-
Device-independent security is the gold standard for quantum cryptography:
not only is security based entirely on the laws of quantum mechanics, but it
holds irrespective of any a priori assumptions on the quantum devices used in a
protocol, making it particularly applicable in a quantum-wary environment.
While the existence of device-independent protocols for tasks such as
randomness expansion and quantum key distribution has recently been
established, the underlying proofs of security remain very challenging, yield
rather poor key rates, and demand very high-quality quantum devices, thus
making them all but impossible to implement in practice.
We introduce a technique for the analysis of device-independent cryptographic
protocols. We provide a flexible protocol and give a security proof that
provides quantitative bounds that are asymptotically tight, even in the
presence of general quantum adversaries. At a high level our approach amounts
to establishing a reduction to the scenario in which the untrusted device
operates in an identical and independent way in each round of the protocol.
This is achieved by leveraging the sequential nature of the protocol, and makes
use of a newly developed tool, the "entropy accumulation theorem" of Dupuis et
al.
As concrete applications we give simple and modular security proofs for
device-independent quantum key distribution and randomness expansion protocols
based on the CHSH inequality. For both tasks we establish essentially optimal
asymptotic key rates and noise tolerance. In view of recent experimental
progress, which has culminated in loophole-free Bell tests, it is likely that
these protocols can be practically implemented in the near future.
-
We advance the state-of-the-art in automated symbolic analysis for e-voting
protocols by introducing three conditions that together are sufficient to
guarantee ballot secrecy. There are two main advantages to using our
conditions, compared to existing automated approaches. The first is a
substantial expansion of the class of protocols and threat models that can be
automatically analysed: we can systematically deal with (a) honest authorities
present in different phases, (b) threat models in which no dishonest voters
occur, and (c) protocols whose ballot secrecy depends on fresh data coming from
other phases. The second advantage is that it can significantly improve
verification efficiency, as the individual conditions are often simpler to
verify. E.g., for the LEE protocol, we obtain a speedup of over two orders of
magnitude. We show the scope and effectiveness of our approach using ProVerif
in several case studies, including FOO, LEE, JCJ, and Belenios. In these case
studies, our approach does not yield any false attacks, suggesting that our
conditions are tight.
-
Machine learning (ML) techniques are increasingly common in security
applications, such as malware and intrusion detection. However, ML models are
often susceptible to evasion attacks, in which an adversary makes changes to
the input (such as malware) in order to avoid being detected. A conventional
approach to evaluate ML robustness to such attacks, as well as to design robust
ML, is by considering simplified feature-space models of attacks, where the
attacker changes ML features directly to effect evasion, while minimizing or
constraining the magnitude of this change. We investigate the effectiveness of
this approach to designing robust ML in the face of attacks that can be
realized in actual malware (realizable attacks). We demonstrate that in the
context of structure-based PDF malware detection, such techniques appear to
have limited effectiveness, but they are effective with content-based
detectors. In either case, we show that augmenting the feature space models
with conserved features (those that cannot be unilaterally modified without
compromising malicious functionality) significantly improves performance.
Finally, we show that feature space models enable generalized robustness when
faced with a variety of realizable attacks, as compared to classifiers which
are tuned to be robust to a specific realizable attack.
-
Deep learning-based techniques have achieved state-of-the-art performance on
a wide variety of recognition and classification tasks. However, these networks
are typically computationally expensive to train, requiring weeks of
computation on many GPUs; as a result, many users outsource the training
procedure to the cloud or rely on pre-trained models that are then fine-tuned
for a specific task. In this paper we show that outsourced training introduces
new security risks: an adversary can create a maliciously trained network (a
backdoored neural network, or a \emph{BadNet}) that has state-of-the-art
performance on the user's training and validation samples, but behaves badly on
specific attacker-chosen inputs. We first explore the properties of BadNets in
a toy example, by creating a backdoored handwritten digit classifier. Next, we
demonstrate backdoors in a more realistic scenario by creating a U.S. street
sign classifier that identifies stop signs as speed limits when a special
sticker is added to the stop sign; we then show in addition that the backdoor
in our US street sign detector can persist even if the network is later
retrained for another task and cause a drop in accuracy of {25}\% on average
when the backdoor trigger is present. These results demonstrate that backdoors
in neural networks are both powerful and---because the behavior of neural
networks is difficult to explicate---stealthy. This work provides motivation
for further research into techniques for verifying and inspecting neural
networks, just as we have developed tools for verifying and debugging software.
-
Modern authentication systems store hashed values of passwords of users using
cryptographic hash functions. Therefore, to crack a password an attacker needs
to guess a hash function input that is mapped to the hashed value, as opposed
to the password itself. We call a hash function that maps the same number of
inputs to each bin, as \textbf{unbiased}. However, cryptographic hash functions
in use have not been proven to be unbiased (i.e., they may have an unequal
number of inputs mapped to different bins). A cryptographic hash function has
the property that it is computationally difficult to find an input mapped to a
bin. In this work we introduce a structured notion of biased hash functions for
which we analyze the average guesswork under certain types of brute force
attacks. This work shows that the level of security depends on the set of
hashed values of valid users as well as the statistical profile of a hash
function, resulting from bias. We examine the average guesswork conditioned on
the set of hashed values, and model the statistical profile through the
empirical distribution of the number of inputs that are mapped to a bin. In
particular, we focus on a class of statistical profiles (capturing the bias) ,
which we call type-class statistical profiles, that has an empirical
distribution related to the probability of the type classes defined in the
method of types. For such profiles, we show that the average guesswork is
related to basic measures in information theory such as entropy and divergence.
We use this to show that the effect of bias on the conditional average
guesswork is limited compared to other system parameters such as the number of
valid users who store their hashed passwords in the system.
-
In this paper we characterize the set of polynomials $f\in\mathbb F_q[X]$
satisfying the following property: there exists a positive integer $d$ such
that for any positive integer $\ell$ less or equal than the degree of $f$,
there exists $t_0$ in $\mathbb F_{q^d}$ such that the polynomial $f-t_0$ has an
irreducible factor of degree $\ell$ over $\mathbb F_{q^d}[X]$. This result is
then used to progress in the last step which is needed to remove the heuristic
from one of the quasi-polynomial time algorithms for discrete logarithm
problems (DLP) in small characteristic. Our characterization allows a
construction of polynomials satisfying the wanted property. The method is
general and can be used to tackle similar problems which involve factorization
patterns of polynomials over finite fields.
-
State-of-the-art password guessing tools, such as HashCat and John the
Ripper, enable users to check billions of passwords per second against password
hashes. In addition to performing straightforward dictionary attacks, these
tools can expand password dictionaries using password generation rules, such as
concatenation of words (e.g., "password123456") and leet speak (e.g.,
"password" becomes "p4s5w0rd"). Although these rules work well in practice,
expanding them to model further passwords is a laborious task that requires
specialized expertise. To address this issue, in this paper we introduce
PassGAN, a novel approach that replaces human-generated password rules with
theory-grounded machine learning algorithms. Instead of relying on manual
password analysis, PassGAN uses a Generative Adversarial Network (GAN) to
autonomously learn the distribution of real passwords from actual password
leaks, and to generate high-quality password guesses. Our experiments show that
this approach is very promising. When we evaluated PassGAN on two large
password datasets, we were able to surpass rule-based and state-of-the-art
machine learning password guessing tools. However, in contrast with the other
tools, PassGAN achieved this result without any a-priori knowledge on passwords
or common password structures. Additionally, when we combined the output of
PassGAN with the output of HashCat, we were able to match 51%-73% more
passwords than with HashCat alone. This is remarkable, because it shows that
PassGAN can autonomously extract a considerable number of password properties
that current state-of-the art rules do not encode.
-
Data sharing among partners---users, organizations, companies---is crucial
for the advancement of data analytics in many domains. Sharing through secure
computation and differential privacy allows these partners to perform private
computations on their sensitive data in controlled ways. However, in reality,
there exist complex relationships among members. Politics, regulations,
interest, trust, data demands and needs are one of the many reasons. Thus,
there is a need for a mechanism to meet these conflicting relationships on data
sharing. This paper presents Curie, an approach to exchange data among members
whose membership has complex relationships. The CPL policy language that allows
members to define the specifications of data exchange requirements is
introduced. Members (partners) assert who and what to exchange through their
local policies and negotiate a global sharing agreement. The agreement is
implemented in a multi-party computation that guarantees sharing among members
will comply with the policy as negotiated. The use of Curie is validated
through an example of a health care application built on recently introduced
secure multi-party computation and differential privacy frameworks, and policy
and performance trade-offs are explored.
-
Gated Recurrent Unit (GRU) is a recently-developed variation of the long
short-term memory (LSTM) unit, both of which are types of recurrent neural
network (RNN). Through empirical evidence, both models have been proven to be
effective in a wide variety of machine learning tasks such as natural language
processing (Wen et al., 2015), speech recognition (Chorowski et al., 2015), and
text classification (Yang et al., 2016). Conventionally, like most neural
networks, both of the aforementioned RNN variants employ the Softmax function
as its final output layer for its prediction, and the cross-entropy function
for computing its loss. In this paper, we present an amendment to this norm by
introducing linear support vector machine (SVM) as the replacement for Softmax
in the final output layer of a GRU model. Furthermore, the cross-entropy
function shall be replaced with a margin-based function. While there have been
similar studies (Alalshekmubarak & Smith, 2013; Tang, 2013), this proposal is
primarily intended for binary classification on intrusion detection using the
2013 network traffic data from the honeypot systems of Kyoto University.
Results show that the GRU-SVM model performs relatively higher than the
conventional GRU-Softmax model. The proposed model reached a training accuracy
of ~81.54% and a testing accuracy of ~84.15%, while the latter was able to
reach a training accuracy of ~63.07% and a testing accuracy of ~70.75%. In
addition, the juxtaposition of these two final output layers indicate that the
SVM would outperform Softmax in prediction time - a theoretical implication
which was supported by the actual training and testing time in the study.
-
Capture the Flag (CTF) competitions are increasingly important for the
Brazilian cybersecurity community as education and professional tools.
Unfortunately, CTF platforms may suffer from security issues, giving an unfair
advantage to competitors. To mitigate this, we propose NIZKCTF, the first
open-audit CTF platform based on non-interactive zero-knowledge proofs.
-
We consider two basic algorithmic problems concerning tuples of
(skew-)symmetric matrices. The first problem asks to decide, given two tuples
of (skew-)symmetric matrices $(B_1, \dots, B_m)$ and $(C_1, \dots, C_m)$,
whether there exists an invertible matrix $A$ such that for every $i\in\{1,
\dots, m\}$, $A^tB_iA=C_i$. We show that this problem can be solved in
randomized polynomial time over finite fields of odd size, the real field, and
the complex field. The second problem asks to decide, given a tuple of square
matrices $(B_1, \dots, B_m)$, whether there exist invertible matrices $A$ and
$D$, such that for every $i\in\{1, \dots, m\}$, $AB_iD$ is (skew-)symmetric. We
show that this problem can be solved in deterministic polynomial time over
fields of characteristic not $2$. For both problems we exploit the structure of
the underlying $*$-algebras, and utilize results and methods from the module
isomorphism problem.
Applications of our results range from multivariate cryptography, group
isomorphism, to polynomial identity testing. Specifically, these results imply
efficient algorithms for the following problems. (1) Test isomorphism of
quadratic forms with one secret over a finite field of odd size. This problem
belongs to a family of problems that serves as the security basis of certain
authentication schemes proposed by Patarin (Eurocrypto 1996). (2) Test
isomorphism of $p$-groups of class 2 and exponent $p$ ($p$ odd) with order
$p^k$ in time polynomial in the group order, when the commutator subgroup is of
order $p^{O(\sqrt{k})}$. (3) Deterministically reveal two families of
singularity witnesses caused by the skew-symmetric structure, which represents
a natural next step for the polynomial identity testing problem following the
direction set up by the recent resolution of the non-commutative rank problem
(Garg et al., FOCS 2016; Ivanyos et al., ITCS 2017).
-
Constructing a Pseudo Random Function (PRF) is a fundamental problem in
cryptology. Such a construction, implemented by truncating the last $m$ bits of
permutations of $\{0, 1\}^{n}$ was suggested by Hall et al. (1998). They
conjectured that the distinguishing advantage of an adversary with $q$ queries,
${\bf Adv}_{n, m} (q)$, is small if $q = o (2^{(n+m)/2})$, established an upper
bound on ${\bf Adv}_{n, m} (q)$ that confirms the conjecture for $m < n/7$, and
also declared a general lower bound ${\bf Adv}_{n,m}(q)=\Omega(q^2/2^{n+m})$.
The conjecture was essentially confirmed by Bellare and Impagliazzo (1999).
Nevertheless, the problem of {\em estimating} ${\bf Adv}_{n, m} (q)$ remained
open. Combining the trivial bound $1$, the birthday bound, and a result of Stam
(1978) leads to the upper bound \begin{equation*} {\bf Adv}_{n,m}(q) =
O\left(\min\left\{\frac{q(q-1)}{2^n},\,\frac{q}{2^{\frac{n+m}{2}}},\,1\right\}\right).
\end{equation*} In this paper we show that this upper bound is tight for every
$0\leq m<n$ and any $q$. This, in turn, verifies that the converse to the
conjecture of Hall et al. is also correct, i.e., that ${\bf Adv}_{n, m} (q)$ is
negligible only for $q = o (2^{(n+m)/2})$.
-
Many efficient data structures use randomness, allowing them to improve upon
deterministic ones. Usually, their efficiency and correctness are analyzed
using probabilistic tools under the assumption that the inputs and queries are
independent of the internal randomness of the data structure. In this work, we
consider data structures in a more robust model, which we call the adversarial
model. Roughly speaking, this model allows an adversary to choose inputs and
queries adaptively according to previous responses. Specifically, we consider a
data structure known as "Bloom filter" and prove a tight connection between
Bloom filters in this model and cryptography.
A Bloom filter represents a set $S$ of elements approximately, by using fewer
bits than a precise representation. The price for succinctness is allowing some
errors: for any $x \in S$ it should always answer `Yes', and for any $x \notin
S$ it should answer `Yes' only with small probability.
In the adversarial model, we consider both efficient adversaries (that run in
polynomial time) and computationally unbounded adversaries that are only
bounded in the number of queries they can make. For computationally bounded
adversaries, we show that non-trivial (memory-wise) Bloom filters exist if and
only if one-way functions exist. For unbounded adversaries we show that there
exists a Bloom filter for sets of size $n$ and error $\varepsilon$, that is
secure against $t$ queries and uses only $O(n \log{\frac{1}{\varepsilon}}+t)$
bits of memory. In comparison, $n\log{\frac{1}{\varepsilon}}$ is the best
possible under a non-adaptive adversary.
-
Galois field (GF) arithmetic is used to implement critical arithmetic
components in communication and security-related hardware, and verification of
such components is of prime importance. Current techniques for formally
verifying such components are based on computer algebra methods that proved
successful in verification of integer arithmetic circuits. However, these
methods are sequential in nature and do not offer any parallelism. This paper
presents an algebraic functional verification technique of gate-level GF (2m )
multipliers, in which verification is performed in bit-parallel fashion. The
method is based on extracting a unique polynomial in Galois field of each
output bit independently. We demonstrate that this method is able to verify an
n-bit GF multiplier in n threads. Experiments performed on pre- and
post-synthesized Mastrovito and Montgomery multipliers show high efficiency up
to 571 bits.
-
Recent studies observe that app foreground is the most striking component
that influences the access control decisions in mobile platform, as users tend
to deny permission requests lacking visible evidence. However, none of the
existing permission models provides a systematic approach that can
automatically answer the question: Is the resource access indicated by app
foreground? In this work, we present the design, implementation, and evaluation
of COSMOS, a context-aware mediation system that bridges the semantic gap
between foreground interaction and background access, in order to protect
system integrity and user privacy. Specifically, COSMOS learns from a large set
of apps with similar functionalities and user interfaces to construct generic
models that detect the outliers at runtime. It can be further customized to
satisfy specific user privacy preference by continuously evolving with user
decisions. Experiments show that COSMOS achieves both high precision and high
recall in detecting malicious requests. We also demonstrate the effectiveness
of COSMOS in capturing specific user preferences using the decisions collected
from 24 users and illustrate that COSMOS can be easily deployed on smartphones
as a real-time guard with a very low performance overhead.
-
Advanced persistent threats (APTs) are stealthy attacks which make use of
social engineering and deception to give adversaries insider access to
networked systems. Against APTs, active defense technologies aim to create and
exploit information asymmetry for defenders. In this paper, we study a scenario
in which a powerful defender uses honeynets for active defense in order to
observe an attacker who has penetrated the network. Rather than immediately
eject the attacker, the defender may elect to gather information. We introduce
an undiscounted, infinite-horizon Markov decision process on a continuous state
space in order to model the defender's problem. We find a threshold of
information that the defender should gather about the attacker before ejecting
him. Then we study the robustness of this policy using a Stackelberg game.
Finally, we simulate the policy for a conceptual network. Our results provide a
quantitative foundation for studying optimal timing for attacker engagement in
network defense.
-
In this article, we propose a new implementation of John von Neumann's middle
square random number generator (RNG). A Weyl sequence keeps the generator
running through a long period.
-
Recently, many studies have demonstrated deep neural network (DNN)
classifiers can be fooled by the adversarial example, which is crafted via
introducing some perturbations into an original sample. Accordingly, some
powerful defense techniques were proposed. However, existing defense techniques
often require modifying the target model or depend on the prior knowledge of
attacks. In this paper, we propose a straightforward method for detecting
adversarial image examples, which can be directly deployed into unmodified
off-the-shelf DNN models. We consider the perturbation to images as a kind of
noise and introduce two classic image processing techniques, scalar
quantization and smoothing spatial filter, to reduce its effect. The image
entropy is employed as a metric to implement an adaptive noise reduction for
different kinds of images. Consequently, the adversarial example can be
effectively detected by comparing the classification results of a given sample
and its denoised version, without referring to any prior knowledge of attacks.
More than 20,000 adversarial examples against some state-of-the-art DNN models
are used to evaluate the proposed method, which are crafted with different
attack techniques. The experiments show that our detection method can achieve a
high overall F1 score of 96.39% and certainly raises the bar for defense-aware
attacks.
-
In this paper, we present an effective method to craft text adversarial
samples, revealing one important yet underestimated fact that DNN-based text
classifiers are also prone to adversarial sample attack. Specifically,
confronted with different adversarial scenarios, the text items that are
important for classification are identified by computing the cost gradients of
the input (white-box attack) or generating a series of occluded test samples
(black-box attack). Based on these items, we design three perturbation
strategies, namely insertion, modification, and removal, to generate
adversarial samples. The experiment results show that the adversarial samples
generated by our method can successfully fool both state-of-the-art
character-level and word-level DNN-based text classifiers. The adversarial
samples can be perturbed to any desirable classes without compromising their
utilities. At the same time, the introduced perturbation is difficult to be
perceived.
-
We present a new idea to design perfectly secure information exchange
protocol, based on so called Deep Randomness, which means randomness relying on
hidden probability distribution. Such idea drives us to introduce a new axiom
in probability theory, thanks to which we can design a protocol, beyond Shannon
limit, enabling two legitimate partners, sharing originally no common private
information, to exchange secret information with accuracy as close as desired
from perfection, and knowledge as close as desired from zero by any unlimitedly
powered opponent.
-
Penetration testing is a well-established practical concept for the
identification of potentially exploitable security weaknesses and an important
component of a security audit. Providing a holistic security assessment for
networks consisting of several hundreds hosts is hardly feasible though without
some sort of mechanization. Mitigation, prioritizing counter-measures subject
to a given budget, currently lacks a solid theoretical understanding and is
hence more art than science. In this work, we propose the first approach for
conducting comprehensive what-if analyses in order to reason about mitigation
in a conceptually well-founded manner. To evaluate and compare mitigation
strategies, we use simulated penetration testing, i.e., automated
attack-finding, based on a network model to which a subset of a given set of
mitigation actions, e.g., changes to the network topology, system updates,
configuration changes etc. is applied. Using Stackelberg planning, we determine
optimal combinations that minimize the maximal attacker success (similar to a
Stackelberg game), and thus provide a well-founded basis for a holistic
mitigation strategy. We show that these Stackelberg planning models can largely
be derived from network scan, public vulnerability databases and manual
inspection with various degrees of automation and detail, and we simulate
mitigation analysis on networks of different size and vulnerability.
-
A pay-TV consumer uses a decoder to access encrypted digital content. To this
end, the decoder contains a chip capable of decrypting the content if
provisioned with the appropriate content decryption keys. A key establishment
protocol is used to secure the delivery of the content decryption keys to the
chip. This paper presents a new protocol and shows how the protocol can be
applied in a pay-TV system. Compared to existing protocols, the presented
solution reduces the risk that decoders need to be replaced in order to correct
a security breach. The new protocol has recently been incorporated in an ETSI
standard.
-
Administrative Role Based Access Control (ARBAC) models specify how to manage
user-role assignments (URA), permission-role assignments (PRA), and role-role
assignments (RRA). Many approaches have been proposed in the literature for
URA, PRA, and RRA. In this paper, we propose a model for attribute-based
role-role assignment (ARRA), a novel way to unify prior RRA approaches. We
leverage the idea that attributes of various RBAC entities such as admin users
and regular roles can be used to administer RRA in a highly flexible manner. We
demonstrate that ARRA can express and unify prior RRA models.
-
Consensus is fundamental for distributed systems since it underpins key
functionalities of such systems ranging from distributed information fusion,
decision-making, to decentralized control. In order to reach an agreement,
existing consensus algorithms require each agent to exchange explicit state
information with its neighbors. This leads to the disclosure of private state
information, which is undesirable in cases where privacy is of concern. In this
paper, we propose a novel approach that enables secure and privacy-preserving
average consensus in a decentralized architecture in the absence of an
aggregator or third-party. By leveraging partial homomorphic cryptography to
embed secrecy in pairwise interaction dynamics, our approach can guarantee
consensus to the exact value in a deterministic manner without disclosing a
node's state to its neighbors. In addition to enabling resilience to passive
attackers aiming to steal state information, the approach also allows easy
incorporation of defending mechanisms against active attackers which try to
alter the content of exchanged messages. Furthermore, in contrast to existing
noise-injection based privacy-preserving mechanisms which have to reconfigure
the entire network when the topology or number of nodes varies, our approach is
applicable to dynamic environments with time-varying coupling topologies. This
secure and privacy-preservation approach is also applicable to weighted average
consensus as well as maximum/minimum consensus under a new update rule. The
approach is light-weight in computation and communication. Implementation
details and numerical examples are provided to demonstrate the capability of
our approach.
-
This paper defines The Dead Cryptographers Society Problem - DCS (where
several great cryptographers created many polynomial-time Deterministic Turing
Machines (DTMs) of a specific type, ran them on their proper descriptions
concatenated with some arbitrary strings, deleted them and left only the
results from those running, after they died: if those DTMs only permute and
sometimes invert the bits on input, is it possible to decide the language
formed by such resulting strings within polynomial time?), proves some facts
about its computational complexity, and discusses some possible uses on
Cryptography, such as into distance keys distribution, online reverse auction
and secure communication.





 Device-independent security is the gold standard for quantum cryptography: not only is security based entirely on the laws of quantum mechanics, but it holds irrespective of any a priori assumptions on the quantum devices used in a protocol, making it particularly applicable in a quantum-wary environment. While the existence of device-independent protocols for tasks such as randomness expansion and quantum key distribution has recently been established, the underlying proofs of security remain very challenging, yield rather poor key rates, and demand very high-quality quantum devices, thus making them all but impossible to implement in practice. We introduce a technique for the analysis of device-independent cryptographic protocols. We provide a flexible protocol and give a security proof that provides quantitative bounds that are asymptotically tight, even in the presence of general quantum adversaries. At a high level our approach amounts to establishing a reduction to the scenario in which the untrusted device operates in an identical and independent way in each round of the protocol. This is achieved by leveraging the sequential nature of the protocol, and makes use of a newly developed tool, the "entropy accumulation theorem" of Dupuis et al. As concrete applications we give simple and modular security proofs for device-independent quantum key distribution and randomness expansion protocols based on the CHSH inequality. For both tasks we establish essentially optimal asymptotic key rates and noise tolerance. In view of recent experimental progress, which has culminated in loophole-free Bell tests, it is likely that these protocols can be practically implemented in the near future.
Device-independent security is the gold standard for quantum cryptography: not only is security based entirely on the laws of quantum mechanics, but it holds irrespective of any a priori assumptions on the quantum devices used in a protocol, making it particularly applicable in a quantum-wary environment. While the existence of device-independent protocols for tasks such as randomness expansion and quantum key distribution has recently been established, the underlying proofs of security remain very challenging, yield rather poor key rates, and demand very high-quality quantum devices, thus making them all but impossible to implement in practice. We introduce a technique for the analysis of device-independent cryptographic protocols. We provide a flexible protocol and give a security proof that provides quantitative bounds that are asymptotically tight, even in the presence of general quantum adversaries. At a high level our approach amounts to establishing a reduction to the scenario in which the untrusted device operates in an identical and independent way in each round of the protocol. This is achieved by leveraging the sequential nature of the protocol, and makes use of a newly developed tool, the "entropy accumulation theorem" of Dupuis et al. As concrete applications we give simple and modular security proofs for device-independent quantum key distribution and randomness expansion protocols based on the CHSH inequality. For both tasks we establish essentially optimal asymptotic key rates and noise tolerance. In view of recent experimental progress, which has culminated in loophole-free Bell tests, it is likely that these protocols can be practically implemented in the near future.


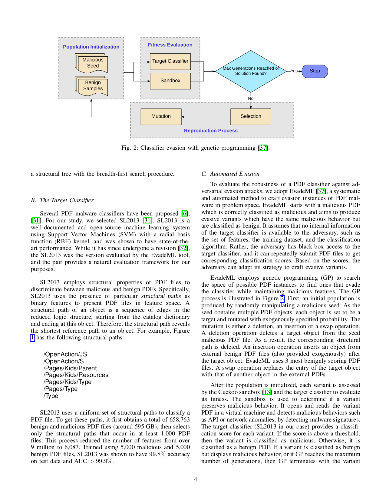

 Machine learning (ML) techniques are increasingly common in security applications, such as malware and intrusion detection. However, ML models are often susceptible to evasion attacks, in which an adversary makes changes to the input (such as malware) in order to avoid being detected. A conventional approach to evaluate ML robustness to such attacks, as well as to design robust ML, is by considering simplified feature-space models of attacks, where the attacker changes ML features directly to effect evasion, while minimizing or constraining the magnitude of this change. We investigate the effectiveness of this approach to designing robust ML in the face of attacks that can be realized in actual malware (realizable attacks). We demonstrate that in the context of structure-based PDF malware detection, such techniques appear to have limited effectiveness, but they are effective with content-based detectors. In either case, we show that augmenting the feature space models with conserved features (those that cannot be unilaterally modified without compromising malicious functionality) significantly improves performance. Finally, we show that feature space models enable generalized robustness when faced with a variety of realizable attacks, as compared to classifiers which are tuned to be robust to a specific realizable attack.
Machine learning (ML) techniques are increasingly common in security applications, such as malware and intrusion detection. However, ML models are often susceptible to evasion attacks, in which an adversary makes changes to the input (such as malware) in order to avoid being detected. A conventional approach to evaluate ML robustness to such attacks, as well as to design robust ML, is by considering simplified feature-space models of attacks, where the attacker changes ML features directly to effect evasion, while minimizing or constraining the magnitude of this change. We investigate the effectiveness of this approach to designing robust ML in the face of attacks that can be realized in actual malware (realizable attacks). We demonstrate that in the context of structure-based PDF malware detection, such techniques appear to have limited effectiveness, but they are effective with content-based detectors. In either case, we show that augmenting the feature space models with conserved features (those that cannot be unilaterally modified without compromising malicious functionality) significantly improves performance. Finally, we show that feature space models enable generalized robustness when faced with a variety of realizable attacks, as compared to classifiers which are tuned to be robust to a specific realizable attack.




 Deep learning-based techniques have achieved state-of-the-art performance on a wide variety of recognition and classification tasks. However, these networks are typically computationally expensive to train, requiring weeks of computation on many GPUs; as a result, many users outsource the training procedure to the cloud or rely on pre-trained models that are then fine-tuned for a specific task. In this paper we show that outsourced training introduces new security risks: an adversary can create a maliciously trained network (a backdoored neural network, or a \emph{BadNet}) that has state-of-the-art performance on the user's training and validation samples, but behaves badly on specific attacker-chosen inputs. We first explore the properties of BadNets in a toy example, by creating a backdoored handwritten digit classifier. Next, we demonstrate backdoors in a more realistic scenario by creating a U.S. street sign classifier that identifies stop signs as speed limits when a special sticker is added to the stop sign; we then show in addition that the backdoor in our US street sign detector can persist even if the network is later retrained for another task and cause a drop in accuracy of {25}\% on average when the backdoor trigger is present. These results demonstrate that backdoors in neural networks are both powerful and---because the behavior of neural networks is difficult to explicate---stealthy. This work provides motivation for further research into techniques for verifying and inspecting neural networks, just as we have developed tools for verifying and debugging software.
Deep learning-based techniques have achieved state-of-the-art performance on a wide variety of recognition and classification tasks. However, these networks are typically computationally expensive to train, requiring weeks of computation on many GPUs; as a result, many users outsource the training procedure to the cloud or rely on pre-trained models that are then fine-tuned for a specific task. In this paper we show that outsourced training introduces new security risks: an adversary can create a maliciously trained network (a backdoored neural network, or a \emph{BadNet}) that has state-of-the-art performance on the user's training and validation samples, but behaves badly on specific attacker-chosen inputs. We first explore the properties of BadNets in a toy example, by creating a backdoored handwritten digit classifier. Next, we demonstrate backdoors in a more realistic scenario by creating a U.S. street sign classifier that identifies stop signs as speed limits when a special sticker is added to the stop sign; we then show in addition that the backdoor in our US street sign detector can persist even if the network is later retrained for another task and cause a drop in accuracy of {25}\% on average when the backdoor trigger is present. These results demonstrate that backdoors in neural networks are both powerful and---because the behavior of neural networks is difficult to explicate---stealthy. This work provides motivation for further research into techniques for verifying and inspecting neural networks, just as we have developed tools for verifying and debugging software.




 Modern authentication systems store hashed values of passwords of users using cryptographic hash functions. Therefore, to crack a password an attacker needs to guess a hash function input that is mapped to the hashed value, as opposed to the password itself. We call a hash function that maps the same number of inputs to each bin, as \textbf{unbiased}. However, cryptographic hash functions in use have not been proven to be unbiased (i.e., they may have an unequal number of inputs mapped to different bins). A cryptographic hash function has the property that it is computationally difficult to find an input mapped to a bin. In this work we introduce a structured notion of biased hash functions for which we analyze the average guesswork under certain types of brute force attacks. This work shows that the level of security depends on the set of hashed values of valid users as well as the statistical profile of a hash function, resulting from bias. We examine the average guesswork conditioned on the set of hashed values, and model the statistical profile through the empirical distribution of the number of inputs that are mapped to a bin. In particular, we focus on a class of statistical profiles (capturing the bias) , which we call type-class statistical profiles, that has an empirical distribution related to the probability of the type classes defined in the method of types. For such profiles, we show that the average guesswork is related to basic measures in information theory such as entropy and divergence. We use this to show that the effect of bias on the conditional average guesswork is limited compared to other system parameters such as the number of valid users who store their hashed passwords in the system.
Modern authentication systems store hashed values of passwords of users using cryptographic hash functions. Therefore, to crack a password an attacker needs to guess a hash function input that is mapped to the hashed value, as opposed to the password itself. We call a hash function that maps the same number of inputs to each bin, as \textbf{unbiased}. However, cryptographic hash functions in use have not been proven to be unbiased (i.e., they may have an unequal number of inputs mapped to different bins). A cryptographic hash function has the property that it is computationally difficult to find an input mapped to a bin. In this work we introduce a structured notion of biased hash functions for which we analyze the average guesswork under certain types of brute force attacks. This work shows that the level of security depends on the set of hashed values of valid users as well as the statistical profile of a hash function, resulting from bias. We examine the average guesswork conditioned on the set of hashed values, and model the statistical profile through the empirical distribution of the number of inputs that are mapped to a bin. In particular, we focus on a class of statistical profiles (capturing the bias) , which we call type-class statistical profiles, that has an empirical distribution related to the probability of the type classes defined in the method of types. For such profiles, we show that the average guesswork is related to basic measures in information theory such as entropy and divergence. We use this to show that the effect of bias on the conditional average guesswork is limited compared to other system parameters such as the number of valid users who store their hashed passwords in the system.




 In this paper we characterize the set of polynomials $f\in\mathbb F_q[X]$ satisfying the following property: there exists a positive integer $d$ such that for any positive integer $\ell$ less or equal than the degree of $f$, there exists $t_0$ in $\mathbb F_{q^d}$ such that the polynomial $f-t_0$ has an irreducible factor of degree $\ell$ over $\mathbb F_{q^d}[X]$. This result is then used to progress in the last step which is needed to remove the heuristic from one of the quasi-polynomial time algorithms for discrete logarithm problems (DLP) in small characteristic. Our characterization allows a construction of polynomials satisfying the wanted property. The method is general and can be used to tackle similar problems which involve factorization patterns of polynomials over finite fields.
In this paper we characterize the set of polynomials $f\in\mathbb F_q[X]$ satisfying the following property: there exists a positive integer $d$ such that for any positive integer $\ell$ less or equal than the degree of $f$, there exists $t_0$ in $\mathbb F_{q^d}$ such that the polynomial $f-t_0$ has an irreducible factor of degree $\ell$ over $\mathbb F_{q^d}[X]$. This result is then used to progress in the last step which is needed to remove the heuristic from one of the quasi-polynomial time algorithms for discrete logarithm problems (DLP) in small characteristic. Our characterization allows a construction of polynomials satisfying the wanted property. The method is general and can be used to tackle similar problems which involve factorization patterns of polynomials over finite fields.




 Data sharing among partners---users, organizations, companies---is crucial for the advancement of data analytics in many domains. Sharing through secure computation and differential privacy allows these partners to perform private computations on their sensitive data in controlled ways. However, in reality, there exist complex relationships among members. Politics, regulations, interest, trust, data demands and needs are one of the many reasons. Thus, there is a need for a mechanism to meet these conflicting relationships on data sharing. This paper presents Curie, an approach to exchange data among members whose membership has complex relationships. The CPL policy language that allows members to define the specifications of data exchange requirements is introduced. Members (partners) assert who and what to exchange through their local policies and negotiate a global sharing agreement. The agreement is implemented in a multi-party computation that guarantees sharing among members will comply with the policy as negotiated. The use of Curie is validated through an example of a health care application built on recently introduced secure multi-party computation and differential privacy frameworks, and policy and performance trade-offs are explored.
Data sharing among partners---users, organizations, companies---is crucial for the advancement of data analytics in many domains. Sharing through secure computation and differential privacy allows these partners to perform private computations on their sensitive data in controlled ways. However, in reality, there exist complex relationships among members. Politics, regulations, interest, trust, data demands and needs are one of the many reasons. Thus, there is a need for a mechanism to meet these conflicting relationships on data sharing. This paper presents Curie, an approach to exchange data among members whose membership has complex relationships. The CPL policy language that allows members to define the specifications of data exchange requirements is introduced. Members (partners) assert who and what to exchange through their local policies and negotiate a global sharing agreement. The agreement is implemented in a multi-party computation that guarantees sharing among members will comply with the policy as negotiated. The use of Curie is validated through an example of a health care application built on recently introduced secure multi-party computation and differential privacy frameworks, and policy and performance trade-offs are explored.

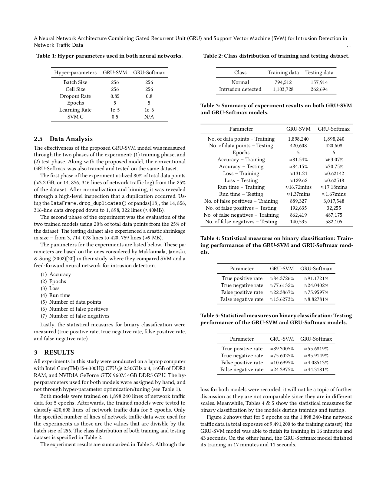
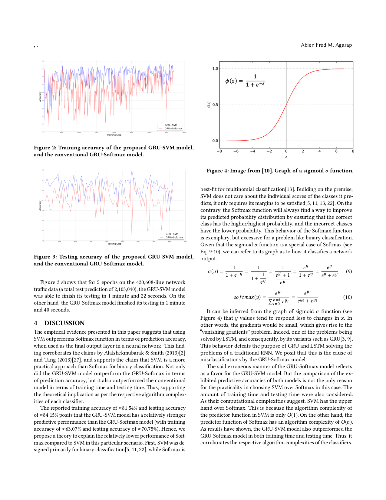

 Gated Recurrent Unit (GRU) is a recently-developed variation of the long short-term memory (LSTM) unit, both of which are types of recurrent neural network (RNN). Through empirical evidence, both models have been proven to be effective in a wide variety of machine learning tasks such as natural language processing (Wen et al., 2015), speech recognition (Chorowski et al., 2015), and text classification (Yang et al., 2016). Conventionally, like most neural networks, both of the aforementioned RNN variants employ the Softmax function as its final output layer for its prediction, and the cross-entropy function for computing its loss. In this paper, we present an amendment to this norm by introducing linear support vector machine (SVM) as the replacement for Softmax in the final output layer of a GRU model. Furthermore, the cross-entropy function shall be replaced with a margin-based function. While there have been similar studies (Alalshekmubarak & Smith, 2013; Tang, 2013), this proposal is primarily intended for binary classification on intrusion detection using the 2013 network traffic data from the honeypot systems of Kyoto University. Results show that the GRU-SVM model performs relatively higher than the conventional GRU-Softmax model. The proposed model reached a training accuracy of ~81.54% and a testing accuracy of ~84.15%, while the latter was able to reach a training accuracy of ~63.07% and a testing accuracy of ~70.75%. In addition, the juxtaposition of these two final output layers indicate that the SVM would outperform Softmax in prediction time - a theoretical implication which was supported by the actual training and testing time in the study.
Gated Recurrent Unit (GRU) is a recently-developed variation of the long short-term memory (LSTM) unit, both of which are types of recurrent neural network (RNN). Through empirical evidence, both models have been proven to be effective in a wide variety of machine learning tasks such as natural language processing (Wen et al., 2015), speech recognition (Chorowski et al., 2015), and text classification (Yang et al., 2016). Conventionally, like most neural networks, both of the aforementioned RNN variants employ the Softmax function as its final output layer for its prediction, and the cross-entropy function for computing its loss. In this paper, we present an amendment to this norm by introducing linear support vector machine (SVM) as the replacement for Softmax in the final output layer of a GRU model. Furthermore, the cross-entropy function shall be replaced with a margin-based function. While there have been similar studies (Alalshekmubarak & Smith, 2013; Tang, 2013), this proposal is primarily intended for binary classification on intrusion detection using the 2013 network traffic data from the honeypot systems of Kyoto University. Results show that the GRU-SVM model performs relatively higher than the conventional GRU-Softmax model. The proposed model reached a training accuracy of ~81.54% and a testing accuracy of ~84.15%, while the latter was able to reach a training accuracy of ~63.07% and a testing accuracy of ~70.75%. In addition, the juxtaposition of these two final output layers indicate that the SVM would outperform Softmax in prediction time - a theoretical implication which was supported by the actual training and testing time in the study.

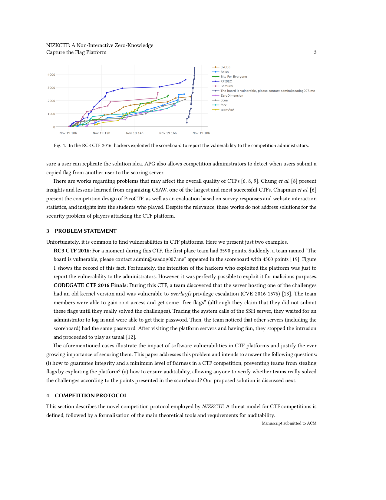


 Capture the Flag (CTF) competitions are increasingly important for the Brazilian cybersecurity community as education and professional tools. Unfortunately, CTF platforms may suffer from security issues, giving an unfair advantage to competitors. To mitigate this, we propose NIZKCTF, the first open-audit CTF platform based on non-interactive zero-knowledge proofs.
Capture the Flag (CTF) competitions are increasingly important for the Brazilian cybersecurity community as education and professional tools. Unfortunately, CTF platforms may suffer from security issues, giving an unfair advantage to competitors. To mitigate this, we propose NIZKCTF, the first open-audit CTF platform based on non-interactive zero-knowledge proofs.




 We consider two basic algorithmic problems concerning tuples of (skew-)symmetric matrices. The first problem asks to decide, given two tuples of (skew-)symmetric matrices $(B_1, \dots, B_m)$ and $(C_1, \dots, C_m)$, whether there exists an invertible matrix $A$ such that for every $i\in\{1, \dots, m\}$, $A^tB_iA=C_i$. We show that this problem can be solved in randomized polynomial time over finite fields of odd size, the real field, and the complex field. The second problem asks to decide, given a tuple of square matrices $(B_1, \dots, B_m)$, whether there exist invertible matrices $A$ and $D$, such that for every $i\in\{1, \dots, m\}$, $AB_iD$ is (skew-)symmetric. We show that this problem can be solved in deterministic polynomial time over fields of characteristic not $2$. For both problems we exploit the structure of the underlying $*$-algebras, and utilize results and methods from the module isomorphism problem. Applications of our results range from multivariate cryptography, group isomorphism, to polynomial identity testing. Specifically, these results imply efficient algorithms for the following problems. (1) Test isomorphism of quadratic forms with one secret over a finite field of odd size. This problem belongs to a family of problems that serves as the security basis of certain authentication schemes proposed by Patarin (Eurocrypto 1996). (2) Test isomorphism of $p$-groups of class 2 and exponent $p$ ($p$ odd) with order $p^k$ in time polynomial in the group order, when the commutator subgroup is of order $p^{O(\sqrt{k})}$. (3) Deterministically reveal two families of singularity witnesses caused by the skew-symmetric structure, which represents a natural next step for the polynomial identity testing problem following the direction set up by the recent resolution of the non-commutative rank problem (Garg et al., FOCS 2016; Ivanyos et al., ITCS 2017).
We consider two basic algorithmic problems concerning tuples of (skew-)symmetric matrices. The first problem asks to decide, given two tuples of (skew-)symmetric matrices $(B_1, \dots, B_m)$ and $(C_1, \dots, C_m)$, whether there exists an invertible matrix $A$ such that for every $i\in\{1, \dots, m\}$, $A^tB_iA=C_i$. We show that this problem can be solved in randomized polynomial time over finite fields of odd size, the real field, and the complex field. The second problem asks to decide, given a tuple of square matrices $(B_1, \dots, B_m)$, whether there exist invertible matrices $A$ and $D$, such that for every $i\in\{1, \dots, m\}$, $AB_iD$ is (skew-)symmetric. We show that this problem can be solved in deterministic polynomial time over fields of characteristic not $2$. For both problems we exploit the structure of the underlying $*$-algebras, and utilize results and methods from the module isomorphism problem. Applications of our results range from multivariate cryptography, group isomorphism, to polynomial identity testing. Specifically, these results imply efficient algorithms for the following problems. (1) Test isomorphism of quadratic forms with one secret over a finite field of odd size. This problem belongs to a family of problems that serves as the security basis of certain authentication schemes proposed by Patarin (Eurocrypto 1996). (2) Test isomorphism of $p$-groups of class 2 and exponent $p$ ($p$ odd) with order $p^k$ in time polynomial in the group order, when the commutator subgroup is of order $p^{O(\sqrt{k})}$. (3) Deterministically reveal two families of singularity witnesses caused by the skew-symmetric structure, which represents a natural next step for the polynomial identity testing problem following the direction set up by the recent resolution of the non-commutative rank problem (Garg et al., FOCS 2016; Ivanyos et al., ITCS 2017).




 Constructing a Pseudo Random Function (PRF) is a fundamental problem in cryptology. Such a construction, implemented by truncating the last $m$ bits of permutations of $\{0, 1\}^{n}$ was suggested by Hall et al. (1998). They conjectured that the distinguishing advantage of an adversary with $q$ queries, ${\bf Adv}_{n, m} (q)$, is small if $q = o (2^{(n+m)/2})$, established an upper bound on ${\bf Adv}_{n, m} (q)$ that confirms the conjecture for $m < n/7$, and also declared a general lower bound ${\bf Adv}_{n,m}(q)=\Omega(q^2/2^{n+m})$. The conjecture was essentially confirmed by Bellare and Impagliazzo (1999). Nevertheless, the problem of {\em estimating} ${\bf Adv}_{n, m} (q)$ remained open. Combining the trivial bound $1$, the birthday bound, and a result of Stam (1978) leads to the upper bound \begin{equation*} {\bf Adv}_{n,m}(q) = O\left(\min\left\{\frac{q(q-1)}{2^n},\,\frac{q}{2^{\frac{n+m}{2}}},\,1\right\}\right). \end{equation*} In this paper we show that this upper bound is tight for every $0\leq m<n$ and any $q$. This, in turn, verifies that the converse to the conjecture of Hall et al. is also correct, i.e., that ${\bf Adv}_{n, m} (q)$ is negligible only for $q = o (2^{(n+m)/2})$.
Constructing a Pseudo Random Function (PRF) is a fundamental problem in cryptology. Such a construction, implemented by truncating the last $m$ bits of permutations of $\{0, 1\}^{n}$ was suggested by Hall et al. (1998). They conjectured that the distinguishing advantage of an adversary with $q$ queries, ${\bf Adv}_{n, m} (q)$, is small if $q = o (2^{(n+m)/2})$, established an upper bound on ${\bf Adv}_{n, m} (q)$ that confirms the conjecture for $m < n/7$, and also declared a general lower bound ${\bf Adv}_{n,m}(q)=\Omega(q^2/2^{n+m})$. The conjecture was essentially confirmed by Bellare and Impagliazzo (1999). Nevertheless, the problem of {\em estimating} ${\bf Adv}_{n, m} (q)$ remained open. Combining the trivial bound $1$, the birthday bound, and a result of Stam (1978) leads to the upper bound \begin{equation*} {\bf Adv}_{n,m}(q) = O\left(\min\left\{\frac{q(q-1)}{2^n},\,\frac{q}{2^{\frac{n+m}{2}}},\,1\right\}\right). \end{equation*} In this paper we show that this upper bound is tight for every $0\leq m<n$ and any $q$. This, in turn, verifies that the converse to the conjecture of Hall et al. is also correct, i.e., that ${\bf Adv}_{n, m} (q)$ is negligible only for $q = o (2^{(n+m)/2})$.




 Many efficient data structures use randomness, allowing them to improve upon deterministic ones. Usually, their efficiency and correctness are analyzed using probabilistic tools under the assumption that the inputs and queries are independent of the internal randomness of the data structure. In this work, we consider data structures in a more robust model, which we call the adversarial model. Roughly speaking, this model allows an adversary to choose inputs and queries adaptively according to previous responses. Specifically, we consider a data structure known as "Bloom filter" and prove a tight connection between Bloom filters in this model and cryptography. A Bloom filter represents a set $S$ of elements approximately, by using fewer bits than a precise representation. The price for succinctness is allowing some errors: for any $x \in S$ it should always answer `Yes', and for any $x \notin S$ it should answer `Yes' only with small probability. In the adversarial model, we consider both efficient adversaries (that run in polynomial time) and computationally unbounded adversaries that are only bounded in the number of queries they can make. For computationally bounded adversaries, we show that non-trivial (memory-wise) Bloom filters exist if and only if one-way functions exist. For unbounded adversaries we show that there exists a Bloom filter for sets of size $n$ and error $\varepsilon$, that is secure against $t$ queries and uses only $O(n \log{\frac{1}{\varepsilon}}+t)$ bits of memory. In comparison, $n\log{\frac{1}{\varepsilon}}$ is the best possible under a non-adaptive adversary.
Many efficient data structures use randomness, allowing them to improve upon deterministic ones. Usually, their efficiency and correctness are analyzed using probabilistic tools under the assumption that the inputs and queries are independent of the internal randomness of the data structure. In this work, we consider data structures in a more robust model, which we call the adversarial model. Roughly speaking, this model allows an adversary to choose inputs and queries adaptively according to previous responses. Specifically, we consider a data structure known as "Bloom filter" and prove a tight connection between Bloom filters in this model and cryptography. A Bloom filter represents a set $S$ of elements approximately, by using fewer bits than a precise representation. The price for succinctness is allowing some errors: for any $x \in S$ it should always answer `Yes', and for any $x \notin S$ it should answer `Yes' only with small probability. In the adversarial model, we consider both efficient adversaries (that run in polynomial time) and computationally unbounded adversaries that are only bounded in the number of queries they can make. For computationally bounded adversaries, we show that non-trivial (memory-wise) Bloom filters exist if and only if one-way functions exist. For unbounded adversaries we show that there exists a Bloom filter for sets of size $n$ and error $\varepsilon$, that is secure against $t$ queries and uses only $O(n \log{\frac{1}{\varepsilon}}+t)$ bits of memory. In comparison, $n\log{\frac{1}{\varepsilon}}$ is the best possible under a non-adaptive adversary.



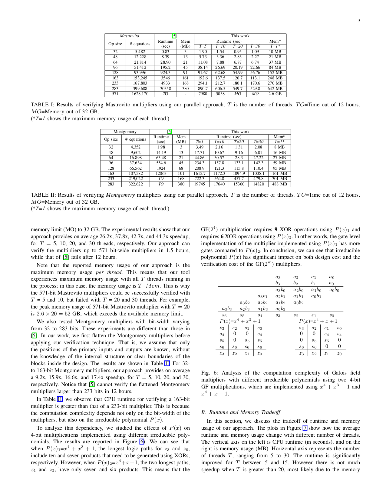
 Galois field (GF) arithmetic is used to implement critical arithmetic components in communication and security-related hardware, and verification of such components is of prime importance. Current techniques for formally verifying such components are based on computer algebra methods that proved successful in verification of integer arithmetic circuits. However, these methods are sequential in nature and do not offer any parallelism. This paper presents an algebraic functional verification technique of gate-level GF (2m ) multipliers, in which verification is performed in bit-parallel fashion. The method is based on extracting a unique polynomial in Galois field of each output bit independently. We demonstrate that this method is able to verify an n-bit GF multiplier in n threads. Experiments performed on pre- and post-synthesized Mastrovito and Montgomery multipliers show high efficiency up to 571 bits.
Galois field (GF) arithmetic is used to implement critical arithmetic components in communication and security-related hardware, and verification of such components is of prime importance. Current techniques for formally verifying such components are based on computer algebra methods that proved successful in verification of integer arithmetic circuits. However, these methods are sequential in nature and do not offer any parallelism. This paper presents an algebraic functional verification technique of gate-level GF (2m ) multipliers, in which verification is performed in bit-parallel fashion. The method is based on extracting a unique polynomial in Galois field of each output bit independently. We demonstrate that this method is able to verify an n-bit GF multiplier in n threads. Experiments performed on pre- and post-synthesized Mastrovito and Montgomery multipliers show high efficiency up to 571 bits.




 Advanced persistent threats (APTs) are stealthy attacks which make use of social engineering and deception to give adversaries insider access to networked systems. Against APTs, active defense technologies aim to create and exploit information asymmetry for defenders. In this paper, we study a scenario in which a powerful defender uses honeynets for active defense in order to observe an attacker who has penetrated the network. Rather than immediately eject the attacker, the defender may elect to gather information. We introduce an undiscounted, infinite-horizon Markov decision process on a continuous state space in order to model the defender's problem. We find a threshold of information that the defender should gather about the attacker before ejecting him. Then we study the robustness of this policy using a Stackelberg game. Finally, we simulate the policy for a conceptual network. Our results provide a quantitative foundation for studying optimal timing for attacker engagement in network defense.
Advanced persistent threats (APTs) are stealthy attacks which make use of social engineering and deception to give adversaries insider access to networked systems. Against APTs, active defense technologies aim to create and exploit information asymmetry for defenders. In this paper, we study a scenario in which a powerful defender uses honeynets for active defense in order to observe an attacker who has penetrated the network. Rather than immediately eject the attacker, the defender may elect to gather information. We introduce an undiscounted, infinite-horizon Markov decision process on a continuous state space in order to model the defender's problem. We find a threshold of information that the defender should gather about the attacker before ejecting him. Then we study the robustness of this policy using a Stackelberg game. Finally, we simulate the policy for a conceptual network. Our results provide a quantitative foundation for studying optimal timing for attacker engagement in network defense.




 In this article, we propose a new implementation of John von Neumann's middle square random number generator (RNG). A Weyl sequence keeps the generator running through a long period.
In this article, we propose a new implementation of John von Neumann's middle square random number generator (RNG). A Weyl sequence keeps the generator running through a long period.



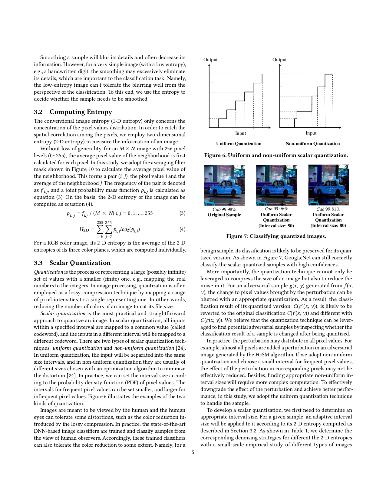
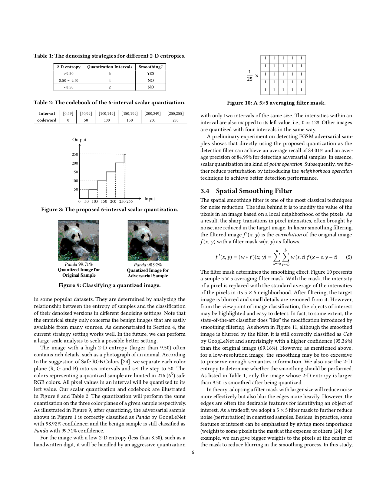 Recently, many studies have demonstrated deep neural network (DNN) classifiers can be fooled by the adversarial example, which is crafted via introducing some perturbations into an original sample. Accordingly, some powerful defense techniques were proposed. However, existing defense techniques often require modifying the target model or depend on the prior knowledge of attacks. In this paper, we propose a straightforward method for detecting adversarial image examples, which can be directly deployed into unmodified off-the-shelf DNN models. We consider the perturbation to images as a kind of noise and introduce two classic image processing techniques, scalar quantization and smoothing spatial filter, to reduce its effect. The image entropy is employed as a metric to implement an adaptive noise reduction for different kinds of images. Consequently, the adversarial example can be effectively detected by comparing the classification results of a given sample and its denoised version, without referring to any prior knowledge of attacks. More than 20,000 adversarial examples against some state-of-the-art DNN models are used to evaluate the proposed method, which are crafted with different attack techniques. The experiments show that our detection method can achieve a high overall F1 score of 96.39% and certainly raises the bar for defense-aware attacks.
Recently, many studies have demonstrated deep neural network (DNN) classifiers can be fooled by the adversarial example, which is crafted via introducing some perturbations into an original sample. Accordingly, some powerful defense techniques were proposed. However, existing defense techniques often require modifying the target model or depend on the prior knowledge of attacks. In this paper, we propose a straightforward method for detecting adversarial image examples, which can be directly deployed into unmodified off-the-shelf DNN models. We consider the perturbation to images as a kind of noise and introduce two classic image processing techniques, scalar quantization and smoothing spatial filter, to reduce its effect. The image entropy is employed as a metric to implement an adaptive noise reduction for different kinds of images. Consequently, the adversarial example can be effectively detected by comparing the classification results of a given sample and its denoised version, without referring to any prior knowledge of attacks. More than 20,000 adversarial examples against some state-of-the-art DNN models are used to evaluate the proposed method, which are crafted with different attack techniques. The experiments show that our detection method can achieve a high overall F1 score of 96.39% and certainly raises the bar for defense-aware attacks.




 Penetration testing is a well-established practical concept for the identification of potentially exploitable security weaknesses and an important component of a security audit. Providing a holistic security assessment for networks consisting of several hundreds hosts is hardly feasible though without some sort of mechanization. Mitigation, prioritizing counter-measures subject to a given budget, currently lacks a solid theoretical understanding and is hence more art than science. In this work, we propose the first approach for conducting comprehensive what-if analyses in order to reason about mitigation in a conceptually well-founded manner. To evaluate and compare mitigation strategies, we use simulated penetration testing, i.e., automated attack-finding, based on a network model to which a subset of a given set of mitigation actions, e.g., changes to the network topology, system updates, configuration changes etc. is applied. Using Stackelberg planning, we determine optimal combinations that minimize the maximal attacker success (similar to a Stackelberg game), and thus provide a well-founded basis for a holistic mitigation strategy. We show that these Stackelberg planning models can largely be derived from network scan, public vulnerability databases and manual inspection with various degrees of automation and detail, and we simulate mitigation analysis on networks of different size and vulnerability.
Penetration testing is a well-established practical concept for the identification of potentially exploitable security weaknesses and an important component of a security audit. Providing a holistic security assessment for networks consisting of several hundreds hosts is hardly feasible though without some sort of mechanization. Mitigation, prioritizing counter-measures subject to a given budget, currently lacks a solid theoretical understanding and is hence more art than science. In this work, we propose the first approach for conducting comprehensive what-if analyses in order to reason about mitigation in a conceptually well-founded manner. To evaluate and compare mitigation strategies, we use simulated penetration testing, i.e., automated attack-finding, based on a network model to which a subset of a given set of mitigation actions, e.g., changes to the network topology, system updates, configuration changes etc. is applied. Using Stackelberg planning, we determine optimal combinations that minimize the maximal attacker success (similar to a Stackelberg game), and thus provide a well-founded basis for a holistic mitigation strategy. We show that these Stackelberg planning models can largely be derived from network scan, public vulnerability databases and manual inspection with various degrees of automation and detail, and we simulate mitigation analysis on networks of different size and vulnerability.




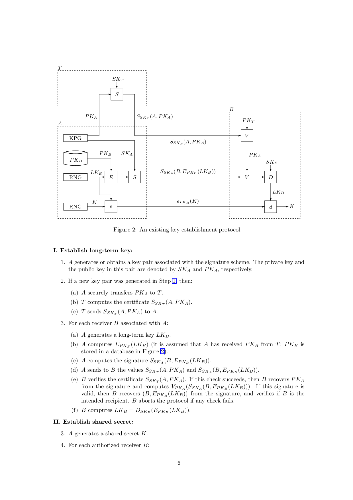 A pay-TV consumer uses a decoder to access encrypted digital content. To this end, the decoder contains a chip capable of decrypting the content if provisioned with the appropriate content decryption keys. A key establishment protocol is used to secure the delivery of the content decryption keys to the chip. This paper presents a new protocol and shows how the protocol can be applied in a pay-TV system. Compared to existing protocols, the presented solution reduces the risk that decoders need to be replaced in order to correct a security breach. The new protocol has recently been incorporated in an ETSI standard.
A pay-TV consumer uses a decoder to access encrypted digital content. To this end, the decoder contains a chip capable of decrypting the content if provisioned with the appropriate content decryption keys. A key establishment protocol is used to secure the delivery of the content decryption keys to the chip. This paper presents a new protocol and shows how the protocol can be applied in a pay-TV system. Compared to existing protocols, the presented solution reduces the risk that decoders need to be replaced in order to correct a security breach. The new protocol has recently been incorporated in an ETSI standard.




 Administrative Role Based Access Control (ARBAC) models specify how to manage user-role assignments (URA), permission-role assignments (PRA), and role-role assignments (RRA). Many approaches have been proposed in the literature for URA, PRA, and RRA. In this paper, we propose a model for attribute-based role-role assignment (ARRA), a novel way to unify prior RRA approaches. We leverage the idea that attributes of various RBAC entities such as admin users and regular roles can be used to administer RRA in a highly flexible manner. We demonstrate that ARRA can express and unify prior RRA models.
Administrative Role Based Access Control (ARBAC) models specify how to manage user-role assignments (URA), permission-role assignments (PRA), and role-role assignments (RRA). Many approaches have been proposed in the literature for URA, PRA, and RRA. In this paper, we propose a model for attribute-based role-role assignment (ARRA), a novel way to unify prior RRA approaches. We leverage the idea that attributes of various RBAC entities such as admin users and regular roles can be used to administer RRA in a highly flexible manner. We demonstrate that ARRA can express and unify prior RRA models.




 Consensus is fundamental for distributed systems since it underpins key functionalities of such systems ranging from distributed information fusion, decision-making, to decentralized control. In order to reach an agreement, existing consensus algorithms require each agent to exchange explicit state information with its neighbors. This leads to the disclosure of private state information, which is undesirable in cases where privacy is of concern. In this paper, we propose a novel approach that enables secure and privacy-preserving average consensus in a decentralized architecture in the absence of an aggregator or third-party. By leveraging partial homomorphic cryptography to embed secrecy in pairwise interaction dynamics, our approach can guarantee consensus to the exact value in a deterministic manner without disclosing a node's state to its neighbors. In addition to enabling resilience to passive attackers aiming to steal state information, the approach also allows easy incorporation of defending mechanisms against active attackers which try to alter the content of exchanged messages. Furthermore, in contrast to existing noise-injection based privacy-preserving mechanisms which have to reconfigure the entire network when the topology or number of nodes varies, our approach is applicable to dynamic environments with time-varying coupling topologies. This secure and privacy-preservation approach is also applicable to weighted average consensus as well as maximum/minimum consensus under a new update rule. The approach is light-weight in computation and communication. Implementation details and numerical examples are provided to demonstrate the capability of our approach.
Consensus is fundamental for distributed systems since it underpins key functionalities of such systems ranging from distributed information fusion, decision-making, to decentralized control. In order to reach an agreement, existing consensus algorithms require each agent to exchange explicit state information with its neighbors. This leads to the disclosure of private state information, which is undesirable in cases where privacy is of concern. In this paper, we propose a novel approach that enables secure and privacy-preserving average consensus in a decentralized architecture in the absence of an aggregator or third-party. By leveraging partial homomorphic cryptography to embed secrecy in pairwise interaction dynamics, our approach can guarantee consensus to the exact value in a deterministic manner without disclosing a node's state to its neighbors. In addition to enabling resilience to passive attackers aiming to steal state information, the approach also allows easy incorporation of defending mechanisms against active attackers which try to alter the content of exchanged messages. Furthermore, in contrast to existing noise-injection based privacy-preserving mechanisms which have to reconfigure the entire network when the topology or number of nodes varies, our approach is applicable to dynamic environments with time-varying coupling topologies. This secure and privacy-preservation approach is also applicable to weighted average consensus as well as maximum/minimum consensus under a new update rule. The approach is light-weight in computation and communication. Implementation details and numerical examples are provided to demonstrate the capability of our approach.