-
The rapid growth of IoT driven by recent advancements in consumer
electronics, 5G communication technologies, and cloud-computing enabled
big-data analytics, has recently attracted tremendous attention from both the
industry and academia. One of the major open challenges for IoT is the limited
network lifetime due to massive IoT devices being powered by batteries with
finite capacities. The low-power and low-complexity backscatter communications
(BackCom), which simply relies on passive reflection and modulation of an
incident radio-frequency (RF) wave, has emerged to be a promising technology
for tackling this challenge. However, the contemporary BackCom has several
major limitations, such as short transmission range, low data rate, and
uni-directional information transmission. The article aims at introducing the
recent advances in the active area of BackCom. Specifically, we provide a
systematic introduction of the next generation BackCom covering basic
principles, systems, techniques besides IoT applications. Lastly, we describe
the IoT application scenarios with the next generation BackCom.
-
Information theory is a mathematical theory of learning with deep connections
with topics as diverse as artificial intelligence, statistical physics, and
biological evolution. Many primers on information theory paint a broad picture
with relatively little mathematical sophistication, while many others develop
specific application areas in detail. In contrast, these informal notes aim to
outline some elements of the information-theoretic "way of thinking," by
cutting a rapid and interesting path through some of the theory's foundational
concepts and results. They are aimed at practicing systems scientists who are
interested in exploring potential connections between information theory and
their own fields. The main mathematical prerequisite for the notes is comfort
with elementary probability, including sample spaces, conditioning, and
expectations. We take the Kullback-Leibler divergence as our most basic
concept, and then proceed to develop the entropy and mutual information. We
discuss some of the main results, including the Chernoff bounds as a
characterization of the divergence; Gibbs' Theorem; and the Data Processing
Inequality. A recurring theme is that the definitions of information theory
support natural theorems that sound ``obvious'' when translated into English.
More pithily, ``information theory makes common sense precise.'' Since the
focus of the notes is not primarily on technical details, proofs are provided
only where the relevant techniques are illustrative of broader themes.
Otherwise, proofs and intriguing tangents are referenced in liberally-sprinkled
footnotes. The notes close with a highly nonexhaustive list of references to
resources and other perspectives on the field.
-
The coding problem for wiretap channels with causal channel state information
available at the encoder and/or the decoder is studied under the strong secrecy
criterion. This problem consists of two aspects: one is due to naive wiretap
channel coding and the other is due to one-time pad cipher based on the secret
key agreement between Alice and Bob using the channel state information. These
two aspects are closely related to each other and investigated in details from
the viewpoint of achievable rates with strong secrecy. The general wiretap
channel with various directions of channel state informations among Alice, Bob
and Eve (called the multi-way channel state information) is also studied, which
includes the above systems as special cases. We provide a unified view about
wiretap channel coding with causal multi-way channel state information.
-
We show that there is a binary subspace code of constant dimension 3 in
ambient dimension 7, having minimum distance 4 and cardinality 333, i.e., $333
\le A_2(7,4;3)$, which improves the previous best known lower bound of 329.
Moreover, if a code with these parameters has at least 333 elements, its
automorphism group is in one of $31$ conjugacy classes. This is achieved by a
more general technique for an exhaustive search in a finite group that does not
depend on the enumeration of all subgroups.
-
We consider Additive White Gaussian Noise channels and Discrete Memoryless
channels when the transmitter harvests energy from the environment. These can
model wireless sensor networks as well as Internet of Things. By providing a
unifying framework that works for any energy harvesting channel, we study these
channels assuming an infinite energy buffer and provide the corresponding
achievability and converse bounds on the channel capacity in the finite
blocklength regime. We additionally provide moderate deviation asymptotic
bounds as well.
-
This article investigates emergence and complexity in complex systems that
can share information on a network. To this end, we use a theoretical approach
from information theory, computability theory, and complex networks. One key
studied question is how much emergent complexity (or information) arises when a
population of computable systems is networked compared with when this
population is isolated. First, we define a general model for networked
theoretical machines, which we call algorithmic networks. Then, we narrow our
scope to investigate algorithmic networks that optimize the average fitnesses
of nodes in a scenario in which each node imitates the fittest neighbor and the
randomly generated population is networked by a time-varying graph. We show
that there are graph-topological conditions that cause these algorithmic
networks to have the property of expected emergent open-endedness for large
enough populations. In other words, the expected emergent algorithmic
complexity of a node tends to infinity as the population size tends to
infinity. Given a dynamic network, we show that these conditions imply the
existence of a central time to trigger expected emergent open-endedness.
Moreover, we show that networks with small diameter compared to the network
size meet these conditions. We also discuss future research based on how our
results are related to some problems in network science, information theory,
computability theory, distributed computing, game theory, evolutionary biology,
and synergy in complex systems.
-
This paper studies the effectiveness of relaying for interference mitigation
in an interference-limited communication scenario. We are motivated by the
observation that in a cellular network, a relay node placed at the cell edge
observes a combination of intended signal and inter-cell interference that is
correlated with the received signal at a nearby destination, so a relaying link
can effectively allow the antennas at the relay and at the destination to be
pooled together for both signal enhancement and interference mitigation. We
model this scenario by a MIMO Gaussian relay channel with a digital
relay-to-destination link of finite capacity, and with correlated noise across
the relay and destination antennas. Assuming a compress-and-forward strategy
with Gaussian input distribution and quantization noise, we propose a
coordinate ascent algorithm for obtaining a stationary point of the non-convex
joint optimization of the transmit and quantization covariance matrices. For
fixed input distribution, the globally optimum quantization noise covariance
matrix can be found in closed-form using a transformation of the relay's
observation that simultaneously diagonalizes two conditional covariance
matrices by congruence. For fixed quantization, the globally optimum transmit
covariance matrix can be found via convex optimization. This paper further
shows that such an optimized achievable rate is within a constant additive gap
of the MIMO relay channel capacity. The optimal structure of the quantization
noise covariance enables a characterization of the slope of the achievable rate
as a function of the relay-to-destination link capacity. Moreover, this paper
shows that the improvement in spatial degrees of freedom by MIMO relaying in
the presence of noise correlation is related to the aforementioned slope via a
connection to the deterministic relay channel.
-
We introduce a new information theoretic measure of quantum correlations for
multiparticle systems. We use a form of multivariate mutual information -- the
interaction information and generalize it to multiparticle quantum systems.
There are a number of different possible generalizations. We consider two of
them. One of them is related to the notion of quantum discord and the other to
the concept of quantum dissension. This new measure, called dissension vector,
is a set of numbers -- quantumness vector. This can be thought of as a
fine-grained measure, as opposed to measures that quantify some average quantum
properties of a system. These quantities quantify/characterize the correlations
present in multiparticle states. We consider some multiqubit states and find
that these quantities are responsive to different aspects of quantumness, and
correlations present in a state. We find that different dissension vectors can
track the correlations (both classical and quantum), or quantumness only. As
physical applications, we find that these vectors might be useful in several
information processing tasks. We consider the role of dissension vectors -- (a)
in deciding the security of BB84 protocol against an eavesdropper and (b) in
determining the possible role of correlations in the performance of Grover
search algorithm. Especially, in the Grover search algorithm, we find that
dissension vectors can detect the correlations and show the maximum
correlations when one expects.
-
We study high-dimensional distribution learning in an agnostic setting where
an adversary is allowed to arbitrarily corrupt an $\varepsilon$-fraction of the
samples. Such questions have a rich history spanning statistics, machine
learning and theoretical computer science. Even in the most basic settings, the
only known approaches are either computationally inefficient or lose
dimension-dependent factors in their error guarantees. This raises the
following question:Is high-dimensional agnostic distribution learning even
possible, algorithmically?
In this work, we obtain the first computationally efficient algorithms with
dimension-independent error guarantees for agnostically learning several
fundamental classes of high-dimensional distributions: (1) a single Gaussian,
(2) a product distribution on the hypercube, (3) mixtures of two product
distributions (under a natural balancedness condition), and (4) mixtures of
spherical Gaussians. Our algorithms achieve error that is independent of the
dimension, and in many cases scales nearly-linearly with the fraction of
adversarially corrupted samples. Moreover, we develop a general recipe for
detecting and correcting corruptions in high-dimensions, that may be applicable
to many other problems.
-
Hybrid beamforming for frequency-selective channels is a challenging problem
as the phase shifters provide the same phase shift to all of the subcarriers.
The existing approaches solely rely on the channel's frequency response and the
hybrid beamformers maximize the average spectral efficiency over the whole
frequency band. Compared to state-of-the-art, we show that substantial sum-rate
gains can be achieved, both for rich and sparse scattering channels, by jointly
exploiting the frequency and time domain characteristics of the massive
multiple-input multiple-output (MIMO) channels. In our proposed approach, the
radio frequency (RF) beamformer coherently combines the received symbols in the
time domain and, thus, it concentrates signal's power on a specific time
sample. As a result, the RF beamformer flattens the frequency response of the
"effective" transmission channel and reduces its root mean square delay spread.
Then, a baseband combiner mitigates the residual interference in the frequency
domain. We present the closed-form expressions of the proposed beamformer and
its performance by leveraging the favorable propagation condition of massive
MIMO channels and we prove that our proposed scheme can achieve the performance
of fully-digital zero-forcing when number of employed phase shifter networks is
twice the resolvable multipath components in the time domain.
-
We study the problem of variable selection for linear models under the
high-dimensional asymptotic setting, where the number of observations $n$ grows
at the same rate as the number of predictors $p$. We consider two-stage
variable selection techniques (TVS) in which the first stage uses bridge
estimators to obtain an estimate of the regression coefficients, and the second
stage simply thresholds this estimate to select the "important" predictors. The
asymptotic false discovery proportion (AFDP) and true positive proportion
(ATPP) of these TVS are evaluated. We prove that for a fixed ATPP, in order to
obtain a smaller AFDP, one should pick a bridge estimator with smaller
asymptotic mean square error in the first stage of TVS. Based on such
principled discovery, we present a sharp comparison of different TVS, via an
in-depth investigation of the estimation properties of bridge estimators.
Rather than "order-wise" error bounds with loose constants, our analysis
focuses on precise error characterization. Various interesting signal-to-noise
ratio and sparsity settings are studied. Our results offer new and thorough
insights into high-dimensional variable selection. For instance, we prove that
a TVS with Ridge in its first stage outperforms TVS with other bridge
estimators in large noise settings; two-stage LASSO becomes inferior when the
signal is rare and weak. As a by-product, we show that two-stage methods
outperform some standard variable selection techniques, such as LASSO and Sure
Independence Screening, under certain conditions.
-
This summary of the doctoral thesis is created to emphasize the close
connection of the proposed spectral analysis method with the Discrete Fourier
Transform (DFT), the most extensively studied and frequently used approach in
the history of signal processing. It is shown that in a typical application
case, where uniform data readings are transformed to the same number of
uniformly spaced frequencies, the results of the classical DFT and proposed
approach coincide. The difference in performance appears when the length of the
DFT is selected to be greater than the length of the data. The DFT solves the
unknown data problem by padding readings with zeros up to the length of the
DFT, while the proposed Extended DFT (EDFT) deals with this situation in a
different way, it uses the Fourier integral transform as a target and optimizes
the transform basis in the extended frequency range without putting such
restrictions on the time domain. Consequently, the Inverse DFT (IDFT) applied
to the result of EDFT returns not only known readings, but also the
extrapolated data, where classical DFT is able to give back just zeros, and
higher resolution are achieved at frequencies where the data has been
successfully extended. It has been demonstrated that EDFT able to process data
with missing readings or gaps inside or even nonuniformly distributed data.
Thus, EDFT significantly extends the usability of the DFT-based methods, where
previously these approaches have been considered as not applicable. The EDFT
founds the solution in an iterative way and requires repeated calculations to
get the adaptive basis, and this makes it numerical complexity much higher
compared to DFT. This disadvantage was a serious problem in the 1990s, when the
method has been proposed. Fortunately, since then the power of computers has
increased so much that nowadays EDFT application could be considered as a real
alternative.
-
Motivated by applications of distributed storage systems to key-value stores,
the multi-version coding problem was formulated to efficiently store frequently
updated data in asynchronous decentralized storage systems. Inspired by
consistency requirements in distributed systems, the main goal in the
multi-version coding problem is to ensure that the latest possible version of
the data is decodable, even if the data updates have not reached some servers
in the system. In this paper, we study the storage cost of ensuring consistency
for the case where the data versions are correlated, in contrast to previous
work where data versions were treated as being independent. We provide
multi-version code constructions that show that the storage cost can be
significantly smaller than the previous constructions depending on the degree
of correlation, despite the asynchrony and the decentralized nature. Our
achievability results are based on Reed-Solomon codes and random binning.
Through an information-theoretic converse, we show that our multi-version codes
are nearly-optimal, within a factor of $2$, in certain interesting regimes.
-
The majority of works in distributed storage networks assume a simple network
model with a collection of identical storage nodes with the same communication
cost between the nodes. In this paper, we consider a realistic multi-rack
distributed data storage network and present a code design framework for this
model. Considering the cheaper data transmission within the racks, our code
construction method is able to locally repair the nodes failure within the same
rack by using only the survived nodes in the same rack. However, in the case of
severe failure patterns when the information content of the survived nodes is
not sufficient to repair the failures, other racks will participate in the
repair process. By employing the criteria of our multi-rack storage code, we
establish a linear programming bound on the size of the code in order to
maximize the code rate.
-
Consider any sequence of finite groups $A^t$, where $t$ takes values in an
integer index set $\mathbf{Z}$. A group system $A$ is a set of sequences with
components in $A^t$ that forms a group under componentwise addition in $A^t$,
for each $t\in\mathbf{Z}$. In the setting of group systems, a natural
definition of a linear system is a homomorphism from a group of inputs to an
output group system $A$. We show that any group can be the input group of a
linear system and some group system. In general the kernel of the homomorphism
is nontrivial. We show that any $\ell$-controllable complete group system $A$
is a linear system whose input group is a generator group
$({\mathcal{U}},\circ)$, deduced from $A$, and then the kernel is always
trivial. The input set ${\mathcal{U}}$ is a set of tensors, a double Cartesian
product space of sets $G_k^t$, with indices $k$, for $0\le k\le\ell$, and time
$t$, for $t\in\mathbf{Z}$. $G_k^t$ is a set of generator labels $g_k^t$ where
$g_k^t$ is the label of a generator with nontrivial span for the time interval
$[t,t+k]$. We show the generator group contains an elementary system, an
infinite collection of elementary groups, one for each $k$ and $t$, defined on
small subsets of ${\mathcal{U}}$, in the shape of triangles, which form a tile
like structure over ${\mathcal{U}}$. Any elementary system is sufficient to
define a unique generator group up to isomorphism. Therefore an elementary
system is sufficient to construct a linear system and group system as well. Any
linear block code is a strongly controllable group system which is nontrivial
on a finite time interval. Therefore it is a linear system whose input is a
generator group, and we use the generator group to obtain new results on the
structure of block codes.
-
Due to the big size of data and limited data storage volume of a single
computer or a single server, data are often stored in a distributed manner.
Thus, performing large-scale machine learning operations with the distributed
datasets through communication networks is often required. In this paper, we
study the convergence rate of the distributed dual coordinate ascent for
distributed machine learning problems in a general tree-structured network.
Since a tree network model can be understood as the generalization of a star
network model, our algorithm can be thought of as the generalization of the
distributed dual coordinate ascent in a star network model. We provide the
convergence rate of the distributed dual coordinate ascent over a general tree
network in a recursive manner and analyze the network effect on the convergence
rate. Secondly, by considering network communication delays, we optimize the
distributed dual coordinate ascent algorithm to maximize its convergence speed.
From our analytical result, we can choose the optimal number of local
iterations depending on the communication delay severity to achieve the fastest
convergence speed. In numerical experiments, we consider machine learning
scenarios over communication networks, where local workers cannot directly
reach to a central node due to constraints in communication, and demonstrate
that the usability of our distributed dual coordinate ascent algorithm in tree
networks. Additionally, we show that adapting number of local and global
iterations to network communication delays in the distributed dual coordinated
ascent algorithm can improve its convergence speed.
-
This work considers a super-resolution framework for overcomplete tensor
decomposition. Specifically, we view tensor decomposition as a super-resolution
problem of recovering a sum of Dirac measures on the sphere and solve it by
minimizing a continuous analog of the $\ell_1$ norm on the space of measures.
The optimal value of this optimization defines the tensor nuclear norm. Similar
to the separation condition in the super-resolution problem, by explicitly
constructing a dual certificate, we develop incoherence conditions of the
tensor factors so that they form the unique optimal solution of the continuous
analog of $\ell_1$ norm minimization. Remarkably, the derived incoherence
conditions are satisfied with high probability by random tensor factors
uniformly distributed on the sphere, implying global identifiability of random
tensor factors.
-
We consider the problem of distributed estimation of a Gaussian vector with
linear observation model. Each sensor makes a scalar noisy observation of the
unknown vector, quantizes its observation, maps it to a digitally modulated
symbol, and transmits the symbol over orthogonal power-constrained fading
channels to a fusion center (FC). The FC is tasked with fusing the received
signals from sensors and estimating the unknown vector. We derive the Bayesian
Fisher Information Matrix (FIM) for three types of receivers: (i) coherent
receiver (ii) noncoherent receiver with known channel envelopes (iii)
noncoherent receiver with known channel statistics only. We also derive the
Weiss-Weinstein bound (WWB). We formulate two constrained optimization
problems, namely maximizing trace and log-determinant of Bayesian FIM under
network transmit power constraint, with sensors transmit powers being the
optimization variables. We show that for coherent receiver, these problems are
concave. However, for noncoherent receivers, they are not necessarily concave.
The solution to the trace of Bayesian FIM maximization problem can be
implemented in a distributed fashion. We numerically investigate how the
FIM-max power allocation across sensors depends on the sensors observation
qualities and physical layer parameters as well as the network transmit power
constraint. Moreover, we evaluate the system performance in terms of MSE using
the solutions of FIM-max schemes, and compare it with the solution obtained
from minimizing the MSE of the LMMSE estimator (MSE-min scheme), and that of
uniform power allocation. These comparisons illustrate that, although the WWB
is tighter than the inverse of Bayesian FIM, it is still suitable to use
FIM-max schemes, since the performance loss in terms of the MSE of the LMMSE
estimator is not significant.
-
Coded source compression, also known as source compression with helpers, has
been a major variant of distributed source compression, but has hitherto
received little attention in the quantum regime. This work treats and solves
the corresponding quantum coded source compression through an observation that
connects coded source compression with channel simulation. First, we consider
classical source coding with quantum side information where the quantum side
information is observed by a helper and sent to the decoder via a classical
channel. We derive a single-letter characterization of the achievable rate
region for this problem. The direct coding theorem of our result is proved via
the measurement compression theory of Winter, a quantum-to-classical channel
simulation. Our result reveals that a helper's scheme which separately conducts
a measurement and a compression is suboptimal, and measurement compression
seems necessary to achieve the optimal rate region. We then study coded source
compression in the fully quantum regime, where two different scenarios are
considered depending on the types of communication channels between the
legitimate source and the receiver. We further allow entanglement assistance
from the quantum helper in both scenarios. We characterize the involved quantum
resources, and derive single-letter expressions of the achievable rate region.
The direct coding proofs are based on well-known quantum protocols, the quantum
state merging protocol and the fully quantum Slepian-Wolf protocol, together
with the quantum reverse Shannon theorem.
-
We introduce the Fixed Cluster Repair System (FCRS) as a novel architecture
for Distributed Storage Systems (DSS), achieving a small repair bandwidth while
guaranteeing a high availability. Specifically we partition the set of servers
in a DSS into $s$ clusters and allow a failed server to choose any cluster
other than its own as its repair group. Thereby, we guarantee an availability
of $s-1$. We characterize the repair bandwidth vs. storage trade-off for the
FCRS under functional repair and show that the minimum repair bandwidth can be
improved by an asymptotic multiplicative factor of $2/3$ compared to the state
of the art coding techniques that guarantee the same availability. We further
introduce Cubic Codes designed to minimize the repair bandwidth of the FCRS
under the exact repair model. We prove an asymptotic multiplicative improvement
of $0.79$ in the minimum repair bandwidth compared to the existing exact repair
coding techniques that achieve the same availability. We show that Cubic Codes
are information-theoretically optimal for the FCRS with $2$ and $3$ complete
clusters. Furthermore, under the repair-by-transfer model, Cubic Codes are
optimal irrespective of the number of clusters.
-
We consider non-binary polarization transform problem of polar codes. The
focus of this work is on finding equidistant (or almost equidistant) polarizing
transforms to maximize the minimum distance and to approach the equidistant
distant spectrum bound as a function of signal set. This bound is an ultimate
limit and tight for additive white Gaussian channels. In this way, polarization
of error probability for the good channel is improved while the bad channel is
almost the same for a given signal set. Our main result is that the
polarization speed is increased by using polarizing transform with an improved
distance profile. A non-binary polarization transform for q = 5 is found that
can provide the equidistant distant spectrum bound. Almost equidistant
polarization transforms for q = 4, 6, 7 and 8 are introduced for PSK signal
sets. As a private solution, we provided new geometries for the signal set
design to define the equidistant transform for q = 3 and q = 4 for one and two
dimensional signalings. We proposed a procedure to design transforms that have
better distance profiles for q-ary signal sets. Finally, we show improvements
in frame error rates.
-
Modern authentication systems store hashed values of passwords of users using
cryptographic hash functions. Therefore, to crack a password an attacker needs
to guess a hash function input that is mapped to the hashed value, as opposed
to the password itself. We call a hash function that maps the same number of
inputs to each bin, as \textbf{unbiased}. However, cryptographic hash functions
in use have not been proven to be unbiased (i.e., they may have an unequal
number of inputs mapped to different bins). A cryptographic hash function has
the property that it is computationally difficult to find an input mapped to a
bin. In this work we introduce a structured notion of biased hash functions for
which we analyze the average guesswork under certain types of brute force
attacks. This work shows that the level of security depends on the set of
hashed values of valid users as well as the statistical profile of a hash
function, resulting from bias. We examine the average guesswork conditioned on
the set of hashed values, and model the statistical profile through the
empirical distribution of the number of inputs that are mapped to a bin. In
particular, we focus on a class of statistical profiles (capturing the bias) ,
which we call type-class statistical profiles, that has an empirical
distribution related to the probability of the type classes defined in the
method of types. For such profiles, we show that the average guesswork is
related to basic measures in information theory such as entropy and divergence.
We use this to show that the effect of bias on the conditional average
guesswork is limited compared to other system parameters such as the number of
valid users who store their hashed passwords in the system.
-
To attain the targeted data rates of next generation cellular networks
requires dense deployment of small cells in addition to macro cells which
provide wide coverage. Dynamic radio resource management is crucial to the
success of such heterogeneous networks due to much more pronounced traffic and
interference variations in small cells. This work proposes a framework for
spectrum management organized according to two timescales, which include 1)
centralized optimization on a moderate timescale corresponding to typical
duration of user sessions (several seconds to minutes in today's networks), and
2) distributed spectrum allocation on a fast timescale corresponding to typical
latency requirements (a few milliseconds). An optimization problem is
formulated to allocate resources on the slower timescale with consideration of
(distributed) opportunistic scheduling on the faster timescale. Both fixed and
fully flexible user association schemes are considered. Iterative algorithms
are developed to solve these optimization problems efficiently for a cluster of
cells with guaranteed convergence. Simulation results demonstrate advantages of
the proposed framework and algorithms.
-
This paper studies the need for individualizing vehicular communications in
order to improve collision warning systems for an N-lane highway scenario. By
relating the traffic-based and communications studies, we aim at reducing
highway traffic accidents. To the best of our knowledge, this is the first
paper that shows how to customize vehicular communications to driver's
characteristics and traffic information. We propose to develop VANET protocols
that selectively identify crash relevant information and customize the
communications of that information based on each driver's assigned safety
score. In this paper, first, we derive the packet success probability by
accounting for multi-user interference, path loss, and fading. Then, by Monte
carlo simulations, we demonstrate how appropriate channel access probabilities
that satisfy the delay requirements of the safety application result in
noticeable performance enhancement.
-
The secrecy rate region of wiretap interference channels with a multi-antenna
passive eavesdropper is studied under receiver energy harvesting constraints.
To stay operational in the network, the legitimate receivers demand energy
alongside information, which is fulfilled by power transmission and exploiting
a power splitting (PS) receiver. By simultaneous wireless information and power
transfer (SWIPT), the amount of leakage to the eavesdropper increases, which in
turn reduces the secrecy rates. For this setup, lower-bounds for secure
communication rate are derived without imposing any limitation at the
eavesdropper processing. These lower-bounds are then compared with the rates
achieved by assuming the worst-case linear eavesdropper processing. We show
that in certain special cases the worst-case eavesdropper does not enlarge the
achievable secure rate region in comparison to the unconstrained eavesdropper
case. It turns out that in order to achieve the Pareto boundary of the secrecy
rate region, smart tuning of the transmit power and receiver PS coefficient is
required. Hence, we propose an efficient algorithm to optimize these parameters
jointly in polynomial-time. The secrecy rate region characterization is
formulated as a weighted max-min optimization problem. This problem turns out
to be a non-convex problem due to the non-convex constrained set. This set is
replaced by a convex subset that in consequence leads to an achievable
suboptimal solution which is improved iteratively. By solving the problem
efficiently, we obtain the amount of rate loss for providing secrecy, meanwhile
satisfying the energy demands.





 The rapid growth of IoT driven by recent advancements in consumer electronics, 5G communication technologies, and cloud-computing enabled big-data analytics, has recently attracted tremendous attention from both the industry and academia. One of the major open challenges for IoT is the limited network lifetime due to massive IoT devices being powered by batteries with finite capacities. The low-power and low-complexity backscatter communications (BackCom), which simply relies on passive reflection and modulation of an incident radio-frequency (RF) wave, has emerged to be a promising technology for tackling this challenge. However, the contemporary BackCom has several major limitations, such as short transmission range, low data rate, and uni-directional information transmission. The article aims at introducing the recent advances in the active area of BackCom. Specifically, we provide a systematic introduction of the next generation BackCom covering basic principles, systems, techniques besides IoT applications. Lastly, we describe the IoT application scenarios with the next generation BackCom.
The rapid growth of IoT driven by recent advancements in consumer electronics, 5G communication technologies, and cloud-computing enabled big-data analytics, has recently attracted tremendous attention from both the industry and academia. One of the major open challenges for IoT is the limited network lifetime due to massive IoT devices being powered by batteries with finite capacities. The low-power and low-complexity backscatter communications (BackCom), which simply relies on passive reflection and modulation of an incident radio-frequency (RF) wave, has emerged to be a promising technology for tackling this challenge. However, the contemporary BackCom has several major limitations, such as short transmission range, low data rate, and uni-directional information transmission. The article aims at introducing the recent advances in the active area of BackCom. Specifically, we provide a systematic introduction of the next generation BackCom covering basic principles, systems, techniques besides IoT applications. Lastly, we describe the IoT application scenarios with the next generation BackCom.




 Information theory is a mathematical theory of learning with deep connections with topics as diverse as artificial intelligence, statistical physics, and biological evolution. Many primers on information theory paint a broad picture with relatively little mathematical sophistication, while many others develop specific application areas in detail. In contrast, these informal notes aim to outline some elements of the information-theoretic "way of thinking," by cutting a rapid and interesting path through some of the theory's foundational concepts and results. They are aimed at practicing systems scientists who are interested in exploring potential connections between information theory and their own fields. The main mathematical prerequisite for the notes is comfort with elementary probability, including sample spaces, conditioning, and expectations. We take the Kullback-Leibler divergence as our most basic concept, and then proceed to develop the entropy and mutual information. We discuss some of the main results, including the Chernoff bounds as a characterization of the divergence; Gibbs' Theorem; and the Data Processing Inequality. A recurring theme is that the definitions of information theory support natural theorems that sound ``obvious'' when translated into English. More pithily, ``information theory makes common sense precise.'' Since the focus of the notes is not primarily on technical details, proofs are provided only where the relevant techniques are illustrative of broader themes. Otherwise, proofs and intriguing tangents are referenced in liberally-sprinkled footnotes. The notes close with a highly nonexhaustive list of references to resources and other perspectives on the field.
Information theory is a mathematical theory of learning with deep connections with topics as diverse as artificial intelligence, statistical physics, and biological evolution. Many primers on information theory paint a broad picture with relatively little mathematical sophistication, while many others develop specific application areas in detail. In contrast, these informal notes aim to outline some elements of the information-theoretic "way of thinking," by cutting a rapid and interesting path through some of the theory's foundational concepts and results. They are aimed at practicing systems scientists who are interested in exploring potential connections between information theory and their own fields. The main mathematical prerequisite for the notes is comfort with elementary probability, including sample spaces, conditioning, and expectations. We take the Kullback-Leibler divergence as our most basic concept, and then proceed to develop the entropy and mutual information. We discuss some of the main results, including the Chernoff bounds as a characterization of the divergence; Gibbs' Theorem; and the Data Processing Inequality. A recurring theme is that the definitions of information theory support natural theorems that sound ``obvious'' when translated into English. More pithily, ``information theory makes common sense precise.'' Since the focus of the notes is not primarily on technical details, proofs are provided only where the relevant techniques are illustrative of broader themes. Otherwise, proofs and intriguing tangents are referenced in liberally-sprinkled footnotes. The notes close with a highly nonexhaustive list of references to resources and other perspectives on the field.




 The coding problem for wiretap channels with causal channel state information available at the encoder and/or the decoder is studied under the strong secrecy criterion. This problem consists of two aspects: one is due to naive wiretap channel coding and the other is due to one-time pad cipher based on the secret key agreement between Alice and Bob using the channel state information. These two aspects are closely related to each other and investigated in details from the viewpoint of achievable rates with strong secrecy. The general wiretap channel with various directions of channel state informations among Alice, Bob and Eve (called the multi-way channel state information) is also studied, which includes the above systems as special cases. We provide a unified view about wiretap channel coding with causal multi-way channel state information.
The coding problem for wiretap channels with causal channel state information available at the encoder and/or the decoder is studied under the strong secrecy criterion. This problem consists of two aspects: one is due to naive wiretap channel coding and the other is due to one-time pad cipher based on the secret key agreement between Alice and Bob using the channel state information. These two aspects are closely related to each other and investigated in details from the viewpoint of achievable rates with strong secrecy. The general wiretap channel with various directions of channel state informations among Alice, Bob and Eve (called the multi-way channel state information) is also studied, which includes the above systems as special cases. We provide a unified view about wiretap channel coding with causal multi-way channel state information.




 We show that there is a binary subspace code of constant dimension 3 in ambient dimension 7, having minimum distance 4 and cardinality 333, i.e., $333 \le A_2(7,4;3)$, which improves the previous best known lower bound of 329. Moreover, if a code with these parameters has at least 333 elements, its automorphism group is in one of $31$ conjugacy classes. This is achieved by a more general technique for an exhaustive search in a finite group that does not depend on the enumeration of all subgroups.
We show that there is a binary subspace code of constant dimension 3 in ambient dimension 7, having minimum distance 4 and cardinality 333, i.e., $333 \le A_2(7,4;3)$, which improves the previous best known lower bound of 329. Moreover, if a code with these parameters has at least 333 elements, its automorphism group is in one of $31$ conjugacy classes. This is achieved by a more general technique for an exhaustive search in a finite group that does not depend on the enumeration of all subgroups.




 We consider Additive White Gaussian Noise channels and Discrete Memoryless channels when the transmitter harvests energy from the environment. These can model wireless sensor networks as well as Internet of Things. By providing a unifying framework that works for any energy harvesting channel, we study these channels assuming an infinite energy buffer and provide the corresponding achievability and converse bounds on the channel capacity in the finite blocklength regime. We additionally provide moderate deviation asymptotic bounds as well.
We consider Additive White Gaussian Noise channels and Discrete Memoryless channels when the transmitter harvests energy from the environment. These can model wireless sensor networks as well as Internet of Things. By providing a unifying framework that works for any energy harvesting channel, we study these channels assuming an infinite energy buffer and provide the corresponding achievability and converse bounds on the channel capacity in the finite blocklength regime. We additionally provide moderate deviation asymptotic bounds as well.




 This article investigates emergence and complexity in complex systems that can share information on a network. To this end, we use a theoretical approach from information theory, computability theory, and complex networks. One key studied question is how much emergent complexity (or information) arises when a population of computable systems is networked compared with when this population is isolated. First, we define a general model for networked theoretical machines, which we call algorithmic networks. Then, we narrow our scope to investigate algorithmic networks that optimize the average fitnesses of nodes in a scenario in which each node imitates the fittest neighbor and the randomly generated population is networked by a time-varying graph. We show that there are graph-topological conditions that cause these algorithmic networks to have the property of expected emergent open-endedness for large enough populations. In other words, the expected emergent algorithmic complexity of a node tends to infinity as the population size tends to infinity. Given a dynamic network, we show that these conditions imply the existence of a central time to trigger expected emergent open-endedness. Moreover, we show that networks with small diameter compared to the network size meet these conditions. We also discuss future research based on how our results are related to some problems in network science, information theory, computability theory, distributed computing, game theory, evolutionary biology, and synergy in complex systems.
This article investigates emergence and complexity in complex systems that can share information on a network. To this end, we use a theoretical approach from information theory, computability theory, and complex networks. One key studied question is how much emergent complexity (or information) arises when a population of computable systems is networked compared with when this population is isolated. First, we define a general model for networked theoretical machines, which we call algorithmic networks. Then, we narrow our scope to investigate algorithmic networks that optimize the average fitnesses of nodes in a scenario in which each node imitates the fittest neighbor and the randomly generated population is networked by a time-varying graph. We show that there are graph-topological conditions that cause these algorithmic networks to have the property of expected emergent open-endedness for large enough populations. In other words, the expected emergent algorithmic complexity of a node tends to infinity as the population size tends to infinity. Given a dynamic network, we show that these conditions imply the existence of a central time to trigger expected emergent open-endedness. Moreover, we show that networks with small diameter compared to the network size meet these conditions. We also discuss future research based on how our results are related to some problems in network science, information theory, computability theory, distributed computing, game theory, evolutionary biology, and synergy in complex systems.




 This paper studies the effectiveness of relaying for interference mitigation in an interference-limited communication scenario. We are motivated by the observation that in a cellular network, a relay node placed at the cell edge observes a combination of intended signal and inter-cell interference that is correlated with the received signal at a nearby destination, so a relaying link can effectively allow the antennas at the relay and at the destination to be pooled together for both signal enhancement and interference mitigation. We model this scenario by a MIMO Gaussian relay channel with a digital relay-to-destination link of finite capacity, and with correlated noise across the relay and destination antennas. Assuming a compress-and-forward strategy with Gaussian input distribution and quantization noise, we propose a coordinate ascent algorithm for obtaining a stationary point of the non-convex joint optimization of the transmit and quantization covariance matrices. For fixed input distribution, the globally optimum quantization noise covariance matrix can be found in closed-form using a transformation of the relay's observation that simultaneously diagonalizes two conditional covariance matrices by congruence. For fixed quantization, the globally optimum transmit covariance matrix can be found via convex optimization. This paper further shows that such an optimized achievable rate is within a constant additive gap of the MIMO relay channel capacity. The optimal structure of the quantization noise covariance enables a characterization of the slope of the achievable rate as a function of the relay-to-destination link capacity. Moreover, this paper shows that the improvement in spatial degrees of freedom by MIMO relaying in the presence of noise correlation is related to the aforementioned slope via a connection to the deterministic relay channel.
This paper studies the effectiveness of relaying for interference mitigation in an interference-limited communication scenario. We are motivated by the observation that in a cellular network, a relay node placed at the cell edge observes a combination of intended signal and inter-cell interference that is correlated with the received signal at a nearby destination, so a relaying link can effectively allow the antennas at the relay and at the destination to be pooled together for both signal enhancement and interference mitigation. We model this scenario by a MIMO Gaussian relay channel with a digital relay-to-destination link of finite capacity, and with correlated noise across the relay and destination antennas. Assuming a compress-and-forward strategy with Gaussian input distribution and quantization noise, we propose a coordinate ascent algorithm for obtaining a stationary point of the non-convex joint optimization of the transmit and quantization covariance matrices. For fixed input distribution, the globally optimum quantization noise covariance matrix can be found in closed-form using a transformation of the relay's observation that simultaneously diagonalizes two conditional covariance matrices by congruence. For fixed quantization, the globally optimum transmit covariance matrix can be found via convex optimization. This paper further shows that such an optimized achievable rate is within a constant additive gap of the MIMO relay channel capacity. The optimal structure of the quantization noise covariance enables a characterization of the slope of the achievable rate as a function of the relay-to-destination link capacity. Moreover, this paper shows that the improvement in spatial degrees of freedom by MIMO relaying in the presence of noise correlation is related to the aforementioned slope via a connection to the deterministic relay channel.




 We introduce a new information theoretic measure of quantum correlations for multiparticle systems. We use a form of multivariate mutual information -- the interaction information and generalize it to multiparticle quantum systems. There are a number of different possible generalizations. We consider two of them. One of them is related to the notion of quantum discord and the other to the concept of quantum dissension. This new measure, called dissension vector, is a set of numbers -- quantumness vector. This can be thought of as a fine-grained measure, as opposed to measures that quantify some average quantum properties of a system. These quantities quantify/characterize the correlations present in multiparticle states. We consider some multiqubit states and find that these quantities are responsive to different aspects of quantumness, and correlations present in a state. We find that different dissension vectors can track the correlations (both classical and quantum), or quantumness only. As physical applications, we find that these vectors might be useful in several information processing tasks. We consider the role of dissension vectors -- (a) in deciding the security of BB84 protocol against an eavesdropper and (b) in determining the possible role of correlations in the performance of Grover search algorithm. Especially, in the Grover search algorithm, we find that dissension vectors can detect the correlations and show the maximum correlations when one expects.
We introduce a new information theoretic measure of quantum correlations for multiparticle systems. We use a form of multivariate mutual information -- the interaction information and generalize it to multiparticle quantum systems. There are a number of different possible generalizations. We consider two of them. One of them is related to the notion of quantum discord and the other to the concept of quantum dissension. This new measure, called dissension vector, is a set of numbers -- quantumness vector. This can be thought of as a fine-grained measure, as opposed to measures that quantify some average quantum properties of a system. These quantities quantify/characterize the correlations present in multiparticle states. We consider some multiqubit states and find that these quantities are responsive to different aspects of quantumness, and correlations present in a state. We find that different dissension vectors can track the correlations (both classical and quantum), or quantumness only. As physical applications, we find that these vectors might be useful in several information processing tasks. We consider the role of dissension vectors -- (a) in deciding the security of BB84 protocol against an eavesdropper and (b) in determining the possible role of correlations in the performance of Grover search algorithm. Especially, in the Grover search algorithm, we find that dissension vectors can detect the correlations and show the maximum correlations when one expects.




 We study high-dimensional distribution learning in an agnostic setting where an adversary is allowed to arbitrarily corrupt an $\varepsilon$-fraction of the samples. Such questions have a rich history spanning statistics, machine learning and theoretical computer science. Even in the most basic settings, the only known approaches are either computationally inefficient or lose dimension-dependent factors in their error guarantees. This raises the following question:Is high-dimensional agnostic distribution learning even possible, algorithmically? In this work, we obtain the first computationally efficient algorithms with dimension-independent error guarantees for agnostically learning several fundamental classes of high-dimensional distributions: (1) a single Gaussian, (2) a product distribution on the hypercube, (3) mixtures of two product distributions (under a natural balancedness condition), and (4) mixtures of spherical Gaussians. Our algorithms achieve error that is independent of the dimension, and in many cases scales nearly-linearly with the fraction of adversarially corrupted samples. Moreover, we develop a general recipe for detecting and correcting corruptions in high-dimensions, that may be applicable to many other problems.
We study high-dimensional distribution learning in an agnostic setting where an adversary is allowed to arbitrarily corrupt an $\varepsilon$-fraction of the samples. Such questions have a rich history spanning statistics, machine learning and theoretical computer science. Even in the most basic settings, the only known approaches are either computationally inefficient or lose dimension-dependent factors in their error guarantees. This raises the following question:Is high-dimensional agnostic distribution learning even possible, algorithmically? In this work, we obtain the first computationally efficient algorithms with dimension-independent error guarantees for agnostically learning several fundamental classes of high-dimensional distributions: (1) a single Gaussian, (2) a product distribution on the hypercube, (3) mixtures of two product distributions (under a natural balancedness condition), and (4) mixtures of spherical Gaussians. Our algorithms achieve error that is independent of the dimension, and in many cases scales nearly-linearly with the fraction of adversarially corrupted samples. Moreover, we develop a general recipe for detecting and correcting corruptions in high-dimensions, that may be applicable to many other problems.




 Hybrid beamforming for frequency-selective channels is a challenging problem as the phase shifters provide the same phase shift to all of the subcarriers. The existing approaches solely rely on the channel's frequency response and the hybrid beamformers maximize the average spectral efficiency over the whole frequency band. Compared to state-of-the-art, we show that substantial sum-rate gains can be achieved, both for rich and sparse scattering channels, by jointly exploiting the frequency and time domain characteristics of the massive multiple-input multiple-output (MIMO) channels. In our proposed approach, the radio frequency (RF) beamformer coherently combines the received symbols in the time domain and, thus, it concentrates signal's power on a specific time sample. As a result, the RF beamformer flattens the frequency response of the "effective" transmission channel and reduces its root mean square delay spread. Then, a baseband combiner mitigates the residual interference in the frequency domain. We present the closed-form expressions of the proposed beamformer and its performance by leveraging the favorable propagation condition of massive MIMO channels and we prove that our proposed scheme can achieve the performance of fully-digital zero-forcing when number of employed phase shifter networks is twice the resolvable multipath components in the time domain.
Hybrid beamforming for frequency-selective channels is a challenging problem as the phase shifters provide the same phase shift to all of the subcarriers. The existing approaches solely rely on the channel's frequency response and the hybrid beamformers maximize the average spectral efficiency over the whole frequency band. Compared to state-of-the-art, we show that substantial sum-rate gains can be achieved, both for rich and sparse scattering channels, by jointly exploiting the frequency and time domain characteristics of the massive multiple-input multiple-output (MIMO) channels. In our proposed approach, the radio frequency (RF) beamformer coherently combines the received symbols in the time domain and, thus, it concentrates signal's power on a specific time sample. As a result, the RF beamformer flattens the frequency response of the "effective" transmission channel and reduces its root mean square delay spread. Then, a baseband combiner mitigates the residual interference in the frequency domain. We present the closed-form expressions of the proposed beamformer and its performance by leveraging the favorable propagation condition of massive MIMO channels and we prove that our proposed scheme can achieve the performance of fully-digital zero-forcing when number of employed phase shifter networks is twice the resolvable multipath components in the time domain.




 We study the problem of variable selection for linear models under the high-dimensional asymptotic setting, where the number of observations $n$ grows at the same rate as the number of predictors $p$. We consider two-stage variable selection techniques (TVS) in which the first stage uses bridge estimators to obtain an estimate of the regression coefficients, and the second stage simply thresholds this estimate to select the "important" predictors. The asymptotic false discovery proportion (AFDP) and true positive proportion (ATPP) of these TVS are evaluated. We prove that for a fixed ATPP, in order to obtain a smaller AFDP, one should pick a bridge estimator with smaller asymptotic mean square error in the first stage of TVS. Based on such principled discovery, we present a sharp comparison of different TVS, via an in-depth investigation of the estimation properties of bridge estimators. Rather than "order-wise" error bounds with loose constants, our analysis focuses on precise error characterization. Various interesting signal-to-noise ratio and sparsity settings are studied. Our results offer new and thorough insights into high-dimensional variable selection. For instance, we prove that a TVS with Ridge in its first stage outperforms TVS with other bridge estimators in large noise settings; two-stage LASSO becomes inferior when the signal is rare and weak. As a by-product, we show that two-stage methods outperform some standard variable selection techniques, such as LASSO and Sure Independence Screening, under certain conditions.
We study the problem of variable selection for linear models under the high-dimensional asymptotic setting, where the number of observations $n$ grows at the same rate as the number of predictors $p$. We consider two-stage variable selection techniques (TVS) in which the first stage uses bridge estimators to obtain an estimate of the regression coefficients, and the second stage simply thresholds this estimate to select the "important" predictors. The asymptotic false discovery proportion (AFDP) and true positive proportion (ATPP) of these TVS are evaluated. We prove that for a fixed ATPP, in order to obtain a smaller AFDP, one should pick a bridge estimator with smaller asymptotic mean square error in the first stage of TVS. Based on such principled discovery, we present a sharp comparison of different TVS, via an in-depth investigation of the estimation properties of bridge estimators. Rather than "order-wise" error bounds with loose constants, our analysis focuses on precise error characterization. Various interesting signal-to-noise ratio and sparsity settings are studied. Our results offer new and thorough insights into high-dimensional variable selection. For instance, we prove that a TVS with Ridge in its first stage outperforms TVS with other bridge estimators in large noise settings; two-stage LASSO becomes inferior when the signal is rare and weak. As a by-product, we show that two-stage methods outperform some standard variable selection techniques, such as LASSO and Sure Independence Screening, under certain conditions.




 Motivated by applications of distributed storage systems to key-value stores, the multi-version coding problem was formulated to efficiently store frequently updated data in asynchronous decentralized storage systems. Inspired by consistency requirements in distributed systems, the main goal in the multi-version coding problem is to ensure that the latest possible version of the data is decodable, even if the data updates have not reached some servers in the system. In this paper, we study the storage cost of ensuring consistency for the case where the data versions are correlated, in contrast to previous work where data versions were treated as being independent. We provide multi-version code constructions that show that the storage cost can be significantly smaller than the previous constructions depending on the degree of correlation, despite the asynchrony and the decentralized nature. Our achievability results are based on Reed-Solomon codes and random binning. Through an information-theoretic converse, we show that our multi-version codes are nearly-optimal, within a factor of $2$, in certain interesting regimes.
Motivated by applications of distributed storage systems to key-value stores, the multi-version coding problem was formulated to efficiently store frequently updated data in asynchronous decentralized storage systems. Inspired by consistency requirements in distributed systems, the main goal in the multi-version coding problem is to ensure that the latest possible version of the data is decodable, even if the data updates have not reached some servers in the system. In this paper, we study the storage cost of ensuring consistency for the case where the data versions are correlated, in contrast to previous work where data versions were treated as being independent. We provide multi-version code constructions that show that the storage cost can be significantly smaller than the previous constructions depending on the degree of correlation, despite the asynchrony and the decentralized nature. Our achievability results are based on Reed-Solomon codes and random binning. Through an information-theoretic converse, we show that our multi-version codes are nearly-optimal, within a factor of $2$, in certain interesting regimes.



 Due to the big size of data and limited data storage volume of a single computer or a single server, data are often stored in a distributed manner. Thus, performing large-scale machine learning operations with the distributed datasets through communication networks is often required. In this paper, we study the convergence rate of the distributed dual coordinate ascent for distributed machine learning problems in a general tree-structured network. Since a tree network model can be understood as the generalization of a star network model, our algorithm can be thought of as the generalization of the distributed dual coordinate ascent in a star network model. We provide the convergence rate of the distributed dual coordinate ascent over a general tree network in a recursive manner and analyze the network effect on the convergence rate. Secondly, by considering network communication delays, we optimize the distributed dual coordinate ascent algorithm to maximize its convergence speed. From our analytical result, we can choose the optimal number of local iterations depending on the communication delay severity to achieve the fastest convergence speed. In numerical experiments, we consider machine learning scenarios over communication networks, where local workers cannot directly reach to a central node due to constraints in communication, and demonstrate that the usability of our distributed dual coordinate ascent algorithm in tree networks. Additionally, we show that adapting number of local and global iterations to network communication delays in the distributed dual coordinated ascent algorithm can improve its convergence speed.
Due to the big size of data and limited data storage volume of a single computer or a single server, data are often stored in a distributed manner. Thus, performing large-scale machine learning operations with the distributed datasets through communication networks is often required. In this paper, we study the convergence rate of the distributed dual coordinate ascent for distributed machine learning problems in a general tree-structured network. Since a tree network model can be understood as the generalization of a star network model, our algorithm can be thought of as the generalization of the distributed dual coordinate ascent in a star network model. We provide the convergence rate of the distributed dual coordinate ascent over a general tree network in a recursive manner and analyze the network effect on the convergence rate. Secondly, by considering network communication delays, we optimize the distributed dual coordinate ascent algorithm to maximize its convergence speed. From our analytical result, we can choose the optimal number of local iterations depending on the communication delay severity to achieve the fastest convergence speed. In numerical experiments, we consider machine learning scenarios over communication networks, where local workers cannot directly reach to a central node due to constraints in communication, and demonstrate that the usability of our distributed dual coordinate ascent algorithm in tree networks. Additionally, we show that adapting number of local and global iterations to network communication delays in the distributed dual coordinated ascent algorithm can improve its convergence speed.




 This work considers a super-resolution framework for overcomplete tensor decomposition. Specifically, we view tensor decomposition as a super-resolution problem of recovering a sum of Dirac measures on the sphere and solve it by minimizing a continuous analog of the $\ell_1$ norm on the space of measures. The optimal value of this optimization defines the tensor nuclear norm. Similar to the separation condition in the super-resolution problem, by explicitly constructing a dual certificate, we develop incoherence conditions of the tensor factors so that they form the unique optimal solution of the continuous analog of $\ell_1$ norm minimization. Remarkably, the derived incoherence conditions are satisfied with high probability by random tensor factors uniformly distributed on the sphere, implying global identifiability of random tensor factors.
This work considers a super-resolution framework for overcomplete tensor decomposition. Specifically, we view tensor decomposition as a super-resolution problem of recovering a sum of Dirac measures on the sphere and solve it by minimizing a continuous analog of the $\ell_1$ norm on the space of measures. The optimal value of this optimization defines the tensor nuclear norm. Similar to the separation condition in the super-resolution problem, by explicitly constructing a dual certificate, we develop incoherence conditions of the tensor factors so that they form the unique optimal solution of the continuous analog of $\ell_1$ norm minimization. Remarkably, the derived incoherence conditions are satisfied with high probability by random tensor factors uniformly distributed on the sphere, implying global identifiability of random tensor factors.




 We consider the problem of distributed estimation of a Gaussian vector with linear observation model. Each sensor makes a scalar noisy observation of the unknown vector, quantizes its observation, maps it to a digitally modulated symbol, and transmits the symbol over orthogonal power-constrained fading channels to a fusion center (FC). The FC is tasked with fusing the received signals from sensors and estimating the unknown vector. We derive the Bayesian Fisher Information Matrix (FIM) for three types of receivers: (i) coherent receiver (ii) noncoherent receiver with known channel envelopes (iii) noncoherent receiver with known channel statistics only. We also derive the Weiss-Weinstein bound (WWB). We formulate two constrained optimization problems, namely maximizing trace and log-determinant of Bayesian FIM under network transmit power constraint, with sensors transmit powers being the optimization variables. We show that for coherent receiver, these problems are concave. However, for noncoherent receivers, they are not necessarily concave. The solution to the trace of Bayesian FIM maximization problem can be implemented in a distributed fashion. We numerically investigate how the FIM-max power allocation across sensors depends on the sensors observation qualities and physical layer parameters as well as the network transmit power constraint. Moreover, we evaluate the system performance in terms of MSE using the solutions of FIM-max schemes, and compare it with the solution obtained from minimizing the MSE of the LMMSE estimator (MSE-min scheme), and that of uniform power allocation. These comparisons illustrate that, although the WWB is tighter than the inverse of Bayesian FIM, it is still suitable to use FIM-max schemes, since the performance loss in terms of the MSE of the LMMSE estimator is not significant.
We consider the problem of distributed estimation of a Gaussian vector with linear observation model. Each sensor makes a scalar noisy observation of the unknown vector, quantizes its observation, maps it to a digitally modulated symbol, and transmits the symbol over orthogonal power-constrained fading channels to a fusion center (FC). The FC is tasked with fusing the received signals from sensors and estimating the unknown vector. We derive the Bayesian Fisher Information Matrix (FIM) for three types of receivers: (i) coherent receiver (ii) noncoherent receiver with known channel envelopes (iii) noncoherent receiver with known channel statistics only. We also derive the Weiss-Weinstein bound (WWB). We formulate two constrained optimization problems, namely maximizing trace and log-determinant of Bayesian FIM under network transmit power constraint, with sensors transmit powers being the optimization variables. We show that for coherent receiver, these problems are concave. However, for noncoherent receivers, they are not necessarily concave. The solution to the trace of Bayesian FIM maximization problem can be implemented in a distributed fashion. We numerically investigate how the FIM-max power allocation across sensors depends on the sensors observation qualities and physical layer parameters as well as the network transmit power constraint. Moreover, we evaluate the system performance in terms of MSE using the solutions of FIM-max schemes, and compare it with the solution obtained from minimizing the MSE of the LMMSE estimator (MSE-min scheme), and that of uniform power allocation. These comparisons illustrate that, although the WWB is tighter than the inverse of Bayesian FIM, it is still suitable to use FIM-max schemes, since the performance loss in terms of the MSE of the LMMSE estimator is not significant.




 We introduce the Fixed Cluster Repair System (FCRS) as a novel architecture for Distributed Storage Systems (DSS), achieving a small repair bandwidth while guaranteeing a high availability. Specifically we partition the set of servers in a DSS into $s$ clusters and allow a failed server to choose any cluster other than its own as its repair group. Thereby, we guarantee an availability of $s-1$. We characterize the repair bandwidth vs. storage trade-off for the FCRS under functional repair and show that the minimum repair bandwidth can be improved by an asymptotic multiplicative factor of $2/3$ compared to the state of the art coding techniques that guarantee the same availability. We further introduce Cubic Codes designed to minimize the repair bandwidth of the FCRS under the exact repair model. We prove an asymptotic multiplicative improvement of $0.79$ in the minimum repair bandwidth compared to the existing exact repair coding techniques that achieve the same availability. We show that Cubic Codes are information-theoretically optimal for the FCRS with $2$ and $3$ complete clusters. Furthermore, under the repair-by-transfer model, Cubic Codes are optimal irrespective of the number of clusters.
We introduce the Fixed Cluster Repair System (FCRS) as a novel architecture for Distributed Storage Systems (DSS), achieving a small repair bandwidth while guaranteeing a high availability. Specifically we partition the set of servers in a DSS into $s$ clusters and allow a failed server to choose any cluster other than its own as its repair group. Thereby, we guarantee an availability of $s-1$. We characterize the repair bandwidth vs. storage trade-off for the FCRS under functional repair and show that the minimum repair bandwidth can be improved by an asymptotic multiplicative factor of $2/3$ compared to the state of the art coding techniques that guarantee the same availability. We further introduce Cubic Codes designed to minimize the repair bandwidth of the FCRS under the exact repair model. We prove an asymptotic multiplicative improvement of $0.79$ in the minimum repair bandwidth compared to the existing exact repair coding techniques that achieve the same availability. We show that Cubic Codes are information-theoretically optimal for the FCRS with $2$ and $3$ complete clusters. Furthermore, under the repair-by-transfer model, Cubic Codes are optimal irrespective of the number of clusters.
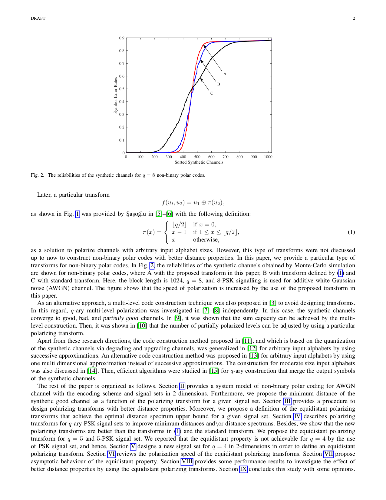



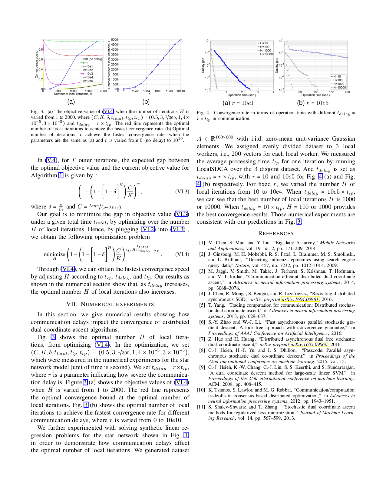
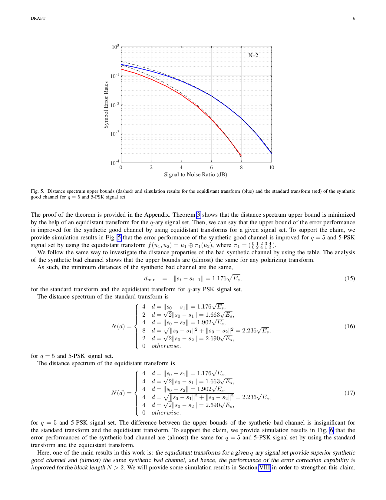 We consider non-binary polarization transform problem of polar codes. The focus of this work is on finding equidistant (or almost equidistant) polarizing transforms to maximize the minimum distance and to approach the equidistant distant spectrum bound as a function of signal set. This bound is an ultimate limit and tight for additive white Gaussian channels. In this way, polarization of error probability for the good channel is improved while the bad channel is almost the same for a given signal set. Our main result is that the polarization speed is increased by using polarizing transform with an improved distance profile. A non-binary polarization transform for q = 5 is found that can provide the equidistant distant spectrum bound. Almost equidistant polarization transforms for q = 4, 6, 7 and 8 are introduced for PSK signal sets. As a private solution, we provided new geometries for the signal set design to define the equidistant transform for q = 3 and q = 4 for one and two dimensional signalings. We proposed a procedure to design transforms that have better distance profiles for q-ary signal sets. Finally, we show improvements in frame error rates.
We consider non-binary polarization transform problem of polar codes. The focus of this work is on finding equidistant (or almost equidistant) polarizing transforms to maximize the minimum distance and to approach the equidistant distant spectrum bound as a function of signal set. This bound is an ultimate limit and tight for additive white Gaussian channels. In this way, polarization of error probability for the good channel is improved while the bad channel is almost the same for a given signal set. Our main result is that the polarization speed is increased by using polarizing transform with an improved distance profile. A non-binary polarization transform for q = 5 is found that can provide the equidistant distant spectrum bound. Almost equidistant polarization transforms for q = 4, 6, 7 and 8 are introduced for PSK signal sets. As a private solution, we provided new geometries for the signal set design to define the equidistant transform for q = 3 and q = 4 for one and two dimensional signalings. We proposed a procedure to design transforms that have better distance profiles for q-ary signal sets. Finally, we show improvements in frame error rates.




 Modern authentication systems store hashed values of passwords of users using cryptographic hash functions. Therefore, to crack a password an attacker needs to guess a hash function input that is mapped to the hashed value, as opposed to the password itself. We call a hash function that maps the same number of inputs to each bin, as \textbf{unbiased}. However, cryptographic hash functions in use have not been proven to be unbiased (i.e., they may have an unequal number of inputs mapped to different bins). A cryptographic hash function has the property that it is computationally difficult to find an input mapped to a bin. In this work we introduce a structured notion of biased hash functions for which we analyze the average guesswork under certain types of brute force attacks. This work shows that the level of security depends on the set of hashed values of valid users as well as the statistical profile of a hash function, resulting from bias. We examine the average guesswork conditioned on the set of hashed values, and model the statistical profile through the empirical distribution of the number of inputs that are mapped to a bin. In particular, we focus on a class of statistical profiles (capturing the bias) , which we call type-class statistical profiles, that has an empirical distribution related to the probability of the type classes defined in the method of types. For such profiles, we show that the average guesswork is related to basic measures in information theory such as entropy and divergence. We use this to show that the effect of bias on the conditional average guesswork is limited compared to other system parameters such as the number of valid users who store their hashed passwords in the system.
Modern authentication systems store hashed values of passwords of users using cryptographic hash functions. Therefore, to crack a password an attacker needs to guess a hash function input that is mapped to the hashed value, as opposed to the password itself. We call a hash function that maps the same number of inputs to each bin, as \textbf{unbiased}. However, cryptographic hash functions in use have not been proven to be unbiased (i.e., they may have an unequal number of inputs mapped to different bins). A cryptographic hash function has the property that it is computationally difficult to find an input mapped to a bin. In this work we introduce a structured notion of biased hash functions for which we analyze the average guesswork under certain types of brute force attacks. This work shows that the level of security depends on the set of hashed values of valid users as well as the statistical profile of a hash function, resulting from bias. We examine the average guesswork conditioned on the set of hashed values, and model the statistical profile through the empirical distribution of the number of inputs that are mapped to a bin. In particular, we focus on a class of statistical profiles (capturing the bias) , which we call type-class statistical profiles, that has an empirical distribution related to the probability of the type classes defined in the method of types. For such profiles, we show that the average guesswork is related to basic measures in information theory such as entropy and divergence. We use this to show that the effect of bias on the conditional average guesswork is limited compared to other system parameters such as the number of valid users who store their hashed passwords in the system.




 To attain the targeted data rates of next generation cellular networks requires dense deployment of small cells in addition to macro cells which provide wide coverage. Dynamic radio resource management is crucial to the success of such heterogeneous networks due to much more pronounced traffic and interference variations in small cells. This work proposes a framework for spectrum management organized according to two timescales, which include 1) centralized optimization on a moderate timescale corresponding to typical duration of user sessions (several seconds to minutes in today's networks), and 2) distributed spectrum allocation on a fast timescale corresponding to typical latency requirements (a few milliseconds). An optimization problem is formulated to allocate resources on the slower timescale with consideration of (distributed) opportunistic scheduling on the faster timescale. Both fixed and fully flexible user association schemes are considered. Iterative algorithms are developed to solve these optimization problems efficiently for a cluster of cells with guaranteed convergence. Simulation results demonstrate advantages of the proposed framework and algorithms.
To attain the targeted data rates of next generation cellular networks requires dense deployment of small cells in addition to macro cells which provide wide coverage. Dynamic radio resource management is crucial to the success of such heterogeneous networks due to much more pronounced traffic and interference variations in small cells. This work proposes a framework for spectrum management organized according to two timescales, which include 1) centralized optimization on a moderate timescale corresponding to typical duration of user sessions (several seconds to minutes in today's networks), and 2) distributed spectrum allocation on a fast timescale corresponding to typical latency requirements (a few milliseconds). An optimization problem is formulated to allocate resources on the slower timescale with consideration of (distributed) opportunistic scheduling on the faster timescale. Both fixed and fully flexible user association schemes are considered. Iterative algorithms are developed to solve these optimization problems efficiently for a cluster of cells with guaranteed convergence. Simulation results demonstrate advantages of the proposed framework and algorithms.
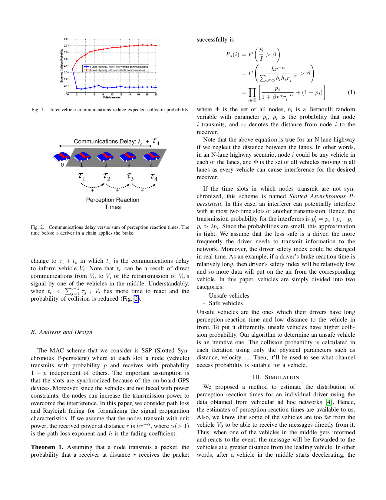
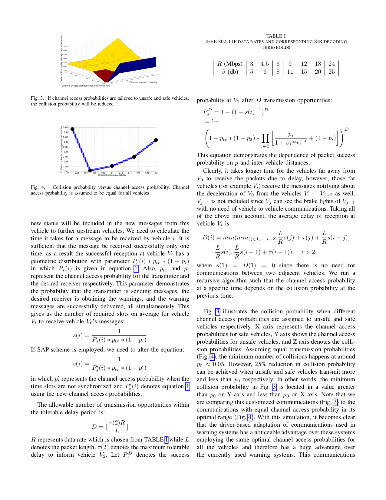


 This paper studies the need for individualizing vehicular communications in order to improve collision warning systems for an N-lane highway scenario. By relating the traffic-based and communications studies, we aim at reducing highway traffic accidents. To the best of our knowledge, this is the first paper that shows how to customize vehicular communications to driver's characteristics and traffic information. We propose to develop VANET protocols that selectively identify crash relevant information and customize the communications of that information based on each driver's assigned safety score. In this paper, first, we derive the packet success probability by accounting for multi-user interference, path loss, and fading. Then, by Monte carlo simulations, we demonstrate how appropriate channel access probabilities that satisfy the delay requirements of the safety application result in noticeable performance enhancement.
This paper studies the need for individualizing vehicular communications in order to improve collision warning systems for an N-lane highway scenario. By relating the traffic-based and communications studies, we aim at reducing highway traffic accidents. To the best of our knowledge, this is the first paper that shows how to customize vehicular communications to driver's characteristics and traffic information. We propose to develop VANET protocols that selectively identify crash relevant information and customize the communications of that information based on each driver's assigned safety score. In this paper, first, we derive the packet success probability by accounting for multi-user interference, path loss, and fading. Then, by Monte carlo simulations, we demonstrate how appropriate channel access probabilities that satisfy the delay requirements of the safety application result in noticeable performance enhancement.