-
In this article, inspired by Shi, et al. we investigate the optimal portfolio
selection with one risk-free asset and one risky asset in a multiple period
setting under cumulative prospect theory (CPT). Compared with their study, our
novelty is that we consider a stochastic benchmark, and portfolio constraints.
We test the sensitivity of the optimal CPT-investment strategies to different
model parameters by performing a numerical analysis.
-
This paper presents several models addressing optimal portfolio choice,
optimal portfolio liquidation, and optimal portfolio transition issues, in
which the expected returns of risky assets are unknown. Our approach is based
on a coupling between Bayesian learning and dynamic programming techniques that
leads to partial differential equations. It enables to recover the well-known
results of Karatzas and Zhao in a framework \`a la Merton, but also to deal
with cases where martingale methods are no longer available. In particular, we
address optimal portfolio choice, portfolio liquidation, and portfolio
transition problems in a framework \`a la Almgren-Chriss, and we build
therefore a model in which the agent takes into account in his decision process
both the liquidity of assets and the uncertainty with respect to their expected
return.
-
We introduce a new class of forward performance processes that are endogenous
and predictable with regards to an underlying market information set and,
furthermore, are updated at discrete times. We analyze in detail a binomial
model whose parameters are random and updated dynamically as the market
evolves. We show that the key step in the construction of the associated
predictable forward performance process is to solve a single-period inverse
investment problem, namely, to determine, period-by-period and conditionally on
the current market information, the end-time utility function from a given
initial-time value function. We reduce this inverse problem to solving a
functional equation and establish conditions for the existence and uniqueness
of its solutions in the class of inverse marginal functions.
-
How do macro-financial shocks affect investor behavior and market dynamics?
Recent evidence on experience effects suggests a long-lasting influence of
personally experienced outcomes on investor beliefs and investment, but also
significant differences across older and younger generations. We formalize
experience-based learning in an OLG model, where different cross-cohort
experiences generate persistent heterogeneity in beliefs, portfolio choices,
and trade. The model allows us to characterize a novel link between investor
demographics and the dependence of prices on past dividends, while also
generating known features of asset prices, such as excess volatility and return
predictability. The model produces new implications for the cross-section of
asset holdings, trade volume, and investors' heterogenous responses to recent
financial crises, which we show to be in line with the data.
-
We consider the robust exponential utility maximization problem in discrete
time: An investor maximizes the worst case expected exponential utility with
respect to a family of nondominated probabilistic models of her endowment by
dynamically investing in a financial market, and statically in available
options. We show that, for any measurable random endowment (regardless of
whether the problem is finite or not) an optimal strategy exists, a dual
representation in terms of (calibrated) martingale measures holds true, and
that the problem satisfies the dynamic programming principle (in case of no
options). Further it is shown that the value of the utility maximization
problem converges to the robust superhedging price as the risk aversion
parameter gets large, and examples of nondominated probabilistic models are
discussed.
-
We study portfolio selection in a model with both temporary and transient
price impact introduced by Garleanu and Pedersen (2016). In the large-liquidity
limit where both frictions are small, we derive explicit formulas for the
asymptotically optimal trading rate and the corresponding minimal leading-order
performance loss. We find that the losses are governed by the volatility of the
frictionless target strategy, like in models with only temporary price impact.
In contrast, the corresponding optimal portfolio not only tracks the
frictionless optimizer, but also exploits the displacement of the market price
from its unaffected level.
-
We study the Merton problem of optimal consumption-investment for the case of
two investors sharing a final wealth. The typical example would be a husband
and wife sharing a portfolio looking to optimize the expected utility of
consumption and final wealth. Each agent has different utility function and
discount factor. An explicit formulation for the optimal consumptions and
portfolio can be obtained in the case of a complete market. The problem is
shown to be equivalent to maximizing three different utilities separately with
separate initial wealths. We study a numerical example where the market price
of risk is assumed to be mean reverting, and provide insights on the influence
of risk aversion or discount rates on the initial optimal allocation.
-
We give complete algorithms and source code for constructing (multilevel)
statistical industry classifications, including methods for fixing the number
of clusters at each level (and the number of levels). Under the hood there are
clustering algorithms (e.g., k-means). However, what should we cluster?
Correlations? Returns? The answer turns out to be neither and our backtests
suggest that these details make a sizable difference. We also give an algorithm
and source code for building "hybrid" industry classifications by improving
off-the-shelf "fundamental" industry classifications by applying our
statistical industry classification methods to them. The presentation is
intended to be pedagogical and geared toward practical applications in
quantitative trading.
-
It is well known that combining multiple hedge fund alpha streams yields
diversification benefits to the resultant portfolio. Additionally, crossing
trades between different alpha streams reduces transaction costs. As the number
of alpha streams increases, the relative turnover of the portfolio decreases as
more trades are crossed. However, we argue, under reasonable assumptions, that
as the number of alphas increases, the turnover does not decrease indefinitely;
instead, the turnover approaches a non-vanishing limit related to the
correlation structure of the portfolio's alphas. We also point out that, more
generally, computational simplifications can arise when the number of alphas is
large.
-
We develop models to price long term loans in the securities lending
business. These longer horizon deals can be viewed as contracts with
optionality embedded in them and can be priced using established methods from
derivatives theory, becoming to our limited knowledge, the first application
that can lead to greater synergies between the operations of derivative and
delta-one trading desks, perhaps even being able to combine certain aspects of
the day to day operations of these seemingly disparate entities. We run
numerical simulations to demonstrate the practical applicability of these
models. These models are part of one of the least explored yet profit laden
areas of modern investment management.
We develop a heuristic that can mitigate the loss of information that sets in
when parameters are estimated first and then the valuation is performed by
directly calculating the valuation using the historical time series. This can
lead to reduced models errors and greater financial stability. We illustrate
how the methodologies developed here could be useful for inventory management.
All these techniques could have applications for dealing with other financial
instruments, non-financial commodities and many forms of uncertainty. An
unintended consequence of our efforts, has become a review of the vast
literature on options pricing, which can be useful for anyone that attempts to
apply the corresponding techniques to the problems mentioned here.
Admittedly, our initial ambitions to produce a normative theory on long term
loan valuations are undone by the present state of affairs in social science
modeling. Though we consider many elements of a securities lending system at
face value, this cannot be termed a positive theory. For now, if it ends up
producing a useful theory, our work is done.
-
In this work, we study a dynamic portfolio optimization problem related to
pairs trading, which is an investment strategy that matches a long position in
one security with a short position in another security with similar
characteristics. The relationship between pairs, called a spread, is modeled by
a Gaussian mean-reverting process whose drift rate is modulated by an
unobservable continuous-time, finite-state Markov chain. Using the classical
stochastic filtering theory, we reduce this problem with partial information to
the one with full information and solve it for the logarithmic utility
function, where the terminal wealth is penalized by the riskiness of the
portfolio according to the realized volatility of the wealth process. We
characterize optimal dollar-neutral strategies as well as optimal value
functions under full and partial information and show that the certainty
equivalence principle holds for the optimal portfolio strategy. Finally, we
provide a numerical analysis for a toy example with a two-state Markov chain.
-
In this paper, we propose a novel investment strategy for portfolio
optimization problems. The proposed strategy maximizes the expected portfolio
value bounded within a targeted range, composed of a conservative lower target
representing a need for capital protection and a desired upper target
representing an investment goal. This strategy favorably shapes the entire
probability distribution of returns, as it simultaneously seeks a desired
expected return, cuts off downside risk and implicitly caps volatility and
higher moments. To illustrate the effectiveness of this investment strategy, we
study a multiperiod portfolio optimization problem with transaction costs and
develop a two-stage regression approach that improves the classical least
squares Monte Carlo (LSMC) algorithm when dealing with difficult payoffs, such
as highly concave, abruptly changing or discontinuous functions. Our numerical
results show substantial improvements over the classical LSMC algorithm for
both the constant relative risk-aversion (CRRA) utility approach and the
proposed skewed target range strategy (STRS). Our numerical results illustrate
the ability of the STRS to contain the portfolio value within the targeted
range. When compared with the CRRA utility approach, the STRS achieves a
similar mean-variance efficient frontier while delivering a better downside
risk-return trade-off.
-
By Markowitz geometry we mean the intersection theory of ellipsoids and
affine subspaces in a real finite-dimensional linear space. In the paper we
give a meticulous and self-contained treatment of this arch-classical subject,
which lays a solid mathematical groundwork of Markowitz mean-variance theory of
efficient portfolios in economics.
-
This paper aims at developing a new method by which to build a data-driven
portfolio featuring a target risk-return. We first present a comparative study
of recurrent neural network models (RNNs), including a simple RNN, long
short-term memory (LSTM), and gated recurrent unit (GRU) for selecting the best
predictor to use in portfolio construction. The models are applied to the
investment universe consisted of ten stocks in the S&P500. The experimental
results shows that LSTM outperforms the others in terms of hit ratio of
one-month-ahead forecasts. We then build predictive threshold-based portfolios
(TBPs) that are subsets of the universe satisfying given threshold criteria for
the predicted returns. The TBPs are rebalanced monthly to restore equal weights
to each security within the TBPs. We find that the risk and return profile of
the realized TBP represents a monotonically increasing frontier on the
risk-return plane, where the equally weighted portfolio (EWP) of all ten stocks
plays a role in their lower bound. This shows the availability of TBPs in
targeting specific risk-return levels, and an EWP based on all the assets plays
a role in the reference portfolio of TBPs. In the process, thresholds play
dominant roles in characterizing risk, return, and the prediction accuracy of
the subset. The TBP is more data-driven in designing portfolio target risk and
return than existing ones, in the sense that it requires no prior knowledge of
finance such as financial assumptions, financial mathematics, or expert
insights. In a practical application, we present the TBP management procedure
for a time horizon extending over multiple time periods; we also discuss their
application to mean-variance portfolios to reduce estimation risk.
-
We consider a stochastic control problem with the assumption that the system
is controlled until the state process breaks the fixed barrier. Assuming some
general conditions, it is proved that the resulting Hamilton Jacobi Bellman
equations has smooth solution. The aforementioned result is used to solve the
optimal dividend and consumption problem. In the proof we use a fixed point
type argument, with an operator which is based on the stochastic representation
for a linear equation.
-
In this paper we estimate the mean-variance (MV) portfolio in the
high-dimensional case using the recent results from the theory of random
matrices. We construct a linear shrinkage estimator which is distribution-free
and is optimal in the sense of maximizing with probability $1$ the asymptotic
out-of-sample expected utility, i.e., mean-variance objective function for
several values of risk aversion coefficient which in particular leads to the
maximization of the out-of sample expected utility, to the maximization of the
out-of-sample Sharpe ratio, and to the minimization of the out-of-sample
variance. Its asymptotic properties are investigated when the number of assets
$p$ together with the sample size $n$ tend to infinity such that $p/n
\rightarrow c\in (0,+\infty)$. The results are obtained under weak assumptions
imposed on the distribution of the asset returns, namely the existence of the
fourth moments is only required. Thereafter we perform numerical and empirical
studies where the small- and large-sample behavior of the derived estimator is
investigated. The suggested estimator shows significant improvements over the
naive diversification and it is robust to the deviations from normality.
-
The optimization of the variance supplemented by a budget constraint and an
asymmetric $\ell_1$ regularizer is carried out analytically by the replica
method borrowed from the theory of disordered systems. The asymmetric
regularizer allows us to penalize short and long positions differently, so the
present treatment includes the no-short-constrained portfolio optimization
problem as a special case. Results are presented for the out-of-sample and the
in-sample estimator of the regularized variance, the relative estimation error,
the density of the assets eliminated from the portfolio by the regularizer, and
the distribution of the optimal portfolio weights. We have studied the
dependence of these quantities on the ratio $r$ of the portfolio's dimension
$N$ to the sample size $T$, and on the strength of the regularizer. We have
checked the analytic results by numerical simulations, and found general
agreement. Regularization extends the interval where the optimization can be
carried out, and suppresses the large sample fluctuations, but the performance
of $\ell_1$ regularization is rather disappointing: if the sample size is large
relative to the dimension, i.e. $r$ is small, the regularizer does not play any
role, while for $r$'s where the regularizer starts to be felt the estimation
error is already so large as to make the whole optimization exercise pointless.
We find that the $\ell_1$ regularization can eliminate at most half the assets
from the portfolio, corresponding to this there is a critical ratio $r=2$
beyond which the $\ell_1$ regularized variance cannot be optimized: the
regularized variance becomes constant over the simplex. These facts do not seem
to have been noticed in the literature.
-
The optimization of a large random portfolio under the Expected Shortfall
risk measure with an $\ell_2$ regularizer is carried out by analytical
calculation. The regularizer reins in the large sample fluctuations and the
concomitant divergent estimation error, and eliminates the phase transition
where this error would otherwise blow up. In the data-dominated region, where
the number $N$ of different assets in the portfolio is much less than the
length $T$ of the available time series, the regularizer plays a negligible
role even if its strength $\eta$ is large, while in the opposite limit, where
the size of samples is comparable to, or even smaller than the number of
assets, the optimum is almost entirely determined by the regularizer. We
construct the contour map of estimation error on the $N/T$ vs. $\eta$ plane and
find that for a given value of the estimation error the gain in $N/T$ due to
the regularizer can reach a factor of about 4 for a sufficiently strong
regularizer.
-
Accounting for the non-normality of asset returns remains challenging in
robust portfolio optimization. In this article, we tackle this problem by
assessing the risk of the portfolio through the "amount of randomness" conveyed
by its returns. We achieve this by using an objective function that relies on
the exponential of R\'enyi entropy, an information-theoretic criterion that
precisely quantifies the uncertainty embedded in a distribution, accounting for
higher-order moments. Compared to Shannon entropy, R\'enyi entropy features a
parameter that can be tuned to play around the notion of uncertainty. A
Gram-Charlier expansion shows that it controls the relative contributions of
the central (variance) and tail (kurtosis) parts of the distribution in the
measure. We further rely on a non-parametric estimator of the exponential
R\'enyi entropy that extends a robust sample-spacings estimator initially
designed for Shannon entropy. A portfolio selection application illustrates
that minimizing R\'enyi entropy yields portfolios that outperform
state-of-the-art minimum variance portfolios in terms of risk-return-turnover
trade-off.
-
We theoretically and empirically study portfolio optimization under
transaction costs and establish a link between turnover penalization and
covariance shrinkage with the penalization governed by transaction costs. We
show how the ex ante incorporation of transaction costs shifts optimal
portfolios towards regularized versions of efficient allocations. The
regulatory effect of transaction costs is studied in an econometric setting
incorporating parameter uncertainty and optimally combining predictive
distributions resulting from high-frequency and low-frequency data. In an
extensive empirical study, we illustrate that turnover penalization is more
effective than commonly employed shrinkage methods and is crucial in order to
construct empirically well-performing portfolios.
-
We give an algebraic definition of a Markowitz market and classify markets up
to isomorphism. Given this classification, the theory of portfolio optimization
in Markowitz markets without short selling constraints becomes trivial.
Conversely, this classification shows that, up to isomorphism, there is little
that can be said about a Markowitz market that is not already detected by the
theory of portfolio optimization. In particular, if one seeks to develop a
simplified low-dimensional model of a large financial market using
mean--variance analysis alone, the resulting model can be at most
two-dimensional.
-
We use pathwise It\^o calculus to prove two strictly pathwise versions of the
master formula in Fernholz' stochastic portfolio theory. Our first version is
set within the framework of F\"ollmer's pathwise It\^o calculus and works for
portfolios generated from functions that may depend on the current states of
the market portfolio and an additional path of finite variation. The second
version is formulated within the functional pathwise It\^o calculus of Dupire
(2009) and Cont \& Fourni\'e (2010) and allows for portfolio-generating
functionals that may depend additionally on the entire path of the market
portfolio. Our results are illustrated by several examples and shown to work on
empirical market data.
-
We proposed a new Portfolio Management method termed as Robust Log-Optimal
Strategy (RLOS), which ameliorates the General Log-Optimal Strategy (GLOS) by
approximating the traditional objective function with quadratic Taylor
expansion. It avoids GLOS's complex CDF estimation process,hence resists the
"Butterfly Effect" caused by estimation error. Besides,RLOS retains GLOS's
profitability and the optimization problem involved in RLOS is computationally
far more practical compared to GLOS. Further, we combine RLOS with
Reinforcement Learning (RL) and propose the so-called Robust Log-Optimal
Strategy with Reinforcement Learning (RLOSRL), where the RL agent receives the
analyzed results from RLOS and observes the trading environment to make
comprehensive investment decisions. The RLOSRL's performance is compared to
some traditional strategies on several back tests, where we randomly choose a
selection of constituent stocks of the CSI300 index as assets under management
and the test results validate its profitability and stability.
-
This paper presents a simple method for a posteriori (historical)
multi-variate multi-stage optimal trading under transaction costs and a
diversification constraint. Starting from a given amount of money in some
currency, we analyze the stage-wise optimal allocation over a time horizon with
potential investments in multiple currencies and various assets. Three variants
are discussed, including unconstrained trading frequency, a fixed number of
total admissable trades, and the waiting of a specific time-period after every
executed trade until the next trade. The developed methods are based on
efficient graph generation and consequent graph search, and are evaluated
quantitatively on real-world data. The fundamental motivation of this work is
preparatory labeling of financial time-series data for supervised machine
learning.
-
We study the problem of utility maximization from terminal wealth in which an
agent optimally builds her portfolio by investing in a bond and a risky asset.
The asset price dynamics follow a diffusion process with regime-switching
coefficients modeled by a continuous-time finite-state Markov chain. We
consider an investor with a Constant Relative Risk Aversion (CRRA) utility
function. We deduce the associated Hamilton-Jacobi-Bellman equation to
construct the solution and the optimal trading strategy and verify optimality
by showing that the value function is the unique constrained viscosity solution
of the HJB equation. By means of a Laplace transform method, we show how to
explicitly compute the value function and illustrate the method with the two-
and three-states cases. This method is interesting in its own right and can be
adapted in other applications involving hybrid systems and using other types of
transforms with basic properties similar to the Laplace transform.





 In this article, inspired by Shi, et al. we investigate the optimal portfolio selection with one risk-free asset and one risky asset in a multiple period setting under cumulative prospect theory (CPT). Compared with their study, our novelty is that we consider a stochastic benchmark, and portfolio constraints. We test the sensitivity of the optimal CPT-investment strategies to different model parameters by performing a numerical analysis.
In this article, inspired by Shi, et al. we investigate the optimal portfolio selection with one risk-free asset and one risky asset in a multiple period setting under cumulative prospect theory (CPT). Compared with their study, our novelty is that we consider a stochastic benchmark, and portfolio constraints. We test the sensitivity of the optimal CPT-investment strategies to different model parameters by performing a numerical analysis.




 This paper presents several models addressing optimal portfolio choice, optimal portfolio liquidation, and optimal portfolio transition issues, in which the expected returns of risky assets are unknown. Our approach is based on a coupling between Bayesian learning and dynamic programming techniques that leads to partial differential equations. It enables to recover the well-known results of Karatzas and Zhao in a framework \`a la Merton, but also to deal with cases where martingale methods are no longer available. In particular, we address optimal portfolio choice, portfolio liquidation, and portfolio transition problems in a framework \`a la Almgren-Chriss, and we build therefore a model in which the agent takes into account in his decision process both the liquidity of assets and the uncertainty with respect to their expected return.
This paper presents several models addressing optimal portfolio choice, optimal portfolio liquidation, and optimal portfolio transition issues, in which the expected returns of risky assets are unknown. Our approach is based on a coupling between Bayesian learning and dynamic programming techniques that leads to partial differential equations. It enables to recover the well-known results of Karatzas and Zhao in a framework \`a la Merton, but also to deal with cases where martingale methods are no longer available. In particular, we address optimal portfolio choice, portfolio liquidation, and portfolio transition problems in a framework \`a la Almgren-Chriss, and we build therefore a model in which the agent takes into account in his decision process both the liquidity of assets and the uncertainty with respect to their expected return.




 We introduce a new class of forward performance processes that are endogenous and predictable with regards to an underlying market information set and, furthermore, are updated at discrete times. We analyze in detail a binomial model whose parameters are random and updated dynamically as the market evolves. We show that the key step in the construction of the associated predictable forward performance process is to solve a single-period inverse investment problem, namely, to determine, period-by-period and conditionally on the current market information, the end-time utility function from a given initial-time value function. We reduce this inverse problem to solving a functional equation and establish conditions for the existence and uniqueness of its solutions in the class of inverse marginal functions.
We introduce a new class of forward performance processes that are endogenous and predictable with regards to an underlying market information set and, furthermore, are updated at discrete times. We analyze in detail a binomial model whose parameters are random and updated dynamically as the market evolves. We show that the key step in the construction of the associated predictable forward performance process is to solve a single-period inverse investment problem, namely, to determine, period-by-period and conditionally on the current market information, the end-time utility function from a given initial-time value function. We reduce this inverse problem to solving a functional equation and establish conditions for the existence and uniqueness of its solutions in the class of inverse marginal functions.




 How do macro-financial shocks affect investor behavior and market dynamics? Recent evidence on experience effects suggests a long-lasting influence of personally experienced outcomes on investor beliefs and investment, but also significant differences across older and younger generations. We formalize experience-based learning in an OLG model, where different cross-cohort experiences generate persistent heterogeneity in beliefs, portfolio choices, and trade. The model allows us to characterize a novel link between investor demographics and the dependence of prices on past dividends, while also generating known features of asset prices, such as excess volatility and return predictability. The model produces new implications for the cross-section of asset holdings, trade volume, and investors' heterogenous responses to recent financial crises, which we show to be in line with the data.
How do macro-financial shocks affect investor behavior and market dynamics? Recent evidence on experience effects suggests a long-lasting influence of personally experienced outcomes on investor beliefs and investment, but also significant differences across older and younger generations. We formalize experience-based learning in an OLG model, where different cross-cohort experiences generate persistent heterogeneity in beliefs, portfolio choices, and trade. The model allows us to characterize a novel link between investor demographics and the dependence of prices on past dividends, while also generating known features of asset prices, such as excess volatility and return predictability. The model produces new implications for the cross-section of asset holdings, trade volume, and investors' heterogenous responses to recent financial crises, which we show to be in line with the data.




 We consider the robust exponential utility maximization problem in discrete time: An investor maximizes the worst case expected exponential utility with respect to a family of nondominated probabilistic models of her endowment by dynamically investing in a financial market, and statically in available options. We show that, for any measurable random endowment (regardless of whether the problem is finite or not) an optimal strategy exists, a dual representation in terms of (calibrated) martingale measures holds true, and that the problem satisfies the dynamic programming principle (in case of no options). Further it is shown that the value of the utility maximization problem converges to the robust superhedging price as the risk aversion parameter gets large, and examples of nondominated probabilistic models are discussed.
We consider the robust exponential utility maximization problem in discrete time: An investor maximizes the worst case expected exponential utility with respect to a family of nondominated probabilistic models of her endowment by dynamically investing in a financial market, and statically in available options. We show that, for any measurable random endowment (regardless of whether the problem is finite or not) an optimal strategy exists, a dual representation in terms of (calibrated) martingale measures holds true, and that the problem satisfies the dynamic programming principle (in case of no options). Further it is shown that the value of the utility maximization problem converges to the robust superhedging price as the risk aversion parameter gets large, and examples of nondominated probabilistic models are discussed.




 We study portfolio selection in a model with both temporary and transient price impact introduced by Garleanu and Pedersen (2016). In the large-liquidity limit where both frictions are small, we derive explicit formulas for the asymptotically optimal trading rate and the corresponding minimal leading-order performance loss. We find that the losses are governed by the volatility of the frictionless target strategy, like in models with only temporary price impact. In contrast, the corresponding optimal portfolio not only tracks the frictionless optimizer, but also exploits the displacement of the market price from its unaffected level.
We study portfolio selection in a model with both temporary and transient price impact introduced by Garleanu and Pedersen (2016). In the large-liquidity limit where both frictions are small, we derive explicit formulas for the asymptotically optimal trading rate and the corresponding minimal leading-order performance loss. We find that the losses are governed by the volatility of the frictionless target strategy, like in models with only temporary price impact. In contrast, the corresponding optimal portfolio not only tracks the frictionless optimizer, but also exploits the displacement of the market price from its unaffected level.




 We study the Merton problem of optimal consumption-investment for the case of two investors sharing a final wealth. The typical example would be a husband and wife sharing a portfolio looking to optimize the expected utility of consumption and final wealth. Each agent has different utility function and discount factor. An explicit formulation for the optimal consumptions and portfolio can be obtained in the case of a complete market. The problem is shown to be equivalent to maximizing three different utilities separately with separate initial wealths. We study a numerical example where the market price of risk is assumed to be mean reverting, and provide insights on the influence of risk aversion or discount rates on the initial optimal allocation.
We study the Merton problem of optimal consumption-investment for the case of two investors sharing a final wealth. The typical example would be a husband and wife sharing a portfolio looking to optimize the expected utility of consumption and final wealth. Each agent has different utility function and discount factor. An explicit formulation for the optimal consumptions and portfolio can be obtained in the case of a complete market. The problem is shown to be equivalent to maximizing three different utilities separately with separate initial wealths. We study a numerical example where the market price of risk is assumed to be mean reverting, and provide insights on the influence of risk aversion or discount rates on the initial optimal allocation.




 We give complete algorithms and source code for constructing (multilevel) statistical industry classifications, including methods for fixing the number of clusters at each level (and the number of levels). Under the hood there are clustering algorithms (e.g., k-means). However, what should we cluster? Correlations? Returns? The answer turns out to be neither and our backtests suggest that these details make a sizable difference. We also give an algorithm and source code for building "hybrid" industry classifications by improving off-the-shelf "fundamental" industry classifications by applying our statistical industry classification methods to them. The presentation is intended to be pedagogical and geared toward practical applications in quantitative trading.
We give complete algorithms and source code for constructing (multilevel) statistical industry classifications, including methods for fixing the number of clusters at each level (and the number of levels). Under the hood there are clustering algorithms (e.g., k-means). However, what should we cluster? Correlations? Returns? The answer turns out to be neither and our backtests suggest that these details make a sizable difference. We also give an algorithm and source code for building "hybrid" industry classifications by improving off-the-shelf "fundamental" industry classifications by applying our statistical industry classification methods to them. The presentation is intended to be pedagogical and geared toward practical applications in quantitative trading.




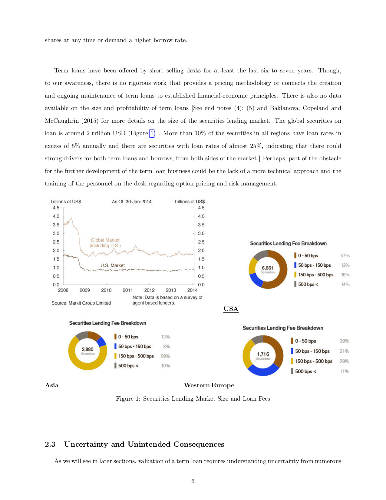 We develop models to price long term loans in the securities lending business. These longer horizon deals can be viewed as contracts with optionality embedded in them and can be priced using established methods from derivatives theory, becoming to our limited knowledge, the first application that can lead to greater synergies between the operations of derivative and delta-one trading desks, perhaps even being able to combine certain aspects of the day to day operations of these seemingly disparate entities. We run numerical simulations to demonstrate the practical applicability of these models. These models are part of one of the least explored yet profit laden areas of modern investment management. We develop a heuristic that can mitigate the loss of information that sets in when parameters are estimated first and then the valuation is performed by directly calculating the valuation using the historical time series. This can lead to reduced models errors and greater financial stability. We illustrate how the methodologies developed here could be useful for inventory management. All these techniques could have applications for dealing with other financial instruments, non-financial commodities and many forms of uncertainty. An unintended consequence of our efforts, has become a review of the vast literature on options pricing, which can be useful for anyone that attempts to apply the corresponding techniques to the problems mentioned here. Admittedly, our initial ambitions to produce a normative theory on long term loan valuations are undone by the present state of affairs in social science modeling. Though we consider many elements of a securities lending system at face value, this cannot be termed a positive theory. For now, if it ends up producing a useful theory, our work is done.
We develop models to price long term loans in the securities lending business. These longer horizon deals can be viewed as contracts with optionality embedded in them and can be priced using established methods from derivatives theory, becoming to our limited knowledge, the first application that can lead to greater synergies between the operations of derivative and delta-one trading desks, perhaps even being able to combine certain aspects of the day to day operations of these seemingly disparate entities. We run numerical simulations to demonstrate the practical applicability of these models. These models are part of one of the least explored yet profit laden areas of modern investment management. We develop a heuristic that can mitigate the loss of information that sets in when parameters are estimated first and then the valuation is performed by directly calculating the valuation using the historical time series. This can lead to reduced models errors and greater financial stability. We illustrate how the methodologies developed here could be useful for inventory management. All these techniques could have applications for dealing with other financial instruments, non-financial commodities and many forms of uncertainty. An unintended consequence of our efforts, has become a review of the vast literature on options pricing, which can be useful for anyone that attempts to apply the corresponding techniques to the problems mentioned here. Admittedly, our initial ambitions to produce a normative theory on long term loan valuations are undone by the present state of affairs in social science modeling. Though we consider many elements of a securities lending system at face value, this cannot be termed a positive theory. For now, if it ends up producing a useful theory, our work is done.




 In this work, we study a dynamic portfolio optimization problem related to pairs trading, which is an investment strategy that matches a long position in one security with a short position in another security with similar characteristics. The relationship between pairs, called a spread, is modeled by a Gaussian mean-reverting process whose drift rate is modulated by an unobservable continuous-time, finite-state Markov chain. Using the classical stochastic filtering theory, we reduce this problem with partial information to the one with full information and solve it for the logarithmic utility function, where the terminal wealth is penalized by the riskiness of the portfolio according to the realized volatility of the wealth process. We characterize optimal dollar-neutral strategies as well as optimal value functions under full and partial information and show that the certainty equivalence principle holds for the optimal portfolio strategy. Finally, we provide a numerical analysis for a toy example with a two-state Markov chain.
In this work, we study a dynamic portfolio optimization problem related to pairs trading, which is an investment strategy that matches a long position in one security with a short position in another security with similar characteristics. The relationship between pairs, called a spread, is modeled by a Gaussian mean-reverting process whose drift rate is modulated by an unobservable continuous-time, finite-state Markov chain. Using the classical stochastic filtering theory, we reduce this problem with partial information to the one with full information and solve it for the logarithmic utility function, where the terminal wealth is penalized by the riskiness of the portfolio according to the realized volatility of the wealth process. We characterize optimal dollar-neutral strategies as well as optimal value functions under full and partial information and show that the certainty equivalence principle holds for the optimal portfolio strategy. Finally, we provide a numerical analysis for a toy example with a two-state Markov chain.




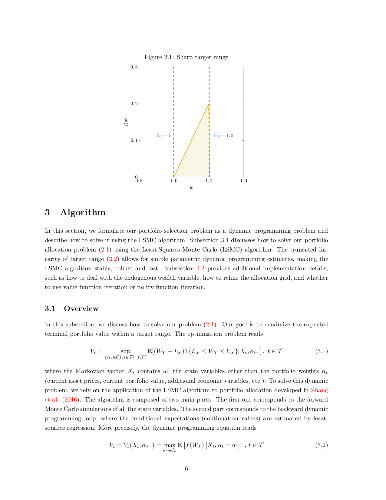 In this paper, we propose a novel investment strategy for portfolio optimization problems. The proposed strategy maximizes the expected portfolio value bounded within a targeted range, composed of a conservative lower target representing a need for capital protection and a desired upper target representing an investment goal. This strategy favorably shapes the entire probability distribution of returns, as it simultaneously seeks a desired expected return, cuts off downside risk and implicitly caps volatility and higher moments. To illustrate the effectiveness of this investment strategy, we study a multiperiod portfolio optimization problem with transaction costs and develop a two-stage regression approach that improves the classical least squares Monte Carlo (LSMC) algorithm when dealing with difficult payoffs, such as highly concave, abruptly changing or discontinuous functions. Our numerical results show substantial improvements over the classical LSMC algorithm for both the constant relative risk-aversion (CRRA) utility approach and the proposed skewed target range strategy (STRS). Our numerical results illustrate the ability of the STRS to contain the portfolio value within the targeted range. When compared with the CRRA utility approach, the STRS achieves a similar mean-variance efficient frontier while delivering a better downside risk-return trade-off.
In this paper, we propose a novel investment strategy for portfolio optimization problems. The proposed strategy maximizes the expected portfolio value bounded within a targeted range, composed of a conservative lower target representing a need for capital protection and a desired upper target representing an investment goal. This strategy favorably shapes the entire probability distribution of returns, as it simultaneously seeks a desired expected return, cuts off downside risk and implicitly caps volatility and higher moments. To illustrate the effectiveness of this investment strategy, we study a multiperiod portfolio optimization problem with transaction costs and develop a two-stage regression approach that improves the classical least squares Monte Carlo (LSMC) algorithm when dealing with difficult payoffs, such as highly concave, abruptly changing or discontinuous functions. Our numerical results show substantial improvements over the classical LSMC algorithm for both the constant relative risk-aversion (CRRA) utility approach and the proposed skewed target range strategy (STRS). Our numerical results illustrate the ability of the STRS to contain the portfolio value within the targeted range. When compared with the CRRA utility approach, the STRS achieves a similar mean-variance efficient frontier while delivering a better downside risk-return trade-off.




 By Markowitz geometry we mean the intersection theory of ellipsoids and affine subspaces in a real finite-dimensional linear space. In the paper we give a meticulous and self-contained treatment of this arch-classical subject, which lays a solid mathematical groundwork of Markowitz mean-variance theory of efficient portfolios in economics.
By Markowitz geometry we mean the intersection theory of ellipsoids and affine subspaces in a real finite-dimensional linear space. In the paper we give a meticulous and self-contained treatment of this arch-classical subject, which lays a solid mathematical groundwork of Markowitz mean-variance theory of efficient portfolios in economics.




 In this paper we estimate the mean-variance (MV) portfolio in the high-dimensional case using the recent results from the theory of random matrices. We construct a linear shrinkage estimator which is distribution-free and is optimal in the sense of maximizing with probability $1$ the asymptotic out-of-sample expected utility, i.e., mean-variance objective function for several values of risk aversion coefficient which in particular leads to the maximization of the out-of sample expected utility, to the maximization of the out-of-sample Sharpe ratio, and to the minimization of the out-of-sample variance. Its asymptotic properties are investigated when the number of assets $p$ together with the sample size $n$ tend to infinity such that $p/n \rightarrow c\in (0,+\infty)$. The results are obtained under weak assumptions imposed on the distribution of the asset returns, namely the existence of the fourth moments is only required. Thereafter we perform numerical and empirical studies where the small- and large-sample behavior of the derived estimator is investigated. The suggested estimator shows significant improvements over the naive diversification and it is robust to the deviations from normality.
In this paper we estimate the mean-variance (MV) portfolio in the high-dimensional case using the recent results from the theory of random matrices. We construct a linear shrinkage estimator which is distribution-free and is optimal in the sense of maximizing with probability $1$ the asymptotic out-of-sample expected utility, i.e., mean-variance objective function for several values of risk aversion coefficient which in particular leads to the maximization of the out-of sample expected utility, to the maximization of the out-of-sample Sharpe ratio, and to the minimization of the out-of-sample variance. Its asymptotic properties are investigated when the number of assets $p$ together with the sample size $n$ tend to infinity such that $p/n \rightarrow c\in (0,+\infty)$. The results are obtained under weak assumptions imposed on the distribution of the asset returns, namely the existence of the fourth moments is only required. Thereafter we perform numerical and empirical studies where the small- and large-sample behavior of the derived estimator is investigated. The suggested estimator shows significant improvements over the naive diversification and it is robust to the deviations from normality.




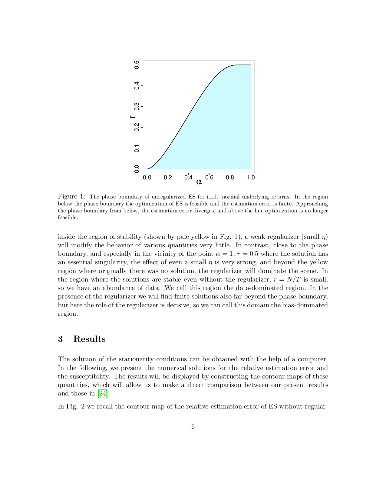 The optimization of a large random portfolio under the Expected Shortfall risk measure with an $\ell_2$ regularizer is carried out by analytical calculation. The regularizer reins in the large sample fluctuations and the concomitant divergent estimation error, and eliminates the phase transition where this error would otherwise blow up. In the data-dominated region, where the number $N$ of different assets in the portfolio is much less than the length $T$ of the available time series, the regularizer plays a negligible role even if its strength $\eta$ is large, while in the opposite limit, where the size of samples is comparable to, or even smaller than the number of assets, the optimum is almost entirely determined by the regularizer. We construct the contour map of estimation error on the $N/T$ vs. $\eta$ plane and find that for a given value of the estimation error the gain in $N/T$ due to the regularizer can reach a factor of about 4 for a sufficiently strong regularizer.
The optimization of a large random portfolio under the Expected Shortfall risk measure with an $\ell_2$ regularizer is carried out by analytical calculation. The regularizer reins in the large sample fluctuations and the concomitant divergent estimation error, and eliminates the phase transition where this error would otherwise blow up. In the data-dominated region, where the number $N$ of different assets in the portfolio is much less than the length $T$ of the available time series, the regularizer plays a negligible role even if its strength $\eta$ is large, while in the opposite limit, where the size of samples is comparable to, or even smaller than the number of assets, the optimum is almost entirely determined by the regularizer. We construct the contour map of estimation error on the $N/T$ vs. $\eta$ plane and find that for a given value of the estimation error the gain in $N/T$ due to the regularizer can reach a factor of about 4 for a sufficiently strong regularizer.


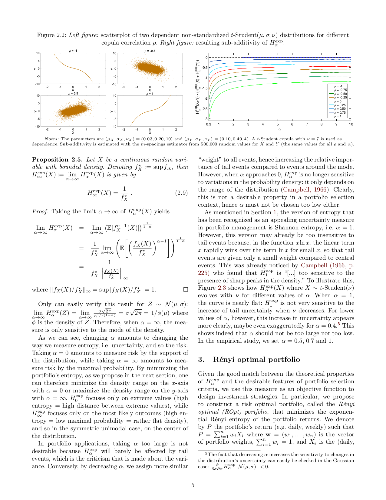
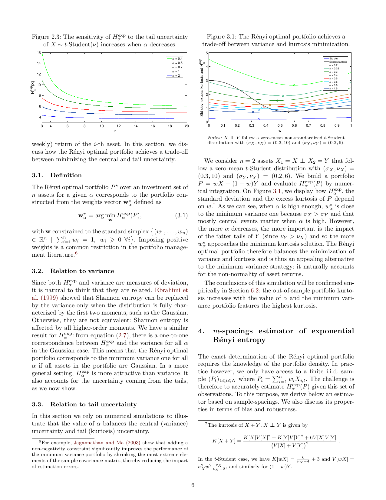 Accounting for the non-normality of asset returns remains challenging in robust portfolio optimization. In this article, we tackle this problem by assessing the risk of the portfolio through the "amount of randomness" conveyed by its returns. We achieve this by using an objective function that relies on the exponential of R\'enyi entropy, an information-theoretic criterion that precisely quantifies the uncertainty embedded in a distribution, accounting for higher-order moments. Compared to Shannon entropy, R\'enyi entropy features a parameter that can be tuned to play around the notion of uncertainty. A Gram-Charlier expansion shows that it controls the relative contributions of the central (variance) and tail (kurtosis) parts of the distribution in the measure. We further rely on a non-parametric estimator of the exponential R\'enyi entropy that extends a robust sample-spacings estimator initially designed for Shannon entropy. A portfolio selection application illustrates that minimizing R\'enyi entropy yields portfolios that outperform state-of-the-art minimum variance portfolios in terms of risk-return-turnover trade-off.
Accounting for the non-normality of asset returns remains challenging in robust portfolio optimization. In this article, we tackle this problem by assessing the risk of the portfolio through the "amount of randomness" conveyed by its returns. We achieve this by using an objective function that relies on the exponential of R\'enyi entropy, an information-theoretic criterion that precisely quantifies the uncertainty embedded in a distribution, accounting for higher-order moments. Compared to Shannon entropy, R\'enyi entropy features a parameter that can be tuned to play around the notion of uncertainty. A Gram-Charlier expansion shows that it controls the relative contributions of the central (variance) and tail (kurtosis) parts of the distribution in the measure. We further rely on a non-parametric estimator of the exponential R\'enyi entropy that extends a robust sample-spacings estimator initially designed for Shannon entropy. A portfolio selection application illustrates that minimizing R\'enyi entropy yields portfolios that outperform state-of-the-art minimum variance portfolios in terms of risk-return-turnover trade-off.




 We give an algebraic definition of a Markowitz market and classify markets up to isomorphism. Given this classification, the theory of portfolio optimization in Markowitz markets without short selling constraints becomes trivial. Conversely, this classification shows that, up to isomorphism, there is little that can be said about a Markowitz market that is not already detected by the theory of portfolio optimization. In particular, if one seeks to develop a simplified low-dimensional model of a large financial market using mean--variance analysis alone, the resulting model can be at most two-dimensional.
We give an algebraic definition of a Markowitz market and classify markets up to isomorphism. Given this classification, the theory of portfolio optimization in Markowitz markets without short selling constraints becomes trivial. Conversely, this classification shows that, up to isomorphism, there is little that can be said about a Markowitz market that is not already detected by the theory of portfolio optimization. In particular, if one seeks to develop a simplified low-dimensional model of a large financial market using mean--variance analysis alone, the resulting model can be at most two-dimensional.




 We use pathwise It\^o calculus to prove two strictly pathwise versions of the master formula in Fernholz' stochastic portfolio theory. Our first version is set within the framework of F\"ollmer's pathwise It\^o calculus and works for portfolios generated from functions that may depend on the current states of the market portfolio and an additional path of finite variation. The second version is formulated within the functional pathwise It\^o calculus of Dupire (2009) and Cont \& Fourni\'e (2010) and allows for portfolio-generating functionals that may depend additionally on the entire path of the market portfolio. Our results are illustrated by several examples and shown to work on empirical market data.
We use pathwise It\^o calculus to prove two strictly pathwise versions of the master formula in Fernholz' stochastic portfolio theory. Our first version is set within the framework of F\"ollmer's pathwise It\^o calculus and works for portfolios generated from functions that may depend on the current states of the market portfolio and an additional path of finite variation. The second version is formulated within the functional pathwise It\^o calculus of Dupire (2009) and Cont \& Fourni\'e (2010) and allows for portfolio-generating functionals that may depend additionally on the entire path of the market portfolio. Our results are illustrated by several examples and shown to work on empirical market data.