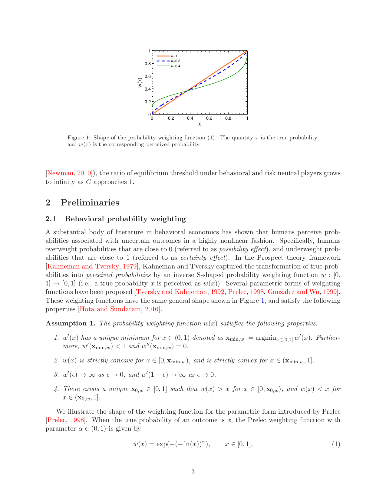
-
We consider the problem of stopping a diffusion process with a payoff
functional that renders the problem time-inconsistent. We study stopping
decisions of naive agents who reoptimize continuously in time, as well as
equilibrium strategies of sophisticated agents who anticipate but lack control
over their future selves' behaviors. When the state process is one dimensional
and the payoff functional satisfies some regularity conditions, we prove that
any equilibrium can be obtained as a fixed point of an operator. This operator
represents strategic reasoning that takes the future selves' behaviors into
account. We then apply the general results to the case when the agents distort
probability and the diffusion process is a geometric Brownian motion. The
problem is inherently time-inconsistent as the level of distortion of a same
event changes over time. We show how the strategic reasoning may turn a naive
agent into a sophisticated one. Moreover, we derive stopping strategies of the
two types of agent for various parameter specifications of the problem,
illustrating rich behaviors beyond the extreme ones such as "never-stopping" or
"never-starting".
-
We model learning in a continuous-time Brownian setting where there is prior
ambiguity. The associated model of preference values robustness and is
time-consistent. It is applied to study optimal learning when the choice
between actions can be postponed, at a per-unit-time cost, in order to observe
a signal that provides information about an unknown parameter. The
corresponding optimal stopping problem is solved in closed-form, with a focus
on two specific settings: Ellsberg's two-urn thought experiment expanded to
allow learning before the choice of bets, and a robust version of the classical
problem of sequential testing of two simple hypotheses about the unknown drift
of a Wiener process. In both cases, the link between robustness and the demand
for learning is studied.
-
We study decentralized protection strategies against
Susceptible-Infected-Susceptible (SIS) epidemics on networks. We consider a
population game framework where nodes choose whether or not to vaccinate
themselves, and the epidemic risk is defined as the infection probability at
the endemic state of the epidemic under a degree-based mean-field
approximation. Motivated by studies in behavioral economics showing that humans
perceive probabilities and risks in a nonlinear fashion, we specifically
examine the impacts of such misperceptions on the Nash equilibrium protection
strategies. We first establish the existence and uniqueness of a threshold
equilibrium where nodes with degrees larger than a certain threshold vaccinate.
When the vaccination cost is sufficiently high, we show that behavioral biases
cause fewer players to vaccinate, and vice versa. We quantify this effect for a
class of networks with power-law degree distributions by proving tight bounds
on the ratio of equilibrium thresholds under behavioral and true perceptions of
probabilities. We further characterize the socially optimal vaccination policy
and investigate the inefficiency of Nash equilibrium.
-
How do macro-financial shocks affect investor behavior and market dynamics?
Recent evidence on experience effects suggests a long-lasting influence of
personally experienced outcomes on investor beliefs and investment, but also
significant differences across older and younger generations. We formalize
experience-based learning in an OLG model, where different cross-cohort
experiences generate persistent heterogeneity in beliefs, portfolio choices,
and trade. The model allows us to characterize a novel link between investor
demographics and the dependence of prices on past dividends, while also
generating known features of asset prices, such as excess volatility and return
predictability. The model produces new implications for the cross-section of
asset holdings, trade volume, and investors' heterogenous responses to recent
financial crises, which we show to be in line with the data.
-
We reconsider the microeconomic foundations of financial economics. Motivated
by the importance of Knightian Uncertainty in markets, we present a model that
does not carry any probabilistic structure ex ante, yet is based on a common
order. We derive the fundamental equivalence of economic viability of asset
prices and absence of arbitrage. We also obtain a modified version of the
Fundamental Theorem of Asset Pricing using the notion of sublinear pricing
measures. Different versions of the Efficient Market Hypothesis are related to
the assumptions one is willing to impose on the common order.
-
In Chinese societies, superstition is of paramount importance, and vehicle
license plates with desirable numbers can fetch very high prices in auctions.
Unlike other valuable items, license plates are not allocated an estimated
price before auction. I propose that the task of predicting plate prices can be
viewed as a natural language processing (NLP) task, as the value depends on the
meaning of each individual character on the plate and its semantics. I
construct a deep recurrent neural network (RNN) to predict the prices of
vehicle license plates in Hong Kong, based on the characters on a plate. I
demonstrate the importance of having a deep network and of retraining.
Evaluated on 13 years of historical auction prices, the deep RNN's predictions
can explain over 80 percent of price variations, outperforming previous models
by a significant margin. I also demonstrate how the model can be extended to
become a search engine for plates and to provide estimates of the expected
price distribution.
-
The structure of the International Trade Network (ITN), whose nodes and links
represent world countries and their trade relations respectively, affects key
economic processes worldwide, including globalization, economic integration,
industrial production, and the propagation of shocks and instabilities.
Characterizing the ITN via a simple yet accurate model is an open problem. The
traditional Gravity Model (GM) successfully reproduces the volume of trade
between connected countries, using macroeconomic properties such as GDP,
geographic distance, and possibly other factors. However, it predicts a network
with complete or homogeneous topology, thus failing to reproduce the highly
heterogeneous structure of the ITN. On the other hand, recent maximum-entropy
network models successfully reproduce the complex topology of the ITN, but
provide no information about trade volumes. Here we integrate these two
currently incompatible approaches via the introduction of an Enhanced Gravity
Model (EGM) of trade. The EGM is the simplest model combining the GM with the
network approach within a maximum-entropy framework. Via a unified and
principled mechanism that is transparent enough to be generalized to any
economic network, the EGM provides a new econometric framework wherein trade
probabilities and trade volumes can be separately controlled by any combination
of dyadic and country-specific macroeconomic variables. The model successfully
reproduces both the global topology and the local link weights of the ITN,
parsimoniously reconciling the conflicting approaches. It also indicates that
the probability that any two countries trade a certain volume should follow a
geometric or exponential distribution with an additional point mass at zero
volume.
-
In this paper, we extend the optimal securitisation model of Pag\`es [50] and
Possama\"i and Pag\`es [51] between an investor and a bank to a setting
allowing both moral hazard and adverse selection. Following the recent approach
to these problems of Cvitani\'c, Wan and Yang [14], we characterise explicitly
and rigorously the so-called credible set of the continuation and temptation
values of the bank, and obtain the value function of the investor as well as
the optimal contracts through a recursive system of first-order variational
inequalities with gradient constraints. We provide a detailed discussion of the
properties of the optimal menu of contracts.
-
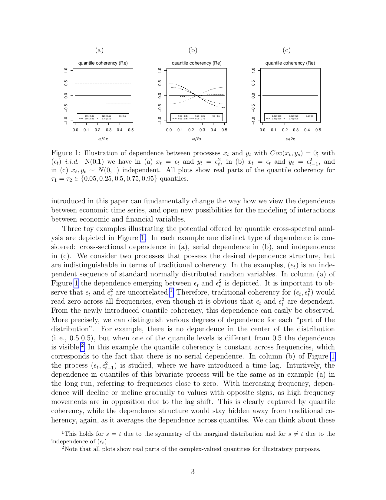
In this paper, we introduce quantile coherency to measure general dependence
structures emerging in the joint distribution in the frequency domain and argue
that this type of dependence is natural for economic time series but remains
invisible when only the traditional analysis is employed. We define estimators
which capture the general dependence structure, provide a detailed analysis of
their asymptotic properties and discuss how to conduct inference for a general
class of possibly nonlinear processes. In an empirical illustration we examine
the dependence of bivariate stock market returns and shed new light on
measurement of tail risk in financial markets. We also provide a modelling
exercise to illustrate how applied researchers can benefit from using quantile
coherency when assessing time series models.
-
A set of data with positive values follows a Pareto distribution if the
log-log plot of value versus rank is approximately a straight line. A Pareto
distribution satisfies Zipf's law if the log-log plot has a slope of -1. Since
many types of ranked data follow Zipf's law, it is considered a form of
universality. We propose a mathematical explanation for this phenomenon based
on Atlas models and first-order models, systems of positive continuous
semimartingales with parameters that depend only on rank. We show that the
stable distribution of an Atlas model will follow Zipf's law if and only if two
natural conditions, conservation and completeness, are satisfied. Since Atlas
models and first-order models can be constructed to approximate systems of
time-dependent rank-based data, our results can explain the universality of
Zipf's law for such systems. However, ranked data generated by other means may
follow non-Zipfian Pareto distributions. Hence, our results explain why Zipf's
law holds for word frequency, firm size, household wealth, and city size, while
it does not hold for earthquake magnitude, cumulative book sales, the intensity
of solar flares, and the intensity of wars, all of which follow non-Zipfian
Pareto distributions.
-
This paper provides a comprehensive analysis of welfare measures when
oligopolistic firms face multiple policy interventions and external changes
under general forms of market demands, production costs, and imperfect
competition. We present our results in terms of two welfare measures, namely,
marginal cost of public funds and incidence, in relation to multi-dimensional
pass-through. Our arguments are best understood with two-dimensional taxation
where homogeneous firms face unit and ad valorem taxes. The first part of the
paper studies this leading case. We show, e.g., that there exists a simple and
empirically relevant set of sufficient statistics for the marginal cost of
public funds, namely unit tax and ad valorem pass-through and industry demand
elasticity. We then specialize our general setting to the case of price or
quantity competition and show how the marginal cost of public funds and the
pass-through are expressed using elasticities and curvatures of regular and
inverse demands. Based on the results of the leading case, the second part of
the paper presents a generalization with the tax revenue function specified as
a general function parameterized by a vector of multi-dimensional tax
parameters. We then argue that our results are carried over to the case of
heterogeneous firms and other extensions.
-
This paper studies models in which hypothesis tests have trivial power, that
is, power smaller than size. This testing impossibility, or impossibility type
A, arises when any alternative is not distinguishable from the null. We also
study settings in which it is impossible to have almost surely bounded
confidence sets for a parameter of interest. This second type of impossibility
(type B) occurs under a condition weaker than the condition for type A
impossibility: the parameter of interest must be nearly unidentified. Our
theoretical framework connects many existing publications on impossible
inference that rely on different notions of topologies to show models are not
distinguishable or nearly unidentified. We also derive both types of
impossibility using the weak topology induced by convergence in distribution.
Impossibility in the weak topology is often easier to prove, it is applicable
for many widely-used tests, and it is useful for robust hypothesis testing. We
conclude by demonstrating impossible inference in multiple economic
applications of models with discontinuity and time-series models.
-
We consider a general nonzero-sum impulse game with two players. The main
mathematical contribution of the paper is a verification theorem which
provides, under some regularity conditions, a suitable system of
quasi-variational inequalities for the value functions and the optimal
strategies of the two players. As an application, we study an impulse game with
a one-dimensional state variable, following a real-valued scaled Brownian
motion, and two players with linear and symmetric running payoffs. We fully
characterize a Nash equilibrium and provide explicit expressions for the
optimal strategies and the value functions. We also prove some asymptotic
results with respect to the intervention costs. Finally, we consider two
further non-symmetric examples where a Nash equilibrium is found numerically.
-
High dimensional vector autoregressive (VAR) models require a large number of
parameters to be estimated and may suffer of inferential problems. We propose a
new Bayesian nonparametric (BNP) Lasso prior (BNP-Lasso) for high-dimensional
VAR models that can improve estimation efficiency and prediction accuracy. Our
hierarchical prior overcomes overparametrization and overfitting issues by
clustering the VAR coefficients into groups and by shrinking the coefficients
of each group toward a common location. Clustering and shrinking effects
induced by the BNP-Lasso prior are well suited for the extraction of causal
networks from time series, since they account for some stylized facts in
real-world networks, which are sparsity, communities structures and
heterogeneity in the edges intensity. In order to fully capture the richness of
the data and to achieve a better understanding of financial and macroeconomic
risk, it is therefore crucial that the model used to extract network accounts
for these stylized facts.
-
We consider a two player simultaneous-move game where the two players each
select any permissible $n$-sided die for a fixed integer $n$. A player wins if
the outcome of his roll is greater than that of his opponent. Remarkably, for
$n>3$, there is a unique Nash Equilibrium in pure strategies. The unique Nash
Equilibrium is for each player to throw the Standard $n$-sided die, where each
side has a different number. Our proof of uniqueness is constructive. We
introduce an algorithm with which, for any nonstandard die, we may generate
another die that beats it.
-
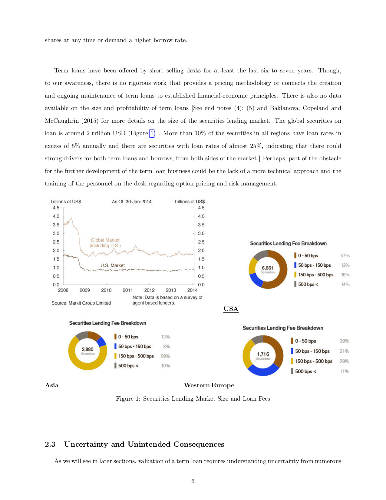
We develop models to price long term loans in the securities lending
business. These longer horizon deals can be viewed as contracts with
optionality embedded in them and can be priced using established methods from
derivatives theory, becoming to our limited knowledge, the first application
that can lead to greater synergies between the operations of derivative and
delta-one trading desks, perhaps even being able to combine certain aspects of
the day to day operations of these seemingly disparate entities. We run
numerical simulations to demonstrate the practical applicability of these
models. These models are part of one of the least explored yet profit laden
areas of modern investment management.
We develop a heuristic that can mitigate the loss of information that sets in
when parameters are estimated first and then the valuation is performed by
directly calculating the valuation using the historical time series. This can
lead to reduced models errors and greater financial stability. We illustrate
how the methodologies developed here could be useful for inventory management.
All these techniques could have applications for dealing with other financial
instruments, non-financial commodities and many forms of uncertainty. An
unintended consequence of our efforts, has become a review of the vast
literature on options pricing, which can be useful for anyone that attempts to
apply the corresponding techniques to the problems mentioned here.
Admittedly, our initial ambitions to produce a normative theory on long term
loan valuations are undone by the present state of affairs in social science
modeling. Though we consider many elements of a securities lending system at
face value, this cannot be termed a positive theory. For now, if it ends up
producing a useful theory, our work is done.
-
We represent the functioning of the housing market and study the relation
between income segregation, income inequality and house prices by introducing a
spatial Agent-Based Model (ABM). Differently from traditional models in urban
economics, we explicitly specify the behavior of buyers and sellers and the
price formation mechanism. Buyers who differ by income select among
heterogeneous neighborhoods using a probabilistic model of residential choice;
sellers employ an aspiration level heuristic to set their reservation offer
price; prices are determined through a continuous double auction. We first
provide an approximate analytical solution of the ABM, shedding light on the
structure of the model and on the effect of the parameters. We then simulate
the ABM and find that: (i) a more unequal income distribution lowers the prices
globally, but implies stronger segregation; (ii) a spike of the demand in one
part of the city increases the prices all over the city; (iii) subsidies are
more efficient than taxes in fostering social mixing.
-
Almost by definition, radical innovations create a need to revise existing
classification systems. In this paper, we argue that classification system
changes and patent reclassification are common and reveal interesting
information about technological evolution. To support our argument, we present
three sets of findings regarding classification volatility in the U.S. patent
classification system. First, we study the evolution of the number of distinct
classes. Reconstructed time series based on the current classification scheme
are very different from historical data. This suggests that using the current
classification to analyze the past produces a distorted view of the evolution
of the system. Second, we study the relative sizes of classes. The size
distribution is exponential so classes are of quite different sizes, but the
largest classes are not necessarily the oldest. To explain this pattern with a
simple stochastic growth model, we introduce the assumption that classes have a
regular chance to be split. Third, we study reclassification. The share of
patents that are in a different class now than they were at birth can be quite
high. Reclassification mostly occurs across classes belonging to the same
1-digit NBER category, but not always. We also document that reclassified
patents tend to be more cited than non-reclassified ones, even after
controlling for grant year and class of origin.
-
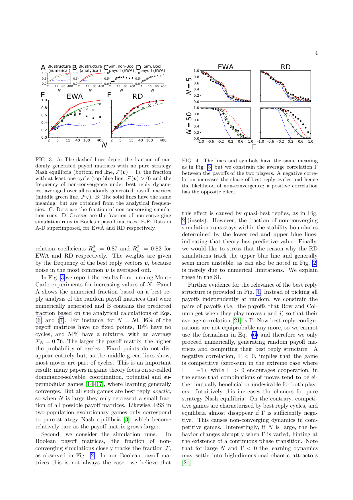
Game theory is widely used as a behavioral model for strategic interactions
in biology and social science. It is common practice to assume that players
quickly converge to an equilibrium, e.g. a Nash equilibrium. This can be
studied in terms of best reply dynamics, in which each player myopically uses
the best response to her opponent's last move. Existing research shows that
convergence can be problematic when there are best reply cycles. Here we
calculate how typical this is by studying the space of all possible two-player
normal form games and counting the frequency of best reply cycles. The two key
parameters are the number of moves, which defines how complicated the game is,
and the anti-correlation of the payoffs, which determines how competitive it
is. We find that as games get more complicated and more competitive, best reply
cycles become dominant. The existence of best reply cycles predicts
non-convergence of six different learning algorithms that have support from
human experiments. Our results imply that for complicated and competitive games
equilibrium is typically an unrealistic assumption. Alternatively, if for some
reason "real" games are special and do not possess cycles, we raise the
interesting question of why this should be so.
-
We used to marry people to whom we were somehow connected. Since we were more
connected to people similar to us, we were also likely to marry someone from
our own race. However, online dating has changed this pattern; people who meet
online tend to be complete strangers. We investigate the effects of those
previously absent ties on the diversity of modern societies.
We find that social integration occurs rapidly when a society benefits from
new connections. Our analysis of state-level data on interracial marriage and
broadband adoption (proxy for online dating) suggests that this integration
process is significant and ongoing.
-
Indirect inference requires simulating realisations of endogenous variables
from the model under study. When the endogenous variables are discontinuous
functions of the model parameters, the resulting indirect inference criterion
function is discontinuous and does not permit the use of derivative-based
optimisation routines. Using a change of variables technique, we propose a
novel simulation algorithm that alleviates the discontinuities inherent in such
indirect inference criterion functions, and permits the application of
derivative-based optimisation routines to estimate the unknown model
parameters. Unlike competing approaches, this approach does not rely on kernel
smoothing or bandwidth parameters. Several Monte Carlo examples that have
featured in the literature on indirect inference with discontinuous outcomes
illustrate the approach, and demonstrate the superior performance of this
approach over existing alternatives.
-
We consider how to optimally allocate investments in a portfolio of competing
technologies using the standard mean-variance framework of portfolio theory. We
assume that technologies follow the empirically observed relationship known as
Wright's law, also called a "learning curve" or "experience curve", which
postulates that costs drop as cumulative production increases. This introduces
a positive feedback between cost and investment that complicates the portfolio
problem, leading to multiple local optima, and causing a trade-off between
concentrating investments in one project to spur rapid progress vs.
diversifying over many projects to hedge against failure. We study the
two-technology case and characterize the optimal diversification in terms of
progress rates, variability, initial costs, initial experience, risk aversion,
discount rate and total demand. The efficient frontier framework is used to
visualize technology portfolios and show how feedback results in nonlinear
distortions of the feasible set. For the two-period case, in which learning and
uncertainty interact with discounting, we compare different scenarios and find
that the discount rate plays a critical role.
-
We provide a framework for determining the centralities of agents in a broad
family of random networks. Current understanding of network centrality is
largely restricted to deterministic settings, but practitioners frequently use
random network models to accommodate data limitations or prove asymptotic
results. Our main theorems show that on large random networks, centrality
measures are close to their expected values with high probability. We
illustrate the economic consequences of these results by presenting three
applications: (1) In network formation models based on community structure
(called stochastic block models), we show network segregation and differences
in community size produce inequality. Benefits from peer effects tend to accrue
disproportionately to bigger and better-connected communities. (2) When link
probabilities depend on geography, we can compute and compare the centralities
of agents in different locations. (3) In models where connections depend on
several independent characteristics, we give a formula that determines
centralities 'characteristic-by-characteristic'. The basic techniques from
these applications, which use the main theorems to reduce questions about
random networks to deterministic calculations, extend to many network games.
-
We present functional forms allowing a broader range of analytic solutions to
common economic equilibrium problems. These can increase the realism of
pen-and-paper solutions or speed large-scale numerical solutions as
computational subroutines. We use the latter approach to build a tractable
heterogeneous firm model of international trade accommodating economies of
scale in export and diseconomies of scale in production, providing a natural,
unified solution to several puzzles concerning trade costs. We briefly
highlight applications in a range of other fields. Our method of generating
analytic solutions is a discrete approximation to a logarithmically modified
Laplace transform of equilibrium conditions.
-
The range of a payoff function for an $n$-player finite strategic game is
investigated using a novel approach, the notion of extreme points of a
non-convex set. The shape of a noncooperative payoff region can be estimated
using extreme points and supporting hyperplanes of the cooperative payoff
region. A basic structural characteristic of a noncooperative payoff region is
that any of its subregions must be non-strictly convex if the subregion
contains a relative neighborhood of a point on its boundary. Besides, applying
the properties of extreme points of a noncooperative payoff region is a simple
and effective way to prove some results about Pareto efficiency and social
efficiency in game theory.





 We model learning in a continuous-time Brownian setting where there is prior ambiguity. The associated model of preference values robustness and is time-consistent. It is applied to study optimal learning when the choice between actions can be postponed, at a per-unit-time cost, in order to observe a signal that provides information about an unknown parameter. The corresponding optimal stopping problem is solved in closed-form, with a focus on two specific settings: Ellsberg's two-urn thought experiment expanded to allow learning before the choice of bets, and a robust version of the classical problem of sequential testing of two simple hypotheses about the unknown drift of a Wiener process. In both cases, the link between robustness and the demand for learning is studied.
We model learning in a continuous-time Brownian setting where there is prior ambiguity. The associated model of preference values robustness and is time-consistent. It is applied to study optimal learning when the choice between actions can be postponed, at a per-unit-time cost, in order to observe a signal that provides information about an unknown parameter. The corresponding optimal stopping problem is solved in closed-form, with a focus on two specific settings: Ellsberg's two-urn thought experiment expanded to allow learning before the choice of bets, and a robust version of the classical problem of sequential testing of two simple hypotheses about the unknown drift of a Wiener process. In both cases, the link between robustness and the demand for learning is studied.



 We study decentralized protection strategies against Susceptible-Infected-Susceptible (SIS) epidemics on networks. We consider a population game framework where nodes choose whether or not to vaccinate themselves, and the epidemic risk is defined as the infection probability at the endemic state of the epidemic under a degree-based mean-field approximation. Motivated by studies in behavioral economics showing that humans perceive probabilities and risks in a nonlinear fashion, we specifically examine the impacts of such misperceptions on the Nash equilibrium protection strategies. We first establish the existence and uniqueness of a threshold equilibrium where nodes with degrees larger than a certain threshold vaccinate. When the vaccination cost is sufficiently high, we show that behavioral biases cause fewer players to vaccinate, and vice versa. We quantify this effect for a class of networks with power-law degree distributions by proving tight bounds on the ratio of equilibrium thresholds under behavioral and true perceptions of probabilities. We further characterize the socially optimal vaccination policy and investigate the inefficiency of Nash equilibrium.
We study decentralized protection strategies against Susceptible-Infected-Susceptible (SIS) epidemics on networks. We consider a population game framework where nodes choose whether or not to vaccinate themselves, and the epidemic risk is defined as the infection probability at the endemic state of the epidemic under a degree-based mean-field approximation. Motivated by studies in behavioral economics showing that humans perceive probabilities and risks in a nonlinear fashion, we specifically examine the impacts of such misperceptions on the Nash equilibrium protection strategies. We first establish the existence and uniqueness of a threshold equilibrium where nodes with degrees larger than a certain threshold vaccinate. When the vaccination cost is sufficiently high, we show that behavioral biases cause fewer players to vaccinate, and vice versa. We quantify this effect for a class of networks with power-law degree distributions by proving tight bounds on the ratio of equilibrium thresholds under behavioral and true perceptions of probabilities. We further characterize the socially optimal vaccination policy and investigate the inefficiency of Nash equilibrium.




 How do macro-financial shocks affect investor behavior and market dynamics? Recent evidence on experience effects suggests a long-lasting influence of personally experienced outcomes on investor beliefs and investment, but also significant differences across older and younger generations. We formalize experience-based learning in an OLG model, where different cross-cohort experiences generate persistent heterogeneity in beliefs, portfolio choices, and trade. The model allows us to characterize a novel link between investor demographics and the dependence of prices on past dividends, while also generating known features of asset prices, such as excess volatility and return predictability. The model produces new implications for the cross-section of asset holdings, trade volume, and investors' heterogenous responses to recent financial crises, which we show to be in line with the data.
How do macro-financial shocks affect investor behavior and market dynamics? Recent evidence on experience effects suggests a long-lasting influence of personally experienced outcomes on investor beliefs and investment, but also significant differences across older and younger generations. We formalize experience-based learning in an OLG model, where different cross-cohort experiences generate persistent heterogeneity in beliefs, portfolio choices, and trade. The model allows us to characterize a novel link between investor demographics and the dependence of prices on past dividends, while also generating known features of asset prices, such as excess volatility and return predictability. The model produces new implications for the cross-section of asset holdings, trade volume, and investors' heterogenous responses to recent financial crises, which we show to be in line with the data.




 We reconsider the microeconomic foundations of financial economics. Motivated by the importance of Knightian Uncertainty in markets, we present a model that does not carry any probabilistic structure ex ante, yet is based on a common order. We derive the fundamental equivalence of economic viability of asset prices and absence of arbitrage. We also obtain a modified version of the Fundamental Theorem of Asset Pricing using the notion of sublinear pricing measures. Different versions of the Efficient Market Hypothesis are related to the assumptions one is willing to impose on the common order.
We reconsider the microeconomic foundations of financial economics. Motivated by the importance of Knightian Uncertainty in markets, we present a model that does not carry any probabilistic structure ex ante, yet is based on a common order. We derive the fundamental equivalence of economic viability of asset prices and absence of arbitrage. We also obtain a modified version of the Fundamental Theorem of Asset Pricing using the notion of sublinear pricing measures. Different versions of the Efficient Market Hypothesis are related to the assumptions one is willing to impose on the common order.




 In Chinese societies, superstition is of paramount importance, and vehicle license plates with desirable numbers can fetch very high prices in auctions. Unlike other valuable items, license plates are not allocated an estimated price before auction. I propose that the task of predicting plate prices can be viewed as a natural language processing (NLP) task, as the value depends on the meaning of each individual character on the plate and its semantics. I construct a deep recurrent neural network (RNN) to predict the prices of vehicle license plates in Hong Kong, based on the characters on a plate. I demonstrate the importance of having a deep network and of retraining. Evaluated on 13 years of historical auction prices, the deep RNN's predictions can explain over 80 percent of price variations, outperforming previous models by a significant margin. I also demonstrate how the model can be extended to become a search engine for plates and to provide estimates of the expected price distribution.
In Chinese societies, superstition is of paramount importance, and vehicle license plates with desirable numbers can fetch very high prices in auctions. Unlike other valuable items, license plates are not allocated an estimated price before auction. I propose that the task of predicting plate prices can be viewed as a natural language processing (NLP) task, as the value depends on the meaning of each individual character on the plate and its semantics. I construct a deep recurrent neural network (RNN) to predict the prices of vehicle license plates in Hong Kong, based on the characters on a plate. I demonstrate the importance of having a deep network and of retraining. Evaluated on 13 years of historical auction prices, the deep RNN's predictions can explain over 80 percent of price variations, outperforming previous models by a significant margin. I also demonstrate how the model can be extended to become a search engine for plates and to provide estimates of the expected price distribution.




 The structure of the International Trade Network (ITN), whose nodes and links represent world countries and their trade relations respectively, affects key economic processes worldwide, including globalization, economic integration, industrial production, and the propagation of shocks and instabilities. Characterizing the ITN via a simple yet accurate model is an open problem. The traditional Gravity Model (GM) successfully reproduces the volume of trade between connected countries, using macroeconomic properties such as GDP, geographic distance, and possibly other factors. However, it predicts a network with complete or homogeneous topology, thus failing to reproduce the highly heterogeneous structure of the ITN. On the other hand, recent maximum-entropy network models successfully reproduce the complex topology of the ITN, but provide no information about trade volumes. Here we integrate these two currently incompatible approaches via the introduction of an Enhanced Gravity Model (EGM) of trade. The EGM is the simplest model combining the GM with the network approach within a maximum-entropy framework. Via a unified and principled mechanism that is transparent enough to be generalized to any economic network, the EGM provides a new econometric framework wherein trade probabilities and trade volumes can be separately controlled by any combination of dyadic and country-specific macroeconomic variables. The model successfully reproduces both the global topology and the local link weights of the ITN, parsimoniously reconciling the conflicting approaches. It also indicates that the probability that any two countries trade a certain volume should follow a geometric or exponential distribution with an additional point mass at zero volume.
The structure of the International Trade Network (ITN), whose nodes and links represent world countries and their trade relations respectively, affects key economic processes worldwide, including globalization, economic integration, industrial production, and the propagation of shocks and instabilities. Characterizing the ITN via a simple yet accurate model is an open problem. The traditional Gravity Model (GM) successfully reproduces the volume of trade between connected countries, using macroeconomic properties such as GDP, geographic distance, and possibly other factors. However, it predicts a network with complete or homogeneous topology, thus failing to reproduce the highly heterogeneous structure of the ITN. On the other hand, recent maximum-entropy network models successfully reproduce the complex topology of the ITN, but provide no information about trade volumes. Here we integrate these two currently incompatible approaches via the introduction of an Enhanced Gravity Model (EGM) of trade. The EGM is the simplest model combining the GM with the network approach within a maximum-entropy framework. Via a unified and principled mechanism that is transparent enough to be generalized to any economic network, the EGM provides a new econometric framework wherein trade probabilities and trade volumes can be separately controlled by any combination of dyadic and country-specific macroeconomic variables. The model successfully reproduces both the global topology and the local link weights of the ITN, parsimoniously reconciling the conflicting approaches. It also indicates that the probability that any two countries trade a certain volume should follow a geometric or exponential distribution with an additional point mass at zero volume.




 In this paper, we extend the optimal securitisation model of Pag\`es [50] and Possama\"i and Pag\`es [51] between an investor and a bank to a setting allowing both moral hazard and adverse selection. Following the recent approach to these problems of Cvitani\'c, Wan and Yang [14], we characterise explicitly and rigorously the so-called credible set of the continuation and temptation values of the bank, and obtain the value function of the investor as well as the optimal contracts through a recursive system of first-order variational inequalities with gradient constraints. We provide a detailed discussion of the properties of the optimal menu of contracts.
In this paper, we extend the optimal securitisation model of Pag\`es [50] and Possama\"i and Pag\`es [51] between an investor and a bank to a setting allowing both moral hazard and adverse selection. Following the recent approach to these problems of Cvitani\'c, Wan and Yang [14], we characterise explicitly and rigorously the so-called credible set of the continuation and temptation values of the bank, and obtain the value function of the investor as well as the optimal contracts through a recursive system of first-order variational inequalities with gradient constraints. We provide a detailed discussion of the properties of the optimal menu of contracts.



 In this paper, we introduce quantile coherency to measure general dependence structures emerging in the joint distribution in the frequency domain and argue that this type of dependence is natural for economic time series but remains invisible when only the traditional analysis is employed. We define estimators which capture the general dependence structure, provide a detailed analysis of their asymptotic properties and discuss how to conduct inference for a general class of possibly nonlinear processes. In an empirical illustration we examine the dependence of bivariate stock market returns and shed new light on measurement of tail risk in financial markets. We also provide a modelling exercise to illustrate how applied researchers can benefit from using quantile coherency when assessing time series models.
In this paper, we introduce quantile coherency to measure general dependence structures emerging in the joint distribution in the frequency domain and argue that this type of dependence is natural for economic time series but remains invisible when only the traditional analysis is employed. We define estimators which capture the general dependence structure, provide a detailed analysis of their asymptotic properties and discuss how to conduct inference for a general class of possibly nonlinear processes. In an empirical illustration we examine the dependence of bivariate stock market returns and shed new light on measurement of tail risk in financial markets. We also provide a modelling exercise to illustrate how applied researchers can benefit from using quantile coherency when assessing time series models.




 A set of data with positive values follows a Pareto distribution if the log-log plot of value versus rank is approximately a straight line. A Pareto distribution satisfies Zipf's law if the log-log plot has a slope of -1. Since many types of ranked data follow Zipf's law, it is considered a form of universality. We propose a mathematical explanation for this phenomenon based on Atlas models and first-order models, systems of positive continuous semimartingales with parameters that depend only on rank. We show that the stable distribution of an Atlas model will follow Zipf's law if and only if two natural conditions, conservation and completeness, are satisfied. Since Atlas models and first-order models can be constructed to approximate systems of time-dependent rank-based data, our results can explain the universality of Zipf's law for such systems. However, ranked data generated by other means may follow non-Zipfian Pareto distributions. Hence, our results explain why Zipf's law holds for word frequency, firm size, household wealth, and city size, while it does not hold for earthquake magnitude, cumulative book sales, the intensity of solar flares, and the intensity of wars, all of which follow non-Zipfian Pareto distributions.
A set of data with positive values follows a Pareto distribution if the log-log plot of value versus rank is approximately a straight line. A Pareto distribution satisfies Zipf's law if the log-log plot has a slope of -1. Since many types of ranked data follow Zipf's law, it is considered a form of universality. We propose a mathematical explanation for this phenomenon based on Atlas models and first-order models, systems of positive continuous semimartingales with parameters that depend only on rank. We show that the stable distribution of an Atlas model will follow Zipf's law if and only if two natural conditions, conservation and completeness, are satisfied. Since Atlas models and first-order models can be constructed to approximate systems of time-dependent rank-based data, our results can explain the universality of Zipf's law for such systems. However, ranked data generated by other means may follow non-Zipfian Pareto distributions. Hence, our results explain why Zipf's law holds for word frequency, firm size, household wealth, and city size, while it does not hold for earthquake magnitude, cumulative book sales, the intensity of solar flares, and the intensity of wars, all of which follow non-Zipfian Pareto distributions.




 This paper provides a comprehensive analysis of welfare measures when oligopolistic firms face multiple policy interventions and external changes under general forms of market demands, production costs, and imperfect competition. We present our results in terms of two welfare measures, namely, marginal cost of public funds and incidence, in relation to multi-dimensional pass-through. Our arguments are best understood with two-dimensional taxation where homogeneous firms face unit and ad valorem taxes. The first part of the paper studies this leading case. We show, e.g., that there exists a simple and empirically relevant set of sufficient statistics for the marginal cost of public funds, namely unit tax and ad valorem pass-through and industry demand elasticity. We then specialize our general setting to the case of price or quantity competition and show how the marginal cost of public funds and the pass-through are expressed using elasticities and curvatures of regular and inverse demands. Based on the results of the leading case, the second part of the paper presents a generalization with the tax revenue function specified as a general function parameterized by a vector of multi-dimensional tax parameters. We then argue that our results are carried over to the case of heterogeneous firms and other extensions.
This paper provides a comprehensive analysis of welfare measures when oligopolistic firms face multiple policy interventions and external changes under general forms of market demands, production costs, and imperfect competition. We present our results in terms of two welfare measures, namely, marginal cost of public funds and incidence, in relation to multi-dimensional pass-through. Our arguments are best understood with two-dimensional taxation where homogeneous firms face unit and ad valorem taxes. The first part of the paper studies this leading case. We show, e.g., that there exists a simple and empirically relevant set of sufficient statistics for the marginal cost of public funds, namely unit tax and ad valorem pass-through and industry demand elasticity. We then specialize our general setting to the case of price or quantity competition and show how the marginal cost of public funds and the pass-through are expressed using elasticities and curvatures of regular and inverse demands. Based on the results of the leading case, the second part of the paper presents a generalization with the tax revenue function specified as a general function parameterized by a vector of multi-dimensional tax parameters. We then argue that our results are carried over to the case of heterogeneous firms and other extensions.




 This paper studies models in which hypothesis tests have trivial power, that is, power smaller than size. This testing impossibility, or impossibility type A, arises when any alternative is not distinguishable from the null. We also study settings in which it is impossible to have almost surely bounded confidence sets for a parameter of interest. This second type of impossibility (type B) occurs under a condition weaker than the condition for type A impossibility: the parameter of interest must be nearly unidentified. Our theoretical framework connects many existing publications on impossible inference that rely on different notions of topologies to show models are not distinguishable or nearly unidentified. We also derive both types of impossibility using the weak topology induced by convergence in distribution. Impossibility in the weak topology is often easier to prove, it is applicable for many widely-used tests, and it is useful for robust hypothesis testing. We conclude by demonstrating impossible inference in multiple economic applications of models with discontinuity and time-series models.
This paper studies models in which hypothesis tests have trivial power, that is, power smaller than size. This testing impossibility, or impossibility type A, arises when any alternative is not distinguishable from the null. We also study settings in which it is impossible to have almost surely bounded confidence sets for a parameter of interest. This second type of impossibility (type B) occurs under a condition weaker than the condition for type A impossibility: the parameter of interest must be nearly unidentified. Our theoretical framework connects many existing publications on impossible inference that rely on different notions of topologies to show models are not distinguishable or nearly unidentified. We also derive both types of impossibility using the weak topology induced by convergence in distribution. Impossibility in the weak topology is often easier to prove, it is applicable for many widely-used tests, and it is useful for robust hypothesis testing. We conclude by demonstrating impossible inference in multiple economic applications of models with discontinuity and time-series models.




 We consider a general nonzero-sum impulse game with two players. The main mathematical contribution of the paper is a verification theorem which provides, under some regularity conditions, a suitable system of quasi-variational inequalities for the value functions and the optimal strategies of the two players. As an application, we study an impulse game with a one-dimensional state variable, following a real-valued scaled Brownian motion, and two players with linear and symmetric running payoffs. We fully characterize a Nash equilibrium and provide explicit expressions for the optimal strategies and the value functions. We also prove some asymptotic results with respect to the intervention costs. Finally, we consider two further non-symmetric examples where a Nash equilibrium is found numerically.
We consider a general nonzero-sum impulse game with two players. The main mathematical contribution of the paper is a verification theorem which provides, under some regularity conditions, a suitable system of quasi-variational inequalities for the value functions and the optimal strategies of the two players. As an application, we study an impulse game with a one-dimensional state variable, following a real-valued scaled Brownian motion, and two players with linear and symmetric running payoffs. We fully characterize a Nash equilibrium and provide explicit expressions for the optimal strategies and the value functions. We also prove some asymptotic results with respect to the intervention costs. Finally, we consider two further non-symmetric examples where a Nash equilibrium is found numerically.




 We consider a two player simultaneous-move game where the two players each select any permissible $n$-sided die for a fixed integer $n$. A player wins if the outcome of his roll is greater than that of his opponent. Remarkably, for $n>3$, there is a unique Nash Equilibrium in pure strategies. The unique Nash Equilibrium is for each player to throw the Standard $n$-sided die, where each side has a different number. Our proof of uniqueness is constructive. We introduce an algorithm with which, for any nonstandard die, we may generate another die that beats it.
We consider a two player simultaneous-move game where the two players each select any permissible $n$-sided die for a fixed integer $n$. A player wins if the outcome of his roll is greater than that of his opponent. Remarkably, for $n>3$, there is a unique Nash Equilibrium in pure strategies. The unique Nash Equilibrium is for each player to throw the Standard $n$-sided die, where each side has a different number. Our proof of uniqueness is constructive. We introduce an algorithm with which, for any nonstandard die, we may generate another die that beats it.




 We develop models to price long term loans in the securities lending business. These longer horizon deals can be viewed as contracts with optionality embedded in them and can be priced using established methods from derivatives theory, becoming to our limited knowledge, the first application that can lead to greater synergies between the operations of derivative and delta-one trading desks, perhaps even being able to combine certain aspects of the day to day operations of these seemingly disparate entities. We run numerical simulations to demonstrate the practical applicability of these models. These models are part of one of the least explored yet profit laden areas of modern investment management. We develop a heuristic that can mitigate the loss of information that sets in when parameters are estimated first and then the valuation is performed by directly calculating the valuation using the historical time series. This can lead to reduced models errors and greater financial stability. We illustrate how the methodologies developed here could be useful for inventory management. All these techniques could have applications for dealing with other financial instruments, non-financial commodities and many forms of uncertainty. An unintended consequence of our efforts, has become a review of the vast literature on options pricing, which can be useful for anyone that attempts to apply the corresponding techniques to the problems mentioned here. Admittedly, our initial ambitions to produce a normative theory on long term loan valuations are undone by the present state of affairs in social science modeling. Though we consider many elements of a securities lending system at face value, this cannot be termed a positive theory. For now, if it ends up producing a useful theory, our work is done.
We develop models to price long term loans in the securities lending business. These longer horizon deals can be viewed as contracts with optionality embedded in them and can be priced using established methods from derivatives theory, becoming to our limited knowledge, the first application that can lead to greater synergies between the operations of derivative and delta-one trading desks, perhaps even being able to combine certain aspects of the day to day operations of these seemingly disparate entities. We run numerical simulations to demonstrate the practical applicability of these models. These models are part of one of the least explored yet profit laden areas of modern investment management. We develop a heuristic that can mitigate the loss of information that sets in when parameters are estimated first and then the valuation is performed by directly calculating the valuation using the historical time series. This can lead to reduced models errors and greater financial stability. We illustrate how the methodologies developed here could be useful for inventory management. All these techniques could have applications for dealing with other financial instruments, non-financial commodities and many forms of uncertainty. An unintended consequence of our efforts, has become a review of the vast literature on options pricing, which can be useful for anyone that attempts to apply the corresponding techniques to the problems mentioned here. Admittedly, our initial ambitions to produce a normative theory on long term loan valuations are undone by the present state of affairs in social science modeling. Though we consider many elements of a securities lending system at face value, this cannot be termed a positive theory. For now, if it ends up producing a useful theory, our work is done.




 We represent the functioning of the housing market and study the relation between income segregation, income inequality and house prices by introducing a spatial Agent-Based Model (ABM). Differently from traditional models in urban economics, we explicitly specify the behavior of buyers and sellers and the price formation mechanism. Buyers who differ by income select among heterogeneous neighborhoods using a probabilistic model of residential choice; sellers employ an aspiration level heuristic to set their reservation offer price; prices are determined through a continuous double auction. We first provide an approximate analytical solution of the ABM, shedding light on the structure of the model and on the effect of the parameters. We then simulate the ABM and find that: (i) a more unequal income distribution lowers the prices globally, but implies stronger segregation; (ii) a spike of the demand in one part of the city increases the prices all over the city; (iii) subsidies are more efficient than taxes in fostering social mixing.
We represent the functioning of the housing market and study the relation between income segregation, income inequality and house prices by introducing a spatial Agent-Based Model (ABM). Differently from traditional models in urban economics, we explicitly specify the behavior of buyers and sellers and the price formation mechanism. Buyers who differ by income select among heterogeneous neighborhoods using a probabilistic model of residential choice; sellers employ an aspiration level heuristic to set their reservation offer price; prices are determined through a continuous double auction. We first provide an approximate analytical solution of the ABM, shedding light on the structure of the model and on the effect of the parameters. We then simulate the ABM and find that: (i) a more unequal income distribution lowers the prices globally, but implies stronger segregation; (ii) a spike of the demand in one part of the city increases the prices all over the city; (iii) subsidies are more efficient than taxes in fostering social mixing.




 Almost by definition, radical innovations create a need to revise existing classification systems. In this paper, we argue that classification system changes and patent reclassification are common and reveal interesting information about technological evolution. To support our argument, we present three sets of findings regarding classification volatility in the U.S. patent classification system. First, we study the evolution of the number of distinct classes. Reconstructed time series based on the current classification scheme are very different from historical data. This suggests that using the current classification to analyze the past produces a distorted view of the evolution of the system. Second, we study the relative sizes of classes. The size distribution is exponential so classes are of quite different sizes, but the largest classes are not necessarily the oldest. To explain this pattern with a simple stochastic growth model, we introduce the assumption that classes have a regular chance to be split. Third, we study reclassification. The share of patents that are in a different class now than they were at birth can be quite high. Reclassification mostly occurs across classes belonging to the same 1-digit NBER category, but not always. We also document that reclassified patents tend to be more cited than non-reclassified ones, even after controlling for grant year and class of origin.
Almost by definition, radical innovations create a need to revise existing classification systems. In this paper, we argue that classification system changes and patent reclassification are common and reveal interesting information about technological evolution. To support our argument, we present three sets of findings regarding classification volatility in the U.S. patent classification system. First, we study the evolution of the number of distinct classes. Reconstructed time series based on the current classification scheme are very different from historical data. This suggests that using the current classification to analyze the past produces a distorted view of the evolution of the system. Second, we study the relative sizes of classes. The size distribution is exponential so classes are of quite different sizes, but the largest classes are not necessarily the oldest. To explain this pattern with a simple stochastic growth model, we introduce the assumption that classes have a regular chance to be split. Third, we study reclassification. The share of patents that are in a different class now than they were at birth can be quite high. Reclassification mostly occurs across classes belonging to the same 1-digit NBER category, but not always. We also document that reclassified patents tend to be more cited than non-reclassified ones, even after controlling for grant year and class of origin.



 Game theory is widely used as a behavioral model for strategic interactions in biology and social science. It is common practice to assume that players quickly converge to an equilibrium, e.g. a Nash equilibrium. This can be studied in terms of best reply dynamics, in which each player myopically uses the best response to her opponent's last move. Existing research shows that convergence can be problematic when there are best reply cycles. Here we calculate how typical this is by studying the space of all possible two-player normal form games and counting the frequency of best reply cycles. The two key parameters are the number of moves, which defines how complicated the game is, and the anti-correlation of the payoffs, which determines how competitive it is. We find that as games get more complicated and more competitive, best reply cycles become dominant. The existence of best reply cycles predicts non-convergence of six different learning algorithms that have support from human experiments. Our results imply that for complicated and competitive games equilibrium is typically an unrealistic assumption. Alternatively, if for some reason "real" games are special and do not possess cycles, we raise the interesting question of why this should be so.
Game theory is widely used as a behavioral model for strategic interactions in biology and social science. It is common practice to assume that players quickly converge to an equilibrium, e.g. a Nash equilibrium. This can be studied in terms of best reply dynamics, in which each player myopically uses the best response to her opponent's last move. Existing research shows that convergence can be problematic when there are best reply cycles. Here we calculate how typical this is by studying the space of all possible two-player normal form games and counting the frequency of best reply cycles. The two key parameters are the number of moves, which defines how complicated the game is, and the anti-correlation of the payoffs, which determines how competitive it is. We find that as games get more complicated and more competitive, best reply cycles become dominant. The existence of best reply cycles predicts non-convergence of six different learning algorithms that have support from human experiments. Our results imply that for complicated and competitive games equilibrium is typically an unrealistic assumption. Alternatively, if for some reason "real" games are special and do not possess cycles, we raise the interesting question of why this should be so.




 Indirect inference requires simulating realisations of endogenous variables from the model under study. When the endogenous variables are discontinuous functions of the model parameters, the resulting indirect inference criterion function is discontinuous and does not permit the use of derivative-based optimisation routines. Using a change of variables technique, we propose a novel simulation algorithm that alleviates the discontinuities inherent in such indirect inference criterion functions, and permits the application of derivative-based optimisation routines to estimate the unknown model parameters. Unlike competing approaches, this approach does not rely on kernel smoothing or bandwidth parameters. Several Monte Carlo examples that have featured in the literature on indirect inference with discontinuous outcomes illustrate the approach, and demonstrate the superior performance of this approach over existing alternatives.
Indirect inference requires simulating realisations of endogenous variables from the model under study. When the endogenous variables are discontinuous functions of the model parameters, the resulting indirect inference criterion function is discontinuous and does not permit the use of derivative-based optimisation routines. Using a change of variables technique, we propose a novel simulation algorithm that alleviates the discontinuities inherent in such indirect inference criterion functions, and permits the application of derivative-based optimisation routines to estimate the unknown model parameters. Unlike competing approaches, this approach does not rely on kernel smoothing or bandwidth parameters. Several Monte Carlo examples that have featured in the literature on indirect inference with discontinuous outcomes illustrate the approach, and demonstrate the superior performance of this approach over existing alternatives.




 We consider how to optimally allocate investments in a portfolio of competing technologies using the standard mean-variance framework of portfolio theory. We assume that technologies follow the empirically observed relationship known as Wright's law, also called a "learning curve" or "experience curve", which postulates that costs drop as cumulative production increases. This introduces a positive feedback between cost and investment that complicates the portfolio problem, leading to multiple local optima, and causing a trade-off between concentrating investments in one project to spur rapid progress vs. diversifying over many projects to hedge against failure. We study the two-technology case and characterize the optimal diversification in terms of progress rates, variability, initial costs, initial experience, risk aversion, discount rate and total demand. The efficient frontier framework is used to visualize technology portfolios and show how feedback results in nonlinear distortions of the feasible set. For the two-period case, in which learning and uncertainty interact with discounting, we compare different scenarios and find that the discount rate plays a critical role.
We consider how to optimally allocate investments in a portfolio of competing technologies using the standard mean-variance framework of portfolio theory. We assume that technologies follow the empirically observed relationship known as Wright's law, also called a "learning curve" or "experience curve", which postulates that costs drop as cumulative production increases. This introduces a positive feedback between cost and investment that complicates the portfolio problem, leading to multiple local optima, and causing a trade-off between concentrating investments in one project to spur rapid progress vs. diversifying over many projects to hedge against failure. We study the two-technology case and characterize the optimal diversification in terms of progress rates, variability, initial costs, initial experience, risk aversion, discount rate and total demand. The efficient frontier framework is used to visualize technology portfolios and show how feedback results in nonlinear distortions of the feasible set. For the two-period case, in which learning and uncertainty interact with discounting, we compare different scenarios and find that the discount rate plays a critical role.




 The range of a payoff function for an $n$-player finite strategic game is investigated using a novel approach, the notion of extreme points of a non-convex set. The shape of a noncooperative payoff region can be estimated using extreme points and supporting hyperplanes of the cooperative payoff region. A basic structural characteristic of a noncooperative payoff region is that any of its subregions must be non-strictly convex if the subregion contains a relative neighborhood of a point on its boundary. Besides, applying the properties of extreme points of a noncooperative payoff region is a simple and effective way to prove some results about Pareto efficiency and social efficiency in game theory.
The range of a payoff function for an $n$-player finite strategic game is investigated using a novel approach, the notion of extreme points of a non-convex set. The shape of a noncooperative payoff region can be estimated using extreme points and supporting hyperplanes of the cooperative payoff region. A basic structural characteristic of a noncooperative payoff region is that any of its subregions must be non-strictly convex if the subregion contains a relative neighborhood of a point on its boundary. Besides, applying the properties of extreme points of a noncooperative payoff region is a simple and effective way to prove some results about Pareto efficiency and social efficiency in game theory.