-
Common trends in model order reduction of large nonlinear
finite-element-discretized systems involve the introduction of a linear mapping
into a reduced set of unknowns, followed by Galerkin projection of the
governing equations onto a constant reduction basis. Though this reduces the
number of unknowns in the system, the computational cost for obtaining the
solution could still be high due to the prohibitive computational costs
involved in the evaluation of nonlinear terms. Hyper-reduction methods are then
seen as a fast way of approximating the nonlinearity in the system of
equations. In the finite element context, the energy conserving sampling and
weighing (ECSW) method has emerged as a stability and structure-preserving
method for hyper-reduction. Classical hyper-reduction techniques, however, are
applicable only in the context of linear mappings into the reduction subspace.
In this work, we extend the concept of hyper-reduction using ECSW to general
nonlinear mappings, while retaining its desirable stability and
structure-preserving properties. As a proof of concept, the proposed
hyper-reduction technique is demonstrated over models of a flat plate and a
realistic wing structure, whose dynamics has been shown to evolve over a
nonlinear (quadratic) manifold. An online speed-up of over one thousand times
relative to the full system has been obtained for the wing structure using the
proposed method, which is higher than its linear counterpart using the ECSW.
-
EnKF-C provides a compact generic framework for off-line data assimilation
into large-scale layered geophysical models with the ensemble Kalman filter
(EnKF). It is coded in C for GNU/Linux platform and can work either in EnKF,
ensemble optimal interpolation (EnOI), or hybrid (EnKF/EnOI) modes.
-
Scaling algorithms for entropic transport-type problems have become a very
popular numerical method, encompassing Wasserstein barycenters, multi-marginal
problems, gradient flows and unbalanced transport. However, a standard
implementation of the scaling algorithm has several numerical limitations: the
scaling factors diverge and convergence becomes impractically slow as the
entropy regularization approaches zero. Moreover, handling the dense kernel
matrix becomes unfeasible for large problems. To address this, we combine
several modifications: A log-domain stabilized formulation, the well-known
epsilon-scaling heuristic, an adaptive truncation of the kernel and a
coarse-to-fine scheme. This permits the solution of larger problems with
smaller regularization and negligible truncation error. A new convergence
analysis of the Sinkhorn algorithm is developed, working towards a better
understanding of epsilon-scaling. Numerical examples illustrate efficiency and
versatility of the modified algorithm.
-
This report describes the computation of gradients by algorithmic
differentiation for statistically optimum beamforming operations. Especially
the derivation of complex-valued functions is a key component of this approach.
Therefore the real-valued algorithmic differentiation is extended via the
complex-valued chain rule. In addition to the basic mathematic operations the
derivative of the eigenvalue problem with complex-valued eigenvectors is one of
the key results of this report. The potential of this approach is shown with
experimental results on the CHiME-3 challenge database. There, the beamforming
task is used as a front-end for an ASR system. With the developed derivatives a
joint optimization of a speech enhancement and speech recognition system w.r.t.
the recognition optimization criterion is possible.
-
We develop an algorithm that forecasts cascading events, by employing a
Green's function scheme on the basis of the self-exciting point process model.
This method is applied to open data of 10 types of crimes happened in Chicago.
It shows a good prediction accuracy superior to or comparable to the standard
methods which are the expectation-maximization method and prospective hotspot
maps method. We find a cascade influence of the crimes that has a long-time,
logarithmic tail; this result is consistent with an earlier study on
burglaries. This long-tail feature cannot be reproduced by the other standard
methods. In addition, a merit of the Green's function method is the low
computational cost in the case of high density of events and/or large amount of
the training data.
-
The development of chemical reaction models aids understanding and prediction
in areas ranging from biology to electrochemistry and combustion. A systematic
approach to building reaction network models uses observational data not only
to estimate unknown parameters, but also to learn model structure. Bayesian
inference provides a natural approach to this data-driven construction of
models. Yet traditional Bayesian model inference methodologies that numerically
evaluate the evidence for each model are often infeasible for nonlinear
reaction network inference, as the number of plausible models can be
combinatorially large. Alternative approaches based on model-space sampling can
enable large-scale network inference, but their realization presents many
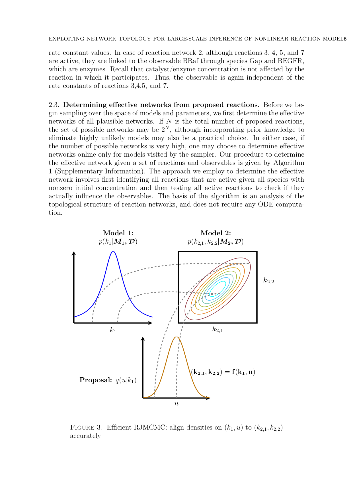
challenges. In this paper, we present new computational methods that make
large-scale nonlinear network inference tractable. First, we exploit the
topology of networks describing potential interactions among chemical species
to design improved "between-model" proposals for reversible-jump Markov chain
Monte Carlo. Second, we introduce a sensitivity-based determination of move
types which, when combined with network-aware proposals, yields significant
additional gains in sampling performance. These algorithms are demonstrated on
inference problems drawn from systems biology, with nonlinear differential
equation models of species interactions.
-
We design, analyse and implement an arbitrary order scheme applicable to
generic meshes for a coupled elliptic-parabolic PDE system describing miscible
displacement in porous media. The discretisation is based on several
adaptations of the Hybrid-High-Order (HHO) method due to Di Pietro et al.
[Computational Methods in Applied Mathematics, 14(4), (2014)]. The equation
governing the pressure is discretised using an adaptation of the HHO method for
variable diffusion, while the discrete concentration equation is based on the
HHO method for advection-diffusion-reaction problems combined with numerically
stable flux reconstructions for the advective velocity that we have derived
using the results of Cockburn et al. [ESAIM: Mathematical Modelling and
Numerical Analysis, 50(3), (2016)]. We perform some rigorous analysis of the
method to demonstrate its L2 stability under the irregular data often
presented by reservoir engineering problems and present several numerical tests
to demonstrate the quality of the results that are produced by the proposed
scheme.
-
A unified fluid-structure interaction (FSI) formulation is presented for
solid, liquid and mixed membranes. Nonlinear finite elements (FE) and the
generalized-alpha scheme are used for the spatial and temporal discretization.
The membrane discretization is based on curvilinear surface elements that can
describe large deformations and rotations, and also provide a straightforward
description for contact. The fluid is described by the incompressible
Navier-Stokes equations, and its discretization is based on stabilized
Petrov-Galerkin FE. The coupling between fluid and structure uses a conforming
sharp interface discretization, and the resulting non-linear FE equations are
solved monolithically within the Newton-Raphson scheme. An arbitrary
Lagrangian-Eulerian formulation is used for the fluid in order to account for
the mesh motion around the structure. The formulation is very general and
admits diverse applications that include contact at free surfaces. This is
demonstrated by two analytical and three numerical examples exhibiting strong
coupling between fluid and structure. The examples include balloon inflation,
droplet rolling and flapping flags. They span a Reynolds-number range from
0.001 to 2000. One of the examples considers the extension to rotation-free
shells using isogeometric FE.
-
The fraction nonconforming is a key quality measure used in statistical
quality control design in clinical laboratory medicine. The confidence bounds
of normal populations of measurements for the fraction nonconforming each of
the lower and upper quality specification limits when both the random and the
systematic error are unknown can be calculated using the noncentral
t-distribution, as it is described in detail and illustrated with examples.
-
Despite its numerical challenges, finite element method is used to compute
viscous fluid flow. A consensus on the cause of numerical problems has been
reached; however, general algorithms---allowing a robust and accurate
simulation for any process---are still missing. Either a very high
computational cost is necessary for a direct numerical solution (DNS) or some
limiting procedure is used by adding artificial dissipation to the system.
These stabilization methods are useful; however, they are often applied
relative to the element size such that a local monotonous convergence is
challenging to acquire. We need a computational strategy for solving viscous
fluid flow using solely the balance equations. In this work, we present a
general procedure solving fluid mechanics problems without use of any
stabilization or splitting schemes. Hence, its generalization to multiphysics
applications is straightforward. We discuss emerging numerical problems and
present the methodology rigorously. Implementation is achieved by using
open-source packages and the accuracy as well as the robustness is demonstrated
by comparing results to the closed-form solutions and also by solving
well-known benchmarking problems.
-
We propose a new approach to linear ill-posed inverse problems. Our algorithm
alternates between enforcing two constraints: the measurements and the
statistical correlation structure in some transformed space. We use a
non-linear multiscale scattering transform which discards the phase and thus
exposes strong spectral correlations otherwise hidden beneath the phase
fluctuations. As a result, both constraints may be put into effect by linear
projections in their respective spaces. We apply the algorithm to
super-resolution and tomography and show that it outperforms ad hoc convex
regularizers and stably recovers the missing spectrum.
-
This paper introduces a novel boundary integral approach of shape uncertainty
quantification for the Helmholtz scattering problem in the framework of the
so-called parametric method. The key idea is to construct an integration grid
whose associated weight function encompasses the irregularities and
nonsmoothness imposed by the random boundary. Thus, the solution can be
evaluated accurately with relatively low number of grid points. The integration
grid is obtained by employing a low-dimensional spatial embedding using the
coarea formula. The proposed method can handle large variation as well as
non-smoothness of the random boundary. For the ease of presentation the theory
is restricted to star-shaped obstacles in low-dimensional setting. Higher
spatial and parametric dimensional cases are discussed, though, not extensively
explored in the current study.
-
We present a continuous model for structural brain connectivity based on the
Poisson point process. The model treats each streamline curve in a tractography
as an observed event in connectome space, here a product space of cortical
white matter boundaries. We approximate the model parameter via kernel density
estimation. To deal with the heavy computational burden, we develop a fast
parameter estimation method by pre-computing associated Legendre products of
the data, leveraging properties of the spherical heat kernel. We show how our
approach can be used to assess the quality of cortical parcellations with
respect to connectivty. We further present empirical results that suggest the
discrete connectomes derived from our model have substantially higher
test-retest reliability compared to standard methods.
-
The optimization of power systems involves complex uncertainties, such as
technological progress, political context, geopolitical constraints.
Negotiations at COP21 are complicated by the huge number of scenarios that
various people want to consider; these scenarios correspond to many
uncertainties. These uncertainties are difficult to modelize as probabilities,
due to the lack of data for future technologies and due to partially
adversarial geopolitical decision makers. Tools for such difficult decision
making problems include Wald and Savage criteria, possibilistic reasoning and
Nash equilibria. We investigate the rationale behind the use of a two-player
Nash equilibrium approach in such a difficult context; we show that the
computational cost is indeed smaller than for simpler criteria. Moreover, it
naturally provides a selection of decisions and scenarios, and it has a natural
interpretation in the sense that Nature does not make decisions taking into
account our own decisions. The algorithm naturally provides a matrix of
results, namely the matrix of outcomes in the most interesting decisions and
for the most critical scenarios. These decisions and scenarios are also
equipped with a ranking.
-
To the knowledge of the author, this is the first time it has been shown that
interest rates that are extremely high by modern standards (100% and higher)
are necessary within a zero-sum monetary system, and not just driven by greed.
Extreme interest rates that appeared in various places and times reinforce the
idea that hard money may have contributed to high rates of interest. Here a
model is presented that examines the interest rate required to succeed as an
investor in a zero-sum fixed quantity hard-money system. Even when the playing
field is significantly tilted toward the investor, interest rates need to be
much higher than expected. In a completely fair zero-sum system, an investor
cannot break even without charging 100% interest. Even with a 5% advantage, an
investor won't break even at 15% interest. From this it is concluded that what
we consider usurious rates today are, within a hard-money system, driven by
necessity.
Cryptocurrency is a novel form of hard-currency. The inability to virtualize
the money creates a system close to zero-sum because of the limited supply
design. Therefore, within the bounds of a cryptocurrency system that limits
money creation, interest rates must rise to levels that the modern world
considers usury. It is impossible, therefore, that a cryptocurrency that is not
expandable could take over a modern economy and replace modern fiat currency.
-
This paper presents our work on designing a parallel platform for large-scale
reservoir simulations. Detailed components, such as grid and linear solver, and
data structures are introduced, which can serve as a guide to parallel
reservoir simulations and other parallel applications. The main objective of
platform is to support implementation of various parallel reservoir simulators
on distributed-memory parallel systems, where MPI (Message Passing Interface)
is employed for communications among computation nodes. It provides structured
grid due to its simplicity and cell-centered data is applied for each cell. The
platform has a distributed matrix and vector module and a map module. The
matrix and vector module is the base of our parallel linear systems. The map
connects grid and linear system modules, which defines various mappings between
grid and linear systems. Commonly-used Krylov subspace linear solvers are
implemented, including the restarted GMRES method and the BiCGSTAB method. It
also has an interface to a parallel algebraic multigrid solver, BoomerAMG from
HYPRE. Parallel general-purpose preconditioners and special preconditioners for
reservoir simulations are also developed. Various data structures are designed,
such as grid, cell, data, linear solver and preconditioner, and some key
default parameters are presented in this paper. The numerical experiments show
that our platform has excellent scalability and it can simulate giant reservoir
models with hundreds of millions of grid cells using thousands of CPU cores.
-
Managing the prediction of metrics in high-frequency financial markets is a
challenging task. An efficient way is by monitoring the dynamics of a limit
order book to identify the information edge. This paper describes the first
publicly available benchmark dataset of high-frequency limit order markets for
mid-price prediction. We extracted normalized data representations of time
series data for five stocks from the NASDAQ Nordic stock market for a time
period of ten consecutive days, leading to a dataset of ~4,000,000 time series
samples in total. A day-based anchored cross-validation experimental protocol
is also provided that can be used as a benchmark for comparing the performance
of state-of-the-art methodologies. Performance of baseline approaches are also
provided to facilitate experimental comparisons. We expect that such a
large-scale dataset can serve as a testbed for devising novel solutions of
expert systems for high-frequency limit order book data analysis.
-
We devise and evaluate numerically Hybrid High-Order (HHO) methods for
hyperelastic materials undergoing finite deformations. The HHO methods use as
discrete unknowns piecewise polynomials of order k≥1 on the mesh skeleton,
together with cell-based polynomials that can be eliminated locally by static
condensation. The discrete problem is written as the minimization of the broken
nonlinear elastic energy where a local reconstruction of the displacement
gradient is used. Two HHO methods are considered: a stabilized method where the
gradient is reconstructed as a tensor-valued polynomial of order k and a
stabilization is added to the discrete energy functional, and an unstabilized
method which reconstructs a stable higher-order gradient and circumvents the
need for stabilization. Both methods satisfy the principle of virtual work
locally with equilibrated tractions. We present a numerical study of both HHO
methods on test cases with known solution and on more challenging
three-dimensional test cases including finite deformations with strong shear
layers and cavitating voids. We assess the computational efficiency of both
methods, and we compare our results to those obtained with an industrial
software using conforming finite elements and to results from the literature.
Both methods exhibit robust behavior in the quasi-incompressible regime.
-
Bayesian methods and their implementations by means of sophisticated Monte
Carlo techniques have become very popular in signal processing over the last
years. Importance Sampling (IS) is a well-known Monte Carlo technique that
approximates integrals involving a posterior distribution by means of weighted
samples. In this work, we study the assignation of a single weighted sample
which compresses the information contained in a population of weighted samples.
Part of the theory that we present as Group Importance Sampling (GIS) has been
employed implicitly in different works in the literature. The provided analysis
yields several theoretical and practical consequences. For instance, we discuss
the application of GIS into the Sequential Importance Resampling framework and
show that Independent Multiple Try Metropolis schemes can be interpreted as a
standard Metropolis-Hastings algorithm, following the GIS approach. We also
introduce two novel Markov Chain Monte Carlo (MCMC) techniques based on GIS.
The first one, named Group Metropolis Sampling method, produces a Markov chain
of sets of weighted samples. All these sets are then employed for obtaining a
unique global estimator. The second one is the Distributed Particle
Metropolis-Hastings technique, where different parallel particle filters are
jointly used to drive an MCMC algorithm. Different resampled trajectories are
compared and then tested with a proper acceptance probability. The novel
schemes are tested in different numerical experiments such as learning the
hyperparameters of Gaussian Processes, two localization problems in a wireless
sensor network (with synthetic and real data) and the tracking of vegetation
parameters given satellite observations, where they are compared with several
benchmark Monte Carlo techniques. Three illustrative Matlab demos are also
provided.
-
Learning to detect fraud in large-scale accounting data is one of the
long-standing challenges in financial statement audits or fraud investigations.
Nowadays, the majority of applied techniques refer to handcrafted rules derived
from known fraud scenarios. While fairly successful, these rules exhibit the
drawback that they often fail to generalize beyond known fraud scenarios and
fraudsters gradually find ways to circumvent them. To overcome this
disadvantage and inspired by the recent success of deep learning we propose the
application of deep autoencoder neural networks to detect anomalous journal
entries. We demonstrate that the trained network's reconstruction error
obtainable for a journal entry and regularized by the entry's individual
attribute probabilities can be interpreted as a highly adaptive anomaly
assessment. Experiments on two real-world datasets of journal entries, show the
effectiveness of the approach resulting in high f1-scores of 32.93 (dataset A)
and 16.95 (dataset B) and less false positive alerts compared to state of the
art baseline methods. Initial feedback received by chartered accountants and
fraud examiners underpinned the quality of the approach in capturing highly
relevant accounting anomalies.
-
We present a novel approach to fast on-the-fly low order finite element
assembly for scalar elliptic partial differential equations of Darcy type with
variable coefficients optimized for matrix-free implementations. Our approach
introduces a new operator that is obtained by appropriately scaling the
reference stiffness matrix from the constant coefficient case. Assuming
sufficient regularity, an a priori analysis shows that solutions obtained by
this approach are unique and have asymptotically optimal order convergence in
the H1- and the L2-norm on hierarchical hybrid grids. For the
pre-asymptotic regime, we present a local modification that guarantees uniform
ellipticity of the operator. Cost considerations show that our novel approach
requires roughly one third of the floating-point operations compared to a
classical finite element assembly scheme employing nodal integration. Our
theoretical considerations are illustrated by numerical tests that confirm the
expectations with respect to accuracy and run-time. A large scale application
with more than a hundred billion (1.6⋅1011) degrees of freedom
executed on 14,310 compute cores demonstrates the efficiency of the new scaling
approach.
-
Reliability theory is used to assess the sensitivity of a passive flexion and
active flexion of the human lower leg Finite Element (FE) models with Total
Knee Replacement (TKR) to the variability in the input parameters of the
respective FE models. The sensitivity of the active flexion simulating the
stair ascent of the human lower leg FE model with TKR was presented before in
[1,2] whereas now in this paper a comparison is made with the passive flexion
of the human lower leg FE model with TKR. First, with the Monte Carlo
Simulation Technique (MCST), a number of randomly generated input data of the
FE model(s) are obtained based on the normal standard deviations of the
respective input parameters. Then a series of FE simulations are done and the
output kinematics and peak contact pressures are obtained for the respective FE
models (passive flexion and/or active flexion models). Seven output performance
measures are reported for the passive flexion model and one more parameter was
reported for the active flexion FE model (patello-femoral peak contact
pressure) in [1]. A sensitivity study will be performed based on the Response
Surface Method (RSM) to identify the key parameters that influence the
kinematics and peak contact pressures of the passive flexion FE model. Another
two MCST and RSM-based probabilistic FE analyses will be performed based on a
reduced list of 19 key input parameters. In total 4 probabilistic FE analyses
will be performed: 2 probabilistic FE analyses (MCST and RSM) based on an
extended set of 78 input variables and another 2 probabilistic FE analyses
(MCST and RSM) based on a reduced set of 19 input variables. Due to the likely
computation cost in order to make hundreds of FE simulations with MCST, a
high-performance and distributed computing system will be used for the passive
flexion FE model the same as it was used for the active flexion FE model in
[1].
-
Designed to compete with fiat currencies, bitcoin proposes it is a
crypto-currency alternative. Bitcoin makes a number of false claims, including:
solving the double-spending problem is a good thing; bitcoin can be a reserve
currency for banking; hoarding equals saving, and that we should believe
bitcoin can expand by deflation to become a global transactional currency
supply. Bitcoin's developers combine technical implementation proficiency with
ignorance of currency and banking fundamentals. This has resulted in a failed
attempt to change finance. A set of recommendations to change finance are
provided in the Afterword: Investment/venture banking for the masses; Venture
banking to bring back what investment banks once were; Open-outcry exchange for
all CDS contracts; Attempting to develop CDS type contracts on investments in
startup and existing enterprises; and Improving the connection between startup
tech/ideas, business organization and investment.
-
Multiscale models allow for the treatment of complex phenomena involving
different scales, such as remodeling and growth of tissues, muscular
activation, and cardiac electrophysiology. Numerous numerical approaches have
been developed to simulate multiscale problems. However, compared to the
well-established methods for classical problems, many questions have yet to be
answered. Here, we give an overview of existing models and methods, with
particular emphasis on mechanical and bio-mechanical applications. Moreover, we
discuss state-of-the-art techniques for multilevel and multifidelity
uncertainty quantification. In particular, we focus on the similarities that
can be found across multiscale models, discretizations, solvers, and
statistical methods for uncertainty quantification. Similarly to the current
trend of removing the segregation between discretizations and solution methods
in scientific computing, we anticipate that the future of multiscale simulation
will provide a closer interaction with also the models and the statistical
methods. This will yield better strategies for transferring the information
across different scales and for a more seamless transition in selecting and
adapting the level of details in the models. Finally, we note that machine
learning and Bayesian techniques have shown a promising capability to capture
complex model dependencies and enrich the results with statistical information;
therefore, they can complement traditional physics-based and numerical analysis
approaches.
-
Two-dimensional (2D) pressure field estimation in molecular dynamics (MD)
simulations has been done using three-dimensional (3D) pressure field
calculations followed by averaging, which is computationally expensive due to
3D convolutions. In this work, we develop a direct 2D pressure field estimation
method which is much faster than 3D methods without losing accuracy. The method
is validated with MD simulations on two systems: a liquid film and a
cylindrical drop of argon suspended in surrounding vapor.