-
The key challenge in multiagent learning is learning a best response to the
behaviour of other agents, which may be non-stationary: if the other agents
adapt their strategy as well, the learning target moves. Disparate streams of
research have approached non-stationarity from several angles, which make a
variety of implicit assumptions that make it hard to keep an overview of the
state of the art and to validate the innovation and significance of new works.
This survey presents a coherent overview of work that addresses
opponent-induced non-stationarity with tools from game theory, reinforcement
learning and multi-armed bandits. Further, we reflect on the principle
approaches how algorithms model and cope with this non-stationarity, arriving
at a new framework and five categories (in increasing order of sophistication):
ignore, forget, respond to target models, learn models, and theory of mind. A
wide range of state-of-the-art algorithms is classified into a taxonomy, using
these categories and key characteristics of the environment (e.g.,
observability) and adaptation behaviour of the opponents (e.g., smooth,
abrupt). To clarify even further we present illustrative variations of one
domain, contrasting the strengths and limitations of each category. Finally, we
discuss in which environments the different approaches yield most merit, and
point to promising avenues of future research.
-
Collective, especially group-based, managerial decision making is crucial in
organizations. Using an evolutionary theoretic approach to collective decision
making, agent-based simulations were conducted to investigate how human
collective decision making would be affected by the agents' diversity in
problem understanding and/or behavior in discussion, as well as by their social
network structure. Simulation results indicated that groups with consistent
problem understanding tended to produce higher utility values of ideas and
displayed better decision convergence, but only if there was no group-level
bias in collective problem understanding. Simulation results also indicated the
importance of balance between selection-oriented (i.e., exploitative) and
variation-oriented (i.e., explorative) behaviors in discussion to achieve
quality final decisions. Expanding the group size and introducing non-trivial
social network structure generally improved the quality of ideas at the cost of
decision convergence. Simulations with different social network topologies
revealed collective decision making on small-world networks with high local
clustering tended to achieve highest decision quality more often than on random
or scale-free networks. Implications of this evolutionary theory and simulation
approach for future managerial research on collective, group, and multi-level
decision making are discussed.
-
The beer game is a widely used in-class game that is played in supply chain
management classes to demonstrate the bullwhip effect. The game is a
decentralized, multi-agent, cooperative problem that can be modeled as a serial
supply chain network in which agents cooperatively attempt to minimize the
total cost of the network even though each agent can only observe its own local
information. Each agent chooses order quantities to replenish its stock. Under
some conditions, a base-stock replenishment policy is known to be optimal.
However, in a decentralized supply chain in which some agents (stages) may act
irrationally (as they do in the beer game), there is no known optimal policy
for an agent wishing to act optimally.
We propose a machine learning algorithm, based on deep Q-networks, to
optimize the replenishment decisions at a given stage. When playing alongside
agents who follow a base-stock policy, our algorithm obtains near-optimal order
quantities. It performs much better than a base-stock policy when the other
agents use a more realistic model of human ordering behavior. Unlike most other
algorithms in the literature, our algorithm does not have any limits on the
beer game parameter values. Like any deep learning algorithm, training the
algorithm can be computationally intensive, but this can be performed ahead of
time; the algorithm executes in real time when the game is played. Moreover, we
propose a transfer learning approach so that the training performed for one
agent and one set of cost coefficients can be adapted quickly for other agents
and costs. Our algorithm can be extended to other decentralized multi-agent
cooperative games with partially observed information, which is a common type
of situation in real-world supply chain problems.
-
Electric vehicles (EVs) are expected to be a major component of the smart
grid. The rapid proliferation of EVs will introduce an unprecedented load on
the existing electric grid due to the charging/discharging behavior of the EVs,
thus motivating the need for novel approaches for routing EVs across the grid.
In this paper, a novel gametheoretic framework for smart routing of EVs within
the smart grid is proposed. The goal of this framework is to balance the
electricity load across the grid while taking into account the traffic
congestion and the waiting time at charging stations. The EV routing problem is
formulated as a noncooperative game. For this game, it is shown that selfish
behavior of EVs will result in a pure-strategy Nash equilibrium with the price
of anarchy upper bounded by the variance of the ground load induced by the
residential, industrial, or commercial users. Moreover, the results are
extended to capture the stochastic nature of induced ground load as well as the
subjective behavior of the owners of EVs as captured by using notions from the
behavioral framework of prospect theory. Simulation results provide new
insights on more efficient energy pricing at charging stations and under more
realistic grid conditions.
-
In this paper, we develop a class of decentralized algorithms for solving a
convex resource allocation problem in a network of $n$ agents, where the agent
objectives are decoupled while the resource constraints are coupled. The agents
communicate over a connected undirected graph, and they want to collaboratively
determine a solution to the overall network problem, while each agent only
communicates with its neighbors. We first study the connection between the
decentralized resource allocation problem and the decentralized consensus
optimization problem. Then, using a class of algorithms for solving consensus
optimization problems, we propose a novel class of decentralized schemes for
solving resource allocation problems in a distributed manner. Specifically, we
first propose an algorithm for solving the resource allocation problem with an
$o(1/k)$ convergence rate guarantee when the agents' objective functions are
generally convex (could be nondifferentiable) and per agent local convex
constraints are allowed; We then propose a gradient-based algorithm for solving
the resource allocation problem when per agent local constraints are absent and
show that such scheme can achieve geometric rate when the objective functions
are strongly convex and have Lipschitz continuous gradients. We have also
provided scalability/network dependency analysis. Based on these two
algorithms, we have further proposed a gradient projection-based algorithm
which can handle smooth objective and simple constraints more efficiently.
Numerical experiments demonstrates the viability and performance of all the
proposed algorithms.
-
Many important stable matching problems are known to be NP-hard, even when
strong restrictions are placed on the input. In this paper we seek to identify
structural properties of instances of stable matching problems which will allow
us to design efficient algorithms using elementary techniques. We focus on the
setting in which all agents involved in some matching problem can be
partitioned into k different types, where the type of an agent determines his
or her preferences, and agents have preferences over types (which may be
refined by more detailed preferences within a single type). This situation
would arise in practice if agents form preferences solely based on some small
collection of agents' attributes. We also consider a generalisation in which
each agent may consider some small collection of other agents to be
exceptional, and rank these in a way that is not consistent with their types;
this could happen in practice if agents have prior contact with a small number
of candidates. We show that (for the case without exceptions), several
well-studied NP-hard stable matching problems including Max SMTI (that of
finding the maximum cardinality stable matching in an instance of stable
marriage with ties and incomplete lists) belong to the parameterised complexity
class FPT when parameterised by the number of different types of agents needed
to describe the instance. For Max SMTI this tractability result can be extended
to the setting in which each agent promotes at most one `exceptional' candidate
to the top of his/her list (when preferences within types are not refined), but
the problem remains NP-hard if preference lists can contain two or more
exceptions and the exceptional candidates can be placed anywhere in the
preference lists, even if the number of types is bounded by a constant.
-
To well understand crowd behavior, microscopic models have been developed in
recent decades, in which an individual's behavioral/psychological status can be
modeled and simulated. A well-known model is the social-force model innovated
by physical scientists (Helbing and Molnar, 1995; Helbing, Farkas and Vicsek,
2000; Helbing et al., 2002). This model has been widely accepted and mainly
used in simulation of crowd evacuation in the past decade. A problem, however,
is that the testing results of the model were not explained in consistency with
the psychological findings, resulting in misunderstanding of the model by
psychologists. This paper will bridge the gap between psychological studies and
physical explanation about this model. We reinterpret this physics-based model
from a psychological perspective, clarifying that the model is consistent with
psychological theories on stress, including time-related stress and
interpersonal stress. Based on the conception of stress, we renew the model at
both micro-and-macro level, referring to multi-agent simulation in a
microscopic sense and fluid-based analysis in a macroscopic sense. The
cognition and behavior of individual agents are critically modeled as response
to environmental stimuli. Existing simulation results such as faster-is-slower
effect will be reinterpreted by Yerkes-Dodson law, and herding and grouping
effect are further discussed by integrating attraction into the social force.
In brief the social-force model exhibits a bridge between the physics laws and
psychological principles regarding crowd motion, and this paper will renew and
reinterpret the model on the foundation of psychological studies.
-
Multi-target tracking is an important problem in civilian and military
applications. This paper investigates multi-target tracking in distributed
sensor networks. Data association, which arises particularly in multi-object
scenarios, can be tackled by various solutions. We consider sequential Monte
Carlo implementations of the Probability Hypothesis Density (PHD) filter based
on random finite sets. This approach circumvents the data association issue by
jointly estimating all targets in the region of interest. To this end, we
develop the Diffusion Particle PHD Filter (D-PPHDF) as well as a centralized
version, called the Multi-Sensor Particle PHD Filter (MS-PPHDF). Their
performance is evaluated in terms of the Optimal Subpattern Assignment (OSPA)
metric, benchmarked against a distributed extension of the Posterior
Cram\'er-Rao Lower Bound (PCRLB), and compared to the performance of an
existing distributed PHD Particle Filter. Furthermore, the robustness of the
proposed tracking algorithms against outliers and their performance with
respect to different amounts of clutter is investigated.
-
We introduce the problem of assigning resources to improve their utilization.
The motivation comes from settings where agents have uncertainty about their
own values for using a resource, and where it is in the interest of a group
that resources be used and not wasted. Done in the right way, improved
utilization maximizes social welfare--- balancing the utility of a high value
but unreliable agent with the group's preference that resources be used. We
introduce the family of contingent payment mechanisms (CP), which may charge an
agent contingent on use (a penalty). A CP mechanism is parameterized by a
maximum penalty, and has a dominant-strategy equilibrium. Under a set of
axiomatic properties, we establish welfare-optimality for the special case
CP(W), with CP instantiated for a maximum penalty equal to societal value W for
utilization. CP(W) is not dominated for expected welfare by any other
mechanism, and second, amongst mechanisms that always allocate the resource and
have a simple indirect structure, CP(W) strictly dominates every other
mechanism. The special case with no upper bound on penalty, the contingent
second-price mechanism, maximizes utilization. We extend the mechanisms to
assign multiple, heterogeneous resources, and present a simulation study of the
welfare properties of these mechanisms.
-
A fundamental challenge in multiagent systems is to design local control
algorithms to ensure a desirable collective behaviour. The information
available to the agents, gathered either through communication or sensing,
naturally restricts the achievable performance. Hence, it is fundamental to
identify what piece of information is valuable and can be exploited to design
control laws with enhanced performance guarantees. This paper studies the case
when such information is uncertain or inaccessible for a class of submodular
resource allocation problems termed covering problems. In the first part of
this work we pinpoint a fundamental risk-reward tradeoff faced by the system
operator when conditioning the control design on a valuable but uncertain piece
of information, which we refer to as the cardinality, that represents the
maximum number of agents that can simultaneously select any given resource.
Building on this analysis, we propose a distributed algorithm that allows
agents to learn the cardinality while adjusting their behaviour over time. This
algorithm is proved to perform on par or better to the optimal design obtained
when the exact cardinality is known a priori.
-
Many societal decision problems lie in high-dimensional continuous spaces not
amenable to the voting techniques common for their discrete or
single-dimensional counterparts. These problems are typically discretized
before running an election or decided upon through negotiation by
representatives. We propose a algorithm called {\sc Iterative Local Voting} for
collective decision-making in this setting. In this algorithm, voters are
sequentially sampled and asked to modify a candidate solution within some local
neighborhood of its current value, as defined by a ball in some chosen norm,
with the size of the ball shrinking at a specified rate.
We first prove the convergence of this algorithm under appropriate choices of
neighborhoods to Pareto optimal solutions with desirable fairness properties in
certain natural settings: when the voters' utilities can be expressed in terms
of some form of distance from their ideal solution, and when these utilities
are additively decomposable across dimensions. In many of these cases, we
obtain convergence to the societal welfare maximizing solution.
We then describe an experiment in which we test our algorithm for the
decision of the U.S. Federal Budget on Mechanical Turk with over 2,000 workers,
employing neighborhoods defined by $\mathcal{L}^1, \mathcal{L}^2$ and
$\mathcal{L}^\infty$ balls. We make several observations that inform future
implementations of such a procedure.
-
We consider social welfare functions that satisfy Arrow's classic axioms of
independence of irrelevant alternatives and Pareto optimality when the outcome
space is the convex hull of some finite set of alternatives. Individual and
collective preferences are assumed to be continuous and convex, which
guarantees the existence of maximal elements and the consistency of choice
functions that return these elements, even without insisting on transitivity.
We provide characterizations of both the domains of preferences and the social
welfare functions that allow for anonymous Arrovian aggregation. The domains
admit arbitrary preferences over alternatives, which completely determine an
agent's preferences over all mixed outcomes. On these domains, Arrow's
impossibility turns into a complete characterization of a unique social welfare
function, which can be readily applied in settings involving divisible
resources such as probability, time, or money.
-
We present two distributed methods for the estimation of the kinematic
parameters, the dynamic parameters, and the kinematic state of an unknown
planar body manipulated by a decentralized multi-agent system. The proposed
approaches rely on the rigid body kinematics and dynamics, on nonlinear
observation theory, and on consensus algorithms. The only three requirements
are that each agent can exert a 2D wrench on the load, it can measure the
velocity of its contact point, and that the communication graph is connected.
Both theoretical nonlinear observability analysis and convergence proofs are
provided. The first method assumes constant parameters while the second one can
deal with time-varying parameters and can be applied in parallel to any
task-oriented control law. For the cases in which a control law is not
provided, we propose a distributed and safe control strategy satisfying the
observability condition. The effectiveness and robustness of the estimation
strategy is showcased by means of realistic MonteCarlo simulations.
-
Due to the complexity of the natural world, a programmer cannot foresee all
possible situations, a connected and autonomous vehicle (CAV) will face during
its operation, and hence, CAVs will need to learn to make decisions
autonomously. Due to the sensing of its surroundings and information exchanged
with other vehicles and road infrastructure, a CAV will have access to large
amounts of useful data. While different control algorithms have been proposed
for CAVs, the benefits brought about by connectedness of autonomous vehicles to
other vehicles and to the infrastructure, and its implications on policy
learning has not been investigated in literature. This paper investigates a
data driven driving policy learning framework through an agent-based modelling
approaches. The contributions of the paper are two-fold. A dynamic programming
framework is proposed for in-vehicle policy learning with and without
connectivity to neighboring vehicles. The simulation results indicate that
while a CAV can learn to make autonomous decisions, vehicle-to-vehicle (V2V)
communication of information improves this capability. Furthermore, to overcome
the limitations of sensing in a CAV, the paper proposes a novel concept for
infrastructure-led policy learning and communication with autonomous vehicles.
In infrastructure-led policy learning, road-side infrastructure senses and
captures successful vehicle maneuvers and learns an optimal policy from those
temporal sequences, and when a vehicle approaches the road-side unit, the
policy is communicated to the CAV. Deep-imitation learning methodology is
proposed to develop such an infrastructure-led policy learning framework.
-
Two fundamental algorithm-design paradigms are Tree Search and Dynamic
Programming. The techniques used therein have been shown to complement one
another when solving the complete set partitioning problem, also known as the
coalition structure generation problem [5]. Inspired by this observation, we
develop in this paper an algorithm to solve the coalition structure generation
problem on graphs, where the goal is to identifying an optimal partition of a
graph into connected subgraphs. More specifically, we develop a new depth-first
search algorithm, and combine it with an existing dynamic programming algorithm
due to Vinyals et al. [9]. The resulting hybrid algorithm is empirically shown
to significantly outperform both its constituent parts when the
subset-evaluation function happens to have certain intuitive properties.
-
This paper presents a methodology for simulating the Internet of Things (IoT)
using multi-level simulation models. With respect to conventional simulators,
this approach allows us to tune the level of detail of different parts of the
model without compromising the scalability of the simulation. As a use case, we
have developed a two-level simulator to study the deployment of smart services
over rural territories. The higher level is base on a coarse grained,
agent-based adaptive parallel and distributed simulator. When needed, this
simulator spawns OMNeT++ model instances to evaluate in more detail the issues
concerned with wireless communications in restricted areas of the simulated
world. The performance evaluation confirms the viability of multi-level
simulations for IoT environments.
-
In this paper we consider the problem of identifying intersections between
two sets of d-dimensional axis-parallel rectangles. This is a common problem
that arises in many agent-based simulation studies, and is of central
importance in the context of High Level Architecture (HLA), where it is at the
core of the Data Distribution Management (DDM) service. Several realizations of
the DDM service have been proposed; however, many of them are either
inefficient or inherently sequential. These are serious limitations since
multicore processors are now ubiquitous, and DDM algorithms -- being
CPU-intensive -- could benefit from additional computing power. We propose a
parallel version of the Sort-Based Matching algorithm for shared-memory
multiprocessors. Sort-Based Matching is one of the most efficient serial
algorithms for the DDM problem, but is quite difficult to parallelize due to
data dependencies. We describe the algorithm and compute its asymptotic running
time; we complete the analysis by assessing its performance and scalability
through extensive experiments on two commodity multicore systems based on a
dual socket Intel Xeon processor, and a single socket Intel Core i7 processor.
-
The price of anarchy and price of stability are three well-studied
performance metrics that seek to characterize the inefficiency of equilibria in
distributed systems. The distinction between these two performance metrics
centers on the equilibria that they focus on: the price of anarchy
characterizes the quality of the worst-performing equilibria, while the price
of stability characterizes the quality of the best-performing equilibria. While
much of the literature focuses on these metrics from an analysis perspective,
in this work we consider these performance metrics from a design perspective.
Specifically, we focus on the setting where a system operator is tasked with
designing local utility functions to optimize these performance metrics in a
class of games termed covering games. Our main result characterizes a
fundamental trade-off between the price of anarchy and price of stability in
the form of a fully explicit Pareto frontier. Within this setup, optimizing the
price of anarchy comes directly at the expense of the price of stability (and
vice versa). Our second results demonstrates how a system-operator could
incorporate an additional piece of system-level information into the design of
the agents' utility functions to breach these limitations and improve the
system's performance. This valuable piece of system-level information pertains
to the performance of worst performing agent in the system.
-
Swarm systems constitute a challenging problem for reinforcement learning
(RL) as the algorithm needs to learn decentralized control policies that can
cope with limited local sensing and communication abilities of the agents.
While it is often difficult to directly define the behavior of the agents,
simple communication protocols can be defined more easily using prior knowledge
about the given task. In this paper, we propose a number of simple
communication protocols that can be exploited by deep reinforcement learning to
find decentralized control policies in a multi-robot swarm environment. The
protocols are based on histograms that encode the local neighborhood relations
of the agents and can also transmit task-specific information, such as the
shortest distance and direction to a desired target. In our framework, we use
an adaptation of Trust Region Policy Optimization to learn complex
collaborative tasks, such as formation building and building a communication
link. We evaluate our findings in a simulated 2D-physics environment, and
compare the implications of different communication protocols.
-
We study the computations that Bayesian agents undertake when exchanging
opinions over a network. The agents act repeatedly on their private information
and take myopic actions that maximize their expected utility according to a
fully rational posterior belief. We show that such computations are NP-hard for
two natural utility functions: one with binary actions, and another where
agents reveal their posterior beliefs. In fact, we show that distinguishing
between posteriors that are concentrated on different states of the world is
NP-hard. Therefore, even approximating the Bayesian posterior beliefs is hard.
We also describe a natural search algorithm to compute agents' actions, which
we call elimination of impossible signals, and show that if the network is
transitive, the algorithm can be modified to run in polynomial time.
-
Two fundamental problems in computational game theory are computing a Nash
equilibrium and learning to exploit opponents given observations of their play
(opponent exploitation). The latter is perhaps even more important than the
former: Nash equilibrium does not have a compelling theoretical justification
in game classes other than two-player zero-sum, and for all games one can
potentially do better by exploiting perceived weaknesses of the opponent than
by following a static equilibrium strategy throughout the match. The natural
setting for opponent exploitation is the Bayesian setting where we have a prior
model that is integrated with observations to create a posterior opponent model
that we respond to. The most natural, and a well-studied prior distribution is
the Dirichlet distribution. An exact polynomial-time algorithm is known for
best-responding to the posterior distribution for an opponent assuming a
Dirichlet prior with multinomial sampling in normal-form games; however, for
imperfect-information games the best known algorithm is based on approximating
an infinite integral without theoretical guarantees. We present the first exact
algorithm for a natural class of imperfect-information games. We demonstrate
that our algorithm runs quickly in practice and outperforms the best prior
approaches. We also present an algorithm for the uniform prior setting.
-
We study the interaction between a fleet of electric, self-driving vehicles
servicing on-demand transportation requests (referred to as Autonomous
Mobility-on-Demand, or AMoD, system) and the electric power network. We propose
a model that captures the coupling between the two systems stemming from the
vehicles' charging requirements and captures time-varying customer demand and
power generation costs, road congestion, battery depreciation, and power
transmission and distribution constraints. We then leverage the model to
jointly optimize the operation of both systems. We devise an algorithmic
procedure to losslessly reduce the problem size by bundling customer requests,
allowing it to be efficiently solved by off-the-shelf linear programming
solvers. Next, we show that the socially optimal solution to the joint problem
can be enforced as a general equilibrium, and we provide a dual decomposition
algorithm that allows self-interested agents to compute the market clearing
prices without sharing private information. We assess the performance of the
mode by studying a hypothetical AMoD system in Dallas-Fort Worth and its impact
on the Texas power network. Lack of coordination between the AMoD system and
the power network can cause a 4.4% increase in the price of electricity in
Dallas-Fort Worth; conversely, coordination between the AMoD system and the
power network could reduce electricity expenditure compared to the case where
no cars are present (despite the increased demand for electricity) and yield
savings of up $147M/year. Finally, we provide a receding-horizon implementation
and assess its performance with agent-based simulations. Collectively, the
results of this paper provide a first-of-a-kind characterization of the
interaction between electric-powered AMoD systems and the power network, and
shed additional light on the economic and societal value of AMoD.
-
In this paper, we develop a distributed intermittent communication and task
planning framework for mobile robot teams. The goal of the robots is to
accomplish complex tasks, captured by local Linear Temporal Logic formulas, and
share the collected information with all other robots and possibly also with a
user. Specifically, we consider situations where the robot communication
capabilities are not sufficient to form reliable and connected networks while
the robots move to accomplish their tasks. In this case, intermittent
communication protocols are necessary that allow the robots to temporarily
disconnect from the network in order to accomplish their tasks free of
communication constraints. We assume that the robots can only communicate with
each other when they meet at common locations in space. Our distributed control
framework jointly determines local plans that allow all robots fulfill their
assigned temporal tasks, sequences of communication events that guarantee
information exchange infinitely often, and optimal communication locations that
minimize a desired distance metric. Simulation results verify the efficacy of
the proposed controllers.
-
This article introduces new tools to study self-organisation in a family of
simple cellular automata which contain some particle-like objects with good
collision properties (coalescence) in their time evolution. We draw an initial
configuration at random according to some initial $\sigma$-ergodic measure
$\mu$, and use the limit measure to descrbe the asymptotic behaviour of the
automata. We first take a qualitative approach, i.e. we obtain information on
the limit measure(s). We prove that only particles moving in one particular
direction can persist asymptotically. This provides some previously unknown
information on the limit measures of various deterministic and probabilistic
cellular automata: 3 and 4-cyclic cellular automata (introduced in [Fis90b]),
one-sided captive cellular automata (introduced in [The04]), N. Fat{\`e}s'
candidate to solve the density classification problem [Fat13], self
stabilization process toward a discrete line [RR15]... In a second time we
restrict our study to to a subclass, the gliders cellular automata. For this
class we show quantitative results, consisting in the asymptotic law of some
parameters: the entry times (generalising [KFD11]), the density of particles
and the rate of convergence to the limit measure.
-
Intelligent systems for the annotation of media content are increasingly
being used for the automation of parts of social science research. In this
domain the problem of integrating various Artificial Intelligence (AI)
algorithms into a single intelligent system arises spontaneously. As part of
our ongoing effort in automating media content analysis for the social
sciences, we have built a modular system by combining multiple AI modules into
a flexible framework in which they can cooperate in complex tasks. Our system
combines data gathering, machine translation, topic classification, extraction
and annotation of entities and social networks, as well as many other tasks
that have been perfected over the past years of AI research. Over the last few
years, it has allowed us to realise a series of scientific studies over a vast
range of applications including comparative studies between news outlets and
media content in different countries, modelling of user preferences, and
monitoring public mood. The framework is flexible and allows the design and
implementation of modular agents, where simple modules cooperate in the
annotation of a large dataset without central coordination.





 The key challenge in multiagent learning is learning a best response to the behaviour of other agents, which may be non-stationary: if the other agents adapt their strategy as well, the learning target moves. Disparate streams of research have approached non-stationarity from several angles, which make a variety of implicit assumptions that make it hard to keep an overview of the state of the art and to validate the innovation and significance of new works. This survey presents a coherent overview of work that addresses opponent-induced non-stationarity with tools from game theory, reinforcement learning and multi-armed bandits. Further, we reflect on the principle approaches how algorithms model and cope with this non-stationarity, arriving at a new framework and five categories (in increasing order of sophistication): ignore, forget, respond to target models, learn models, and theory of mind. A wide range of state-of-the-art algorithms is classified into a taxonomy, using these categories and key characteristics of the environment (e.g., observability) and adaptation behaviour of the opponents (e.g., smooth, abrupt). To clarify even further we present illustrative variations of one domain, contrasting the strengths and limitations of each category. Finally, we discuss in which environments the different approaches yield most merit, and point to promising avenues of future research.
The key challenge in multiagent learning is learning a best response to the behaviour of other agents, which may be non-stationary: if the other agents adapt their strategy as well, the learning target moves. Disparate streams of research have approached non-stationarity from several angles, which make a variety of implicit assumptions that make it hard to keep an overview of the state of the art and to validate the innovation and significance of new works. This survey presents a coherent overview of work that addresses opponent-induced non-stationarity with tools from game theory, reinforcement learning and multi-armed bandits. Further, we reflect on the principle approaches how algorithms model and cope with this non-stationarity, arriving at a new framework and five categories (in increasing order of sophistication): ignore, forget, respond to target models, learn models, and theory of mind. A wide range of state-of-the-art algorithms is classified into a taxonomy, using these categories and key characteristics of the environment (e.g., observability) and adaptation behaviour of the opponents (e.g., smooth, abrupt). To clarify even further we present illustrative variations of one domain, contrasting the strengths and limitations of each category. Finally, we discuss in which environments the different approaches yield most merit, and point to promising avenues of future research.




 The beer game is a widely used in-class game that is played in supply chain management classes to demonstrate the bullwhip effect. The game is a decentralized, multi-agent, cooperative problem that can be modeled as a serial supply chain network in which agents cooperatively attempt to minimize the total cost of the network even though each agent can only observe its own local information. Each agent chooses order quantities to replenish its stock. Under some conditions, a base-stock replenishment policy is known to be optimal. However, in a decentralized supply chain in which some agents (stages) may act irrationally (as they do in the beer game), there is no known optimal policy for an agent wishing to act optimally. We propose a machine learning algorithm, based on deep Q-networks, to optimize the replenishment decisions at a given stage. When playing alongside agents who follow a base-stock policy, our algorithm obtains near-optimal order quantities. It performs much better than a base-stock policy when the other agents use a more realistic model of human ordering behavior. Unlike most other algorithms in the literature, our algorithm does not have any limits on the beer game parameter values. Like any deep learning algorithm, training the algorithm can be computationally intensive, but this can be performed ahead of time; the algorithm executes in real time when the game is played. Moreover, we propose a transfer learning approach so that the training performed for one agent and one set of cost coefficients can be adapted quickly for other agents and costs. Our algorithm can be extended to other decentralized multi-agent cooperative games with partially observed information, which is a common type of situation in real-world supply chain problems.
The beer game is a widely used in-class game that is played in supply chain management classes to demonstrate the bullwhip effect. The game is a decentralized, multi-agent, cooperative problem that can be modeled as a serial supply chain network in which agents cooperatively attempt to minimize the total cost of the network even though each agent can only observe its own local information. Each agent chooses order quantities to replenish its stock. Under some conditions, a base-stock replenishment policy is known to be optimal. However, in a decentralized supply chain in which some agents (stages) may act irrationally (as they do in the beer game), there is no known optimal policy for an agent wishing to act optimally. We propose a machine learning algorithm, based on deep Q-networks, to optimize the replenishment decisions at a given stage. When playing alongside agents who follow a base-stock policy, our algorithm obtains near-optimal order quantities. It performs much better than a base-stock policy when the other agents use a more realistic model of human ordering behavior. Unlike most other algorithms in the literature, our algorithm does not have any limits on the beer game parameter values. Like any deep learning algorithm, training the algorithm can be computationally intensive, but this can be performed ahead of time; the algorithm executes in real time when the game is played. Moreover, we propose a transfer learning approach so that the training performed for one agent and one set of cost coefficients can be adapted quickly for other agents and costs. Our algorithm can be extended to other decentralized multi-agent cooperative games with partially observed information, which is a common type of situation in real-world supply chain problems.




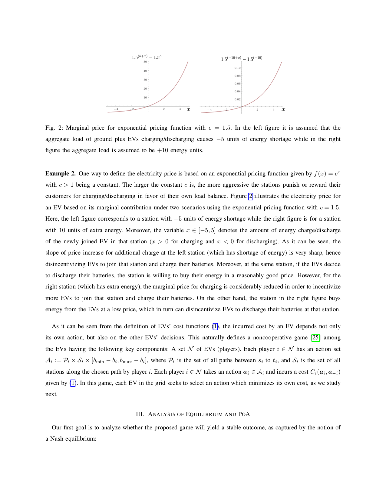 Electric vehicles (EVs) are expected to be a major component of the smart grid. The rapid proliferation of EVs will introduce an unprecedented load on the existing electric grid due to the charging/discharging behavior of the EVs, thus motivating the need for novel approaches for routing EVs across the grid. In this paper, a novel gametheoretic framework for smart routing of EVs within the smart grid is proposed. The goal of this framework is to balance the electricity load across the grid while taking into account the traffic congestion and the waiting time at charging stations. The EV routing problem is formulated as a noncooperative game. For this game, it is shown that selfish behavior of EVs will result in a pure-strategy Nash equilibrium with the price of anarchy upper bounded by the variance of the ground load induced by the residential, industrial, or commercial users. Moreover, the results are extended to capture the stochastic nature of induced ground load as well as the subjective behavior of the owners of EVs as captured by using notions from the behavioral framework of prospect theory. Simulation results provide new insights on more efficient energy pricing at charging stations and under more realistic grid conditions.
Electric vehicles (EVs) are expected to be a major component of the smart grid. The rapid proliferation of EVs will introduce an unprecedented load on the existing electric grid due to the charging/discharging behavior of the EVs, thus motivating the need for novel approaches for routing EVs across the grid. In this paper, a novel gametheoretic framework for smart routing of EVs within the smart grid is proposed. The goal of this framework is to balance the electricity load across the grid while taking into account the traffic congestion and the waiting time at charging stations. The EV routing problem is formulated as a noncooperative game. For this game, it is shown that selfish behavior of EVs will result in a pure-strategy Nash equilibrium with the price of anarchy upper bounded by the variance of the ground load induced by the residential, industrial, or commercial users. Moreover, the results are extended to capture the stochastic nature of induced ground load as well as the subjective behavior of the owners of EVs as captured by using notions from the behavioral framework of prospect theory. Simulation results provide new insights on more efficient energy pricing at charging stations and under more realistic grid conditions.




 In this paper, we develop a class of decentralized algorithms for solving a convex resource allocation problem in a network of $n$ agents, where the agent objectives are decoupled while the resource constraints are coupled. The agents communicate over a connected undirected graph, and they want to collaboratively determine a solution to the overall network problem, while each agent only communicates with its neighbors. We first study the connection between the decentralized resource allocation problem and the decentralized consensus optimization problem. Then, using a class of algorithms for solving consensus optimization problems, we propose a novel class of decentralized schemes for solving resource allocation problems in a distributed manner. Specifically, we first propose an algorithm for solving the resource allocation problem with an $o(1/k)$ convergence rate guarantee when the agents' objective functions are generally convex (could be nondifferentiable) and per agent local convex constraints are allowed; We then propose a gradient-based algorithm for solving the resource allocation problem when per agent local constraints are absent and show that such scheme can achieve geometric rate when the objective functions are strongly convex and have Lipschitz continuous gradients. We have also provided scalability/network dependency analysis. Based on these two algorithms, we have further proposed a gradient projection-based algorithm which can handle smooth objective and simple constraints more efficiently. Numerical experiments demonstrates the viability and performance of all the proposed algorithms.
In this paper, we develop a class of decentralized algorithms for solving a convex resource allocation problem in a network of $n$ agents, where the agent objectives are decoupled while the resource constraints are coupled. The agents communicate over a connected undirected graph, and they want to collaboratively determine a solution to the overall network problem, while each agent only communicates with its neighbors. We first study the connection between the decentralized resource allocation problem and the decentralized consensus optimization problem. Then, using a class of algorithms for solving consensus optimization problems, we propose a novel class of decentralized schemes for solving resource allocation problems in a distributed manner. Specifically, we first propose an algorithm for solving the resource allocation problem with an $o(1/k)$ convergence rate guarantee when the agents' objective functions are generally convex (could be nondifferentiable) and per agent local convex constraints are allowed; We then propose a gradient-based algorithm for solving the resource allocation problem when per agent local constraints are absent and show that such scheme can achieve geometric rate when the objective functions are strongly convex and have Lipschitz continuous gradients. We have also provided scalability/network dependency analysis. Based on these two algorithms, we have further proposed a gradient projection-based algorithm which can handle smooth objective and simple constraints more efficiently. Numerical experiments demonstrates the viability and performance of all the proposed algorithms.




 Many important stable matching problems are known to be NP-hard, even when strong restrictions are placed on the input. In this paper we seek to identify structural properties of instances of stable matching problems which will allow us to design efficient algorithms using elementary techniques. We focus on the setting in which all agents involved in some matching problem can be partitioned into k different types, where the type of an agent determines his or her preferences, and agents have preferences over types (which may be refined by more detailed preferences within a single type). This situation would arise in practice if agents form preferences solely based on some small collection of agents' attributes. We also consider a generalisation in which each agent may consider some small collection of other agents to be exceptional, and rank these in a way that is not consistent with their types; this could happen in practice if agents have prior contact with a small number of candidates. We show that (for the case without exceptions), several well-studied NP-hard stable matching problems including Max SMTI (that of finding the maximum cardinality stable matching in an instance of stable marriage with ties and incomplete lists) belong to the parameterised complexity class FPT when parameterised by the number of different types of agents needed to describe the instance. For Max SMTI this tractability result can be extended to the setting in which each agent promotes at most one `exceptional' candidate to the top of his/her list (when preferences within types are not refined), but the problem remains NP-hard if preference lists can contain two or more exceptions and the exceptional candidates can be placed anywhere in the preference lists, even if the number of types is bounded by a constant.
Many important stable matching problems are known to be NP-hard, even when strong restrictions are placed on the input. In this paper we seek to identify structural properties of instances of stable matching problems which will allow us to design efficient algorithms using elementary techniques. We focus on the setting in which all agents involved in some matching problem can be partitioned into k different types, where the type of an agent determines his or her preferences, and agents have preferences over types (which may be refined by more detailed preferences within a single type). This situation would arise in practice if agents form preferences solely based on some small collection of agents' attributes. We also consider a generalisation in which each agent may consider some small collection of other agents to be exceptional, and rank these in a way that is not consistent with their types; this could happen in practice if agents have prior contact with a small number of candidates. We show that (for the case without exceptions), several well-studied NP-hard stable matching problems including Max SMTI (that of finding the maximum cardinality stable matching in an instance of stable marriage with ties and incomplete lists) belong to the parameterised complexity class FPT when parameterised by the number of different types of agents needed to describe the instance. For Max SMTI this tractability result can be extended to the setting in which each agent promotes at most one `exceptional' candidate to the top of his/her list (when preferences within types are not refined), but the problem remains NP-hard if preference lists can contain two or more exceptions and the exceptional candidates can be placed anywhere in the preference lists, even if the number of types is bounded by a constant.



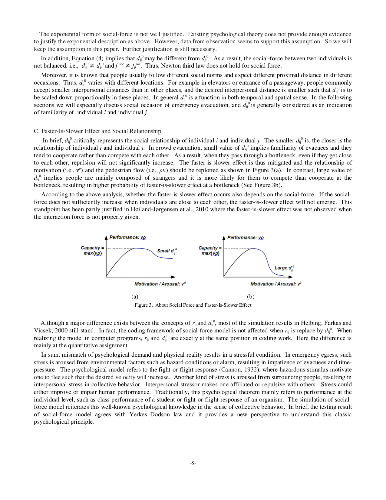
 To well understand crowd behavior, microscopic models have been developed in recent decades, in which an individual's behavioral/psychological status can be modeled and simulated. A well-known model is the social-force model innovated by physical scientists (Helbing and Molnar, 1995; Helbing, Farkas and Vicsek, 2000; Helbing et al., 2002). This model has been widely accepted and mainly used in simulation of crowd evacuation in the past decade. A problem, however, is that the testing results of the model were not explained in consistency with the psychological findings, resulting in misunderstanding of the model by psychologists. This paper will bridge the gap between psychological studies and physical explanation about this model. We reinterpret this physics-based model from a psychological perspective, clarifying that the model is consistent with psychological theories on stress, including time-related stress and interpersonal stress. Based on the conception of stress, we renew the model at both micro-and-macro level, referring to multi-agent simulation in a microscopic sense and fluid-based analysis in a macroscopic sense. The cognition and behavior of individual agents are critically modeled as response to environmental stimuli. Existing simulation results such as faster-is-slower effect will be reinterpreted by Yerkes-Dodson law, and herding and grouping effect are further discussed by integrating attraction into the social force. In brief the social-force model exhibits a bridge between the physics laws and psychological principles regarding crowd motion, and this paper will renew and reinterpret the model on the foundation of psychological studies.
To well understand crowd behavior, microscopic models have been developed in recent decades, in which an individual's behavioral/psychological status can be modeled and simulated. A well-known model is the social-force model innovated by physical scientists (Helbing and Molnar, 1995; Helbing, Farkas and Vicsek, 2000; Helbing et al., 2002). This model has been widely accepted and mainly used in simulation of crowd evacuation in the past decade. A problem, however, is that the testing results of the model were not explained in consistency with the psychological findings, resulting in misunderstanding of the model by psychologists. This paper will bridge the gap between psychological studies and physical explanation about this model. We reinterpret this physics-based model from a psychological perspective, clarifying that the model is consistent with psychological theories on stress, including time-related stress and interpersonal stress. Based on the conception of stress, we renew the model at both micro-and-macro level, referring to multi-agent simulation in a microscopic sense and fluid-based analysis in a macroscopic sense. The cognition and behavior of individual agents are critically modeled as response to environmental stimuli. Existing simulation results such as faster-is-slower effect will be reinterpreted by Yerkes-Dodson law, and herding and grouping effect are further discussed by integrating attraction into the social force. In brief the social-force model exhibits a bridge between the physics laws and psychological principles regarding crowd motion, and this paper will renew and reinterpret the model on the foundation of psychological studies.
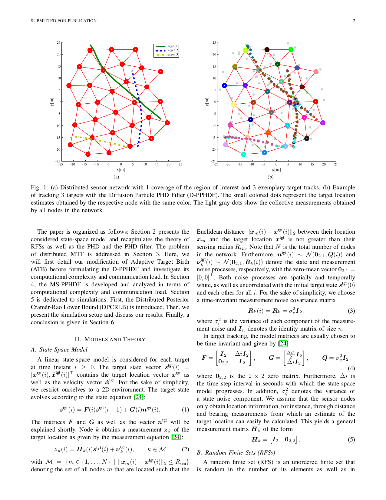



 Multi-target tracking is an important problem in civilian and military applications. This paper investigates multi-target tracking in distributed sensor networks. Data association, which arises particularly in multi-object scenarios, can be tackled by various solutions. We consider sequential Monte Carlo implementations of the Probability Hypothesis Density (PHD) filter based on random finite sets. This approach circumvents the data association issue by jointly estimating all targets in the region of interest. To this end, we develop the Diffusion Particle PHD Filter (D-PPHDF) as well as a centralized version, called the Multi-Sensor Particle PHD Filter (MS-PPHDF). Their performance is evaluated in terms of the Optimal Subpattern Assignment (OSPA) metric, benchmarked against a distributed extension of the Posterior Cram\'er-Rao Lower Bound (PCRLB), and compared to the performance of an existing distributed PHD Particle Filter. Furthermore, the robustness of the proposed tracking algorithms against outliers and their performance with respect to different amounts of clutter is investigated.
Multi-target tracking is an important problem in civilian and military applications. This paper investigates multi-target tracking in distributed sensor networks. Data association, which arises particularly in multi-object scenarios, can be tackled by various solutions. We consider sequential Monte Carlo implementations of the Probability Hypothesis Density (PHD) filter based on random finite sets. This approach circumvents the data association issue by jointly estimating all targets in the region of interest. To this end, we develop the Diffusion Particle PHD Filter (D-PPHDF) as well as a centralized version, called the Multi-Sensor Particle PHD Filter (MS-PPHDF). Their performance is evaluated in terms of the Optimal Subpattern Assignment (OSPA) metric, benchmarked against a distributed extension of the Posterior Cram\'er-Rao Lower Bound (PCRLB), and compared to the performance of an existing distributed PHD Particle Filter. Furthermore, the robustness of the proposed tracking algorithms against outliers and their performance with respect to different amounts of clutter is investigated.




 We introduce the problem of assigning resources to improve their utilization. The motivation comes from settings where agents have uncertainty about their own values for using a resource, and where it is in the interest of a group that resources be used and not wasted. Done in the right way, improved utilization maximizes social welfare--- balancing the utility of a high value but unreliable agent with the group's preference that resources be used. We introduce the family of contingent payment mechanisms (CP), which may charge an agent contingent on use (a penalty). A CP mechanism is parameterized by a maximum penalty, and has a dominant-strategy equilibrium. Under a set of axiomatic properties, we establish welfare-optimality for the special case CP(W), with CP instantiated for a maximum penalty equal to societal value W for utilization. CP(W) is not dominated for expected welfare by any other mechanism, and second, amongst mechanisms that always allocate the resource and have a simple indirect structure, CP(W) strictly dominates every other mechanism. The special case with no upper bound on penalty, the contingent second-price mechanism, maximizes utilization. We extend the mechanisms to assign multiple, heterogeneous resources, and present a simulation study of the welfare properties of these mechanisms.
We introduce the problem of assigning resources to improve their utilization. The motivation comes from settings where agents have uncertainty about their own values for using a resource, and where it is in the interest of a group that resources be used and not wasted. Done in the right way, improved utilization maximizes social welfare--- balancing the utility of a high value but unreliable agent with the group's preference that resources be used. We introduce the family of contingent payment mechanisms (CP), which may charge an agent contingent on use (a penalty). A CP mechanism is parameterized by a maximum penalty, and has a dominant-strategy equilibrium. Under a set of axiomatic properties, we establish welfare-optimality for the special case CP(W), with CP instantiated for a maximum penalty equal to societal value W for utilization. CP(W) is not dominated for expected welfare by any other mechanism, and second, amongst mechanisms that always allocate the resource and have a simple indirect structure, CP(W) strictly dominates every other mechanism. The special case with no upper bound on penalty, the contingent second-price mechanism, maximizes utilization. We extend the mechanisms to assign multiple, heterogeneous resources, and present a simulation study of the welfare properties of these mechanisms.




 Many societal decision problems lie in high-dimensional continuous spaces not amenable to the voting techniques common for their discrete or single-dimensional counterparts. These problems are typically discretized before running an election or decided upon through negotiation by representatives. We propose a algorithm called {\sc Iterative Local Voting} for collective decision-making in this setting. In this algorithm, voters are sequentially sampled and asked to modify a candidate solution within some local neighborhood of its current value, as defined by a ball in some chosen norm, with the size of the ball shrinking at a specified rate. We first prove the convergence of this algorithm under appropriate choices of neighborhoods to Pareto optimal solutions with desirable fairness properties in certain natural settings: when the voters' utilities can be expressed in terms of some form of distance from their ideal solution, and when these utilities are additively decomposable across dimensions. In many of these cases, we obtain convergence to the societal welfare maximizing solution. We then describe an experiment in which we test our algorithm for the decision of the U.S. Federal Budget on Mechanical Turk with over 2,000 workers, employing neighborhoods defined by $\mathcal{L}^1, \mathcal{L}^2$ and $\mathcal{L}^\infty$ balls. We make several observations that inform future implementations of such a procedure.
Many societal decision problems lie in high-dimensional continuous spaces not amenable to the voting techniques common for their discrete or single-dimensional counterparts. These problems are typically discretized before running an election or decided upon through negotiation by representatives. We propose a algorithm called {\sc Iterative Local Voting} for collective decision-making in this setting. In this algorithm, voters are sequentially sampled and asked to modify a candidate solution within some local neighborhood of its current value, as defined by a ball in some chosen norm, with the size of the ball shrinking at a specified rate. We first prove the convergence of this algorithm under appropriate choices of neighborhoods to Pareto optimal solutions with desirable fairness properties in certain natural settings: when the voters' utilities can be expressed in terms of some form of distance from their ideal solution, and when these utilities are additively decomposable across dimensions. In many of these cases, we obtain convergence to the societal welfare maximizing solution. We then describe an experiment in which we test our algorithm for the decision of the U.S. Federal Budget on Mechanical Turk with over 2,000 workers, employing neighborhoods defined by $\mathcal{L}^1, \mathcal{L}^2$ and $\mathcal{L}^\infty$ balls. We make several observations that inform future implementations of such a procedure.




 We consider social welfare functions that satisfy Arrow's classic axioms of independence of irrelevant alternatives and Pareto optimality when the outcome space is the convex hull of some finite set of alternatives. Individual and collective preferences are assumed to be continuous and convex, which guarantees the existence of maximal elements and the consistency of choice functions that return these elements, even without insisting on transitivity. We provide characterizations of both the domains of preferences and the social welfare functions that allow for anonymous Arrovian aggregation. The domains admit arbitrary preferences over alternatives, which completely determine an agent's preferences over all mixed outcomes. On these domains, Arrow's impossibility turns into a complete characterization of a unique social welfare function, which can be readily applied in settings involving divisible resources such as probability, time, or money.
We consider social welfare functions that satisfy Arrow's classic axioms of independence of irrelevant alternatives and Pareto optimality when the outcome space is the convex hull of some finite set of alternatives. Individual and collective preferences are assumed to be continuous and convex, which guarantees the existence of maximal elements and the consistency of choice functions that return these elements, even without insisting on transitivity. We provide characterizations of both the domains of preferences and the social welfare functions that allow for anonymous Arrovian aggregation. The domains admit arbitrary preferences over alternatives, which completely determine an agent's preferences over all mixed outcomes. On these domains, Arrow's impossibility turns into a complete characterization of a unique social welfare function, which can be readily applied in settings involving divisible resources such as probability, time, or money.




 We present two distributed methods for the estimation of the kinematic parameters, the dynamic parameters, and the kinematic state of an unknown planar body manipulated by a decentralized multi-agent system. The proposed approaches rely on the rigid body kinematics and dynamics, on nonlinear observation theory, and on consensus algorithms. The only three requirements are that each agent can exert a 2D wrench on the load, it can measure the velocity of its contact point, and that the communication graph is connected. Both theoretical nonlinear observability analysis and convergence proofs are provided. The first method assumes constant parameters while the second one can deal with time-varying parameters and can be applied in parallel to any task-oriented control law. For the cases in which a control law is not provided, we propose a distributed and safe control strategy satisfying the observability condition. The effectiveness and robustness of the estimation strategy is showcased by means of realistic MonteCarlo simulations.
We present two distributed methods for the estimation of the kinematic parameters, the dynamic parameters, and the kinematic state of an unknown planar body manipulated by a decentralized multi-agent system. The proposed approaches rely on the rigid body kinematics and dynamics, on nonlinear observation theory, and on consensus algorithms. The only three requirements are that each agent can exert a 2D wrench on the load, it can measure the velocity of its contact point, and that the communication graph is connected. Both theoretical nonlinear observability analysis and convergence proofs are provided. The first method assumes constant parameters while the second one can deal with time-varying parameters and can be applied in parallel to any task-oriented control law. For the cases in which a control law is not provided, we propose a distributed and safe control strategy satisfying the observability condition. The effectiveness and robustness of the estimation strategy is showcased by means of realistic MonteCarlo simulations.



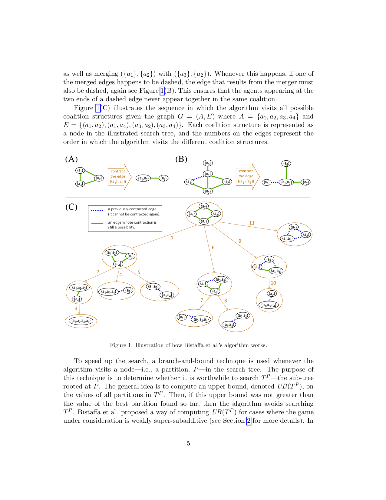
 Two fundamental algorithm-design paradigms are Tree Search and Dynamic Programming. The techniques used therein have been shown to complement one another when solving the complete set partitioning problem, also known as the coalition structure generation problem [5]. Inspired by this observation, we develop in this paper an algorithm to solve the coalition structure generation problem on graphs, where the goal is to identifying an optimal partition of a graph into connected subgraphs. More specifically, we develop a new depth-first search algorithm, and combine it with an existing dynamic programming algorithm due to Vinyals et al. [9]. The resulting hybrid algorithm is empirically shown to significantly outperform both its constituent parts when the subset-evaluation function happens to have certain intuitive properties.
Two fundamental algorithm-design paradigms are Tree Search and Dynamic Programming. The techniques used therein have been shown to complement one another when solving the complete set partitioning problem, also known as the coalition structure generation problem [5]. Inspired by this observation, we develop in this paper an algorithm to solve the coalition structure generation problem on graphs, where the goal is to identifying an optimal partition of a graph into connected subgraphs. More specifically, we develop a new depth-first search algorithm, and combine it with an existing dynamic programming algorithm due to Vinyals et al. [9]. The resulting hybrid algorithm is empirically shown to significantly outperform both its constituent parts when the subset-evaluation function happens to have certain intuitive properties.




 In this paper we consider the problem of identifying intersections between two sets of d-dimensional axis-parallel rectangles. This is a common problem that arises in many agent-based simulation studies, and is of central importance in the context of High Level Architecture (HLA), where it is at the core of the Data Distribution Management (DDM) service. Several realizations of the DDM service have been proposed; however, many of them are either inefficient or inherently sequential. These are serious limitations since multicore processors are now ubiquitous, and DDM algorithms -- being CPU-intensive -- could benefit from additional computing power. We propose a parallel version of the Sort-Based Matching algorithm for shared-memory multiprocessors. Sort-Based Matching is one of the most efficient serial algorithms for the DDM problem, but is quite difficult to parallelize due to data dependencies. We describe the algorithm and compute its asymptotic running time; we complete the analysis by assessing its performance and scalability through extensive experiments on two commodity multicore systems based on a dual socket Intel Xeon processor, and a single socket Intel Core i7 processor.
In this paper we consider the problem of identifying intersections between two sets of d-dimensional axis-parallel rectangles. This is a common problem that arises in many agent-based simulation studies, and is of central importance in the context of High Level Architecture (HLA), where it is at the core of the Data Distribution Management (DDM) service. Several realizations of the DDM service have been proposed; however, many of them are either inefficient or inherently sequential. These are serious limitations since multicore processors are now ubiquitous, and DDM algorithms -- being CPU-intensive -- could benefit from additional computing power. We propose a parallel version of the Sort-Based Matching algorithm for shared-memory multiprocessors. Sort-Based Matching is one of the most efficient serial algorithms for the DDM problem, but is quite difficult to parallelize due to data dependencies. We describe the algorithm and compute its asymptotic running time; we complete the analysis by assessing its performance and scalability through extensive experiments on two commodity multicore systems based on a dual socket Intel Xeon processor, and a single socket Intel Core i7 processor.




 We study the computations that Bayesian agents undertake when exchanging opinions over a network. The agents act repeatedly on their private information and take myopic actions that maximize their expected utility according to a fully rational posterior belief. We show that such computations are NP-hard for two natural utility functions: one with binary actions, and another where agents reveal their posterior beliefs. In fact, we show that distinguishing between posteriors that are concentrated on different states of the world is NP-hard. Therefore, even approximating the Bayesian posterior beliefs is hard. We also describe a natural search algorithm to compute agents' actions, which we call elimination of impossible signals, and show that if the network is transitive, the algorithm can be modified to run in polynomial time.
We study the computations that Bayesian agents undertake when exchanging opinions over a network. The agents act repeatedly on their private information and take myopic actions that maximize their expected utility according to a fully rational posterior belief. We show that such computations are NP-hard for two natural utility functions: one with binary actions, and another where agents reveal their posterior beliefs. In fact, we show that distinguishing between posteriors that are concentrated on different states of the world is NP-hard. Therefore, even approximating the Bayesian posterior beliefs is hard. We also describe a natural search algorithm to compute agents' actions, which we call elimination of impossible signals, and show that if the network is transitive, the algorithm can be modified to run in polynomial time.




 Two fundamental problems in computational game theory are computing a Nash equilibrium and learning to exploit opponents given observations of their play (opponent exploitation). The latter is perhaps even more important than the former: Nash equilibrium does not have a compelling theoretical justification in game classes other than two-player zero-sum, and for all games one can potentially do better by exploiting perceived weaknesses of the opponent than by following a static equilibrium strategy throughout the match. The natural setting for opponent exploitation is the Bayesian setting where we have a prior model that is integrated with observations to create a posterior opponent model that we respond to. The most natural, and a well-studied prior distribution is the Dirichlet distribution. An exact polynomial-time algorithm is known for best-responding to the posterior distribution for an opponent assuming a Dirichlet prior with multinomial sampling in normal-form games; however, for imperfect-information games the best known algorithm is based on approximating an infinite integral without theoretical guarantees. We present the first exact algorithm for a natural class of imperfect-information games. We demonstrate that our algorithm runs quickly in practice and outperforms the best prior approaches. We also present an algorithm for the uniform prior setting.
Two fundamental problems in computational game theory are computing a Nash equilibrium and learning to exploit opponents given observations of their play (opponent exploitation). The latter is perhaps even more important than the former: Nash equilibrium does not have a compelling theoretical justification in game classes other than two-player zero-sum, and for all games one can potentially do better by exploiting perceived weaknesses of the opponent than by following a static equilibrium strategy throughout the match. The natural setting for opponent exploitation is the Bayesian setting where we have a prior model that is integrated with observations to create a posterior opponent model that we respond to. The most natural, and a well-studied prior distribution is the Dirichlet distribution. An exact polynomial-time algorithm is known for best-responding to the posterior distribution for an opponent assuming a Dirichlet prior with multinomial sampling in normal-form games; however, for imperfect-information games the best known algorithm is based on approximating an infinite integral without theoretical guarantees. We present the first exact algorithm for a natural class of imperfect-information games. We demonstrate that our algorithm runs quickly in practice and outperforms the best prior approaches. We also present an algorithm for the uniform prior setting.




 In this paper, we develop a distributed intermittent communication and task planning framework for mobile robot teams. The goal of the robots is to accomplish complex tasks, captured by local Linear Temporal Logic formulas, and share the collected information with all other robots and possibly also with a user. Specifically, we consider situations where the robot communication capabilities are not sufficient to form reliable and connected networks while the robots move to accomplish their tasks. In this case, intermittent communication protocols are necessary that allow the robots to temporarily disconnect from the network in order to accomplish their tasks free of communication constraints. We assume that the robots can only communicate with each other when they meet at common locations in space. Our distributed control framework jointly determines local plans that allow all robots fulfill their assigned temporal tasks, sequences of communication events that guarantee information exchange infinitely often, and optimal communication locations that minimize a desired distance metric. Simulation results verify the efficacy of the proposed controllers.
In this paper, we develop a distributed intermittent communication and task planning framework for mobile robot teams. The goal of the robots is to accomplish complex tasks, captured by local Linear Temporal Logic formulas, and share the collected information with all other robots and possibly also with a user. Specifically, we consider situations where the robot communication capabilities are not sufficient to form reliable and connected networks while the robots move to accomplish their tasks. In this case, intermittent communication protocols are necessary that allow the robots to temporarily disconnect from the network in order to accomplish their tasks free of communication constraints. We assume that the robots can only communicate with each other when they meet at common locations in space. Our distributed control framework jointly determines local plans that allow all robots fulfill their assigned temporal tasks, sequences of communication events that guarantee information exchange infinitely often, and optimal communication locations that minimize a desired distance metric. Simulation results verify the efficacy of the proposed controllers.




 This article introduces new tools to study self-organisation in a family of simple cellular automata which contain some particle-like objects with good collision properties (coalescence) in their time evolution. We draw an initial configuration at random according to some initial $\sigma$-ergodic measure $\mu$, and use the limit measure to descrbe the asymptotic behaviour of the automata. We first take a qualitative approach, i.e. we obtain information on the limit measure(s). We prove that only particles moving in one particular direction can persist asymptotically. This provides some previously unknown information on the limit measures of various deterministic and probabilistic cellular automata: 3 and 4-cyclic cellular automata (introduced in [Fis90b]), one-sided captive cellular automata (introduced in [The04]), N. Fat{\`e}s' candidate to solve the density classification problem [Fat13], self stabilization process toward a discrete line [RR15]... In a second time we restrict our study to to a subclass, the gliders cellular automata. For this class we show quantitative results, consisting in the asymptotic law of some parameters: the entry times (generalising [KFD11]), the density of particles and the rate of convergence to the limit measure.
This article introduces new tools to study self-organisation in a family of simple cellular automata which contain some particle-like objects with good collision properties (coalescence) in their time evolution. We draw an initial configuration at random according to some initial $\sigma$-ergodic measure $\mu$, and use the limit measure to descrbe the asymptotic behaviour of the automata. We first take a qualitative approach, i.e. we obtain information on the limit measure(s). We prove that only particles moving in one particular direction can persist asymptotically. This provides some previously unknown information on the limit measures of various deterministic and probabilistic cellular automata: 3 and 4-cyclic cellular automata (introduced in [Fis90b]), one-sided captive cellular automata (introduced in [The04]), N. Fat{\`e}s' candidate to solve the density classification problem [Fat13], self stabilization process toward a discrete line [RR15]... In a second time we restrict our study to to a subclass, the gliders cellular automata. For this class we show quantitative results, consisting in the asymptotic law of some parameters: the entry times (generalising [KFD11]), the density of particles and the rate of convergence to the limit measure.