-
Semidefinite programs (SDPs) -- some of the most useful and versatile
optimization problems of the last few decades -- are often pathological: the
optimal values of the primal and dual problems may differ and may not be
attained. Such SDPs are both theoretically interesting and often impossible to
solve; yet, the pathological SDPs in the literature look strikingly similar.
Based on our recent work \cite{Pataki:17} we characterize pathological
semidefinite systems by certain {\em excluded matrices}, which are easy to spot
in all published examples. Our main tool is a normal (canonical) form of
semidefinite systems, which makes their pathological behavior easy to verify.
The normal form is constructed in a surprisingly simple fashion, using mostly
elementary row operations inherited from Gaussian elimination. The proofs are
elementary and can be followed by a reader at the advanced undergraduate level.
As a byproduct, we show how to transform any linear map acting on symmetric
matrices into a normal form, which allows us to quickly check whether the image
of the semidefinite cone under the map is closed. We can thus introduce readers
to a fundamental issue in convex analysis: the linear image of a closed convex
set may not be closed, and often simple conditions are available to verify the
closedness, or lack of it.
-
LaSalle invariance principle was originally proposed in the 1950's and has
become a fundamental mathematical tool in the area of dynamical systems and
control. In both theoretical research and engineering practice, discrete-time
dynamical systems have been at least as extensively studied as continuous-time
systems. For example, model predictive control is typically studied in
discrete-time via Lyapunov methods. However, there is a peculiar absence in the
standard literature of standard treatments of Lyapunov functions and LaSalle
invariance principle for discrete-time nonlinear systems. Most of the textbooks
on nonlinear dynamical systems focus only on continuous-time systems. In
Chapter 1 of the book by LaSalle [11], the author establishes the LaSalle
invariance principle for difference equation systems. However, all the useful
lemmas in [11] are given in the form of exercises with no proof provided. In
this document, we provide the proofs of all the lemmas proposed in [11] that
are needed to derive the main theorem on the LaSalle invariance principle for
discrete-time dynamical systems. We organize all the materials in a
self-contained manner. We first introduce some basic concepts and definitions
in Section 1, such as dynamical systems, invariant sets, and limit sets. In
Section 2 we present and prove some useful lemmas on the properties of
invariant sets and limit sets. Finally, we establish the original LaSalle
invariance principle for discrete-time dynamical systems and a simple extension
in Section~3. In Section 4, we provide some references on extensions of LaSalle
invariance principles for further reading. This document is intended for
educational and tutorial purposes and contains lemmas that might be useful as a
reference for researchers.
-
We study some optimal control problems on networks with junctions,
approximate the junctions by a switching rule of delay-relay type and study the
passage to the limit when $\varepsilon$, the parameter of the approximation,
goes to zero. First, for a twofold junction problem we characterize the limit
value function as viscosity solution and maximal subsolution of a suitable
Hamilton-Jacobi problem. Then, for a threefold junction problem we consider two
different approximations, recovering in both cases some uniqueness results in
the sense of maximal subsolution.
-
We study the problem of decentralized secondary frequency regulation in power
networks where ancillary services are provided via on-off load-side
participation. We initially consider on-off loads that switch when prescribed
frequency thresholds are exceeded, together with a large class of passive
continuous dynamics for generation and demand. The considered on-off loads are
able to assist existing secondary frequency control mechanisms and return to
their nominal operation when the power system is restored to its normal
operation, a highly desirable feature which minimizes users disruption. We show
that system stability is not compromised despite the switching nature of the
loads. However, such control policies are prone to chattering, which limits the
practicality of these schemes. As a remedy to this problem, we propose a
hysteretic on-off policy where loads switch on and off at different frequency
thresholds and show that stability guarantees are retained when the same
decentralized passivity conditions for continuous generation and demand hold.
Several relevant examples are discussed to demonstrate the applicability of the
proposed results. Furthermore, we verify our analytic results with numerical
investigations on the Northeast Power Coordinating Council (NPCC) 140-bus
system.
-
In this article, inspired by Shi, et al. we investigate the optimal portfolio
selection with one risk-free asset and one risky asset in a multiple period
setting under cumulative prospect theory (CPT). Compared with their study, our
novelty is that we consider a stochastic benchmark, and portfolio constraints.
We test the sensitivity of the optimal CPT-investment strategies to different
model parameters by performing a numerical analysis.
-
Distributed machine learning algorithms enable learning of models from
datasets that are distributed over a network without gathering the data at a
centralized location. While efficient distributed algorithms have been
developed under the assumption of faultless networks, failures that can render
these algorithms nonfunctional occur frequently in the real world. This paper
focuses on the problem of Byzantine failures, which are the hardest to
safeguard against in distributed algorithms. While Byzantine fault tolerance
has a rich history, existing work does not translate into efficient and
practical algorithms for high-dimensional learning in fully distributed (also
known as decentralized) settings. In this paper, an algorithm termed
Byzantine-resilient distributed coordinate descent (ByRDiE) is developed and
analyzed that enables distributed learning in the presence of Byzantine
failures. Theoretical analysis (convex settings) and numerical experiments
(convex and nonconvex settings) highlight its usefulness for high-dimensional
distributed learning in the presence of Byzantine failures.
-
This paper introduces a theoretical framework for the analysis and control of
the stochastic susceptible-infected-removed (SIR) spreading process over a
network of heterogeneous agents. In our analysis, we analyze the exact
networked Markov process describing the SIR model, without resorting to
mean-field approximations, and introduce a convex optimization framework to
find an efficient allocation of resources to contain the expected number of
accumulated infections over time. Numerical simulations are presented to
illustrate the effectiveness of the obtained results.
-
Information communicated within cyber-physical systems (CPSs) is often used
in determining the physical states of such systems, and malicious adversaries
may intercept these communications in order to infer future states of a CPS or
its components. Accordingly, there arises a need to protect the state values of
a system. Recently, the notion of differential privacy has been used to protect
state trajectories in dynamical systems, and it is this notion of privacy that
we use here to protect the state trajectories of CPSs. We incorporate a cloud
computer to coordinate the agents comprising the CPSs of interest, and the
cloud offers the ability to remotely coordinate many agents, rapidly perform
computations, and broadcast the results, making it a natural fit for systems
with many interacting agents or components. Striving for broad applicability,
we solve infinite-horizon linear-quadratic-regulator (LQR) problems, and each
agent protects its own state trajectory by adding noise to its states before
they are sent to the cloud. The cloud then uses these state values to generate
optimal inputs for the agents. As a result, private data is fed into feedback
loops at each iteration, and each noisy term affects every future state of
every agent. In this paper, we show that the differentially private LQR problem
can be related to the well-studied linear-quadratic-Gaussian (LQG) problem, and
we provide bounds on how agents' privacy requirements affect the cloud's
ability to generate optimal feedback control values for the agents. These
results are illustrated in numerical simulations.
-
Control problems not admitting the dynamic programming principle are known as
time-inconsistent. The game-theoretic approach is to interpret such problems as
intrapersonal dynamic games and look for subgame perfect Nash equilibria. A
fundamental result of time-inconsistent stochastic control is a verification
theorem saying that solving the extended HJB system is a sufficient condition
for equilibrium. We show that solving the extended HJB system is a necessary
condition for equilibrium, under regularity assumptions. The controlled process
is a general It\^o diffusion.
-
We analyze the learning properties of the stochastic gradient method when
multiple passes over the data and mini-batches are allowed. We study how
regularization properties are controlled by the step-size, the number of passes
and the mini-batch size. In particular, we consider the square loss and show
that for a universal step-size choice, the number of passes acts as a
regularization parameter, and optimal finite sample bounds can be achieved by
early-stopping. Moreover, we show that larger step-sizes are allowed when
considering mini-batches. Our analysis is based on a unifying approach,
encompassing both batch and stochastic gradient methods as special cases. As a
byproduct, we derive optimal convergence results for batch gradient methods
(even in the non-attainable cases).
-
We study fundamental performance limitations of distributed feedback control
in large-scale networked dynamical systems. Specifically, we address the
question of whether dynamic feedback controllers perform better than static
(memoryless) ones when subject to locality constraints. We consider distributed
linear consensus and vehicular formation control problems modeled over toric
lattice networks. For the resulting spatially invariant systems we study the
large-scale asymptotics (in network size) of global performance metrics that
quantify the level of network coherence. With static feedback from relative
state measurements, such metrics are known to scale unfavorably in lattices of
low spatial dimensions, preventing, for example, a 1-dimensional string of
vehicles to move like a rigid object. We show that the same limitations in
general apply also to dynamic feedback control that is locally of first order.
This means that the addition of one local state to the controller gives a
similar asymptotic performance to the memoryless case. This holds unless the
controller can access noiseless measurements of its local state with respect to
an absolute reference frame, in which case the addition of controller memory
may fundamentally improve performance. In simulations of platoons with 20-200
vehicles we show that the performance limitations we derive manifest as
unwanted accordion-like motions. Similar behaviors are to be expected in any
network that is embeddable in a low-dimensional toric lattice, and the same
fundamental limitations would apply. To derive our results, we present a
general technical framework for the analysis of stability and performance of
spatially invariant systems in the limit of large networks.
-
We explore the lifting question in the context of cut-generating functions.
Most of the prior literature on this question focuses on cut-generating
functions that have the unique lifting property. We develop a general theory
for understanding the lifting question for cut-generating functions that do not
necessarily have the unique lifting property.
-
This document presents a (mostly) chronologically ordered bibliography of
scientific publications on the superiorization methodology and perturbation
resilience of algorithms which is compiled and continuously updated by us at:
http://math.haifa.ac.il/yair/bib-superiorization-censor.html. Since the
beginnings of this topic we try to trace the work that has been published about
it since its inception. To the best of our knowledge this bibliography
represents all available publications on this topic to date, and while the URL
is continuously updated we will revise this document and bring it up to date on
arXiv approximately once a year. Abstracts of the cited works, and some links
and downloadable files of preprints or reprints are available on the above
mentioned Internet page. If you know of a related scientific work in any form
that should be included here kindly write to me on: yair@math.haifa.ac.il with
full bibliographic details, a DOI if available, and a PDF copy of the work if
possible. The Internet page was initiated on March 7, 2015, and has been last
updated on March 2, 2021.
Comment: Some of the items have on the above mentioned Internet page more
information and links than in this report.
Acknowledgment: This work was supported by the ISF-NSFC joint research
program grant No. 2874/19.
-
Let $A$ be an $(m \times n)$ integral matrix, and let $P=\{ x : A x \leq b\}$
be an $n$-dimensional polytope. The width of $P$ is defined as $ w(P)=min\{
x\in \mathbb{Z}^n\setminus\{0\} :\: max_{x \in P} x^\top u - min_{x \in P}
x^\top v \}$. Let $\Delta(A)$ and $\delta(A)$ denote the greatest and the
smallest absolute values of a determinant among all $r(A) \times r(A)$
sub-matrices of $A$, where $r(A)$ is the rank of a matrix $A$. We prove that if
every $r(A) \times r(A)$ sub-matrix of $A$ has a determinant equal to $\pm
\Delta(A)$ or $0$ and $w(P)\ge (\Delta(A)-1)(n+1)$, then $P$ contains $n$
affine independent integer points. Also we have similar results for the case of
\emph{$k$-modular} matrices. The matrix $A$ is called \emph{totally
$k$-modular} if every square sub-matrix of $A$ has a determinant in the set
$\{0,\, \pm k^r :\: r \in \mathbb{N} \}$. When $P$ is a simplex and $w(P)\ge
\delta(A)-1$, we describe a polynomial time algorithm for finding an integer
point in $P$. Finally we show that if $A$ is \emph{almost unimodular}, then
integer program $\max \{c^\top x :\: x \in P \cap \mathbb{Z}^n \}$ can be
solved in polynomial time. The matrix $A$ is called \emph{almost unimodular} if
$\Delta(A) \leq 2$ and any $(r(A)-1)\times(r(A)-1)$ sub-matrix has a
determinant from the set $\{0,\pm 1\}$.
-
This paper investigates the behavior of the Min-Sum message passing scheme to
solve systems of linear equations in the Laplacian matrices of graphs and to
compute electric flows. Voltage and flow problems involve the minimization of
quadratic functions and are fundamental primitives that arise in several
domains. Algorithms that have been proposed are typically centralized and
involve multiple graph-theoretic constructions or sampling mechanisms that make
them difficult to implement and analyze. On the other hand, message passing
routines are distributed, simple, and easy to implement. In this paper we
establish a framework to analyze Min-Sum to solve voltage and flow problems. We
characterize the error committed by the algorithm on general weighted graphs in
terms of hitting times of random walks defined on the computation trees that
support the operations of the algorithms with time. For $d$-regular graphs with
equal weights, we show that the convergence of the algorithms is controlled by
the total variation distance between the distributions of non-backtracking
random walks defined on the original graph that start from neighboring nodes.
The framework that we introduce extends the analysis of Min-Sum to settings
where the contraction arguments previously considered in the literature (based
on the assumption of walk summability or scaled diagonal dominance) can not be
used, possibly in the presence of constraints.
-
Accounting for model uncertainty in risk management and option pricing leads
to infinite dimensional optimization problems which are both analytically and
numerically intractable. In this article we study when this hurdle can be
overcome for the so-called optimized certainty equivalent risk measure (OCE) --
including the average value-at-risk as a special case. First we focus on the
case where the uncertainty is modeled by a nonlinear expectation penalizing
distributions that are "far" in terms of optimal-transport distance
(Wasserstein distance for instance) from a given baseline distribution. It
turns out that the computation of the robust OCE reduces to a finite
dimensional problem, which in some cases can even be solved explicitly. This
principle also applies to the shortfall risk measure as well as for the pricing
of European options. Further, we derive convex dual representations of the
robust OCE for measurable claims without any assumptions on the set of
distributions. Finally, we give conditions on the latter set under which the
robust average value-at-risk is a tail risk measure.
-
Large networks of queueing systems model important real-world systems such as
MapReduce clusters, web-servers, hospitals, call centers and airport passenger
terminals. To model such systems accurately, we must infer queueing parameters
from data. Unfortunately, for many queueing networks there is no clear way to
proceed with parameter inference from data. Approximate Bayesian computation
could offer a straightforward way to infer parameters for such networks if we
could simulate data quickly enough.
We present a computationally efficient method for simulating from a very
general set of queueing networks with the R package queuecomputer. Remarkable
speedups of more than 2 orders of magnitude are observed relative to the
popular DES packages simmer and simpy. We replicate output from these packages
to validate the package.
The package is modular and integrates well with the popular R package dplyr.
Complex queueing networks with tandem, parallel and fork/join topologies can
easily be built with these two packages together. We show how to use this
package with two examples: a call center and an airport terminal.
-
This paper investigates the synthesis of distributed economic control
algorithms under which dynamically coupled physical systems are regulated to a
variational equilibrium of a constrained convex game. We study two
complementary cases: (i) each subsystem is linear and controllable; and (ii)
each subsystem is nonlinear and in the strict-feedback form. The convergence of
the proposed algorithms is guaranteed using Lyapunov analysis. Their
performance is verified by two case studies on a multi-zone building
temperature regulation problem and an optimal power flow problem, respectively.
-
This paper develops an analytic framework to design both stress-controlled
and displacement-controlled T-periodic loadings which make the quasistatic
evolution of a one-dimensional network of elastoplastic springs converging to a
unique periodic regime. The solution of such an evolution problem is a function
t-> (e(t),p(t)), where e_i(t) and p_i(t) are the elastic and plastic
deformations of spring i, defined on [t0,\infty) by the initial condition
(e(t0),p(t0)).
After we rigorously convert the problem into a Moreau sweeping process with a
moving polyhedron C(t) in a vector space E of dimension d, it becomes natural
to expect (based on a result by Krejci) that the solution t->(e(t),p(t)) always
converges to a T-periodic function. The achievement of this paper is in
spotting a class of loadings where the Krejci's limit doesn't depend on the
initial condition (e(t0),p(t0)) and so all the trajectories approach the same
T-periodic regime. The proposed class of sweeping processes is the one for
which the normal vectors of any d different facets of the moving polyhedron
C(t) are linearly independent. We further link this geometric condition to
mechanical properties of the given network of springs. We discover that the
normal vectors of any d different facets of the moving polyhedron C(t) are
linearly independent, if the number of displacement-controlled loadings is two
less the number of nodes of the given network of springs and when the magnitude
of the stress-controlled loading is sufficiently large (but admissible). The
result can be viewed as an analogue of the high-gain control method for
elastoplastic systems. In continuum theory of plasticity, the respective result
is known as Frederick-Armstrong theorem.
-
The classic Alternating Direction Method of Multipliers (ADMM) is a popular
framework to solve linear-equality constrained problems. In this paper, we
extend the ADMM naturally to nonlinear equality-constrained problems, called
neADMM. The difficulty of neADMM is to solve nonconvex subproblems. We provide
globally optimal solutions to them in two important applications. Experiments
on synthetic and real-world datasets demonstrate excellent performance and
scalability of our proposed neADMM over existing state-of-the-start methods.
-
In stochastic simulation, input uncertainty (IU) is caused by the error in
estimating the input distributions using finite real-world data. When it comes
to simulation-based Ranking and Selection (R&S), ignoring IU could lead to the
failure of many existing selection procedures. In this paper, we study R&S
under IU by allowing the possibility of acquiring additional data. Two
classical R&S formulations are extended to account for IU: (i) for fixed
confidence, we consider when data arrive sequentially so that IU can be reduced
over time; (ii) for fixed budget, a joint budget is assumed to be available for
both collecting input data and running simulations. New procedures are proposed
for each formulation using the frameworks of Sequential Elimination and Optimal
Computing Budget Allocation, with theoretical guarantees provided accordingly
(e.g., upper bound on the expected running time and finite-sample bound on the
probability of false selection). Numerical results demonstrate the
effectiveness of our procedures through a multi-stage production-inventory
problem.
-
We derive a closed form description of the convex hull of mixed-integer
bilinear covering set with bounds on the integer variables. This convex hull
description is determined by considering some orthogonal disjunctive sets
defined in a certain way. This description does not introduce any new
variables, but consists of exponentially many inequalities. An extended
formulation with a few extra variables and much smaller number of constraints
is presented. We also derive a linear time separation algorithm for finding the
facet defining inequalities of this convex hull. We study the effectiveness of
the new inequalities and the extended formulation using some examples.
-
Motivated by applications arising from large scale optimization and machine
learning, we consider stochastic quasi-Newton (SQN) methods for solving
unconstrained convex optimization problems. The convergence analysis of the SQN
methods, both full and limited-memory variants, require the objective function
to be strongly convex. However, this assumption is fairly restrictive and does
not hold for applications such as minimizing the logistic regression loss
function. To the best of our knowledge, no rate statements currently exist for
SQN methods in the absence of such an assumption. Also, among the existing
first-order methods for addressing stochastic optimization problems with merely
convex objectives, those equipped with provable convergence rates employ
averaging. However, this averaging technique has a detrimental impact on
inducing sparsity. Motivated by these gaps, the main contributions of the paper
are as follows: (i) Addressing large scale stochastic optimization problems, we
develop an iteratively regularized stochastic limited-memory BFGS (IRS-LBFGS)
algorithm, where the stepsize, regularization parameter, and the Hessian
inverse approximation matrix are updated iteratively. We establish the
convergence to an optimal solution of the original problem both in an
almost-sure and mean senses. We derive the convergence rate in terms of the
objective function's values and show that it is of the order
$\mathcal{O}\left(k^{-\left(\frac{1}{3}-\epsilon\right)}\right)$, where
$\epsilon$ is an arbitrary small positive scalar; (ii) In deterministic regime,
we show that the regularized limited-memory BFGS algorithm displays a rate of
the order $\mathcal{O}\left(\frac{1}{k^{1 -\epsilon'}}\right)$, where
$\epsilon'$ is an arbitrary small positive scalar. We present our numerical
experiments performed on a large scale text classification problem.
-
We propose a new method for simplifying semidefinite programs (SDP) inspired
by symmetry reduction. Specifically, we show if an orthogonal projection map
satisfies certain invariance conditions, restricting to its range yields an
equivalent primal-dual pair over a lower-dimensional symmetric cone---namely,
the cone-of-squares of a Jordan subalgebra of symmetric matrices. We present a
simple algorithm for minimizing the rank of this projection and hence the
dimension of this subalgebra. We also show that minimizing rank optimizes the
direct-sum decomposition of the algebra into simple ideals, yielding an optimal
"block-diagonalization" of the SDP. Finally, we give combinatorial versions of
our algorithm that execute at reduced computational cost and illustrate
effectiveness of an implementation on examples. Through the theory of Jordan
algebras, the proposed method easily extends to linear and second-order-cone
programming and, more generally, symmetric cone optimization.
-
We present a mathematical analysis of a non-convex energy landscape for
robust subspace recovery. We prove that an underlying subspace is the only
stationary point and local minimizer in a specified neighborhood under a
deterministic condition on a dataset. If the deterministic condition is
satisfied, we further show that a geodesic gradient descent method over the
Grassmannian manifold can exactly recover the underlying subspace when the
method is properly initialized. Proper initialization by principal component
analysis is guaranteed with a simple deterministic condition. Under slightly
stronger assumptions, the gradient descent method with a piecewise constant
step-size scheme achieves linear convergence. The practicality of the
deterministic condition is demonstrated on some statistical models of data, and
the method achieves almost state-of-the-art recovery guarantees on the Haystack
Model for different regimes of sample size and ambient dimension. In
particular, when the ambient dimension is fixed and the sample size is large
enough, we show that our gradient method can exactly recover the underlying
subspace for any fixed fraction of outliers (less than 1).





 We study the problem of decentralized secondary frequency regulation in power networks where ancillary services are provided via on-off load-side participation. We initially consider on-off loads that switch when prescribed frequency thresholds are exceeded, together with a large class of passive continuous dynamics for generation and demand. The considered on-off loads are able to assist existing secondary frequency control mechanisms and return to their nominal operation when the power system is restored to its normal operation, a highly desirable feature which minimizes users disruption. We show that system stability is not compromised despite the switching nature of the loads. However, such control policies are prone to chattering, which limits the practicality of these schemes. As a remedy to this problem, we propose a hysteretic on-off policy where loads switch on and off at different frequency thresholds and show that stability guarantees are retained when the same decentralized passivity conditions for continuous generation and demand hold. Several relevant examples are discussed to demonstrate the applicability of the proposed results. Furthermore, we verify our analytic results with numerical investigations on the Northeast Power Coordinating Council (NPCC) 140-bus system.
We study the problem of decentralized secondary frequency regulation in power networks where ancillary services are provided via on-off load-side participation. We initially consider on-off loads that switch when prescribed frequency thresholds are exceeded, together with a large class of passive continuous dynamics for generation and demand. The considered on-off loads are able to assist existing secondary frequency control mechanisms and return to their nominal operation when the power system is restored to its normal operation, a highly desirable feature which minimizes users disruption. We show that system stability is not compromised despite the switching nature of the loads. However, such control policies are prone to chattering, which limits the practicality of these schemes. As a remedy to this problem, we propose a hysteretic on-off policy where loads switch on and off at different frequency thresholds and show that stability guarantees are retained when the same decentralized passivity conditions for continuous generation and demand hold. Several relevant examples are discussed to demonstrate the applicability of the proposed results. Furthermore, we verify our analytic results with numerical investigations on the Northeast Power Coordinating Council (NPCC) 140-bus system.




 In this article, inspired by Shi, et al. we investigate the optimal portfolio selection with one risk-free asset and one risky asset in a multiple period setting under cumulative prospect theory (CPT). Compared with their study, our novelty is that we consider a stochastic benchmark, and portfolio constraints. We test the sensitivity of the optimal CPT-investment strategies to different model parameters by performing a numerical analysis.
In this article, inspired by Shi, et al. we investigate the optimal portfolio selection with one risk-free asset and one risky asset in a multiple period setting under cumulative prospect theory (CPT). Compared with their study, our novelty is that we consider a stochastic benchmark, and portfolio constraints. We test the sensitivity of the optimal CPT-investment strategies to different model parameters by performing a numerical analysis.




 Distributed machine learning algorithms enable learning of models from datasets that are distributed over a network without gathering the data at a centralized location. While efficient distributed algorithms have been developed under the assumption of faultless networks, failures that can render these algorithms nonfunctional occur frequently in the real world. This paper focuses on the problem of Byzantine failures, which are the hardest to safeguard against in distributed algorithms. While Byzantine fault tolerance has a rich history, existing work does not translate into efficient and practical algorithms for high-dimensional learning in fully distributed (also known as decentralized) settings. In this paper, an algorithm termed Byzantine-resilient distributed coordinate descent (ByRDiE) is developed and analyzed that enables distributed learning in the presence of Byzantine failures. Theoretical analysis (convex settings) and numerical experiments (convex and nonconvex settings) highlight its usefulness for high-dimensional distributed learning in the presence of Byzantine failures.
Distributed machine learning algorithms enable learning of models from datasets that are distributed over a network without gathering the data at a centralized location. While efficient distributed algorithms have been developed under the assumption of faultless networks, failures that can render these algorithms nonfunctional occur frequently in the real world. This paper focuses on the problem of Byzantine failures, which are the hardest to safeguard against in distributed algorithms. While Byzantine fault tolerance has a rich history, existing work does not translate into efficient and practical algorithms for high-dimensional learning in fully distributed (also known as decentralized) settings. In this paper, an algorithm termed Byzantine-resilient distributed coordinate descent (ByRDiE) is developed and analyzed that enables distributed learning in the presence of Byzantine failures. Theoretical analysis (convex settings) and numerical experiments (convex and nonconvex settings) highlight its usefulness for high-dimensional distributed learning in the presence of Byzantine failures.



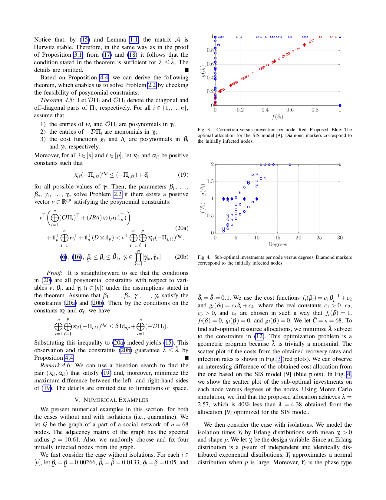
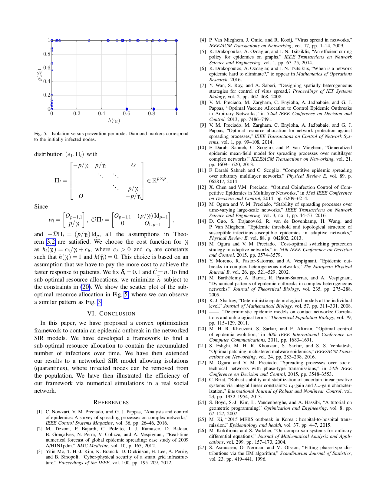 This paper introduces a theoretical framework for the analysis and control of the stochastic susceptible-infected-removed (SIR) spreading process over a network of heterogeneous agents. In our analysis, we analyze the exact networked Markov process describing the SIR model, without resorting to mean-field approximations, and introduce a convex optimization framework to find an efficient allocation of resources to contain the expected number of accumulated infections over time. Numerical simulations are presented to illustrate the effectiveness of the obtained results.
This paper introduces a theoretical framework for the analysis and control of the stochastic susceptible-infected-removed (SIR) spreading process over a network of heterogeneous agents. In our analysis, we analyze the exact networked Markov process describing the SIR model, without resorting to mean-field approximations, and introduce a convex optimization framework to find an efficient allocation of resources to contain the expected number of accumulated infections over time. Numerical simulations are presented to illustrate the effectiveness of the obtained results.




 Control problems not admitting the dynamic programming principle are known as time-inconsistent. The game-theoretic approach is to interpret such problems as intrapersonal dynamic games and look for subgame perfect Nash equilibria. A fundamental result of time-inconsistent stochastic control is a verification theorem saying that solving the extended HJB system is a sufficient condition for equilibrium. We show that solving the extended HJB system is a necessary condition for equilibrium, under regularity assumptions. The controlled process is a general It\^o diffusion.
Control problems not admitting the dynamic programming principle are known as time-inconsistent. The game-theoretic approach is to interpret such problems as intrapersonal dynamic games and look for subgame perfect Nash equilibria. A fundamental result of time-inconsistent stochastic control is a verification theorem saying that solving the extended HJB system is a sufficient condition for equilibrium. We show that solving the extended HJB system is a necessary condition for equilibrium, under regularity assumptions. The controlled process is a general It\^o diffusion.




 We analyze the learning properties of the stochastic gradient method when multiple passes over the data and mini-batches are allowed. We study how regularization properties are controlled by the step-size, the number of passes and the mini-batch size. In particular, we consider the square loss and show that for a universal step-size choice, the number of passes acts as a regularization parameter, and optimal finite sample bounds can be achieved by early-stopping. Moreover, we show that larger step-sizes are allowed when considering mini-batches. Our analysis is based on a unifying approach, encompassing both batch and stochastic gradient methods as special cases. As a byproduct, we derive optimal convergence results for batch gradient methods (even in the non-attainable cases).
We analyze the learning properties of the stochastic gradient method when multiple passes over the data and mini-batches are allowed. We study how regularization properties are controlled by the step-size, the number of passes and the mini-batch size. In particular, we consider the square loss and show that for a universal step-size choice, the number of passes acts as a regularization parameter, and optimal finite sample bounds can be achieved by early-stopping. Moreover, we show that larger step-sizes are allowed when considering mini-batches. Our analysis is based on a unifying approach, encompassing both batch and stochastic gradient methods as special cases. As a byproduct, we derive optimal convergence results for batch gradient methods (even in the non-attainable cases).




 We explore the lifting question in the context of cut-generating functions. Most of the prior literature on this question focuses on cut-generating functions that have the unique lifting property. We develop a general theory for understanding the lifting question for cut-generating functions that do not necessarily have the unique lifting property.
We explore the lifting question in the context of cut-generating functions. Most of the prior literature on this question focuses on cut-generating functions that have the unique lifting property. We develop a general theory for understanding the lifting question for cut-generating functions that do not necessarily have the unique lifting property.




 This document presents a (mostly) chronologically ordered bibliography of scientific publications on the superiorization methodology and perturbation resilience of algorithms which is compiled and continuously updated by us at: http://math.haifa.ac.il/yair/bib-superiorization-censor.html. Since the beginnings of this topic we try to trace the work that has been published about it since its inception. To the best of our knowledge this bibliography represents all available publications on this topic to date, and while the URL is continuously updated we will revise this document and bring it up to date on arXiv approximately once a year. Abstracts of the cited works, and some links and downloadable files of preprints or reprints are available on the above mentioned Internet page. If you know of a related scientific work in any form that should be included here kindly write to me on: yair@math.haifa.ac.il with full bibliographic details, a DOI if available, and a PDF copy of the work if possible. The Internet page was initiated on March 7, 2015, and has been last updated on March 2, 2021. Comment: Some of the items have on the above mentioned Internet page more information and links than in this report. Acknowledgment: This work was supported by the ISF-NSFC joint research program grant No. 2874/19.
This document presents a (mostly) chronologically ordered bibliography of scientific publications on the superiorization methodology and perturbation resilience of algorithms which is compiled and continuously updated by us at: http://math.haifa.ac.il/yair/bib-superiorization-censor.html. Since the beginnings of this topic we try to trace the work that has been published about it since its inception. To the best of our knowledge this bibliography represents all available publications on this topic to date, and while the URL is continuously updated we will revise this document and bring it up to date on arXiv approximately once a year. Abstracts of the cited works, and some links and downloadable files of preprints or reprints are available on the above mentioned Internet page. If you know of a related scientific work in any form that should be included here kindly write to me on: yair@math.haifa.ac.il with full bibliographic details, a DOI if available, and a PDF copy of the work if possible. The Internet page was initiated on March 7, 2015, and has been last updated on March 2, 2021. Comment: Some of the items have on the above mentioned Internet page more information and links than in this report. Acknowledgment: This work was supported by the ISF-NSFC joint research program grant No. 2874/19.




 Let $A$ be an $(m \times n)$ integral matrix, and let $P=\{ x : A x \leq b\}$ be an $n$-dimensional polytope. The width of $P$ is defined as $ w(P)=min\{ x\in \mathbb{Z}^n\setminus\{0\} :\: max_{x \in P} x^\top u - min_{x \in P} x^\top v \}$. Let $\Delta(A)$ and $\delta(A)$ denote the greatest and the smallest absolute values of a determinant among all $r(A) \times r(A)$ sub-matrices of $A$, where $r(A)$ is the rank of a matrix $A$. We prove that if every $r(A) \times r(A)$ sub-matrix of $A$ has a determinant equal to $\pm \Delta(A)$ or $0$ and $w(P)\ge (\Delta(A)-1)(n+1)$, then $P$ contains $n$ affine independent integer points. Also we have similar results for the case of \emph{$k$-modular} matrices. The matrix $A$ is called \emph{totally $k$-modular} if every square sub-matrix of $A$ has a determinant in the set $\{0,\, \pm k^r :\: r \in \mathbb{N} \}$. When $P$ is a simplex and $w(P)\ge \delta(A)-1$, we describe a polynomial time algorithm for finding an integer point in $P$. Finally we show that if $A$ is \emph{almost unimodular}, then integer program $\max \{c^\top x :\: x \in P \cap \mathbb{Z}^n \}$ can be solved in polynomial time. The matrix $A$ is called \emph{almost unimodular} if $\Delta(A) \leq 2$ and any $(r(A)-1)\times(r(A)-1)$ sub-matrix has a determinant from the set $\{0,\pm 1\}$.
Let $A$ be an $(m \times n)$ integral matrix, and let $P=\{ x : A x \leq b\}$ be an $n$-dimensional polytope. The width of $P$ is defined as $ w(P)=min\{ x\in \mathbb{Z}^n\setminus\{0\} :\: max_{x \in P} x^\top u - min_{x \in P} x^\top v \}$. Let $\Delta(A)$ and $\delta(A)$ denote the greatest and the smallest absolute values of a determinant among all $r(A) \times r(A)$ sub-matrices of $A$, where $r(A)$ is the rank of a matrix $A$. We prove that if every $r(A) \times r(A)$ sub-matrix of $A$ has a determinant equal to $\pm \Delta(A)$ or $0$ and $w(P)\ge (\Delta(A)-1)(n+1)$, then $P$ contains $n$ affine independent integer points. Also we have similar results for the case of \emph{$k$-modular} matrices. The matrix $A$ is called \emph{totally $k$-modular} if every square sub-matrix of $A$ has a determinant in the set $\{0,\, \pm k^r :\: r \in \mathbb{N} \}$. When $P$ is a simplex and $w(P)\ge \delta(A)-1$, we describe a polynomial time algorithm for finding an integer point in $P$. Finally we show that if $A$ is \emph{almost unimodular}, then integer program $\max \{c^\top x :\: x \in P \cap \mathbb{Z}^n \}$ can be solved in polynomial time. The matrix $A$ is called \emph{almost unimodular} if $\Delta(A) \leq 2$ and any $(r(A)-1)\times(r(A)-1)$ sub-matrix has a determinant from the set $\{0,\pm 1\}$.




 This paper investigates the behavior of the Min-Sum message passing scheme to solve systems of linear equations in the Laplacian matrices of graphs and to compute electric flows. Voltage and flow problems involve the minimization of quadratic functions and are fundamental primitives that arise in several domains. Algorithms that have been proposed are typically centralized and involve multiple graph-theoretic constructions or sampling mechanisms that make them difficult to implement and analyze. On the other hand, message passing routines are distributed, simple, and easy to implement. In this paper we establish a framework to analyze Min-Sum to solve voltage and flow problems. We characterize the error committed by the algorithm on general weighted graphs in terms of hitting times of random walks defined on the computation trees that support the operations of the algorithms with time. For $d$-regular graphs with equal weights, we show that the convergence of the algorithms is controlled by the total variation distance between the distributions of non-backtracking random walks defined on the original graph that start from neighboring nodes. The framework that we introduce extends the analysis of Min-Sum to settings where the contraction arguments previously considered in the literature (based on the assumption of walk summability or scaled diagonal dominance) can not be used, possibly in the presence of constraints.
This paper investigates the behavior of the Min-Sum message passing scheme to solve systems of linear equations in the Laplacian matrices of graphs and to compute electric flows. Voltage and flow problems involve the minimization of quadratic functions and are fundamental primitives that arise in several domains. Algorithms that have been proposed are typically centralized and involve multiple graph-theoretic constructions or sampling mechanisms that make them difficult to implement and analyze. On the other hand, message passing routines are distributed, simple, and easy to implement. In this paper we establish a framework to analyze Min-Sum to solve voltage and flow problems. We characterize the error committed by the algorithm on general weighted graphs in terms of hitting times of random walks defined on the computation trees that support the operations of the algorithms with time. For $d$-regular graphs with equal weights, we show that the convergence of the algorithms is controlled by the total variation distance between the distributions of non-backtracking random walks defined on the original graph that start from neighboring nodes. The framework that we introduce extends the analysis of Min-Sum to settings where the contraction arguments previously considered in the literature (based on the assumption of walk summability or scaled diagonal dominance) can not be used, possibly in the presence of constraints.




 Accounting for model uncertainty in risk management and option pricing leads to infinite dimensional optimization problems which are both analytically and numerically intractable. In this article we study when this hurdle can be overcome for the so-called optimized certainty equivalent risk measure (OCE) -- including the average value-at-risk as a special case. First we focus on the case where the uncertainty is modeled by a nonlinear expectation penalizing distributions that are "far" in terms of optimal-transport distance (Wasserstein distance for instance) from a given baseline distribution. It turns out that the computation of the robust OCE reduces to a finite dimensional problem, which in some cases can even be solved explicitly. This principle also applies to the shortfall risk measure as well as for the pricing of European options. Further, we derive convex dual representations of the robust OCE for measurable claims without any assumptions on the set of distributions. Finally, we give conditions on the latter set under which the robust average value-at-risk is a tail risk measure.
Accounting for model uncertainty in risk management and option pricing leads to infinite dimensional optimization problems which are both analytically and numerically intractable. In this article we study when this hurdle can be overcome for the so-called optimized certainty equivalent risk measure (OCE) -- including the average value-at-risk as a special case. First we focus on the case where the uncertainty is modeled by a nonlinear expectation penalizing distributions that are "far" in terms of optimal-transport distance (Wasserstein distance for instance) from a given baseline distribution. It turns out that the computation of the robust OCE reduces to a finite dimensional problem, which in some cases can even be solved explicitly. This principle also applies to the shortfall risk measure as well as for the pricing of European options. Further, we derive convex dual representations of the robust OCE for measurable claims without any assumptions on the set of distributions. Finally, we give conditions on the latter set under which the robust average value-at-risk is a tail risk measure.




 Large networks of queueing systems model important real-world systems such as MapReduce clusters, web-servers, hospitals, call centers and airport passenger terminals. To model such systems accurately, we must infer queueing parameters from data. Unfortunately, for many queueing networks there is no clear way to proceed with parameter inference from data. Approximate Bayesian computation could offer a straightforward way to infer parameters for such networks if we could simulate data quickly enough. We present a computationally efficient method for simulating from a very general set of queueing networks with the R package queuecomputer. Remarkable speedups of more than 2 orders of magnitude are observed relative to the popular DES packages simmer and simpy. We replicate output from these packages to validate the package. The package is modular and integrates well with the popular R package dplyr. Complex queueing networks with tandem, parallel and fork/join topologies can easily be built with these two packages together. We show how to use this package with two examples: a call center and an airport terminal.
Large networks of queueing systems model important real-world systems such as MapReduce clusters, web-servers, hospitals, call centers and airport passenger terminals. To model such systems accurately, we must infer queueing parameters from data. Unfortunately, for many queueing networks there is no clear way to proceed with parameter inference from data. Approximate Bayesian computation could offer a straightforward way to infer parameters for such networks if we could simulate data quickly enough. We present a computationally efficient method for simulating from a very general set of queueing networks with the R package queuecomputer. Remarkable speedups of more than 2 orders of magnitude are observed relative to the popular DES packages simmer and simpy. We replicate output from these packages to validate the package. The package is modular and integrates well with the popular R package dplyr. Complex queueing networks with tandem, parallel and fork/join topologies can easily be built with these two packages together. We show how to use this package with two examples: a call center and an airport terminal.




 This paper develops an analytic framework to design both stress-controlled and displacement-controlled T-periodic loadings which make the quasistatic evolution of a one-dimensional network of elastoplastic springs converging to a unique periodic regime. The solution of such an evolution problem is a function t-> (e(t),p(t)), where e_i(t) and p_i(t) are the elastic and plastic deformations of spring i, defined on [t0,\infty) by the initial condition (e(t0),p(t0)). After we rigorously convert the problem into a Moreau sweeping process with a moving polyhedron C(t) in a vector space E of dimension d, it becomes natural to expect (based on a result by Krejci) that the solution t->(e(t),p(t)) always converges to a T-periodic function. The achievement of this paper is in spotting a class of loadings where the Krejci's limit doesn't depend on the initial condition (e(t0),p(t0)) and so all the trajectories approach the same T-periodic regime. The proposed class of sweeping processes is the one for which the normal vectors of any d different facets of the moving polyhedron C(t) are linearly independent. We further link this geometric condition to mechanical properties of the given network of springs. We discover that the normal vectors of any d different facets of the moving polyhedron C(t) are linearly independent, if the number of displacement-controlled loadings is two less the number of nodes of the given network of springs and when the magnitude of the stress-controlled loading is sufficiently large (but admissible). The result can be viewed as an analogue of the high-gain control method for elastoplastic systems. In continuum theory of plasticity, the respective result is known as Frederick-Armstrong theorem.
This paper develops an analytic framework to design both stress-controlled and displacement-controlled T-periodic loadings which make the quasistatic evolution of a one-dimensional network of elastoplastic springs converging to a unique periodic regime. The solution of such an evolution problem is a function t-> (e(t),p(t)), where e_i(t) and p_i(t) are the elastic and plastic deformations of spring i, defined on [t0,\infty) by the initial condition (e(t0),p(t0)). After we rigorously convert the problem into a Moreau sweeping process with a moving polyhedron C(t) in a vector space E of dimension d, it becomes natural to expect (based on a result by Krejci) that the solution t->(e(t),p(t)) always converges to a T-periodic function. The achievement of this paper is in spotting a class of loadings where the Krejci's limit doesn't depend on the initial condition (e(t0),p(t0)) and so all the trajectories approach the same T-periodic regime. The proposed class of sweeping processes is the one for which the normal vectors of any d different facets of the moving polyhedron C(t) are linearly independent. We further link this geometric condition to mechanical properties of the given network of springs. We discover that the normal vectors of any d different facets of the moving polyhedron C(t) are linearly independent, if the number of displacement-controlled loadings is two less the number of nodes of the given network of springs and when the magnitude of the stress-controlled loading is sufficiently large (but admissible). The result can be viewed as an analogue of the high-gain control method for elastoplastic systems. In continuum theory of plasticity, the respective result is known as Frederick-Armstrong theorem.




 The classic Alternating Direction Method of Multipliers (ADMM) is a popular framework to solve linear-equality constrained problems. In this paper, we extend the ADMM naturally to nonlinear equality-constrained problems, called neADMM. The difficulty of neADMM is to solve nonconvex subproblems. We provide globally optimal solutions to them in two important applications. Experiments on synthetic and real-world datasets demonstrate excellent performance and scalability of our proposed neADMM over existing state-of-the-start methods.
The classic Alternating Direction Method of Multipliers (ADMM) is a popular framework to solve linear-equality constrained problems. In this paper, we extend the ADMM naturally to nonlinear equality-constrained problems, called neADMM. The difficulty of neADMM is to solve nonconvex subproblems. We provide globally optimal solutions to them in two important applications. Experiments on synthetic and real-world datasets demonstrate excellent performance and scalability of our proposed neADMM over existing state-of-the-start methods.




 In stochastic simulation, input uncertainty (IU) is caused by the error in estimating the input distributions using finite real-world data. When it comes to simulation-based Ranking and Selection (R&S), ignoring IU could lead to the failure of many existing selection procedures. In this paper, we study R&S under IU by allowing the possibility of acquiring additional data. Two classical R&S formulations are extended to account for IU: (i) for fixed confidence, we consider when data arrive sequentially so that IU can be reduced over time; (ii) for fixed budget, a joint budget is assumed to be available for both collecting input data and running simulations. New procedures are proposed for each formulation using the frameworks of Sequential Elimination and Optimal Computing Budget Allocation, with theoretical guarantees provided accordingly (e.g., upper bound on the expected running time and finite-sample bound on the probability of false selection). Numerical results demonstrate the effectiveness of our procedures through a multi-stage production-inventory problem.
In stochastic simulation, input uncertainty (IU) is caused by the error in estimating the input distributions using finite real-world data. When it comes to simulation-based Ranking and Selection (R&S), ignoring IU could lead to the failure of many existing selection procedures. In this paper, we study R&S under IU by allowing the possibility of acquiring additional data. Two classical R&S formulations are extended to account for IU: (i) for fixed confidence, we consider when data arrive sequentially so that IU can be reduced over time; (ii) for fixed budget, a joint budget is assumed to be available for both collecting input data and running simulations. New procedures are proposed for each formulation using the frameworks of Sequential Elimination and Optimal Computing Budget Allocation, with theoretical guarantees provided accordingly (e.g., upper bound on the expected running time and finite-sample bound on the probability of false selection). Numerical results demonstrate the effectiveness of our procedures through a multi-stage production-inventory problem.



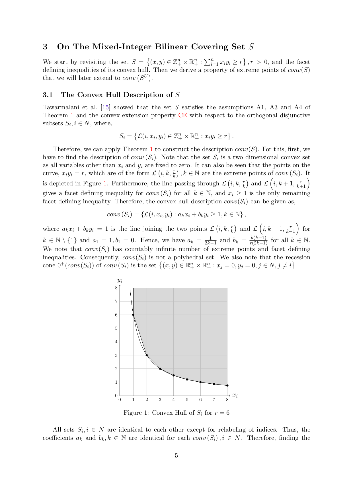
 We derive a closed form description of the convex hull of mixed-integer bilinear covering set with bounds on the integer variables. This convex hull description is determined by considering some orthogonal disjunctive sets defined in a certain way. This description does not introduce any new variables, but consists of exponentially many inequalities. An extended formulation with a few extra variables and much smaller number of constraints is presented. We also derive a linear time separation algorithm for finding the facet defining inequalities of this convex hull. We study the effectiveness of the new inequalities and the extended formulation using some examples.
We derive a closed form description of the convex hull of mixed-integer bilinear covering set with bounds on the integer variables. This convex hull description is determined by considering some orthogonal disjunctive sets defined in a certain way. This description does not introduce any new variables, but consists of exponentially many inequalities. An extended formulation with a few extra variables and much smaller number of constraints is presented. We also derive a linear time separation algorithm for finding the facet defining inequalities of this convex hull. We study the effectiveness of the new inequalities and the extended formulation using some examples.




 We propose a new method for simplifying semidefinite programs (SDP) inspired by symmetry reduction. Specifically, we show if an orthogonal projection map satisfies certain invariance conditions, restricting to its range yields an equivalent primal-dual pair over a lower-dimensional symmetric cone---namely, the cone-of-squares of a Jordan subalgebra of symmetric matrices. We present a simple algorithm for minimizing the rank of this projection and hence the dimension of this subalgebra. We also show that minimizing rank optimizes the direct-sum decomposition of the algebra into simple ideals, yielding an optimal "block-diagonalization" of the SDP. Finally, we give combinatorial versions of our algorithm that execute at reduced computational cost and illustrate effectiveness of an implementation on examples. Through the theory of Jordan algebras, the proposed method easily extends to linear and second-order-cone programming and, more generally, symmetric cone optimization.
We propose a new method for simplifying semidefinite programs (SDP) inspired by symmetry reduction. Specifically, we show if an orthogonal projection map satisfies certain invariance conditions, restricting to its range yields an equivalent primal-dual pair over a lower-dimensional symmetric cone---namely, the cone-of-squares of a Jordan subalgebra of symmetric matrices. We present a simple algorithm for minimizing the rank of this projection and hence the dimension of this subalgebra. We also show that minimizing rank optimizes the direct-sum decomposition of the algebra into simple ideals, yielding an optimal "block-diagonalization" of the SDP. Finally, we give combinatorial versions of our algorithm that execute at reduced computational cost and illustrate effectiveness of an implementation on examples. Through the theory of Jordan algebras, the proposed method easily extends to linear and second-order-cone programming and, more generally, symmetric cone optimization.

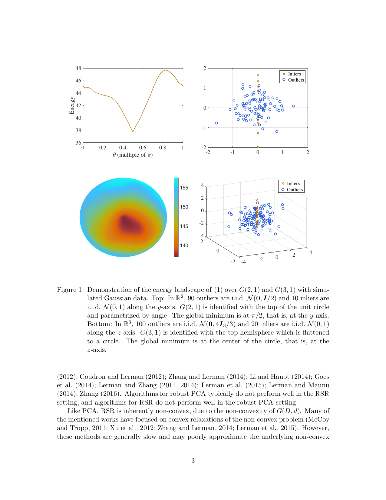


 We present a mathematical analysis of a non-convex energy landscape for robust subspace recovery. We prove that an underlying subspace is the only stationary point and local minimizer in a specified neighborhood under a deterministic condition on a dataset. If the deterministic condition is satisfied, we further show that a geodesic gradient descent method over the Grassmannian manifold can exactly recover the underlying subspace when the method is properly initialized. Proper initialization by principal component analysis is guaranteed with a simple deterministic condition. Under slightly stronger assumptions, the gradient descent method with a piecewise constant step-size scheme achieves linear convergence. The practicality of the deterministic condition is demonstrated on some statistical models of data, and the method achieves almost state-of-the-art recovery guarantees on the Haystack Model for different regimes of sample size and ambient dimension. In particular, when the ambient dimension is fixed and the sample size is large enough, we show that our gradient method can exactly recover the underlying subspace for any fixed fraction of outliers (less than 1).
We present a mathematical analysis of a non-convex energy landscape for robust subspace recovery. We prove that an underlying subspace is the only stationary point and local minimizer in a specified neighborhood under a deterministic condition on a dataset. If the deterministic condition is satisfied, we further show that a geodesic gradient descent method over the Grassmannian manifold can exactly recover the underlying subspace when the method is properly initialized. Proper initialization by principal component analysis is guaranteed with a simple deterministic condition. Under slightly stronger assumptions, the gradient descent method with a piecewise constant step-size scheme achieves linear convergence. The practicality of the deterministic condition is demonstrated on some statistical models of data, and the method achieves almost state-of-the-art recovery guarantees on the Haystack Model for different regimes of sample size and ambient dimension. In particular, when the ambient dimension is fixed and the sample size is large enough, we show that our gradient method can exactly recover the underlying subspace for any fixed fraction of outliers (less than 1).