-
The traditional measurement theory interprets the variance as the dispersion
of a measured value, which is actually contrary to a general mathematical
concept that the variance of a constant is 0. This paper will fully demonstrate
that the variance in measurement theory is actually the evaluation of
probability interval of an error instead of the dispersion of a measured value,
point out the key point of mistake in the traditional interpretation, and fully
interpret a series of changes in conceptual logic and processing method brought
about by this new concept.
-
We consider the problem of selecting a portfolio of entries of fixed
cardinality for contests with top-heavy payoff structures, i.e. most of the
winnings go to the top-ranked entries. This framework is general and can be
used to model a variety of problems, such as movie studios selecting movies to
produce, venture capital firms picking start-up companies to invest in, or
individuals selecting lineups for daily fantasy sports contests, which is the
example we focus on here. We model the portfolio selection task as a
combinatorial optimization problem with a submodular objective function, which
is given by the probability of at least one entry winning. We then show that
this probability can be approximated using only pairwise marginal probabilities
of the entries winning when there is a certain structure on their joint
distribution. We consider a model where the entries are jointly Gaussian random
variables and present a closed form approximation to the objective function.
Building on this, we then consider a scenario where the entries are given by
sums of constrained resources and present an integer programming formulation to
construct the entries. Our formulation uses principles based on our theoretical
analysis to construct entries: we maximize the expected score of an entry
subject to a lower bound on its variance and an upper bound on its correlation
with previously constructed entries. To demonstrate the effectiveness of our
integer programming approach, we apply it to daily fantasy sports contests that
have top-heavy payoff structures. We find that our approach performs well in
practice. Using our integer programming approach, we are able to rank in the
top-ten multiple times in hockey and baseball contests with thousands of
competing entries. Our approach can easily be extended to other problems with
constrained resources and a top-heavy payoff structure.
-
A simple, intuitive approach to the assessment of probabilistic inferences is
introduced. The Shannon information metrics are translated to the probability
domain. The translation shows that the negative logarithmic score and the
geometric mean are equivalent measures of the accuracy of a probabilistic
inference. Thus there is both a quantitative reduction in perplexity, which is
the inverse of the geometric mean of the probabilities, as good inference
algorithms reduce the uncertainty and a qualitative reduction due to the
increased clarity between the original set of probabilistic forecasts and their
central tendency, the geometric mean. Further insight is provided by showing
that the R\'enyi and Tsallis entropy functions translated to the probability
domain are both the weighted generalized mean of the distribution. The
generalized mean of probabilistic forecasts forms a spectrum of performance
metrics referred to as a Risk Profile. The arithmetic mean is used to measure
the decisiveness, while the -2/3 mean is used to measure the robustness.
-
We investigate a Poisson sampling design in the presence of unknown selection
probabilities when applied to a population of unknown size for multiple
sampling occasions. The fixed-population model is adopted and extended upon for
inference. The complete minimal sufficient statistic is derived for the
sampling model parameters and fixed-population parameter vector. The
Rao-Blackwell version of population quantity estimators is detailed. An
application is applied to an emprical population. The extended inferential
framework is found to have much potential and utility for empirical studies.
-
Quality control in industrial processes is increasingly making use of prior
scientific knowledge, often encoded in physical models that require numerical
approximation. Statistical prediction, and subsequent optimization, is key to
ensuring the process output meets a specification target. However, the
numerical expense of approximating the models poses computational challenges to
the identification of combinations of the process factors where there is
confidence in the quality of the response. Recent work in Bayesian computation
and statistical approximation (emulation) of expensive computational models is
exploited to develop a novel strategy for optimizing the posterior probability
of a process meeting specification. The ensuing methodology is motivated by,
and demonstrated on, a chemical synthesis process to manufacture a
pharmaceutical product, within which an initial set of substances evolve
according to chemical reactions, under certain process conditions, into a
series of new substances. One of these substances is a target pharmaceutical
product and two are unwanted by-products. The aim is to determine the
combinations of process conditions and amounts of initial substances that
maximize the probability of obtaining sufficient target pharmaceutical product
whilst ensuring unwanted by-products do not exceed a given level. The
relationship between the factors and amounts of substances of interest is
theoretically described by the solution to a system of ordinary differential
equations incorporating temperature dependence. Using data from a small
experiment, it is shown how the methodology can approximate the multivariate
posterior predictive distribution of the pharmaceutical target and by-products,
and therefore identify suitable operating values. Materials to replicate the
analysis can be found at www.github.com/amo105/chemicalkinetics.
-
This study demonstrates how to use "spmoran", an R package estimating spatial
additive mixed models and other spatial regression models for Gaussian and
non-Gaussian data. Moran eigenvectors are used to an approximate Gaussian
process modeling which is interpretable in terms of the Moran coefficient. The
GP is used for modeling the spatial processes in residuals and regression
coefficients. All these models are estimated computationally efficiently. For
the sample code used in this paper, see https://github.com/dmuraka/spmoran.
-
Objective prior distributions represent an important tool that allows one to
have the advantages of using the Bayesian framework even when information about
the parameters of a model is not available. The usual objective approaches work
off the chosen statistical model and in the majority of cases the resulting
prior is improper, which can pose limitations to a practical implementation,
even when the complexity of the model is moderate. In this paper we propose to
take a novel look at the construction of objective prior distributions, where
the connection with a chosen sampling distribution model is removed. We explore
the notion of defining objective prior distributions which allow one to have
some degree of flexibility, in particular in exhibiting some desirable
features, such as being proper, or centered on specific values which would be
of interest in nested model comparisons. The basic tool we use are proper
scoring rules and the main result is a class of objective prior distributions
that can be employed in scenarios where the usual model based priors fail, such
as mixture models and model selection via Bayes factors. In addition, we show
that the proposed class of priors is the result of minimising the information
it contains, providing solid interpretation to the method.
-
New results on functional prediction of the Ornstein-Uhlenbeck process in an
autoregressive Hilbert-valued and Banach-valued frameworks are derived.
Specifically, consistency of the maximum likelihood estimator of the
autocorrelation operator, and of the associated plug-in predictor is obtained
in both frameworks.
-
This paper presents new results on prediction of linear processes in function
spaces. The autoregressive Hilbertian process framework of order one (ARH(1)
process framework) is adopted. A componentwise estimator of the autocorrelation
operator is formulated, from the moment-based estimation of its diagonal
coefficients, with respect to the orthogonal eigenvectors of the
auto-covariance operator, which are assumed to be known. Mean-square
convergence to the theoretical autocorrelation operator, in the space of
Hilbert-Schmidt operators, is proved. Consistency then follows in that space.
For the associated ARH(1) plug-in predictor, mean absolute convergence to the
corresponding conditional expectation, in the considered Hilbert space, is
obtained. Hence, consistency in that space also holds. A simulation study is
undertaken to illustrate the finite-large sample behavior of the formulated
componentwise estimator and predictor. The performance of the presented
approach is compared with alternative approaches in the previous and current
ARH(1) framework literature, including the case of unknown eigenvectors.
-
A special class of standard Gaussian Autoregressive Hilbertian processes of
order one (Gaussian ARH(1) processes), with bounded linear autocorrelation
operator, which does not satisfy the usual Hilbert-Schmidt assumption, is
considered. To compensate the slow decay of the diagonal coefficients of the
autocorrelation operator, a faster decay velocity of the eigenvalues of the
trace autocovariance operator of the innovation process is assumed. As usual,
the eigenvectors of the autocovariance operator of the ARH(1) process are
considered for projection, since, here, they are assumed to be known. Diagonal
componentwise classical and bayesian estimation of the autocorrelation operator
is studied for prediction. The asymptotic efficiency and equivalence of both
estimators is proved, as well as of their associated componentwise ARH(1)
plugin predictors. A simulation study is undertaken to illustrate the
theoretical results derived.
-
Possible parameter values in a random sampling model are shown by definition
to have uniform base-rate prior probabilities. This allows a frequentist
posterior probability distribution to be calculated for such possible parameter
values conditional solely on actual study observations. If the likelihood
probability distribution of a random selection is modelled with a symmetrical
continuous function then the frequentist posterior probability of something
equal to or more extreme than the null hypothesis will be equal to the P-value;
otherwise the P value would be an approximation. An idealistic probability of
replication based on an assumption of perfect study methodological
reproducibility can be used as the upper bound of a realistic probability of
replication that may be affected by various confounding factors. Bayesian
distributions can be combined with these frequentist distributions. The
idealistic frequentist posterior probability of replication may be easier than
the P-value for non-statisticians to understand and to interpret.
-
Regression for count data is widely performed by models such as Poisson,
negative binomial (NB) and zero-inflated regression. A challenge often faced by
practitioners is the selection of the right model to take into account
dispersion, which typically occurs in count datasets. It is highly desirable to
have a unified model that can automatically adapt to the underlying dispersion
and that can be easily implemented in practice. In this paper, a discrete
Weibull regression model is shown to be able to adapt in a simple way to
different types of dispersions relative to Poisson regression: overdispersion,
underdispersion and covariate-specific dispersion. Maximum likelihood can be
used for efficient parameter estimation. The description of the model,
parameter inference and model diagnostics is accompanied by simulated and real
data analyses.
-
Consider a real-valued function that can only be observed with stochastic
noise at a finite set of design points within a Euclidean space. We wish to
determine whether there exists a convex function that goes through the true
function values at the design points. We develop an asymptotically consistent
Bayesian sequential sampling procedure that estimates the posterior probability
of this being true. In each iteration, the posterior probability is estimated
using Monte Carlo simulation. We offer three variance reduction methods --
change of measure, acceptance-rejection, and conditional Monte Carlo. Numerical
experiments suggest that the conditional Monte Carlo method should be
preferred.
-
We developed a simulation game to study the effectiveness of decision-makers
in overcoming two complexities in building cybersecurity capabilities:
potential delays in capability development; and uncertainties in predicting
cyber incidents. Analyzing 1,479 simulation runs, we compared the performances
of a group of experienced professionals with those of an inexperienced control
group. Experienced subjects did not understand the mechanisms of delays any
better than inexperienced subjects; however, experienced subjects were better
able to learn the need for proactive decision-making through an iterative
process. Both groups exhibited similar errors when dealing with the uncertainty
of cyber incidents. Our findings highlight the importance of training for
decision-makers with a focus on systems thinking skills, and lay the groundwork
for future research on uncovering mental biases about the complexities of
cybersecurity.
-
In several literatures, the authors give a new thinking of measurement theory
system based on error non-classification philosophy, which completely
overthrows the existing measurement concept system of precision, trueness and
accuracy. In this paper, by focusing on the issues of error's regularities and
effect characteristics, the authors will do a thematic interpretation, and
prove that the error's regularities actually come from different cognitive
perspectives, are also unable to be used for classifying errors, and that the
error's effect characteristics actually depend on artificial condition rules of
repeated measurement, and are still unable to be used for classifying errors.
Thus, from the perspectives of error's regularities and effect characteristics,
the existing error classification philosophy is still incorrect; and an
uncertainty concept system, which must be interpreted by the error
non-classification philosophy, naturally becomes the only way out of
measurement theory.
-
Here we define and study the properties of retrodictive inference. We derive
equations relating retrodiction entropy and thermodynamic entropy, and as a
special case, show that under equilibrium conditions, the two are identical. We
demonstrate relations involving the KL-divergence and retrodiction probability,
and bound the time rate of change of retrodiction entropy. As a specific case,
we invert various Langevin processes, inferring the initial condition of \(N\)
particles given their final positions at some later time. We evaluate the
retrodiction entropy for Langevin dynamics exactly for special cases, and find
that one's ability to infer the initial state of a system can exhibit two
possible qualitative behaviors depending on the potential energy landscape,
either decreasing indefinitely, or asymptotically approaching a fixed value. We
also study how well we can retrodict points that evolve based on the logistic
map. We find singular changes in the retrodictivity near bifurcations.
Counterintuitively, the transition to chaos is accompanied by maximal
retrodictability.
-
Numerical (and experimental) data analysis often requires the restoration of
a smooth function from a set of sampled integrals over finite bins. We present
the bin hierarchy method that efficiently computes the maximally smooth
function from the sampled integrals using essentially all the information
contained in the data. We perform extensive tests with different classes of
functions and levels of data quality, including Monte Carlo data suffering from
a severe sign problem and physical data for the Green's function of the
Fr\"ohlich polaron.
-
In this paper we develop an Expectation Maximization(EM) algorithm to
estimate the parameter of a Yule-Simon distribution. The Yule-Simon
distribution exhibits the "rich get richer" effect whereby an 80-20 type of
rule tends to dominate. These distributions are ubiquitous in industrial
settings. The EM algorithm presented provides both frequentist and Bayesian
estimates of the $\lambda$ parameter. By placing the estimation method within
the EM framework we are able to derive Standard errors of the resulting
estimate. Additionally, we prove convergence of the Yule-Simon EM algorithm and
study the rate of convergence. An explicit, closed form solution for the rate
of convergence of the algorithm is given.
-
The analysis of adverse events (AEs) is a key component in the assessment of
a drug's safety profile. Inappropriate analysis methods may result in
misleading conclusions about a therapy's safety and consequently its
benefit-risk ratio. The statistical analysis of AEs is complicated by the fact
that the follow-up times can vary between the patients included in a clinical
trial. This paper takes as its focus the analysis of AE data in the presence of
varying follow-up times within the benefit assessment of therapeutic
interventions. Instead of approaching this issue directly and solely from an
analysis point of view, we first discuss what should be estimated in the
context of safety data, leading to the concept of estimands. Although the
current discussion on estimands is mainly related to efficacy evaluation, the
concept is applicable to safety endpoints as well. Within the framework of
estimands, we present statistical methods for analysing AEs with the focus
being on the time to the occurrence of the first AE of a specific type. We give
recommendations which estimators should be used for the estimands described.
Furthermore, we state practical implications of the analysis of AEs in clinical
trials and give an overview of examples across different indications. We also
provide a review of current practices of health technology assessment (HTA)
agencies with respect to the evaluation of safety data. Finally, we describe
problems with meta-analyses of AE data and sketch possible solutions.
-
Consider a finite population of N items, where item i has a probability p_i
to be defective. The goal is to identify all items by means of group testing.
This is the generalized group testing problem (GGTP hereafter). In the case of
p_1=...=p_N=p Yao and Hwang (1990) proved that the pairwise testing algorithm
(PTA hereafter) is the optimal nested algorithm for all N if and only if p in
[1-1/\sqrt{2},\,(3-\sqrt{5})/2] (R-range hereafter) (an optimal at the boundary
values). In this note, we present a result that helps to define the generalized
pairwise testing algorithm (GPTA hereafter) for GGTP. We conjecture that in
GGTP when all p_i, i=1,...,N belong to the R-range the optimal nested procedure
is GPTA. Although this conjecture is logically reasonable, we only were able to
verify it empirically up to a particular level of N. As a byproduct, a slight
improvement of the algorithm by Kurtz and Sidi (1988) was obtained.
-
In this paper, we will see that the proportion of d as p th digit, where p >
1 and d $\in$ 0, 9, in data (obtained thanks to the hereunder developed model)
is more likely to follow a law whose probability distribution is determined by
a specific upper bound, rather than the generalization of Benford's Law to
digits beyond the first one. These probability distributions fluctuate around
theoretical values determined by Hill in 1995. Knowing beforehand the value of
the upper bound can be a way to find a better adjusted law than Hill's one.
-
Data science is the business of learning from data, which is traditionally
the business of statistics. Data science, however, is often understood as a
broader, task-driven and computationally-oriented version of statistics. Both
the term data science and the broader idea it conveys have origins in
statistics and are a reaction to a narrower view of data analysis. Expanding
upon the views of a number of statisticians, this paper encourages a big-tent
view of data analysis. We examine how evolving approaches to modern data
analysis relate to the existing discipline of statistics (e.g. exploratory
analysis, machine learning, reproducibility, computation, communication and the
role of theory). Finally, we discuss what these trends mean for the future of
statistics by highlighting promising directions for communication, education
and research.
-
We introduce a framework for updating large scale geospatial processes using
a model-data synthesis method based on Bayesian hierarchical modelling. Two
major challenges come from updating large-scale Gaussian process and modelling
non-stationarity. To address the first, we adopt the SPDE approach that uses a
sparse Gaussian Markov random fields (GMRF) approximation to reduce the
computational cost and implement the Bayesian inference by using the INLA
method. For non-stationary global processes, we propose two general models that
accommodate commonly-seen geospatial problems. Finally, we show an example of
updating an estimate of global glacial isostatic adjustment (GIA) using GPS
measurements.
-
The R package BNSP implements Markov chain Monte Carlo algorithms for fitting
non- and semi-parametric Bayesian models. In this paper we present the
implemented methods for fitting semiparametric, heteroscedastic Gaussian
models. The statistical model that we present utilizes basis function
expansions to represent semiparametric covariate effects in the mean and
variance functions, and it utilizes spike-slab priors to perform selection and
to regularize estimated effects. In addition to the main function that performs
posterior sampling, the package includes functions for assessing convergence of
the sampler and for visualizing covariate effects.
-
The rational solution of the Monty Hall problem unsettles many people. Most
people, including the authors, think it feels wrong to switch the initial
choice of one of the three doors, despite having fully accepted the
mathematical proof for its superiority. Many people, if given the choice to
switch, think the chances are fifty-fifty between their options, but still
strongly prefer to stay with their initial choice. Is there some ratio behind
these irrational feelings? We argue that intuition solves the problem of how to
behave in a real game show, not in the abstracted textbook version of the Monty
Hall problem. A real show master sometimes plays evil, either to make the show
more interesting, to save money, or because having a bad mood. A moody show
master erases any information advantage the guest could extract from him
opening other doors, driving the chance for the car being behind the chosen
door towards fifty percent. Furthermore, the show master could try to read or
manipulate the guest's strategy to the guest's disadvantage. Given this, the
preference to stay with the initial choice is a very rational mental defense
strategy of the show's guest against the threat of being manipulated by its
host. Folding these realistic possibilities into the considerations confirms
that the intuitive feelings most people have on the Monty Hall problem are
indeed very rational.





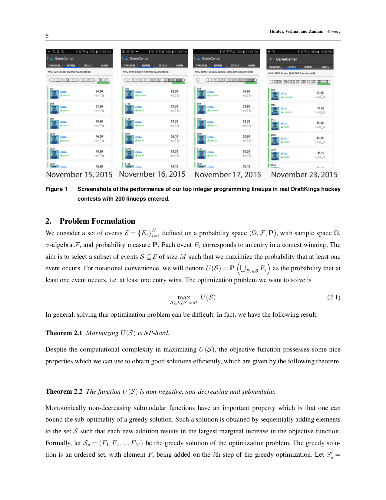 We consider the problem of selecting a portfolio of entries of fixed cardinality for contests with top-heavy payoff structures, i.e. most of the winnings go to the top-ranked entries. This framework is general and can be used to model a variety of problems, such as movie studios selecting movies to produce, venture capital firms picking start-up companies to invest in, or individuals selecting lineups for daily fantasy sports contests, which is the example we focus on here. We model the portfolio selection task as a combinatorial optimization problem with a submodular objective function, which is given by the probability of at least one entry winning. We then show that this probability can be approximated using only pairwise marginal probabilities of the entries winning when there is a certain structure on their joint distribution. We consider a model where the entries are jointly Gaussian random variables and present a closed form approximation to the objective function. Building on this, we then consider a scenario where the entries are given by sums of constrained resources and present an integer programming formulation to construct the entries. Our formulation uses principles based on our theoretical analysis to construct entries: we maximize the expected score of an entry subject to a lower bound on its variance and an upper bound on its correlation with previously constructed entries. To demonstrate the effectiveness of our integer programming approach, we apply it to daily fantasy sports contests that have top-heavy payoff structures. We find that our approach performs well in practice. Using our integer programming approach, we are able to rank in the top-ten multiple times in hockey and baseball contests with thousands of competing entries. Our approach can easily be extended to other problems with constrained resources and a top-heavy payoff structure.
We consider the problem of selecting a portfolio of entries of fixed cardinality for contests with top-heavy payoff structures, i.e. most of the winnings go to the top-ranked entries. This framework is general and can be used to model a variety of problems, such as movie studios selecting movies to produce, venture capital firms picking start-up companies to invest in, or individuals selecting lineups for daily fantasy sports contests, which is the example we focus on here. We model the portfolio selection task as a combinatorial optimization problem with a submodular objective function, which is given by the probability of at least one entry winning. We then show that this probability can be approximated using only pairwise marginal probabilities of the entries winning when there is a certain structure on their joint distribution. We consider a model where the entries are jointly Gaussian random variables and present a closed form approximation to the objective function. Building on this, we then consider a scenario where the entries are given by sums of constrained resources and present an integer programming formulation to construct the entries. Our formulation uses principles based on our theoretical analysis to construct entries: we maximize the expected score of an entry subject to a lower bound on its variance and an upper bound on its correlation with previously constructed entries. To demonstrate the effectiveness of our integer programming approach, we apply it to daily fantasy sports contests that have top-heavy payoff structures. We find that our approach performs well in practice. Using our integer programming approach, we are able to rank in the top-ten multiple times in hockey and baseball contests with thousands of competing entries. Our approach can easily be extended to other problems with constrained resources and a top-heavy payoff structure.




 We investigate a Poisson sampling design in the presence of unknown selection probabilities when applied to a population of unknown size for multiple sampling occasions. The fixed-population model is adopted and extended upon for inference. The complete minimal sufficient statistic is derived for the sampling model parameters and fixed-population parameter vector. The Rao-Blackwell version of population quantity estimators is detailed. An application is applied to an emprical population. The extended inferential framework is found to have much potential and utility for empirical studies.
We investigate a Poisson sampling design in the presence of unknown selection probabilities when applied to a population of unknown size for multiple sampling occasions. The fixed-population model is adopted and extended upon for inference. The complete minimal sufficient statistic is derived for the sampling model parameters and fixed-population parameter vector. The Rao-Blackwell version of population quantity estimators is detailed. An application is applied to an emprical population. The extended inferential framework is found to have much potential and utility for empirical studies.




 Quality control in industrial processes is increasingly making use of prior scientific knowledge, often encoded in physical models that require numerical approximation. Statistical prediction, and subsequent optimization, is key to ensuring the process output meets a specification target. However, the numerical expense of approximating the models poses computational challenges to the identification of combinations of the process factors where there is confidence in the quality of the response. Recent work in Bayesian computation and statistical approximation (emulation) of expensive computational models is exploited to develop a novel strategy for optimizing the posterior probability of a process meeting specification. The ensuing methodology is motivated by, and demonstrated on, a chemical synthesis process to manufacture a pharmaceutical product, within which an initial set of substances evolve according to chemical reactions, under certain process conditions, into a series of new substances. One of these substances is a target pharmaceutical product and two are unwanted by-products. The aim is to determine the combinations of process conditions and amounts of initial substances that maximize the probability of obtaining sufficient target pharmaceutical product whilst ensuring unwanted by-products do not exceed a given level. The relationship between the factors and amounts of substances of interest is theoretically described by the solution to a system of ordinary differential equations incorporating temperature dependence. Using data from a small experiment, it is shown how the methodology can approximate the multivariate posterior predictive distribution of the pharmaceutical target and by-products, and therefore identify suitable operating values. Materials to replicate the analysis can be found at www.github.com/amo105/chemicalkinetics.
Quality control in industrial processes is increasingly making use of prior scientific knowledge, often encoded in physical models that require numerical approximation. Statistical prediction, and subsequent optimization, is key to ensuring the process output meets a specification target. However, the numerical expense of approximating the models poses computational challenges to the identification of combinations of the process factors where there is confidence in the quality of the response. Recent work in Bayesian computation and statistical approximation (emulation) of expensive computational models is exploited to develop a novel strategy for optimizing the posterior probability of a process meeting specification. The ensuing methodology is motivated by, and demonstrated on, a chemical synthesis process to manufacture a pharmaceutical product, within which an initial set of substances evolve according to chemical reactions, under certain process conditions, into a series of new substances. One of these substances is a target pharmaceutical product and two are unwanted by-products. The aim is to determine the combinations of process conditions and amounts of initial substances that maximize the probability of obtaining sufficient target pharmaceutical product whilst ensuring unwanted by-products do not exceed a given level. The relationship between the factors and amounts of substances of interest is theoretically described by the solution to a system of ordinary differential equations incorporating temperature dependence. Using data from a small experiment, it is shown how the methodology can approximate the multivariate posterior predictive distribution of the pharmaceutical target and by-products, and therefore identify suitable operating values. Materials to replicate the analysis can be found at www.github.com/amo105/chemicalkinetics.




 Objective prior distributions represent an important tool that allows one to have the advantages of using the Bayesian framework even when information about the parameters of a model is not available. The usual objective approaches work off the chosen statistical model and in the majority of cases the resulting prior is improper, which can pose limitations to a practical implementation, even when the complexity of the model is moderate. In this paper we propose to take a novel look at the construction of objective prior distributions, where the connection with a chosen sampling distribution model is removed. We explore the notion of defining objective prior distributions which allow one to have some degree of flexibility, in particular in exhibiting some desirable features, such as being proper, or centered on specific values which would be of interest in nested model comparisons. The basic tool we use are proper scoring rules and the main result is a class of objective prior distributions that can be employed in scenarios where the usual model based priors fail, such as mixture models and model selection via Bayes factors. In addition, we show that the proposed class of priors is the result of minimising the information it contains, providing solid interpretation to the method.
Objective prior distributions represent an important tool that allows one to have the advantages of using the Bayesian framework even when information about the parameters of a model is not available. The usual objective approaches work off the chosen statistical model and in the majority of cases the resulting prior is improper, which can pose limitations to a practical implementation, even when the complexity of the model is moderate. In this paper we propose to take a novel look at the construction of objective prior distributions, where the connection with a chosen sampling distribution model is removed. We explore the notion of defining objective prior distributions which allow one to have some degree of flexibility, in particular in exhibiting some desirable features, such as being proper, or centered on specific values which would be of interest in nested model comparisons. The basic tool we use are proper scoring rules and the main result is a class of objective prior distributions that can be employed in scenarios where the usual model based priors fail, such as mixture models and model selection via Bayes factors. In addition, we show that the proposed class of priors is the result of minimising the information it contains, providing solid interpretation to the method.




 This paper presents new results on prediction of linear processes in function spaces. The autoregressive Hilbertian process framework of order one (ARH(1) process framework) is adopted. A componentwise estimator of the autocorrelation operator is formulated, from the moment-based estimation of its diagonal coefficients, with respect to the orthogonal eigenvectors of the auto-covariance operator, which are assumed to be known. Mean-square convergence to the theoretical autocorrelation operator, in the space of Hilbert-Schmidt operators, is proved. Consistency then follows in that space. For the associated ARH(1) plug-in predictor, mean absolute convergence to the corresponding conditional expectation, in the considered Hilbert space, is obtained. Hence, consistency in that space also holds. A simulation study is undertaken to illustrate the finite-large sample behavior of the formulated componentwise estimator and predictor. The performance of the presented approach is compared with alternative approaches in the previous and current ARH(1) framework literature, including the case of unknown eigenvectors.
This paper presents new results on prediction of linear processes in function spaces. The autoregressive Hilbertian process framework of order one (ARH(1) process framework) is adopted. A componentwise estimator of the autocorrelation operator is formulated, from the moment-based estimation of its diagonal coefficients, with respect to the orthogonal eigenvectors of the auto-covariance operator, which are assumed to be known. Mean-square convergence to the theoretical autocorrelation operator, in the space of Hilbert-Schmidt operators, is proved. Consistency then follows in that space. For the associated ARH(1) plug-in predictor, mean absolute convergence to the corresponding conditional expectation, in the considered Hilbert space, is obtained. Hence, consistency in that space also holds. A simulation study is undertaken to illustrate the finite-large sample behavior of the formulated componentwise estimator and predictor. The performance of the presented approach is compared with alternative approaches in the previous and current ARH(1) framework literature, including the case of unknown eigenvectors.




 A special class of standard Gaussian Autoregressive Hilbertian processes of order one (Gaussian ARH(1) processes), with bounded linear autocorrelation operator, which does not satisfy the usual Hilbert-Schmidt assumption, is considered. To compensate the slow decay of the diagonal coefficients of the autocorrelation operator, a faster decay velocity of the eigenvalues of the trace autocovariance operator of the innovation process is assumed. As usual, the eigenvectors of the autocovariance operator of the ARH(1) process are considered for projection, since, here, they are assumed to be known. Diagonal componentwise classical and bayesian estimation of the autocorrelation operator is studied for prediction. The asymptotic efficiency and equivalence of both estimators is proved, as well as of their associated componentwise ARH(1) plugin predictors. A simulation study is undertaken to illustrate the theoretical results derived.
A special class of standard Gaussian Autoregressive Hilbertian processes of order one (Gaussian ARH(1) processes), with bounded linear autocorrelation operator, which does not satisfy the usual Hilbert-Schmidt assumption, is considered. To compensate the slow decay of the diagonal coefficients of the autocorrelation operator, a faster decay velocity of the eigenvalues of the trace autocovariance operator of the innovation process is assumed. As usual, the eigenvectors of the autocovariance operator of the ARH(1) process are considered for projection, since, here, they are assumed to be known. Diagonal componentwise classical and bayesian estimation of the autocorrelation operator is studied for prediction. The asymptotic efficiency and equivalence of both estimators is proved, as well as of their associated componentwise ARH(1) plugin predictors. A simulation study is undertaken to illustrate the theoretical results derived.




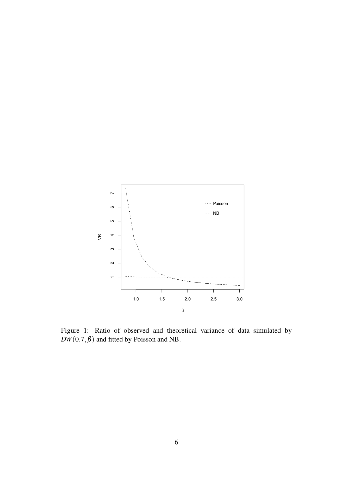 Regression for count data is widely performed by models such as Poisson, negative binomial (NB) and zero-inflated regression. A challenge often faced by practitioners is the selection of the right model to take into account dispersion, which typically occurs in count datasets. It is highly desirable to have a unified model that can automatically adapt to the underlying dispersion and that can be easily implemented in practice. In this paper, a discrete Weibull regression model is shown to be able to adapt in a simple way to different types of dispersions relative to Poisson regression: overdispersion, underdispersion and covariate-specific dispersion. Maximum likelihood can be used for efficient parameter estimation. The description of the model, parameter inference and model diagnostics is accompanied by simulated and real data analyses.
Regression for count data is widely performed by models such as Poisson, negative binomial (NB) and zero-inflated regression. A challenge often faced by practitioners is the selection of the right model to take into account dispersion, which typically occurs in count datasets. It is highly desirable to have a unified model that can automatically adapt to the underlying dispersion and that can be easily implemented in practice. In this paper, a discrete Weibull regression model is shown to be able to adapt in a simple way to different types of dispersions relative to Poisson regression: overdispersion, underdispersion and covariate-specific dispersion. Maximum likelihood can be used for efficient parameter estimation. The description of the model, parameter inference and model diagnostics is accompanied by simulated and real data analyses.




 Consider a real-valued function that can only be observed with stochastic noise at a finite set of design points within a Euclidean space. We wish to determine whether there exists a convex function that goes through the true function values at the design points. We develop an asymptotically consistent Bayesian sequential sampling procedure that estimates the posterior probability of this being true. In each iteration, the posterior probability is estimated using Monte Carlo simulation. We offer three variance reduction methods -- change of measure, acceptance-rejection, and conditional Monte Carlo. Numerical experiments suggest that the conditional Monte Carlo method should be preferred.
Consider a real-valued function that can only be observed with stochastic noise at a finite set of design points within a Euclidean space. We wish to determine whether there exists a convex function that goes through the true function values at the design points. We develop an asymptotically consistent Bayesian sequential sampling procedure that estimates the posterior probability of this being true. In each iteration, the posterior probability is estimated using Monte Carlo simulation. We offer three variance reduction methods -- change of measure, acceptance-rejection, and conditional Monte Carlo. Numerical experiments suggest that the conditional Monte Carlo method should be preferred.




 We developed a simulation game to study the effectiveness of decision-makers in overcoming two complexities in building cybersecurity capabilities: potential delays in capability development; and uncertainties in predicting cyber incidents. Analyzing 1,479 simulation runs, we compared the performances of a group of experienced professionals with those of an inexperienced control group. Experienced subjects did not understand the mechanisms of delays any better than inexperienced subjects; however, experienced subjects were better able to learn the need for proactive decision-making through an iterative process. Both groups exhibited similar errors when dealing with the uncertainty of cyber incidents. Our findings highlight the importance of training for decision-makers with a focus on systems thinking skills, and lay the groundwork for future research on uncovering mental biases about the complexities of cybersecurity.
We developed a simulation game to study the effectiveness of decision-makers in overcoming two complexities in building cybersecurity capabilities: potential delays in capability development; and uncertainties in predicting cyber incidents. Analyzing 1,479 simulation runs, we compared the performances of a group of experienced professionals with those of an inexperienced control group. Experienced subjects did not understand the mechanisms of delays any better than inexperienced subjects; however, experienced subjects were better able to learn the need for proactive decision-making through an iterative process. Both groups exhibited similar errors when dealing with the uncertainty of cyber incidents. Our findings highlight the importance of training for decision-makers with a focus on systems thinking skills, and lay the groundwork for future research on uncovering mental biases about the complexities of cybersecurity.




 Numerical (and experimental) data analysis often requires the restoration of a smooth function from a set of sampled integrals over finite bins. We present the bin hierarchy method that efficiently computes the maximally smooth function from the sampled integrals using essentially all the information contained in the data. We perform extensive tests with different classes of functions and levels of data quality, including Monte Carlo data suffering from a severe sign problem and physical data for the Green's function of the Fr\"ohlich polaron.
Numerical (and experimental) data analysis often requires the restoration of a smooth function from a set of sampled integrals over finite bins. We present the bin hierarchy method that efficiently computes the maximally smooth function from the sampled integrals using essentially all the information contained in the data. We perform extensive tests with different classes of functions and levels of data quality, including Monte Carlo data suffering from a severe sign problem and physical data for the Green's function of the Fr\"ohlich polaron.




 Data science is the business of learning from data, which is traditionally the business of statistics. Data science, however, is often understood as a broader, task-driven and computationally-oriented version of statistics. Both the term data science and the broader idea it conveys have origins in statistics and are a reaction to a narrower view of data analysis. Expanding upon the views of a number of statisticians, this paper encourages a big-tent view of data analysis. We examine how evolving approaches to modern data analysis relate to the existing discipline of statistics (e.g. exploratory analysis, machine learning, reproducibility, computation, communication and the role of theory). Finally, we discuss what these trends mean for the future of statistics by highlighting promising directions for communication, education and research.
Data science is the business of learning from data, which is traditionally the business of statistics. Data science, however, is often understood as a broader, task-driven and computationally-oriented version of statistics. Both the term data science and the broader idea it conveys have origins in statistics and are a reaction to a narrower view of data analysis. Expanding upon the views of a number of statisticians, this paper encourages a big-tent view of data analysis. We examine how evolving approaches to modern data analysis relate to the existing discipline of statistics (e.g. exploratory analysis, machine learning, reproducibility, computation, communication and the role of theory). Finally, we discuss what these trends mean for the future of statistics by highlighting promising directions for communication, education and research.