-
It is well recognised that animal and plant pathogens form complex ecological
communities of interacting organisms within their hosts. Although community
ecology approaches have been applied to determine pathogen interactions at the
within-host scale, methodologies enabling robust inference of the
epidemiological impact of pathogen interactions are lacking. Here we developed
a novel statistical framework to identify statistical covariances from the
infection time-series of multiple pathogens simultaneously. Our framework
extends Bayesian multivariate disease mapping models to analyse multivariate
time series data by accounting for within- and between-year dependencies in
infection risk and incorporating a between-pathogen covariance matrix which we
estimate. Importantly, our approach accounts for possible confounding drivers
of temporal patterns in pathogen infection frequencies, enabling robust
inference of pathogen-pathogen interactions. We illustrate the validity of our
statistical framework using simulated data and applied it to diagnostic data
available for five respiratory viruses co-circulating in a major urban
population between 2005 and 2013: adenovirus, human coronavirus, human
metapneumovirus, influenza B virus and respiratory syncytial virus. We found
positive and negative covariances indicative of epidemiological interactions
among specific virus pairs. This statistical framework enables a community
ecology perspective to be applied to infectious disease epidemiology with
important utility for public health planning and preparedness.
-
In the genomic era, the identification of gene signatures associated with
disease is of significant interest. Such signatures are often used to predict
clinical outcomes in new patients and aid clinical decision-making. However,
recent studies have shown that gene signatures are often not replicable. This
occurrence has practical implications regarding the generalizability and
clinical applicability of such signatures. To improve replicability, we
introduce a novel approach to select gene signatures from multiple datasets
whose effects are consistently non-zero and account for between-study
heterogeneity. We build our model upon some rank-based quantities, facilitating
integration over different genomic datasets. A high dimensional penalized
Generalized Linear Mixed Model (pGLMM) is used to select gene signatures and
address data heterogeneity. We compare our method to some commonly used
strategies that select gene signatures ignoring between-study heterogeneity. We
provide asymptotic results justifying the performance of our method and
demonstrate its advantage in the presence of heterogeneity through thorough
simulation studies. Lastly, we motivate our method through a case study
subtyping pancreatic cancer patients from four gene expression studies.
-
We propose a general framework for nonasymptotic covariance matrix estimation
making use of concentration inequality-based confidence sets. We specify this
framework for the estimation of large sparse covariance matrices through
incorporation of past thresholding estimators with key emphasis on support
recovery. This technique goes beyond past results for thresholding estimators
by allowing for a wide range of distributional assumptions beyond merely
sub-Gaussian tails. This methodology can furthermore be adapted to a wide range
of other estimators and settings. The usage of nonasymptotic dimension-free
confidence sets yields good theoretical performance. Through extensive
simulations, it is demonstrated to have superior performance when compared with
other such methods. In the context of support recovery, we are able to specify
a false positive rate and optimize to maximize the true recoveries.
-
Large-scale multiple testing with highly correlated test statistics arises
frequently in many scientific research. Incorporating correlation information
in estimating false discovery proportion has attracted increasing attention in
recent years. When the covariance matrix of test statistics is known, Fan, Han
& Gu (2012) provided a consistent estimate of False Discovery Proportion (FDP)
under arbitrary dependence structure. However, the covariance matrix is often
unknown in many applications and such dependence information has to be
estimated before estimating FDP (Efron, 2010). The estimation accuracy can
greatly affect the convergence result of FDP or even violate its consistency.
In the current paper, we provide methodological modification and theoretical
investigations for estimation of FDP with unknown covariance. First we develop
requirements for estimates of eigenvalues and eigenvectors such that we can
obtain a consistent estimate of FDP. Secondly we give conditions on the
dependence structures such that the estimate of FDP is consistent. Such
dependence structures include sparse covariance matrices, which have been
popularly considered in the contemporary random matrix theory. When data are
sampled from an approximate factor model, which encompasses most practical
situations, we provide a consistent estimate of FDP via exploiting this
specific dependence structure. The results are further demonstrated by
simulation studies and some real data applications.
-
The literature on regression kink designs develops identification results for
average effects of continuous treatments (Card, Lee, Pei, and Weber, 2015),
average effects of binary treatments (Dong, 2018), and quantile-wise effects of
continuous treatments (Chiang and Sasaki, 2019), but there has been no
identification result for quantile-wise effects of binary treatments to date.
In this paper, we fill this void in the literature by providing an
identification of quantile treatment effects in regression kink designs with
binary treatment variables. For completeness, we also develop large sample
theories for statistical inference and a practical guideline on estimation and
inference.
-
While many statistical models and methods are now available for network
analysis, resampling network data remains a challenging problem.
Cross-validation is a useful general tool for model selection and parameter
tuning, but is not directly applicable to networks since splitting network
nodes into groups requires deleting edges and destroys some of the network
structure. Here we propose a new network resampling strategy based on splitting
node pairs rather than nodes applicable to cross-validation for a wide range of
network model selection tasks. We provide a theoretical justification for our
method in a general setting and examples of how our method can be used in
specific network model selection and parameter tuning tasks. Numerical results
on simulated networks and on a citation network of statisticians show that this
cross-validation approach works well for model selection.
-
In this paper we present a novel inference methodology to perform Bayesian
inference for spatiotemporal Cox processes where the intensity function depends
on a multivariate Gaussian process. Dynamic Gaussian processes are introduced
to allow for evolution of the intensity function over discrete time. The
novelty of the method lies on the fact that no discretisation error is involved
despite the non-tractability of the likelihood function and infinite
dimensionality of the problem. The method is based on a Markov chain Monte
Carlo algorithm that samples from the joint posterior distribution of the
parameters and latent variables of the model. The models are defined in a
general and flexible way but they are amenable to direct sampling from the
relevant distributions, due to careful characterisation of its components. The
models also allow for the inclusion of regression covariates and/or temporal
components to explain the variability of the intensity function. These
components may be subject to relevant interaction with space and/or time. Real
and simulated examples illustrate the methodology, followed by concluding
remarks.
-
There is a growing need for the ability to analyse interval-valued data.
However, existing descriptive frameworks to achieve this ignore the process by
which interval-valued data are typically constructed; namely by the aggregation
of real-valued data generated from some underlying process. In this article we
develop the foundations of likelihood based statistical inference for random
intervals that directly incorporates the underlying generative procedure into
the analysis. That is, it permits the direct fitting of models for the
underlying real-valued data given only the random interval-valued summaries.
This generative approach overcomes several problems associated with existing
methods, including the rarely satisfied assumption of within-interval
uniformity. The new methods are illustrated by simulated and real data
analyses.
-
This paper studies non-separable models with a continuous treatment when the
dimension of the control variables is high and potentially larger than the
effective sample size. We propose a three-step estimation procedure to estimate
the average, quantile, and marginal treatment effects. In the first stage we
estimate the conditional mean, distribution, and density objects by penalized
local least squares, penalized local maximum likelihood estimation, and
numerical differentiation, respectively, where control variables are selected
via a localized method of L1-penalization at each value of the continuous
treatment. In the second stage we estimate the average and marginal
distribution of the potential outcome via the plug-in principle. In the third
stage, we estimate the quantile and marginal treatment effects by inverting the
estimated distribution function and using the local linear regression,
respectively. We study the asymptotic properties of these estimators and
propose a weighted-bootstrap method for inference. Using simulated and real
datasets, we demonstrate that the proposed estimators perform well in finite
samples.
-
We consider joint selection of fixed and random effects in general
mixed-effects models. The interpretation of estimated mixed-effects models is
challenging since changing the structure of one set of effects can lead to
different choices of important covariates in the model. We propose a stepwise
selection algorithm to perform simultaneous selection of the fixed and random
effects. It is based on BIC-type criteria whose penalties are adapted to
mixed-effects models. The proposed procedure performs model selection in both
linear and nonlinear models. It should be used in the low-dimension setting
where the number of covariates and the number of random effects are moderate
with respect to the total number of observations. The performance of the
algorithm is assessed via a simulation study, that includes also a comparative
study with alternatives when available in the literature. The use of the method
is illustrated in the clinical study of an antibiotic agent kinetics.
-
Dimension reduction provides a useful tool for analyzing high dimensional
data. The recently developed \textit{Envelope} method is a parsimonious version
of the classical multivariate regression model through identifying a minimal
reducing subspace of the responses. However, existing envelope methods assume
an independent error structure in the model. While the assumption of
independence is convenient, it does not address the additional complications
associated with spatial or temporal correlations in the data. In this article,
we introduce a \textit{Spatial Envelope} method for dimension reduction in the
presence of dependencies across space. We study the asymptotic properties of
the proposed estimators and show that the asymptotic variance of the estimated
regression coefficients under the spatial envelope model is smaller than that
from the traditional maximum likelihood estimation. Furthermore, we present a
computationally efficient approach for inference. The efficacy of the new
approach is investigated through simulation studies and an analysis of an Air
Quality Standard (AQS) dataset from the Environmental Protection Agency (EPA).
-
Estimation of the number of species or unobserved classes from a random
sample of the underlying population is a ubiquitous problem in statistics. In
classical settings, the size of the sample is usually small. New technologies
such as high-throughput DNA sequencing have allowed for the sampling of
extremely large and heterogeneous populations at scales not previously
attainable or even considered. New algorithms are required that take advantage
of the size of the data to account for heterogeneity, but are also sufficiently
fast and scale well with large data. We present a non-parametric moment-based
estimator that is both computationally efficient and is sufficiently flexible
to account for heterogeneity in the abundances of underlying population. This
estimator is based on an extension of a popular moment-based lower bound (Chao,
1984), originally developed by Harris (1959) but unattainable due to the lack
of economical algorithms to solve the system of nonlinear equation required for
estimation. We apply results from the classical moment problem to show that
solutions can be obtained efficiently, allowing for estimators that are
simultaneously conservative and use more information. This is critical for
modern genomic applications, where there may be many large experiments that
require the application of species estimation. We present applications of our
estimator to estimating T-Cell receptor repertoire and dropout in single cell
RNA-seq experiments.
-
The goal of this paper is to contrast and survey the major advances in two of
the most commonly used high-dimensional techniques, namely, the Lasso and
horseshoe regularization. Lasso is a gold standard for predictor selection
while horseshoe is a state-of-the-art Bayesian estimator for sparse signals.
Lasso is fast and scalable and uses convex optimization whilst the horseshoe is
non-convex. Our novel perspective focuses on three aspects: (i) theoretical
optimality in high dimensional inference for the Gaussian sparse model and
beyond, (ii) efficiency and scalability of computation and (iii) methodological
development and performance.
-
We propose an optimal experimental design for a curvilinear regression model
that minimizes the band-width of simultaneous confidence bands. Simultaneous
confidence bands for curvilinear regression are constructed by evaluating the
volume of a tube about a curve that is defined as a trajectory of a regression
basis vector (Naiman, 1986). The proposed criterion is constructed based on the
volume of a tube, and the corresponding optimal design that minimizes the
volume of tube is referred to as the tube-volume optimal (TV-optimal) design.
For Fourier and weighted polynomial regressions, the problem is formalized as
one of minimization over the cone of Hankel positive definite matrices, and the
criterion to minimize is expressed as an elliptic integral. We show that the
M\"obius group keeps our problem invariant, and hence, minimization can be
conducted over cross-sections of orbits. We demonstrate that for the weighted
polynomial regression and the Fourier regression with three bases, the
tube-volume optimal design forms an orbit of the M\"obius group containing
D-optimal designs as representative elements.
-
In this article, we propose a factor-adjusted multiple testing (FAT)
procedure based on factor-adjusted p-values in a linear factor model involving
some observable and unobservable factors, for the purpose of selecting skilled
funds in empirical finance. The factor-adjusted p-values were obtained after
extracting the latent common factors by the principal component method. Under
some mild conditions, the false discovery proportion can be consistently
estimated even if the idiosyncratic errors are allowed to be weakly correlated
across units. Furthermore, by appropriately setting a sequence of threshold
values approaching zero, the proposed FAT procedure enjoys model selection
consistency. Extensive simulation studies and a real data analysis for
selecting skilled funds in the U.S. financial market are presented to
illustrate the practical utility of the proposed method. Supplementary
materials for this article are available online.
-
Feature selection is a standard approach to understanding and modeling
high-dimensional classification data, but the corresponding statistical methods
hinge on tuning parameters that are difficult to calibrate. In particular,
existing calibration schemes in the logistic regression framework lack any
finite sample guarantees. In this paper, we introduce a novel calibration
scheme for $\ell_1$-penalized logistic regression. It is based on simple tests
along the tuning parameter path and is equipped with optimal guarantees for
feature selection. It is also amenable to easy and efficient implementations,
and it rivals or outmatches existing methods in simulations and real data
applications.
-
Bayesian matrix factorization (BMF) is a powerful tool for producing low-rank
representations of matrices and for predicting missing values and providing
confidence intervals. Scaling up the posterior inference for massive-scale
matrices is challenging and requires distributing both data and computation
over many workers, making communication the main computational bottleneck.
Embarrassingly parallel inference would remove the communication needed, by
using completely independent computations on different data subsets, but it
suffers from the inherent unidentifiability of BMF solutions. We introduce a
hierarchical decomposition of the joint posterior distribution, which couples
the subset inferences, allowing for embarrassingly parallel computations in a
sequence of at most three stages. Using an efficient approximate
implementation, we show improvements empirically on both real and simulated
data. Our distributed approach is able to achieve a speed-up of almost an order
of magnitude over the full posterior, with a negligible effect on predictive
accuracy. Our method outperforms state-of-the-art embarrassingly parallel MCMC
methods in accuracy, and achieves results competitive to other available
distributed and parallel implementations of BMF.
-
We propose new tests for assessing whether covariates in a treatment group
and matched control group are balanced in observational studies. The tests
exhibit high power under a wide range of multivariate alternatives, some of
which existing tests have little power for. The asymptotic permutation null
distributions of the proposed tests are studied and the p-values calculated
through the asymptotic results work well in finite samples, facilitating the
application of the test to large data sets. The tests are illustrated in a
study of the effect of smoking on blood lead levels. The proposed tests are
implemented in an R package BalanceCheck.
-
Bayesian inference for factorial hidden Markov models is challenging due to
the exponentially sized latent variable space. Standard Monte Carlo samplers
can have difficulties effectively exploring the posterior landscape and are
often restricted to exploration around localised regions that depend on
initialisation. We introduce a general purpose ensemble Markov Chain Monte
Carlo (MCMC) technique to improve on existing poorly mixing samplers. This is
achieved by combining parallel tempering and an auxiliary variable scheme to
exchange information between the chains in an efficient way. The latter
exploits a genetic algorithm within an augmented Gibbs sampler. We compare our
technique with various existing samplers in a simulation study as well as in a
cancer genomics application, demonstrating the improvements obtained by our
augmented ensemble approach.
-
We consider the estimation and inference of graphical models that
characterize the dependency structure of high-dimensional tensor-valued data.
To facilitate the estimation of the precision matrix corresponding to each way
of the tensor, we assume the data follow a tensor normal distribution whose
covariance has a Kronecker product structure. A critical challenge in the
estimation and inference of this model is the fact that its penalized maximum
likelihood estimation involves minimizing a non-convex objective function. To
address it, this paper makes two contributions: (i) In spite of the
non-convexity of this estimation problem, we prove that an alternating
minimization algorithm, which iteratively estimates each sparse precision
matrix while fixing the others, attains an estimator with an optimal
statistical rate of convergence. (ii) We propose a de-biased statistical
inference procedure for testing hypotheses on the true support of the sparse
precision matrices, and employ it for testing a growing number of hypothesis
with false discovery rate (FDR) control. The asymptotic normality of our test
statistic and the consistency of FDR control procedure are established. Our
theoretical results are backed up by thorough numerical studies and our real
applications on neuroimaging studies of Autism spectrum disorder and users'
advertising click analysis bring new scientific findings and business insights.
The proposed methods are encoded into a publicly available R package Tlasso.
-
The practical importance of inference with robustness against large
bandwidths for causal effects in regression discontinuity and kink designs is
widely recognized. Existing robust methods cover many cases, but do not handle
uniform inference for CDF and quantile processes in fuzzy designs, despite its
use in the recent literature in empirical microeconomics. In this light, this
paper extends the literature by developing a unified framework of inference
with robustness against large bandwidths that applies to uniform inference for
quantile treatment effects in fuzzy designs, as well as all the other cases of
sharp/fuzzy mean/quantile regression discontinuity/kink designs. We present
Monte Carlo simulation studies and an empirical application for evaluations of
the Oklahoma pre-K program.
-
Statistics derived from the eigenvalues of sample covariance matrices are
called spectral statistics, and they play a central role in multivariate
testing. Although bootstrap methods are an established approach to
approximating the laws of spectral statistics in low-dimensional problems,
these methods are relatively unexplored in the high-dimensional setting. The
aim of this paper is to focus on linear spectral statistics as a class of
prototypes for developing a new bootstrap in high-dimensions --- and we refer
to this method as the Spectral Bootstrap. In essence, the method originates
from the parametric bootstrap, and is motivated by the notion that, in high
dimensions, it is difficult to obtain a non-parametric approximation to the
full data-generating distribution. From a practical standpoint, the method is
easy to use, and allows the user to circumvent the difficulties of complex
asymptotic formulas for linear spectral statistics. In addition to proving the
consistency of the proposed method, we provide encouraging empirical results in
a variety of settings. Lastly, and perhaps most interestingly, we show through
simulations that the method can be applied successfully to statistics outside
the class of linear spectral statistics, such as the largest sample eigenvalue
and others.
-
Consider the problem of modeling memory effects in discrete-state random
walks using higher-order Markov chains. This paper explores cross validation
and information criteria as proxies for a model's predictive accuracy. Our
objective is to select, from data, the number of prior states of recent history
upon which a trajectory is statistically dependent. Through simulations, I
evaluate these criteria in the case where data are drawn from systems with
fixed orders of history, noting trends in the relative performance of the
criteria. As a real-world illustrative example of these methods, this
manuscript evaluates the problem of detecting statistical dependencies in shot
outcomes in free throw shooting. Over three NBA seasons analyzed, several
players exhibited statistical dependencies in free throw hitting probability of
various types - hot handedness, cold handedness, and error correction. For the
2013-2014 through 2015-2016 NBA seasons, I detected statistical dependencies in
23% of all player-seasons. Focusing on a single player, in two of these three
seasons, LeBron James shot a better percentage after an immediate miss than
otherwise. In those seasons, conditioning on the previous outcome makes for a
more predictive model than treating free throw makes as independent. When
extended to data from the 2016-2017 NBA season specifically for LeBron James, a
model depending on the previous shot (single-step Markovian) does not clearly
beat a model with independent outcomes. An error-correcting variable length
model of two parameters, where James shoots a higher percentage after a missed
free throw than otherwise, is more predictive than either model.
-
The spectral distribution $f(\omega)$ of a stationary time series
$\{Y_t\}_{t\in\mathbb{Z}}$ can be used to investigate whether or not periodic
structures are present in $\{Y_t\}_{t\in\mathbb{Z}}$, but $f(\omega)$ has some
limitations due to its dependence on the autocovariances $\gamma(h)$. For
example, $f(\omega)$ can not distinguish white i.i.d. noise from GARCH-type
models (whose terms are dependent, but uncorrelated), which implies that
$f(\omega)$ can be an inadequate tool when $\{Y_t\}_{t\in\mathbb{Z}}$ contains
asymmetries and nonlinear dependencies.
Asymmetries between the upper and lower tails of a time series can be
investigated by means of the local Gaussian autocorrelations introduced in
Tj{\o}stheim and Hufthammer (2013), and these local measures of dependence can
be used to construct the local Gaussian spectral density presented in this
paper. A key feature of the new local spectral density is that it coincides
with $f(\omega)$ for Gaussian time series, which implies that it can be used to
detect non-Gaussian traits in the time series under investigation. In
particular, if $f(\omega)$ is flat, then peaks and troughs of the new local
spectral density can indicate nonlinear traits, which potentially might
discover local periodic phenomena that remain undetected in an ordinary
spectral analysis.
-
Hypothesis testing in the linear regression model is a fundamental
statistical problem. We consider linear regression in the high-dimensional
regime where the number of parameters exceeds the number of samples ($p> n$).
In order to make informative inference, we assume that the model is
approximately sparse, that is the effect of covariates on the response can be
well approximated by conditioning on a relatively small number of covariates
whose identities are unknown. We develop a framework for testing very general
hypotheses regarding the model parameters. Our framework encompasses testing
whether the parameter lies in a convex cone, testing the signal strength, and
testing arbitrary functionals of the parameter. We show that the proposed
procedure controls the type I error, and also analyze the power of the
procedure. Our numerical experiments confirm our theoretical findings and
demonstrate that we control false positive rate (type I error) near the nominal
level, and have high power. By duality between hypotheses testing and
confidence intervals, the proposed framework can be used to obtain valid
confidence intervals for various functionals of the model parameters. For
linear functionals, the length of confidence intervals is shown to be minimax
rate optimal.



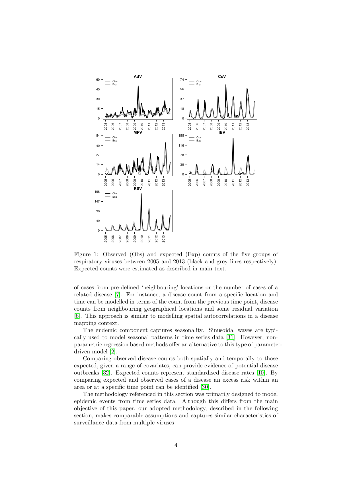

 It is well recognised that animal and plant pathogens form complex ecological communities of interacting organisms within their hosts. Although community ecology approaches have been applied to determine pathogen interactions at the within-host scale, methodologies enabling robust inference of the epidemiological impact of pathogen interactions are lacking. Here we developed a novel statistical framework to identify statistical covariances from the infection time-series of multiple pathogens simultaneously. Our framework extends Bayesian multivariate disease mapping models to analyse multivariate time series data by accounting for within- and between-year dependencies in infection risk and incorporating a between-pathogen covariance matrix which we estimate. Importantly, our approach accounts for possible confounding drivers of temporal patterns in pathogen infection frequencies, enabling robust inference of pathogen-pathogen interactions. We illustrate the validity of our statistical framework using simulated data and applied it to diagnostic data available for five respiratory viruses co-circulating in a major urban population between 2005 and 2013: adenovirus, human coronavirus, human metapneumovirus, influenza B virus and respiratory syncytial virus. We found positive and negative covariances indicative of epidemiological interactions among specific virus pairs. This statistical framework enables a community ecology perspective to be applied to infectious disease epidemiology with important utility for public health planning and preparedness.
It is well recognised that animal and plant pathogens form complex ecological communities of interacting organisms within their hosts. Although community ecology approaches have been applied to determine pathogen interactions at the within-host scale, methodologies enabling robust inference of the epidemiological impact of pathogen interactions are lacking. Here we developed a novel statistical framework to identify statistical covariances from the infection time-series of multiple pathogens simultaneously. Our framework extends Bayesian multivariate disease mapping models to analyse multivariate time series data by accounting for within- and between-year dependencies in infection risk and incorporating a between-pathogen covariance matrix which we estimate. Importantly, our approach accounts for possible confounding drivers of temporal patterns in pathogen infection frequencies, enabling robust inference of pathogen-pathogen interactions. We illustrate the validity of our statistical framework using simulated data and applied it to diagnostic data available for five respiratory viruses co-circulating in a major urban population between 2005 and 2013: adenovirus, human coronavirus, human metapneumovirus, influenza B virus and respiratory syncytial virus. We found positive and negative covariances indicative of epidemiological interactions among specific virus pairs. This statistical framework enables a community ecology perspective to be applied to infectious disease epidemiology with important utility for public health planning and preparedness.




 In the genomic era, the identification of gene signatures associated with disease is of significant interest. Such signatures are often used to predict clinical outcomes in new patients and aid clinical decision-making. However, recent studies have shown that gene signatures are often not replicable. This occurrence has practical implications regarding the generalizability and clinical applicability of such signatures. To improve replicability, we introduce a novel approach to select gene signatures from multiple datasets whose effects are consistently non-zero and account for between-study heterogeneity. We build our model upon some rank-based quantities, facilitating integration over different genomic datasets. A high dimensional penalized Generalized Linear Mixed Model (pGLMM) is used to select gene signatures and address data heterogeneity. We compare our method to some commonly used strategies that select gene signatures ignoring between-study heterogeneity. We provide asymptotic results justifying the performance of our method and demonstrate its advantage in the presence of heterogeneity through thorough simulation studies. Lastly, we motivate our method through a case study subtyping pancreatic cancer patients from four gene expression studies.
In the genomic era, the identification of gene signatures associated with disease is of significant interest. Such signatures are often used to predict clinical outcomes in new patients and aid clinical decision-making. However, recent studies have shown that gene signatures are often not replicable. This occurrence has practical implications regarding the generalizability and clinical applicability of such signatures. To improve replicability, we introduce a novel approach to select gene signatures from multiple datasets whose effects are consistently non-zero and account for between-study heterogeneity. We build our model upon some rank-based quantities, facilitating integration over different genomic datasets. A high dimensional penalized Generalized Linear Mixed Model (pGLMM) is used to select gene signatures and address data heterogeneity. We compare our method to some commonly used strategies that select gene signatures ignoring between-study heterogeneity. We provide asymptotic results justifying the performance of our method and demonstrate its advantage in the presence of heterogeneity through thorough simulation studies. Lastly, we motivate our method through a case study subtyping pancreatic cancer patients from four gene expression studies.




 We propose a general framework for nonasymptotic covariance matrix estimation making use of concentration inequality-based confidence sets. We specify this framework for the estimation of large sparse covariance matrices through incorporation of past thresholding estimators with key emphasis on support recovery. This technique goes beyond past results for thresholding estimators by allowing for a wide range of distributional assumptions beyond merely sub-Gaussian tails. This methodology can furthermore be adapted to a wide range of other estimators and settings. The usage of nonasymptotic dimension-free confidence sets yields good theoretical performance. Through extensive simulations, it is demonstrated to have superior performance when compared with other such methods. In the context of support recovery, we are able to specify a false positive rate and optimize to maximize the true recoveries.
We propose a general framework for nonasymptotic covariance matrix estimation making use of concentration inequality-based confidence sets. We specify this framework for the estimation of large sparse covariance matrices through incorporation of past thresholding estimators with key emphasis on support recovery. This technique goes beyond past results for thresholding estimators by allowing for a wide range of distributional assumptions beyond merely sub-Gaussian tails. This methodology can furthermore be adapted to a wide range of other estimators and settings. The usage of nonasymptotic dimension-free confidence sets yields good theoretical performance. Through extensive simulations, it is demonstrated to have superior performance when compared with other such methods. In the context of support recovery, we are able to specify a false positive rate and optimize to maximize the true recoveries.




 Large-scale multiple testing with highly correlated test statistics arises frequently in many scientific research. Incorporating correlation information in estimating false discovery proportion has attracted increasing attention in recent years. When the covariance matrix of test statistics is known, Fan, Han & Gu (2012) provided a consistent estimate of False Discovery Proportion (FDP) under arbitrary dependence structure. However, the covariance matrix is often unknown in many applications and such dependence information has to be estimated before estimating FDP (Efron, 2010). The estimation accuracy can greatly affect the convergence result of FDP or even violate its consistency. In the current paper, we provide methodological modification and theoretical investigations for estimation of FDP with unknown covariance. First we develop requirements for estimates of eigenvalues and eigenvectors such that we can obtain a consistent estimate of FDP. Secondly we give conditions on the dependence structures such that the estimate of FDP is consistent. Such dependence structures include sparse covariance matrices, which have been popularly considered in the contemporary random matrix theory. When data are sampled from an approximate factor model, which encompasses most practical situations, we provide a consistent estimate of FDP via exploiting this specific dependence structure. The results are further demonstrated by simulation studies and some real data applications.
Large-scale multiple testing with highly correlated test statistics arises frequently in many scientific research. Incorporating correlation information in estimating false discovery proportion has attracted increasing attention in recent years. When the covariance matrix of test statistics is known, Fan, Han & Gu (2012) provided a consistent estimate of False Discovery Proportion (FDP) under arbitrary dependence structure. However, the covariance matrix is often unknown in many applications and such dependence information has to be estimated before estimating FDP (Efron, 2010). The estimation accuracy can greatly affect the convergence result of FDP or even violate its consistency. In the current paper, we provide methodological modification and theoretical investigations for estimation of FDP with unknown covariance. First we develop requirements for estimates of eigenvalues and eigenvectors such that we can obtain a consistent estimate of FDP. Secondly we give conditions on the dependence structures such that the estimate of FDP is consistent. Such dependence structures include sparse covariance matrices, which have been popularly considered in the contemporary random matrix theory. When data are sampled from an approximate factor model, which encompasses most practical situations, we provide a consistent estimate of FDP via exploiting this specific dependence structure. The results are further demonstrated by simulation studies and some real data applications.




 The literature on regression kink designs develops identification results for average effects of continuous treatments (Card, Lee, Pei, and Weber, 2015), average effects of binary treatments (Dong, 2018), and quantile-wise effects of continuous treatments (Chiang and Sasaki, 2019), but there has been no identification result for quantile-wise effects of binary treatments to date. In this paper, we fill this void in the literature by providing an identification of quantile treatment effects in regression kink designs with binary treatment variables. For completeness, we also develop large sample theories for statistical inference and a practical guideline on estimation and inference.
The literature on regression kink designs develops identification results for average effects of continuous treatments (Card, Lee, Pei, and Weber, 2015), average effects of binary treatments (Dong, 2018), and quantile-wise effects of continuous treatments (Chiang and Sasaki, 2019), but there has been no identification result for quantile-wise effects of binary treatments to date. In this paper, we fill this void in the literature by providing an identification of quantile treatment effects in regression kink designs with binary treatment variables. For completeness, we also develop large sample theories for statistical inference and a practical guideline on estimation and inference.




 While many statistical models and methods are now available for network analysis, resampling network data remains a challenging problem. Cross-validation is a useful general tool for model selection and parameter tuning, but is not directly applicable to networks since splitting network nodes into groups requires deleting edges and destroys some of the network structure. Here we propose a new network resampling strategy based on splitting node pairs rather than nodes applicable to cross-validation for a wide range of network model selection tasks. We provide a theoretical justification for our method in a general setting and examples of how our method can be used in specific network model selection and parameter tuning tasks. Numerical results on simulated networks and on a citation network of statisticians show that this cross-validation approach works well for model selection.
While many statistical models and methods are now available for network analysis, resampling network data remains a challenging problem. Cross-validation is a useful general tool for model selection and parameter tuning, but is not directly applicable to networks since splitting network nodes into groups requires deleting edges and destroys some of the network structure. Here we propose a new network resampling strategy based on splitting node pairs rather than nodes applicable to cross-validation for a wide range of network model selection tasks. We provide a theoretical justification for our method in a general setting and examples of how our method can be used in specific network model selection and parameter tuning tasks. Numerical results on simulated networks and on a citation network of statisticians show that this cross-validation approach works well for model selection.




 In this paper we present a novel inference methodology to perform Bayesian inference for spatiotemporal Cox processes where the intensity function depends on a multivariate Gaussian process. Dynamic Gaussian processes are introduced to allow for evolution of the intensity function over discrete time. The novelty of the method lies on the fact that no discretisation error is involved despite the non-tractability of the likelihood function and infinite dimensionality of the problem. The method is based on a Markov chain Monte Carlo algorithm that samples from the joint posterior distribution of the parameters and latent variables of the model. The models are defined in a general and flexible way but they are amenable to direct sampling from the relevant distributions, due to careful characterisation of its components. The models also allow for the inclusion of regression covariates and/or temporal components to explain the variability of the intensity function. These components may be subject to relevant interaction with space and/or time. Real and simulated examples illustrate the methodology, followed by concluding remarks.
In this paper we present a novel inference methodology to perform Bayesian inference for spatiotemporal Cox processes where the intensity function depends on a multivariate Gaussian process. Dynamic Gaussian processes are introduced to allow for evolution of the intensity function over discrete time. The novelty of the method lies on the fact that no discretisation error is involved despite the non-tractability of the likelihood function and infinite dimensionality of the problem. The method is based on a Markov chain Monte Carlo algorithm that samples from the joint posterior distribution of the parameters and latent variables of the model. The models are defined in a general and flexible way but they are amenable to direct sampling from the relevant distributions, due to careful characterisation of its components. The models also allow for the inclusion of regression covariates and/or temporal components to explain the variability of the intensity function. These components may be subject to relevant interaction with space and/or time. Real and simulated examples illustrate the methodology, followed by concluding remarks.




 There is a growing need for the ability to analyse interval-valued data. However, existing descriptive frameworks to achieve this ignore the process by which interval-valued data are typically constructed; namely by the aggregation of real-valued data generated from some underlying process. In this article we develop the foundations of likelihood based statistical inference for random intervals that directly incorporates the underlying generative procedure into the analysis. That is, it permits the direct fitting of models for the underlying real-valued data given only the random interval-valued summaries. This generative approach overcomes several problems associated with existing methods, including the rarely satisfied assumption of within-interval uniformity. The new methods are illustrated by simulated and real data analyses.
There is a growing need for the ability to analyse interval-valued data. However, existing descriptive frameworks to achieve this ignore the process by which interval-valued data are typically constructed; namely by the aggregation of real-valued data generated from some underlying process. In this article we develop the foundations of likelihood based statistical inference for random intervals that directly incorporates the underlying generative procedure into the analysis. That is, it permits the direct fitting of models for the underlying real-valued data given only the random interval-valued summaries. This generative approach overcomes several problems associated with existing methods, including the rarely satisfied assumption of within-interval uniformity. The new methods are illustrated by simulated and real data analyses.




 This paper studies non-separable models with a continuous treatment when the dimension of the control variables is high and potentially larger than the effective sample size. We propose a three-step estimation procedure to estimate the average, quantile, and marginal treatment effects. In the first stage we estimate the conditional mean, distribution, and density objects by penalized local least squares, penalized local maximum likelihood estimation, and numerical differentiation, respectively, where control variables are selected via a localized method of L1-penalization at each value of the continuous treatment. In the second stage we estimate the average and marginal distribution of the potential outcome via the plug-in principle. In the third stage, we estimate the quantile and marginal treatment effects by inverting the estimated distribution function and using the local linear regression, respectively. We study the asymptotic properties of these estimators and propose a weighted-bootstrap method for inference. Using simulated and real datasets, we demonstrate that the proposed estimators perform well in finite samples.
This paper studies non-separable models with a continuous treatment when the dimension of the control variables is high and potentially larger than the effective sample size. We propose a three-step estimation procedure to estimate the average, quantile, and marginal treatment effects. In the first stage we estimate the conditional mean, distribution, and density objects by penalized local least squares, penalized local maximum likelihood estimation, and numerical differentiation, respectively, where control variables are selected via a localized method of L1-penalization at each value of the continuous treatment. In the second stage we estimate the average and marginal distribution of the potential outcome via the plug-in principle. In the third stage, we estimate the quantile and marginal treatment effects by inverting the estimated distribution function and using the local linear regression, respectively. We study the asymptotic properties of these estimators and propose a weighted-bootstrap method for inference. Using simulated and real datasets, we demonstrate that the proposed estimators perform well in finite samples.




 We consider joint selection of fixed and random effects in general mixed-effects models. The interpretation of estimated mixed-effects models is challenging since changing the structure of one set of effects can lead to different choices of important covariates in the model. We propose a stepwise selection algorithm to perform simultaneous selection of the fixed and random effects. It is based on BIC-type criteria whose penalties are adapted to mixed-effects models. The proposed procedure performs model selection in both linear and nonlinear models. It should be used in the low-dimension setting where the number of covariates and the number of random effects are moderate with respect to the total number of observations. The performance of the algorithm is assessed via a simulation study, that includes also a comparative study with alternatives when available in the literature. The use of the method is illustrated in the clinical study of an antibiotic agent kinetics.
We consider joint selection of fixed and random effects in general mixed-effects models. The interpretation of estimated mixed-effects models is challenging since changing the structure of one set of effects can lead to different choices of important covariates in the model. We propose a stepwise selection algorithm to perform simultaneous selection of the fixed and random effects. It is based on BIC-type criteria whose penalties are adapted to mixed-effects models. The proposed procedure performs model selection in both linear and nonlinear models. It should be used in the low-dimension setting where the number of covariates and the number of random effects are moderate with respect to the total number of observations. The performance of the algorithm is assessed via a simulation study, that includes also a comparative study with alternatives when available in the literature. The use of the method is illustrated in the clinical study of an antibiotic agent kinetics.




 Dimension reduction provides a useful tool for analyzing high dimensional data. The recently developed \textit{Envelope} method is a parsimonious version of the classical multivariate regression model through identifying a minimal reducing subspace of the responses. However, existing envelope methods assume an independent error structure in the model. While the assumption of independence is convenient, it does not address the additional complications associated with spatial or temporal correlations in the data. In this article, we introduce a \textit{Spatial Envelope} method for dimension reduction in the presence of dependencies across space. We study the asymptotic properties of the proposed estimators and show that the asymptotic variance of the estimated regression coefficients under the spatial envelope model is smaller than that from the traditional maximum likelihood estimation. Furthermore, we present a computationally efficient approach for inference. The efficacy of the new approach is investigated through simulation studies and an analysis of an Air Quality Standard (AQS) dataset from the Environmental Protection Agency (EPA).
Dimension reduction provides a useful tool for analyzing high dimensional data. The recently developed \textit{Envelope} method is a parsimonious version of the classical multivariate regression model through identifying a minimal reducing subspace of the responses. However, existing envelope methods assume an independent error structure in the model. While the assumption of independence is convenient, it does not address the additional complications associated with spatial or temporal correlations in the data. In this article, we introduce a \textit{Spatial Envelope} method for dimension reduction in the presence of dependencies across space. We study the asymptotic properties of the proposed estimators and show that the asymptotic variance of the estimated regression coefficients under the spatial envelope model is smaller than that from the traditional maximum likelihood estimation. Furthermore, we present a computationally efficient approach for inference. The efficacy of the new approach is investigated through simulation studies and an analysis of an Air Quality Standard (AQS) dataset from the Environmental Protection Agency (EPA).




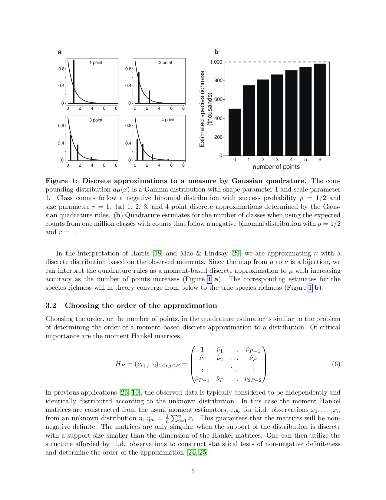 Estimation of the number of species or unobserved classes from a random sample of the underlying population is a ubiquitous problem in statistics. In classical settings, the size of the sample is usually small. New technologies such as high-throughput DNA sequencing have allowed for the sampling of extremely large and heterogeneous populations at scales not previously attainable or even considered. New algorithms are required that take advantage of the size of the data to account for heterogeneity, but are also sufficiently fast and scale well with large data. We present a non-parametric moment-based estimator that is both computationally efficient and is sufficiently flexible to account for heterogeneity in the abundances of underlying population. This estimator is based on an extension of a popular moment-based lower bound (Chao, 1984), originally developed by Harris (1959) but unattainable due to the lack of economical algorithms to solve the system of nonlinear equation required for estimation. We apply results from the classical moment problem to show that solutions can be obtained efficiently, allowing for estimators that are simultaneously conservative and use more information. This is critical for modern genomic applications, where there may be many large experiments that require the application of species estimation. We present applications of our estimator to estimating T-Cell receptor repertoire and dropout in single cell RNA-seq experiments.
Estimation of the number of species or unobserved classes from a random sample of the underlying population is a ubiquitous problem in statistics. In classical settings, the size of the sample is usually small. New technologies such as high-throughput DNA sequencing have allowed for the sampling of extremely large and heterogeneous populations at scales not previously attainable or even considered. New algorithms are required that take advantage of the size of the data to account for heterogeneity, but are also sufficiently fast and scale well with large data. We present a non-parametric moment-based estimator that is both computationally efficient and is sufficiently flexible to account for heterogeneity in the abundances of underlying population. This estimator is based on an extension of a popular moment-based lower bound (Chao, 1984), originally developed by Harris (1959) but unattainable due to the lack of economical algorithms to solve the system of nonlinear equation required for estimation. We apply results from the classical moment problem to show that solutions can be obtained efficiently, allowing for estimators that are simultaneously conservative and use more information. This is critical for modern genomic applications, where there may be many large experiments that require the application of species estimation. We present applications of our estimator to estimating T-Cell receptor repertoire and dropout in single cell RNA-seq experiments.




 The goal of this paper is to contrast and survey the major advances in two of the most commonly used high-dimensional techniques, namely, the Lasso and horseshoe regularization. Lasso is a gold standard for predictor selection while horseshoe is a state-of-the-art Bayesian estimator for sparse signals. Lasso is fast and scalable and uses convex optimization whilst the horseshoe is non-convex. Our novel perspective focuses on three aspects: (i) theoretical optimality in high dimensional inference for the Gaussian sparse model and beyond, (ii) efficiency and scalability of computation and (iii) methodological development and performance.
The goal of this paper is to contrast and survey the major advances in two of the most commonly used high-dimensional techniques, namely, the Lasso and horseshoe regularization. Lasso is a gold standard for predictor selection while horseshoe is a state-of-the-art Bayesian estimator for sparse signals. Lasso is fast and scalable and uses convex optimization whilst the horseshoe is non-convex. Our novel perspective focuses on three aspects: (i) theoretical optimality in high dimensional inference for the Gaussian sparse model and beyond, (ii) efficiency and scalability of computation and (iii) methodological development and performance.




 We propose an optimal experimental design for a curvilinear regression model that minimizes the band-width of simultaneous confidence bands. Simultaneous confidence bands for curvilinear regression are constructed by evaluating the volume of a tube about a curve that is defined as a trajectory of a regression basis vector (Naiman, 1986). The proposed criterion is constructed based on the volume of a tube, and the corresponding optimal design that minimizes the volume of tube is referred to as the tube-volume optimal (TV-optimal) design. For Fourier and weighted polynomial regressions, the problem is formalized as one of minimization over the cone of Hankel positive definite matrices, and the criterion to minimize is expressed as an elliptic integral. We show that the M\"obius group keeps our problem invariant, and hence, minimization can be conducted over cross-sections of orbits. We demonstrate that for the weighted polynomial regression and the Fourier regression with three bases, the tube-volume optimal design forms an orbit of the M\"obius group containing D-optimal designs as representative elements.
We propose an optimal experimental design for a curvilinear regression model that minimizes the band-width of simultaneous confidence bands. Simultaneous confidence bands for curvilinear regression are constructed by evaluating the volume of a tube about a curve that is defined as a trajectory of a regression basis vector (Naiman, 1986). The proposed criterion is constructed based on the volume of a tube, and the corresponding optimal design that minimizes the volume of tube is referred to as the tube-volume optimal (TV-optimal) design. For Fourier and weighted polynomial regressions, the problem is formalized as one of minimization over the cone of Hankel positive definite matrices, and the criterion to minimize is expressed as an elliptic integral. We show that the M\"obius group keeps our problem invariant, and hence, minimization can be conducted over cross-sections of orbits. We demonstrate that for the weighted polynomial regression and the Fourier regression with three bases, the tube-volume optimal design forms an orbit of the M\"obius group containing D-optimal designs as representative elements.




 In this article, we propose a factor-adjusted multiple testing (FAT) procedure based on factor-adjusted p-values in a linear factor model involving some observable and unobservable factors, for the purpose of selecting skilled funds in empirical finance. The factor-adjusted p-values were obtained after extracting the latent common factors by the principal component method. Under some mild conditions, the false discovery proportion can be consistently estimated even if the idiosyncratic errors are allowed to be weakly correlated across units. Furthermore, by appropriately setting a sequence of threshold values approaching zero, the proposed FAT procedure enjoys model selection consistency. Extensive simulation studies and a real data analysis for selecting skilled funds in the U.S. financial market are presented to illustrate the practical utility of the proposed method. Supplementary materials for this article are available online.
In this article, we propose a factor-adjusted multiple testing (FAT) procedure based on factor-adjusted p-values in a linear factor model involving some observable and unobservable factors, for the purpose of selecting skilled funds in empirical finance. The factor-adjusted p-values were obtained after extracting the latent common factors by the principal component method. Under some mild conditions, the false discovery proportion can be consistently estimated even if the idiosyncratic errors are allowed to be weakly correlated across units. Furthermore, by appropriately setting a sequence of threshold values approaching zero, the proposed FAT procedure enjoys model selection consistency. Extensive simulation studies and a real data analysis for selecting skilled funds in the U.S. financial market are presented to illustrate the practical utility of the proposed method. Supplementary materials for this article are available online.




 Feature selection is a standard approach to understanding and modeling high-dimensional classification data, but the corresponding statistical methods hinge on tuning parameters that are difficult to calibrate. In particular, existing calibration schemes in the logistic regression framework lack any finite sample guarantees. In this paper, we introduce a novel calibration scheme for $\ell_1$-penalized logistic regression. It is based on simple tests along the tuning parameter path and is equipped with optimal guarantees for feature selection. It is also amenable to easy and efficient implementations, and it rivals or outmatches existing methods in simulations and real data applications.
Feature selection is a standard approach to understanding and modeling high-dimensional classification data, but the corresponding statistical methods hinge on tuning parameters that are difficult to calibrate. In particular, existing calibration schemes in the logistic regression framework lack any finite sample guarantees. In this paper, we introduce a novel calibration scheme for $\ell_1$-penalized logistic regression. It is based on simple tests along the tuning parameter path and is equipped with optimal guarantees for feature selection. It is also amenable to easy and efficient implementations, and it rivals or outmatches existing methods in simulations and real data applications.




 Bayesian matrix factorization (BMF) is a powerful tool for producing low-rank representations of matrices and for predicting missing values and providing confidence intervals. Scaling up the posterior inference for massive-scale matrices is challenging and requires distributing both data and computation over many workers, making communication the main computational bottleneck. Embarrassingly parallel inference would remove the communication needed, by using completely independent computations on different data subsets, but it suffers from the inherent unidentifiability of BMF solutions. We introduce a hierarchical decomposition of the joint posterior distribution, which couples the subset inferences, allowing for embarrassingly parallel computations in a sequence of at most three stages. Using an efficient approximate implementation, we show improvements empirically on both real and simulated data. Our distributed approach is able to achieve a speed-up of almost an order of magnitude over the full posterior, with a negligible effect on predictive accuracy. Our method outperforms state-of-the-art embarrassingly parallel MCMC methods in accuracy, and achieves results competitive to other available distributed and parallel implementations of BMF.
Bayesian matrix factorization (BMF) is a powerful tool for producing low-rank representations of matrices and for predicting missing values and providing confidence intervals. Scaling up the posterior inference for massive-scale matrices is challenging and requires distributing both data and computation over many workers, making communication the main computational bottleneck. Embarrassingly parallel inference would remove the communication needed, by using completely independent computations on different data subsets, but it suffers from the inherent unidentifiability of BMF solutions. We introduce a hierarchical decomposition of the joint posterior distribution, which couples the subset inferences, allowing for embarrassingly parallel computations in a sequence of at most three stages. Using an efficient approximate implementation, we show improvements empirically on both real and simulated data. Our distributed approach is able to achieve a speed-up of almost an order of magnitude over the full posterior, with a negligible effect on predictive accuracy. Our method outperforms state-of-the-art embarrassingly parallel MCMC methods in accuracy, and achieves results competitive to other available distributed and parallel implementations of BMF.




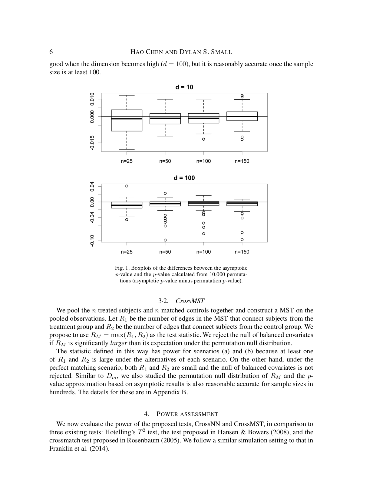 We propose new tests for assessing whether covariates in a treatment group and matched control group are balanced in observational studies. The tests exhibit high power under a wide range of multivariate alternatives, some of which existing tests have little power for. The asymptotic permutation null distributions of the proposed tests are studied and the p-values calculated through the asymptotic results work well in finite samples, facilitating the application of the test to large data sets. The tests are illustrated in a study of the effect of smoking on blood lead levels. The proposed tests are implemented in an R package BalanceCheck.
We propose new tests for assessing whether covariates in a treatment group and matched control group are balanced in observational studies. The tests exhibit high power under a wide range of multivariate alternatives, some of which existing tests have little power for. The asymptotic permutation null distributions of the proposed tests are studied and the p-values calculated through the asymptotic results work well in finite samples, facilitating the application of the test to large data sets. The tests are illustrated in a study of the effect of smoking on blood lead levels. The proposed tests are implemented in an R package BalanceCheck.




 Bayesian inference for factorial hidden Markov models is challenging due to the exponentially sized latent variable space. Standard Monte Carlo samplers can have difficulties effectively exploring the posterior landscape and are often restricted to exploration around localised regions that depend on initialisation. We introduce a general purpose ensemble Markov Chain Monte Carlo (MCMC) technique to improve on existing poorly mixing samplers. This is achieved by combining parallel tempering and an auxiliary variable scheme to exchange information between the chains in an efficient way. The latter exploits a genetic algorithm within an augmented Gibbs sampler. We compare our technique with various existing samplers in a simulation study as well as in a cancer genomics application, demonstrating the improvements obtained by our augmented ensemble approach.
Bayesian inference for factorial hidden Markov models is challenging due to the exponentially sized latent variable space. Standard Monte Carlo samplers can have difficulties effectively exploring the posterior landscape and are often restricted to exploration around localised regions that depend on initialisation. We introduce a general purpose ensemble Markov Chain Monte Carlo (MCMC) technique to improve on existing poorly mixing samplers. This is achieved by combining parallel tempering and an auxiliary variable scheme to exchange information between the chains in an efficient way. The latter exploits a genetic algorithm within an augmented Gibbs sampler. We compare our technique with various existing samplers in a simulation study as well as in a cancer genomics application, demonstrating the improvements obtained by our augmented ensemble approach.




 We consider the estimation and inference of graphical models that characterize the dependency structure of high-dimensional tensor-valued data. To facilitate the estimation of the precision matrix corresponding to each way of the tensor, we assume the data follow a tensor normal distribution whose covariance has a Kronecker product structure. A critical challenge in the estimation and inference of this model is the fact that its penalized maximum likelihood estimation involves minimizing a non-convex objective function. To address it, this paper makes two contributions: (i) In spite of the non-convexity of this estimation problem, we prove that an alternating minimization algorithm, which iteratively estimates each sparse precision matrix while fixing the others, attains an estimator with an optimal statistical rate of convergence. (ii) We propose a de-biased statistical inference procedure for testing hypotheses on the true support of the sparse precision matrices, and employ it for testing a growing number of hypothesis with false discovery rate (FDR) control. The asymptotic normality of our test statistic and the consistency of FDR control procedure are established. Our theoretical results are backed up by thorough numerical studies and our real applications on neuroimaging studies of Autism spectrum disorder and users' advertising click analysis bring new scientific findings and business insights. The proposed methods are encoded into a publicly available R package Tlasso.
We consider the estimation and inference of graphical models that characterize the dependency structure of high-dimensional tensor-valued data. To facilitate the estimation of the precision matrix corresponding to each way of the tensor, we assume the data follow a tensor normal distribution whose covariance has a Kronecker product structure. A critical challenge in the estimation and inference of this model is the fact that its penalized maximum likelihood estimation involves minimizing a non-convex objective function. To address it, this paper makes two contributions: (i) In spite of the non-convexity of this estimation problem, we prove that an alternating minimization algorithm, which iteratively estimates each sparse precision matrix while fixing the others, attains an estimator with an optimal statistical rate of convergence. (ii) We propose a de-biased statistical inference procedure for testing hypotheses on the true support of the sparse precision matrices, and employ it for testing a growing number of hypothesis with false discovery rate (FDR) control. The asymptotic normality of our test statistic and the consistency of FDR control procedure are established. Our theoretical results are backed up by thorough numerical studies and our real applications on neuroimaging studies of Autism spectrum disorder and users' advertising click analysis bring new scientific findings and business insights. The proposed methods are encoded into a publicly available R package Tlasso.




 The practical importance of inference with robustness against large bandwidths for causal effects in regression discontinuity and kink designs is widely recognized. Existing robust methods cover many cases, but do not handle uniform inference for CDF and quantile processes in fuzzy designs, despite its use in the recent literature in empirical microeconomics. In this light, this paper extends the literature by developing a unified framework of inference with robustness against large bandwidths that applies to uniform inference for quantile treatment effects in fuzzy designs, as well as all the other cases of sharp/fuzzy mean/quantile regression discontinuity/kink designs. We present Monte Carlo simulation studies and an empirical application for evaluations of the Oklahoma pre-K program.
The practical importance of inference with robustness against large bandwidths for causal effects in regression discontinuity and kink designs is widely recognized. Existing robust methods cover many cases, but do not handle uniform inference for CDF and quantile processes in fuzzy designs, despite its use in the recent literature in empirical microeconomics. In this light, this paper extends the literature by developing a unified framework of inference with robustness against large bandwidths that applies to uniform inference for quantile treatment effects in fuzzy designs, as well as all the other cases of sharp/fuzzy mean/quantile regression discontinuity/kink designs. We present Monte Carlo simulation studies and an empirical application for evaluations of the Oklahoma pre-K program.




 The spectral distribution $f(\omega)$ of a stationary time series $\{Y_t\}_{t\in\mathbb{Z}}$ can be used to investigate whether or not periodic structures are present in $\{Y_t\}_{t\in\mathbb{Z}}$, but $f(\omega)$ has some limitations due to its dependence on the autocovariances $\gamma(h)$. For example, $f(\omega)$ can not distinguish white i.i.d. noise from GARCH-type models (whose terms are dependent, but uncorrelated), which implies that $f(\omega)$ can be an inadequate tool when $\{Y_t\}_{t\in\mathbb{Z}}$ contains asymmetries and nonlinear dependencies. Asymmetries between the upper and lower tails of a time series can be investigated by means of the local Gaussian autocorrelations introduced in Tj{\o}stheim and Hufthammer (2013), and these local measures of dependence can be used to construct the local Gaussian spectral density presented in this paper. A key feature of the new local spectral density is that it coincides with $f(\omega)$ for Gaussian time series, which implies that it can be used to detect non-Gaussian traits in the time series under investigation. In particular, if $f(\omega)$ is flat, then peaks and troughs of the new local spectral density can indicate nonlinear traits, which potentially might discover local periodic phenomena that remain undetected in an ordinary spectral analysis.
The spectral distribution $f(\omega)$ of a stationary time series $\{Y_t\}_{t\in\mathbb{Z}}$ can be used to investigate whether or not periodic structures are present in $\{Y_t\}_{t\in\mathbb{Z}}$, but $f(\omega)$ has some limitations due to its dependence on the autocovariances $\gamma(h)$. For example, $f(\omega)$ can not distinguish white i.i.d. noise from GARCH-type models (whose terms are dependent, but uncorrelated), which implies that $f(\omega)$ can be an inadequate tool when $\{Y_t\}_{t\in\mathbb{Z}}$ contains asymmetries and nonlinear dependencies. Asymmetries between the upper and lower tails of a time series can be investigated by means of the local Gaussian autocorrelations introduced in Tj{\o}stheim and Hufthammer (2013), and these local measures of dependence can be used to construct the local Gaussian spectral density presented in this paper. A key feature of the new local spectral density is that it coincides with $f(\omega)$ for Gaussian time series, which implies that it can be used to detect non-Gaussian traits in the time series under investigation. In particular, if $f(\omega)$ is flat, then peaks and troughs of the new local spectral density can indicate nonlinear traits, which potentially might discover local periodic phenomena that remain undetected in an ordinary spectral analysis.




 Hypothesis testing in the linear regression model is a fundamental statistical problem. We consider linear regression in the high-dimensional regime where the number of parameters exceeds the number of samples ($p> n$). In order to make informative inference, we assume that the model is approximately sparse, that is the effect of covariates on the response can be well approximated by conditioning on a relatively small number of covariates whose identities are unknown. We develop a framework for testing very general hypotheses regarding the model parameters. Our framework encompasses testing whether the parameter lies in a convex cone, testing the signal strength, and testing arbitrary functionals of the parameter. We show that the proposed procedure controls the type I error, and also analyze the power of the procedure. Our numerical experiments confirm our theoretical findings and demonstrate that we control false positive rate (type I error) near the nominal level, and have high power. By duality between hypotheses testing and confidence intervals, the proposed framework can be used to obtain valid confidence intervals for various functionals of the model parameters. For linear functionals, the length of confidence intervals is shown to be minimax rate optimal.
Hypothesis testing in the linear regression model is a fundamental statistical problem. We consider linear regression in the high-dimensional regime where the number of parameters exceeds the number of samples ($p> n$). In order to make informative inference, we assume that the model is approximately sparse, that is the effect of covariates on the response can be well approximated by conditioning on a relatively small number of covariates whose identities are unknown. We develop a framework for testing very general hypotheses regarding the model parameters. Our framework encompasses testing whether the parameter lies in a convex cone, testing the signal strength, and testing arbitrary functionals of the parameter. We show that the proposed procedure controls the type I error, and also analyze the power of the procedure. Our numerical experiments confirm our theoretical findings and demonstrate that we control false positive rate (type I error) near the nominal level, and have high power. By duality between hypotheses testing and confidence intervals, the proposed framework can be used to obtain valid confidence intervals for various functionals of the model parameters. For linear functionals, the length of confidence intervals is shown to be minimax rate optimal.