008) showed that every single-qubit Clifford+T operator
can be uniquely written of a particular form, which we call the Matsumoto-Amano
normal form. In this mostly expository paper, we give a detailed and
streamlined presentation of Matsumoto and Amano's results, simplifying some
proofs along the way. We also point out some corollaries to Matsumoto and
Amano's work, including an intrinsic characterization of the Clifford+T
subgroup of SO(3), which also yields an efficient T-optimal exact single-qubit
synthesis algorithm. Interestingly, this also gives an alternative proof of
Kliuchnikov, Maslov, and Mosca's exact synthesis result for the Clifford+T
subgroup of U(2).
-
The promise of chemical computation lies in controlling systems incompatible
with traditional electronic micro-controllers, with applications in synthetic
biology and nano-scale manufacturing. Computation is typically embedded in
kinetics---the specific time evolution of a chemical system. However, if the
desired output is not thermodynamically stable, basic physical chemistry
dictates that thermodynamic forces will drive the system toward error
throughout the computation. The thermodynamic binding network (TBN) model was
introduced to formally study how the thermodynamic equilibrium can be made
consistent with the desired computation, and it idealizes tradeoffs between
configurational entropy and binding. Here we prove the computational hardness
of natural questions about TBNs and develop a practical algorithm for verifying
the correctness of constructions by translating the problem into propositional
logic and solving the resulting formula. The TBN model together with automated
verification tools will help inform strategies for error reduction in molecular
computing, including the extensively studied models of strand displacement
cascades and algorithmic tile assembly.
-
Memristive crossbars have become a popular means for realizing unsupervised
and supervised learning techniques. In previous neuromorphic architectures with
leaky integrate-and-fire neurons, the crossbar itself has been separated from
the neuron capacitors to preserve mathematical rigor. In this work, we sought
to simplify the design, creating a fast circuit that consumed significantly
lower power at a minimal cost of accuracy. We also showed that connecting the
neurons directly to the crossbar resulted in a more efficient sparse coding
architecture, and alleviated the need to pre-normalize receptive fields. This
work provides derivations for the design of such a network, named the Simple
Spiking Locally Competitive Algorithm, or SSLCA, as well as CMOS designs and
results on the CIFAR and MNIST datasets. Compared to a non-spiking model which
scored 33% on CIFAR-10 with a single-layer classifier, this hardware scored 32%
accuracy. When used with a state-of-the-art deep learning classifier, the
non-spiking model achieved 82% and our simplified, spiking model achieved 80%,
while compressing the input data by 92%. Compared to a previously proposed
spiking model, our proposed hardware consumed 99% less energy to do the same
work at 21x the throughput. Accuracy held out with online learning to a write
variance of 3%, suitable for the often-reported 4-bit resolution required for
neuromorphic algorithms; with offline learning to a write variance of 27%; and
with read variance to 40%. The proposed architecture's excellent accuracy,
throughput, and significantly lower energy usage demonstrate the utility of our
innovations.
-
We present a uniform method for translating an arbitrary nondeterministic
finite automaton (NFA) into a deterministic mass action input/output chemical
reaction network (I/O CRN) that simulates it. The I/O CRN receives its input as
a continuous time signal consisting of concentrations of chemical species that
vary to represent the NFA's input string in a natural way. The I/O CRN exploits
the inherent parallelism of chemical kinetics to simulate the NFA in real time
with a number of chemical species that is linear in the size of the NFA. We
prove that the simulation is correct and that it is robust with respect to
perturbations of the input signal, the initial concentrations of species, the
output (decision), and the rate constants of the reactions of the I/O CRN.
-
We consider the self-assembly of fractals in one of the most well-studied
models of tile based self-assembling systems known as the Two-handed Tile
Assembly Model (2HAM). In particular, we focus our attention on a class of
fractals called discrete self-similar fractals (a class of fractals that
includes the discrete Sierpi\'nski carpet). We present a 2HAM system that
finitely self-assembles the discrete Sierpi\'nski carpet with scale factor 1.
Moreover, the 2HAM system that we give lends itself to being generalized and we
describe how this system can be modified to obtain a 2HAM system that finitely
self-assembles one of any fractal from an infinite set of fractals which we
call 4-sided fractals. The 2HAM systems we give in this paper are the first
examples of systems that finitely self-assemble discrete self-similar fractals
at scale factor 1 in a purely growth model of self-assembly. Finally, we show
that there exists a 3-sided fractal (which is not a tree fractal) that cannot
be finitely self-assembled by any 2HAM system.
-
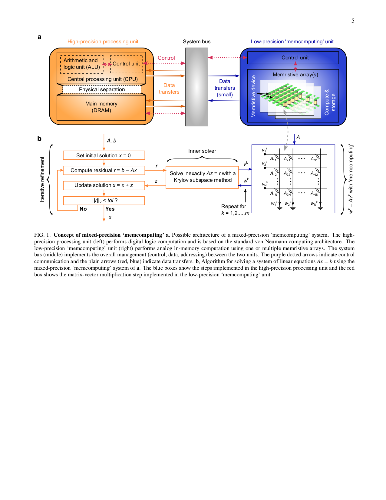
As CMOS scaling reaches its technological limits, a radical departure from
traditional von Neumann systems, which involve separate processing and memory
units, is needed in order to significantly extend the performance of today's
computers. In-memory computing is a promising approach in which nanoscale
resistive memory devices, organized in a computational memory unit, are used
for both processing and memory. However, to reach the numerical accuracy
typically required for data analytics and scientific computing, limitations
arising from device variability and non-ideal device characteristics need to be
addressed. Here we introduce the concept of mixed-precision in-memory
computing, which combines a von Neumann machine with a computational memory
unit. In this hybrid system, the computational memory unit performs the bulk of
a computational task, while the von Neumann machine implements a backward
method to iteratively improve the accuracy of the solution. The system
therefore benefits from both the high precision of digital computing and the
energy/areal efficiency of in-memory computing. We experimentally demonstrate
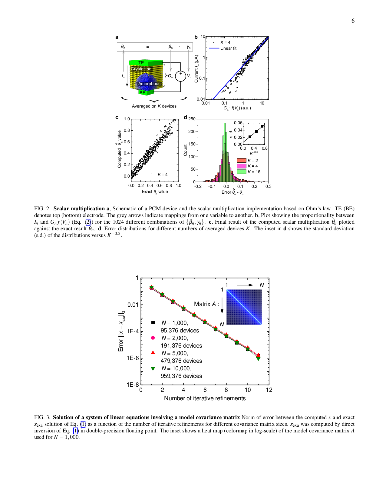
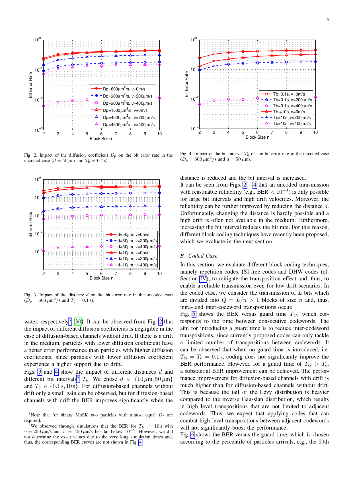
the efficacy of the approach by accurately solving systems of linear equations,
in particular, a system of 5,000 equations using 998,752 phase-change memory
devices.
-
We consider the problem of how to construct a physical process over a finite
state space X that applies some desired conditional distribution P to
initial states to produce final states. This problem arises often in the
thermodynamics of computation and nonequilibrium statistical physics more
generally (e.g., when designing processes to implement some desired
computation, feedback controller, or Maxwell demon). It was previously known
that some conditional distributions cannot be implemented using any master
equation that involves just the states in X. However, here we show that any
conditional distribution P can in fact be implemented---if additional
"hidden" states not in X are available. Moreover, we show that it is always
possible to implement P in a thermodynamically reversible manner. We then
investigate a novel cost of the physical resources needed to implement a given
distribution P: the minimal number of hidden states needed to do so. We
calculate this cost exactly for the special case where P represents a
single-valued function, and provide an upper bound for the general case, in
terms of the nonnegative rank of P. These results show that having access to
one extra binary degree of freedom, thus doubling the total number of states,
is sufficient to implement any P with a master equation in a
thermodynamically reversible way, if there are no constraints on the allowed
form of the master equation. (Such constraints can greatly increase the minimal
needed number of hidden states.) Our results also imply that for certain P
that can be implemented without hidden states, having hidden states permits an
implementation that generates less heat.
-
An analog neural network computing engine based on CMOS-compatible
charge-trap transistor (CTT) is proposed in this paper. CTT devices are used as
analog multipliers. Compared to digital multipliers, CTT-based analog
multiplier shows significant area and power reduction. The proposed computing
engine is composed of a scalable CTT multiplier array and energy efficient
analog-digital interfaces. Through implementing the sequential analog fabric
(SAF), the engine mixed-signal interfaces are simplified and hardware overhead
remains constant regardless of the size of the array. A proof-of-concept 784 by
784 CTT computing engine is implemented using TSMC 28nm CMOS technology and
occupied 0.68mm2. The simulated performance achieves 76.8 TOPS (8-bit) with 500
MHz clock frequency and consumes 14.8 mW. As an example, we utilize this
computing engine to address a classic pattern recognition problem --
classifying handwritten digits on MNIST database and obtained a performance
comparable to state-of-the-art fully connected neural networks using 8-bit
fixed-point resolution.
-
We study the oritatami model for molecular co-transcriptional folding. In
oritatami systems, the transcript (the "molecule") folds as it is synthesized
(transcribed), according to a local energy optimisation process, which is
similar to how actual biomolecules such as RNA fold into complex shapes and
functions as they are transcribed. We prove that there is an oritatami system
embedding universal computation in the folding process itself.
Our result relies on the development of a generic toolbox, which is easily
reusable for future work to design complex functions in oritatami systems. We
develop "low-level" tools that allow to easily spread apart the encoding of
different "functions" in the transcript, even if they are required to be
applied at the same geometrical location in the folding. We build upon these
low-level tools, a programming framework with increasing levels of abstraction,
from encoding of instructions into the transcript to logical analysis. This
framework is similar to the hardware-to-algorithm levels of abstractions in
standard algorithm theory. These various levels of abstractions allow to
separate the proof of correctness of the global behavior of our system, from
the proof of correctness of its implementation. Thanks to this framework, we
were able to computerize the proof of correctness of its implementation and
produce certificates, in the form of a relatively small number of proof trees,
compact and easily readable and checkable by human, while encapsulating huge
case enumerations. We believe this particular type of certificates can be
generalized to other discrete dynamical systems, where proofs involve large
case enumerations as well.
-
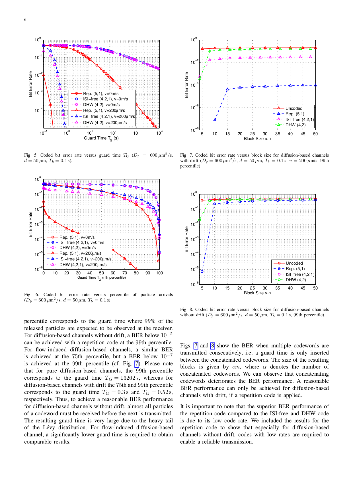
In this work, we consider diffusion-based molecular communication with and
without drift between two static nano-machines. We employ type-based
information encoding, releasing a single molecule per information bit. At the
receiver, we consider an asynchronous detection algorithm which exploits the
arrival order of the molecules. In such systems, transposition errors
fundamentally undermine reliability and capacity. Thus, in this work we study
the impact of transpositions on the system performance. Towards this, we
present an analytical expression for the exact bit error probability (BEP)
caused by transpositions and derive computationally tractable approximations of
the BEP for diffusion-based channels with and without drift. Based on these
results, we analyze the BEP when background is not negligible and derive the
optimal bit interval that minimizes the BEP. Simulation results confirm the
theoretical results and show the error and goodput performance for different
parameters such as block size or noise generation rate.
-
In this paper, we develop a mathematical framework for modeling the
time-variant stochastic channels of diffusive mobile MC systems. In particular,
we consider a diffusive mobile MC system consisting of a pair of transmitter
and receiver nano-machines suspended in a fluid medium with a uniform bulk
flow, where we assume that either the transmitter, or the receiver, or both are
mobile and we model the mobility by Brownian motion. The transmitter and
receiver nano-machines exchange information via diffusive signaling molecules.
Due to the random movements of the transmitter and receiver nano-machines, the
statistics of the channel impulse response (CIR) change over time. We derive
closed-form expressions for the mean, the autocorrelation function (ACF), the
cumulative distribution function (CDF), and the probability density function
(PDF) of the time-variant CIR. Exploiting the ACF, we define the coherence time
of the time-variant MC channel as a metric for characterization of the
variations of the CIR. The derived CDF is employed for calculation of the
outage probability of the system. We also show that under certain conditions,
the PDF of the CIR can be accurately approximated by a Log-normal distribution.
Based on this approximation, we derive a simple model for outdated channel
state information (CSI). Moreover, we derive an analytical expression for
evaluation of the expected error probability of a simple detector for the
considered MC system. In order to investigate the impact of CIR decorrelation
over time, we compare the performances of a detector with perfect CSI knowledge
and a detector with outdated CSI knowledge. The accuracy of the proposed
analytical expressions is verified via particle-based simulation of the
Brownian motion.
-
In this paper we improve the layered implementation of arbitrary stabilizer
circuits introduced by Aaronson and Gottesman in Phys. Rev. A 70(052328), 2004:
to obtain a general stabilizer circuit, we reduce their 11-stage computation
-H-C-P-C-P-C-H-P-C-P-C- over the gate set consisting of Hadamard,
Controlled-NOT, and Phase gates, into a 7-stage computation of the form
-C-CZ-P-H-P-CZ-C-. We show arguments in support of using -CZ- stages over the
-C- stages: not only the use of -CZ- stages allows a shorter layered
expression, but -CZ- stages are simpler and appear to be easier to implement
compared to the -C- stages. Based on this decomposition, we develop a two-qubit
gate depth-(14n−4) implementation of stabilizer circuits over the gate
library {H, P, CNOT}, executable in the Linear Nearest Neighbor (LNN)
architecture, improving best previously known depth-25n circuit, also
executable in the LNN architecture. Our constructions rely on Bruhat
decomposition of the symplectic group and on folding arbitrarily long sequences
of the form (-P-C-)m into a 3-stage computation -P-CZ-C-. Our results
include the reduction of the 11-stage decomposition -H-C-P-C-P-C-H-P-C-P-C-
into a 9-stage decomposition of the form -C-P-C-P-H-C-P-C-P-. This reduction
is based on the Bruhat decomposition of the symplectic group. This result also
implies a new normal form for stabilizer circuits. We show that a circuit in
this normal form is optimal in the number of Hadamard gates used. We also show
that the normal form has an asymptotically optimal number of parameters.
-
A low-energy hardware implementation of deep belief network (DBN)
architecture is developed using near-zero energy barrier probabilistic spin
logic devices (p-bits), which are modeled to realize an intrinsic sigmoidal
activation function. A CMOS/spin based weighted array structure is designed to
implement a restricted Boltzmann machine (RBM). Device-level simulations based
on precise physics relations are used to validate the sigmoidal relation
between the output probability of a p-bit and its input currents.
Characteristics of the resistive networks and p-bits are modeled in SPICE to
perform a circuit-level simulation investigating the performance, area, and
power consumption tradeoffs of the weighted array. In the application-level
simulation, a DBN is implemented in MATLAB for digit recognition using the
extracted device and circuit behavioral models. The MNIST data set is used to
assess the accuracy of the DBN using 5,000 training images for five distinct
network topologies. The results indicate that a baseline error rate of 36.8%
for a 784x10 DBN trained by 100 samples can be reduced to only 3.7% using a
784x800x800x10 DBN trained by 5,000 input samples. Finally, Power dissipation
and accuracy tradeoffs for probabilistic computing mechanisms using resistive
devices are identified.
-
Master equations are commonly used to model the dynamics of physical systems,
including systems that implement single-valued functions like a computer's
update step. However, many such functions cannot be implemented by any master
equation, even approximately, which raises the question of how they can occur
in the real world. Here we show how any function over some "visible" states can
be implemented with master equation dynamics--if the dynamics exploits
additional, "hidden" states at intermediate times. We also show that any master
equation implementing a function can be decomposed into a sequence of "hidden"
timesteps, demarcated by changes in what state-to-state transitions have
nonzero probability. In many real-world situations there is a cost both for
more hidden states and for more hidden timesteps. Accordingly, we derive a
"space-time" tradeoff between the number of hidden states and the number of
hidden timesteps needed to implement any given function.
-
Quantum computation is a promising emerging technology which, compared to
conventional computation, allows for substantial speed-ups e.g. for integer
factorization or database search. However, since physical realizations of
quantum computers are in their infancy, a significant amount of research in
this domain still relies on simulations of quantum computations on conventional
machines. This causes a significant complexity which current state-of-the-art
simulators try to tackle with a rather straight forward array-based
representation and by applying massive hardware power. There also exist
solutions based on decision diagrams (i.e. graph-based approaches) that try to
tackle the exponential complexity by exploiting redundancies in quantum states
and operations. However, these existing approaches do not fully exploit
redundancies that are actually present. In this work, we revisit the basics of
quantum computation, investigate how corresponding quantum states and quantum
operations can be represented even more compactly, and, eventually, simulated
in a more efficient fashion. This leads to a new graph-based simulation
approach which outperforms state-of-the-art simulators (array-based as well as
graph-based). Experimental evaluations show that the proposed solution is
capable of simulating quantum computations for more qubits than before, and in
significantly less run-time (several magnitudes faster compared to previously
proposed simulators). An implementation of the proposed simulator is publicly
available online at http://iic.jku.at/eda/research/quantum_simulation.
-
We develop and implement automated methods for optimizing quantum circuits of
the size and type expected in quantum computations that outperform classical
computers. We show how to handle continuous gate parameters and report a
collection of fast algorithms capable of optimizing large-scale quantum
circuits. For the suite of benchmarks considered, we obtain substantial
reductions in gate counts. In particular, we provide better optimization in
significantly less time than previous approaches, while making minimal
structural changes so as to preserve the basic layout of the underlying quantum
algorithms. Our results help bridge the gap between the computations that can
be run on existing hardware and those that are expected to outperform classical
computers.
-
In this paper we propose a novel method of realizing discrete-time (D-T)
signal amplification using Nano-Electro-Mechanical (NEMS) devices. The
amplifier uses mechanical devices instead of traditional solid-state circuits.
The proposed NEMS-based D-T amplifier provides high gain and operate on a wide
dynamic range of signals, consuming only a few micro watts of power. The
proposed concept is subsequently verified using Verilog-A model of the NEMS
device. Modifications in the proposed amplifier to suit different
specifications are also presented.
-
As the effort to scale up existing quantum hardware proceeds, it becomes
necessary to schedule quantum gates in a way that minimizes the number of
operations. There are three constraints that have to be satisfied: the order or
dependency of the quantum gates in the specific algorithm, the fact that any
qubit may be involved in at most one gate at a time, and the restriction that
two-qubit gates are implementable only between connected qubits. The last
aspect implies that the compilation depends not only on the algorithm, but also
on hardware properties like connectivity. Here we suggest a two-step approach
in which logical gates are initially scheduled neglecting connectivity
considerations, while routing operations are added at a later step in a way
that minimizes their overhead. We rephrase the subtasks of gate scheduling in
terms of graph problems like edge-coloring and maximum subgraph isomorphism.
While this approach is general, we specialize to a one dimensional array of
qubits to propose a routing scheme that is minimal in the number of exchange
operations. As a practical application, we schedule the Quantum Approximate
Optimization Algorithm in a linear geometry and quantify the reduction in the
number of gates and circuit depth that results from increasing the efficacy of
the scheduling strategies.
-
Quantum-dot cellular automata (QCA) is a low-power, non-von-Neumann,
general-purpose paradigm for classical computing using transistor-free logic.
An elementary QCA device called a "cell" is made from a system of coupled
quantum dots with a few mobile charges. The cell's charge configuration encodes
a bit, and quantum charge tunneling within a cell enables device switching.
Arrays of cells networked locally via the electrostatic field form QCA
circuits, which mix logic, memory and interconnect. A molecular QCA
implementation promises ultra-high device densities, high switching speeds, and
room-temperature operation. We propose a novel approach to the technical
challenge of transducing bits from larger conventional devices to nanoscale QCA
molecules. This signal transduction begins with lithographically-formed
electrodes placed on the device plane. A voltage applied across these
electrodes establishes an in-plane electric field, which selects a bit packet
on a large QCA input circuit. A typical QCA binary wire may be used to transmit
a smaller bit packet of a size more suitable for processing from this input to
other QCA circuitry. In contrast to previous concepts for bit inputs to
molecular QCA which require special QCA cells with fixed states, this approach
allows circuits to be comprised of cells of only one species. A brief overview
of the QCA paradigm is given. Proof-of-principle simulation results are shown,
demonstrating the input concept in circuits made from two-dot QCA cells.
-
Advanced electronic device technologies require a faster operation and
smaller average power consumption, which are the most important parameters in
very large scale integrated circuit design. The conventional Complementary
Metal-Oxide Semiconductor (CMOS) technology is limited by the threshold voltage
and subthreshold leakage problems in scaling of devices. This leads to failure
in adapting it to sub-micron and nanotechnologies. The carbon nanotube (CNT)
technology overcomes the threshold voltage and subthreshold leakage problems
despite reduction in size. The CNT based technology develops the most promising
devices among emerging technologies because it has most of the desired
features. Carbon Nanotube Field Effect Transistors (CNFETs) are the novel
devices that are expected to sustain the transistor scalability while
increasing its performance. Recently, there have been tremendous advances in
CNT technology for nanoelectronics applications. CNFETs avoid most of the
fundamental limitations and offer several advantages compared to silicon-based
technology. Though CNT evolves as a better option to overcome some of the bulk
CMOS problems, the CNT itself still immersed with setbacks. The fabrication of
carbon nanotube at very large digital circuits on a single substrate is
difficult to achieve. Therefore, a hybrid NP dynamic Carry Look Ahead Adder
(CLA) is designed using p-CNFET and n-MOS transistors. Here, the performance of
CLA is evaluated in 8-bit, 16-bit, 32-bit and 64-bit stages with the following
four different implementations: silicon MOSFET (Si-MOSFET) domino logic,
Si-MOSFET NP dynamic CMOS, carbon nanotube MOSFET (CN-MOSFET) domino logic, and
CN-MOSFET NP dynamic CMOS. Finally, a Hybrid CMOS-CNFET based 64-bit NP dynamic
CLA is evaluated based on HSPICE simulation in 32nm technology, which
effectively suppresses power dissipation without an increase in propagation
delay.
-
Analog-to-digital (quantization) and digital-to-analog (de-quantization)
conversion are fundamental operations of many information processing systems.
In practice, the precision of these operations is always bounded, first by the
random mismatch error (ME) occurred during system implementation, and
subsequently by the intrinsic quantization error (QE) determined by the system
architecture itself. In this manuscript, we present a new mathematical
interpretation of the previously proposed redundant sensing (RS) architecture
that not only suppresses ME but also allows achieving an effective resolution
exceeding the system's intrinsic resolution, i.e. super-resolution (SR). SR is
enabled by an endogenous property of redundant structures regarded as "code
diffusion" where the references' value spreads into the neighbor sample space
as a result of ME. The proposed concept opens the possibility for a wide range
of applications in low-power fully-integrated sensors and devices where the
cost-accuracy trade-off is inevitable.
-
Recently, Deep Convolutional Neural Network (DCNN) has achieved tremendous
success in many machine learning applications. Nevertheless, the deep structure
has brought significant increases in computation complexity. Largescale deep
learning systems mainly operate in high-performance server clusters, thus
restricting the application extensions to personal or mobile devices. Previous
works on GPU and/or FPGA acceleration for DCNNs show increasing speedup, but
ignore other constraints, such as area, power, and energy. Stochastic Computing
(SC), as a unique data representation and processing technique, has the
potential to enable the design of fully parallel and scalable hardware
implementations of large-scale deep learning systems. This paper proposed an
automatic design allocation algorithm driven by budget requirement considering
overall accuracy performance. This systematic method enables the automatic
design of a DCNN where all design parameters are jointly optimized.
Experimental results demonstrate that proposed algorithm can achieve a joint
optimization of all design parameters given the comprehensive budget of a DCNN.
-
Diffraction drastically limits the bit density in optical data storage. To
increase the storage density, alternative strategies involving supplementary
recording dimensions and robust read-out schemes must be explored. Here, we
propose to encode multiple bits of information in the geometry of subwavelength
dielectric nanostructures. A crucial problem in high-density information
storage concepts is the robustness of the information readout with respect to
fabrication errors and experimental noise. Using a machine-learning based
approach in which the scattering spectra are analyzed by an artificial neural
network, we achieve quasi error free read-out of 4-bit sequences, encoded in
top-down fabricated silicon nanostructures. The read-out speed can further be
increased exploiting the RGB values of microscopy images, and the information
density could be increased beyond current state of the art. Our work paves the
way towards high-density optical information storage using planar silicon
nanostructures, compatible with mass-production ready CMOS technology.
-
This paper presents a survey of the currently available hardware designs for
implementation of the human cortex inspired algorithm, Hierarchical Temporal
Memory (HTM). In this review, we focus on the state of the art advances of
memristive HTM implementation and related HTM applications. With the advent of
edge computing, HTM can be a potential algorithm to implement on-chip near
sensor data processing. The comparison of analog memristive circuit
implementations with the digital and mixed-signal solutions are provided. The
advantages of memristive HTM over digital implementations against performance
metrics such as processing speed, reduced on-chip area and power dissipation
are discussed. The limitations and open problems concerning the memristive HTM,
such as the design scalability, sneak currents, leakage, parasitic effects,
lack of the analog learning circuits implementations and unreliability of the
memristive devices integrated with CMOS circuits are also discussed.
-
Circuits using superconducting single-photon detectors and Josephson
junctions to perform signal reception, synaptic weighting, and integration are
investigated. The circuits convert photon-detection events into flux quanta,
the number of which is determined by the synaptic weight. The current from many
synaptic connections is inductively coupled to a superconducting loop that
implements the neuronal threshold operation. Designs are presented for synapses
and neurons that perform integration as well as detect coincidence events for
temporal coding. Both excitatory and inhibitory connections are demonstrated.
It is shown that a neuron with a single integration loop can receive input from
1000 such synaptic connections, and neurons of similar design could employ many
loops for dendritic processing.