-
Dense kernel matrices $\Theta \in \mathbb{R}^{N \times N}$ obtained from
point evaluations of a covariance function $G$ at locations $\{ x_{i} \}_{1
\leq i \leq N} \subset \mathbb{R}^{d}$ arise in statistics, machine learning,
and numerical analysis. For covariance functions that are Green's functions of
elliptic boundary value problems and homogeneously-distributed sampling points,
we show how to identify a subset $S \subset \{ 1 , \dots , N \}^2$, with $\# S
= O ( N \log (N) \log^{d} ( N /\epsilon ) )$, such that the zero fill-in
incomplete Cholesky factorisation of the sparse matrix $\Theta_{ij} 1_{( i, j )
\in S}$ is an $\epsilon$-approximation of $\Theta$. This factorisation can
provably be obtained in complexity $O ( N \log( N ) \log^{d}( N /\epsilon) )$
in space and $O ( N \log^{2}( N ) \log^{2d}( N /\epsilon) )$ in time, improving
upon the state of the art for general elliptic operators; we further present
numerical evidence that $d$ can be taken to be the intrinsic dimension of the
data set rather than that of the ambient space. The algorithm only needs to
know the spatial configuration of the $x_{i}$ and does not require an analytic
representation of $G$. Furthermore, this factorization straightforwardly
provides an approximate sparse PCA with optimal rate of convergence in the
operator norm. Hence, by using only subsampling and the incomplete Cholesky
factorization, we obtain, at nearly linear complexity, the compression,
inversion and approximate PCA of a large class of covariance matrices. By
inverting the order of the Cholesky factorization we also obtain a solver for
elliptic PDE with complexity $O ( N \log^{d}( N /\epsilon) )$ in space and $O (
N \log^{2d}( N /\epsilon) )$ in time, improving upon the state of the art for
general elliptic operators.
-
Wavelet (Besov) priors are a promising way of reconstructing indirectly
measured fields in a regularized manner. We demonstrate how wavelets can be
used as a localized basis for reconstructing permeability fields with sharp
interfaces from noisy pointwise pressure field measurements in the context of
the elliptic inverse problem. For this we derive the adjoint method of
minimizing the Besov-norm-regularized misfit functional (this corresponds to
determining the maximum a posteriori point in the Bayesian point of view) in
the Haar wavelet setting. As it turns out, choosing a wavelet--based prior
allows for accelerated optimization compared to established
trigonometrically--based priors.
-
This summary of the doctoral thesis is created to emphasize the close
connection of the proposed spectral analysis method with the Discrete Fourier
Transform (DFT), the most extensively studied and frequently used approach in
the history of signal processing. It is shown that in a typical application
case, where uniform data readings are transformed to the same number of
uniformly spaced frequencies, the results of the classical DFT and proposed
approach coincide. The difference in performance appears when the length of the
DFT is selected to be greater than the length of the data. The DFT solves the
unknown data problem by padding readings with zeros up to the length of the
DFT, while the proposed Extended DFT (EDFT) deals with this situation in a
different way, it uses the Fourier integral transform as a target and optimizes
the transform basis in the extended frequency range without putting such
restrictions on the time domain. Consequently, the Inverse DFT (IDFT) applied
to the result of EDFT returns not only known readings, but also the
extrapolated data, where classical DFT is able to give back just zeros, and
higher resolution are achieved at frequencies where the data has been
successfully extended. It has been demonstrated that EDFT able to process data
with missing readings or gaps inside or even nonuniformly distributed data.
Thus, EDFT significantly extends the usability of the DFT-based methods, where
previously these approaches have been considered as not applicable. The EDFT
founds the solution in an iterative way and requires repeated calculations to
get the adaptive basis, and this makes it numerical complexity much higher
compared to DFT. This disadvantage was a serious problem in the 1990s, when the
method has been proposed. Fortunately, since then the power of computers has
increased so much that nowadays EDFT application could be considered as a real
alternative.
-
Algebraic multigrid (AMG) is often an effective solver for symmetric positive
definite (SPD) linear systems resulting from the discretization of general
elliptic PDEs, or the spatial discretization of parabolic PDEs. However,
convergence theory and most variations of AMG rely on $A$ being SPD. Hyperbolic
PDEs, which arise often in large-scale scientific simulations, remain a
challenge for AMG, as well as other fast linear solvers, in part because the
resulting linear systems are often highly nonsymmetric. Here, a novel
convergence framework is developed for nonsymmetric, reduction-based AMG, and
sufficient conditions derived for $\ell^2$-convergence of error and residual.
In particular, classical multigrid approximation properties are connected with
reduction-based measures to develop a robust framework for nonsymmetric,
reduction-based AMG.
Matrices with block-triangular structure are then recognized as being
amenable to reduction-type algorithms, and a reduction-based AMG method is
developed for upwind discretizations of hyperbolic PDEs, based on the concept
of a Neumann approximation to ideal restriction ($n$AIR). $n$AIR can be seen as
a variation of local AIR ($\ell$AIR) introduced in previous work, specifically
targeting matrices with triangular structure. Although less versatile than
$\ell$AIR, setup times for $n$AIR can be substantially faster for problems with
high connectivity. $n$AIR is shown to be an effective and scalable solver of
steady state transport for discontinuous, upwind discretizations, with
unstructured meshes, and up to 6th-order finite elements, offering a
significant improvement over existing AMG methods. $n$AIR is also shown to be
effective on several classes of `nearly triangular' matrices, resulting from
curvilinear finite elements and artificial diffusion.
-
Bayesian matrix factorization (BMF) is a powerful tool for producing low-rank
representations of matrices and for predicting missing values and providing
confidence intervals. Scaling up the posterior inference for massive-scale
matrices is challenging and requires distributing both data and computation
over many workers, making communication the main computational bottleneck.
Embarrassingly parallel inference would remove the communication needed, by
using completely independent computations on different data subsets, but it
suffers from the inherent unidentifiability of BMF solutions. We introduce a
hierarchical decomposition of the joint posterior distribution, which couples
the subset inferences, allowing for embarrassingly parallel computations in a
sequence of at most three stages. Using an efficient approximate
implementation, we show improvements empirically on both real and simulated
data. Our distributed approach is able to achieve a speed-up of almost an order
of magnitude over the full posterior, with a negligible effect on predictive
accuracy. Our method outperforms state-of-the-art embarrassingly parallel MCMC
methods in accuracy, and achieves results competitive to other available
distributed and parallel implementations of BMF.
-
The conditioning of implicit Runge-Kutta (RK) integration for linear finite
element approximation of diffusion equations on general anisotropic meshes is
investigated. Bounds are established for the condition number of the resulting
linear system with and without diagonal preconditioning for the implicit Euler
and general implicit RK methods. Two solution strategies are considered for the
linear system resulting from general implicit RK integration: the simultaneous
solution (the system is solved as a whole) and a successive solution which
follows the commonly used implementation of implicit RK methods to first
transform the system into smaller systems using the Jordan normal form of the
RK matrix and then solve them successively.
For the simultaneous solution in case of a positive semidefinite symmetric
part of the RK coefficient matrix and for the successive solution it is shown
that . If the smallest eigenvalue of the symmetric part of the RK coefficient
matrix is negative and the simultaneous solution strategy is used, an upper
bound on the time step is given so that the system matrix is positive definite.
The obtained bounds for the condition number have explicit geometric
interpretations and take the interplay between the diffusion matrix and the
mesh geometry into full consideration. They show that there are three
mesh-dependent factors that can affect the conditioning: the number of
elements, the mesh nonuniformity measured in the Euclidean metric, and the mesh
nonuniformity with respect to the inverse of the diffusion matrix. They also
reveal that the preconditioning using the diagonal of the system matrix, the
mass matrix, or the lumped mass matrix can effectively eliminate the effects of
the mesh nonuniformity measured in the Euclidean metric. Numerical examples are
given.
-
We develop a framework that allows the use of the multi-level Monte Carlo
(MLMC) methodology (Giles2015) to calculate expectations with respect to the
invariant measure of an ergodic SDE. In that context, we study the
(over-damped) Langevin equations with a strongly concave potential. We show
that, when appropriate contracting couplings for the numerical integrators are
available, one can obtain a uniform in time estimate of the MLMC variance in
contrast to the majority of the results in the MLMC literature. As a
consequence, a root mean square error of $\mathcal{O}(\varepsilon)$ is achieved
with $\mathcal{O}(\varepsilon^{-2})$ complexity on par with Markov Chain Monte
Carlo (MCMC) methods, which however can be computationally intensive when
applied to large data sets. Finally, we present a multi-level version of the
recently introduced Stochastic Gradient Langevin Dynamics (SGLD) method
(Welling and Teh, 2011) built for large datasets applications. We show that
this is the first stochastic gradient MCMC method with complexity
$\mathcal{O}(\varepsilon^{-2}|\log {\varepsilon}|^{3})$, in contrast to the
complexity $\mathcal{O}(\varepsilon^{-3})$ of currently available methods.
Numerical experiments confirm our theoretical findings.
-
Deep neural networks have become invaluable tools for supervised machine
learning, e.g., classification of text or images. While often offering superior
results over traditional techniques and successfully expressing complicated
patterns in data, deep architectures are known to be challenging to design and
train such that they generalize well to new data. Important issues with deep
architectures are numerical instabilities in derivative-based learning
algorithms commonly called exploding or vanishing gradients. In this paper we
propose new forward propagation techniques inspired by systems of Ordinary
Differential Equations (ODE) that overcome this challenge and lead to
well-posed learning problems for arbitrarily deep networks.
The backbone of our approach is our interpretation of deep learning as a
parameter estimation problem of nonlinear dynamical systems. Given this
formulation, we analyze stability and well-posedness of deep learning and use
this new understanding to develop new network architectures. We relate the
exploding and vanishing gradient phenomenon to the stability of the discrete
ODE and present several strategies for stabilizing deep learning for very deep
networks. While our new architectures restrict the solution space, several
numerical experiments show their competitiveness with state-of-the-art
networks.
-
In numerical time-integration with implicit-explicit (IMEX) methods, a
within-step adaptable decomposition called residual balanced decomposition is
introduced. With this decomposition, the requirement of a small enough residual
in the iterative solver can be removed, consequently, this allows to exchange
stability for efficiency. This decomposition transfers any residual occurring
in the implicit equation of the implicit-step into the explicit part of the
decomposition. By balancing the residual, the accuracy of the local truncation
error of the time-stepping method becomes independent from the accuracy by
which the implicit equation is solved. In order to balance the residual, the
original IMEX decomposition is adjusted after the iterative solver has been
stopped. For this to work, the traditional IMEX time-stepping algorithm needs
to be changed. We call this new method the shortcut-IMEX (SIMEX). SIMEX can
gain computational efficiency by exploring the trade-off between the
computational effort placed in solving the implicit equation and the size of
the numerically stable time-step. Typically, increasing the number of solver
iterations increases the largest stable step-size. Both multi-step and
Runge-Kutta (RK) methods are suitable for use with SIMEX. Here, we show the
efficiency of a SIMEX-RK method in overcoming parabolic stiffness by applying
it to a nonlinear reaction-advection-diffusion equation. In order to define a
stability region for SIMEX, a region in the complex plane is depicted by
applying SIMEX to a suitable PDE model containing diffusion and dispersion. A
myriad of stability regions can be reached by changing the RK tableau and the
solver.
-
This report describes the computation of gradients by algorithmic
differentiation for statistically optimum beamforming operations. Especially
the derivation of complex-valued functions is a key component of this approach.
Therefore the real-valued algorithmic differentiation is extended via the
complex-valued chain rule. In addition to the basic mathematic operations the
derivative of the eigenvalue problem with complex-valued eigenvectors is one of
the key results of this report. The potential of this approach is shown with
experimental results on the CHiME-3 challenge database. There, the beamforming
task is used as a front-end for an ASR system. With the developed derivatives a
joint optimization of a speech enhancement and speech recognition system w.r.t.
the recognition optimization criterion is possible.
-
In recent papers the author introduced a simple alternative to isoparametric
finite elements of the n-simplex type, to enhance the accuracy of
approximations of second-order boundary value problems with Dirichlet
conditions, posed in smooth curved domains. This technique is based upon
trial-functions consisting of piecewise polynomials defined on straight-edged
triangular or tetrahedral meshes, interpolating the Dirichlet boundary
conditions at points of the true boundary. In contrast the test-functions are
defined upon the standard degrees of freedom associated with the underlying
method for polytopic domains. While method's mathematical analysis for both
second- and fourth-order problems in two-dimensional domains was carried out in
arxiv NA-1701.00663 and in a submitted paper, this article is devoted to the
study of the three-dimensional case, in which the method is nonconforming.
Well-posedness, uniform stability and optimal a priori error estimates in the
energy norm are demonstrated for a tetrahedron-based Lagrange family of finite
elements. Novel L2-error estimates for the class of problems considered in this
work are also proved. A series of numerical examples illustrates the potential
of the new technique. In particular its better accuracy at equivalent cost as
compared to the isoparametric technique is highlighted. Moreover the great
generality of the new approach is exemplified through a method with degrees of
freedom other than nodal values.
-
We propose a semantics of operating on real numbers that is sound,
Turing-complete, and practical. It modifies the intuitive but super-recursive
Blum-Shub-Smale model (formalizing Computer ALGEBRA Systems), to coincide in
power with the realistic but inconvenient Type-2 Turing machine underlying
Computable Analysis: reconciling both as foundation to a Computer ANALYSIS
System.
Several examples illustrate the elegance of rigorous numerical coding in this
framework, formalized as a simple imperative programming language ERC with
denotational semantics for REALIZING a real function $f$: arguments $x$ are
given as exact real numbers, while values $y=f(x)$ suffice to be returned
approximately up to absolute error $2^p$ with respect to an additionally given
integer parameter $p\to-\infty$. Real comparison (necessarily) becomes partial,
possibly 'returning' the lazy Kleenean value UNDEF (subtly different from
$\bot$ for classically undefined expressions like 1/0). This asserts closure
under composition, and in fact 'Turing-completeness over the reals': All and
only functions computable in the sense of Computable Analysis can be realized
in ERC. Programs thus operate on a many-sorted structure involving real numbers
and integers, connected via the 'error' embedding $Z\ni p\mapsto 2^p\in R$,
whose first-order theory is proven decidable and model-complete. This logic
serves for formally specifying and formally verifying correctness of ERC
programs. We finally expand ERC and its Turing-completeness from real functions
to functionALs.
-
Probabilistic integration of a continuous dynamical system is a way of
systematically introducing model error, at scales no larger than errors
introduced by standard numerical discretisation, in order to enable thorough
exploration of possible responses of the system to inputs. It is thus a
potentially useful approach in a number of applications such as forward
uncertainty quantification, inverse problems, and data assimilation. We extend
the convergence analysis of probabilistic integrators for deterministic
ordinary differential equations, as proposed by Conrad et al.\ (\textit{Stat.\
Comput.}, 2017), to establish mean-square convergence in the uniform norm on
discrete- or continuous-time solutions under relaxed regularity assumptions on
the driving vector fields and their induced flows. Specifically, we show that
randomised high-order integrators for globally Lipschitz flows and randomised
Euler integrators for dissipative vector fields with polynomially-bounded local
Lipschitz constants all have the same mean-square convergence rate as their
deterministic counterparts, provided that the variance of the integration noise
is not of higher order than the corresponding deterministic integrator. These
and similar results are proven for probabilistic integrators where the random
perturbations may be state-dependent, non-Gaussian, or non-centred random
variables.
-
Several test function suites are being used for numerical benchmarking of
multiobjective optimization algorithms. While they have some desirable
properties, like well-understood Pareto sets and Pareto fronts of various
shapes, most of the currently used functions possess characteristics that are
arguably under-represented in real-world problems. They mainly stem from the
easier construction of such functions and result in improbable properties such
as separability, optima located exactly at the boundary constraints, and the
existence of variables that solely control the distance between a solution and
the Pareto front. Here, we propose an alternative way to constructing
multiobjective problems-by combining existing single-objective problems from
the literature. We describe in particular the bbob-biobj test suite with 55
bi-objective functions in continuous domain, and its extended version with 92
bi-objective functions (bbob-biobj-ext). Both test suites have been implemented
in the COCO platform for black-box optimization benchmarking. Finally, we
recommend a general procedure for creating test suites for an arbitrary number
of objectives. Besides providing the formal function definitions and presenting
their (known) properties, this paper also aims at giving the rationale behind
our approach in terms of groups of functions with similar properties, objective
space normalization, and problem instances. The latter allows us to easily
compare the performance of deterministic and stochastic solvers, which is an
often overlooked issue in benchmarking.
-
We study and develop (stochastic) primal--dual block-coordinate descent
methods for convex problems based on the method due to Chambolle and Pock. Our
methods have known convergence rates for the iterates and the ergodic gap:
$O(1/N^2)$ if each block is strongly convex, $O(1/N)$ if no convexity is
present, and more generally a mixed rate $O(1/N^2)+O(1/N)$ for strongly convex
blocks, if only some blocks are strongly convex. Additional novelties of our
methods include blockwise-adapted step lengths and acceleration, as well as the
ability to update both the primal and dual variables randomly in blocks under a
very light compatibility condition. In other words, these variants of our
methods are doubly-stochastic. We test the proposed methods on various image
processing problems, where we employ pixelwise-adapted acceleration.
-
This paper summarizes the development of Veamy, an object-oriented C++
library for the virtual element method (VEM) on general polygonal meshes, whose
modular design is focused on its extensibility. The linear elastostatic and
Poisson problems in two dimensions have been chosen as the starting stage for
the development of this library. The theory of the VEM, upon which Veamy is
built, is presented using a notation and a terminology that resemble the
language of the finite element method (FEM) in engineering analysis. Several
examples are provided to demonstrate the usage of Veamy, and in particular, one
of them features the interaction between Veamy and the polygonal mesh generator
PolyMesher. A computational performance comparison between VEM and FEM is also
conducted. Veamy is free and open source software.
-
This work studies the linear approximation of high-dimensional dynamical
systems using low-rank dynamic mode decomposition (DMD). Searching this
approximation in a data-driven approach is formalised as attempting to solve a
low-rank constrained optimisation problem. This problem is non-convex and
state-of-the-art algorithms are all sub-optimal. This paper shows that there
exists a closed-form solution, which is computed in polynomial time, and
characterises the l2-norm of the optimal approximation error. The paper also
proposes low-complexity algorithms building reduced models from this optimal
solution, based on singular value decomposition or eigen value decomposition.
The algorithms are evaluated by numerical simulations using synthetic and
physical data benchmarks.
-
We consider importance sampling to estimate the probability $\mu$ of a union
of $J$ rare events $H_j$ defined by a random variable $\boldsymbol{x}$. The
sampler we study has been used in spatial statistics, genomics and
combinatorics going back at least to Karp and Luby (1983). It works by sampling
one event at random, then sampling $\boldsymbol{x}$ conditionally on that event
happening and it constructs an unbiased estimate of $\mu$ by multiplying an
inverse moment of the number of occuring events by the union bound. We prove
some variance bounds for this sampler. For a sample size of $n$, it has a
variance no larger than $\mu(\bar\mu-\mu)/n$ where $\bar\mu$ is the union
bound. It also has a coefficient of variation no larger than
$\sqrt{(J+J^{-1}-2)/(4n)}$ regardless of the overlap pattern among the $J$
events. Our motivating problem comes from power system reliability, where the
phase differences between connected nodes have a joint Gaussian distribution
and the $J$ rare events arise from unacceptably large phase differences. In the
grid reliability problems even some events defined by $5772$ constraints in
$326$ dimensions, with probability below $10^{-22}$, are estimated with a
coefficient of variation of about $0.0024$ with only $n=10{,}000$ sample
values.
-
We propose a simple algorithm to locate the "corner" of an L-curve, a
function often used to select the regularisation parameter for the solution of
ill-posed inverse problems. The algorithm involves the Menger curvature of a
circumcircle and the golden section search method. It efficiently finds the
regularisation parameter value corresponding to the maximum positive curvature
region of the L-curve. The algorithm is applied to some commonly available test
problems and compared to the typical way of locating the l-curve corner by
means of its analytical curvature. The application of the algorithm to the data
processing of an electrical resistance tomography experiment on thin conductive
films is also reported.
-
We present a full implementation of the parareal algorithm---an integration
technique to solve differential equations in parallel---in the Julia
programming language for a fully general, first-order, initial-value problem.
We provide a brief overview of Julia---a concurrent programming language for
scientific computing. Our implementation of the parareal algorithm accepts both
coarse and fine integrators as functional arguments. We use Euler's method and
another Runge-Kutta integration technique as the integrators in our
experiments. We also present a simulation of the algorithm for purposes of
pedagogy and as a tool for investigating the performance of the algorithm.
-
This work is devoted to the design of interior penalty discontinuous Galerkin
(dG) schemes that preserve maximum principles at the discrete level for the
steady transport and convection-diffusion problems and the respective transient
problems with implicit time integration. Monotonic schemes that combine
explicit time stepping with dG space discretization are very common, but the
design of such schemes for implicit time stepping is rare, and it had only been
attained so far for 1D problems. The proposed scheme is based on an artificial
diffusion that linearly depends on a shock detector that identifies the
troublesome areas. In order to define the new shock detector, we have
introduced the concept of discrete local extrema. The diffusion operator is a
graph-Laplacian, instead of the more common finite element discretization of
the Laplacian operator, which is essential to keep monotonicity on general
meshes and in multi-dimension. The resulting nonlinear stabilization is
non-smooth and nonlinear solvers can fail to converge. As a result, we propose
a smoothed (twice differentiable) version of the nonlinear stabilization, which
allows us to use Newton with line search nonlinear solvers and dramatically
improve nonlinear convergence. A theoretical numerical analysis of the proposed
schemes show that they satisfy the desired monotonicity properties. Further,
the resulting operator is Lipschitz continuous and there exists at least one
solution of the discrete problem, even in the non-smooth version. We provide a
set of numerical results to support our findings.
-
Tensors are a natural way to express correlations among many physical
variables, but storing tensors in a computer naively requires memory which
scales exponentially in the rank of the tensor. This is not optimal, as the
required memory is actually set not by the rank but by the mutual information
amongst the variables in question. Representations such as the tensor tree
perform near-optimally when the tree decomposition is chosen to reflect the
correlation structure in question, but making such a choice is non-trivial and
good heuristics remain highly context-specific. In this work I present two new
algorithms for choosing efficient tree decompositions, independent of the
physical context of the tensor. The first is a brute-force algorithm which
produces optimal decompositions up to truncation error but is generally
impractical for high-rank tensors, as the number of possible choices grows
exponentially in rank. The second is a greedy algorithm, and while it is not
optimal it performs extremely well in numerical experiments while having
runtime which makes it practical even for tensors of very high rank.
-
This work proposes a space-time least-squares Petrov-Galerkin (ST-LSPG)
projection method for model reduction of nonlinear dynamical systems. In
contrast to typical nonlinear model-reduction methods that first apply
(Petrov-)Galerkin projection in the spatial dimension and subsequently apply
time integration to numerically resolve the resulting low-dimensional dynamical
system, the proposed method applies projection in space and time
simultaneously. To accomplish this, the method first introduces a
low-dimensional space-time trial subspace, which can be obtained by computing
tensor decompositions of state-snapshot data. The method then computes
discrete-optimal approximations in this space-time trial subspace by minimizing
the residual arising after time discretization over all space and time in a
weighted $\ell^2$-norm. This norm can be defined to enable complexity reduction
(i.e., hyper-reduction) in time, which leads to space-time collocation and
space-time GNAT variants of the ST-LSPG method. Advantages of the approach
relative to typical spatial-projection-based nonlinear model reduction methods
such as Galerkin projection and least-squares Petrov-Galerkin projection
include: (1) a reduction of both the spatial and temporal dimensions of the
dynamical system, (2) the removal of spurious temporal modes (e.g., unstable
growth) from the state space, and (3) error bounds that exhibit slower growth
in time. Numerical examples performed on model problems in fluid dynamics
demonstrate the ability of the method to generate orders-of-magnitude
computational savings relative to spatial-projection-based reduced-order models
without sacrificing accuracy.
-
Numerical accuracy of floating point computation is a well studied topic
which has not made its way to the end-user in scientific computing. Yet, it has
become a critical issue with the recent requirements for code modernization to
harness new highly parallel hardware and perform higher resolution computation.
To democratize numerical accuracy analysis, it is important to propose tools
and methodologies to study large use cases in a reliable and automatic way. In
this paper, we propose verificarlo, an extension to the LLVM compiler to
automatically use Monte Carlo Arithmetic in a transparent way for the end-user.
It supports all the major languages including C, C++, and Fortran. Unlike
source-to-source approaches, our implementation captures the influence of
compiler optimizations on the numerical accuracy. We illustrate how Monte Carlo
Arithmetic using the verificarlo tool outperforms the existing approaches on
various use cases and is a step toward automatic numerical analysis.
-
Functions of one or more variables are usually approximated with a basis: a
complete, linearly-independent system of functions that spans a suitable
function space. The topic of this paper is the numerical approximation of
functions using the more general notion of frames: that is, complete systems
that are generally redundant but provide infinite representations with bounded
coefficients. While frames are well-known in image and signal processing,
coding theory and other areas of applied mathematics, their use in numerical
analysis is far less widespread. Yet, as we show via a series of examples,
frames are more flexible than bases, and can be constructed easily in a range
of problems where finding orthonormal bases with desirable properties (rapid
convergence, high resolution power, etc.) is difficult or impossible.
A key concern when using frames is that computing a best approximation
requires solving an ill-conditioned linear system. Nonetheless, we construct a
frame approximation via regularization with bounded condition number (with
respect to perturbations in the data), and which approximates any function up
to an error of order $\sqrt{\epsilon}$, or even of order $\epsilon$ with
suitable modifications. Here $\epsilon$ is a threshold value that can be chosen
by the user. Crucially, rate of decay of the error down to this level is
determined by the existence of approximate representations of $f$ in the frame
possessing small-norm coefficients. We demonstrate the existence of such
representations in all of our examples. Overall, our analysis suggests that
frames are a natural generalization of bases in which to develop numerical
approximation. In particular, even in the presence of severely ill-conditioned
linear systems, the frame condition imposes sufficient mathematical structure
in order to give rise to accurate, well-conditioned approximations.

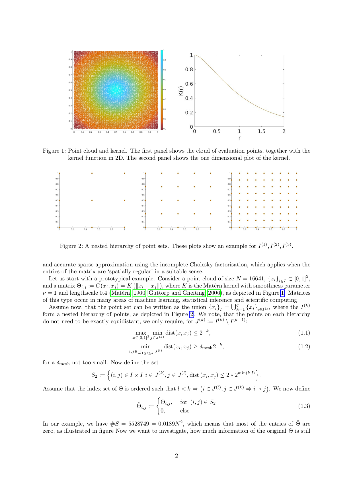
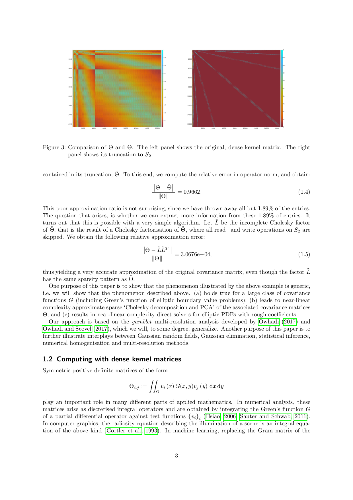

 Dense kernel matrices $\Theta \in \mathbb{R}^{N \times N}$ obtained from point evaluations of a covariance function $G$ at locations $\{ x_{i} \}_{1 \leq i \leq N} \subset \mathbb{R}^{d}$ arise in statistics, machine learning, and numerical analysis. For covariance functions that are Green's functions of elliptic boundary value problems and homogeneously-distributed sampling points, we show how to identify a subset $S \subset \{ 1 , \dots , N \}^2$, with $\# S = O ( N \log (N) \log^{d} ( N /\epsilon ) )$, such that the zero fill-in incomplete Cholesky factorisation of the sparse matrix $\Theta_{ij} 1_{( i, j ) \in S}$ is an $\epsilon$-approximation of $\Theta$. This factorisation can provably be obtained in complexity $O ( N \log( N ) \log^{d}( N /\epsilon) )$ in space and $O ( N \log^{2}( N ) \log^{2d}( N /\epsilon) )$ in time, improving upon the state of the art for general elliptic operators; we further present numerical evidence that $d$ can be taken to be the intrinsic dimension of the data set rather than that of the ambient space. The algorithm only needs to know the spatial configuration of the $x_{i}$ and does not require an analytic representation of $G$. Furthermore, this factorization straightforwardly provides an approximate sparse PCA with optimal rate of convergence in the operator norm. Hence, by using only subsampling and the incomplete Cholesky factorization, we obtain, at nearly linear complexity, the compression, inversion and approximate PCA of a large class of covariance matrices. By inverting the order of the Cholesky factorization we also obtain a solver for elliptic PDE with complexity $O ( N \log^{d}( N /\epsilon) )$ in space and $O ( N \log^{2d}( N /\epsilon) )$ in time, improving upon the state of the art for general elliptic operators.
Dense kernel matrices $\Theta \in \mathbb{R}^{N \times N}$ obtained from point evaluations of a covariance function $G$ at locations $\{ x_{i} \}_{1 \leq i \leq N} \subset \mathbb{R}^{d}$ arise in statistics, machine learning, and numerical analysis. For covariance functions that are Green's functions of elliptic boundary value problems and homogeneously-distributed sampling points, we show how to identify a subset $S \subset \{ 1 , \dots , N \}^2$, with $\# S = O ( N \log (N) \log^{d} ( N /\epsilon ) )$, such that the zero fill-in incomplete Cholesky factorisation of the sparse matrix $\Theta_{ij} 1_{( i, j ) \in S}$ is an $\epsilon$-approximation of $\Theta$. This factorisation can provably be obtained in complexity $O ( N \log( N ) \log^{d}( N /\epsilon) )$ in space and $O ( N \log^{2}( N ) \log^{2d}( N /\epsilon) )$ in time, improving upon the state of the art for general elliptic operators; we further present numerical evidence that $d$ can be taken to be the intrinsic dimension of the data set rather than that of the ambient space. The algorithm only needs to know the spatial configuration of the $x_{i}$ and does not require an analytic representation of $G$. Furthermore, this factorization straightforwardly provides an approximate sparse PCA with optimal rate of convergence in the operator norm. Hence, by using only subsampling and the incomplete Cholesky factorization, we obtain, at nearly linear complexity, the compression, inversion and approximate PCA of a large class of covariance matrices. By inverting the order of the Cholesky factorization we also obtain a solver for elliptic PDE with complexity $O ( N \log^{d}( N /\epsilon) )$ in space and $O ( N \log^{2d}( N /\epsilon) )$ in time, improving upon the state of the art for general elliptic operators.




 Algebraic multigrid (AMG) is often an effective solver for symmetric positive definite (SPD) linear systems resulting from the discretization of general elliptic PDEs, or the spatial discretization of parabolic PDEs. However, convergence theory and most variations of AMG rely on $A$ being SPD. Hyperbolic PDEs, which arise often in large-scale scientific simulations, remain a challenge for AMG, as well as other fast linear solvers, in part because the resulting linear systems are often highly nonsymmetric. Here, a novel convergence framework is developed for nonsymmetric, reduction-based AMG, and sufficient conditions derived for $\ell^2$-convergence of error and residual. In particular, classical multigrid approximation properties are connected with reduction-based measures to develop a robust framework for nonsymmetric, reduction-based AMG. Matrices with block-triangular structure are then recognized as being amenable to reduction-type algorithms, and a reduction-based AMG method is developed for upwind discretizations of hyperbolic PDEs, based on the concept of a Neumann approximation to ideal restriction ($n$AIR). $n$AIR can be seen as a variation of local AIR ($\ell$AIR) introduced in previous work, specifically targeting matrices with triangular structure. Although less versatile than $\ell$AIR, setup times for $n$AIR can be substantially faster for problems with high connectivity. $n$AIR is shown to be an effective and scalable solver of steady state transport for discontinuous, upwind discretizations, with unstructured meshes, and up to 6th-order finite elements, offering a significant improvement over existing AMG methods. $n$AIR is also shown to be effective on several classes of `nearly triangular' matrices, resulting from curvilinear finite elements and artificial diffusion.
Algebraic multigrid (AMG) is often an effective solver for symmetric positive definite (SPD) linear systems resulting from the discretization of general elliptic PDEs, or the spatial discretization of parabolic PDEs. However, convergence theory and most variations of AMG rely on $A$ being SPD. Hyperbolic PDEs, which arise often in large-scale scientific simulations, remain a challenge for AMG, as well as other fast linear solvers, in part because the resulting linear systems are often highly nonsymmetric. Here, a novel convergence framework is developed for nonsymmetric, reduction-based AMG, and sufficient conditions derived for $\ell^2$-convergence of error and residual. In particular, classical multigrid approximation properties are connected with reduction-based measures to develop a robust framework for nonsymmetric, reduction-based AMG. Matrices with block-triangular structure are then recognized as being amenable to reduction-type algorithms, and a reduction-based AMG method is developed for upwind discretizations of hyperbolic PDEs, based on the concept of a Neumann approximation to ideal restriction ($n$AIR). $n$AIR can be seen as a variation of local AIR ($\ell$AIR) introduced in previous work, specifically targeting matrices with triangular structure. Although less versatile than $\ell$AIR, setup times for $n$AIR can be substantially faster for problems with high connectivity. $n$AIR is shown to be an effective and scalable solver of steady state transport for discontinuous, upwind discretizations, with unstructured meshes, and up to 6th-order finite elements, offering a significant improvement over existing AMG methods. $n$AIR is also shown to be effective on several classes of `nearly triangular' matrices, resulting from curvilinear finite elements and artificial diffusion.




 Bayesian matrix factorization (BMF) is a powerful tool for producing low-rank representations of matrices and for predicting missing values and providing confidence intervals. Scaling up the posterior inference for massive-scale matrices is challenging and requires distributing both data and computation over many workers, making communication the main computational bottleneck. Embarrassingly parallel inference would remove the communication needed, by using completely independent computations on different data subsets, but it suffers from the inherent unidentifiability of BMF solutions. We introduce a hierarchical decomposition of the joint posterior distribution, which couples the subset inferences, allowing for embarrassingly parallel computations in a sequence of at most three stages. Using an efficient approximate implementation, we show improvements empirically on both real and simulated data. Our distributed approach is able to achieve a speed-up of almost an order of magnitude over the full posterior, with a negligible effect on predictive accuracy. Our method outperforms state-of-the-art embarrassingly parallel MCMC methods in accuracy, and achieves results competitive to other available distributed and parallel implementations of BMF.
Bayesian matrix factorization (BMF) is a powerful tool for producing low-rank representations of matrices and for predicting missing values and providing confidence intervals. Scaling up the posterior inference for massive-scale matrices is challenging and requires distributing both data and computation over many workers, making communication the main computational bottleneck. Embarrassingly parallel inference would remove the communication needed, by using completely independent computations on different data subsets, but it suffers from the inherent unidentifiability of BMF solutions. We introduce a hierarchical decomposition of the joint posterior distribution, which couples the subset inferences, allowing for embarrassingly parallel computations in a sequence of at most three stages. Using an efficient approximate implementation, we show improvements empirically on both real and simulated data. Our distributed approach is able to achieve a speed-up of almost an order of magnitude over the full posterior, with a negligible effect on predictive accuracy. Our method outperforms state-of-the-art embarrassingly parallel MCMC methods in accuracy, and achieves results competitive to other available distributed and parallel implementations of BMF.




 The conditioning of implicit Runge-Kutta (RK) integration for linear finite element approximation of diffusion equations on general anisotropic meshes is investigated. Bounds are established for the condition number of the resulting linear system with and without diagonal preconditioning for the implicit Euler and general implicit RK methods. Two solution strategies are considered for the linear system resulting from general implicit RK integration: the simultaneous solution (the system is solved as a whole) and a successive solution which follows the commonly used implementation of implicit RK methods to first transform the system into smaller systems using the Jordan normal form of the RK matrix and then solve them successively. For the simultaneous solution in case of a positive semidefinite symmetric part of the RK coefficient matrix and for the successive solution it is shown that . If the smallest eigenvalue of the symmetric part of the RK coefficient matrix is negative and the simultaneous solution strategy is used, an upper bound on the time step is given so that the system matrix is positive definite. The obtained bounds for the condition number have explicit geometric interpretations and take the interplay between the diffusion matrix and the mesh geometry into full consideration. They show that there are three mesh-dependent factors that can affect the conditioning: the number of elements, the mesh nonuniformity measured in the Euclidean metric, and the mesh nonuniformity with respect to the inverse of the diffusion matrix. They also reveal that the preconditioning using the diagonal of the system matrix, the mass matrix, or the lumped mass matrix can effectively eliminate the effects of the mesh nonuniformity measured in the Euclidean metric. Numerical examples are given.
The conditioning of implicit Runge-Kutta (RK) integration for linear finite element approximation of diffusion equations on general anisotropic meshes is investigated. Bounds are established for the condition number of the resulting linear system with and without diagonal preconditioning for the implicit Euler and general implicit RK methods. Two solution strategies are considered for the linear system resulting from general implicit RK integration: the simultaneous solution (the system is solved as a whole) and a successive solution which follows the commonly used implementation of implicit RK methods to first transform the system into smaller systems using the Jordan normal form of the RK matrix and then solve them successively. For the simultaneous solution in case of a positive semidefinite symmetric part of the RK coefficient matrix and for the successive solution it is shown that . If the smallest eigenvalue of the symmetric part of the RK coefficient matrix is negative and the simultaneous solution strategy is used, an upper bound on the time step is given so that the system matrix is positive definite. The obtained bounds for the condition number have explicit geometric interpretations and take the interplay between the diffusion matrix and the mesh geometry into full consideration. They show that there are three mesh-dependent factors that can affect the conditioning: the number of elements, the mesh nonuniformity measured in the Euclidean metric, and the mesh nonuniformity with respect to the inverse of the diffusion matrix. They also reveal that the preconditioning using the diagonal of the system matrix, the mass matrix, or the lumped mass matrix can effectively eliminate the effects of the mesh nonuniformity measured in the Euclidean metric. Numerical examples are given.




 We develop a framework that allows the use of the multi-level Monte Carlo (MLMC) methodology (Giles2015) to calculate expectations with respect to the invariant measure of an ergodic SDE. In that context, we study the (over-damped) Langevin equations with a strongly concave potential. We show that, when appropriate contracting couplings for the numerical integrators are available, one can obtain a uniform in time estimate of the MLMC variance in contrast to the majority of the results in the MLMC literature. As a consequence, a root mean square error of $\mathcal{O}(\varepsilon)$ is achieved with $\mathcal{O}(\varepsilon^{-2})$ complexity on par with Markov Chain Monte Carlo (MCMC) methods, which however can be computationally intensive when applied to large data sets. Finally, we present a multi-level version of the recently introduced Stochastic Gradient Langevin Dynamics (SGLD) method (Welling and Teh, 2011) built for large datasets applications. We show that this is the first stochastic gradient MCMC method with complexity $\mathcal{O}(\varepsilon^{-2}|\log {\varepsilon}|^{3})$, in contrast to the complexity $\mathcal{O}(\varepsilon^{-3})$ of currently available methods. Numerical experiments confirm our theoretical findings.
We develop a framework that allows the use of the multi-level Monte Carlo (MLMC) methodology (Giles2015) to calculate expectations with respect to the invariant measure of an ergodic SDE. In that context, we study the (over-damped) Langevin equations with a strongly concave potential. We show that, when appropriate contracting couplings for the numerical integrators are available, one can obtain a uniform in time estimate of the MLMC variance in contrast to the majority of the results in the MLMC literature. As a consequence, a root mean square error of $\mathcal{O}(\varepsilon)$ is achieved with $\mathcal{O}(\varepsilon^{-2})$ complexity on par with Markov Chain Monte Carlo (MCMC) methods, which however can be computationally intensive when applied to large data sets. Finally, we present a multi-level version of the recently introduced Stochastic Gradient Langevin Dynamics (SGLD) method (Welling and Teh, 2011) built for large datasets applications. We show that this is the first stochastic gradient MCMC method with complexity $\mathcal{O}(\varepsilon^{-2}|\log {\varepsilon}|^{3})$, in contrast to the complexity $\mathcal{O}(\varepsilon^{-3})$ of currently available methods. Numerical experiments confirm our theoretical findings.




 Deep neural networks have become invaluable tools for supervised machine learning, e.g., classification of text or images. While often offering superior results over traditional techniques and successfully expressing complicated patterns in data, deep architectures are known to be challenging to design and train such that they generalize well to new data. Important issues with deep architectures are numerical instabilities in derivative-based learning algorithms commonly called exploding or vanishing gradients. In this paper we propose new forward propagation techniques inspired by systems of Ordinary Differential Equations (ODE) that overcome this challenge and lead to well-posed learning problems for arbitrarily deep networks. The backbone of our approach is our interpretation of deep learning as a parameter estimation problem of nonlinear dynamical systems. Given this formulation, we analyze stability and well-posedness of deep learning and use this new understanding to develop new network architectures. We relate the exploding and vanishing gradient phenomenon to the stability of the discrete ODE and present several strategies for stabilizing deep learning for very deep networks. While our new architectures restrict the solution space, several numerical experiments show their competitiveness with state-of-the-art networks.
Deep neural networks have become invaluable tools for supervised machine learning, e.g., classification of text or images. While often offering superior results over traditional techniques and successfully expressing complicated patterns in data, deep architectures are known to be challenging to design and train such that they generalize well to new data. Important issues with deep architectures are numerical instabilities in derivative-based learning algorithms commonly called exploding or vanishing gradients. In this paper we propose new forward propagation techniques inspired by systems of Ordinary Differential Equations (ODE) that overcome this challenge and lead to well-posed learning problems for arbitrarily deep networks. The backbone of our approach is our interpretation of deep learning as a parameter estimation problem of nonlinear dynamical systems. Given this formulation, we analyze stability and well-posedness of deep learning and use this new understanding to develop new network architectures. We relate the exploding and vanishing gradient phenomenon to the stability of the discrete ODE and present several strategies for stabilizing deep learning for very deep networks. While our new architectures restrict the solution space, several numerical experiments show their competitiveness with state-of-the-art networks.




 In numerical time-integration with implicit-explicit (IMEX) methods, a within-step adaptable decomposition called residual balanced decomposition is introduced. With this decomposition, the requirement of a small enough residual in the iterative solver can be removed, consequently, this allows to exchange stability for efficiency. This decomposition transfers any residual occurring in the implicit equation of the implicit-step into the explicit part of the decomposition. By balancing the residual, the accuracy of the local truncation error of the time-stepping method becomes independent from the accuracy by which the implicit equation is solved. In order to balance the residual, the original IMEX decomposition is adjusted after the iterative solver has been stopped. For this to work, the traditional IMEX time-stepping algorithm needs to be changed. We call this new method the shortcut-IMEX (SIMEX). SIMEX can gain computational efficiency by exploring the trade-off between the computational effort placed in solving the implicit equation and the size of the numerically stable time-step. Typically, increasing the number of solver iterations increases the largest stable step-size. Both multi-step and Runge-Kutta (RK) methods are suitable for use with SIMEX. Here, we show the efficiency of a SIMEX-RK method in overcoming parabolic stiffness by applying it to a nonlinear reaction-advection-diffusion equation. In order to define a stability region for SIMEX, a region in the complex plane is depicted by applying SIMEX to a suitable PDE model containing diffusion and dispersion. A myriad of stability regions can be reached by changing the RK tableau and the solver.
In numerical time-integration with implicit-explicit (IMEX) methods, a within-step adaptable decomposition called residual balanced decomposition is introduced. With this decomposition, the requirement of a small enough residual in the iterative solver can be removed, consequently, this allows to exchange stability for efficiency. This decomposition transfers any residual occurring in the implicit equation of the implicit-step into the explicit part of the decomposition. By balancing the residual, the accuracy of the local truncation error of the time-stepping method becomes independent from the accuracy by which the implicit equation is solved. In order to balance the residual, the original IMEX decomposition is adjusted after the iterative solver has been stopped. For this to work, the traditional IMEX time-stepping algorithm needs to be changed. We call this new method the shortcut-IMEX (SIMEX). SIMEX can gain computational efficiency by exploring the trade-off between the computational effort placed in solving the implicit equation and the size of the numerically stable time-step. Typically, increasing the number of solver iterations increases the largest stable step-size. Both multi-step and Runge-Kutta (RK) methods are suitable for use with SIMEX. Here, we show the efficiency of a SIMEX-RK method in overcoming parabolic stiffness by applying it to a nonlinear reaction-advection-diffusion equation. In order to define a stability region for SIMEX, a region in the complex plane is depicted by applying SIMEX to a suitable PDE model containing diffusion and dispersion. A myriad of stability regions can be reached by changing the RK tableau and the solver.




 This report describes the computation of gradients by algorithmic differentiation for statistically optimum beamforming operations. Especially the derivation of complex-valued functions is a key component of this approach. Therefore the real-valued algorithmic differentiation is extended via the complex-valued chain rule. In addition to the basic mathematic operations the derivative of the eigenvalue problem with complex-valued eigenvectors is one of the key results of this report. The potential of this approach is shown with experimental results on the CHiME-3 challenge database. There, the beamforming task is used as a front-end for an ASR system. With the developed derivatives a joint optimization of a speech enhancement and speech recognition system w.r.t. the recognition optimization criterion is possible.
This report describes the computation of gradients by algorithmic differentiation for statistically optimum beamforming operations. Especially the derivation of complex-valued functions is a key component of this approach. Therefore the real-valued algorithmic differentiation is extended via the complex-valued chain rule. In addition to the basic mathematic operations the derivative of the eigenvalue problem with complex-valued eigenvectors is one of the key results of this report. The potential of this approach is shown with experimental results on the CHiME-3 challenge database. There, the beamforming task is used as a front-end for an ASR system. With the developed derivatives a joint optimization of a speech enhancement and speech recognition system w.r.t. the recognition optimization criterion is possible.




 In recent papers the author introduced a simple alternative to isoparametric finite elements of the n-simplex type, to enhance the accuracy of approximations of second-order boundary value problems with Dirichlet conditions, posed in smooth curved domains. This technique is based upon trial-functions consisting of piecewise polynomials defined on straight-edged triangular or tetrahedral meshes, interpolating the Dirichlet boundary conditions at points of the true boundary. In contrast the test-functions are defined upon the standard degrees of freedom associated with the underlying method for polytopic domains. While method's mathematical analysis for both second- and fourth-order problems in two-dimensional domains was carried out in arxiv NA-1701.00663 and in a submitted paper, this article is devoted to the study of the three-dimensional case, in which the method is nonconforming. Well-posedness, uniform stability and optimal a priori error estimates in the energy norm are demonstrated for a tetrahedron-based Lagrange family of finite elements. Novel L2-error estimates for the class of problems considered in this work are also proved. A series of numerical examples illustrates the potential of the new technique. In particular its better accuracy at equivalent cost as compared to the isoparametric technique is highlighted. Moreover the great generality of the new approach is exemplified through a method with degrees of freedom other than nodal values.
In recent papers the author introduced a simple alternative to isoparametric finite elements of the n-simplex type, to enhance the accuracy of approximations of second-order boundary value problems with Dirichlet conditions, posed in smooth curved domains. This technique is based upon trial-functions consisting of piecewise polynomials defined on straight-edged triangular or tetrahedral meshes, interpolating the Dirichlet boundary conditions at points of the true boundary. In contrast the test-functions are defined upon the standard degrees of freedom associated with the underlying method for polytopic domains. While method's mathematical analysis for both second- and fourth-order problems in two-dimensional domains was carried out in arxiv NA-1701.00663 and in a submitted paper, this article is devoted to the study of the three-dimensional case, in which the method is nonconforming. Well-posedness, uniform stability and optimal a priori error estimates in the energy norm are demonstrated for a tetrahedron-based Lagrange family of finite elements. Novel L2-error estimates for the class of problems considered in this work are also proved. A series of numerical examples illustrates the potential of the new technique. In particular its better accuracy at equivalent cost as compared to the isoparametric technique is highlighted. Moreover the great generality of the new approach is exemplified through a method with degrees of freedom other than nodal values.




 We propose a semantics of operating on real numbers that is sound, Turing-complete, and practical. It modifies the intuitive but super-recursive Blum-Shub-Smale model (formalizing Computer ALGEBRA Systems), to coincide in power with the realistic but inconvenient Type-2 Turing machine underlying Computable Analysis: reconciling both as foundation to a Computer ANALYSIS System. Several examples illustrate the elegance of rigorous numerical coding in this framework, formalized as a simple imperative programming language ERC with denotational semantics for REALIZING a real function $f$: arguments $x$ are given as exact real numbers, while values $y=f(x)$ suffice to be returned approximately up to absolute error $2^p$ with respect to an additionally given integer parameter $p\to-\infty$. Real comparison (necessarily) becomes partial, possibly 'returning' the lazy Kleenean value UNDEF (subtly different from $\bot$ for classically undefined expressions like 1/0). This asserts closure under composition, and in fact 'Turing-completeness over the reals': All and only functions computable in the sense of Computable Analysis can be realized in ERC. Programs thus operate on a many-sorted structure involving real numbers and integers, connected via the 'error' embedding $Z\ni p\mapsto 2^p\in R$, whose first-order theory is proven decidable and model-complete. This logic serves for formally specifying and formally verifying correctness of ERC programs. We finally expand ERC and its Turing-completeness from real functions to functionALs.
We propose a semantics of operating on real numbers that is sound, Turing-complete, and practical. It modifies the intuitive but super-recursive Blum-Shub-Smale model (formalizing Computer ALGEBRA Systems), to coincide in power with the realistic but inconvenient Type-2 Turing machine underlying Computable Analysis: reconciling both as foundation to a Computer ANALYSIS System. Several examples illustrate the elegance of rigorous numerical coding in this framework, formalized as a simple imperative programming language ERC with denotational semantics for REALIZING a real function $f$: arguments $x$ are given as exact real numbers, while values $y=f(x)$ suffice to be returned approximately up to absolute error $2^p$ with respect to an additionally given integer parameter $p\to-\infty$. Real comparison (necessarily) becomes partial, possibly 'returning' the lazy Kleenean value UNDEF (subtly different from $\bot$ for classically undefined expressions like 1/0). This asserts closure under composition, and in fact 'Turing-completeness over the reals': All and only functions computable in the sense of Computable Analysis can be realized in ERC. Programs thus operate on a many-sorted structure involving real numbers and integers, connected via the 'error' embedding $Z\ni p\mapsto 2^p\in R$, whose first-order theory is proven decidable and model-complete. This logic serves for formally specifying and formally verifying correctness of ERC programs. We finally expand ERC and its Turing-completeness from real functions to functionALs.


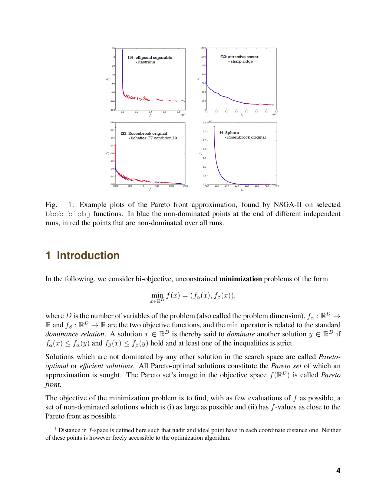

 Several test function suites are being used for numerical benchmarking of multiobjective optimization algorithms. While they have some desirable properties, like well-understood Pareto sets and Pareto fronts of various shapes, most of the currently used functions possess characteristics that are arguably under-represented in real-world problems. They mainly stem from the easier construction of such functions and result in improbable properties such as separability, optima located exactly at the boundary constraints, and the existence of variables that solely control the distance between a solution and the Pareto front. Here, we propose an alternative way to constructing multiobjective problems-by combining existing single-objective problems from the literature. We describe in particular the bbob-biobj test suite with 55 bi-objective functions in continuous domain, and its extended version with 92 bi-objective functions (bbob-biobj-ext). Both test suites have been implemented in the COCO platform for black-box optimization benchmarking. Finally, we recommend a general procedure for creating test suites for an arbitrary number of objectives. Besides providing the formal function definitions and presenting their (known) properties, this paper also aims at giving the rationale behind our approach in terms of groups of functions with similar properties, objective space normalization, and problem instances. The latter allows us to easily compare the performance of deterministic and stochastic solvers, which is an often overlooked issue in benchmarking.
Several test function suites are being used for numerical benchmarking of multiobjective optimization algorithms. While they have some desirable properties, like well-understood Pareto sets and Pareto fronts of various shapes, most of the currently used functions possess characteristics that are arguably under-represented in real-world problems. They mainly stem from the easier construction of such functions and result in improbable properties such as separability, optima located exactly at the boundary constraints, and the existence of variables that solely control the distance between a solution and the Pareto front. Here, we propose an alternative way to constructing multiobjective problems-by combining existing single-objective problems from the literature. We describe in particular the bbob-biobj test suite with 55 bi-objective functions in continuous domain, and its extended version with 92 bi-objective functions (bbob-biobj-ext). Both test suites have been implemented in the COCO platform for black-box optimization benchmarking. Finally, we recommend a general procedure for creating test suites for an arbitrary number of objectives. Besides providing the formal function definitions and presenting their (known) properties, this paper also aims at giving the rationale behind our approach in terms of groups of functions with similar properties, objective space normalization, and problem instances. The latter allows us to easily compare the performance of deterministic and stochastic solvers, which is an often overlooked issue in benchmarking.




 We study and develop (stochastic) primal--dual block-coordinate descent methods for convex problems based on the method due to Chambolle and Pock. Our methods have known convergence rates for the iterates and the ergodic gap: $O(1/N^2)$ if each block is strongly convex, $O(1/N)$ if no convexity is present, and more generally a mixed rate $O(1/N^2)+O(1/N)$ for strongly convex blocks, if only some blocks are strongly convex. Additional novelties of our methods include blockwise-adapted step lengths and acceleration, as well as the ability to update both the primal and dual variables randomly in blocks under a very light compatibility condition. In other words, these variants of our methods are doubly-stochastic. We test the proposed methods on various image processing problems, where we employ pixelwise-adapted acceleration.
We study and develop (stochastic) primal--dual block-coordinate descent methods for convex problems based on the method due to Chambolle and Pock. Our methods have known convergence rates for the iterates and the ergodic gap: $O(1/N^2)$ if each block is strongly convex, $O(1/N)$ if no convexity is present, and more generally a mixed rate $O(1/N^2)+O(1/N)$ for strongly convex blocks, if only some blocks are strongly convex. Additional novelties of our methods include blockwise-adapted step lengths and acceleration, as well as the ability to update both the primal and dual variables randomly in blocks under a very light compatibility condition. In other words, these variants of our methods are doubly-stochastic. We test the proposed methods on various image processing problems, where we employ pixelwise-adapted acceleration.




 This paper summarizes the development of Veamy, an object-oriented C++ library for the virtual element method (VEM) on general polygonal meshes, whose modular design is focused on its extensibility. The linear elastostatic and Poisson problems in two dimensions have been chosen as the starting stage for the development of this library. The theory of the VEM, upon which Veamy is built, is presented using a notation and a terminology that resemble the language of the finite element method (FEM) in engineering analysis. Several examples are provided to demonstrate the usage of Veamy, and in particular, one of them features the interaction between Veamy and the polygonal mesh generator PolyMesher. A computational performance comparison between VEM and FEM is also conducted. Veamy is free and open source software.
This paper summarizes the development of Veamy, an object-oriented C++ library for the virtual element method (VEM) on general polygonal meshes, whose modular design is focused on its extensibility. The linear elastostatic and Poisson problems in two dimensions have been chosen as the starting stage for the development of this library. The theory of the VEM, upon which Veamy is built, is presented using a notation and a terminology that resemble the language of the finite element method (FEM) in engineering analysis. Several examples are provided to demonstrate the usage of Veamy, and in particular, one of them features the interaction between Veamy and the polygonal mesh generator PolyMesher. A computational performance comparison between VEM and FEM is also conducted. Veamy is free and open source software.




 This work studies the linear approximation of high-dimensional dynamical systems using low-rank dynamic mode decomposition (DMD). Searching this approximation in a data-driven approach is formalised as attempting to solve a low-rank constrained optimisation problem. This problem is non-convex and state-of-the-art algorithms are all sub-optimal. This paper shows that there exists a closed-form solution, which is computed in polynomial time, and characterises the l2-norm of the optimal approximation error. The paper also proposes low-complexity algorithms building reduced models from this optimal solution, based on singular value decomposition or eigen value decomposition. The algorithms are evaluated by numerical simulations using synthetic and physical data benchmarks.
This work studies the linear approximation of high-dimensional dynamical systems using low-rank dynamic mode decomposition (DMD). Searching this approximation in a data-driven approach is formalised as attempting to solve a low-rank constrained optimisation problem. This problem is non-convex and state-of-the-art algorithms are all sub-optimal. This paper shows that there exists a closed-form solution, which is computed in polynomial time, and characterises the l2-norm of the optimal approximation error. The paper also proposes low-complexity algorithms building reduced models from this optimal solution, based on singular value decomposition or eigen value decomposition. The algorithms are evaluated by numerical simulations using synthetic and physical data benchmarks.




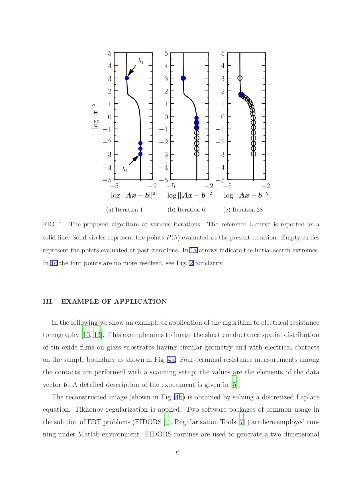 We propose a simple algorithm to locate the "corner" of an L-curve, a function often used to select the regularisation parameter for the solution of ill-posed inverse problems. The algorithm involves the Menger curvature of a circumcircle and the golden section search method. It efficiently finds the regularisation parameter value corresponding to the maximum positive curvature region of the L-curve. The algorithm is applied to some commonly available test problems and compared to the typical way of locating the l-curve corner by means of its analytical curvature. The application of the algorithm to the data processing of an electrical resistance tomography experiment on thin conductive films is also reported.
We propose a simple algorithm to locate the "corner" of an L-curve, a function often used to select the regularisation parameter for the solution of ill-posed inverse problems. The algorithm involves the Menger curvature of a circumcircle and the golden section search method. It efficiently finds the regularisation parameter value corresponding to the maximum positive curvature region of the L-curve. The algorithm is applied to some commonly available test problems and compared to the typical way of locating the l-curve corner by means of its analytical curvature. The application of the algorithm to the data processing of an electrical resistance tomography experiment on thin conductive films is also reported.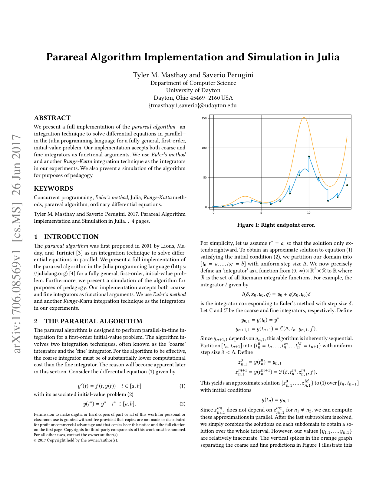

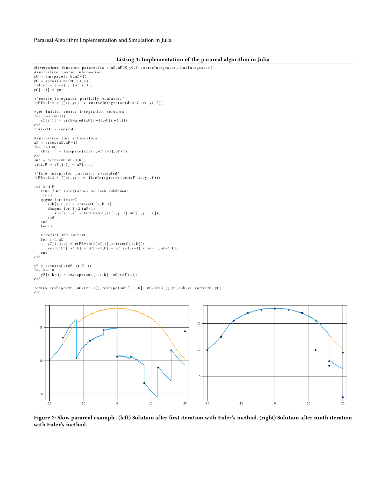


 We present a full implementation of the parareal algorithm---an integration technique to solve differential equations in parallel---in the Julia programming language for a fully general, first-order, initial-value problem. We provide a brief overview of Julia---a concurrent programming language for scientific computing. Our implementation of the parareal algorithm accepts both coarse and fine integrators as functional arguments. We use Euler's method and another Runge-Kutta integration technique as the integrators in our experiments. We also present a simulation of the algorithm for purposes of pedagogy and as a tool for investigating the performance of the algorithm.
We present a full implementation of the parareal algorithm---an integration technique to solve differential equations in parallel---in the Julia programming language for a fully general, first-order, initial-value problem. We provide a brief overview of Julia---a concurrent programming language for scientific computing. Our implementation of the parareal algorithm accepts both coarse and fine integrators as functional arguments. We use Euler's method and another Runge-Kutta integration technique as the integrators in our experiments. We also present a simulation of the algorithm for purposes of pedagogy and as a tool for investigating the performance of the algorithm.




 This work is devoted to the design of interior penalty discontinuous Galerkin (dG) schemes that preserve maximum principles at the discrete level for the steady transport and convection-diffusion problems and the respective transient problems with implicit time integration. Monotonic schemes that combine explicit time stepping with dG space discretization are very common, but the design of such schemes for implicit time stepping is rare, and it had only been attained so far for 1D problems. The proposed scheme is based on an artificial diffusion that linearly depends on a shock detector that identifies the troublesome areas. In order to define the new shock detector, we have introduced the concept of discrete local extrema. The diffusion operator is a graph-Laplacian, instead of the more common finite element discretization of the Laplacian operator, which is essential to keep monotonicity on general meshes and in multi-dimension. The resulting nonlinear stabilization is non-smooth and nonlinear solvers can fail to converge. As a result, we propose a smoothed (twice differentiable) version of the nonlinear stabilization, which allows us to use Newton with line search nonlinear solvers and dramatically improve nonlinear convergence. A theoretical numerical analysis of the proposed schemes show that they satisfy the desired monotonicity properties. Further, the resulting operator is Lipschitz continuous and there exists at least one solution of the discrete problem, even in the non-smooth version. We provide a set of numerical results to support our findings.
This work is devoted to the design of interior penalty discontinuous Galerkin (dG) schemes that preserve maximum principles at the discrete level for the steady transport and convection-diffusion problems and the respective transient problems with implicit time integration. Monotonic schemes that combine explicit time stepping with dG space discretization are very common, but the design of such schemes for implicit time stepping is rare, and it had only been attained so far for 1D problems. The proposed scheme is based on an artificial diffusion that linearly depends on a shock detector that identifies the troublesome areas. In order to define the new shock detector, we have introduced the concept of discrete local extrema. The diffusion operator is a graph-Laplacian, instead of the more common finite element discretization of the Laplacian operator, which is essential to keep monotonicity on general meshes and in multi-dimension. The resulting nonlinear stabilization is non-smooth and nonlinear solvers can fail to converge. As a result, we propose a smoothed (twice differentiable) version of the nonlinear stabilization, which allows us to use Newton with line search nonlinear solvers and dramatically improve nonlinear convergence. A theoretical numerical analysis of the proposed schemes show that they satisfy the desired monotonicity properties. Further, the resulting operator is Lipschitz continuous and there exists at least one solution of the discrete problem, even in the non-smooth version. We provide a set of numerical results to support our findings.




 Tensors are a natural way to express correlations among many physical variables, but storing tensors in a computer naively requires memory which scales exponentially in the rank of the tensor. This is not optimal, as the required memory is actually set not by the rank but by the mutual information amongst the variables in question. Representations such as the tensor tree perform near-optimally when the tree decomposition is chosen to reflect the correlation structure in question, but making such a choice is non-trivial and good heuristics remain highly context-specific. In this work I present two new algorithms for choosing efficient tree decompositions, independent of the physical context of the tensor. The first is a brute-force algorithm which produces optimal decompositions up to truncation error but is generally impractical for high-rank tensors, as the number of possible choices grows exponentially in rank. The second is a greedy algorithm, and while it is not optimal it performs extremely well in numerical experiments while having runtime which makes it practical even for tensors of very high rank.
Tensors are a natural way to express correlations among many physical variables, but storing tensors in a computer naively requires memory which scales exponentially in the rank of the tensor. This is not optimal, as the required memory is actually set not by the rank but by the mutual information amongst the variables in question. Representations such as the tensor tree perform near-optimally when the tree decomposition is chosen to reflect the correlation structure in question, but making such a choice is non-trivial and good heuristics remain highly context-specific. In this work I present two new algorithms for choosing efficient tree decompositions, independent of the physical context of the tensor. The first is a brute-force algorithm which produces optimal decompositions up to truncation error but is generally impractical for high-rank tensors, as the number of possible choices grows exponentially in rank. The second is a greedy algorithm, and while it is not optimal it performs extremely well in numerical experiments while having runtime which makes it practical even for tensors of very high rank.




 This work proposes a space-time least-squares Petrov-Galerkin (ST-LSPG) projection method for model reduction of nonlinear dynamical systems. In contrast to typical nonlinear model-reduction methods that first apply (Petrov-)Galerkin projection in the spatial dimension and subsequently apply time integration to numerically resolve the resulting low-dimensional dynamical system, the proposed method applies projection in space and time simultaneously. To accomplish this, the method first introduces a low-dimensional space-time trial subspace, which can be obtained by computing tensor decompositions of state-snapshot data. The method then computes discrete-optimal approximations in this space-time trial subspace by minimizing the residual arising after time discretization over all space and time in a weighted $\ell^2$-norm. This norm can be defined to enable complexity reduction (i.e., hyper-reduction) in time, which leads to space-time collocation and space-time GNAT variants of the ST-LSPG method. Advantages of the approach relative to typical spatial-projection-based nonlinear model reduction methods such as Galerkin projection and least-squares Petrov-Galerkin projection include: (1) a reduction of both the spatial and temporal dimensions of the dynamical system, (2) the removal of spurious temporal modes (e.g., unstable growth) from the state space, and (3) error bounds that exhibit slower growth in time. Numerical examples performed on model problems in fluid dynamics demonstrate the ability of the method to generate orders-of-magnitude computational savings relative to spatial-projection-based reduced-order models without sacrificing accuracy.
This work proposes a space-time least-squares Petrov-Galerkin (ST-LSPG) projection method for model reduction of nonlinear dynamical systems. In contrast to typical nonlinear model-reduction methods that first apply (Petrov-)Galerkin projection in the spatial dimension and subsequently apply time integration to numerically resolve the resulting low-dimensional dynamical system, the proposed method applies projection in space and time simultaneously. To accomplish this, the method first introduces a low-dimensional space-time trial subspace, which can be obtained by computing tensor decompositions of state-snapshot data. The method then computes discrete-optimal approximations in this space-time trial subspace by minimizing the residual arising after time discretization over all space and time in a weighted $\ell^2$-norm. This norm can be defined to enable complexity reduction (i.e., hyper-reduction) in time, which leads to space-time collocation and space-time GNAT variants of the ST-LSPG method. Advantages of the approach relative to typical spatial-projection-based nonlinear model reduction methods such as Galerkin projection and least-squares Petrov-Galerkin projection include: (1) a reduction of both the spatial and temporal dimensions of the dynamical system, (2) the removal of spurious temporal modes (e.g., unstable growth) from the state space, and (3) error bounds that exhibit slower growth in time. Numerical examples performed on model problems in fluid dynamics demonstrate the ability of the method to generate orders-of-magnitude computational savings relative to spatial-projection-based reduced-order models without sacrificing accuracy.


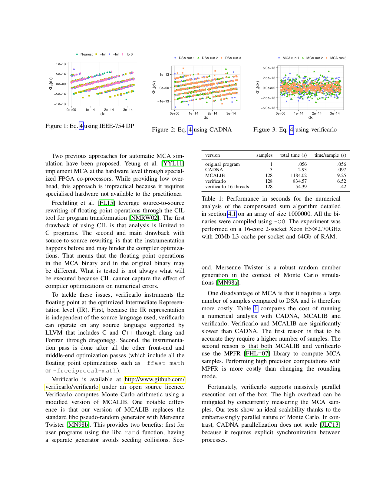

 Numerical accuracy of floating point computation is a well studied topic which has not made its way to the end-user in scientific computing. Yet, it has become a critical issue with the recent requirements for code modernization to harness new highly parallel hardware and perform higher resolution computation. To democratize numerical accuracy analysis, it is important to propose tools and methodologies to study large use cases in a reliable and automatic way. In this paper, we propose verificarlo, an extension to the LLVM compiler to automatically use Monte Carlo Arithmetic in a transparent way for the end-user. It supports all the major languages including C, C++, and Fortran. Unlike source-to-source approaches, our implementation captures the influence of compiler optimizations on the numerical accuracy. We illustrate how Monte Carlo Arithmetic using the verificarlo tool outperforms the existing approaches on various use cases and is a step toward automatic numerical analysis.
Numerical accuracy of floating point computation is a well studied topic which has not made its way to the end-user in scientific computing. Yet, it has become a critical issue with the recent requirements for code modernization to harness new highly parallel hardware and perform higher resolution computation. To democratize numerical accuracy analysis, it is important to propose tools and methodologies to study large use cases in a reliable and automatic way. In this paper, we propose verificarlo, an extension to the LLVM compiler to automatically use Monte Carlo Arithmetic in a transparent way for the end-user. It supports all the major languages including C, C++, and Fortran. Unlike source-to-source approaches, our implementation captures the influence of compiler optimizations on the numerical accuracy. We illustrate how Monte Carlo Arithmetic using the verificarlo tool outperforms the existing approaches on various use cases and is a step toward automatic numerical analysis.




 Functions of one or more variables are usually approximated with a basis: a complete, linearly-independent system of functions that spans a suitable function space. The topic of this paper is the numerical approximation of functions using the more general notion of frames: that is, complete systems that are generally redundant but provide infinite representations with bounded coefficients. While frames are well-known in image and signal processing, coding theory and other areas of applied mathematics, their use in numerical analysis is far less widespread. Yet, as we show via a series of examples, frames are more flexible than bases, and can be constructed easily in a range of problems where finding orthonormal bases with desirable properties (rapid convergence, high resolution power, etc.) is difficult or impossible. A key concern when using frames is that computing a best approximation requires solving an ill-conditioned linear system. Nonetheless, we construct a frame approximation via regularization with bounded condition number (with respect to perturbations in the data), and which approximates any function up to an error of order $\sqrt{\epsilon}$, or even of order $\epsilon$ with suitable modifications. Here $\epsilon$ is a threshold value that can be chosen by the user. Crucially, rate of decay of the error down to this level is determined by the existence of approximate representations of $f$ in the frame possessing small-norm coefficients. We demonstrate the existence of such representations in all of our examples. Overall, our analysis suggests that frames are a natural generalization of bases in which to develop numerical approximation. In particular, even in the presence of severely ill-conditioned linear systems, the frame condition imposes sufficient mathematical structure in order to give rise to accurate, well-conditioned approximations.
Functions of one or more variables are usually approximated with a basis: a complete, linearly-independent system of functions that spans a suitable function space. The topic of this paper is the numerical approximation of functions using the more general notion of frames: that is, complete systems that are generally redundant but provide infinite representations with bounded coefficients. While frames are well-known in image and signal processing, coding theory and other areas of applied mathematics, their use in numerical analysis is far less widespread. Yet, as we show via a series of examples, frames are more flexible than bases, and can be constructed easily in a range of problems where finding orthonormal bases with desirable properties (rapid convergence, high resolution power, etc.) is difficult or impossible. A key concern when using frames is that computing a best approximation requires solving an ill-conditioned linear system. Nonetheless, we construct a frame approximation via regularization with bounded condition number (with respect to perturbations in the data), and which approximates any function up to an error of order $\sqrt{\epsilon}$, or even of order $\epsilon$ with suitable modifications. Here $\epsilon$ is a threshold value that can be chosen by the user. Crucially, rate of decay of the error down to this level is determined by the existence of approximate representations of $f$ in the frame possessing small-norm coefficients. We demonstrate the existence of such representations in all of our examples. Overall, our analysis suggests that frames are a natural generalization of bases in which to develop numerical approximation. In particular, even in the presence of severely ill-conditioned linear systems, the frame condition imposes sufficient mathematical structure in order to give rise to accurate, well-conditioned approximations.