-
We propose a general framework for nonasymptotic covariance matrix estimation
making use of concentration inequality-based confidence sets. We specify this
framework for the estimation of large sparse covariance matrices through
incorporation of past thresholding estimators with key emphasis on support
recovery. This technique goes beyond past results for thresholding estimators
by allowing for a wide range of distributional assumptions beyond merely
sub-Gaussian tails. This methodology can furthermore be adapted to a wide range
of other estimators and settings. The usage of nonasymptotic dimension-free
confidence sets yields good theoretical performance. Through extensive
simulations, it is demonstrated to have superior performance when compared with
other such methods. In the context of support recovery, we are able to specify
a false positive rate and optimize to maximize the true recoveries.
-
We show that several machine learning estimators, including square-root LASSO
(Least Absolute Shrinkage and Selection) and regularized logistic regression
can be represented as solutions to distributionally robust optimization (DRO)
problems. The associated uncertainty regions are based on suitably defined
Wasserstein distances. Hence, our representations allow us to view
regularization as a result of introducing an artificial adversary that perturbs
the empirical distribution to account for out-of-sample effects in loss
estimation. In addition, we introduce RWPI (Robust Wasserstein Profile
Inference), a novel inference methodology which extends the use of methods
inspired by Empirical Likelihood to the setting of optimal transport costs (of
which Wasserstein distances are a particular case). We use RWPI to show how to
optimally select the size of uncertainty regions, and as a consequence, we are
able to choose regularization parameters for these machine learning estimators
without the use of cross validation. Numerical experiments are also given to
validate our theoretical findings.
-
The global sensitivity analysis of a numerical model aims to quantify, by
means of sensitivity indices estimate, the contributions of each uncertain
input variable to the model output uncertainty. The so-called Sobol' indices,
which are based on the functional variance analysis, present a difficult
interpretation in the presence of statistical dependence between inputs. The
Shapley effect was recently introduced to overcome this problem as they
allocate the mutual contribution (due to correlation and interaction) of a
group of inputs to each individual input within the group.In this paper, using
several new analytical results, we study the effects of linear correlation
between some Gaussian input variables on Shapley effects, and compare these
effects to classical first-order and total Sobol' indices.This illustrates the
interest, in terms of sensitivity analysis setting and interpretation, of the
Shapley effects in the case of dependent inputs. For the practical issue of
computationally demanding computer models, we show that the substitution of the
original model by a metamodel (here, kriging) makes it possible to estimate
these indices with precision at a reasonable computational cost.
-
The inductive size bias coupling technique and Stein's method yield a
Berry-Esseen theorem for the number of urns having occupancy $d \ge 2$ when $n$
balls are uniformly distributed over $m$ urns. In particular, there exists a
constant $C$ depending only on $d$ such that $$ \sup_{z \in
\mathbb{R}}|P(W_{n,m} \le z) -P(Z \le z)| \le C \left(
\frac{1+(\frac{n}{m})^3}{\sigma_{n,m}} \right) \quad \mbox{for all $n \ge d$
and $m \ge 2$,} $$ where $W_{n,m}$ and $\sigma_{n,m}^2$ are the standardized
count and variance, respectively, of the number of urns with $d$ balls, and $Z$
is a standard normal random variable. Asymptotically, the bound is optimal up
to constants if $n$ and $m$ tend to infinity together in a way such that $n/m$
stays bounded.
-
Information theory is a mathematical theory of learning with deep connections
with topics as diverse as artificial intelligence, statistical physics, and
biological evolution. Many primers on information theory paint a broad picture
with relatively little mathematical sophistication, while many others develop
specific application areas in detail. In contrast, these informal notes aim to
outline some elements of the information-theoretic "way of thinking," by
cutting a rapid and interesting path through some of the theory's foundational
concepts and results. They are aimed at practicing systems scientists who are
interested in exploring potential connections between information theory and
their own fields. The main mathematical prerequisite for the notes is comfort
with elementary probability, including sample spaces, conditioning, and
expectations. We take the Kullback-Leibler divergence as our most basic
concept, and then proceed to develop the entropy and mutual information. We
discuss some of the main results, including the Chernoff bounds as a
characterization of the divergence; Gibbs' Theorem; and the Data Processing
Inequality. A recurring theme is that the definitions of information theory
support natural theorems that sound ``obvious'' when translated into English.
More pithily, ``information theory makes common sense precise.'' Since the
focus of the notes is not primarily on technical details, proofs are provided
only where the relevant techniques are illustrative of broader themes.
Otherwise, proofs and intriguing tangents are referenced in liberally-sprinkled
footnotes. The notes close with a highly nonexhaustive list of references to
resources and other perspectives on the field.
-
Latent Dirichlet allocation (LDA) is useful in document analysis, image
processing, and many information systems; however, its generalization
performance has been left unknown because it is a singular learning machine to
which regular statistical theory can not be applied.
Stochastic matrix factorization (SMF) is a restricted matrix factorization in
which matrix factors are stochastic; the column of the matrix is in a simplex.
SMF is being applied to image recognition and text mining. We can understand
SMF as a statistical model by which a stochastic matrix of given data is
represented by a product of two stochastic matrices, whose generalization
performance has also been left unknown because of non-regularity.
In this paper, by using an algebraic and geometric method, we show the
analytic equivalence of LDA and SMF, both of which have the same real log
canonical threshold (RLCT), resulting in that they asymptotically have the same
Bayesian generalization error and the same log marginal likelihood. Moreover,
we derive the upper bound of the RLCT and prove that it is smaller than the
dimension of the parameter divided by two, hence the Bayesian generalization
errors of them are smaller than those of regular statistical models.
-
We study full Bayesian procedures for sparse linear regression when errors
have a symmetric but otherwise unknown distribution. The unknown error
distribution is endowed with a symmetrized Dirichlet process mixture of
Gaussians. For the prior on regression coefficients, a mixture of point masses
at zero and continuous distributions is considered. We study behavior of the
posterior with diverging number of predictors. Conditions are provided for
consistency in the mean Hellinger distance. The compatibility and restricted
eigenvalue conditions yield the minimax convergence rate of the regression
coefficients in $\ell_1$- and $\ell_2$-norms, respectively. The convergence
rate is adaptive to both the unknown sparsity level and the unknown symmetric
error density under compatibility conditions. In addition, strong model
selection consistency and a semi-parametric Bernstein-von Mises theorem are
proven under slightly stronger conditions.
-
We develop singular value shrinkage priors for the mean matrix parameters in
the matrix-variate normal model with known covariance matrices. Our priors are
superharmonic and put more weight on matrices with smaller singular values.
They are a natural generalization of the Stein prior. Bayes estimators and
Bayesian predictive densities based on our priors are minimax and dominate
those based on the uniform prior in finite samples. In particular, our priors
work well when the true value of the parameter has low rank.
-
Weighting the p-values is a well-established strategy that improves the power
of multiple testing procedures while dealing with heterogeneous data. However,
how to achieve this task in an optimal way is rarely considered in the
literature. This paper contributes to fill the gap in the case of
group-structured null hypotheses, by introducing a new class of procedures
named ADDOW (for Adaptive Data Driven Optimal Weighting) that adapts both to
the alternative distribution and to the proportion of true null hypotheses. We
prove the asymptotical FDR control and power optimality among all weighted
procedures of ADDOW, which shows that it dominates all existing procedures in
that framework. Some numerical experiments show that the proposed method
preserves its optimal properties in the finite sample setting when the number
of tests is moderately large.
-
A new test of normality based on a standardised empirical process is
introduced in this article.
The first step is to introduce a Cram\'er-von Mises type statistic with
weights equal to the inverse of the standard normal density function supported
on a symmetric interval $[-a_n,a_n]$ depending on the sample size $n.$ The
sequence of end points $a_n$ tends to infinity, and is chosen so that the
statistic goes to infinity at the speed of $\ln \ln n.$ After substracting the
mean, a suitable test statistic is obtained, with the same asymptotic law as
the well-known Shapiro-Wilk statistic. The performance of the new test is
described and compared with three other well-known tests of normality, namely,
Shapiro-Wilk, Anderson-Darling and that of del Barrio-Matr\'an, Cuesta
Albertos, and Rodr\'{\i}guez Rodr\'{\i}guez, by means of power calculations
under many alternative hypotheses.
-
Many theoretical results for the lasso require the samples to be iid. Recent
work has provided guarantees for the lasso assuming that the time series is
generated by a sparse Vector Auto-Regressive (VAR) model with Gaussian
innovations. Proofs of these results rely critically on the fact that the true
data generating mechanism (DGM) is a finite-order Gaussian VAR. This assumption
is quite brittle: linear transformations, including selecting a subset of
variables, can lead to the violation of this assumption. In order to break free
from such assumptions, we derive non-asymptotic inequalities for estimation
error and prediction error of the lasso estimate of the best linear predictor
without assuming any special parametric form of the DGM. Instead, we rely only
on (strict) stationarity and geometrically decaying \b{eta}-mixing coefficients
to establish error bounds for the lasso for subweibull random vectors. The
class of subweibull random variables that we introduce includes subgaussian and
subexponential random variables but also includes random variables with tails
heavier than an exponential. We also show that, for Gaussian processes, the
\b{eta}-mixing condition can be relaxed to summability of the {\alpha}-mixing
coefficients. Our work provides an alternative proof of the consistency of the
lasso for sparse Gaussian VAR models. But the applicability of our results
extends to non-Gaussian and non-linear times series models as the examples we
provide demonstrate.
-
We consider the problem of graph matchability in non-identically distributed
networks. In a general class of edge-independent networks, we demonstrate that
graph matchability can be lost with high probability when matching the networks
directly. We further demonstrate that under mild model assumptions,
matchability is almost perfectly recovered by centering the networks using
Universal Singular Value Thresholding before matching. These theoretical
results are then demonstrated in both real and synthetic simulation settings.
We also recover analogous core-matchability results in a very general core-junk
network model, wherein some vertices do not correspond between the graph pair.
-
We extend the Granger-Johansen representation theorems for I(1) and I(2)
vector autoregressive processes to accommodate processes that take values in an
arbitrary complex separable Hilbert space. This more general setting is of
central relevance for statistical applications involving functional time
series. We first obtain a range of necessary and sufficient conditions for a
pole in the inverse of a holomorphic index-zero Fredholm operator pencil to be
of first or second order. Those conditions form the basis for our development
of I(1) and I(2) representations of autoregressive Hilbertian processes.
Cointegrating and attractor subspaces are characterized in terms of the
behavior of the autoregressive operator pencil in a neighborhood of one.
-
Kriging based on Gaussian random fields is widely used in reconstructing
unknown functions. The kriging method has pointwise predictive distributions
which are computationally simple. However, in many applications one would like
to predict for a range of untried points simultaneously. In this work we obtain
some error bounds for the (simple) kriging predictor under the uniform metric.
It works for a scattered set of input points in an arbitrary dimension, and
also covers the case where the covariance function of the Gaussian process is
misspecified. These results lead to a better understanding of the rate of
convergence of kriging under the Gaussian or the Mat\'ern correlation
functions, the relationship between space-filling designs and kriging models,
and the robustness of the Mat\'ern correlation functions.
-
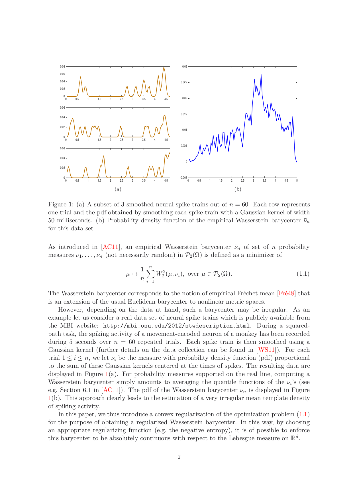
In this paper, a regularization of Wasserstein barycenters for random
measures supported on $\mathbb{R}^{d}$ is introduced via convex penalization.
The existence and uniqueness of such barycenters is first proved for a large
class of penalization functions. The Bregman divergence associated to the
penalization term is then considered to obtain a stability result on penalized
barycenters. This allows the comparison of data made of $n$ absolutely
continuous probability measures, within the more realistic setting where one
only has access to a dataset of random variables sampled from unknown
distributions. The convergence of the penalized empirical barycenter of a set
of $n$ iid random probability measures towards its population counterpart is
finally analyzed. This approach is shown to be appropriate for the statistical
analysis of either discrete or absolutely continuous random measures. It also
allows to construct, from a set of discrete measures, consistent estimators of
population Wasserstein barycenters that are absolutely continuous.
-
We consider the problem of recovering linear image $Bx$ of a signal $x$ known
to belong to a given convex compact set ${\cal X}$ from indirect observation
$\omega=Ax+\xi$ of $x$ corrupted by random noise $\xi$ with finite covariance
matrix. It is shown that under some assumptions on ${\cal X}$ (satisfied, e.g.,
when ${\cal X}$ is the intersection of $K$ concentric ellipsoids/elliptic
cylinders, or the unit ball of the spectral norm in the space of matrices) and
on the norm $\|\cdot\|$ used to measure the recovery error (satisfied, e.g., by
$\|\cdot\|_p$-norms, $1\leq p\leq 2$, on ${\mathbf{R}}^m$ and by the nuclear
norm on the space of matrices), one can build, in a computationally efficient
manner, a "presumably good" linear in observations estimate, and that in the
case of zero mean Gaussian observation noise, this estimate is near-optimal
among all (linear and nonlinear) estimates in terms of its worst-case, over
$x\in {\cal X}$, expected $\|\cdot\|$-loss. These results form an essential
extension of those in our paper arXiv:1602.01355, where the assumptions on
${\cal X}$ were more restrictive, and the norm $\|\cdot\|$ was assumed to be
the Euclidean one. In addition, we develop near-optimal estimates for the case
of "uncertain-but-bounded" noise, where all we know about $\xi$ is that it is
bounded in a given norm by a given $\sigma$. Same as in arXiv:1602.01355, our
results impose no restrictions on $A$ and $B$.
This arXiv paper slightly strengthens the journal publication Juditsky, A.,
Nemirovski, A. "Near-Optimality of Linear Recovery from Indirect Observations,"
Mathematical Statistics and Learning 1:2 (2018), 171-225.
-
Consider the multivariate nonparametric regression model. It is shown that
estimators based on sparsely connected deep neural networks with ReLU
activation function and properly chosen network architecture achieve the
minimax rates of convergence (up to $\log n$-factors) under a general
composition assumption on the regression function. The framework includes many
well-studied structural constraints such as (generalized) additive models.
While there is a lot of flexibility in the network architecture, the tuning
parameter is the sparsity of the network. Specifically, we consider large
networks with number of potential network parameters exceeding the sample size.
The analysis gives some insights into why multilayer feedforward neural
networks perform well in practice. Interestingly, for ReLU activation function
the depth (number of layers) of the neural network architectures plays an
important role and our theory suggests that for nonparametric regression,
scaling the network depth with the sample size is natural. It is also shown
that under the composition assumption wavelet estimators can only achieve
suboptimal rates.
-
We study high-dimensional distribution learning in an agnostic setting where
an adversary is allowed to arbitrarily corrupt an $\varepsilon$-fraction of the
samples. Such questions have a rich history spanning statistics, machine
learning and theoretical computer science. Even in the most basic settings, the
only known approaches are either computationally inefficient or lose
dimension-dependent factors in their error guarantees. This raises the
following question:Is high-dimensional agnostic distribution learning even
possible, algorithmically?
In this work, we obtain the first computationally efficient algorithms with
dimension-independent error guarantees for agnostically learning several
fundamental classes of high-dimensional distributions: (1) a single Gaussian,
(2) a product distribution on the hypercube, (3) mixtures of two product
distributions (under a natural balancedness condition), and (4) mixtures of
spherical Gaussians. Our algorithms achieve error that is independent of the
dimension, and in many cases scales nearly-linearly with the fraction of
adversarially corrupted samples. Moreover, we develop a general recipe for
detecting and correcting corruptions in high-dimensions, that may be applicable
to many other problems.
-
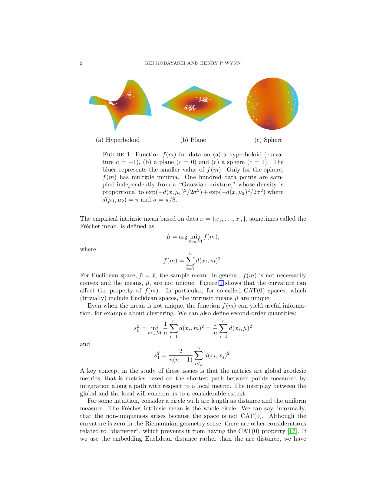
A methodology is developed for data analysis based on empirically constructed
geodesic metric spaces. For a probability distribution, the length along a path
between two points can be defined as the amount of probability mass accumulated
along the path. The geodesic, then, is the shortest such path and defines a
geodesic metric. Such metrics are transformed in a number of ways to produce
parametrised families of geodesic metric spaces, empirical versions of which
allow computation of intrinsic means and associated measures of dispersion.
These reveal properties of the data, based on geometry, such as those that are
difficult to see from the raw Euclidean distances. Examples of application
include clustering and classification. For certain parameter ranges, the spaces
become CAT(0) spaces and the intrinsic means are unique. In one case, a minimal
spanning tree of a graph based on the data becomes CAT(0). In another, a
so-called "metric cone" construction allows extension to CAT($k$) spaces. It is
shown how to empirically tune the parameters of the metrics, making it possible
to apply them to a number of real cases.
-
We tackle the change-point problem with data belonging to a general set. We
build a penalty for choosing the number of change-points in the kernel-based
method of Harchaoui and Capp{\'e} (2007). This penalty generalizes the one
proposed by Lebarbier (2005) for one-dimensional signals. We prove a
non-asymptotic oracle inequality for the proposed method, thanks to a new
concentration result for some function of Hilbert-space valued random
variables. Experiments on synthetic data illustrate the accuracy of our method,
showing that it can detect changes in the whole distribution of data, even when
the mean and variance are constant.
-
We study the problem of variable selection for linear models under the
high-dimensional asymptotic setting, where the number of observations $n$ grows
at the same rate as the number of predictors $p$. We consider two-stage
variable selection techniques (TVS) in which the first stage uses bridge
estimators to obtain an estimate of the regression coefficients, and the second
stage simply thresholds this estimate to select the "important" predictors. The
asymptotic false discovery proportion (AFDP) and true positive proportion
(ATPP) of these TVS are evaluated. We prove that for a fixed ATPP, in order to
obtain a smaller AFDP, one should pick a bridge estimator with smaller
asymptotic mean square error in the first stage of TVS. Based on such
principled discovery, we present a sharp comparison of different TVS, via an
in-depth investigation of the estimation properties of bridge estimators.
Rather than "order-wise" error bounds with loose constants, our analysis
focuses on precise error characterization. Various interesting signal-to-noise
ratio and sparsity settings are studied. Our results offer new and thorough
insights into high-dimensional variable selection. For instance, we prove that
a TVS with Ridge in its first stage outperforms TVS with other bridge
estimators in large noise settings; two-stage LASSO becomes inferior when the
signal is rare and weak. As a by-product, we show that two-stage methods
outperform some standard variable selection techniques, such as LASSO and Sure
Independence Screening, under certain conditions.
-
There is a growing need for the ability to analyse interval-valued data.
However, existing descriptive frameworks to achieve this ignore the process by
which interval-valued data are typically constructed; namely by the aggregation
of real-valued data generated from some underlying process. In this article we
develop the foundations of likelihood based statistical inference for random
intervals that directly incorporates the underlying generative procedure into
the analysis. That is, it permits the direct fitting of models for the
underlying real-valued data given only the random interval-valued summaries.
This generative approach overcomes several problems associated with existing
methods, including the rarely satisfied assumption of within-interval
uniformity. The new methods are illustrated by simulated and real data
analyses.
-
We study the detection problem of finding planted solutions in random
instances of flat satisfiability problems, a generalization of boolean
satisfiability formulas. We describe the properties of random instances of flat
satisfiability, as well of the optimal rates of detection of the associated
hypothesis testing problem. We also study the performance of an algorithmically
efficient testing procedure. We introduce a modification of our model, the
light planting of solutions, and show that it is as hard as the problem of
learning parity with noise. This hints strongly at the difficulty of detecting
planted flat satisfiability for a wide class of tests.
-
We show that prediction performance for global-local shrinkage regression can
overcome two major difficulties of global shrinkage regression: (i) the amount
of relative shrinkage is monotone in the singular values of the design matrix
and (ii) the shrinkage is determined by a single tuning parameter.
Specifically, we show that the horseshoe regression, with heavy-tailed
component-specific local shrinkage parameters, in conjunction with a global
parameter providing shrinkage towards zero, alleviates both these difficulties
and consequently, results in an improved risk for prediction. Numerical
demonstrations of improved prediction over competing approaches in simulations
and in a pharmacogenomics data set confirm our theoretical findings.
-
We consider the challenging problem of statistical inference for
exponential-family random graph models based on a single observation of a
random graph with complex dependence. To facilitate statistical inference, we
consider random graphs with additional structure in the form of block
structure. We have shown elsewhere that when the block structure is known, it
facilitates consistency results for $M$-estimators of canonical and curved
exponential-family random graph models with complex dependence, such as
transitivity. In practice, the block structure is known in some applications
(e.g., multilevel networks), but is unknown in others. When the block structure
is unknown, the first and foremost question is whether it can be recovered with
high probability based on a single observation of a random graph with complex
dependence. The main consistency results of the paper show that it is possible
to do so under weak dependence and smoothness conditions. These results confirm
that exponential-family random graph models with block structure constitute a
promising direction of statistical network analysis.





 We propose a general framework for nonasymptotic covariance matrix estimation making use of concentration inequality-based confidence sets. We specify this framework for the estimation of large sparse covariance matrices through incorporation of past thresholding estimators with key emphasis on support recovery. This technique goes beyond past results for thresholding estimators by allowing for a wide range of distributional assumptions beyond merely sub-Gaussian tails. This methodology can furthermore be adapted to a wide range of other estimators and settings. The usage of nonasymptotic dimension-free confidence sets yields good theoretical performance. Through extensive simulations, it is demonstrated to have superior performance when compared with other such methods. In the context of support recovery, we are able to specify a false positive rate and optimize to maximize the true recoveries.
We propose a general framework for nonasymptotic covariance matrix estimation making use of concentration inequality-based confidence sets. We specify this framework for the estimation of large sparse covariance matrices through incorporation of past thresholding estimators with key emphasis on support recovery. This technique goes beyond past results for thresholding estimators by allowing for a wide range of distributional assumptions beyond merely sub-Gaussian tails. This methodology can furthermore be adapted to a wide range of other estimators and settings. The usage of nonasymptotic dimension-free confidence sets yields good theoretical performance. Through extensive simulations, it is demonstrated to have superior performance when compared with other such methods. In the context of support recovery, we are able to specify a false positive rate and optimize to maximize the true recoveries.




 We show that several machine learning estimators, including square-root LASSO (Least Absolute Shrinkage and Selection) and regularized logistic regression can be represented as solutions to distributionally robust optimization (DRO) problems. The associated uncertainty regions are based on suitably defined Wasserstein distances. Hence, our representations allow us to view regularization as a result of introducing an artificial adversary that perturbs the empirical distribution to account for out-of-sample effects in loss estimation. In addition, we introduce RWPI (Robust Wasserstein Profile Inference), a novel inference methodology which extends the use of methods inspired by Empirical Likelihood to the setting of optimal transport costs (of which Wasserstein distances are a particular case). We use RWPI to show how to optimally select the size of uncertainty regions, and as a consequence, we are able to choose regularization parameters for these machine learning estimators without the use of cross validation. Numerical experiments are also given to validate our theoretical findings.
We show that several machine learning estimators, including square-root LASSO (Least Absolute Shrinkage and Selection) and regularized logistic regression can be represented as solutions to distributionally robust optimization (DRO) problems. The associated uncertainty regions are based on suitably defined Wasserstein distances. Hence, our representations allow us to view regularization as a result of introducing an artificial adversary that perturbs the empirical distribution to account for out-of-sample effects in loss estimation. In addition, we introduce RWPI (Robust Wasserstein Profile Inference), a novel inference methodology which extends the use of methods inspired by Empirical Likelihood to the setting of optimal transport costs (of which Wasserstein distances are a particular case). We use RWPI to show how to optimally select the size of uncertainty regions, and as a consequence, we are able to choose regularization parameters for these machine learning estimators without the use of cross validation. Numerical experiments are also given to validate our theoretical findings.




 The global sensitivity analysis of a numerical model aims to quantify, by means of sensitivity indices estimate, the contributions of each uncertain input variable to the model output uncertainty. The so-called Sobol' indices, which are based on the functional variance analysis, present a difficult interpretation in the presence of statistical dependence between inputs. The Shapley effect was recently introduced to overcome this problem as they allocate the mutual contribution (due to correlation and interaction) of a group of inputs to each individual input within the group.In this paper, using several new analytical results, we study the effects of linear correlation between some Gaussian input variables on Shapley effects, and compare these effects to classical first-order and total Sobol' indices.This illustrates the interest, in terms of sensitivity analysis setting and interpretation, of the Shapley effects in the case of dependent inputs. For the practical issue of computationally demanding computer models, we show that the substitution of the original model by a metamodel (here, kriging) makes it possible to estimate these indices with precision at a reasonable computational cost.
The global sensitivity analysis of a numerical model aims to quantify, by means of sensitivity indices estimate, the contributions of each uncertain input variable to the model output uncertainty. The so-called Sobol' indices, which are based on the functional variance analysis, present a difficult interpretation in the presence of statistical dependence between inputs. The Shapley effect was recently introduced to overcome this problem as they allocate the mutual contribution (due to correlation and interaction) of a group of inputs to each individual input within the group.In this paper, using several new analytical results, we study the effects of linear correlation between some Gaussian input variables on Shapley effects, and compare these effects to classical first-order and total Sobol' indices.This illustrates the interest, in terms of sensitivity analysis setting and interpretation, of the Shapley effects in the case of dependent inputs. For the practical issue of computationally demanding computer models, we show that the substitution of the original model by a metamodel (here, kriging) makes it possible to estimate these indices with precision at a reasonable computational cost.




 The inductive size bias coupling technique and Stein's method yield a Berry-Esseen theorem for the number of urns having occupancy $d \ge 2$ when $n$ balls are uniformly distributed over $m$ urns. In particular, there exists a constant $C$ depending only on $d$ such that $$ \sup_{z \in \mathbb{R}}|P(W_{n,m} \le z) -P(Z \le z)| \le C \left( \frac{1+(\frac{n}{m})^3}{\sigma_{n,m}} \right) \quad \mbox{for all $n \ge d$ and $m \ge 2$,} $$ where $W_{n,m}$ and $\sigma_{n,m}^2$ are the standardized count and variance, respectively, of the number of urns with $d$ balls, and $Z$ is a standard normal random variable. Asymptotically, the bound is optimal up to constants if $n$ and $m$ tend to infinity together in a way such that $n/m$ stays bounded.
The inductive size bias coupling technique and Stein's method yield a Berry-Esseen theorem for the number of urns having occupancy $d \ge 2$ when $n$ balls are uniformly distributed over $m$ urns. In particular, there exists a constant $C$ depending only on $d$ such that $$ \sup_{z \in \mathbb{R}}|P(W_{n,m} \le z) -P(Z \le z)| \le C \left( \frac{1+(\frac{n}{m})^3}{\sigma_{n,m}} \right) \quad \mbox{for all $n \ge d$ and $m \ge 2$,} $$ where $W_{n,m}$ and $\sigma_{n,m}^2$ are the standardized count and variance, respectively, of the number of urns with $d$ balls, and $Z$ is a standard normal random variable. Asymptotically, the bound is optimal up to constants if $n$ and $m$ tend to infinity together in a way such that $n/m$ stays bounded.




 Information theory is a mathematical theory of learning with deep connections with topics as diverse as artificial intelligence, statistical physics, and biological evolution. Many primers on information theory paint a broad picture with relatively little mathematical sophistication, while many others develop specific application areas in detail. In contrast, these informal notes aim to outline some elements of the information-theoretic "way of thinking," by cutting a rapid and interesting path through some of the theory's foundational concepts and results. They are aimed at practicing systems scientists who are interested in exploring potential connections between information theory and their own fields. The main mathematical prerequisite for the notes is comfort with elementary probability, including sample spaces, conditioning, and expectations. We take the Kullback-Leibler divergence as our most basic concept, and then proceed to develop the entropy and mutual information. We discuss some of the main results, including the Chernoff bounds as a characterization of the divergence; Gibbs' Theorem; and the Data Processing Inequality. A recurring theme is that the definitions of information theory support natural theorems that sound ``obvious'' when translated into English. More pithily, ``information theory makes common sense precise.'' Since the focus of the notes is not primarily on technical details, proofs are provided only where the relevant techniques are illustrative of broader themes. Otherwise, proofs and intriguing tangents are referenced in liberally-sprinkled footnotes. The notes close with a highly nonexhaustive list of references to resources and other perspectives on the field.
Information theory is a mathematical theory of learning with deep connections with topics as diverse as artificial intelligence, statistical physics, and biological evolution. Many primers on information theory paint a broad picture with relatively little mathematical sophistication, while many others develop specific application areas in detail. In contrast, these informal notes aim to outline some elements of the information-theoretic "way of thinking," by cutting a rapid and interesting path through some of the theory's foundational concepts and results. They are aimed at practicing systems scientists who are interested in exploring potential connections between information theory and their own fields. The main mathematical prerequisite for the notes is comfort with elementary probability, including sample spaces, conditioning, and expectations. We take the Kullback-Leibler divergence as our most basic concept, and then proceed to develop the entropy and mutual information. We discuss some of the main results, including the Chernoff bounds as a characterization of the divergence; Gibbs' Theorem; and the Data Processing Inequality. A recurring theme is that the definitions of information theory support natural theorems that sound ``obvious'' when translated into English. More pithily, ``information theory makes common sense precise.'' Since the focus of the notes is not primarily on technical details, proofs are provided only where the relevant techniques are illustrative of broader themes. Otherwise, proofs and intriguing tangents are referenced in liberally-sprinkled footnotes. The notes close with a highly nonexhaustive list of references to resources and other perspectives on the field.




 We study full Bayesian procedures for sparse linear regression when errors have a symmetric but otherwise unknown distribution. The unknown error distribution is endowed with a symmetrized Dirichlet process mixture of Gaussians. For the prior on regression coefficients, a mixture of point masses at zero and continuous distributions is considered. We study behavior of the posterior with diverging number of predictors. Conditions are provided for consistency in the mean Hellinger distance. The compatibility and restricted eigenvalue conditions yield the minimax convergence rate of the regression coefficients in $\ell_1$- and $\ell_2$-norms, respectively. The convergence rate is adaptive to both the unknown sparsity level and the unknown symmetric error density under compatibility conditions. In addition, strong model selection consistency and a semi-parametric Bernstein-von Mises theorem are proven under slightly stronger conditions.
We study full Bayesian procedures for sparse linear regression when errors have a symmetric but otherwise unknown distribution. The unknown error distribution is endowed with a symmetrized Dirichlet process mixture of Gaussians. For the prior on regression coefficients, a mixture of point masses at zero and continuous distributions is considered. We study behavior of the posterior with diverging number of predictors. Conditions are provided for consistency in the mean Hellinger distance. The compatibility and restricted eigenvalue conditions yield the minimax convergence rate of the regression coefficients in $\ell_1$- and $\ell_2$-norms, respectively. The convergence rate is adaptive to both the unknown sparsity level and the unknown symmetric error density under compatibility conditions. In addition, strong model selection consistency and a semi-parametric Bernstein-von Mises theorem are proven under slightly stronger conditions.




 We develop singular value shrinkage priors for the mean matrix parameters in the matrix-variate normal model with known covariance matrices. Our priors are superharmonic and put more weight on matrices with smaller singular values. They are a natural generalization of the Stein prior. Bayes estimators and Bayesian predictive densities based on our priors are minimax and dominate those based on the uniform prior in finite samples. In particular, our priors work well when the true value of the parameter has low rank.
We develop singular value shrinkage priors for the mean matrix parameters in the matrix-variate normal model with known covariance matrices. Our priors are superharmonic and put more weight on matrices with smaller singular values. They are a natural generalization of the Stein prior. Bayes estimators and Bayesian predictive densities based on our priors are minimax and dominate those based on the uniform prior in finite samples. In particular, our priors work well when the true value of the parameter has low rank.




 Many theoretical results for the lasso require the samples to be iid. Recent work has provided guarantees for the lasso assuming that the time series is generated by a sparse Vector Auto-Regressive (VAR) model with Gaussian innovations. Proofs of these results rely critically on the fact that the true data generating mechanism (DGM) is a finite-order Gaussian VAR. This assumption is quite brittle: linear transformations, including selecting a subset of variables, can lead to the violation of this assumption. In order to break free from such assumptions, we derive non-asymptotic inequalities for estimation error and prediction error of the lasso estimate of the best linear predictor without assuming any special parametric form of the DGM. Instead, we rely only on (strict) stationarity and geometrically decaying \b{eta}-mixing coefficients to establish error bounds for the lasso for subweibull random vectors. The class of subweibull random variables that we introduce includes subgaussian and subexponential random variables but also includes random variables with tails heavier than an exponential. We also show that, for Gaussian processes, the \b{eta}-mixing condition can be relaxed to summability of the {\alpha}-mixing coefficients. Our work provides an alternative proof of the consistency of the lasso for sparse Gaussian VAR models. But the applicability of our results extends to non-Gaussian and non-linear times series models as the examples we provide demonstrate.
Many theoretical results for the lasso require the samples to be iid. Recent work has provided guarantees for the lasso assuming that the time series is generated by a sparse Vector Auto-Regressive (VAR) model with Gaussian innovations. Proofs of these results rely critically on the fact that the true data generating mechanism (DGM) is a finite-order Gaussian VAR. This assumption is quite brittle: linear transformations, including selecting a subset of variables, can lead to the violation of this assumption. In order to break free from such assumptions, we derive non-asymptotic inequalities for estimation error and prediction error of the lasso estimate of the best linear predictor without assuming any special parametric form of the DGM. Instead, we rely only on (strict) stationarity and geometrically decaying \b{eta}-mixing coefficients to establish error bounds for the lasso for subweibull random vectors. The class of subweibull random variables that we introduce includes subgaussian and subexponential random variables but also includes random variables with tails heavier than an exponential. We also show that, for Gaussian processes, the \b{eta}-mixing condition can be relaxed to summability of the {\alpha}-mixing coefficients. Our work provides an alternative proof of the consistency of the lasso for sparse Gaussian VAR models. But the applicability of our results extends to non-Gaussian and non-linear times series models as the examples we provide demonstrate.




 We consider the problem of graph matchability in non-identically distributed networks. In a general class of edge-independent networks, we demonstrate that graph matchability can be lost with high probability when matching the networks directly. We further demonstrate that under mild model assumptions, matchability is almost perfectly recovered by centering the networks using Universal Singular Value Thresholding before matching. These theoretical results are then demonstrated in both real and synthetic simulation settings. We also recover analogous core-matchability results in a very general core-junk network model, wherein some vertices do not correspond between the graph pair.
We consider the problem of graph matchability in non-identically distributed networks. In a general class of edge-independent networks, we demonstrate that graph matchability can be lost with high probability when matching the networks directly. We further demonstrate that under mild model assumptions, matchability is almost perfectly recovered by centering the networks using Universal Singular Value Thresholding before matching. These theoretical results are then demonstrated in both real and synthetic simulation settings. We also recover analogous core-matchability results in a very general core-junk network model, wherein some vertices do not correspond between the graph pair.




 We extend the Granger-Johansen representation theorems for I(1) and I(2) vector autoregressive processes to accommodate processes that take values in an arbitrary complex separable Hilbert space. This more general setting is of central relevance for statistical applications involving functional time series. We first obtain a range of necessary and sufficient conditions for a pole in the inverse of a holomorphic index-zero Fredholm operator pencil to be of first or second order. Those conditions form the basis for our development of I(1) and I(2) representations of autoregressive Hilbertian processes. Cointegrating and attractor subspaces are characterized in terms of the behavior of the autoregressive operator pencil in a neighborhood of one.
We extend the Granger-Johansen representation theorems for I(1) and I(2) vector autoregressive processes to accommodate processes that take values in an arbitrary complex separable Hilbert space. This more general setting is of central relevance for statistical applications involving functional time series. We first obtain a range of necessary and sufficient conditions for a pole in the inverse of a holomorphic index-zero Fredholm operator pencil to be of first or second order. Those conditions form the basis for our development of I(1) and I(2) representations of autoregressive Hilbertian processes. Cointegrating and attractor subspaces are characterized in terms of the behavior of the autoregressive operator pencil in a neighborhood of one.



 In this paper, a regularization of Wasserstein barycenters for random measures supported on $\mathbb{R}^{d}$ is introduced via convex penalization. The existence and uniqueness of such barycenters is first proved for a large class of penalization functions. The Bregman divergence associated to the penalization term is then considered to obtain a stability result on penalized barycenters. This allows the comparison of data made of $n$ absolutely continuous probability measures, within the more realistic setting where one only has access to a dataset of random variables sampled from unknown distributions. The convergence of the penalized empirical barycenter of a set of $n$ iid random probability measures towards its population counterpart is finally analyzed. This approach is shown to be appropriate for the statistical analysis of either discrete or absolutely continuous random measures. It also allows to construct, from a set of discrete measures, consistent estimators of population Wasserstein barycenters that are absolutely continuous.
In this paper, a regularization of Wasserstein barycenters for random measures supported on $\mathbb{R}^{d}$ is introduced via convex penalization. The existence and uniqueness of such barycenters is first proved for a large class of penalization functions. The Bregman divergence associated to the penalization term is then considered to obtain a stability result on penalized barycenters. This allows the comparison of data made of $n$ absolutely continuous probability measures, within the more realistic setting where one only has access to a dataset of random variables sampled from unknown distributions. The convergence of the penalized empirical barycenter of a set of $n$ iid random probability measures towards its population counterpart is finally analyzed. This approach is shown to be appropriate for the statistical analysis of either discrete or absolutely continuous random measures. It also allows to construct, from a set of discrete measures, consistent estimators of population Wasserstein barycenters that are absolutely continuous.




 We consider the problem of recovering linear image $Bx$ of a signal $x$ known to belong to a given convex compact set ${\cal X}$ from indirect observation $\omega=Ax+\xi$ of $x$ corrupted by random noise $\xi$ with finite covariance matrix. It is shown that under some assumptions on ${\cal X}$ (satisfied, e.g., when ${\cal X}$ is the intersection of $K$ concentric ellipsoids/elliptic cylinders, or the unit ball of the spectral norm in the space of matrices) and on the norm $\|\cdot\|$ used to measure the recovery error (satisfied, e.g., by $\|\cdot\|_p$-norms, $1\leq p\leq 2$, on ${\mathbf{R}}^m$ and by the nuclear norm on the space of matrices), one can build, in a computationally efficient manner, a "presumably good" linear in observations estimate, and that in the case of zero mean Gaussian observation noise, this estimate is near-optimal among all (linear and nonlinear) estimates in terms of its worst-case, over $x\in {\cal X}$, expected $\|\cdot\|$-loss. These results form an essential extension of those in our paper arXiv:1602.01355, where the assumptions on ${\cal X}$ were more restrictive, and the norm $\|\cdot\|$ was assumed to be the Euclidean one. In addition, we develop near-optimal estimates for the case of "uncertain-but-bounded" noise, where all we know about $\xi$ is that it is bounded in a given norm by a given $\sigma$. Same as in arXiv:1602.01355, our results impose no restrictions on $A$ and $B$. This arXiv paper slightly strengthens the journal publication Juditsky, A., Nemirovski, A. "Near-Optimality of Linear Recovery from Indirect Observations," Mathematical Statistics and Learning 1:2 (2018), 171-225.
We consider the problem of recovering linear image $Bx$ of a signal $x$ known to belong to a given convex compact set ${\cal X}$ from indirect observation $\omega=Ax+\xi$ of $x$ corrupted by random noise $\xi$ with finite covariance matrix. It is shown that under some assumptions on ${\cal X}$ (satisfied, e.g., when ${\cal X}$ is the intersection of $K$ concentric ellipsoids/elliptic cylinders, or the unit ball of the spectral norm in the space of matrices) and on the norm $\|\cdot\|$ used to measure the recovery error (satisfied, e.g., by $\|\cdot\|_p$-norms, $1\leq p\leq 2$, on ${\mathbf{R}}^m$ and by the nuclear norm on the space of matrices), one can build, in a computationally efficient manner, a "presumably good" linear in observations estimate, and that in the case of zero mean Gaussian observation noise, this estimate is near-optimal among all (linear and nonlinear) estimates in terms of its worst-case, over $x\in {\cal X}$, expected $\|\cdot\|$-loss. These results form an essential extension of those in our paper arXiv:1602.01355, where the assumptions on ${\cal X}$ were more restrictive, and the norm $\|\cdot\|$ was assumed to be the Euclidean one. In addition, we develop near-optimal estimates for the case of "uncertain-but-bounded" noise, where all we know about $\xi$ is that it is bounded in a given norm by a given $\sigma$. Same as in arXiv:1602.01355, our results impose no restrictions on $A$ and $B$. This arXiv paper slightly strengthens the journal publication Juditsky, A., Nemirovski, A. "Near-Optimality of Linear Recovery from Indirect Observations," Mathematical Statistics and Learning 1:2 (2018), 171-225.




 Consider the multivariate nonparametric regression model. It is shown that estimators based on sparsely connected deep neural networks with ReLU activation function and properly chosen network architecture achieve the minimax rates of convergence (up to $\log n$-factors) under a general composition assumption on the regression function. The framework includes many well-studied structural constraints such as (generalized) additive models. While there is a lot of flexibility in the network architecture, the tuning parameter is the sparsity of the network. Specifically, we consider large networks with number of potential network parameters exceeding the sample size. The analysis gives some insights into why multilayer feedforward neural networks perform well in practice. Interestingly, for ReLU activation function the depth (number of layers) of the neural network architectures plays an important role and our theory suggests that for nonparametric regression, scaling the network depth with the sample size is natural. It is also shown that under the composition assumption wavelet estimators can only achieve suboptimal rates.
Consider the multivariate nonparametric regression model. It is shown that estimators based on sparsely connected deep neural networks with ReLU activation function and properly chosen network architecture achieve the minimax rates of convergence (up to $\log n$-factors) under a general composition assumption on the regression function. The framework includes many well-studied structural constraints such as (generalized) additive models. While there is a lot of flexibility in the network architecture, the tuning parameter is the sparsity of the network. Specifically, we consider large networks with number of potential network parameters exceeding the sample size. The analysis gives some insights into why multilayer feedforward neural networks perform well in practice. Interestingly, for ReLU activation function the depth (number of layers) of the neural network architectures plays an important role and our theory suggests that for nonparametric regression, scaling the network depth with the sample size is natural. It is also shown that under the composition assumption wavelet estimators can only achieve suboptimal rates.




 We study high-dimensional distribution learning in an agnostic setting where an adversary is allowed to arbitrarily corrupt an $\varepsilon$-fraction of the samples. Such questions have a rich history spanning statistics, machine learning and theoretical computer science. Even in the most basic settings, the only known approaches are either computationally inefficient or lose dimension-dependent factors in their error guarantees. This raises the following question:Is high-dimensional agnostic distribution learning even possible, algorithmically? In this work, we obtain the first computationally efficient algorithms with dimension-independent error guarantees for agnostically learning several fundamental classes of high-dimensional distributions: (1) a single Gaussian, (2) a product distribution on the hypercube, (3) mixtures of two product distributions (under a natural balancedness condition), and (4) mixtures of spherical Gaussians. Our algorithms achieve error that is independent of the dimension, and in many cases scales nearly-linearly with the fraction of adversarially corrupted samples. Moreover, we develop a general recipe for detecting and correcting corruptions in high-dimensions, that may be applicable to many other problems.
We study high-dimensional distribution learning in an agnostic setting where an adversary is allowed to arbitrarily corrupt an $\varepsilon$-fraction of the samples. Such questions have a rich history spanning statistics, machine learning and theoretical computer science. Even in the most basic settings, the only known approaches are either computationally inefficient or lose dimension-dependent factors in their error guarantees. This raises the following question:Is high-dimensional agnostic distribution learning even possible, algorithmically? In this work, we obtain the first computationally efficient algorithms with dimension-independent error guarantees for agnostically learning several fundamental classes of high-dimensional distributions: (1) a single Gaussian, (2) a product distribution on the hypercube, (3) mixtures of two product distributions (under a natural balancedness condition), and (4) mixtures of spherical Gaussians. Our algorithms achieve error that is independent of the dimension, and in many cases scales nearly-linearly with the fraction of adversarially corrupted samples. Moreover, we develop a general recipe for detecting and correcting corruptions in high-dimensions, that may be applicable to many other problems.



 A methodology is developed for data analysis based on empirically constructed geodesic metric spaces. For a probability distribution, the length along a path between two points can be defined as the amount of probability mass accumulated along the path. The geodesic, then, is the shortest such path and defines a geodesic metric. Such metrics are transformed in a number of ways to produce parametrised families of geodesic metric spaces, empirical versions of which allow computation of intrinsic means and associated measures of dispersion. These reveal properties of the data, based on geometry, such as those that are difficult to see from the raw Euclidean distances. Examples of application include clustering and classification. For certain parameter ranges, the spaces become CAT(0) spaces and the intrinsic means are unique. In one case, a minimal spanning tree of a graph based on the data becomes CAT(0). In another, a so-called "metric cone" construction allows extension to CAT($k$) spaces. It is shown how to empirically tune the parameters of the metrics, making it possible to apply them to a number of real cases.
A methodology is developed for data analysis based on empirically constructed geodesic metric spaces. For a probability distribution, the length along a path between two points can be defined as the amount of probability mass accumulated along the path. The geodesic, then, is the shortest such path and defines a geodesic metric. Such metrics are transformed in a number of ways to produce parametrised families of geodesic metric spaces, empirical versions of which allow computation of intrinsic means and associated measures of dispersion. These reveal properties of the data, based on geometry, such as those that are difficult to see from the raw Euclidean distances. Examples of application include clustering and classification. For certain parameter ranges, the spaces become CAT(0) spaces and the intrinsic means are unique. In one case, a minimal spanning tree of a graph based on the data becomes CAT(0). In another, a so-called "metric cone" construction allows extension to CAT($k$) spaces. It is shown how to empirically tune the parameters of the metrics, making it possible to apply them to a number of real cases.




 We tackle the change-point problem with data belonging to a general set. We build a penalty for choosing the number of change-points in the kernel-based method of Harchaoui and Capp{\'e} (2007). This penalty generalizes the one proposed by Lebarbier (2005) for one-dimensional signals. We prove a non-asymptotic oracle inequality for the proposed method, thanks to a new concentration result for some function of Hilbert-space valued random variables. Experiments on synthetic data illustrate the accuracy of our method, showing that it can detect changes in the whole distribution of data, even when the mean and variance are constant.
We tackle the change-point problem with data belonging to a general set. We build a penalty for choosing the number of change-points in the kernel-based method of Harchaoui and Capp{\'e} (2007). This penalty generalizes the one proposed by Lebarbier (2005) for one-dimensional signals. We prove a non-asymptotic oracle inequality for the proposed method, thanks to a new concentration result for some function of Hilbert-space valued random variables. Experiments on synthetic data illustrate the accuracy of our method, showing that it can detect changes in the whole distribution of data, even when the mean and variance are constant.




 We study the problem of variable selection for linear models under the high-dimensional asymptotic setting, where the number of observations $n$ grows at the same rate as the number of predictors $p$. We consider two-stage variable selection techniques (TVS) in which the first stage uses bridge estimators to obtain an estimate of the regression coefficients, and the second stage simply thresholds this estimate to select the "important" predictors. The asymptotic false discovery proportion (AFDP) and true positive proportion (ATPP) of these TVS are evaluated. We prove that for a fixed ATPP, in order to obtain a smaller AFDP, one should pick a bridge estimator with smaller asymptotic mean square error in the first stage of TVS. Based on such principled discovery, we present a sharp comparison of different TVS, via an in-depth investigation of the estimation properties of bridge estimators. Rather than "order-wise" error bounds with loose constants, our analysis focuses on precise error characterization. Various interesting signal-to-noise ratio and sparsity settings are studied. Our results offer new and thorough insights into high-dimensional variable selection. For instance, we prove that a TVS with Ridge in its first stage outperforms TVS with other bridge estimators in large noise settings; two-stage LASSO becomes inferior when the signal is rare and weak. As a by-product, we show that two-stage methods outperform some standard variable selection techniques, such as LASSO and Sure Independence Screening, under certain conditions.
We study the problem of variable selection for linear models under the high-dimensional asymptotic setting, where the number of observations $n$ grows at the same rate as the number of predictors $p$. We consider two-stage variable selection techniques (TVS) in which the first stage uses bridge estimators to obtain an estimate of the regression coefficients, and the second stage simply thresholds this estimate to select the "important" predictors. The asymptotic false discovery proportion (AFDP) and true positive proportion (ATPP) of these TVS are evaluated. We prove that for a fixed ATPP, in order to obtain a smaller AFDP, one should pick a bridge estimator with smaller asymptotic mean square error in the first stage of TVS. Based on such principled discovery, we present a sharp comparison of different TVS, via an in-depth investigation of the estimation properties of bridge estimators. Rather than "order-wise" error bounds with loose constants, our analysis focuses on precise error characterization. Various interesting signal-to-noise ratio and sparsity settings are studied. Our results offer new and thorough insights into high-dimensional variable selection. For instance, we prove that a TVS with Ridge in its first stage outperforms TVS with other bridge estimators in large noise settings; two-stage LASSO becomes inferior when the signal is rare and weak. As a by-product, we show that two-stage methods outperform some standard variable selection techniques, such as LASSO and Sure Independence Screening, under certain conditions.




 There is a growing need for the ability to analyse interval-valued data. However, existing descriptive frameworks to achieve this ignore the process by which interval-valued data are typically constructed; namely by the aggregation of real-valued data generated from some underlying process. In this article we develop the foundations of likelihood based statistical inference for random intervals that directly incorporates the underlying generative procedure into the analysis. That is, it permits the direct fitting of models for the underlying real-valued data given only the random interval-valued summaries. This generative approach overcomes several problems associated with existing methods, including the rarely satisfied assumption of within-interval uniformity. The new methods are illustrated by simulated and real data analyses.
There is a growing need for the ability to analyse interval-valued data. However, existing descriptive frameworks to achieve this ignore the process by which interval-valued data are typically constructed; namely by the aggregation of real-valued data generated from some underlying process. In this article we develop the foundations of likelihood based statistical inference for random intervals that directly incorporates the underlying generative procedure into the analysis. That is, it permits the direct fitting of models for the underlying real-valued data given only the random interval-valued summaries. This generative approach overcomes several problems associated with existing methods, including the rarely satisfied assumption of within-interval uniformity. The new methods are illustrated by simulated and real data analyses.




 We study the detection problem of finding planted solutions in random instances of flat satisfiability problems, a generalization of boolean satisfiability formulas. We describe the properties of random instances of flat satisfiability, as well of the optimal rates of detection of the associated hypothesis testing problem. We also study the performance of an algorithmically efficient testing procedure. We introduce a modification of our model, the light planting of solutions, and show that it is as hard as the problem of learning parity with noise. This hints strongly at the difficulty of detecting planted flat satisfiability for a wide class of tests.
We study the detection problem of finding planted solutions in random instances of flat satisfiability problems, a generalization of boolean satisfiability formulas. We describe the properties of random instances of flat satisfiability, as well of the optimal rates of detection of the associated hypothesis testing problem. We also study the performance of an algorithmically efficient testing procedure. We introduce a modification of our model, the light planting of solutions, and show that it is as hard as the problem of learning parity with noise. This hints strongly at the difficulty of detecting planted flat satisfiability for a wide class of tests.




 We show that prediction performance for global-local shrinkage regression can overcome two major difficulties of global shrinkage regression: (i) the amount of relative shrinkage is monotone in the singular values of the design matrix and (ii) the shrinkage is determined by a single tuning parameter. Specifically, we show that the horseshoe regression, with heavy-tailed component-specific local shrinkage parameters, in conjunction with a global parameter providing shrinkage towards zero, alleviates both these difficulties and consequently, results in an improved risk for prediction. Numerical demonstrations of improved prediction over competing approaches in simulations and in a pharmacogenomics data set confirm our theoretical findings.
We show that prediction performance for global-local shrinkage regression can overcome two major difficulties of global shrinkage regression: (i) the amount of relative shrinkage is monotone in the singular values of the design matrix and (ii) the shrinkage is determined by a single tuning parameter. Specifically, we show that the horseshoe regression, with heavy-tailed component-specific local shrinkage parameters, in conjunction with a global parameter providing shrinkage towards zero, alleviates both these difficulties and consequently, results in an improved risk for prediction. Numerical demonstrations of improved prediction over competing approaches in simulations and in a pharmacogenomics data set confirm our theoretical findings.




 We consider the challenging problem of statistical inference for exponential-family random graph models based on a single observation of a random graph with complex dependence. To facilitate statistical inference, we consider random graphs with additional structure in the form of block structure. We have shown elsewhere that when the block structure is known, it facilitates consistency results for $M$-estimators of canonical and curved exponential-family random graph models with complex dependence, such as transitivity. In practice, the block structure is known in some applications (e.g., multilevel networks), but is unknown in others. When the block structure is unknown, the first and foremost question is whether it can be recovered with high probability based on a single observation of a random graph with complex dependence. The main consistency results of the paper show that it is possible to do so under weak dependence and smoothness conditions. These results confirm that exponential-family random graph models with block structure constitute a promising direction of statistical network analysis.
We consider the challenging problem of statistical inference for exponential-family random graph models based on a single observation of a random graph with complex dependence. To facilitate statistical inference, we consider random graphs with additional structure in the form of block structure. We have shown elsewhere that when the block structure is known, it facilitates consistency results for $M$-estimators of canonical and curved exponential-family random graph models with complex dependence, such as transitivity. In practice, the block structure is known in some applications (e.g., multilevel networks), but is unknown in others. When the block structure is unknown, the first and foremost question is whether it can be recovered with high probability based on a single observation of a random graph with complex dependence. The main consistency results of the paper show that it is possible to do so under weak dependence and smoothness conditions. These results confirm that exponential-family random graph models with block structure constitute a promising direction of statistical network analysis.